
内容
mapreduce原语(独创)
mapreduce工作流程(重点)
MR作业提交流程(重点)
YARN RM-HA搭建(熟练)
运行自带的wordcount(了解)
动手写wordcount(熟练)
MapReduce原语
hadoop MapReduce框架可以让你的应用在集群中
可靠地
容错地
并行
处理TB级别的数据
1024TB=1PB 1024PB=1EB 1024EB=1ZB
MapReduce原语

“相同”key的键值对为一组调用一次reduce方法,方法内迭代这一组数据进行计算
分组比较器
YARN:资源管理框架
ResourceManager:一个 主
NodeManager:很多,每个DataNode上有一个 从
Container(容器):CPU、内存
公司为了营业,挣钱租老王家的写字楼
公司相当于MR作业
MR任务相当于公司员工,员工干活,相当于MR的任务运行。
员工在办公室干活,任务在容器运行。
每个容器同时运行一个任务
客人提出订几间房

1、一个ResourceManager主节点
2、每个DataNode上一个NodeManager从节点
3、每个运行于MapReduce的程序有一个MRAppMaster
公司的运作流程

1、MapReduce将输入的数据集逻辑切片 split
2、map任务以并行方式处理切片数据
3、框架对map输出排序,然后将数据发送给reduce
4、MapReduce的输入输出数据存在于同一个文件系统(HDFS)
5、框架负责任务调度、任务监控和失败任务的重新执行
容错地、可靠地、并行计算

1、MapReduce处理键值对形式的很多键值对输入,生成键值对形式的很多键值对输出
2、框架会对键和值序列化,因此键类型和值类型需要实现Writable接口。框架会对键进行排序,因此必须实现WritableComparable接口。
3、map输出键值对类型和reduce键值对输入类型一致
4、map的输入键值对类型和输出键值对类型一般不一致
5、reduce的输入键值对类型和输出键值对类型一般不一致
尽管hadoop框架是java开发的,MapReduce应用不一定得java开发。
hadoop streaming允许用户使用可执行文件的方式提供mapper和reducer,创建和执行作业。
hadoop pipes是一个跟SWIG兼容的C++ API,用于开发MapReduce应用(不基于JNI)。
mapreduce工作流程
为什么叫MapReduce:MapTask & ReduceTask

1、每个block会有map任务
2、block切分为切片,每个切片对应一个map任务,默认一个block一个切片,一个map
3、map默认按行读取切片数据,组成键值对<当前行字节偏移量, "读到的行字符串">
4、map函数对该键值对进行计算,输出若干键值对。<key, value, partition>
partition指定该键值对由哪个reducer进行处理
5、map输出的kvp写到环形缓冲区,环形缓冲区默认100MB,阈值80%,当环缓达到80%就向磁盘溢写小文件,该小文件首先按照分区号排序,相同分区号的按key进行排序。
6、默认如果落磁盘的小文件达到了3个,则进行归并,归并的大文件也是按分区号排序,相同分区号按照key进行排序。只是一个归并。
7、如果map任务处理完了,它的输出被下载到reducer所在主机
按照HTTP GET的方式下载到reducer:
reducer发送HTTP GET请求到mapper主机下载数据,该过程是洗牌shuffle
8、每个map任务都要经历运行结束洗牌的过程
9、可以设置combinClass,先在map端对数据进行一个压缩,比如10w个<hello,1>压缩为1个<hello, 10w>通过网络IO洗牌,肯定要快很多。一般情况下,combineClass就是一个reducerClass。
combinerClass的设置要求数据算法满足结合律。
交换律
1+2=2+1
结合律
1+2+3=(1+2)+3=1+(2+3)
map1 5/3
map2 7/6 reduce: 5/3+7/6+8/11 =? reduce:(5+7+8)/(3+6+11)
map3 8/11
map任务结束
reeduce任务开始
9、等所有map任务都运行结束,并且洗牌结束,每个reducer获取到它自己应得的所有数据,此时开始reducer处理过程。
10、如果有时间,reduce会对洗牌获取的数据进行归并落磁盘
如果没有时间,也归并,只是可能不落磁盘,直接交给reduce方法进行迭代处理了。
洗牌获取到的数据也可能不落磁盘,此时归并的键值对来源可能是磁盘的和内存的一个混合。
11、reduce按照key进行分组,每个分组调用一次reduce方法,该方法迭代计算,将结果写到HDFS输出。
当一个map任务计算结束,所有的reduce需要使用http get请求获取各自分区编号的数据,当所有map任务结束后,开始reduce计算阶段。
blk按照设置进行切片,一个切片对应一个map任务,map按行读取切片内容,以键值对的形式发给map方法(<"偏移量", “zifuchuan”>)
当map对当前简直对计算完成,要写到环形缓冲区,在写之前要计算该键值对的分区编号
默认情况下,key的hash值对reduce个数取模。
当环形缓冲区大小达到到80%的时候,需要向磁盘溢写数据,在溢写的时候需要对键值对按照分区排序,分区内按照key的字典序排序(快排排序)
溢写的小文件如果达到3个,则进行归并,归并为大文件,大文件也是按照分区排序,分区内按照key的字典序排序。
当一个map任务处理完它的切片的数据,此时所有的reduce任务到该map的机器以http get请求获取各自编号分区的数据,下载到reduce本地
reduce获取到map的数据后,如果有时间,也会进行归并
并不能保证此时所有的map都计算结束了。
只有当所有的map计算结束,同时reduce获取到所有的数据之后,才开始进行reduce计算。
按照原语,相同key的键值对为一组,调用一次reduce方法,方法内迭代这组数据计算,结果输出到HDFS中。
mapreduce是一套分布式计算的流程、框架
数单词游戏:

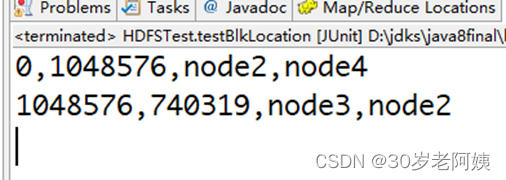
getFileBlockLocations(new Path(), offset, len);

reduce从map端拉取数据的过程称为洗牌shuffle
通过网络拉取,慢!!!
要对map端数据进行压缩:
Combiner:
<hello, 1> 1000万个 <hello, 1000万>
但是不能保证combiner什么时候都能用:
需要计算满足结合律:(A+B)+C=A+(B+C)
job.setCombinerClass(MyReducer.class)
8/9
4/7 REDUCE: (8+4+2)/(9+7+11)
2/11
也不能保证combiner什么时候都用得上:
环形缓冲区小文件归并,进行combiner,如果不归并,没有combiner过程。
reducer通过HTTP按照分区号获取map输出文件的数据。map端有一个HTTP服务处理该reducer的HTTP请求。该HTTP服务最大线程数由mapreduce.shuffle.Max.threads属性指定。这个属性指定nodemanager的线程数,而不是对map任务指定线程数(该数字在多个不同的任务之间共享),因为nodemanager上有可能运行了好几个map任务。默认值是0,表示最大线程数是服务器处理器核心数的两倍。
map输出文件位于运行map任务的本地磁盘。一个reduce任务需要从集群中多个map任务获取指定分区的数据。多个map任务有可能是在不同时间完成的,每当一个map任务运行完,reduce就从该map任务获取指定分区数据。reduce任务会以多线程的方式从多个map任务并行获取指定分区数据。默认线程数是5,可以通过mapreduce.reduce.shuffle.parallelcopies属性指定。
reducer拷贝map的输出如果很小,则放在内存中(mapreduce.reduce.shuffle.input.buffer.percent指定堆空间百分比)否则拷贝到磁盘。当内存缓冲区数据大小达到阈值(mapreduce.reduce.shuffle.merge.percent
)或map输出文件个数达到阈值(mapreduce.reduce.merge.inmem.threshold
),就发生文件合并溢写到磁盘上。如果指定combiner,此处也会进行combine。
二次排序(先了解)
在map阶段按照key对键值对进行排序,对值不排序。如果相对value进行排序,就需要二次排序。
需求:查找每年的最高气温
数据格式:年份为key,每天的气温是value
所谓二次排序:
1、新的key应该是输入的key和value的组合
2、按照复合key进行比较排序
3、分区比较器和分组比较器只对复合key中的原生key进行分区和分组
总结
Map:
1、根据业务需求处理数据并映射为KV模型
2、并行分布式
3、计算向数据移动
Reduce:
1、数据全量/分量加工
2、Reducer中可以包含不同的key 分区的范围大于分组
3、相同分区的Key汇聚到一个Reducer中
4、“相同”的Key调用一次reduce方法
5、排序和比较实现key的汇聚
K,V使用自定义数据类型 MyKey:WritableComparable
MyValue:Writable
1、节省开发成本,提高程序自由度
2、框架会对键和值序列化,因此键类型和值类型需要实现Writable接口。
3、框架会对键进行排序,因此必须实现WritableComparable接口。
作业:
- mapreduce处理过程,自己的语言写
- java API操作HDFS
MR作业提交流程
YARN
ResourceManager管理集群中所有的资源
通过NodeManager管理
NodeManager通过Container管理资源
Container包装资源:CPU/内存/IO
MapReduce作业
AppMaster 调度
向RM申请资源
MapTask
ReduceTask
客户端:
RM客户端:用于申请资源
AM客户端:用于跟AppMaster交互
YARN:解耦资源与计算
ResourceManager
主,核心
集群节点资源管理
NodeManager
与RM汇报资源
管理Container生命周期
计算框架中的资源都以Container表示
Container:【由节点NM管理,CPU,MEM,I/O大小,启动命令】
内存:1024MB
CPU:1个虚拟核心 vcore
默认NodeManager启动线程监控Container大小,超出申请资源额度,kill
支持Linux内核的Cgroup
MR :
AppMaster 拥有 RM客户端
作业为单位,避免单点故障,负载到不同的节点
创建Task,需要和RM申请资源(Container)
Task-Container
Map任务
Reduce任务
Client:
RM-Client:请求资源创建AM
AM-Client:与AM交互
YARN:Yet Another Resource Negotiator;
Hadoop 2.0新引入的资源管理系统,直接从MRv1演化而来的;
核心思想:将MRv1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现
ResourceManager:负责整个集群的资源管理和调度
ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等
YARN的引入,使得多个计算框架可运行在一个集群中
每个应用程序对应一个ApplicationMaster
目前多个计算框架可以运行在YARN上,比如MapReduce、Spark、Storm等
MapReduce On YARN:MRv2
将MapReduce作业直接运行在YARN上,而不是由JobTracker和TaskTracker构建的MRv1系统中
基本功能模块
YARN:负责资源管理和调度
MRAppMaster:负责任务切分、任务调度、任务监控和容错等
MapTask/ReduceTask:任务驱动引擎,与MRv1一致
每个MapRduce作业对应一个MRAppMaster
MRAppMaster任务调度
YARN将资源分配给MRAppMaster
MRAppMaster进一步将资源分配给内部的任务
MRAppMaster****容错
失败后,由YARN重新启动
任务失败后,MRAppMaster重新申请资源
ResourceManager挂怎么办?RM-HA
流程
1、客户端,提交MapReduce作业
2、YARN的资源管理器(Resource Manager),协调集群中计算资源的分配
3、YARN的节点管理器(Node Manager),启动并监控集群中的计算容器
4、MapReduce的Application Master,协调MapReduce作业中任务的运行。Application Master和MapReduce任务运行于容器中,这些容器由resourcemanager调度,由nodemanager管理。
5、分布式文件系统(一般是HDFS),在组件之间共享作业数据。
Job对象的submit方法创建了一个内部的JobSubmitter实例并调用该实例的submitJobInternal方法。一旦提交了作业,waitForCompletion方法每秒钟轮询作业的执行进度,如果进度发生了变化,则向控制台报告进度。当作业成功完成,展示作业计数器的数据。否则展示作业失败的错误日志信息。
客户端:JobSubmitter实现的作业提交的过程有如下几个步骤:
1、向resourcemanager申请一个新的application ID,用于MapReduce作业的ID
2、检查作业的输出。如果没有指定输出或者输出路径已经存在,则不提交作业,MapReduce程序抛异常
3、计算作业的输入切片。如果不能计算切片(比如输入路径不存在等),不提交作业,MR程序抛异常。
4、拷贝执行作业需要的资源到共享文件系统的以作业ID命名的目录中,这些资源包括作业的jar包,配置文件,计算好的输入切片。作业的jar包有一个很高的副本数量(mapreduce.client.submit.file.replication指定,默认值是10),这样当nodemanager如果运行作业中的任务,会有很多副本可以访问。
5、调用resourcemanager的submitApplication方法提交作业。
1、YARN为请求分配一个容器,resourcemanager通过容器所在节点上的nodemanager在该容器中启动application master进程。
2、MapReduce作业的application master是一个java app,主入口类是MRAppMaster。从HDFS抽取客户端计算好的输入切片,为每一个切片创建一个map任务对象,以及一定数量的reduce任务对象.
application master会为作业中所有的map任务以及reduce任务向resourcemanager请求容器。为map任务的请求会首先进行并且相对于reduce任务请求有更高的优先级。当map任务完成率达到了5%之后才会为reduce任务发送容器请求。
appmaster从hdfs抽取客户端上传的信息,计算好map对象和reduce对象,首先向resourcemanager为map任务申请资源,当map任务完成5%之后为reduce任务申请资源
reduce任务可以运行于集群中的任意位置,而map任务会有本地读取数据的限制。移动计算而不是数据。数据本地。次之为机架本地。
请求会指定每个任务需要的内存和cpu资源。默认情况下为每个map任务或reduce任务分配1024MB的内存和一个虚拟核心。这些值对于每个作业都是可以配置的:mapreduce.map.memory.mb,
mapreduce.reduce.memory.mb
mapreduce.map.cpu.vcores
以及mapreduce.reduce.cpu.vcores。
一旦resourcemanager在一个节点上的一个容器中为一个任务分配了资源,application master与nodemanager通信,启动容器。任务通过一个java app来执行,该app的主入口类是YarnChild。在它可以开始任务的执行之前,它要本地化任务需要的资源,包括jar****包,配置文件,以及分布式缓存中存储的其他共享文件。最后,它开始运行map任务或者reduce任务。
当作业的最后一个任务完成并通知application master,AppMaster就更改作业的状态为”successfully”。作业就打印信息告知客户端,客户端waitForCompletion方法返回。此时也会在控制台打印作业的统计信息和计数器的信息。
作业完成,application master****所在容器和任务所在容器销毁工作状态(中间的输出结果删除)。作业的信息被作业历史服务器存档以备以后查询使用。
YARN RM-HA搭建
mapred-site.xml
local/classic/yarn
指定mr作业运行的框架:要么本地运行,要么使用MRv1,要么使用yarn
<property><name>mapreduce.framework.name</name>
<value>yarn</value>
</property>yarn-site.xml
<property><name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> <property><name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property> <property><name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property> <property><name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property> <property><name>yarn.resourcemanager.hostname.rm1</name>
<value>node3</value>
</property> <property><name>yarn.resourcemanager.hostname.rm2</name>
<value>node4</value>
</property> <property><name>yarn.resourcemanager.zk-address</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>将配置文件在四台服务器同步
scp node[234]:pwd
首先启动HDFS
start-ha.sh
#!/bin/bash
for node in node2 node3 node4
do
ssh $node "source /etc/profile; zkServer.sh start"
done
sleep 1
start-dfs.sh
echo "--------------node1-jps----------------"
jps
for node in node2 node3 node4
do
echo "---------------$node-jps-------------------"
ssh $node "source /etc/profile; jps"
done
在node3或node4上执行命令:
start-yarn.sh
在node4或者node3上执行命令:
yarn-daemon.sh start resourcemanager
停止:
在node3或者node4上执行:
stop-yarn.sh
在node4或者node3上执行:
yarn-deamon.sh stop resourcemanager
访问resourcemanager的web页面
运行自带的wordcount
运行的命令:
cd $HADOOP_HOME
cd share/hadoop/mapreduce
hadoop jar hadoop-mapreduce-examples-2.6.5.jar wordcount /input /output
*input:是hdfs文件系统中数据所在的目录
*ouput:是hdfs中不存在的目录,mr程序运行的结果会输出到该目录
输出目录内容:
-rw-r--r-- 3 root supergroup 0 2017-07-02 02:49 /mr/test/output/_SUCCESS
-rw-r--r-- 3 root supergroup 49 2017-07-02 02:49 /mr/test/output/part-r-00000
/_SUCCESS:是信号/标志文件
/part-r-00000:是reduce输出的数据文件
r:reduce的意思,00000是对应的reduce编号,多个reduce会有多个数据文件
启动脚本和停止脚本:
start-hdfs-ha-rm-ha.sh
#!/bin/bash
for node in node2 node3 node4
do
ssh $node "source /etc/profile; zkServer.sh start"
done
sleep 1
start-dfs.sh
ssh node3 ". /etc/profile; start-yarn.sh"
ssh node4 ". /etc/profile; yarn-daemon.sh start resourcemanager"
echo "--------------node1-jps----------------"
jps
for node in node2 node3 node4
do
echo "---------------$node-jps-------------------"
ssh $node "source /etc/profile; jps"
done
stop-hdfs-ha-rm-ha.sh
#!/bin/bash
ssh node4 ". /etc/profile; stop-yarn.sh"
ssh node3 ". /etc/profile; yarn-daemon.sh stop resourcemanager"
stop-dfs.sh
for node in node2 node3 node4
do
ssh $node "source /etc/profile; zkServer.sh stop"
done
echo "-------------node1-jps-----------------"
jps
for node in node2 node3 node4
do
echo "---------------$node-jps-----------------"
ssh $node "source /etc/profile; jps"
done
动手写wordcount
1、新建eclipse的java项目
2、添加hadoop的jar包依赖
121个jar包
$HADOOP_HOME/share/hadoop/{common,common/lib,hdfs,hdfs/lib,mapreduce,mapreduce/lib,tools/lib,yarn,yarn/lib}.jar
3、添加hadoop的配置文件到类路径
从集群拷贝这四个文件到当前项目类路径
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
4、编写Mapper、Reducer以及MainClass
wordcount
WCMapper.java
package com.bjsxt.mr.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Text outKey = new Text();
private LongWritable outValue = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
Thread.sleep(9999999999L);
//一句话 hello bjsxt 1
String line = value.toString();
//将一句话按照空格隔开为单个单词
// {"hello", "bjsxt", "1"}
String[] words = line.split(" ");
for (String word : words) {
outKey.set(word);
outValue.set(1);
// <"hello", 1>
// <"bjsxt", 1>
// <"1", 1>
context.write(outKey, outValue);
}
}
}
WCReducer.java
package com.bjsxt.mr.wordcount;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
private LongWritable outValue = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
// key表示的单词出现的次数,总数
long sum = 0;
// 获取values的迭代器,用于遍历
Iterator<LongWritable> itera = values.iterator();
//<"zhangsan", 1>
//<"zhangsan-0", 1>
//<"zhangsan-1", 1>
//<"zhangsan-2", 1>
//<"zhangsan-3", 1>
//<"zhangsan-4", 1>
while (itera.hasNext()) {
// 获取该值
LongWritable val = itera.next();
// 将该值转换为long类型
long num = val.get();
// 逐个求和
sum += num;
}
// 将总数封装为LongWritable类型对象
outValue.set(sum);
// 输出到HDFS
context.write(key, outValue);
}
}
MainClass.java
package com.bjsxt.mr.wordcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class MainClass {
public static void main(String[] args) throws Exception {
if (args == null || args.length != 2) {
System.out.println("Usage : yarn jar wc.jar com.bjsxt.mr.wordcount.MainClass <input path> <output path>");
System.exit(1);
}
Configuration conf = new Configuration(true);
Job job = Job.getInstance(conf);
//设置主入口程序
job.setJarByClass(MainClass.class);
// 设置作业名称,该名称可以在UI上看到
job.setJobName("我的数单词");
// Path inputPath = new Path("/mr/wc/input/hello.txt");
Path inputPath = new Path(args[0]);
//设置输入路径
FileInputFormat.addInputPath(job, inputPath);
// Path outputPath = new Path("/mr/wc/output");
Path outputPath = new Path(args[1]);
//指定输出路径,该路径一定不能存在
FileOutputFormat.setOutputPath(job, outputPath);
//指定mapper类
job.setMapperClass(WCMapper.class);
//指定reducer类
job.setReducerClass(WCReducer.class);
//map输出键值对的key类型
job.setMapOutputKeyClass(Text.class);
//map端输出键值对的value类型
job.setMapOutputValueClass(LongWritable.class);
//提交作业
job.waitForCompletion(true);
}
}
5、打包
只打包三个类就可以。
6、上传
7、运行
yarn jar </path/to/your/jar.jar> /<inputpath> /<outputpath>
版权归原作者 30岁老阿姨 所有, 如有侵权,请联系我们删除。