
目录
1、HikariCP配置说明
HikariCP: https://github.com/brettwooldridge/HikariCP
2、spring配置文件里,配置HikariCP数据库连接池
<bean id="hikariConfig"class="com.zaxxer.hikari.HikariConfig"><property name="driverClassName" value="${db.driverClassName}"/><property name="jdbcUrl" value="${db.url}"/><property name="username" value="${db.username}"/><property name="password" value="${db.password}"/><property name="connectionTimeout" value="${db.connectionTimeout}"/><property name="readOnly" value="${db.readOnly}"/><property name="maxLifetime" value="${db.maxLifetime}"/><property name="maximumPoolSize" value="${db.maximumPoolSize}"/><property name="idleTimeout" value="${db.idleTimeout}"/><property name="poolName" value="${db.poolName}"/><property name="connectionTestQuery" value="${db.connectionTestQuery}"/><property name="dataSourceProperties"><props><prop key="cachePrepStmts">${db.cachePrepStmts}</prop><prop key="prepStmtCacheSize">${db.prepStmtCacheSize}</prop><prop key="prepStmtCacheSqlLimit">${db.prepStmtCacheSqlLimit}</prop><prop key="useServerPrepStmts">${db.useServerPrepStmts}</prop><prop key="useLocalSessionState">${db.useLocalSessionState}</prop><prop key="useLocalTransactionState">${db.useLocalTransactionState}</prop><prop key="rewriteBatchedStatements">${db.rewriteBatchedStatements}</prop><prop key="cacheResultSetMetadata">${db.cacheResultSetMetadata}</prop><prop key="cacheServerConfiguration">${db.cacheServerConfiguration}</prop><prop key="elideSetAutoCommits">${db.elideSetAutoCommits}</prop><prop key="maintainTimeStats">${db.maintainTimeStats}</prop></props></property></bean>
3、注意连接池大小设置,重点推荐官方说明文档
https://github.com/brettwooldridge/HikariCP/wiki/About-Pool-Sizing
Configuring a connection pool is something that developers often get wrong. There are several, possibly counter-intuitive for some, principles that need tobe understood when configuring the pool.10,000SimultaneousFront-EndUsersImagine that you have a website that while maybe not Facebook-scale still often has 10,000 users making database requests simultaneously -- accounting for some 20,000 transactions per second. How big should your connection pool be?You might be surprised that the question is not how big but rather how small!Watchthisshort video from the OracleReal-WorldPerformance group for an eye-opening demonstration (~10 min.):{SpoilerAlert}if you didn't watch the video. Oh come on!Watch it then come back here.
You can see from the video that reducing the connection pool size alone, in the absence of any other change, decreased the response times of the application from ~100ms to~2ms -- over 50x improvement.
But why?We seem tohave understood in other parts of computing recently that less is more. Why is it that withonly4-threads an nginx web-server can substantially out-perform an Apache web-server with100 processes?Isn't it obvious if you think back toComputerScience101?Even a computer withoneCPU core can "simultaneously" support dozens or hundreds of threads. But we all [should] know that this is merely a trick by the operating system though the magic of time-slicing. In reality, that single core can only execute one thread at a time; then the OS switches contexts and that core executes code for another thread, and so on. It is a basic Law of Computing that given a single CPU resource, executing A and B sequentially will always be faster than executing A and B"simultaneously" through time-slicing. Once the number of threads exceeds the number of CPU cores, you're going slower by adding more threads, not faster.
That is almost true...LimitedResourcesIt is not quite as simple as stated above, but it's close. There are a few other factors at play. When we look at what the major bottlenecks for a database are, they can be summarized as three basic categories:CPU,Disk,Network. We could add Memory in there, but compared toDisk and Network there are several orders of magnitude difference in bandwidth.
If we ignored Disk and Network it would be simple. On a server with8 computing cores, setting the number of connections to8 would provide optimal performance, and anything beyond this would start slowing down due tothe overhead of context switching. But we cannot ignore Disk and Network. Databases typically store data on a Disk, which traditionally is comprised of spinning plates of metal withread/write heads mounted on a stepper-motor driven arm. The read/write heads can only be in one place at a time (reading/writing data for a single query) and must "seek"toanew location toread/write data for a different query. So there is a seek-time cost, and also a rotational cost whereby the disk has towaitfor the data to"come around again" on the platter tobe read/written. Caching of course helps here, but the principle still applies.
Duringthis time ("I/O wait"), the connection/query/thread is simply "blocked" waiting for the disk. And it is during this time that the OS could put that CPU resource tobetter use by executing some more code for another thread. So, because threads become blocked on I/O, we can actually get more work done by having a number of connections/threads that is greater than the number of physical computing cores.
How many more?We shall see. The question of how many more also depends on the disk subsystem, because newer SSD drives do not have a "seek time" cost or rotational factors todealwith. Don't be tricked into thinking,"SSDs are faster and therefore I can have more threads".That is exactly 180 degrees backwards. Faster, no seeks, no rotational delays means less blocking and therefore fewer threads [closer tocore count] will perform better than more threads. More threads only perform better when blocking creates opportunities forexecuting.
Network is similar todisk.Writing data out over the wire, through the ethernet interface, can also introduce blocking when the send/receive buffers fill up and stall. A10-Giginterface is going tostall less than Gigabit ethernet, which will stall less than a 100-megabit. But network is a 3rd place runner in terms of resource blocking and some people often omit it from their calculations.
Here's another chart tobreak up the wall of text.
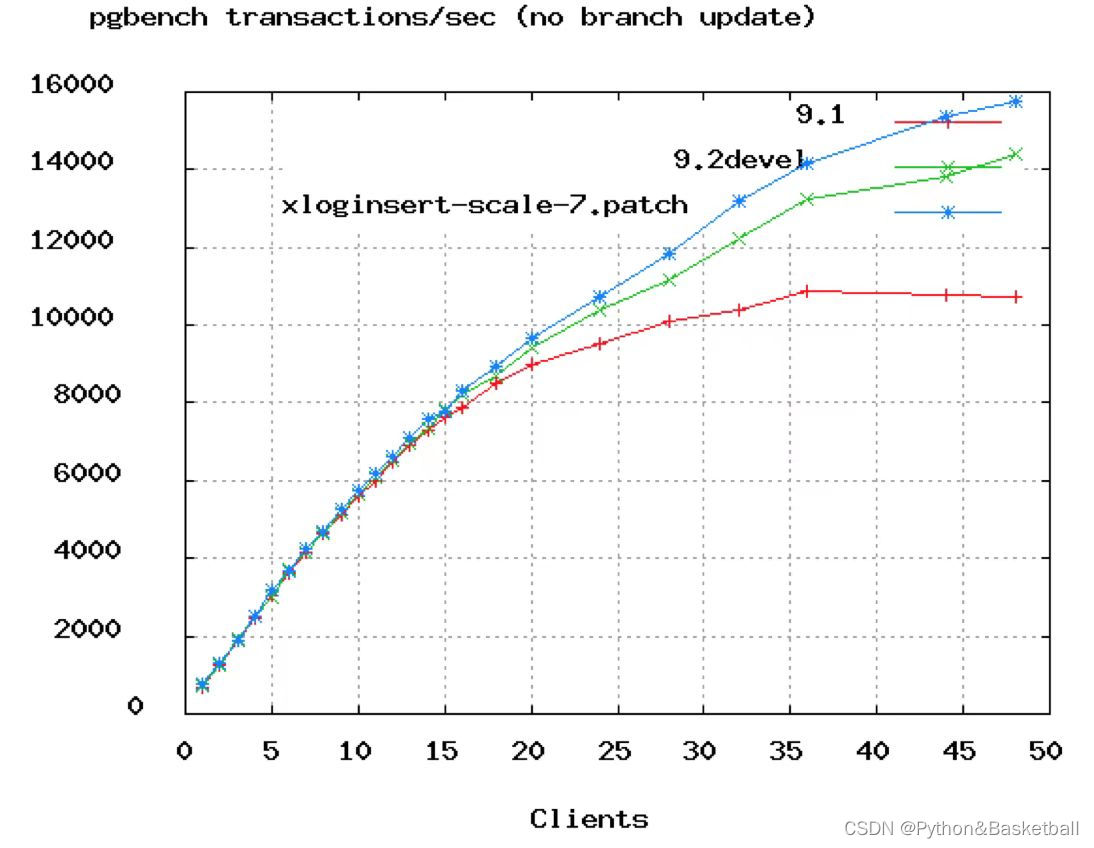
You can see in the above PostgreSQL benchmark that TPS rates start toflatten out at around 50connections. And in Oracle's video above they showed dropping the connections from 2048 down tojust96.We would say that even 96 is probably too high, unless you're looking at a 16 or 32-core box.
TheFormulaThe formula below is provided by the PostgreSQL project as a starting point, but we believe it will be largely applicable across databases. You should test your application, i.e. simulate expected load, and try different pool settings around this starting point:
connections =((core_count *2)+ effective_spindle_count)A formula which has held up pretty well across a lot of benchmarks for years is
that for optimal throughput the number of active connections should be somewhere
near ((core_count *2)+ effective_spindle_count).Core count should not include
HT threads, even if hyperthreading is enabled. Effective spindle count is zero if
the active data set is fully cached, and approaches the actual number of spindles
as the cache hit rate falls....There hasn't been any analysis so far regarding
how well the formula works withSSDs.
Guess what that means?Your little 4-Core i7 server withone hard disk should be running a connection pool of:9=((4*2)+1).Call it 10 as a nice round number. Seem low?Give it a try, we'd wager that you could easily handle 3000 front-end users running simple queries at 6000TPS on such a setup. If you run load tests, you will probably see TPS rates starting tofall, and front-end response times starting toclimb, as you push the connection pool much past 10(on that given hardware).Axiom:You want a small pool, saturated withthreads waiting forconnections.
If you have 10,000 front-end users, having a connection pool of 10,000 would be shear insanity.1000 still horrible. Even100 connections,overkill. You want a small pool of a few dozen connections at most, and you want the rest of the application threads blocked on the pool awaiting connections. If the pool is properly tuned it is set right at the limit of the number of queries the database is capable of processing simultaneously -- which is rarely much more than (CPU cores *2) as noted above.
We never cease toamaze at the in-house web applications we've encountered,witha few dozen front-end users performing periodic activity, and a connection pool of 100connections. Don't over-provision your database."Pool-locking"The prospect of "pool-locking" has been raised withrespecttosingle actors that acquire many connections. This is largely an application-level issue. Yes, increasing the pool size can alleviate lockups in these scenarios, but we would urge you toexamine first what can be done at the application level before enlarging the pool.
The calculation of pool size in order toavoid deadlock is a fairly simple resource allocation formula:
pool size =Tn x (Cm-1)+1WhereTn is the maximum number of threads, and Cm is the maximum number of simultaneous connections held by a single thread.
For example, imagine three threads (Tn=3), each of which requiresfour connections toperform some task (Cm=4).The pool size required toensure that deadlock is never possible is:
pool size =3 x (4-1)+1=10Another example, you have a maximum of eight threads (Tn=8), each of which requiresthree connections toperform some task (Cm=3).The pool size required toensure that deadlock is never possible is:
pool size =8 x (3-1)+1=17
👉 This is not necessarily the optimal pool size, but the minimum required toavoid deadlock.
👉 In some environments, using a JTA(JavaTransactionManager) can dramatically reduce the number of connections required by returning the same Connection from getConnection()toa thread that is already holding a Connection in the current transaction.
这个就不翻译了,大家应该能看懂,其实不需要很大的链接数
4、HikariCP配置
<bean id="dataSource"class="com.zaxxer.hikari.HikariDataSource" destroy-method="close"><constructor-arg ref="hikariConfig"/></bean>
HikariCP配置数据库信息
<bean class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"><property name="locations"><list><value>classpath:hibernate.properties</value></list></property></bean>
配套软件版本:
Obs.: the versions are
log4j: 1.2.16
springframework: 3.1.4.RELEASE
HikariCP: 1.4.0
5、数据库配置文件
Properties file (hibernate.properties):
hibernate.dataSourceClassName=oracle.jdbc.pool.OracleDataSource
hibernate.hikari.maximumPoolSize=10
hibernate.hikari.idleTimeout=30000
dataSource.url=jdbc:oracle:thin:@localhost:1521:xe
dataSource.username=admin
dataSource.password=
参照:https://stackoverflow.com/questions/23172643/how-to-set-up-datasource-with-spring-for-hikaricp
本文转载自: https://blog.csdn.net/superdangbo/article/details/128087951
版权归原作者 Python&Basketball 所有, 如有侵权,请联系我们删除。
版权归原作者 Python&Basketball 所有, 如有侵权,请联系我们删除。