
doris介绍
Doris是一个MPP的OLAP系统,以较低的成本提供在大数据集上的高性能分析和报表查询功能。
MPP (Massively Parallel Processing),即大规模并行处理。简单来说,MPP是将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到终的结果(与Hadoop相似)。
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。基于此,Apache Doris 能够较好的满足报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等使用场景,用户可以在此之上构建用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
doris 使用场景
如下图所示,数据源经过各种数据集成和加工处理后,通常会入库到实时数仓 Doris 和离线湖仓(Hive, Iceberg, Hudi 中),Apache Doris 被广泛应用在以下场景中。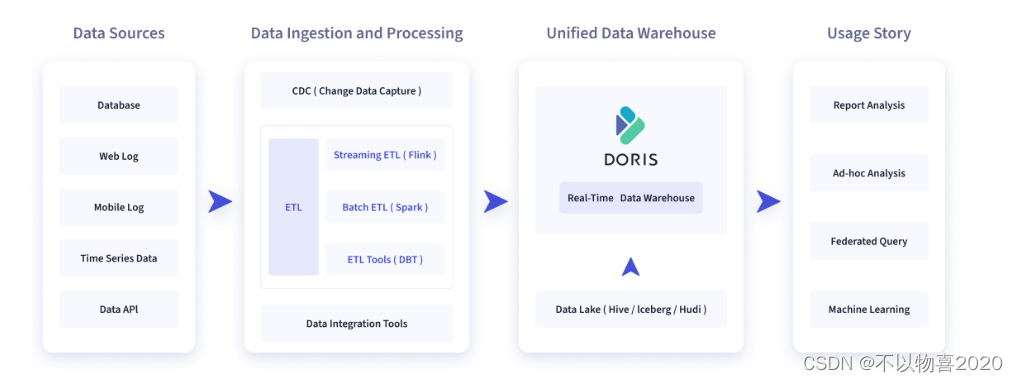
- 报表分析 ① 实时看板 (Dashboards) ② 面向企业内部分析师和管理者的报表 ③ 面向用户或者客户的高并发报表分析(Customer Facing Analytics)。比如面向网站主的站点分析、面向广告主的广告报表,并发通常要求成千上万的 QPS,查询延时要求毫秒级响应。著名的电商公司京东在广告报表中使用 Apache Doris ,每天写入 100 亿行数据,查询并发 QPS上万,99 分位的查询延时 150ms。
- 即席查询(Ad-hoc Query) 面向分析师的自助分析,查询模式不固定,要求较高的吞吐。小米公司基于 Doris 构建了增长分析平台(Growing Analytics,GA),利用用户行为数据对业务进行增长分析,平均查询延时 10s,95 分位的查询延时 30s 以内,每天的 SQL 查询量为数万条。
- 统一数仓构建 一个平台满足统一的数据仓库建设需求,简化繁琐的大数据软件栈。海底捞基于 Doris 构建的统一数仓,替换了原来由 Spark、Hive、Kudu、Hbase、Phoenix 组成的旧架构,架构大大简化。
- 数据湖联邦查询 通过外表的方式联邦分析位于Hive、Iceberg、Hudi 中的数据,在避免数据拷贝的前提下,查询性能大幅提升。
doris架构
Doris整体架构如下图所示,Doris 架构非常简单,只有两类进程
Frontend(FE),主要负责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。
Backend(BE),主要负责数据存储、查询计划的执行。
这两类进程都是可以横向扩展的,单集群可以支持到数百台机器,数十 PB 的存储容量。并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大的降低了一款分布式系统的运维成本。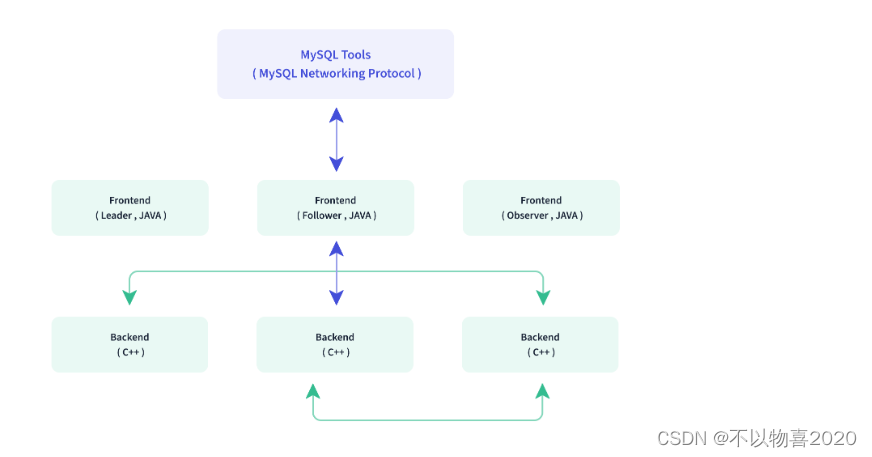
1 整体部署架构
节点角色192.x.x.31FE192.x.x.32BE192.x.x.33BE192.x.x.34BE192.x.x.35BE
2 前期准备
1)Doris 运行在 Linux 环境中,推荐 CentOS 7.x 或者 Ubuntu 16.04 以上版本
2)JDK最低版本要求是8
3)GCC版本4.8.2+
GCC版本可以通过如下命令查看:
gcc -v

4)设置最大打开文件句柄数 – 集群所有节点均需操作
vi /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
5) 时钟同步
Doris 的元数据要求时间精度要小于5000ms,所以所有集群所有机器要进行时钟同步,避免因为时钟问题引发的元数据不一致导致服务出现异常
6)关闭交换分区(swap)-- 集群所有节点均需操作
Linux交换分区会给Doris带来很严重的性能问题,需要在安装之前禁用交换分区
① 执行如下命令
swapoff /mnt/swap
② 删除 /mnt/swap swap swap defaults 0 0 这一行或者注释掉这一行
vim /etc/fstab
③ 确认swap是否关闭
free-mh
如果swap行值都为0,则表示关闭成功
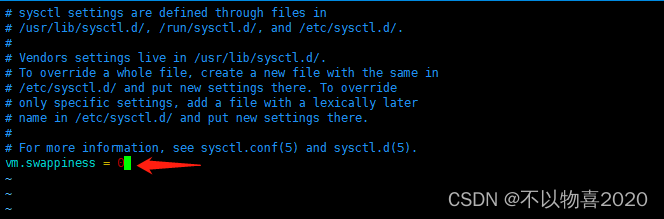
调整 swappiness 参数
# 临时生效echo0> /proc/sys/vm/swappiness
# 永久生效vim /etc/sysctl.conf
# 修改 vm.swappiness 的修改为 0vm.swappiness=0# 使配置生效sysctl-p
7) Liunx文件系统
doris推荐使用ext4文件系统,在安装操作系统的时候,请选择ext4文件系统
- 需要安装mysql客户端用与访问和连接doris
- 下载doris版本:
注:这里需要根据当前安装环境是否支持 avx2指令,选择对应的下载版本。查看当前环境是否支持 avx2命令
cat/proc/cpuinfo |grep flags
发现没有avx2则说明不支持该指令
不支持avx2指令时选择的安装包应选择带有noavx2字段的安装包,如: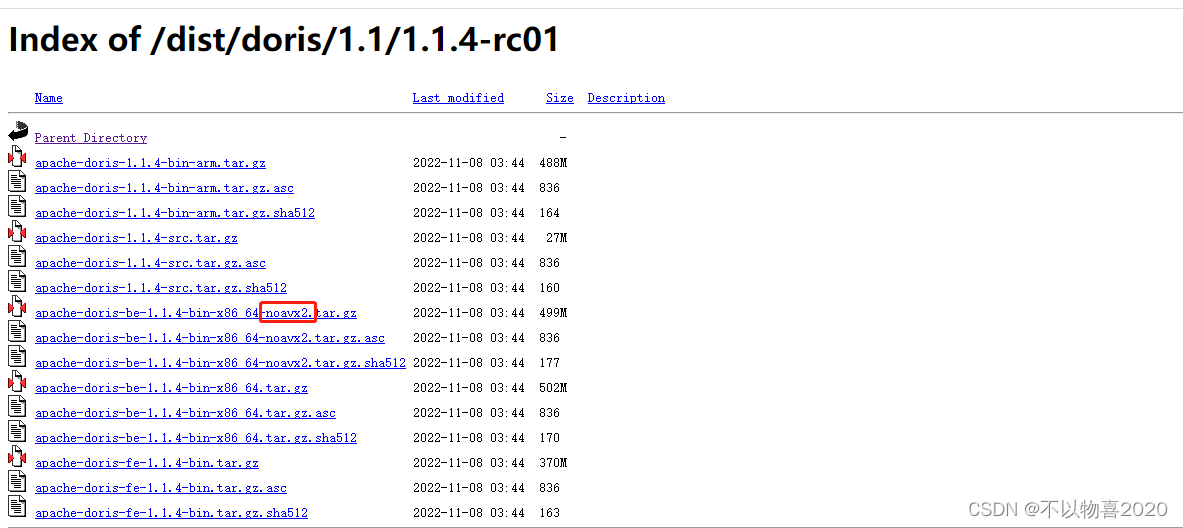
这里的x86和arm指的是CPU的架构,根据服务器的情况选择,大多数情况下是x86的架构。
3 安装部署注意事项
3.1 FE
① FE 的磁盘空间主要用于存储元数据,包括日志和 image。通常从几百 MB 到几个 GB 不等。
② BE> 的磁盘空间主要用于存放用户数据,总磁盘空间按用户总数据量 * 3(3副本)计算,然后再预留额外 40% 的空间用作后台 compaction> 以及一些中间数据的存放。
③ 一台机器上可以部署多个 BE 实例,但是只能部署一个 FE。如果需要 3 副本数据,那么至少需要 3
台机器各部署一个 BE 实例(而不是1台机器部署3个BE实例)。多个FE所在服务器的时钟必须保持一致(允许最多5秒的时钟偏差)
④ 测试环境也可以仅适用一个 BE 进行测试。实际生产环境,BE 实例数量直接决定了整体查询延迟。 所有部署节点关闭 Swap。
3.2 FE节点数量
① FE 角色分为 Follower 和 Observer,(Leader 为 Follower 组中选举出来的一种角色,以下统称 Follower)。
② FE 节点数据至少为1(1 个 Follower)。当部署 1 个 Follower 和 1 个 Observer 时,可以实现读高可用。当部署 3 个 Follower 时,可以实现读写高可用(HA)。
③ Follower 的数量必须为奇数,Observer 数量随意。
根据以往经验,当集群可用性要求很高时(比如提供在线业务),可以部署 3 个 Follower 和 1-3 个 Observer。如果是离线业务,建议部署 1 个 Follower 和 1-3 个 Observer。
3.3 Broker 部署
Broker 是用于访问外部数据源(如 hdfs)的进程。通常,在每台机器上部署一个 broker 实例即可
3.4 网络要求
Doris 各个实例直接通过网络进行通讯。以下表格展示了所有需要的端口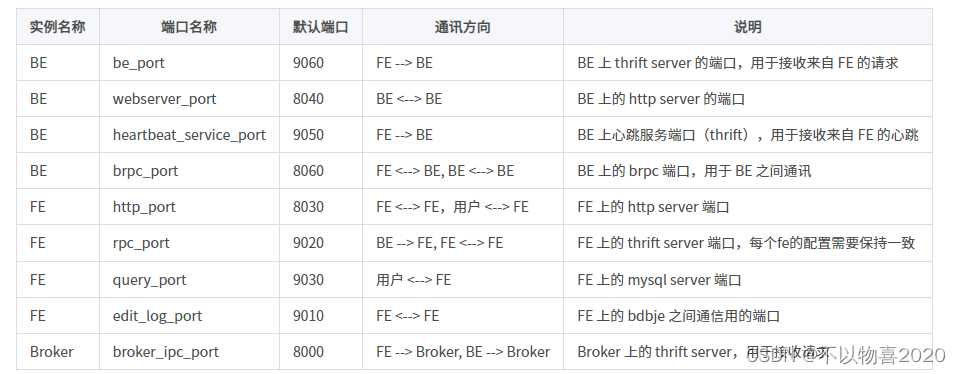
注:
① 当部署多个 FE 实例时,要保证 FE 的 http_port 配置相同。
② 部署前请确保各个端口在应有方向上的访问权限。
4 安装部署Doris
4.1 解压
tar-xvf apache-doris-be-1.2.0-bin-x86_64-noavx2.tar.xz
tar-xvf apache-doris-fe-1.2.0-bin-x86_64.tar.xz
4.2 修改配置文件
cd apache-doris-x.x.x/fe
修改 FE 配置文件 conf/fe.conf ,这里我们主要修改两个参数:priority_networks 及 meta_dir
4.2.1 添加priority_networks 参数
priority_networks=172.23.16.0/24
注意:
这个参数我们在安装的时候是必须要配置的,特别是当一台机器拥有多个IP地址的时候,我们要为 FE 指定唯一的IP地址。
这里假设你的节点 IP 是 172.23.16.32,那么我们可以通过掩码的方式配置为 172.23.16.0/24。
4.3 启动FE
bin/start_fe.sh --daemon
查看日志,可看到如下内容,说明FE已经启动成功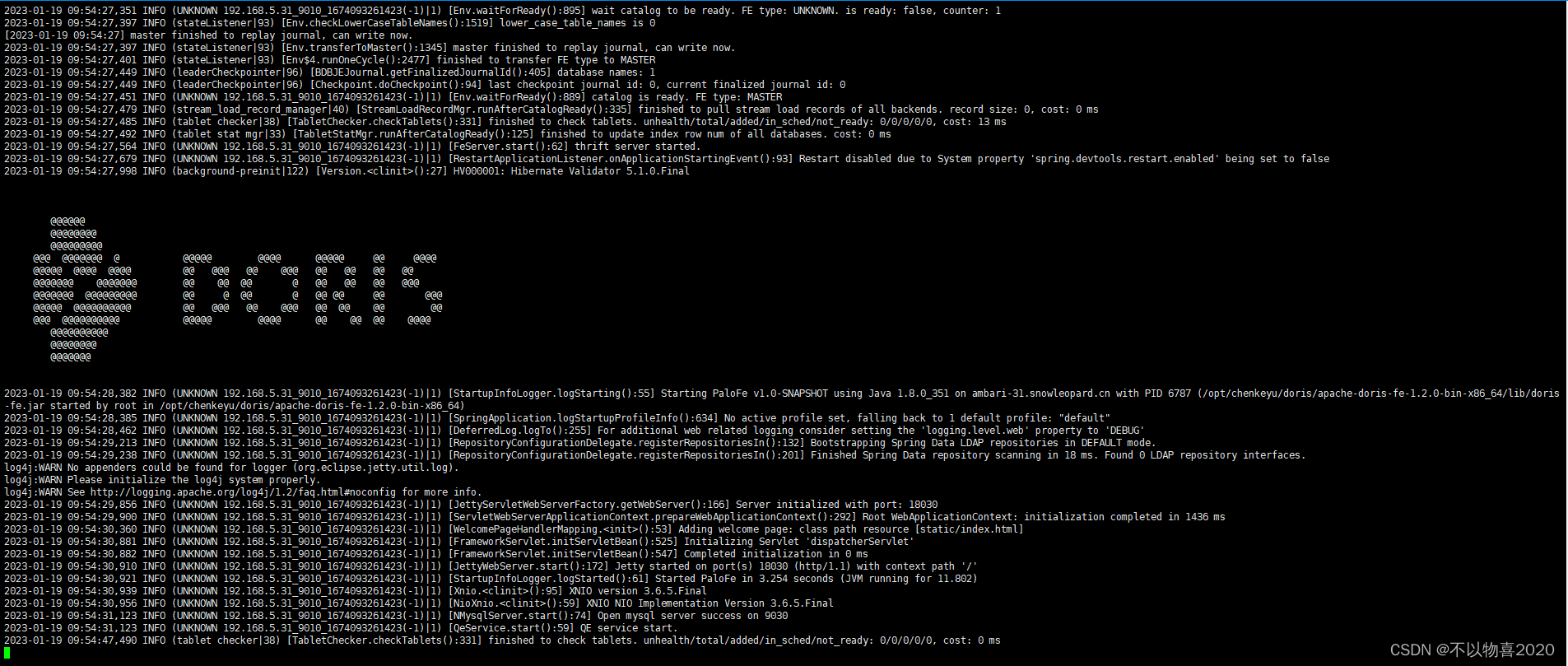
4.4 设置BE
需要安装BE的节点,将BE的安装包拷贝到节点上
4.4.1 修改BE配置文件
修改 be/conf/be.conf。主要是配置 storage_root_path:数据存放目录。默认在be/storage下,需要手动创建该目录。多个路径之间使用英文状态的分号 ; 分隔(最后一个目录后不要加 ‘;’)
4.5 FE节点启动mysql客户端
附加:mysql客户端安装方式
首先,获取rpm包:
wget https://cdn.mysql.com/archives/mysql-8.0/mysql-community-common-8.0.25-1.el7.x86_64.rpm
wget https://cdn.mysql.com/archives/mysql-8.0/mysql-community-client-plugins-8.0.25-1.el7.x86_64.rpm
wget https://cdn.mysql.com/archives/mysql-8.0/mysql-community-libs-8.0.25-1.el7.x86_64.rpm
wget https://cdn.mysql.com/archives/mysql-8.0/mysql-community-client-8.0.25-1.el7.x86_64.rpm
依次安装即可:
rpm -ivh mysql-community-common-8.0.25-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-plugins-8.0.25-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-8.0.25-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-8.0.25-1.el7.x86_64.rpm
mysql -h fe_host -P query_port -uroot
fe_host为FE节点
query_port为在FE节点conf/fe.conf中设置的端口号
mysql -h192.x.x.31 -P9030-uroot
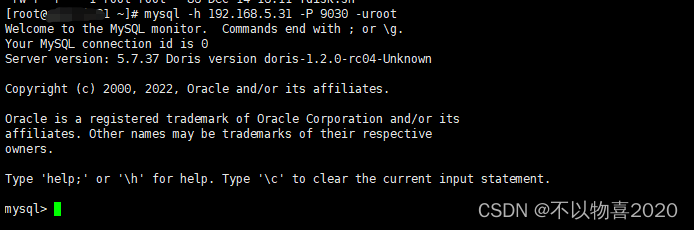
登录后,执行以下命令来添加每一个 BE:
ALTER SYSTEM ADD BACKEND "be_host:heartbeat-service_port";
其中 be_host 为 BE 所在节点 ip;heartbeat_service_port 在 be/conf/be.conf 中。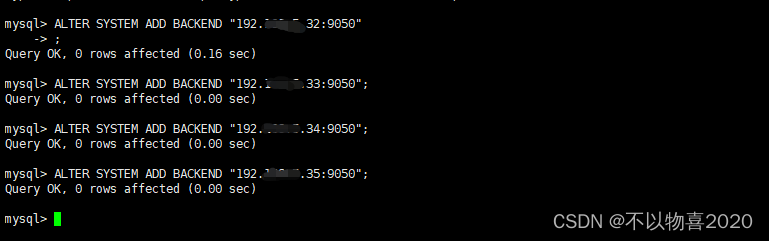
4.6 在BE节点启动BE
bin/start_be.sh --daemon
启动报错如下
在每个BE节点执行
sysctl-wvm.max_map_count=2000000
再次启动报错如下:
原因:安装Java UDF 函数因为从 1.2 版本开始支持 Java UDF 函数,需要从官网下载 Java UDF 函数的 JAR 包放到 BE 的 lib 目录下,否则可能会启动失败。在官网下载依赖的jar包。下载完成后拷贝到BE的lib目录下即可
注意:如果不是安装doris-1.2.0以后的版本可以不用下载该jar包
再次启动BE,看到如下内容,说明启动正常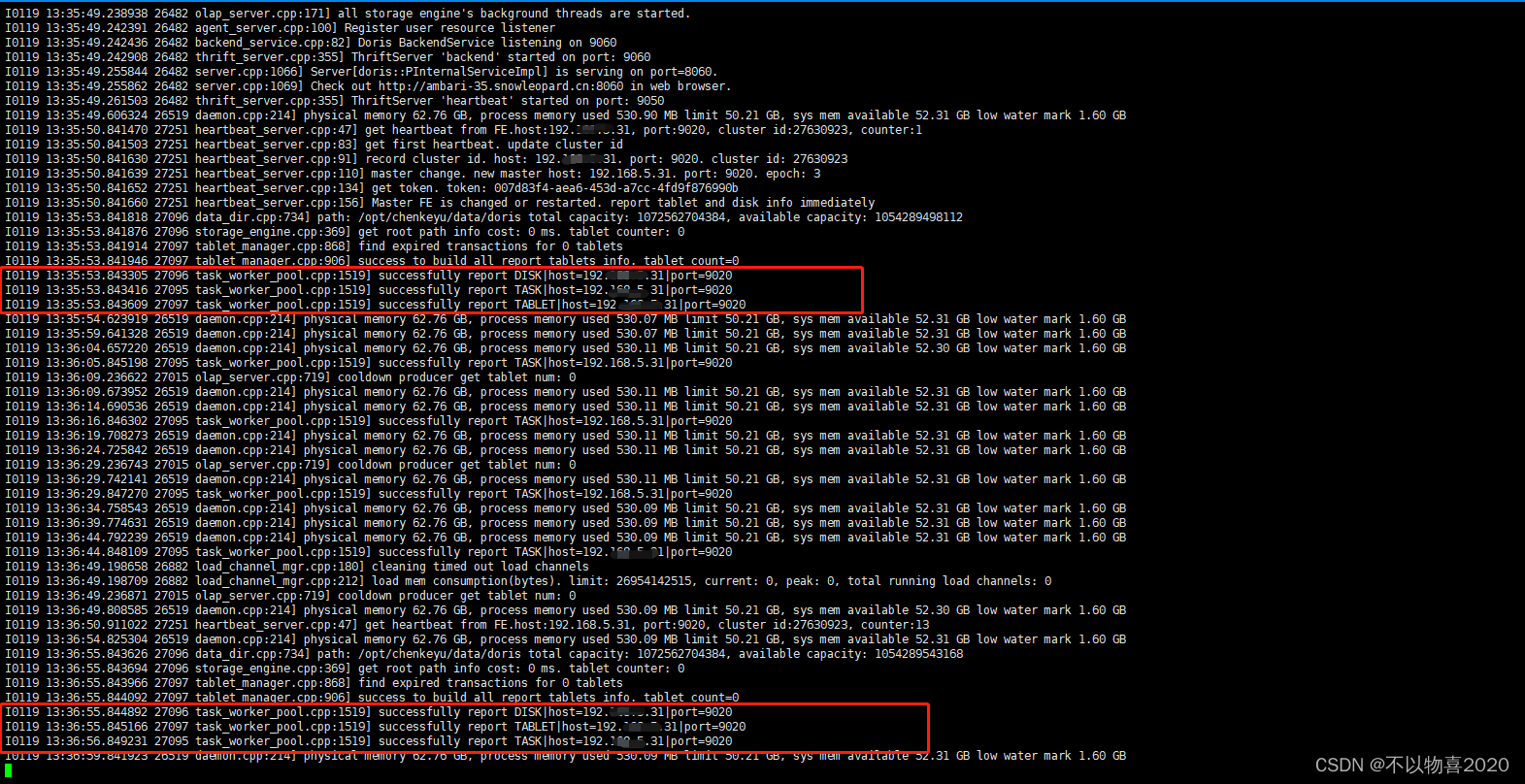
注意:如果 be 部署在 hadoop 集群中,注意调整 be.conf 中的 webserver_port = 8040 (hadoop集群中,nodemanager进程默认使用的是8040端口号),以免造成端口冲突。否则会报如下错误: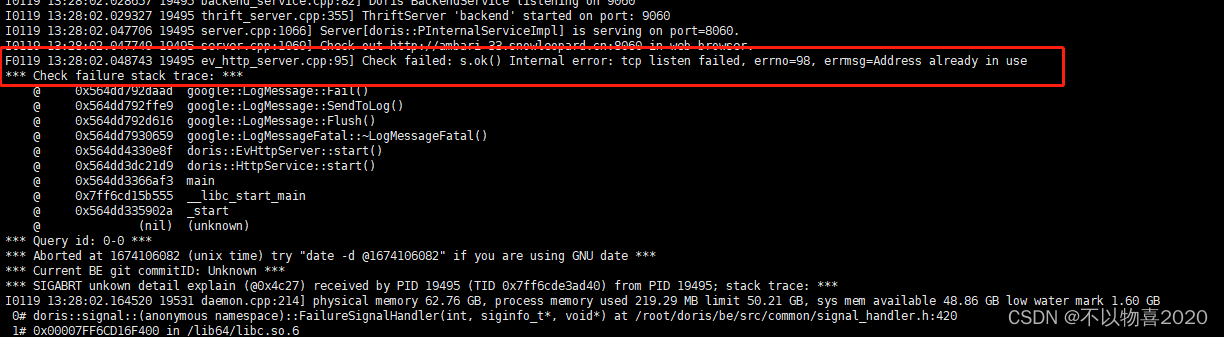
4.7 查看BE状态
方式一:使用 mysql-client 连接到 FE,并执行
SHOWPROC'/backends';
查看 BE 运行情况。如一切正常,isAlive 列应为 true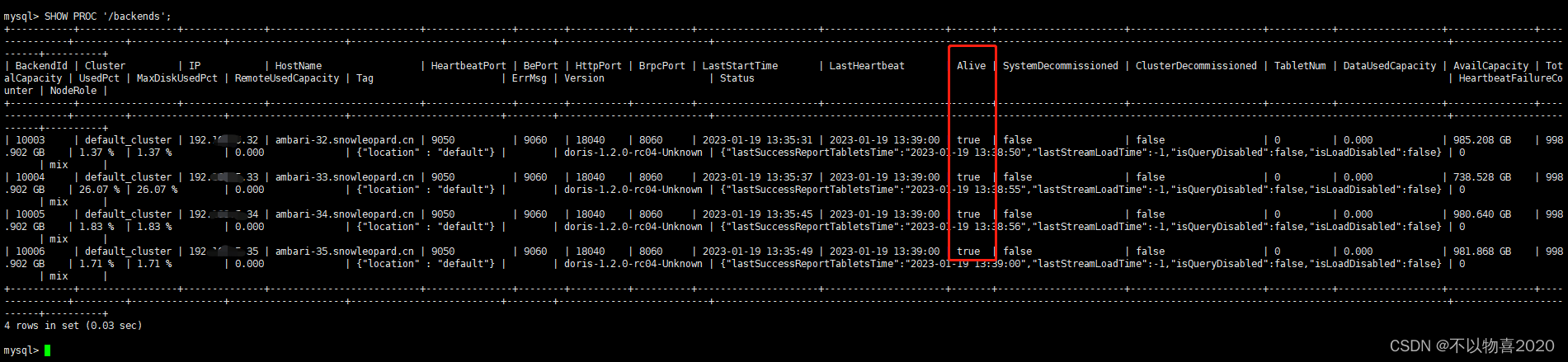
方式二:访问url
http://be_host:be_http_port/api/health
be_host FE节点ip
be_http_port FE安装节点conf/fe.conf中配置的端口
返回如下页面说明FE状态正常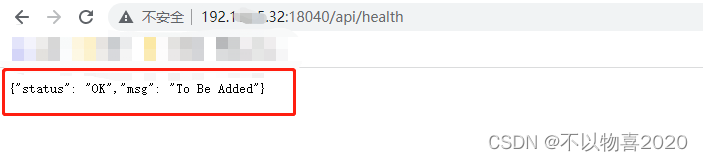
4.8 查看FE状态是否正常
方法一:访问url
http://fe_host:fe_http_port/api/bootstrap
fe_host FE节点ip
fe_http_port FE安装节点conf/fe.conf中配置的端口
返回如下页面说明FE状态正常
方式二:查看FE端日志
最终会看到 thrift server started 日志,并且可以通过 mysql 客户端连接到 FE,则表示 FE 启动成功。
4.9 mysql客户端检查
4.9.1 检查FE
show frontends\G;
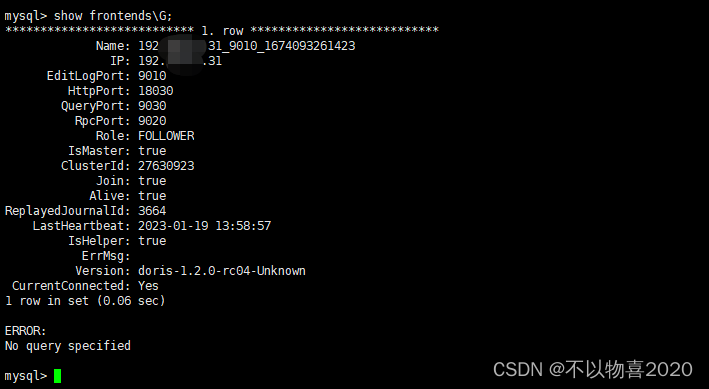
4.9.2 检查BE
SHOW BACKENDS\G;
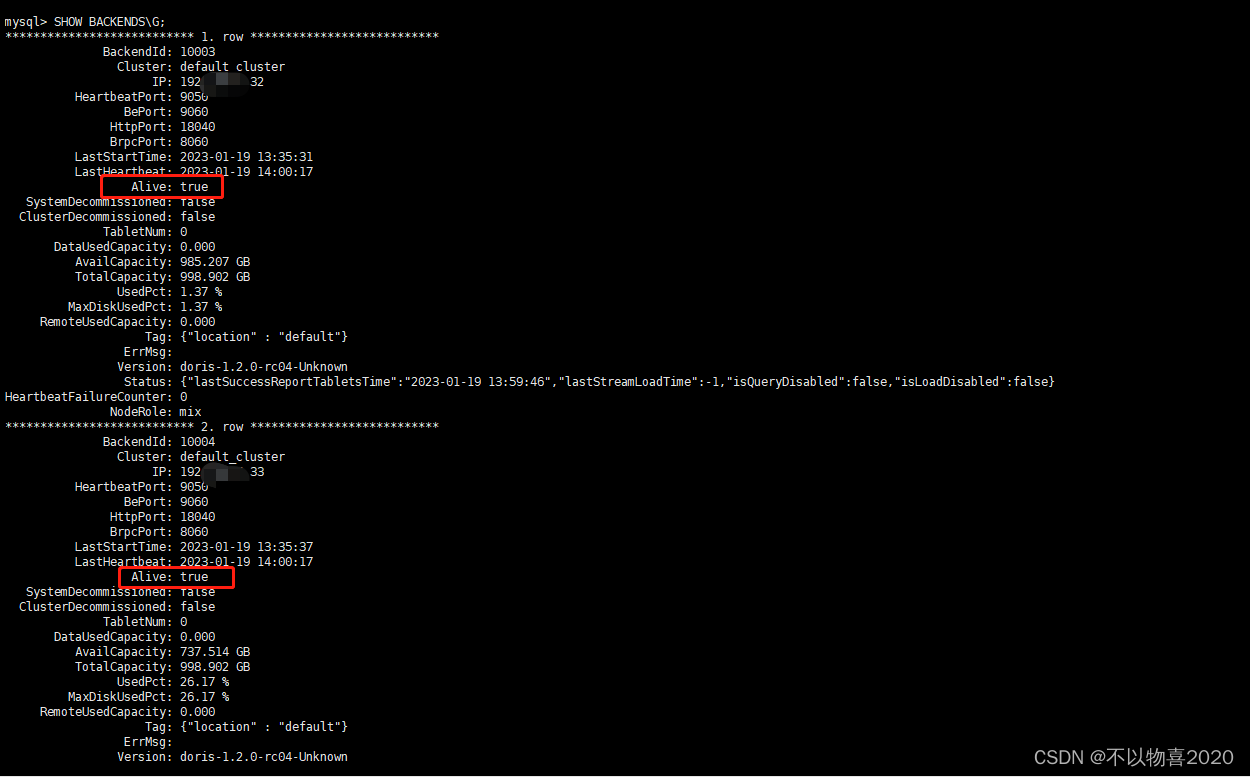
4.10 WEBUI
直接在浏览器输入
http://fe_host:fe_http_port
用户名默认为root,没有密码,点击登录,可以看到如下页面
5 doris使用示例
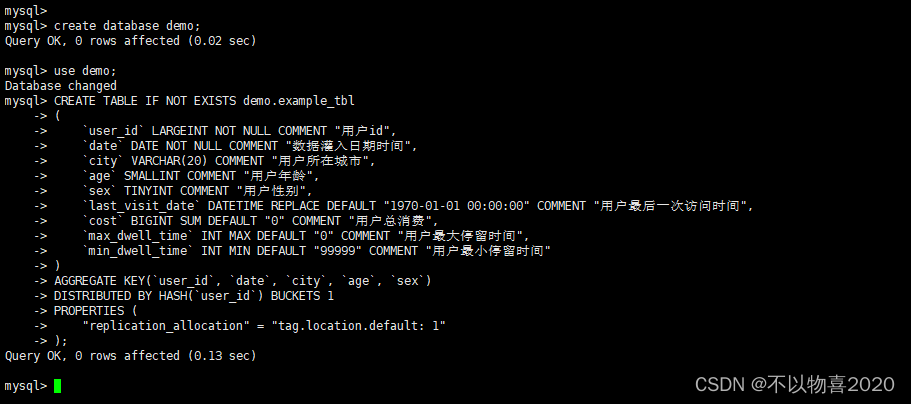
5.1 创建一个数据库
createdatabase demo;
5.2 创建数据库表
use demo;CREATETABLEIFNOTEXISTS demo.example_tbl
(`user_id` LARGEINT NOTNULLCOMMENT"用户id",`date`DATENOTNULLCOMMENT"数据灌入日期时间",`city`VARCHAR(20)COMMENT"用户所在城市",`age`SMALLINTCOMMENT"用户年龄",`sex`TINYINTCOMMENT"用户性别",`last_visit_date`DATETIMEREPLACEDEFAULT"1970-01-01 00:00:00"COMMENT"用户最后一次访问时间",`cost`BIGINT SUM DEFAULT"0"COMMENT"用户总消费",`max_dwell_time`INT MAX DEFAULT"0"COMMENT"用户最大停留时间",`min_dwell_time`INT MIN DEFAULT"99999"COMMENT"用户最小停留时间")
AGGREGATE KEY(`user_id`,`date`,`city`,`age`,`sex`)DISTRIBUTEDBYHASH(`user_id`) BUCKETS 1
PROPERTIES ("replication_allocation"="tag.location.default: 1");
5.3 示例数据
10000,2017-10-01,北京,20,0,2017-10-0106:00:00,20,10,1010000,2017-10-01,北京,20,0,2017-10-0107:00:00,15,2,210001,2017-10-01,北京,30,1,2017-10-0117:05:45,2,22,2210002,2017-10-02,上海,20,1,2017-10-0212:59:12,200,5,510003,2017-10-02,广州,32,0,2017-10-0211:20:00,30,11,1110004,2017-10-01,深圳,35,0,2017-10-0110:00:15,100,3,310004,2017-10-03,深圳,35,0,2017-10-0310:20:22,11,6,6
将上面的数据保存在test.csv文件中。
5.4 导入数据
这里我们通过Stream load 方式将上面保存到文件中的数据导入到我们刚才创建的表里。
curl --location-trusted -u root: -T test.csv -H"column_separator:," http://127.0.0.1:8030/api/demo/example_tbl/_stream_load
-T test.csv : 这里使我们刚才保存的数据文件,如果路径不一样,请指定完整路径
-u root : 这里是用户名密码,我们使用默认用户root,密码是空
127.0.0.1:8030 : 分别是 fe 的 ip 和 http_port
执行成功之后我们可以看到下面的返回信息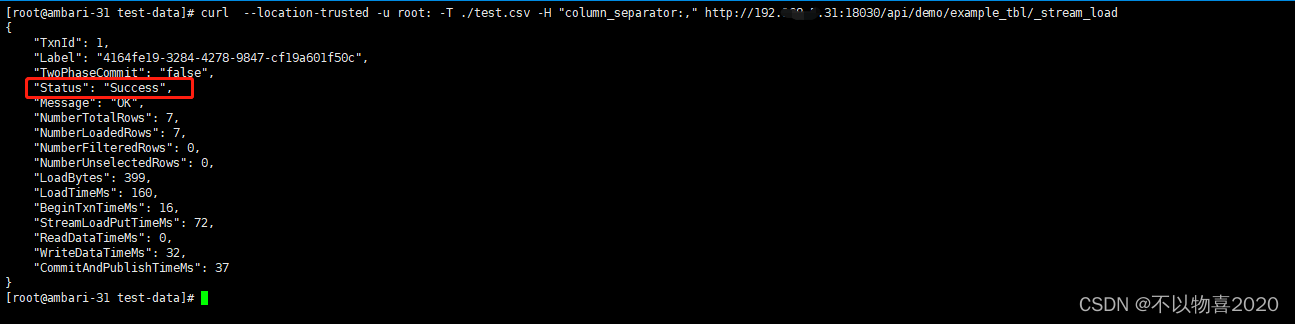
NumberLoadedRows: 表示已经导入的数据记录数
NumberTotalRows: 表示要导入的总数据量 Status
Success 表示导入成功
到这里我们已经完成的数据导入,下面就可以根据我们自己的需求对数据进行查询分析了
5.5 查询数据
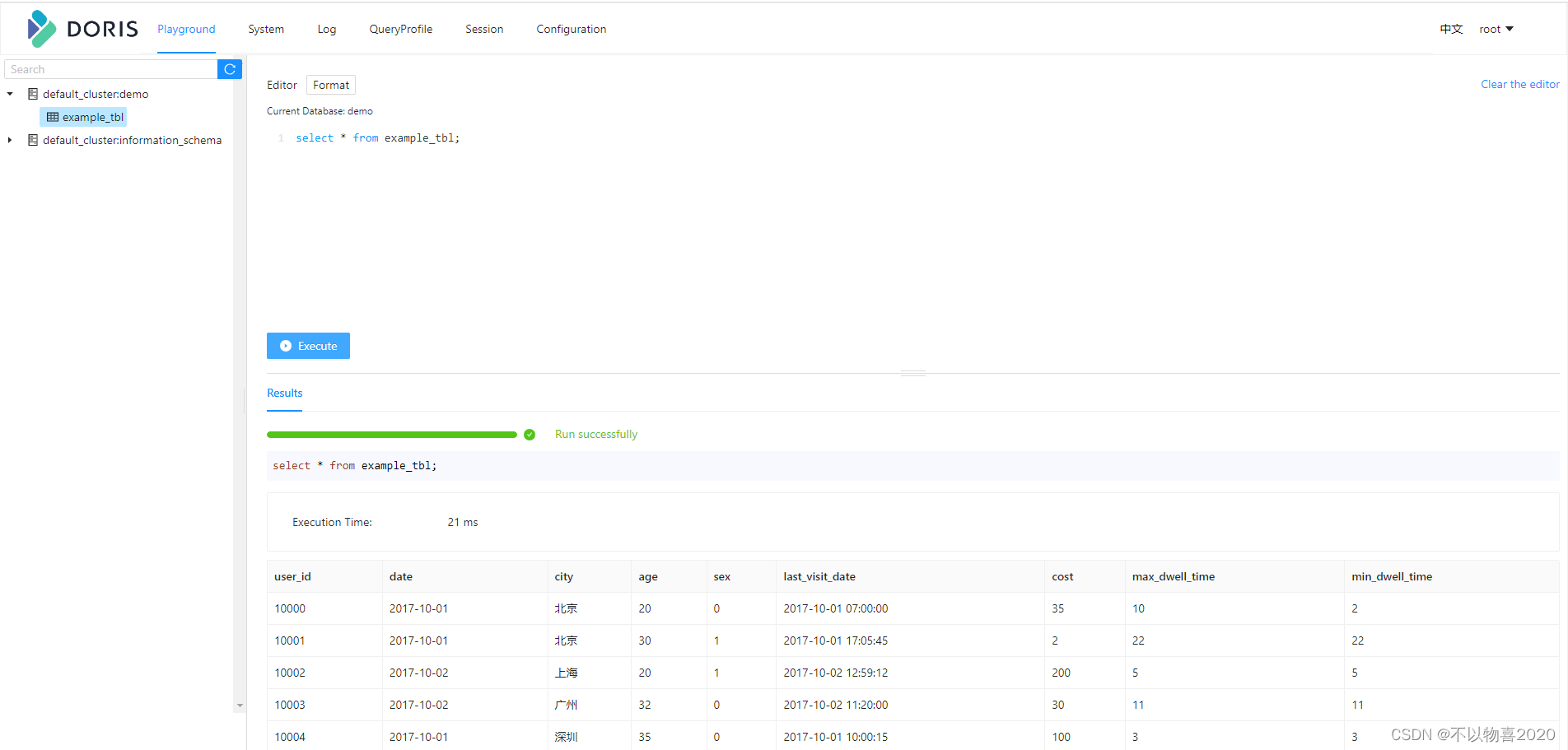
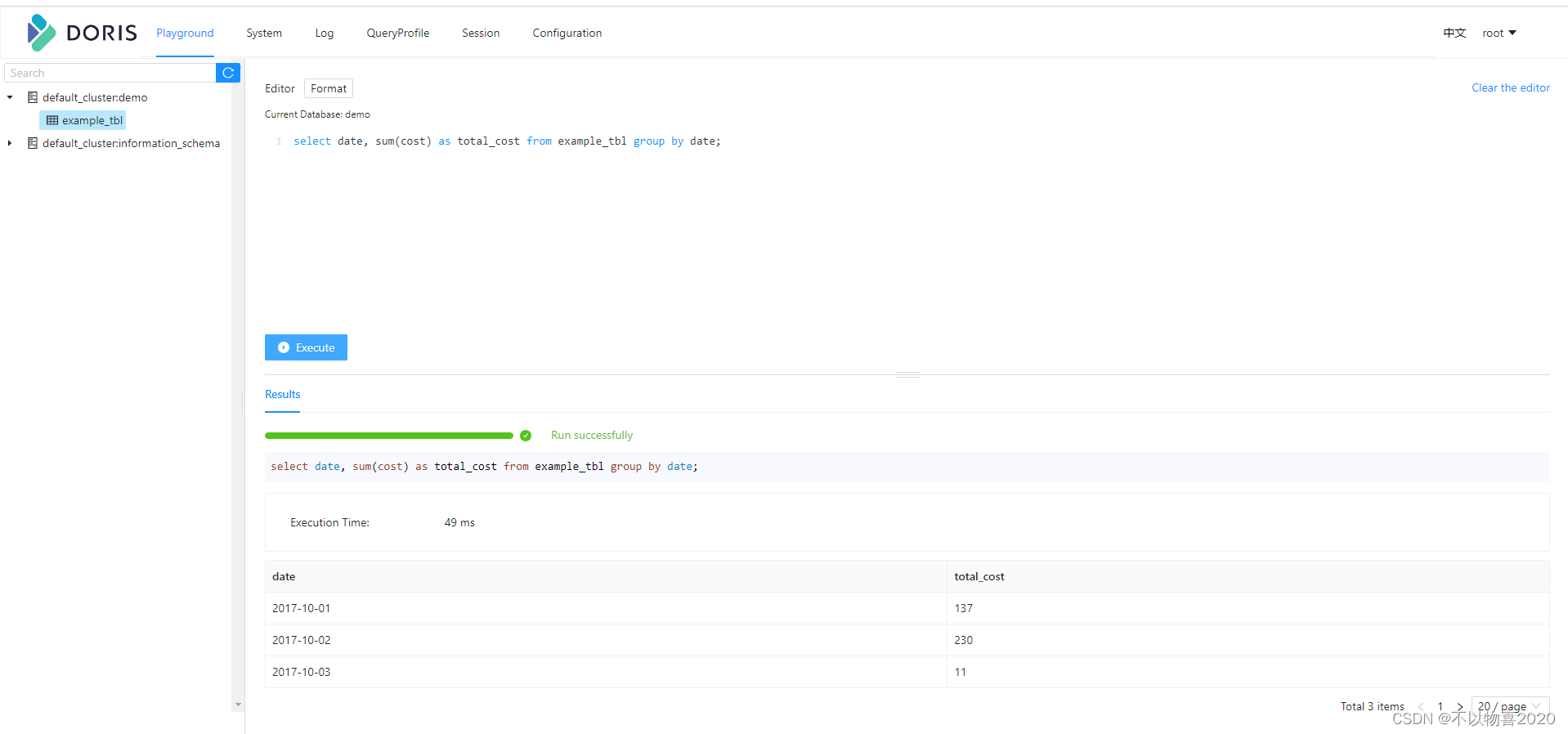
进入doris页面,执行sql
select*from example_tbl;
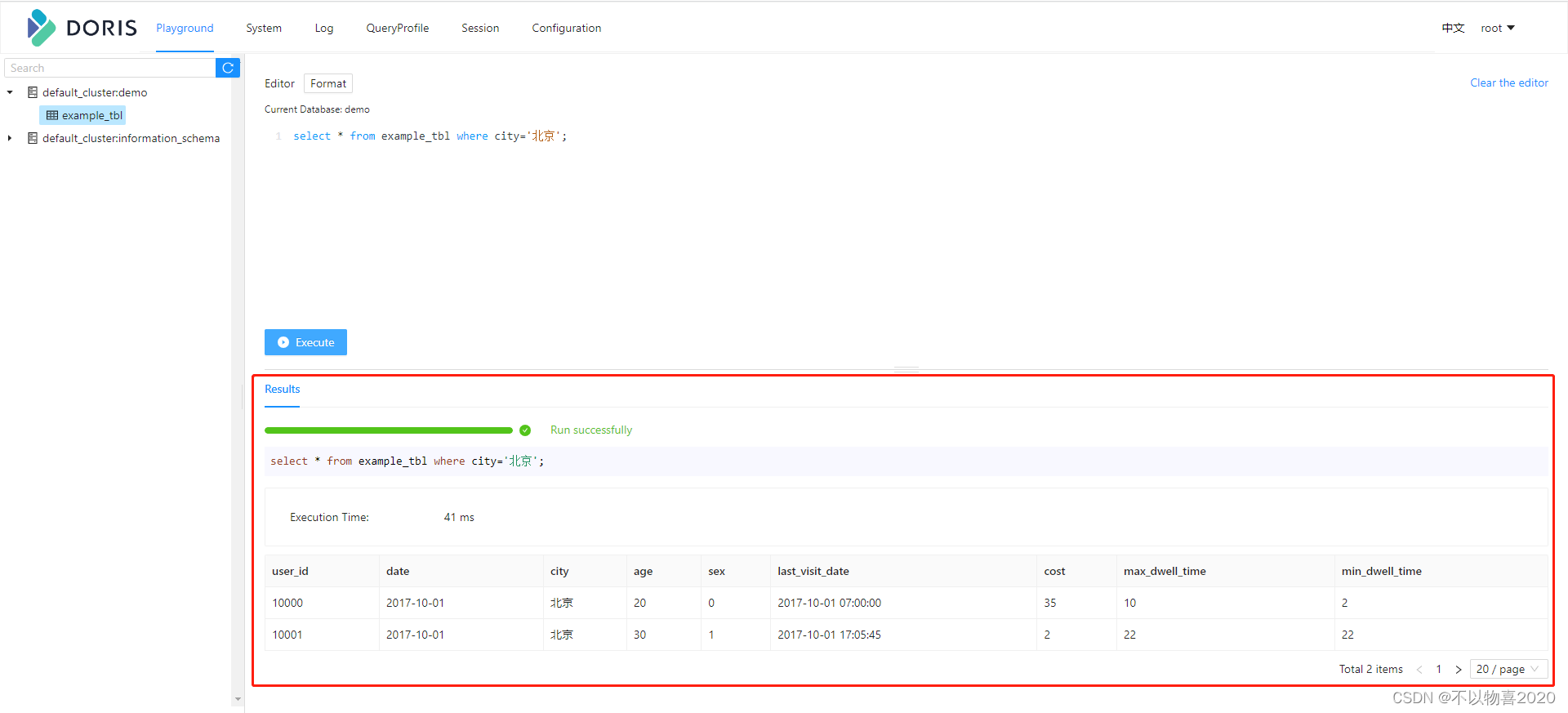
select*from example_tbl where city='北京';
selectdate,sum(cost)as total_cost from example_tbl groupbydate;
版权归原作者 不以物喜2020 所有, 如有侵权,请联系我们删除。