
TCP/IP协议
应用层
最重要的一层,需要自己去实现。就是:设计并实现一个应用层协议。最知名的应用层协议:HTTP
前端和后端之间就是通过网络来进行交互的,交互的过程中,就需要约定好:前端发啥样的数据,后端回对应的数据。设计一个应用层协议,主要就是包含两个工作:
- 明确传输的信息。
- 明确传输的格式。
应用层模板
xml
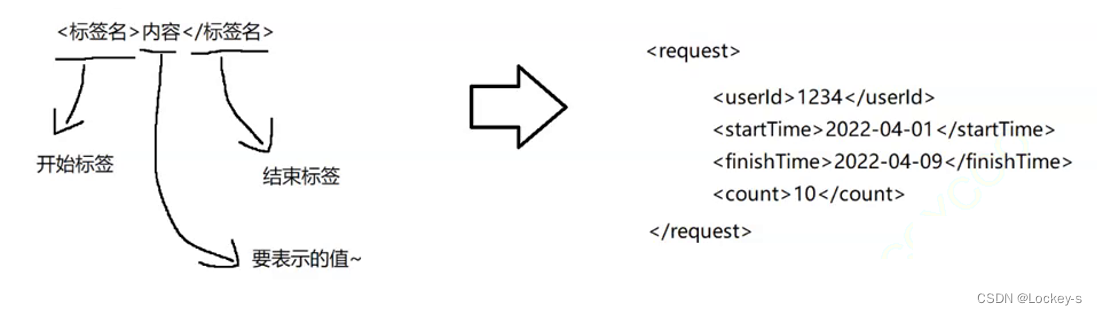
- 可读性好,但是运行效率不高,属于老的数据格式了。虽然也在用,但是用的越来越少了。
- 特点:由标签构成: <标签名>内容</标签名> 标签名就是 key,标签值就是 value 通过标签就更好的提升了可读性。
- 虽然提高了可读性,但是又引入了太多的辅助信息(标签名之类的) 就导致占用了更高的 网络带宽。
- 所以 xml 就很少作为 应用层协议的 模板了,更多的是用来做一些配置文件。
json

- 可读性好,但是运行效率不高。当下最流行的一种设计 应用层协议 的数据格式,通过 大括号 构成了键值对格式。
- 一个 大括号 中有很多键值对,键值对之间使用 逗号 分割,键 和 值 之间使用 冒号 分割。
- 要求 键 必须是字符串类型的 值允许有好多种(数字,字符串,布尔,数组,另一个 json)。
- json 中表示字符串,单引号和双引号都可以,最后一个键值对,后面可以有逗号,也可以没有(标准要求是没有的,但是一般的 json 解释器都不会在意)。
- json 要求 key 一定是字符串,因此 key 这里的引号可以忽略,除非 key 中包含了一些特殊符号(比如像 空格,-,就不能省略了)。

像这里,就出现了很多次 key。
json 和 xml 对比:
- 相比于 xml 来说,json 也能保证可读性,同时又没有那么繁琐(占用的带宽小).
- json 虽然传输效率比 xml 高,但是然然要多传递一些冗余信息,就是 key 的名字,尤其是数组的时候,更明显。当表示数组的时候,就会有很多 key 重复出现,也就占用了带宽。出问题的请求和响应,一目了然。
protobuffer
- 运行效率高,但是可读性不高。
- 是一种 二进制格式 的数据,在 protobuffer 的数据中,不再包含 key 的名字。而是通过顺序以及一些特殊符号,来区分每个字段的含义。同时再通过一个 LDL 文件。来描述这个数据格式(每个部分是啥意思)。
- LDL 只是起到一个辅助开发的作用,并不会真正的进行传输,传输的只是二进制的纯粹的数据。
传输层
虽然是操作系统内核实现,但是仍然有很大意义,进行网络编程都要用到 socket ,一旦调用了 socket,代码就进入传输层的范畴。如果代码出现 bug,就需要传输层的知识了。
端口号:0-65535 之间的整数。常见的端口号:80 http 服务器,443 服务器,22 ssh,23 ftp。
传输层常见的协议:UDP/TCP
UDP
UDP 的数据报文格式:由 UDP 报头,和UDP 数据载荷(完整的应用层数据)。把应用层数据报分装成 UDP 数据报,本质上就是在应用层数据包的基础上,添加了 8 个字节的报头。
- 目的端口就是服务器端口,源端口就是操作系统给客户端自动分配的端口。端口号会被打包到 UDP 数据报中。
- 报文长度是 2 个字节,0-64k 在现代互联网当中,就可能不够用了。数据大的话,就会进行拆包,然后分为多个发送,接收方再重新拼接起来,但是可能回出现丢包和乱序,所以就改成 TCP 来解决,因为 TCP 没有大小限制。
- 校验和就是用来验证网络传输的这个数据是否正确。因为网络传递的本质就是:光信号和电信号,但是外界的磁场之类的会影响到结果。可能就会导致 0 变成 1,就导致数据出错了,所以校验和就能帮助我们发现数据中的错误。还可以使用数据内容参与运算,如果是基于数据内容得到的校验和,那么数据出错的话,被识别出来的概率还是很高的。这里的 校验和 与 以太网 的校验和一样。
TCP
TCP 的报文格式: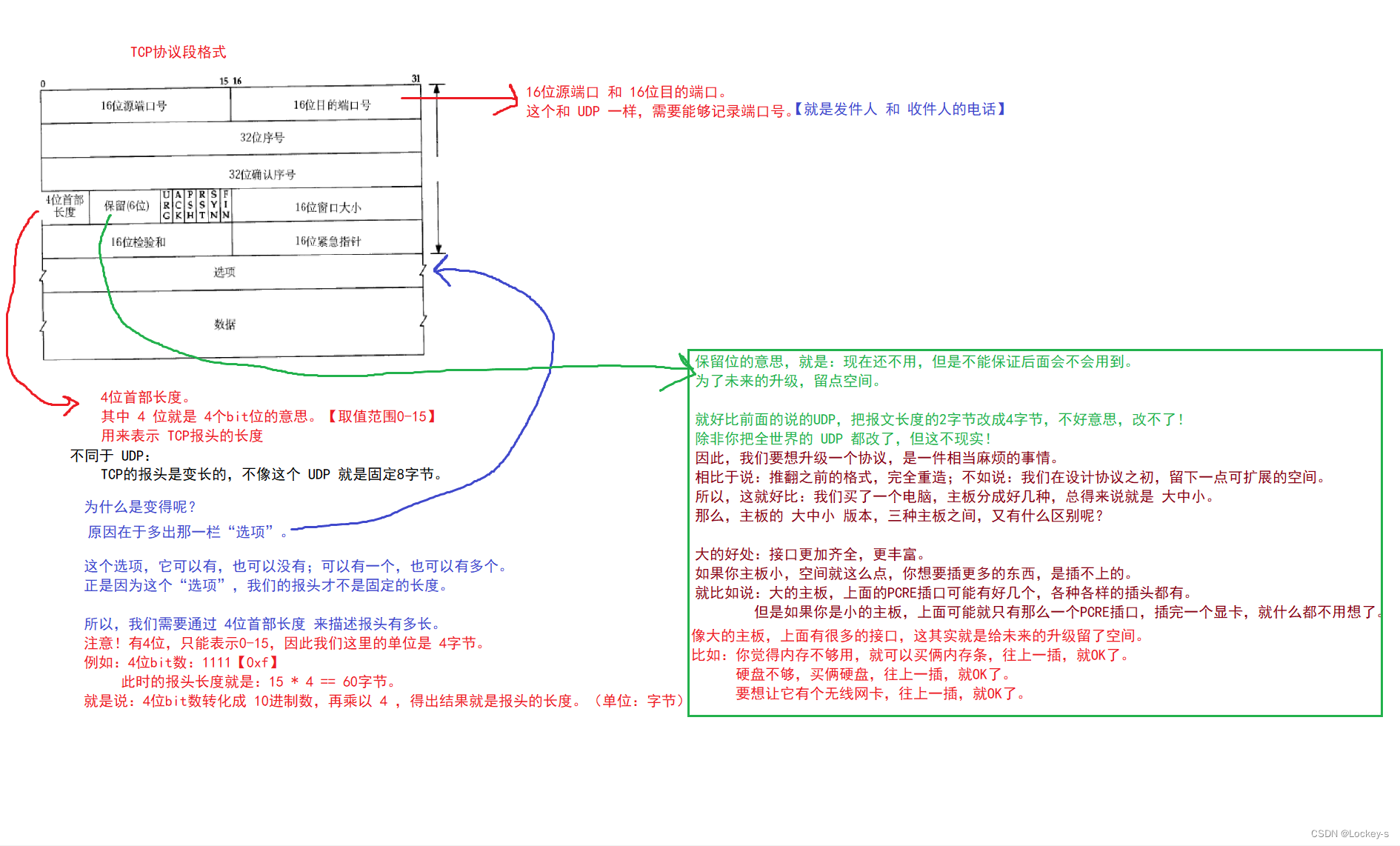
TCP 是一个非常非常重要的协议,在实际开发中广泛使用。特点:有连接,可靠传输,面向字节流,全双工。
可靠传输
可靠传输是 TCP 的核心机制。引入 TCP 的关键原因,就是为了保证可靠传输。在小的时候,通过手机给其他人发短信,可能对方收到短信的顺序和我们发送的顺序不一样。也可能我们收到回复的顺序和对方发送的不一样。就像下面这样: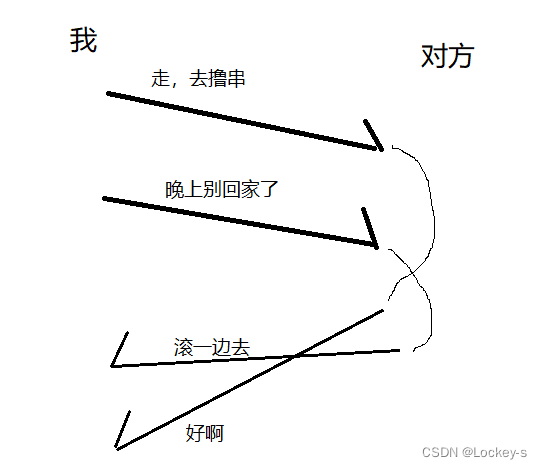
我们收到消息的时候,就可以先收到不回家的回复,然后在收到撸串的回复。这样的传输就是不可靠的。
实现可靠传输的核心:
- 确认应答
- 超时重传
确认应答
- 确认应答就是发出去之后,对方收到了。但是消息可能会乱序。
- 避免出现乱序,就可以根据编号机制来解决,根据编号就可以知道消息是第几条了。
- 就是根据编号来确定当前的 应答报文 就是针对哪个消息进行的确认应答。
就像这样: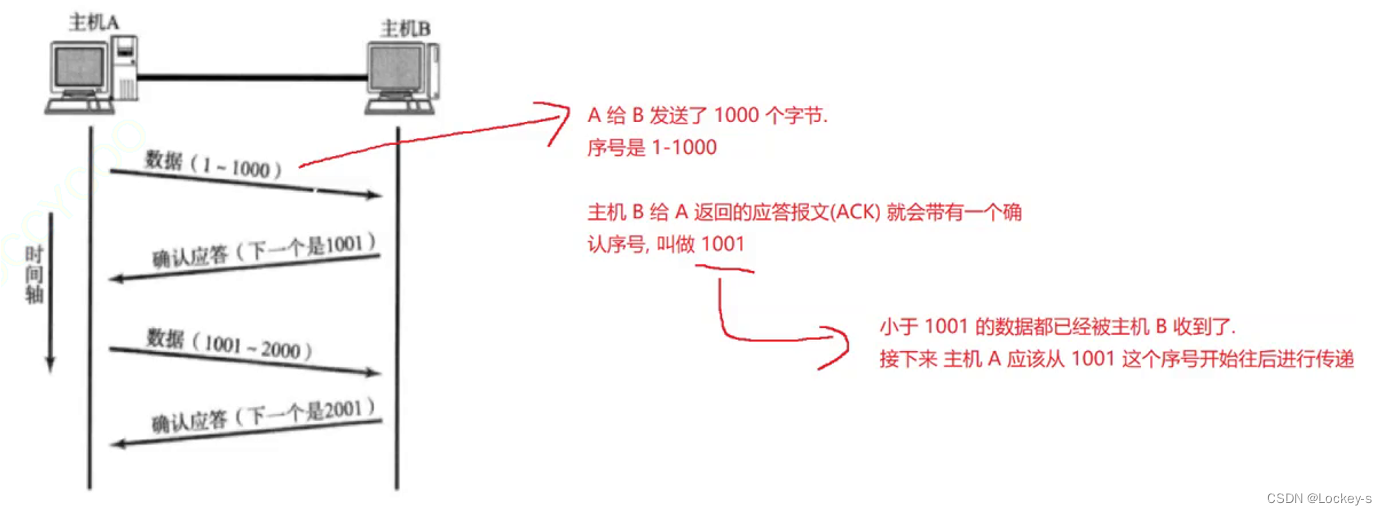
这样就可以确定是针对哪条报文来回答了。
超时重传
超时重传相当于对确认应答进行了补充,确认应答是网络一切正常的时候,通过 ACK 通知发送方收到了数据。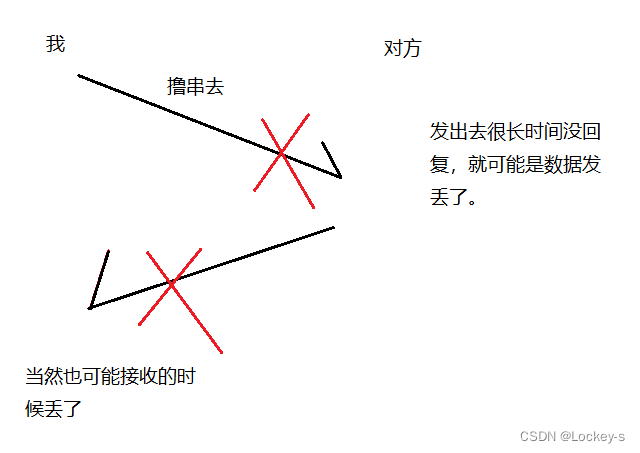
就像上面就出现了丢包的情况,那么就是丢包了。如果出现了丢包的情况,超时重传机制就要起到效果了。如果网络不是有太大问题,一般重传都是可以成功的。
如果是 ACK 丢了,虽然对方收到了消息,但是我收不到 ACK(ACK 丢了),发送方超出了等待时间,就会重新发送一次。那么就会导致接收方收到了重复的消息:
- TCP 内部会有一个去重操作,接收方收到的数据会先放在操作系统的 接收缓冲区 当中的。
- 收到新的数据,TCP 就会去 接收缓冲区 当中检查有没有这个消息,如果有,就丢弃,没有的话,就放到缓冲区。用来保证程序调用 socket API 拿到的这个数据一定是不可重复的。
重传如果失败,还会继续尝试,也不会无休止的重传,连续几次失败的话,就认为是网络遇到了严重的情况,再怎么重传也可能不行,就只能放弃(自动断开与 TCP 的连接)。重传的时间间隔会逐渐变大。
连接管理
连接管理也是 TCP 保证可靠性的一个机制,主要是两部分:
- 如何建立连接。
- 如何断开连接。
如何建立连接
客户端和服务器之间,通过三次交互(三次握手),完成了建立连接的过程。三次握手只是一个形象化的比喻:
- 其实一次握手,就是一次交互的过程。就是客户端 给 服务器 发了一个数据,这就相当于一次握手。
- 服务器再给客户端反馈一个数据,这就是另外一次握手。
- 客户端 根据服务器的反馈,而进行反馈,告诉服务器,它接受到了它的反馈,
一共经历3次,就完成这个三次握手。实际上的流程就构图如下: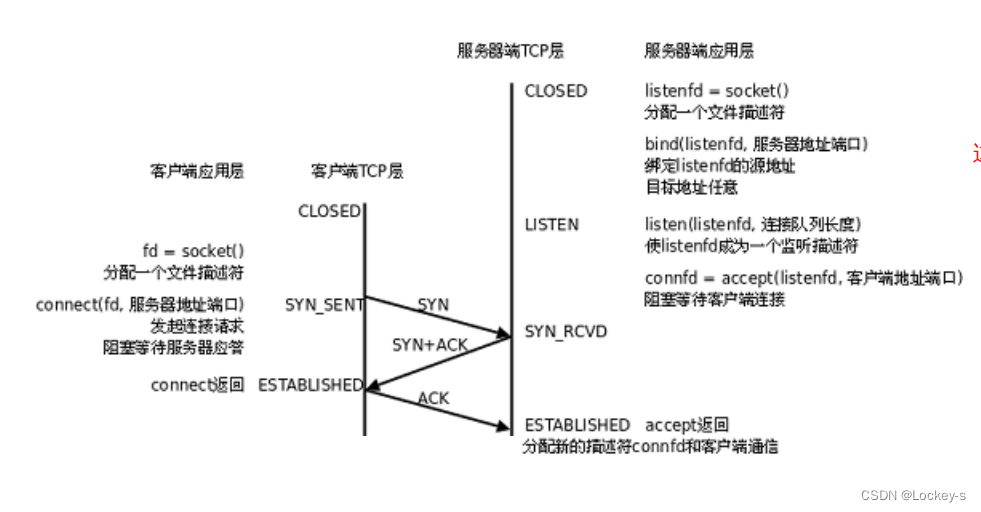
这个图太复杂,而且我们作为程序员,只需了解简化部分就好了: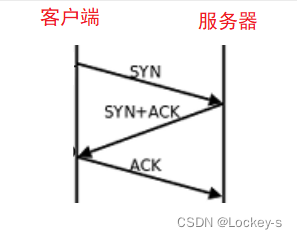
第一次握手的时候客户端给服务器发一个 SYN 同步报文段。意思就是客户端要和服务器建立连接。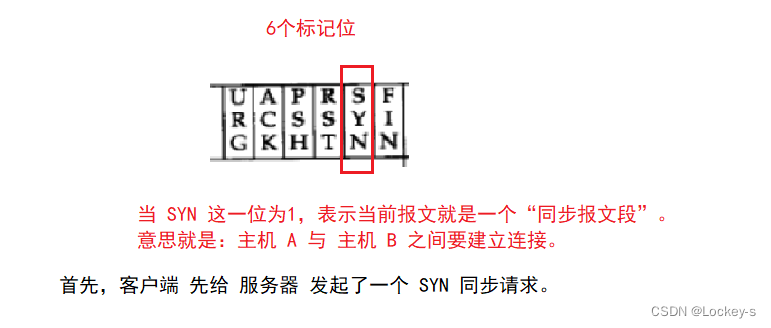
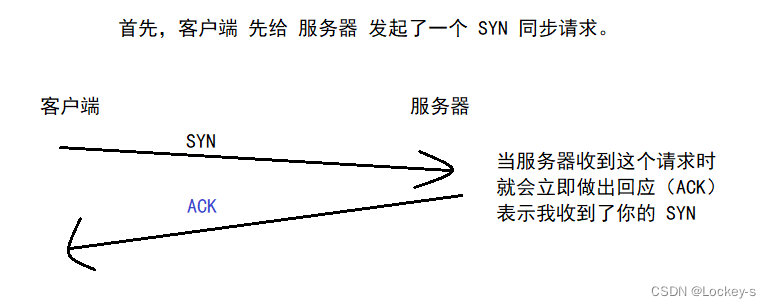
然后服务器也要再发送一个 SYN,表示服务器也想和客户端建立连接: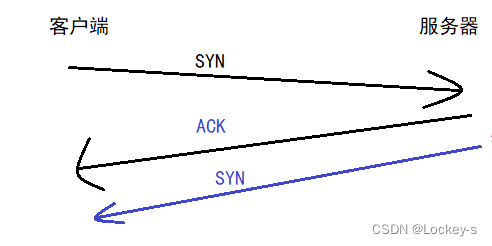
客户端收到服务器的 SYN 之后,也会立即返回一个 ACK: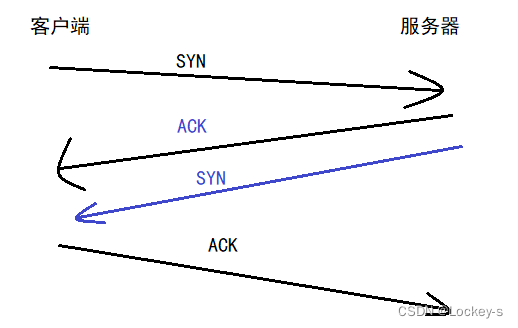
这样的话,双方各自向对方发送 SYN,再各自向对方发送 ACK,双向奔赴之后就建立连接了。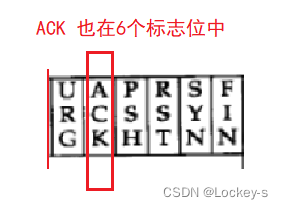
如果 ACK 这一位为 1,就表示这个报文是一个确认报文段(确认应答报文也就是 ACK 为 1)。ACK 这一位为 1 的时候,起到一个应答效果,用来确认消息是已经送到了的。
中间的那两次一定是可以合二为一的,也就是三次握手了。
每次要传输的数据,都要结果一系列的封装和分用,才能完成传输。如果 服务器 的 SYN 和 ACK 分开发送的话,就会导致封装的次数变多,导致效率变低。
只要把六个标志位中的 ACK 和 SYN 变为 1。就可以封装在一起了。
封装在一起之后就是这个样子: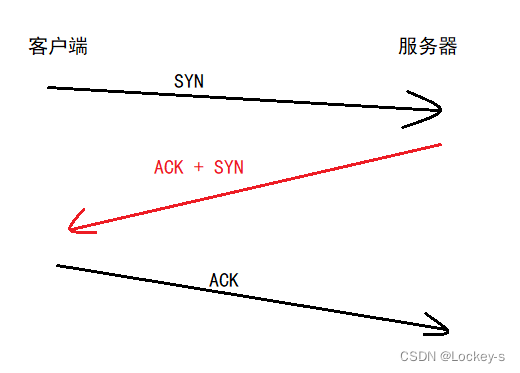
就是 三次握手 了。也就又回到我们刚开始的简化版本了。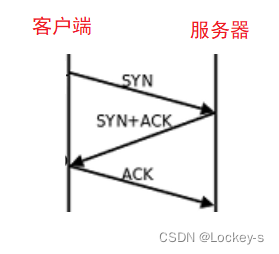
三次握手的本质上是四次,因为之间的两次交互合二为一了。所以就是三次握手了。
常见的状态:
- LISTEN:表示服务器启动成功,端口绑定成功,随时可以有客户端来建立连接。就像是手机开机,有信号,可以随时接电话。
- ESTABLISHED:表示当前客户端已经连接成功,随时可以进行通信。类似有人给我打电话,已经接通了,可以进行交流了。
三次握手和可靠连接的关系
三次握手相当于是 ”投石问路“,检查一下当前网络是否满足可靠传输的基本条件。更具体的来说:三次握手确实也是在检测通信双方的 发送能力 和 接受能力是否正常。举例:甲 给 乙打电话: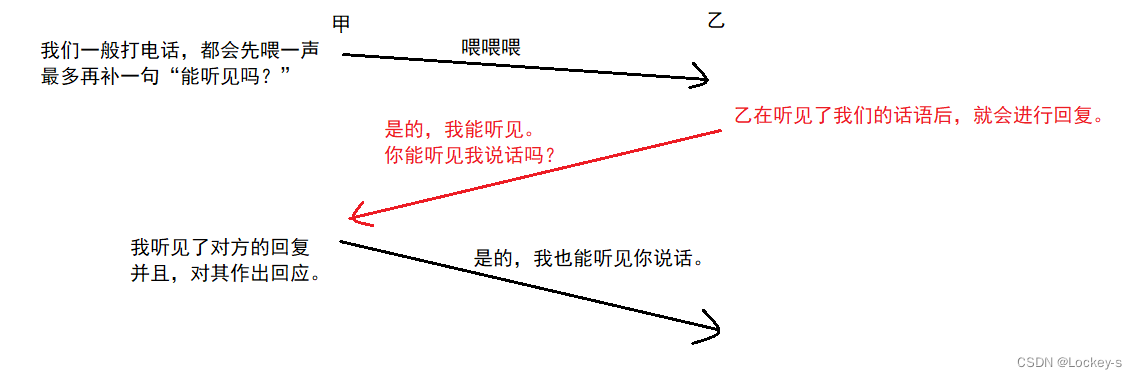
在这个场景中,也就是一个三次握手的情况。就是在验证 麦克风 和 喇叭 是否可以正常工作。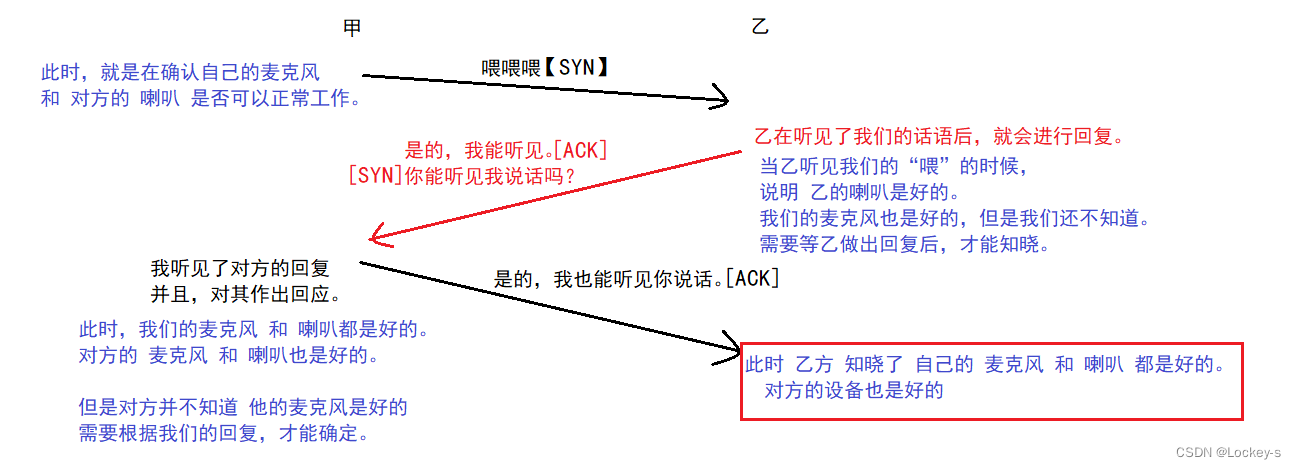
所以 三次握手 的重要意义就是:投石问路。
如果网络不稳定,设备有问题,就是这种情况:
所以 ”三次握手“ 和 超时重传、确认应答 具有关联关系。
如何断开连接
断开连接就是:四次挥手。三次握手,就让客户端和服务器之间建立好了连接。其实在建立好连接之后,操作系统内核当中,就需要使用一定的数据结构来保存连接的相关的信息,保存的信息其实最重要的就是前面说的五元组:源IP、源端口、目的IP、目的端口、TCP。有一天,连接断开了,那么五元组保存的连接信息就没意义了,对应的空间就可以释放了。就像攒钱买了手机,就和手机联系在了一起。如果有一天又买了新的手机,把旧手机卖掉之后,就和旧手机的所有联系都断开了。
四次挥手,就是和对方断开连接: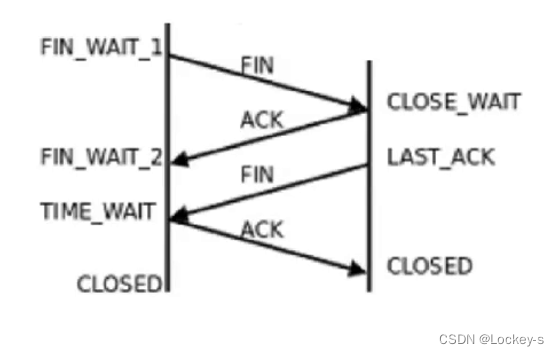
就是双方各自向对方发送了 FIN(结束报文段)请求,并且各自给对方一个 ACK 确认报文。这样的话,就完成了四次挥手。四次挥手就是各自和对方说断开连接。
四次挥手中重要的状态:
CLOSE_WAIT:
- 四次回收挥了两次之后出现的状态,这个状态就是在等待代码中调用 socket.close 方法,来进行后续的挥手过程。
- 正常情况下,一个服务器上面不应该存在大量的 CLOSE_WAIT 如果存在,说明大概率是代码 bug,close 没有被执行到。
TIME_WAIT:
- 谁主动发起 FIN,谁就进入 TIME_WAIT。
- 起到的效果:就是给最后一次 ACK 提供重传机会,表面上看起来 A 发送完 ACK 之后,就没有 A 的啥事了。
- 按理说 A 就应该销毁链接,释放资源了,但是并没有直接释放,而是会进入 TIME_WAIT 状态等待一段时间,一段时间后,再来释放资源。等这一会儿,就是怕最后一个 ACK 丢包了,如果丢包了,就意味着 B 过一会儿就会重传 FIN。
- 如果最后一个 ACK 丢了,B 就无法区别是 FIN 丢了,还是 ACK 丢了。于是 B 就假设 FIN 丢了,就重传 FIN(超时重传)。因为如果断开的太早,就没办法继续重传了。
- TIME_WAIT 持续时间:2*MSL MSL:表示网络上任意两点之间,传输需要的最大时间。这个时间也是系统上可以配置的参数,一个典型的设置就是:60s(经验值)。
四次挥手和三次握手的区别
- 三次握手,一定是客户端主动发起的(主动发起的一方才叫客户端)。
- 四次挥手,可能是客户端主动发起,也可能是 服务器 主动发起的。
- 三次握手,中间两次能合并。
- 四次挥手,中间有两次合并不了(有时候是能合并)不能合并是因为 B 给 A 发送的 ACK 和 FIN 的时机是不同的。
- 三次握手中:B 发生的 ACK 和 SYN 是同一时机发生的,就能够合并。此处的 B 给 A 发送的 ACK 和 SYN 都是操作系统内核负责的。
- 四次挥手中:B 给 A 发的 FIN 是用户代码负责的(B 的代码中调用了 socket.close()方法,才会触发)。
滑动窗口
滑动窗口存在的意义是,保证可靠性的前提下,尽量提高传输效率。先来看看不使用滑动窗口的传输机制是什么样子: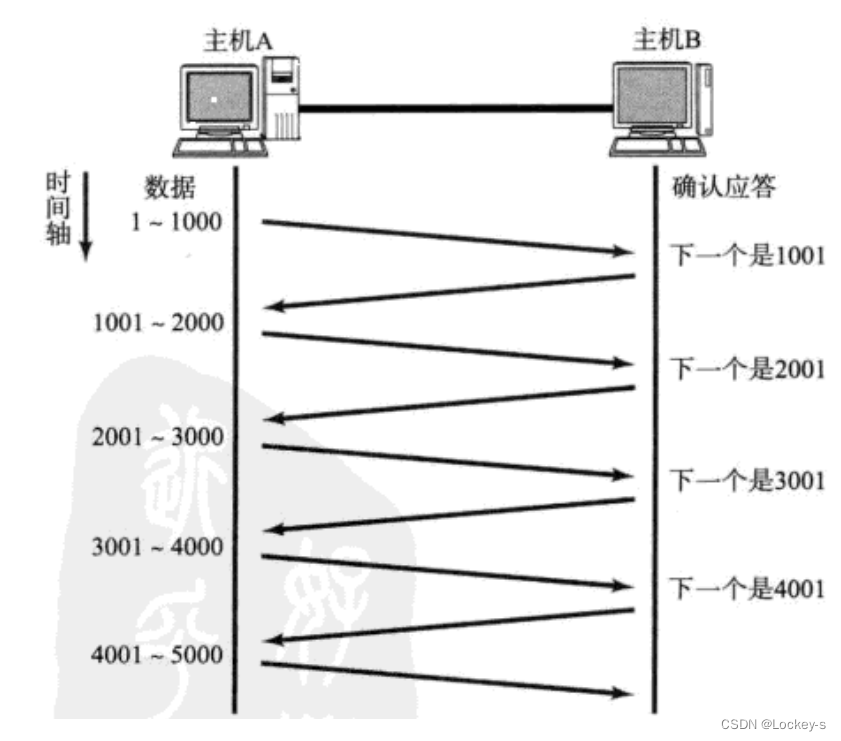
从图里就可以看到,由于确认应答机制存在,就导致了当前每次执行一次发送数据,都需要等待上一个 ACK 到达,大量的时间都浪费在等待 ACK 上面了,就导致效率变低了。
使用滑动窗口就是一次发送一波数据:
就相当于是一次发了 4 组数据,在发生这 4 组数据的过程中,不进行等待,这四组都发完了再统一等。
也就是把等待多份 ACK 的时间压缩成等待一份 ACK 了。
如果一次批量发送的数据位 N,统一等待一波,那么 N 就是窗口大小。等到第一波的第一组 ACK 之后,就发送下一组数据。”滑动“ 的意思是:并不用把 N 组数据的 ACK 都等到了,才继续往下发送。而是收到一个 ACK,就继续往下发一组。
就像当前是在的等待 1001、2001、3001、4001 四组 ACK,不需要等到 4001 到了,才继续往下发。
只要 1001 到了。就可以往下多发一组(4001-5000),如果是 2001 到了,就继续往下发一组(5001-6000),此时等待的
ACK 的范围就是 3001、4001、5001、6001。
如下图: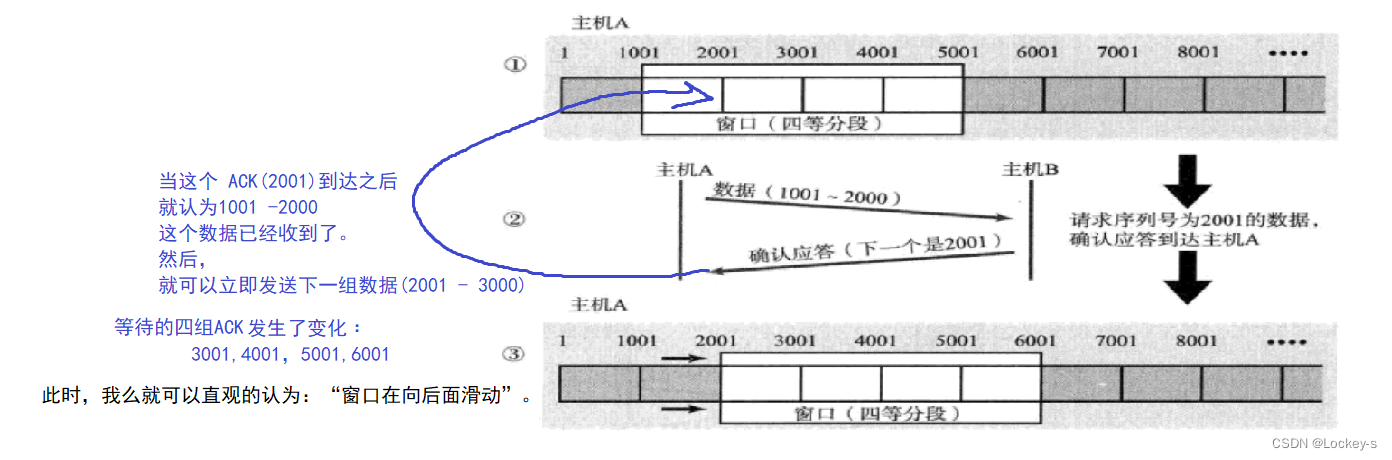
滑动窗口的窗口越大,就可以认为传输速度越快,窗口大了,同一份时间内等待的 ACK 就更多。总的等待 ACK 的时间就少了。
丢包
丢包分成两种:
- ACK 丢了
- 数据丢了
ACK 丢了: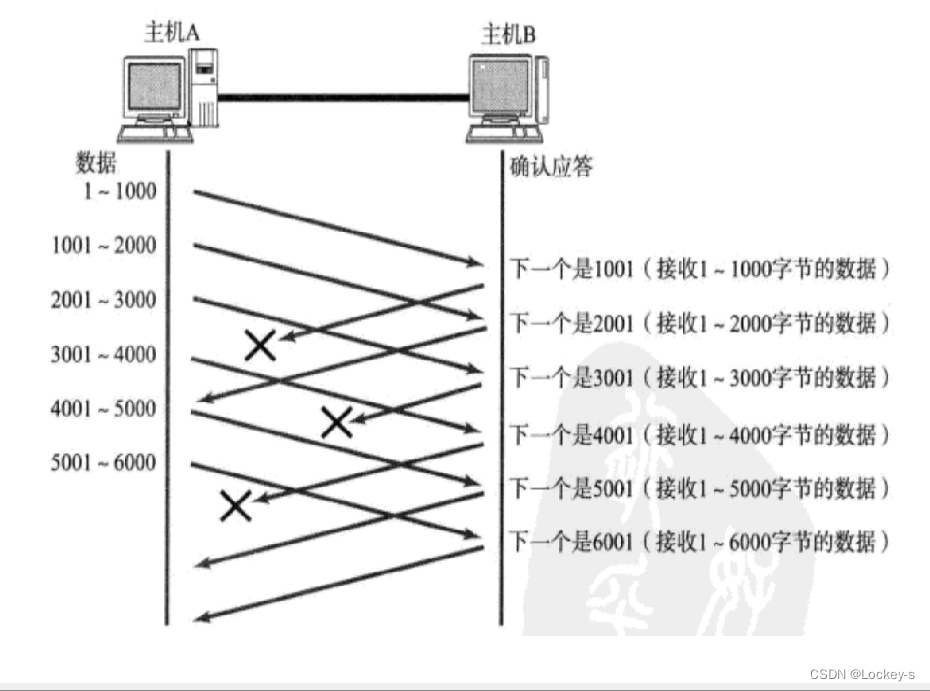
图片这里就是 ACK 丢了。
- 在发送 4001 的数据之前,发现收到了一个 2001 的 ACK,1001 并没有收到.
- 这里的 1001 已经不重要了。因为 2001 的意思就是:2001 之前的数据全都已经确认收到了。
- 由于 ACK 确认序号的含义,就保证了后一条 ACK 就能涵盖前一条。
- 确认序号的含义:表示当前序号之前的数据全都收到了。
- 就像发送方收到了 5001,就意味着 1-5000 的数据都确认收到了,3001、4001 被丢包也毫不影响。只要收到了 5001,就涵盖了 3001、4001 表达的信息。
数据丢了:
就像下面的图片这样: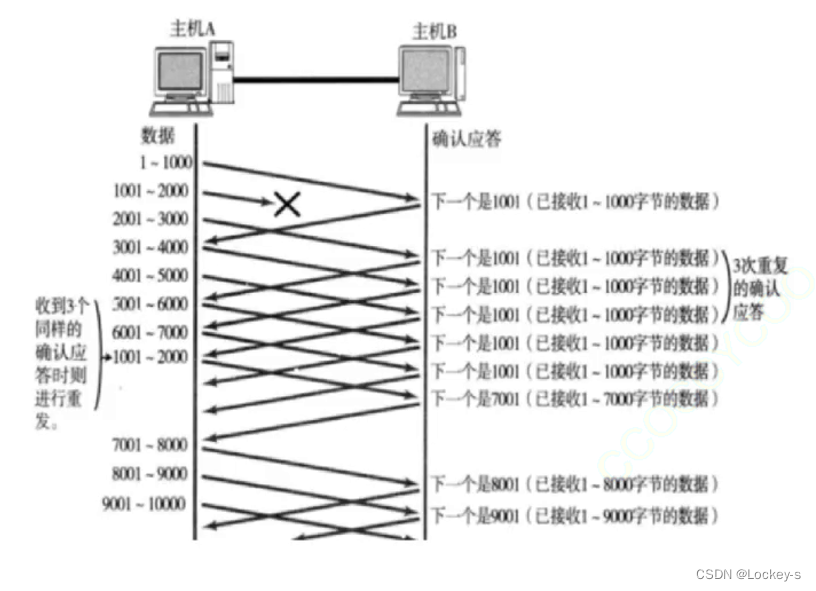
由于 1001-2000 这个数据丢了,所以 B 就再反复索要 1001 这个数据。即使 A 给 B 已经发后面的数据了,这个时候 B 仍然再索要 1001 这个数据。
当 A 被 B 索要多次之后,A 就明白了这个数据丢了,就会触发重传。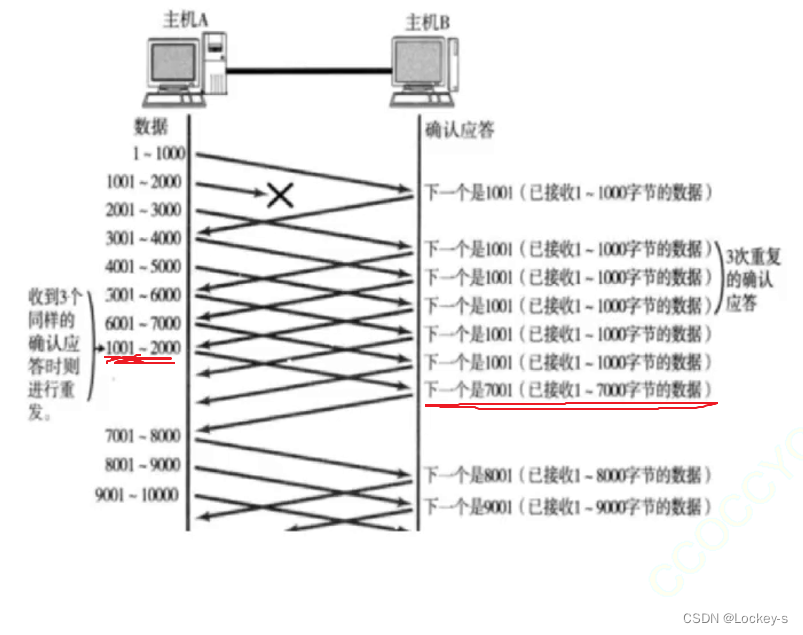
当 B 收到这个数据的时候,返回的 ACK 直接就是 7001 了。
重传 1001-2000 数据之前,接受缓冲区如下: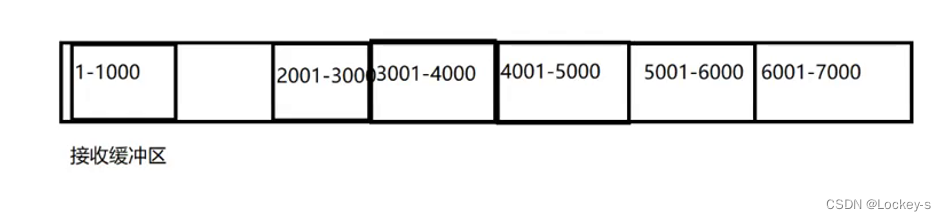
重传之后就是把缺口补上了,后面那些数据已经传过了,就不用再重传了,然后 B 就向 A 索要从 7001 开始的内容就好了:
快速重传就像是看直播的时候有事忙,等忙完的时候把拉下的一部分再补起来就好了。
流量控制
流量控制是滑动窗口的延申,目的也是为了可靠性。
- 滑动窗口越大,传输速率越高,不光要考虑发送方,还得考虑接收方。
- 发送方发的太快,接收方处理不过来,就会把新收的包给丢了,发送方还得重传。
- 流量控制的关键是能够衡量接收方的速度,直接使用接收方接受缓冲区的剩余空间大小,来衡量当前的处理能力。
- 可以把接收缓冲区理解为一个阻塞队列。B 的应用程序,在调用 read 方法的时候,就是从接收缓冲区中来取数据。通过 ACK 报文来看缓冲区大小,如果接收方反馈的窗口大小是 0,那么发送方也会发一个信息,用来探测有没有空间。
就像下面图片这样,也类似于一个生产者消费者模型: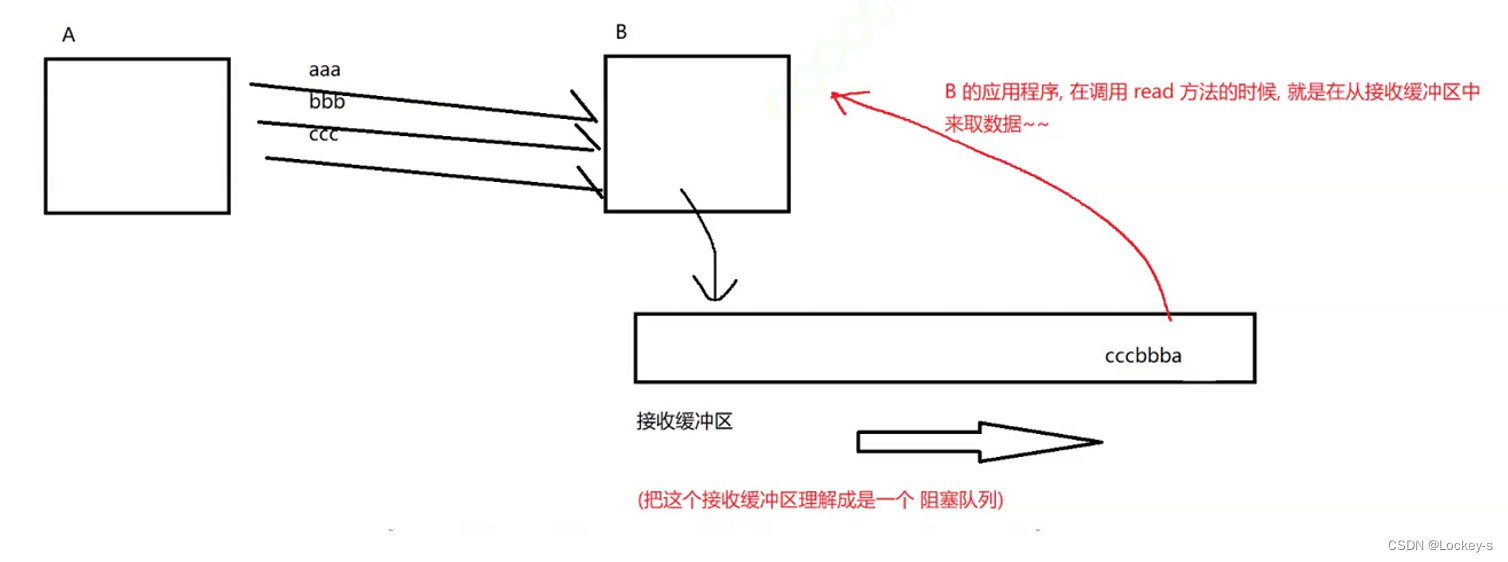
这个过程就像一个水池:
探测接收缓冲区剩余大小的具体流程: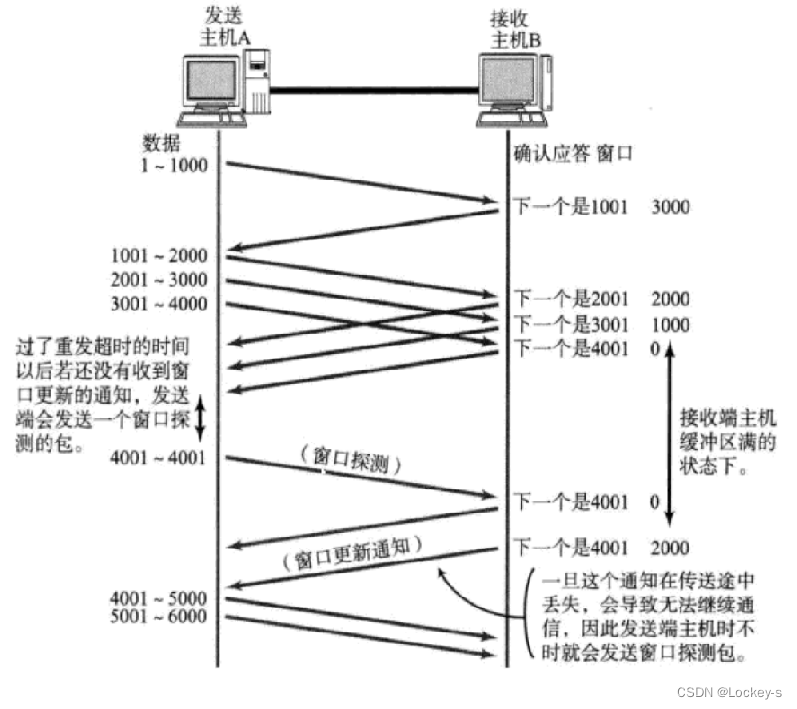
首先 A 给 B 发送 1000 数据的时候,B 返回数据的时候会返回接收缓冲区还剩 3000(就是 B 主机 1001 ACK 的右边的 3000) 的空间,那么下一次 A 就可以一次发送 3000 数据了。当 B 收到 3000 数据的时候,剩余缓冲区的大小就是 0 了。不过要注意的是: 当接受缓冲区大小为 0 的时候,A 也会继续发送窗口探测数据,当探测到接受缓冲区剩余大小又可以发送数据的时候,就可以继续发送数据了。
拥塞控制
拥塞控制也是滑动窗口的延申,也是限制滑动窗口的发送速率。控制衡量的是:
- 发送方到接收方 整个链路之间的拥堵情况,都会影响传输速率。
- 开始的时候,以一个比较小的窗口来发送数据,如果数据很流畅的到达了,那么就加大窗口大小。
- 加大到一定程度之后,出现了丢包(就意味着链路出现拥堵了),然后再减小窗口。
- 通过反复的 增大/减小 最终达到”动态平衡“。通过拥塞窗口来限制滑动窗口的大小。
- 最终滑动窗口的大小 由 拥塞窗口 和 流量控制窗口共同决定,由小的一方决定。一旦丢包,就立刻让窗口变小,降低速度,然后继续去试探的增大。
- 如果把窗口一下变得很小,就是期望这次传输,一定能成功。
过程如下图: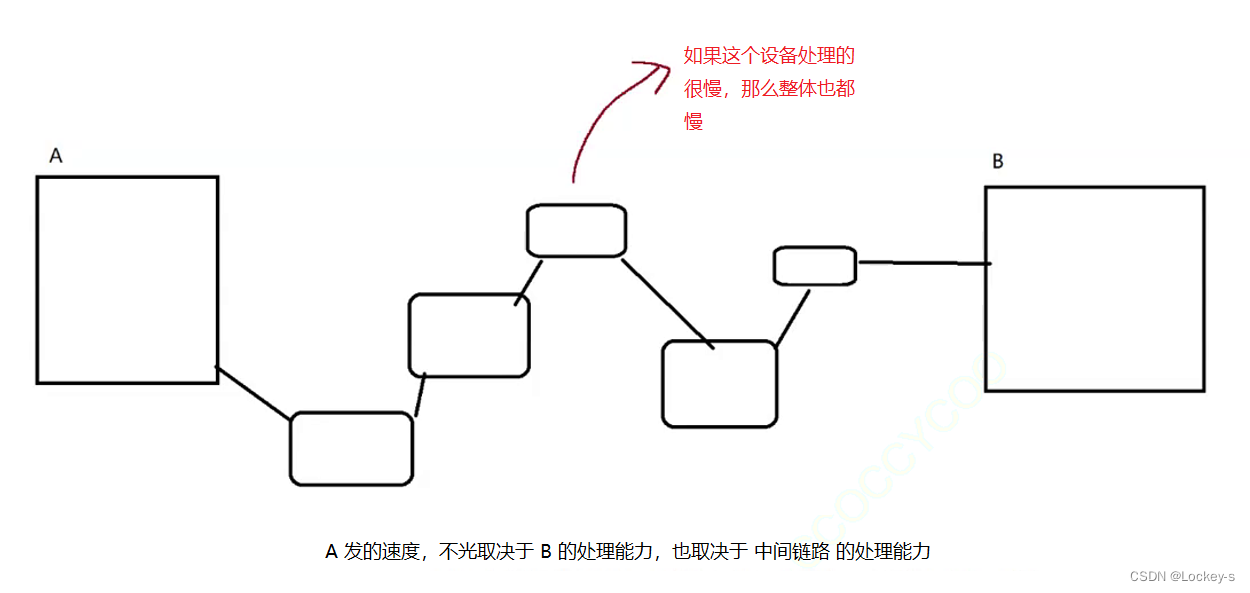
就像这样: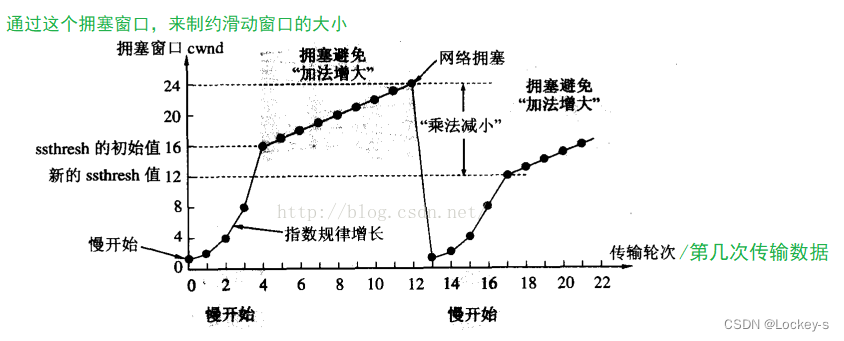
一开始指数增长是因为,初始窗口太小,而我们实际上可能触发丢包的值很大。因此,指数增长就可以帮我们快速找到,丢包的界限。
但是增长到一定的程度时,就会进入线性增长。因为即将达到丢包的界限,如果再来指数增长,就可能一次越界,直接触发丢包。如下图: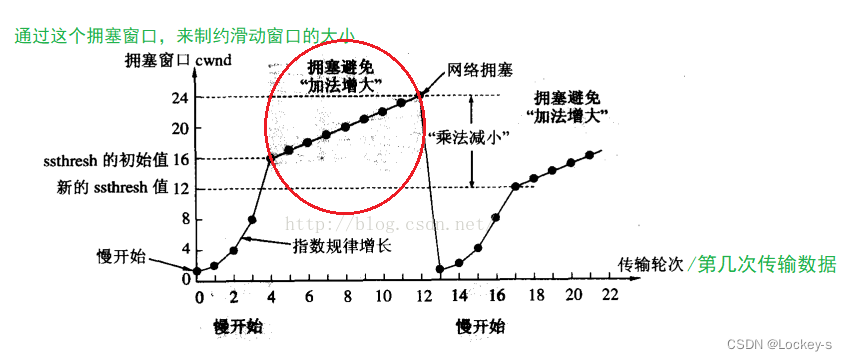
当线性增长达到丢包的界限,发生丢包之后,就让拥塞窗口立即变小,回归到初始窗口的大小。一次变得很小之后,也就是希望这次传输一定能成功。如下图:
延时应答
相当于流量控制的延申,流量控制是踩了下刹车,使发送方发的不要太快。延时应答就是在这个基础上,能尽量的再让窗口更大一些。就是在有限的情况下,尽可能提高一点传输速度。如下图: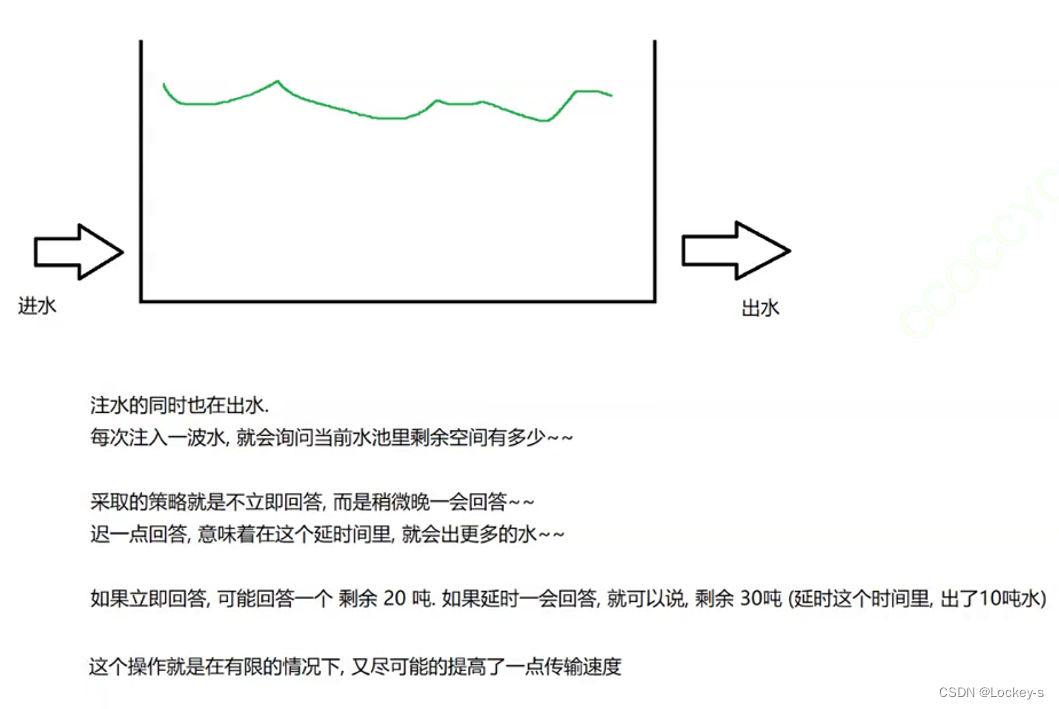
捎带应答
又是延时应答的延申,客户端和服务器之间的通信:由以下几种模型:
- 一问一答,客户端发一个请求,服务器返回一个对应的响应。
- 多问一答:上传文件 最常用的就是这个模型。
- 一问多达:下载文件。
- 多问多答:直播,串流。
面向字节流
面向字节流会引起:“粘包” 问题。指的是在应用层数据报,在 TCP 缓冲区中,若干个 应用层数据报混在一起了,分不出来谁是谁。如下图: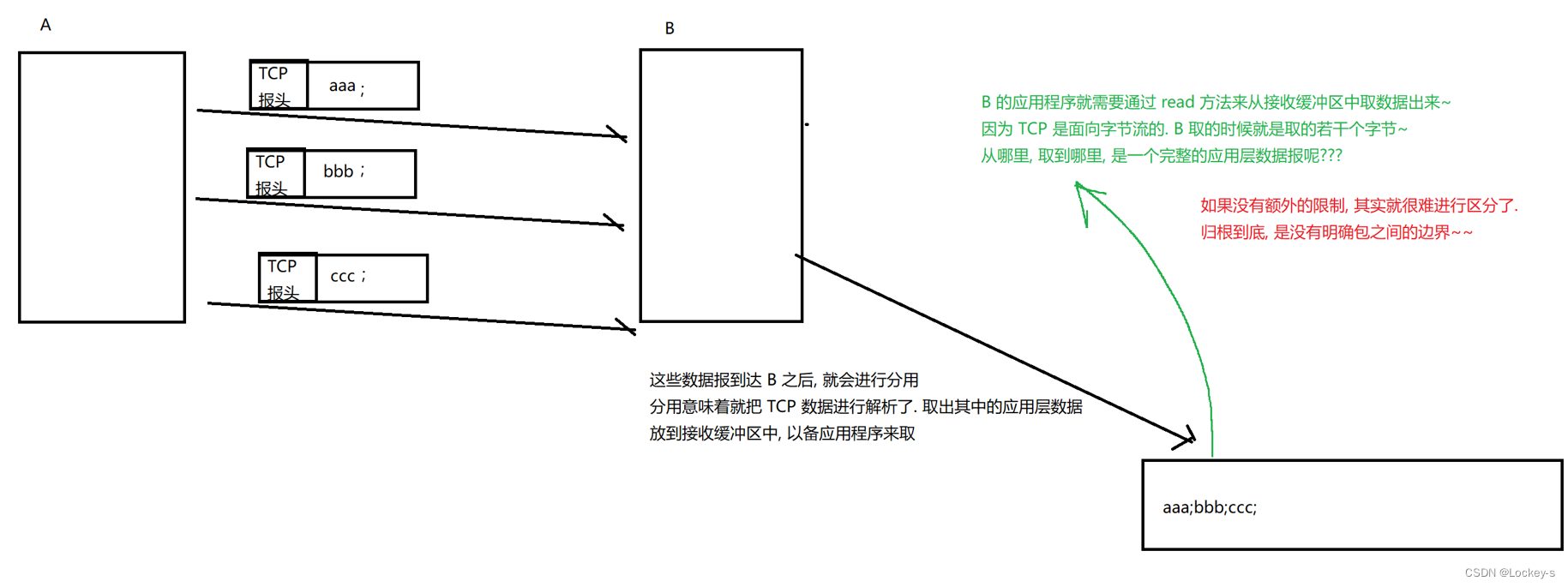
进行一次读操作的话,就把 aaabbbccc 都读走了。
解决粘包的方法:关键就是要在应用层协议这里,加入包之间的边界。粘包问题世界是应用层的问题。例如:约定每个包以 ;结尾。这个时候只要能够按照 ;来进行切分,就可以区分出当前从哪到哪是一个完整的包。如果通过 框架/库 的话,一般粘包问题就已经被 库/框架 处理了。
TCP 异常处理
进程终止
就是触发关闭文件操作,很正常的关闭。就像任务管理器当中的关闭:
一点结束任务,进程就关了。此时进程的 TCP 连接就断开了。此处的文件相当于 “自动关闭” ,这个过程其实和手动调用 socket.close() 一样,都会触发 4 次挥手。
机器关机
就是按照操作系统的正常流程关机,正常流程的关机,会让操作系统杀死所有进程,然后再关机。就和 进程终止 一模一样了。
机器断电/网线断开
就像是台式机拔电源,这样的话,操作系统就没有任何处理措施。就分为两种情况:
- 服务器断电,如下:
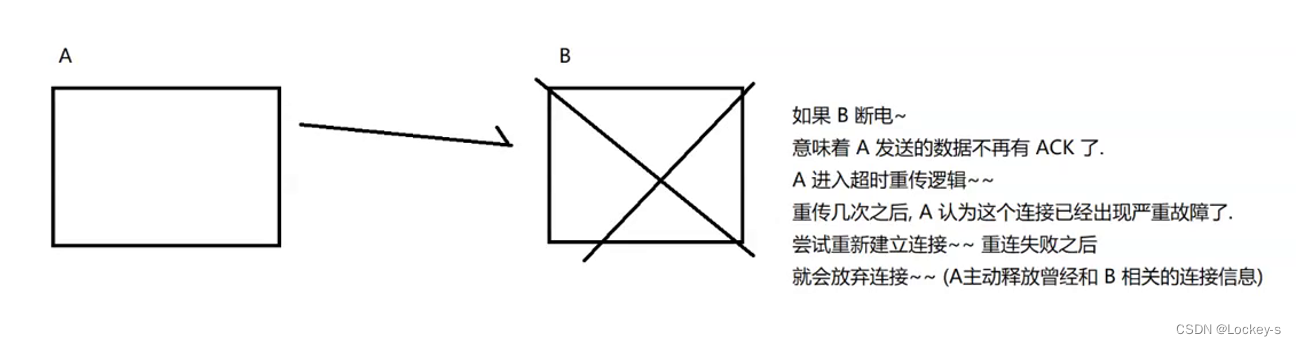
- 客户端断电,如下:
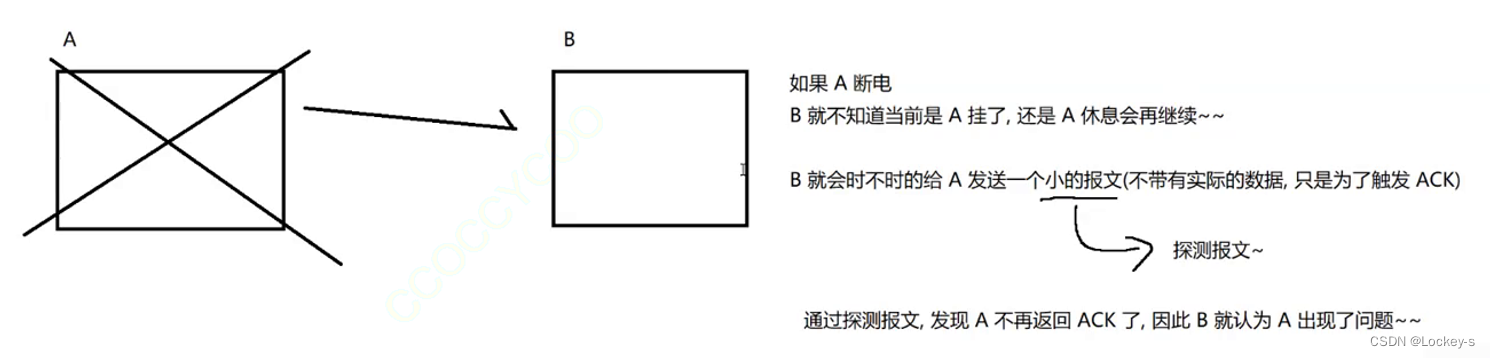
TCP 和 UDP 对比
- 对可靠性有一定要求,就使用 TCP。
- 对可靠性要求不高,对于效率要求更高,使用 UDP。
基于 UDP 如何实现可靠传输
那就根据 TCP 怎么实现的,UDP 的在传输层也照着实现一遍就好。本质就是在应用层基于 UDP 复刻 TCP 的机制。
网络层(IP 协议)
IP 协议完成两方面工作:
- 地址管理
- 路由选择
IP 协议的报头结构和作用:
那么在分包之后,就是i通过里面的标识,来确定是同一个包,通过 13 位片偏移来确定包的顺序。那么剩下的 “三位标志位” 的作用: 如果是 0 就是表示还有后续,如果是 1,就表示这是最后一个包了。如果 UDP 实现分包组包,也是照着抄 TCP 作业就好了。
8 位生存时间:
- 表示一个 IP 数据报,在网上还能存在多久,单位是 转发次数 。
- IP 数据报被发送的时候,会有一个初始的 TTL(常见的是 128、64),IP 数据报每次经过一个路由器, TTL 就会 -1.
- 如果 TTL 减到 0 了,此时遭受到这个白的路由器就会把这个包给弄丢。
- 主要就是有些包里面的 IP 地址,可能是永远也到不了的。像这样的包,不可能在网络上无休止的转发(占用硬件资源太多了)。
- 正常的 IP 数据报都会在既定的 TTL 内来到达。
8 位协议:传输层使用的是 哪种 协议,TCP 或者是 UDP 都有不同的取值。
16位首部校验和: 也是用来校验数据是否正确。
地址管理
如图: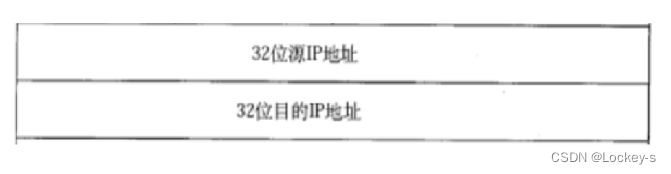
- 源 IP 表示发件人地址,目的 IP 表示收件人地址。
- 对于 IPv4 来说,一个 IP 地址本质上是 32位 的整数。通常会使用 “点分十进制” 来表示这个 IP 地址。三个点,就把 32 位整数分成 4个 部分,每个部分 1 个字节,每个部分的取值就是 0-255。
IP 地址又有两部分: 网络号+主机号。
- 网络号:描述当前的网段信息(局域网的标识)
- 主机号:区分了局域网内部的主机

我们的家里面就是一个局域网,要求:同一个局域网里,不同主机之间的网络号是相同的,主机号不能相。两个相邻的局域网,也是不同的。如下图:
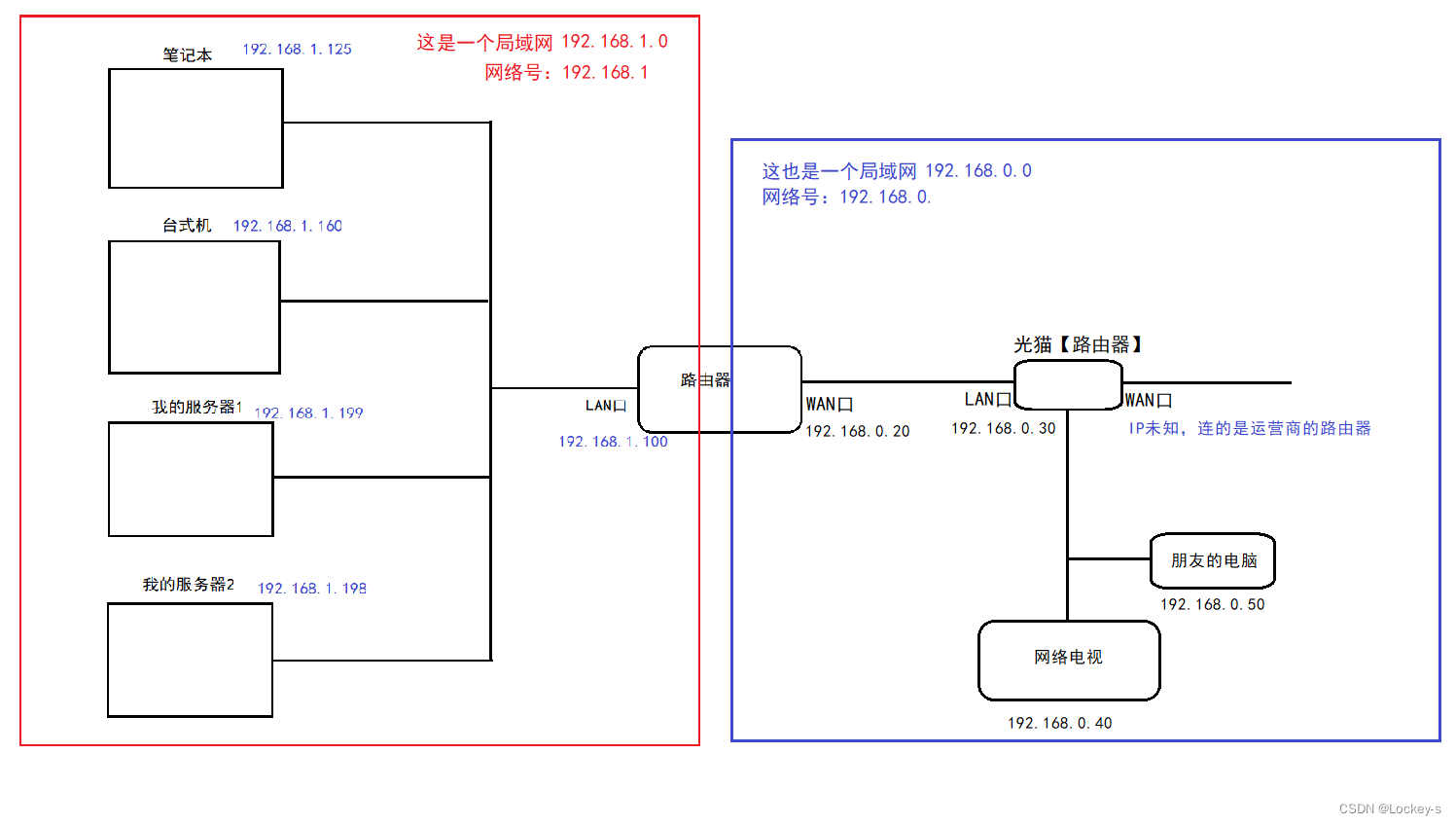
那么,到底前多少个 bit 位是网络号,其实是不固定的。通过引入 “子网掩码” 这样的概念来表示多少个 bit 位是网络号。
子网掩码: 也是一个 32 位,点分十进制来表示的整数。
- 子网掩码的左侧都是 1,右侧都是 0(不会 1 0 混着排列)
- 左边的这些 1 就表示哪些位是网络号,剩下的 0 就表示哪些位是 主机号。
就像这样:
一般家用的场景中,一个局域网设备很少(不会超过 255 个),常见的子网掩码就是 255.255.255.0,如果一个局域网设备多了,子网掩码就会出现一些其他值。
特殊的 IP
IP 地址中,还有特殊的 IP:
- 如果主机号全是 0,那么该 IP 就表示网络号(局域网里的正常设备,主机号不能为 0)
- 如果 IP 的主机号全是 1,该 IP 就表示”广播地址“,往这个广播地址上发的消息,整个局域网中都能收到。
- IP 地址是 127 开头的,就表示”环回 IP“表示主机自己(127.0.0.1:环回 IP 中的典型代表)
- IP 地址是 10 开头 或者 192.168 开头 或者 172.16-172.31 开头,就表示该 IP 地址是一个局域网内部的 IP(内网 IP)
- 除此之外,剩下的 IP 称为 外网IP(直接在广域网上使用的 IP)要求外网IP 一定是唯一的,每个外网 IP都会对应到唯一的一个设备,内网 IP 只是在当前局域网中是唯一的,不同局域网里,可以有相同的内网 ip 的设备。
IP 地址不够用
不同的局域网里,有相同的 IP 设备,主要就是因为当前的 IPv4 协议,使用的地址是 32 位的整数。32 位整数表示的数据范围,就是 42亿9千万。如果给每个设备都分配一个唯一的 IP 地址,就意味着世界上的设备不能超过这么多。所以就有了这样的方式。解决 IP 地址不够用:
- 动态分配 IP 地址:每个设备连上网的时候,才有 IP,不联网的时候就没 IP(这个IP就给别人用),通过 动态IP 来解决 IP地址不够用的问题。
- NAT 机制:就是让多个设备共用一个 IP(外网IP)把网络分为 内网 和 外网。内网可以共用一个 外网的IP。也就是这里的外网 IP,会给所有接入这个运营商设备的局域网都来使用这个 外网IP。外网区分内网的数据,就是通过端口号来区分的。网络的连接,是一个 五元组,即使是 IP 相同也没事。有 NAT 机制,就会隐含一个重要的结论: a)对于一个 外网IP 来说,可以在互联网的任意位置都能访问到, b)对于一个 内网IP 来说,只能在当前局域网内部访问,就是 局域网1 的设备,不能使用内网访问 局域网2 的设备。 c)内网IP 是可以重复的,只有在局域网内才是唯一的。 d)不同的局域网访问的话,就需要一个带有 外网IP 的机器,然后 局域网1 把数据放到 外网服务器,然后 局域网2 就可以访问到外网服务器,就会修改 IP数据报,把内网发出的 源IP,改为 外网IP。 e)NAT 也是存在极限的,端口号个数是 65535,如果一个局域网内的连接数超过了 65535,这时候 NAT 就不一定好使了,因为端口号不够用了。NAT 相当于是续命了,并不是从根本解决。
- IPv6 :从根本解决了 IP 地址不够用的问题。因为 IPV6 在报头中使用了更长的字段来表示 IP地址,使用 16 个字节来表示。16个字节,128位,之前是 4个字节,32位。IPv6 比 IPv4 能表示的多很多很多。IPv6 地址如下:
 IPv6 使用率不是很高的原因是:支持 IPV4 和 IPV6 需要两截然不同的机制。现有的大量网络设备(路由器…)很可能只支持 IPV4,不支持 IPV6。IP地址的划分,是通过 子网掩码 划分的,在子网掩码之前,是通过 ”分类” 的方式来划分的,把 IP 地址分成了 ABCDE。这五类,每一类分别都有几位是 网络号,几位是 主机号。
IPv6 使用率不是很高的原因是:支持 IPV4 和 IPV6 需要两截然不同的机制。现有的大量网络设备(路由器…)很可能只支持 IPV4,不支持 IPV6。IP地址的划分,是通过 子网掩码 划分的,在子网掩码之前,是通过 ”分类” 的方式来划分的,把 IP 地址分成了 ABCDE。这五类,每一类分别都有几位是 网络号,几位是 主机号。
路由管理
路由选择也就是规划路径,当两个设备之间,要找出一条通道,能够完成传输的过程。IP 协议的路由选择也是类似的:
- IP数据报 中的目的地址,就表示了这个包要发送到那里去,如果路由器认识目的地址,就会告诉路。
- 如果不认识路,就告诉大概方向,走到下一个路由器的时候继续问,依次往后走,也就是离目标越来越近,最后就可以找到这个地址。
- 有的时候,不光遇到认识地址的路由器,而且还认识很多路,就可以选择合适的路了。
- 路由器内部维护了一个数据结构(路由表),记录了一些网段信息(网络号,)以及每个网络号对于的网络接口。
数据链路层
数据链路层主要的协议是:以太网。每个网卡,都有 mac地址,是唯一的,在网卡出厂的时候就写死了。以太网数据帧: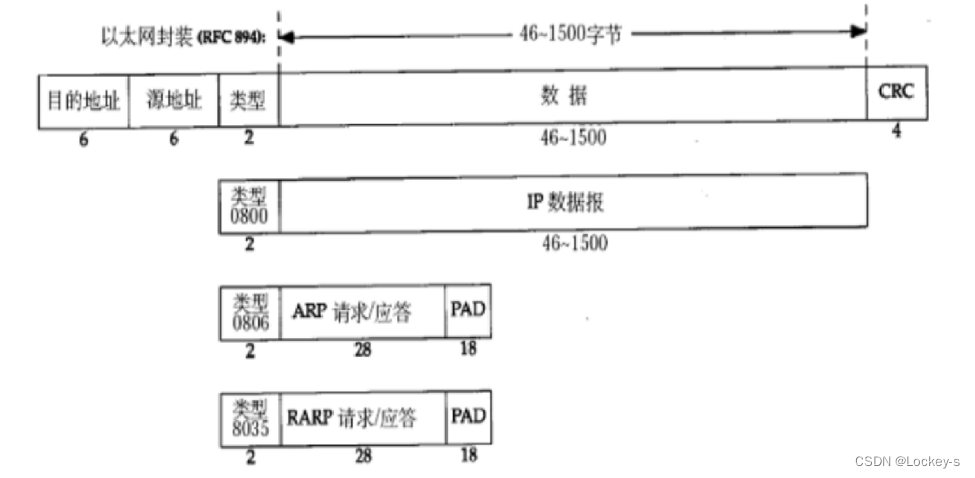
- mac地址,表示传输过程中相邻两个设备的关系。以太网数据帧的末尾会有 CRC算法的校验和:循环冗余算法,把数据的每个字节一次进行累加(溢出就溢出)
- IP 用来表示一次传输过程中的起点和终点(不考虑 NAT 的情况,一个 IP 数据报中的 源IP 和 目的IP 是固定的)
- mac 用来表述传输过程中,任意两个相邻节点之间的地址(一个以太网数据帧,在每次转发过程中,源 mac 和 目的 mac 都会改变)
- MTU:一个以太网数据帧能够承载的数据范围,这个范围取决于硬件设备。以太网和硬件也是密切相关的,不同的硬件设备,对应的 数据链路层协议,可能又不一样,MTU 也不相同。MTU 对IP 的影响;主要影响就是分包的过程。
- MSS:TCP 中在 IP 不分包的前提下,最多搭配多少载荷: a)一方面取决于 MTU。另一方面取决于 TCP 和 IP 的报头。 b)当 TCP 传输的数据长度不高于 MSS 的时候,是处于最高效的状态。 c)ARP 报文并不是用来传输数据的,只是起到一个辅助的效果。 d)路由器拿到一个 IP地址(目的IP),通过 IP地址,来决定接下来这个数据咋走(从哪个端口出去,发到哪个设备上)。 d)所以就得决定,接下来封装的以太网数据帧,目的 mac 是啥,需要根据 ARP协议,建立起 IP -> mac 这样的映射关系。 e)当设备启动的时候,就会向局域网当中,广播 ARP报文,每个设备收到的时候,都会做一个应答。 f)应答信息中就包含了自己的 IP 和 mac,发起广播的那一方,就可以根据这些回应,建立起这个映射表了。
特殊的协议
DNS
DNS 是一个应用层协议,是域名解析。
对于一些难记的地址,就可以使用一串英文单词来表示这个 ip地址,这串英文单词,就叫做域名。域名和 IP地址 之间是一一对应的关系。
DNS 系统:DNS 系统,最开始的时候,只是一个普通文件,称为 hosts 文件。如下图:
打开之后就是这样: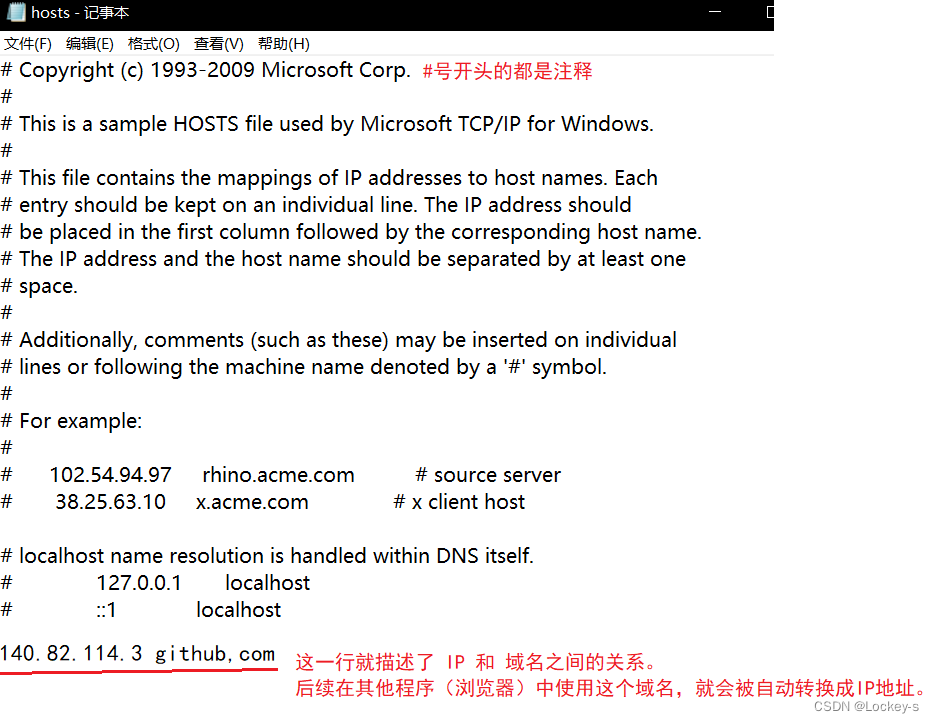
现在 hosts 文件已经不使用了,因为域名太多了,不可能去一直修改 host 文件。于是有了一个机构,专门负责处理这些 域名 和 IP 的对应关系。如果想要对域名进行解析的话,就访问一下这个服务器(域名解析服务器)就好了,每个城市都会有镜像服务器,我们一般都是在访问镜像服务器。
当我们的主机,查询了 DNS 之后,主机就会把这个查询结果缓存一定的时间(浏览器来进行缓存)下次再访问到同一个域名的时候,就可以省略查询 DNS 的过程了。
NAPT
这个就是当 端口号重复时的情况,它的处理机制就是 NAPT。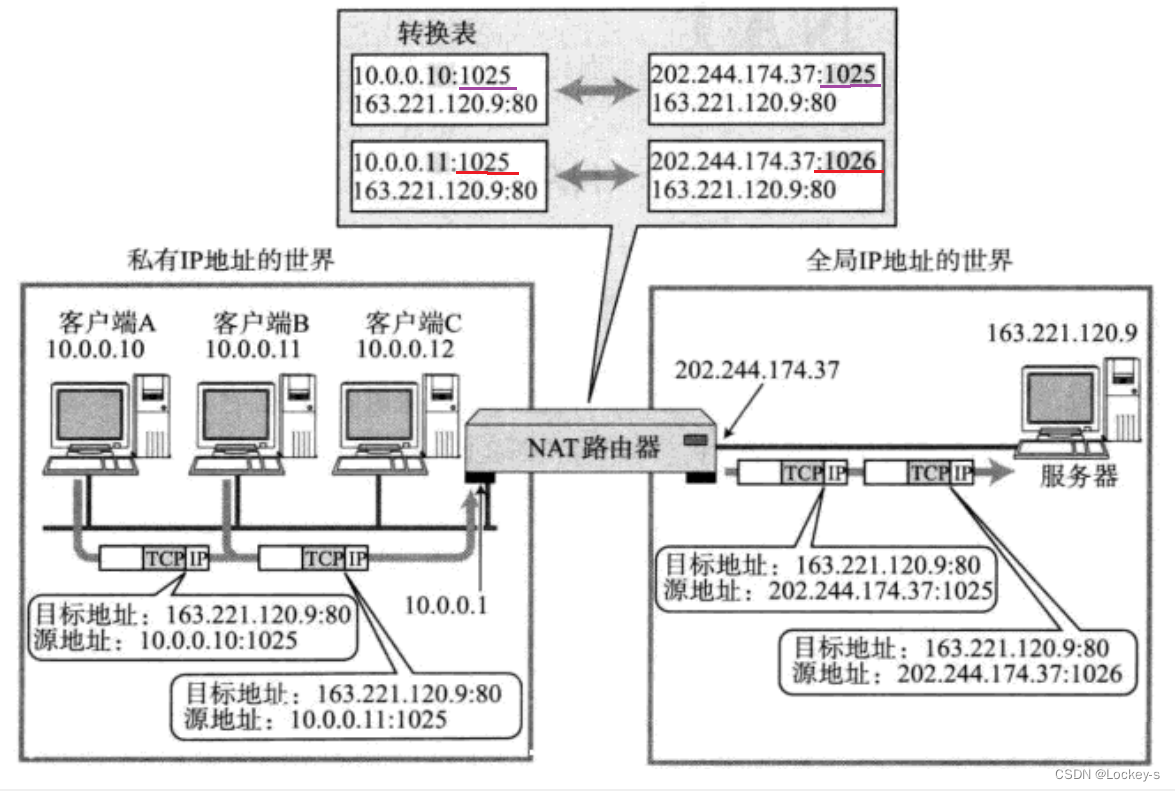
这种关联关系也是由NAT路由器自动维护的。
例如在TCP的情况下,建立连接时,就会生成这个表项;
在断开连接后,就会删除这个表项
版权归原作者 Lockey-s 所有, 如有侵权,请联系我们删除。