
几何深度学习是从对称性和不变性的角度对广泛的ML问题进行几何统一的尝试。这些原理不仅是卷积神经网络的突破性性能和图神经网络的近期成功的基础,而且还为构造新型的特定于问题的归纳偏差提供了一种有原则的方法。
此文章是与Joan Bruna,Taco Cohen和PetarVeličković共同撰写的,并基于MM Bronstein,J。Bruna,T。Cohen和P.Veličković的新论文 Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges (2021),剑桥大学Petar的演讲和2021年ICLR的Michael主题演讲。
1872年10月,巴伐利亚城市埃尔兰根的一所小型大学的哲学系任命了一位新的年轻教授。按照惯例,他被要求提供一个就职研究计划,并以比较长而乏味的标题Versleichende Betrachtungenüberneuere geometrische Forschungen发表(“对几何学最新研究的比较评论”)。教授是菲利克斯·克莱因(Felix Klein),当时年仅23岁,他的开创性工作以“埃尔兰根计划” [1]进入了数学史。

十九世纪在几何学方面硕果累累。欧几里得之后的近两千年来,庞塞莱特(Poncelet)构造了投影几何,高斯,波利亚伊(Galys)和洛巴切夫斯基(Lobachevsky)构造了双曲线几何,里曼(Riemann)构造了椭圆几何,这表明,建立一个具有各种几何形状的整个生态学说是可能的。但是,这些构造很快进入了独立且无关的领域,当时的许多数学家都在质疑不同的几何形状如何相互关联以及实际上定义了什么几何形状。
克莱因(Klein)的突破性见解是将几何学的定义作为不变性的研究,或者换句话说,是在某种类型的转换(对称性)下保留的结构。克莱因(Klein)使用群论的形式主义来定义此类转换,并使用群及其子群的层次结构来分类由此产生的不同几何形状。因此,一组刚性运动导致传统的欧几里得几何,而仿射或投影变换分别产生仿射和投影几何。重要的是,Erlangen程序仅限于齐次空间[2],并最初排除了黎曼几何。
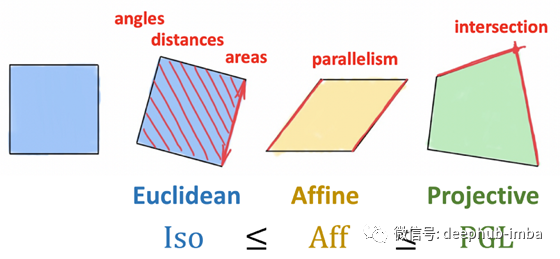
克莱因(Klein)的埃尔兰根计划(Erlangen Program)将几何学作为研究在某些类型的变换下保持不变的属性的方法。二维欧几里得几何形状由保留区域,距离和角度以及平行度的刚性变换(建模为等轴测图组)定义。仿射变换保留并行性,但距离和面积均不保留。最后,射影变换具有最弱的不变性,仅保留了相交和交叉比率,并且对应于三个之中最大的一个。因此,克莱因认为射影几何是最通用的一种。
Erlangen计划对几何和数学的广泛影响非常深远。它也蔓延到其他领域,尤其是物理领域,在这些领域中,对称性考虑允许从第一原理推导守恒律,这是一个令人惊讶的结果,被称为Noether定理[3]。经过几十年的发展,直到证明了这一基本原理(通过规范不变性的概念(由Yang 和 Mills在1954年提出的广义形式))成功地统一了除重力以外的所有自然基本力。这就是所谓的标准模型,它描述了我们目前所知道的所有物理学。我们只能重复诺贝尔奖得主物理学家菲利普·安德森(Philip Anderson)的话[4],
“说物理是对对称性的研究只是有点夸大其词了。’”
我们认为,深度(表示)学习领域的现状让我们想起了19世纪的几何情况:一方面,在过去的十年中,深度学习在数据科学领域带来了一场革命, 以前认为可能无法完成的许多任务-无论是计算机视觉,语音识别,自然语言翻译还是alpha Go。另一方面,我们现在拥有一个针对不同类型数据的不同神经网络体系结构的动物园,但统一原理很少。结果,很难理解不同方法之间的关系,这不可避免地导致相同概念的重新发明。
几何深度学习是我们在[5]中引入的总称,指的是最近提出的ML几何统一的尝试,类似于Klein的Erlangen计划。它有两个目的:首先,提供一个通用的数学框架以推导最成功的神经网络体系结构;其次,给出一个建设性的程序,以有原则的方式构建未来的体系结构。
在最简单的情况下,有监督的机器学习本质上是一个函数估计问题:给定训练集上某些未知函数的输出(例如标记的狗和猫图像),人们试图从某个假设类中找到一个适合训练的函数f 数据,并可以预测以前看不见的输入的输出。在过去的十年中,大型,高质量的数据集(如ImageNet)的可用性与不断增长的计算资源(GPU)吻合,从而允许设计功能丰富的类,这些类可以内插此类大型数据集。
神经网络似乎是表示功能的合适选择,因为即使是最简单的体系结构(如Perceptron),仅使用两层时也可以生成密集类的功能,从而可以将任何连续函数近似为任何所需的精度-这种特性被称为通用近似(Universal Approximation) [6]。
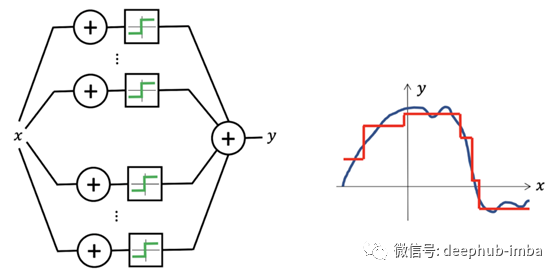
多层感知器是通用逼近器:只有一个隐藏层,它们可以表示阶跃函数的组合,从而可以任意精度近似任何连续函数。
低维问题的设置是逼近理论中的经典问题,该问题已得到广泛研究,并通过精确的数学方法控制估算误差。但是在高维度上情况却完全不同:人们可以快速看出这一点,以便甚至近似一个简单的类别,例如 Lipschitz连续函数使样本数量随维数呈指数增长,这种现象俗称“维数诅咒”。由于现代机器学习方法需要处理成千上万甚至数百万个维度的数据,因此维度的诅咒总是在幕后出现,从而使这种幼稚的学习方法变得不可能。
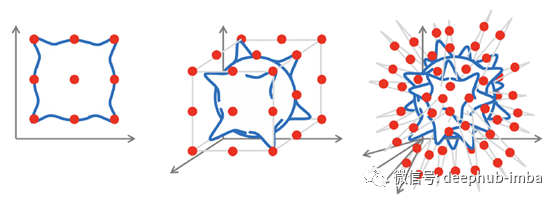
维度诅咒的图示:为了近似由高斯核构成的Lipschitz连续函数,该函数位于误差为ε的d维单位超立方体(蓝色)的象限中,需要𝒪(1 /εᵈ)个样本(红点) )。
在计算机视觉问题(例如图像分类)中可能最好地看到了这一点。即使是很小的图像也往往具有很高的尺寸,但是从直观上讲,当人们将图像解析为矢量以将其馈送到感知器时,它们会被破坏并丢弃很多结构。如果现在仅将图像移位一个像素,则矢量化的输入将有很大的不同,并且神经网络将需要显示很多示例,以了解必须以相同的方式对移位的输入进行分类[7]。
幸运的是,在许多高维ML问题的情况下,我们还有一个附加结构,它来自输入信号的几何形状。我们称这种结构为“先验对称性”,它是一种普遍有效的原理,它使我们对因维数引起的问题感到乐观。在我们的图像分类示例中,输入图像x不仅是d维矢量,而且是在某个域Ω上定义的信号,在此情况下为二维网格。域的结构由对称组𝔊(在我们的示例中为2D平移组)捕获,该组作用于域上的点。在信号𝒳(Ω)的空间中,基础域上的组动作(组元素,𝔤∈𝔊)通过所谓的组表示ρ(𝔤)来表示,在我们的例子中,这只是移位运算符,作用于d维矢量的ad×d矩阵[8]。
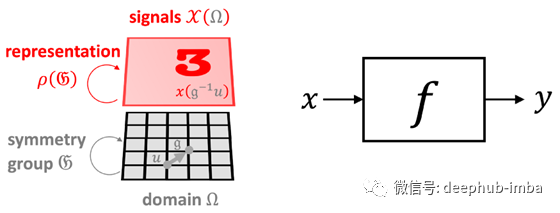
几何先验的图示:输入信号(图像x∈𝒳(Ω))定义在域(网格Ω)上,其对称性(平移组𝔊)通过组表示ρ(𝔤)在信号空间中起作用(移位算子 )。假设函数f(例如图像分类器)如何与该组交互将限制假设类别。
输入信号下面的域的几何结构将结构强加给我们试图学习的函数f。一个不变函数可以不受组的作用的影响,即对于任何𝔤∈𝔊和x,f(ρ(𝔤)x)= f(x)。另一方面,函数可能具有相同的输入和输出结构,并且以与输入相同的方式进行转换,这种情况称为等变且满足f(ρ(𝔤)x)=ρ(𝔤 )f(x)[9]。在计算机视觉领域,图像分类很好地说明了人们希望拥有不变函数的情况(例如,无论猫在图像中的位置如何,我们仍然希望将其分类为猫),而图像分割,其中输出是逐个像素的标签遮罩,是等变函数的一个示例(分割遮罩应遵循输入图像的变换)。
另一个强大的几何先验是“尺度分离”。在某些情况下,我们可以通过“同化”附近的点并生成与粗粒度算子P相关的信号空间的层次结构,来构建域的多尺度层次结构(下图中的Ω和Ω')。尺度,我们可以应用粗尺度函数。我们说,如果函数f可以近似为粗粒度算子P和粗尺度函数f≈f′∘P的组成,则它是局部稳定的。尽管f可能依赖于远程依赖关系,但如果它是局部稳定的,则可以将它们分为局部交互作用,然后向粗尺度传播[10]。
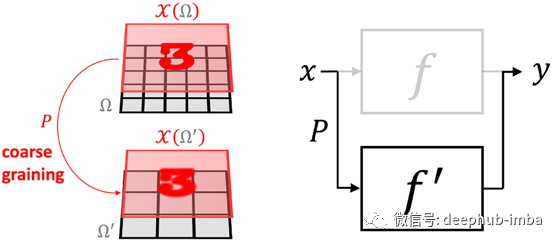
标度分离的示意图,其中我们可以将细级函数f近似为粗级函数f'和粗粒度运算符P的组成f≈f′∘P。
这两个原则为我们提供了一个非常通用的几何深度学习蓝图,可以在大多数用于表示学习的流行深度神经体系结构中得到认可:典型设计由一系列等变层(例如,CNN中的卷积层)组成,可能遵循 通过不变的全局池层将所有内容汇总到一个输出中。在某些情况下,也可以通过采用本地池形式的粗化过程来创建域的层次结构。
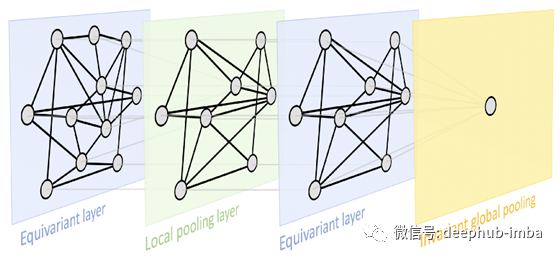
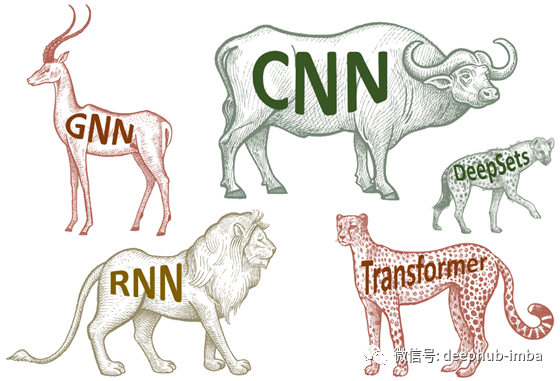
这是一种非常通用的设计,可以应用于不同类型的几何结构,例如网格,具有全局变换组的齐次空间,图形(以及特定情况下的集合)和流形,其中我们具有全局等距不变性和局部性 规范的对称性。这些原则的实现导致了深度学习中当今存在的一些最受欢迎的体系结构:从平移对称出现的卷积网络(CNN),图神经网络,DeepSets [11]和Transformers [12],实现了置换不变性, 时间扭曲不变的门控RNN(例如LSTM网络)[13],计算机图形和视觉中使用的内在网格CNN [14],它们可以从量规对称性派生。
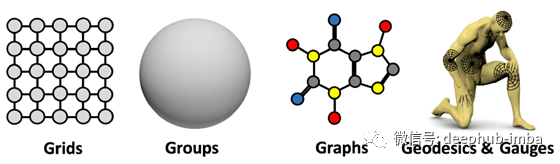
几何深度学习的“ 5G”:网格,组(具有全局对称性的均匀空间),图(以及作为特定情况的集合)和流形,其中几何先验通过全局等距不变性表示(可以使用测地学表示) 和局部量规的对称性。
在以后的文章中,我们将进一步详细探讨“ 5G”上的“几何深度学习”蓝图的实例[15]。最后一点,我们应该强调,对称性在历史上一直是许多科学领域的关键概念,正如开头所提到的,物理学是关键。在机器学习界,对称性的重要性早已得到认可,尤其是在模式识别和计算机视觉的应用中,关于等变特征检测的早期工作可以追溯到Shun’ichi Amari [16]和Reiner Lenz [17]。在神经网络文献中,Marvin Minsky和Seymour Papert [18]提出的感知器的群不变性定理对(单层)感知器学习不变性的能力提出了基本限制。这是研究多层体系结构的主要动机之一[19-20],最终导致了深度学习。
引用
[1] According to a popular belief, repeated in many sources including Wikipedia, the Erlangen Programme was delivered in Klein’s inaugural address in October 1872. Klein indeed gave such a talk (though on December 7, 1872), but it was for a non-mathematical audience and concerned primarily his ideas of mathematical education. What is now called the “Erlangen Programme” was actually the aforementioned brochureVergleichende Betrachtungen, subtitled Programm zum Eintritt in die philosophische Fakultät und den Senat der k. Friedrich-Alexanders-Universität zu Erlangen (“Program for entry into the Philosophical Faculty and the Senate of the Emperor Friedrich-Alexander University of Erlangen”, see an English translation). While Erlangen claims the credit, Klein stayed there for only three years, moving in 1875 to the Technical University of Munich (then called Technische Hochschule), followed by Leipzig (1880), and finally settling down in Göttingen from 1886 until his retirement. See R. Tobies Felix Klein — Mathematician, Academic Organizer, Educational Reformer (2019) In: H. G. Weigand et al. (eds) The Legacy of Felix Klein, Springer.
[2] A homogeneous space is a space where “all points are the same” and any point can be transformed into another by means of group action. This is the case for all geometries proposed before Riemann, including Euclidean, affine, and projective, as well as the first non-Euclidean geometries on spaces of constant curvature such as the sphere or hyperbolic space. It took substantial effort and nearly 50 years, notably by Élie Cartan and the French geometry school, to extend Klein’s ideas to manifolds.
[3] Klein himself has probably anticipated the potential of his ideas in physics, complaining of “how persistently the mathematical physicist disregards the advantages afforded him in many cases by only a moderate cultivation of the projective view”. By that time, it was already common to think of physical systems through the perspective of the calculus of variation, deriving the differential equations governing such systems from the “least action principle”, i.e. as the minimiser of some functional (action). In a paper published in 1918, Emmy Noether showed that every (differentiable) symmetry of the action of a physical system has a corresponding conservation law. This, by all means, was a stunning result: beforehand, meticulous experimental observation was required to discover fundamental laws such as the conservation of energy, and even then, it was an empirical result not coming from anywhere. For historical notes, see C. Quigg, Colloquium: A Century of Noether’s Theorem (2019), arXiv:1902.01989.
[4] P. W. Anderson, More is different (1972), Science 177(4047):393–396.
[5] M. M. Bronstein et al. Geometric deep learning: going beyond Euclidean data (2017), IEEE Signal Processing Magazine 34(4):18–42 attempted to unify learning on grids, graphs, and manifolds from the spectral analysis perspective. The term “geometric deep learning” was actually coined earlier, in Michael’s ERC grant proposal.
[6] There are multiple versions of the Universal Approximation theorem. It is usually credited to G. Cybenko, Approximation by superpositions of a sigmoidal function (1989) Mathematics of Control, Signals, and Systems 2(4):303–314 and K. Hornik, Approximation capabilities of multilayer feedforward networks (1991), Neural Networks 4(2):251–257.
[7] The remedy for this problem in computer vision came from classical works in neuroscience by Hubel and Wiesel, the winners of the Nobel prize in medicine for the study of the visual cortex. They showed that brain neurons are organised into local receptive fields, which served as an inspiration for a new class of neural architectures with local shared weights, first the Neocognitron in K. Fukushima, A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position (1980), Biological Cybernetics 36(4):193–202, and then the Convolutional Neural Networks, the seminar work of Y. LeCun et al., Gradient-based learning applied to document recognition (1998), Proc. IEEE 86(11):2278–2324, where weight sharing across the image effectively solved the curse of dimensionality.
[8] Note that a group is defined as an abstract object, without saying what the group elements are (e.g. transformations of some domain), only how they compose. Hence, very different kinds of objects may have the same symmetry group.
[9] These results can be generalised for the case of approximately invariant and equivariant functions, see e.g. J. Bruna and S. Mallat, Invariant scattering convolution networks (2013), Trans. PAMI 35(8):1872–1886.
[10] Scale separation is a powerful principle exploited in physics, e.g. in the Fast Multipole Method (FMM), a numerical technique originally developed to speed up the calculation of long-range forces in n-body problems. FMM groups sources that lie close together and treats them as a single source.
[11] M. Zaheer et al., Deep Sets (2017), NIPS. In the computer graphics community, a similar architecture was proposed in C. R. Qi et al., PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation (2017), CVPR.
[12] A. Vaswani et al., Attention is all you need (2017), NIPS, introduced the now popular Transformer architecture. It can be considered as a graph neural network with a complete graph.
[13] C. Tallec and Y. Ollivier, Can recurrent neural networks warp time? (2018), arXiv:1804.11188.
[14] J. Masci et al., Geodesic convolutional neural networks on Riemannian manifolds (2015), arXiv:1501.06297 was the first convolutional-like neural network architecture with filters applied in local coordinate charts on meshes. It is a particular case of T. Cohen et al., Gauge Equivariant Convolutional Networks and the Icosahedral CNN (2019), arXiv:1902.04615.
[15] M. M. Bronstein, J. Bruna, T. Cohen, and P. Veličković, Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges (2021)
[16] S.-l. Amari, Feature spaces which admit and detect invariant signal transformations (1978), Joint Conf. Pattern Recognition. Amari is also famous as the pioneer of the field of information geometry, which studies statistical manifolds of probability distributions using tools of differential geometry.
[17] R. Lenz, Group theoretical methods in image processing (1990), Springer.
[18] M. Minsky and S. A Papert. Perceptrons: An introduction to computational geometry (1987), MIT Press. This is the second edition of the (in)famous book blamed for the first “AI winter”, which includes additional results and responds to some of the criticisms of the earlier 1969 version.
[19] T. J. Sejnowski, P. K. Kienker, and G. E. Hinton, Learning symmetry groups with hidden units: Beyond the perceptron (1986), Physica D:Nonlinear Phenomena 22(1–3):260–275
[20] J. Shawe-Taylor, Building symmetries into feedforward networks (1989), ICANN. The first work that can be credited with taking a representation-theoretical view on invariant and equivariant neural networks is J. Wood and J. Shawe-Taylor, Representation theory and invariant neural networks (1996), Discrete Applied Mathematics 69(1–2):33–60.
作者:Michael Bronstein
原文地址:https://towardsdatascience.com/geometric-foundations-of-deep-learning-94cdd45b451d
deephub翻译组