
spark启动与使用
如果想要启动或者使用spark
需要先执行
zk-startall.sh
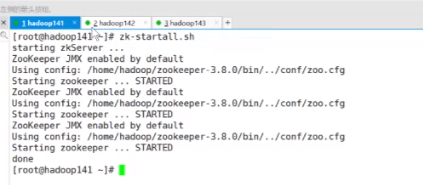
jps
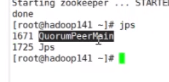
可以查看到zookeeper的进程
hadoop142、143不需要进行任何操作,已经被141启动了
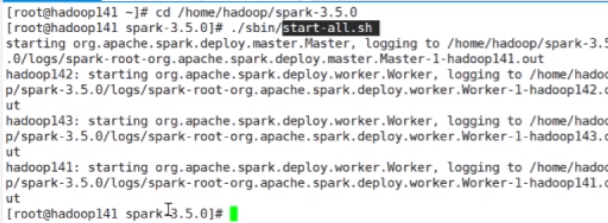
start-all.sh
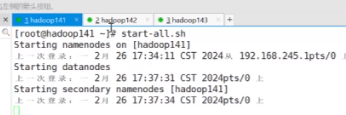
启动集群
结果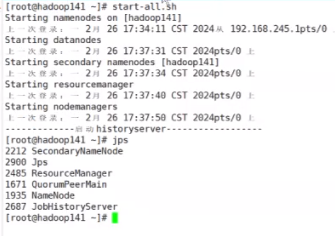
切换路径到spark(根据你自己的路径来)
cd/home/hadoop/spark-3.5.0

./sbin/start-all.sh
在jps查看进程,出现worker说明集群已经启动了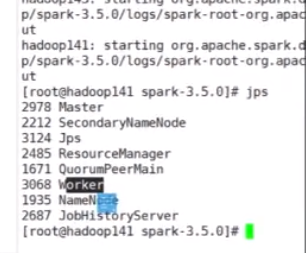
出现worker的进程代表集群已经启动,可以通过访问http://hadoop141:8989/来查看界面
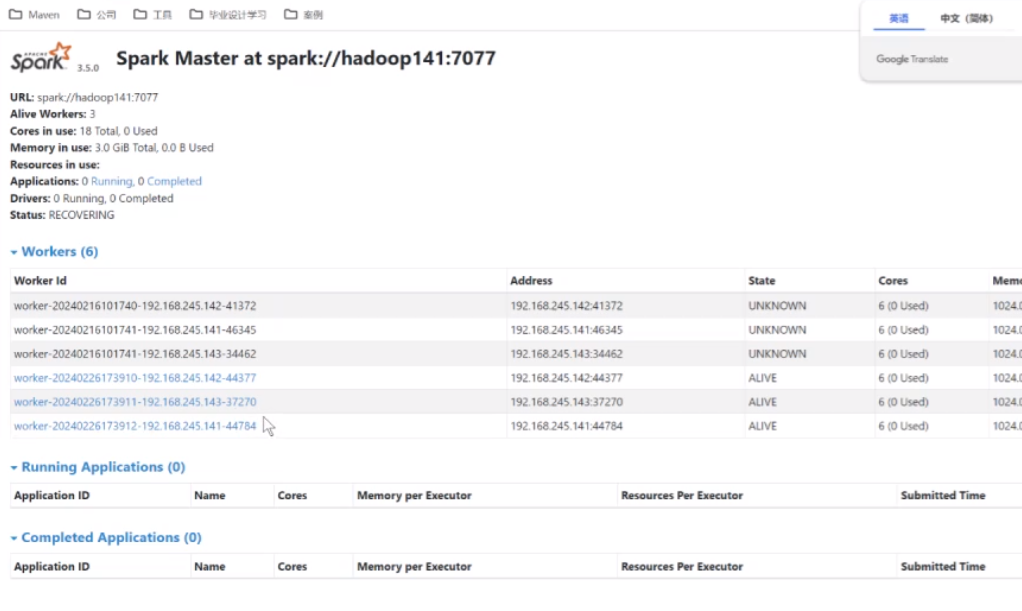
只要能进入这个页面显示出后面三个来就没问题了,启动完成后就可以通过Standalone模式提交任务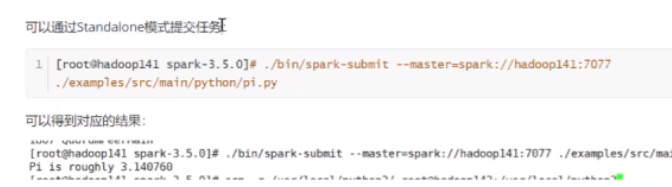
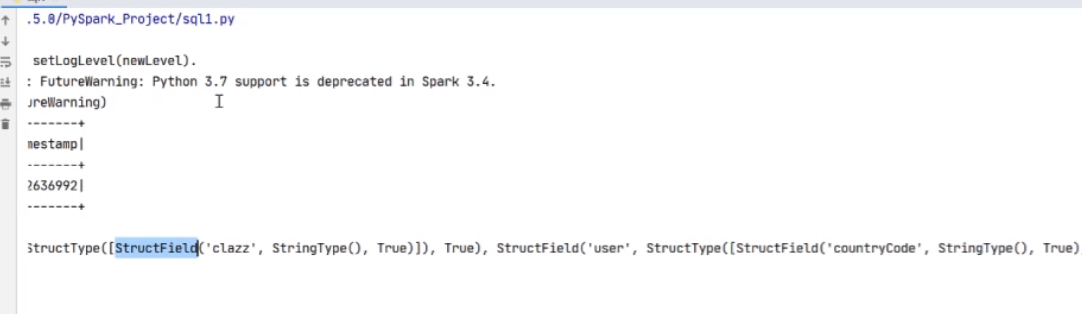
[root@hadoop141 spark-3.5.0]# ./bin/spark-submit --master=spark://hadoop141:7077 ./examples/src/main/python/pi.py
它的7077指的是这个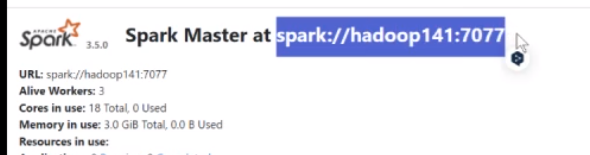
确保结束后就是下面这个目录 单路径,如果不是证明有问题的 需要重修对路径解压,确保是单路径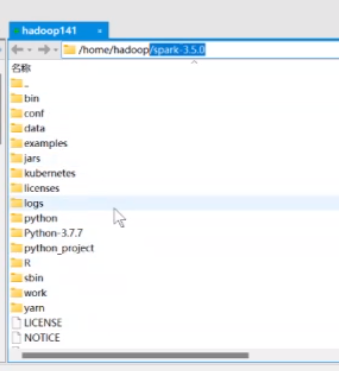
敲回车执行后 出现一个正在跑的程序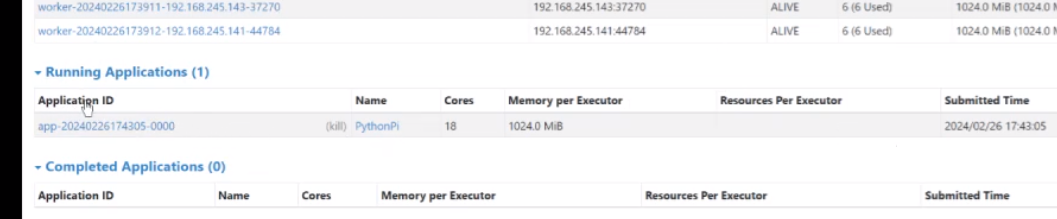
等会 就可以看到跑出结果了
还可以通过yarn模式提交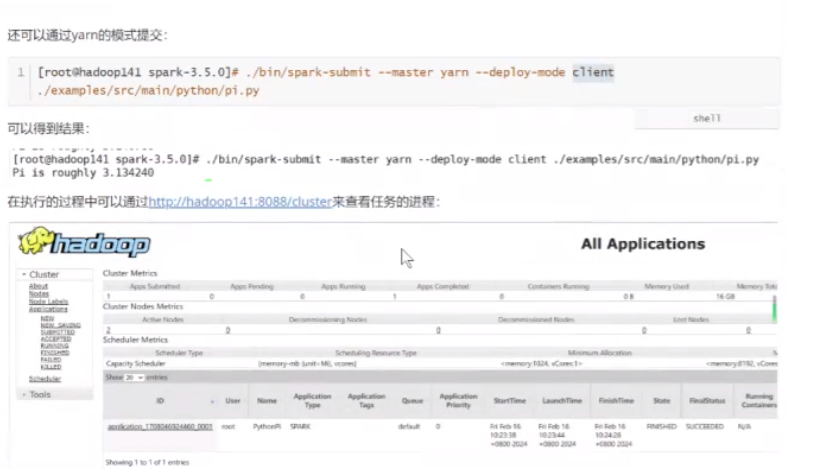
[root@hadoop141 spark-3.5.0]# ./bin/spark-submit --master yarn --deploy-mode client ./examples/src/main/python/pi.py
还有一个是cluster模式
[root@hadoop141 spark-3.5.0]# ./bin/spark-submit --master yarn --deploy-mode cluster ./examples/src/main/python/pi.py
cluster的不太好看 succeeded表示成功了,然后点击ID那个点击进去
会有一个logs(日志),在日志里面就可以查看对应的结果了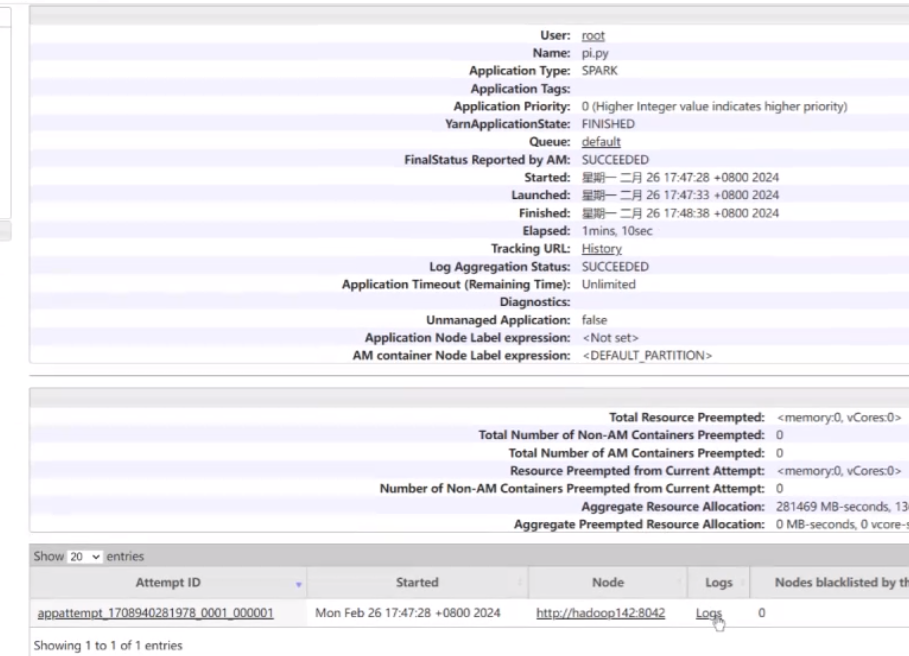
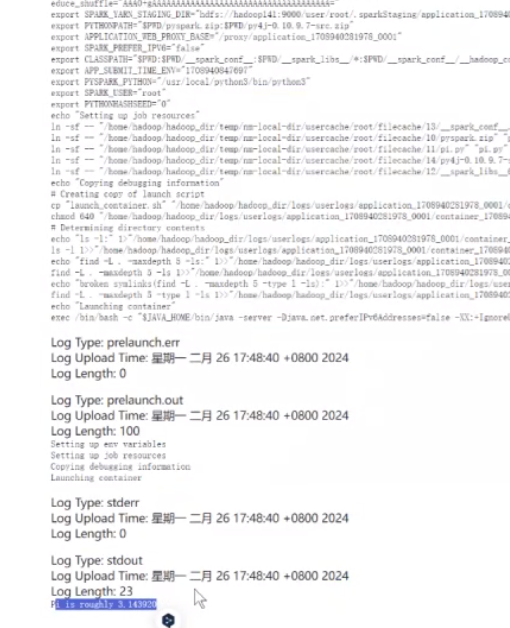
它这个是根据你电脑性能来执行的,执行多次结果都是不会重复的
Anaconda安装以及Jupyter安装
具体操作请跳转到PySpark(超详细笔记)
往下找找 写的很详细
配完以后可以在xshell里去启动
jupyter notebook
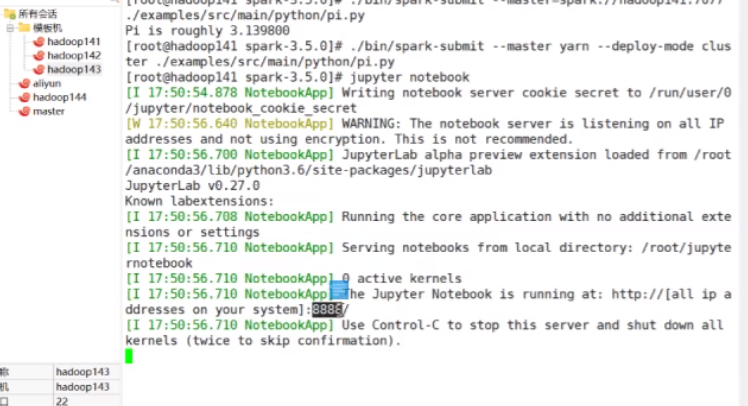
直接访问
hadoop141:8888
密码是之前步骤里设置的
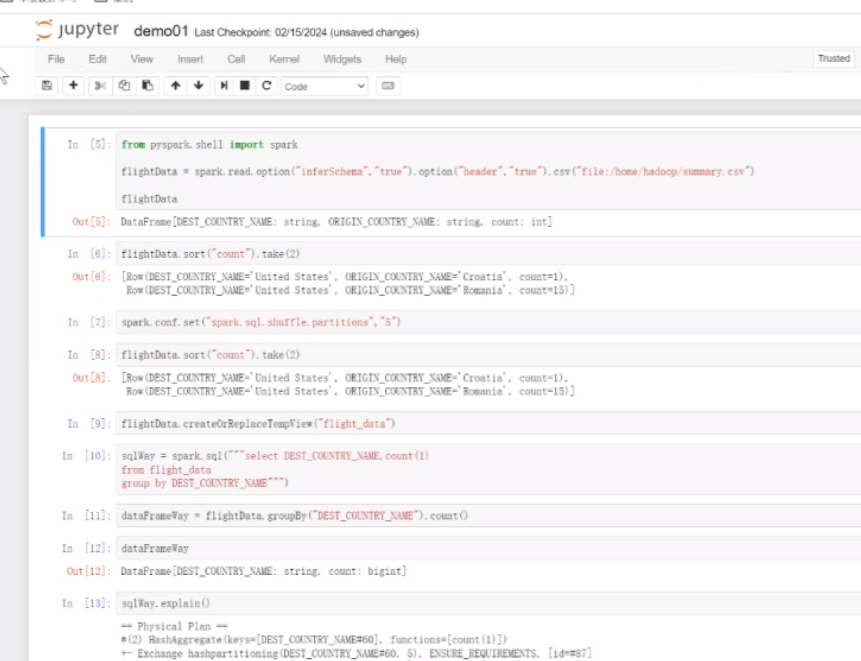
这里面就可以执行Python和pyspark
它的路径保存在设置的路径里
可以使用了

进入这个脚本
./bin/spark-shell
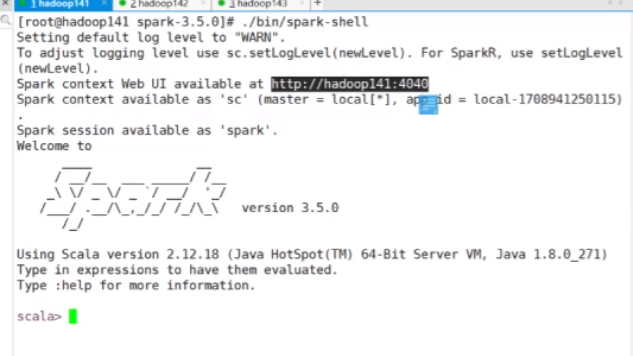
启动以后告诉你可以到4040去访问
后边提交的所有东西都会在这看得到
默认是本地模式执行
也可以别的模式操作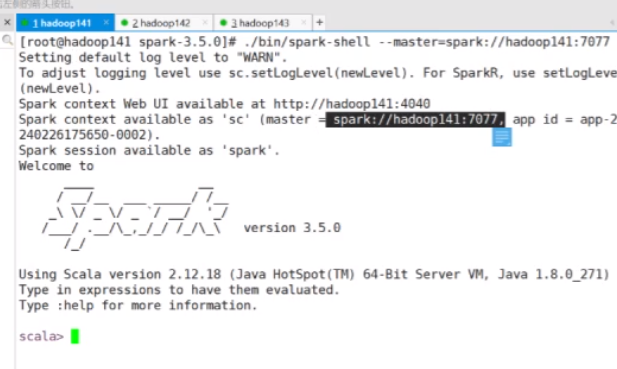
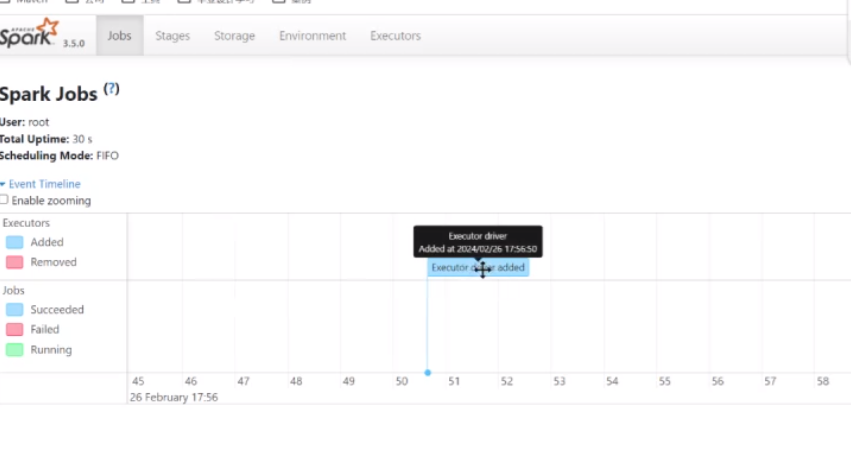
刷新以后再来看会发现有一个编译驱动的一个添加,证明是通过你这个东西来提交的了
spark session的有效值被起了一个别名叫spark 是spark session的一个对象 实例化后的一个对象
试着完成一个案例,通过spark的语法去创建一个0~1000之间的 列名是number的一个列表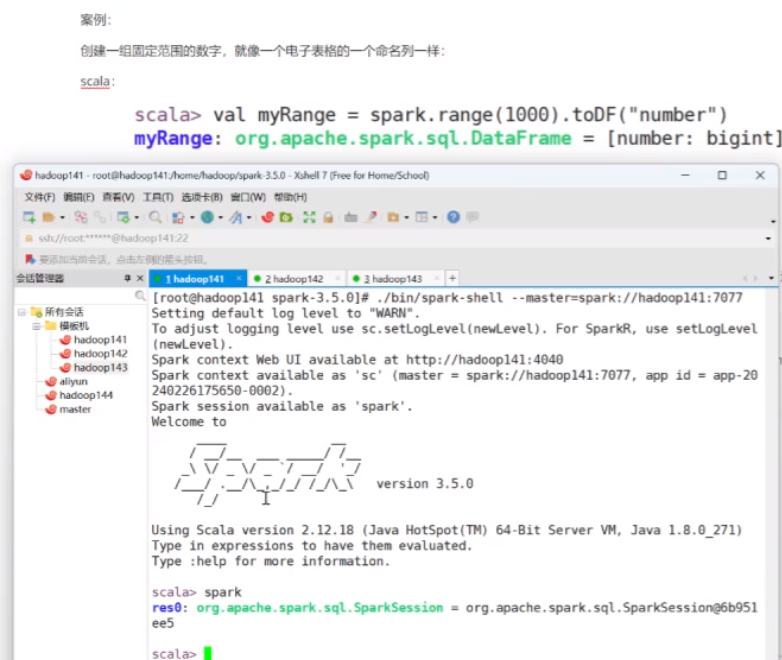
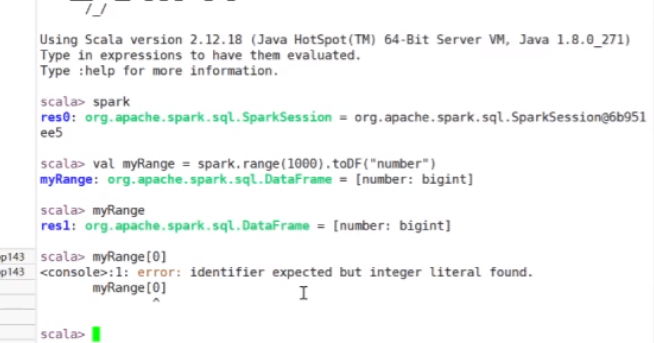
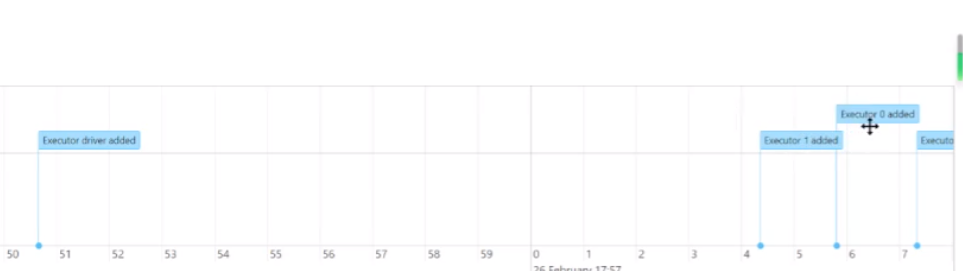
回到上面来会发现有添加
然后dateframe 它是二维数组 尝试案例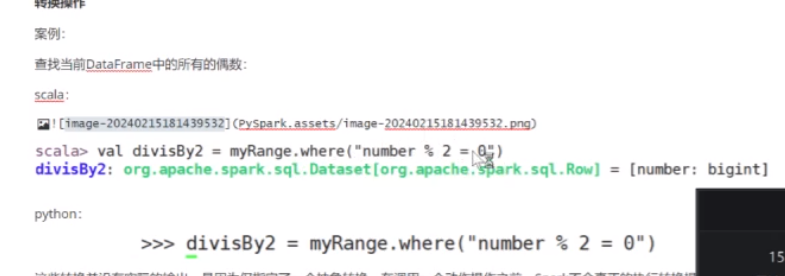

出现stage已经在计算了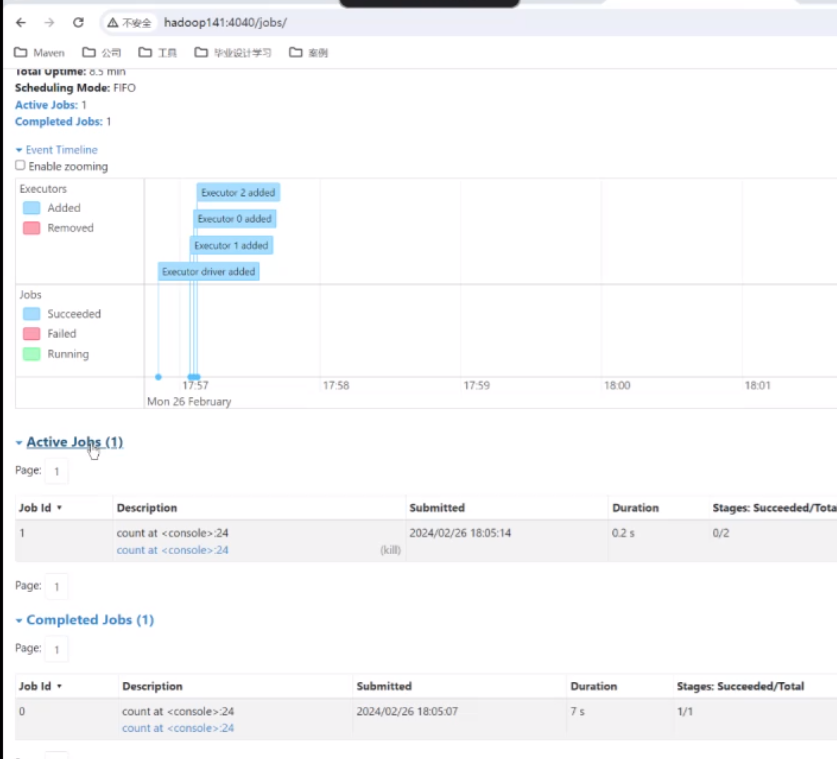
刷新可以看到正在运行的job
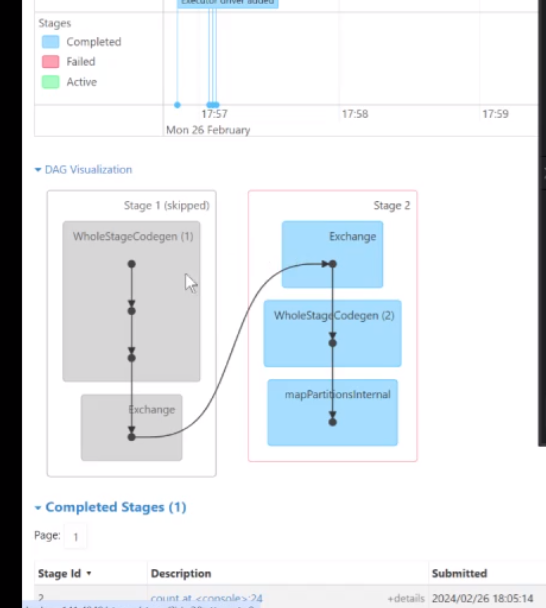
比如说在这个有向无环图里面 第一部是一个整体的一个构建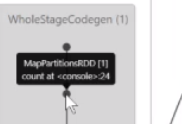
然后进行了一个统计计算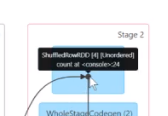
然后来到这个里面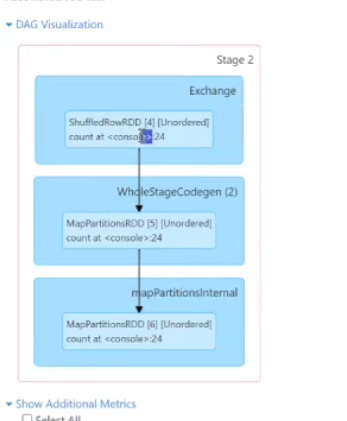
首先第一步是切割你的数据,最后两个是不同的Map计算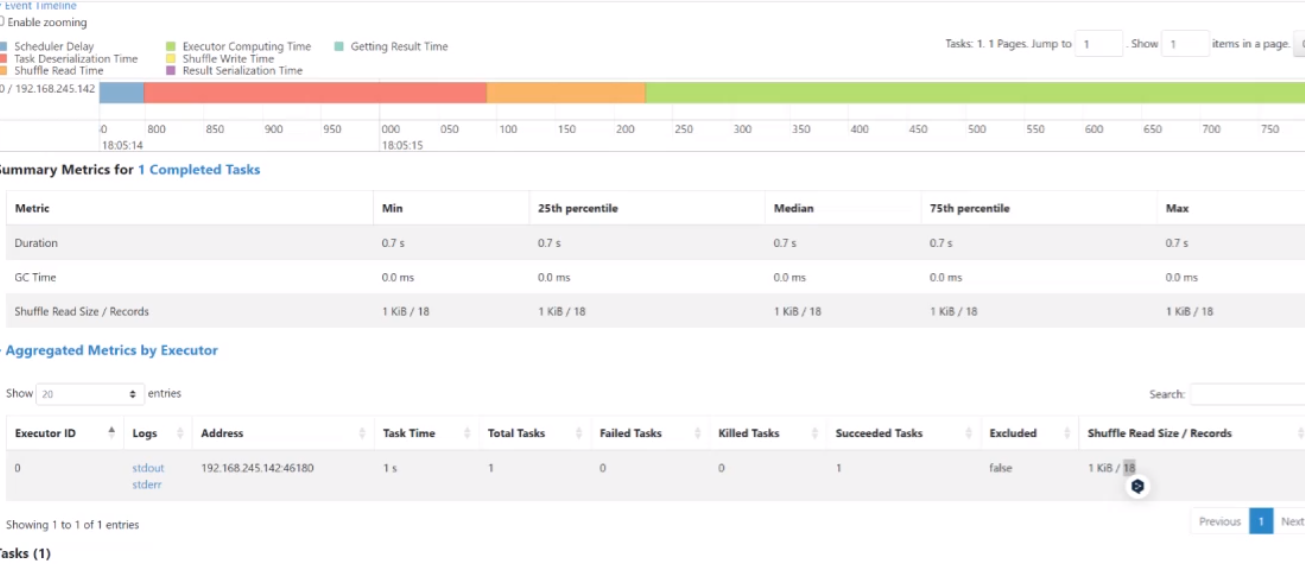
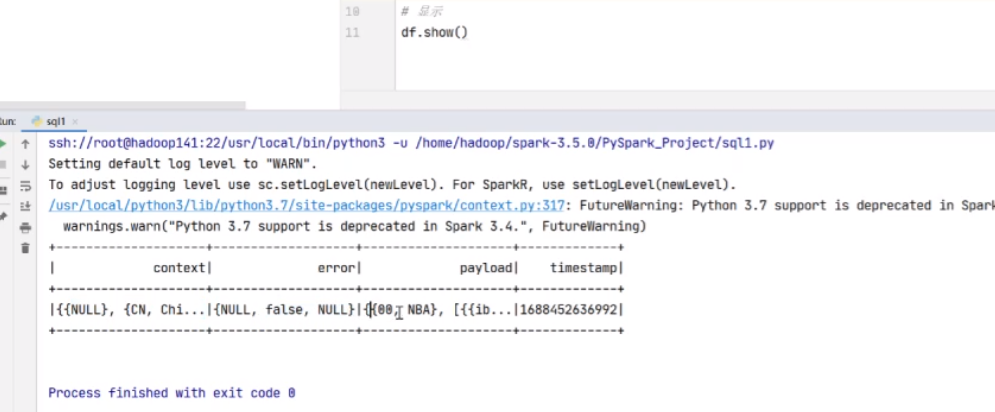
往下翻可以看到记录的执行结果(18条)
这就是spark里面最简单的记录总数的一个计算
Pycharm
接下来需要安装Pycharm软件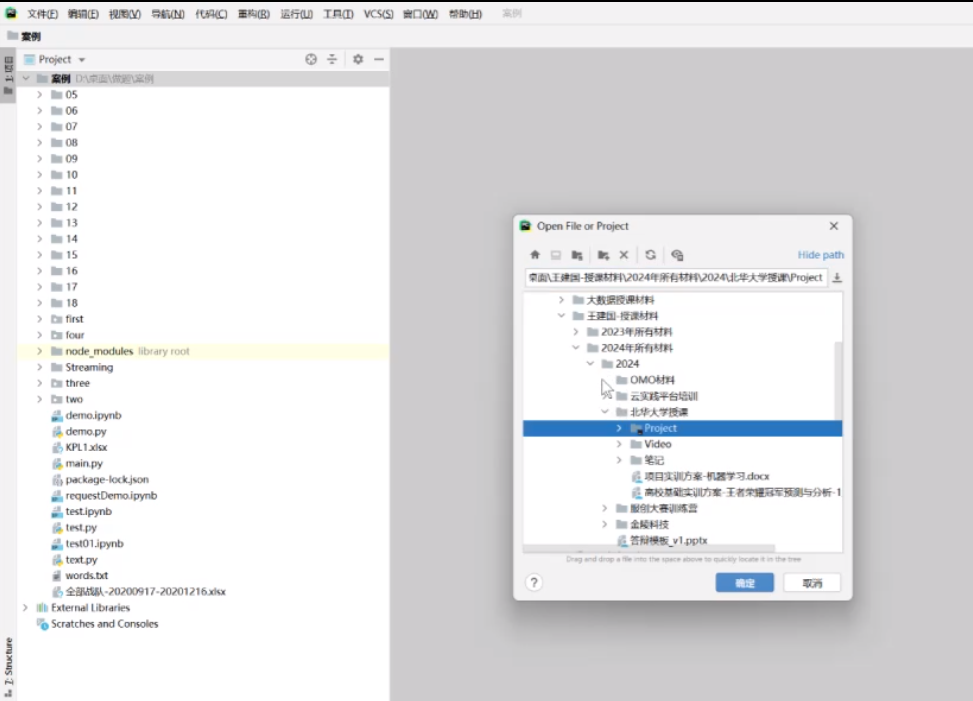
示范 先随便创建个文件夹,然后在里面打开,对于Pycharm来说如果要访问远程集群,必须新建一个解释器
在main里面有一个编辑配置
在+号里面找到这个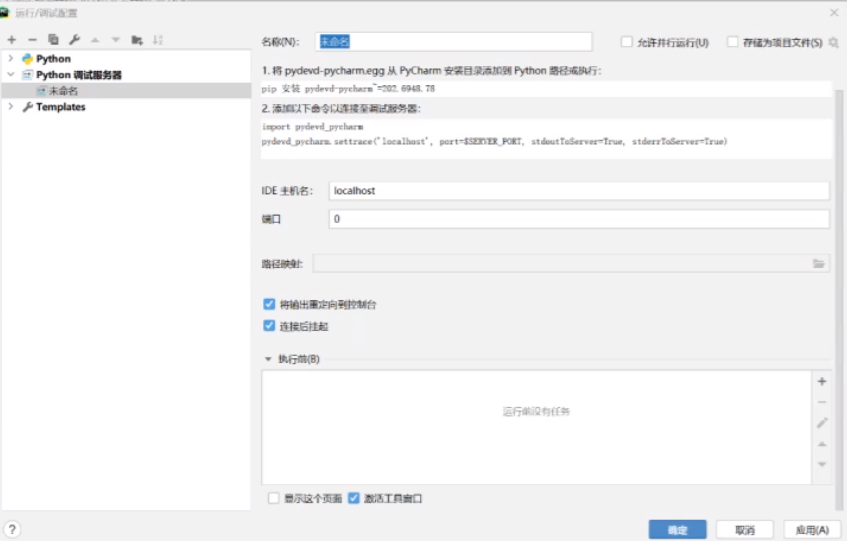
如果没有的话在工具部署配置里面
按照这个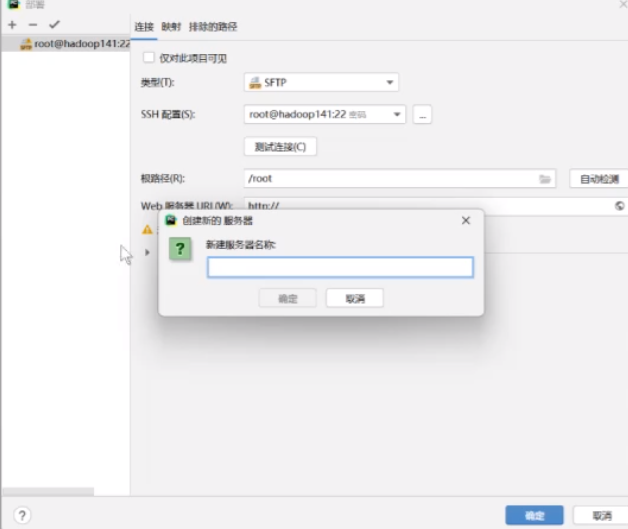

这个要取消掉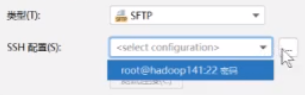
配置没有的话要配置一下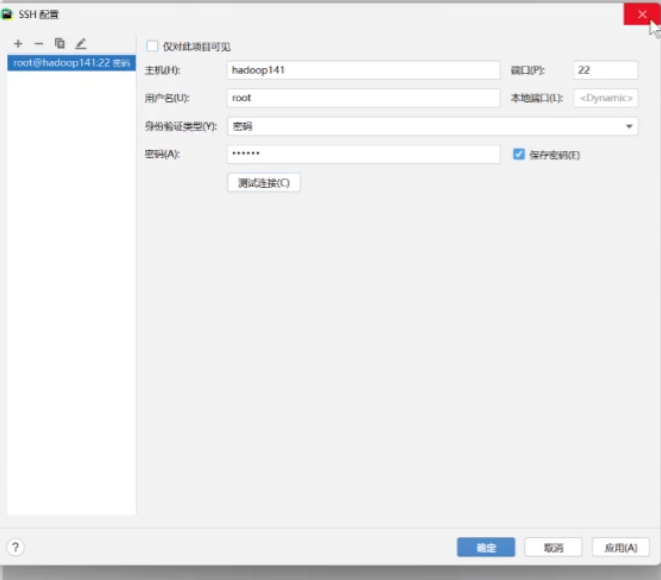
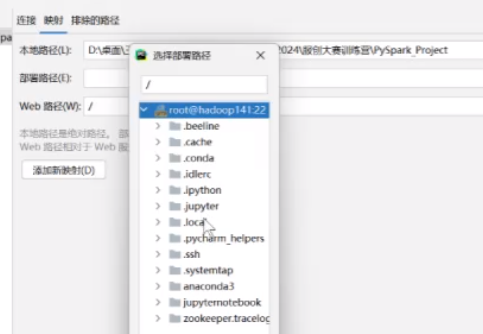
映射里本地路径不要动 部署路径更改
比如映射到这个里面,需要创建对应的文件
然后他就可以自动的映射了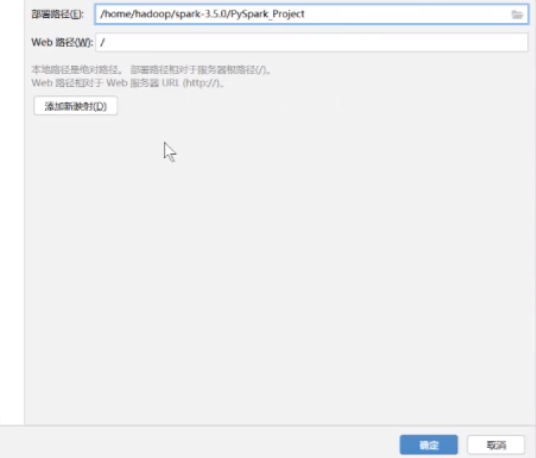
web路径就这个不要动 然后就可以了 点击确定
文件设置里找到python解释器
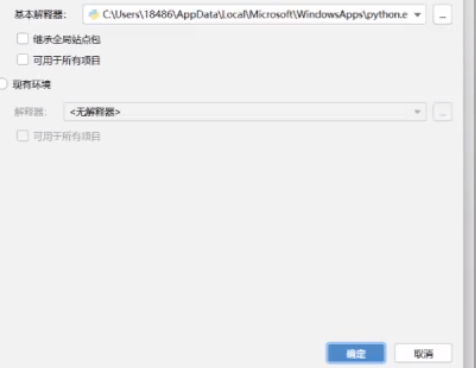
就用刚才配好的那个通过SSH去连接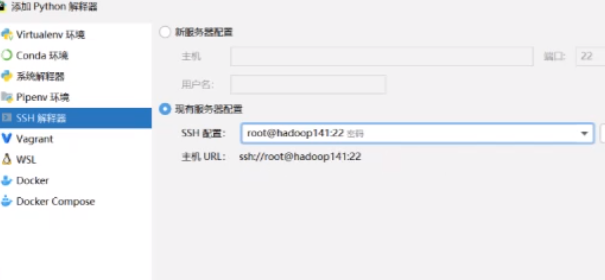
点击下一个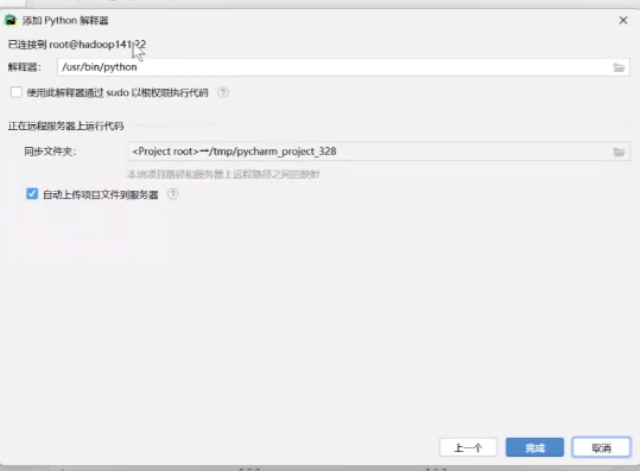
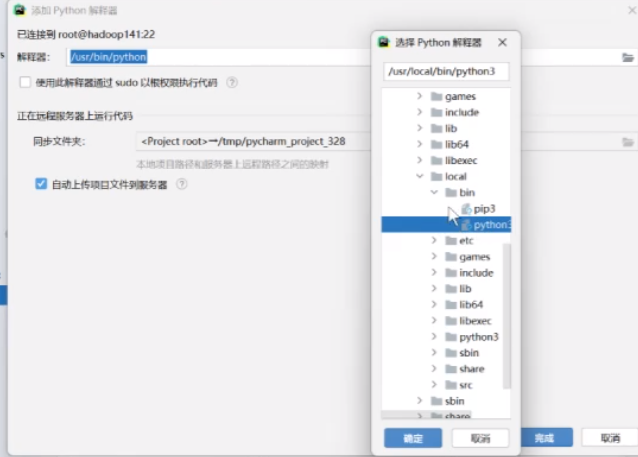
找到python3解释器的路径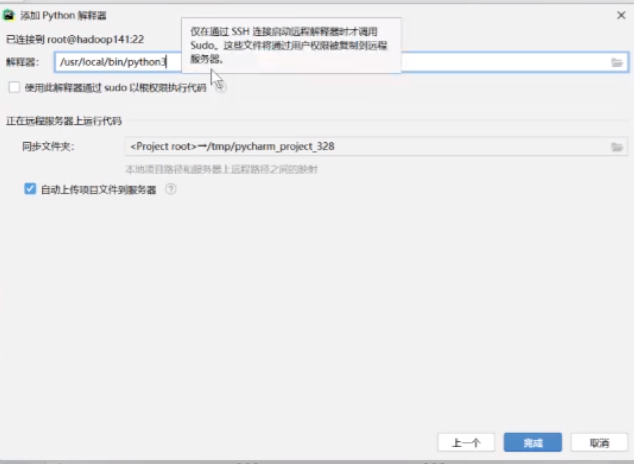
直接点击完成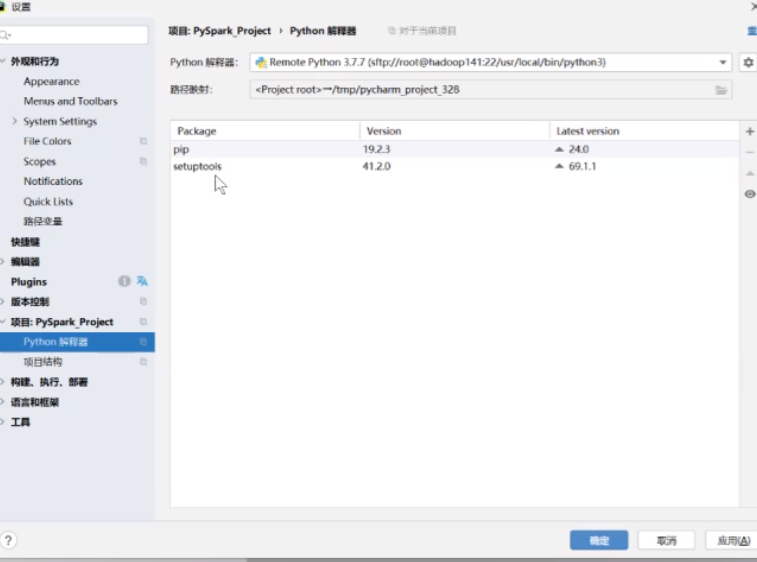
然后就连接上了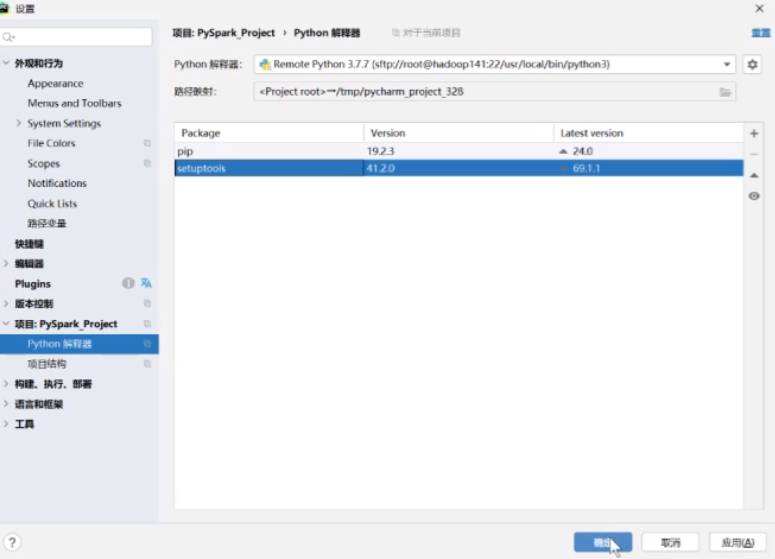
点击确定
他会自动完成上传
前面路径映射错了,可以重新修改
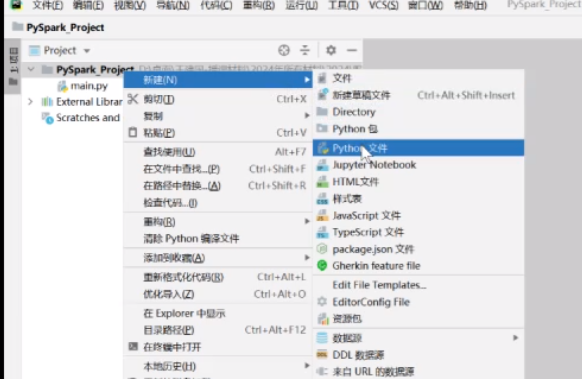
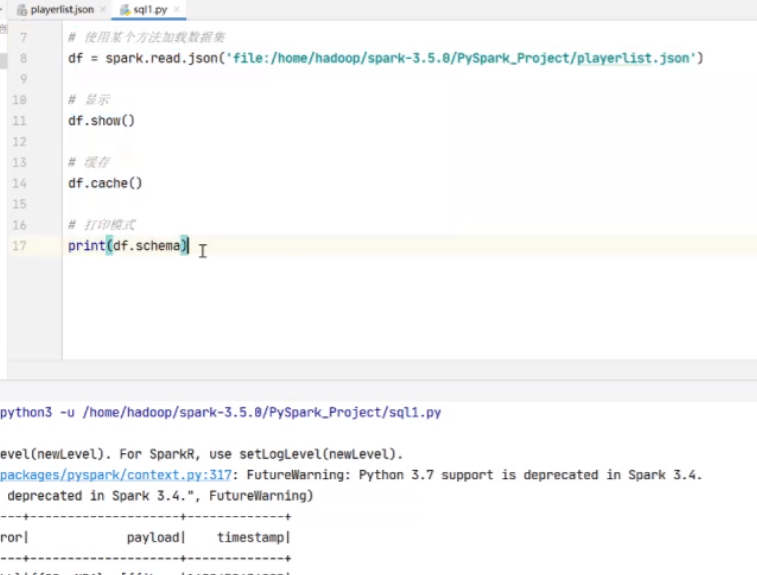
比如说在这里面新建文件wordcount
然后对应路径里会出现
接下来我们所执行的所有代码就相当于在集群里面去执行的
首先我们打包实现一个词频统计
importsys
需要先装包,这个路径下载快一点
pip3 install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple
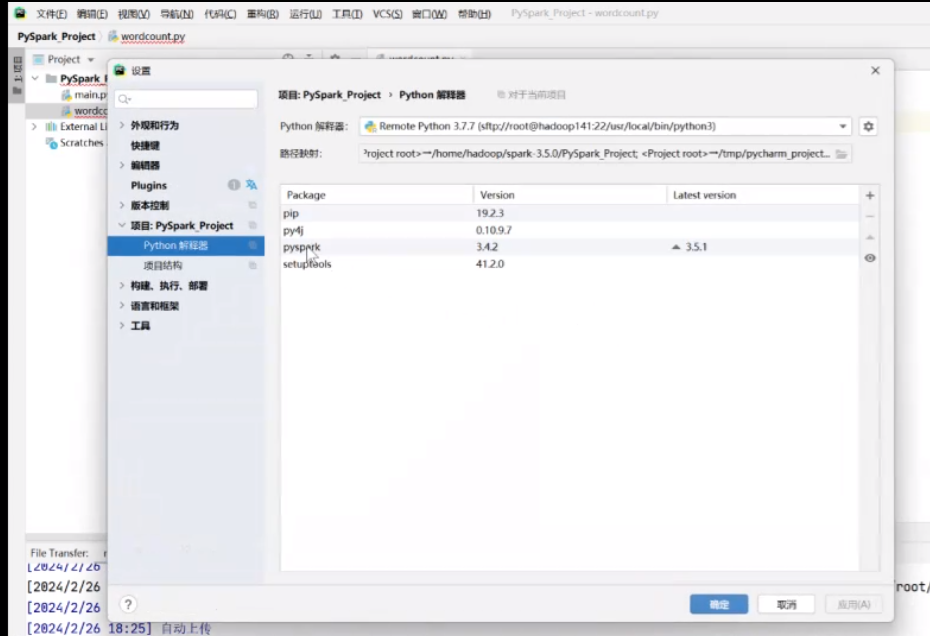
安装好后,就能在这里面看到你安装的pyspark了,然后就可以写程序了
from pyspark.sql importSparkSession

spark = SparkSession.builder.master("local[*]".appName('PycharmJob').getOrCreate()print(spark)
右击运行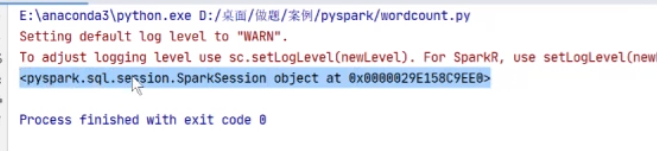
执行出来了
如果不对,可能是解释器映射不对,重新弄
调用方法获取文本路径
words = spark.sparkContext.textFile("/home/hadoop/word.txt")

print(words)

重新加一个file:就可以获取本地文件夹了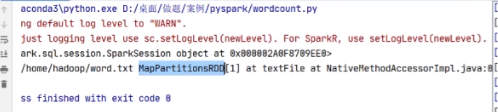
是通过MapPartitionsRDD去走的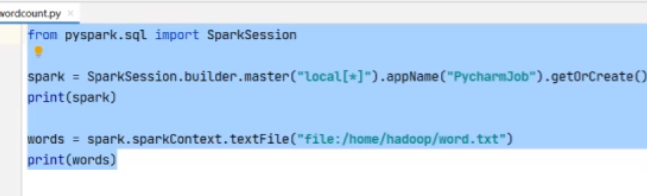
这个可以做词频统计,pycharm进行远程提交
刚才有个问题我们word.txt是没有提前创建的,在这个情况下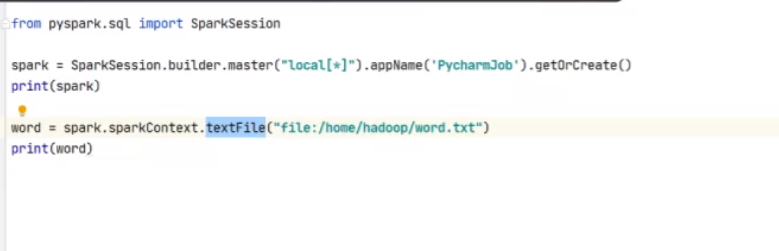

这样是正常输出的,它调用这个方法去寻找文件,当然找不到也没有关系,没涉及到具体的操作和计算,只是一个转换过程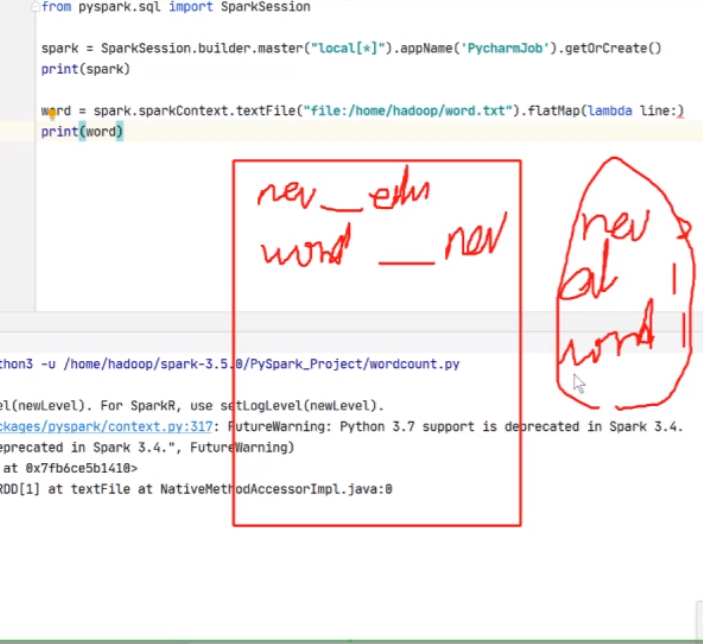
词频统计获取每一行
然后进行切割计算 换行用
相加,结果collect动作打成一个集合

运行结果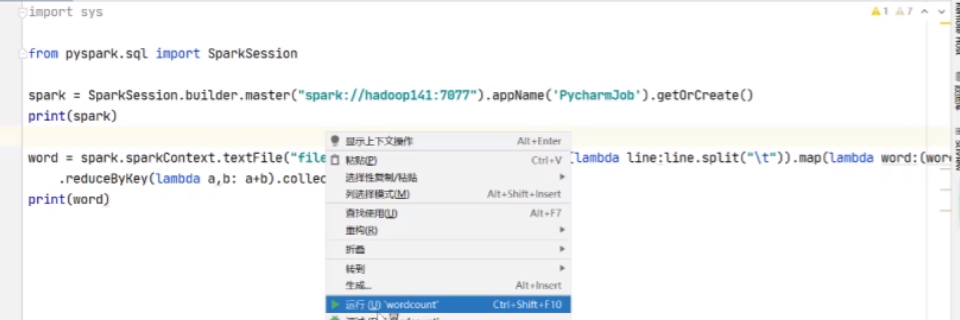
还可以通过hadoop141:7077,用的是远程了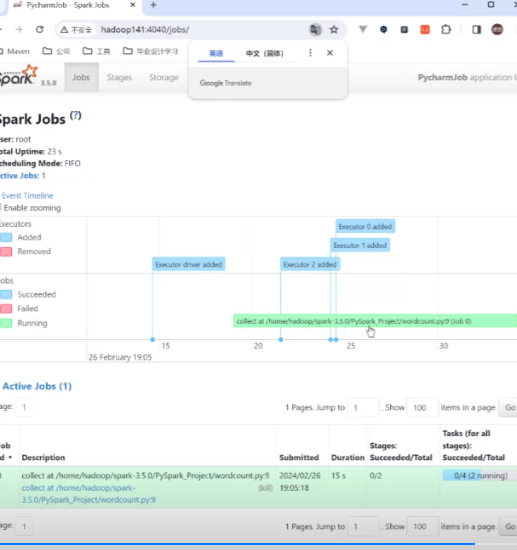
计算结束网页会自动关掉
也可以获取hdfs上路径
词频统计里涉及到的
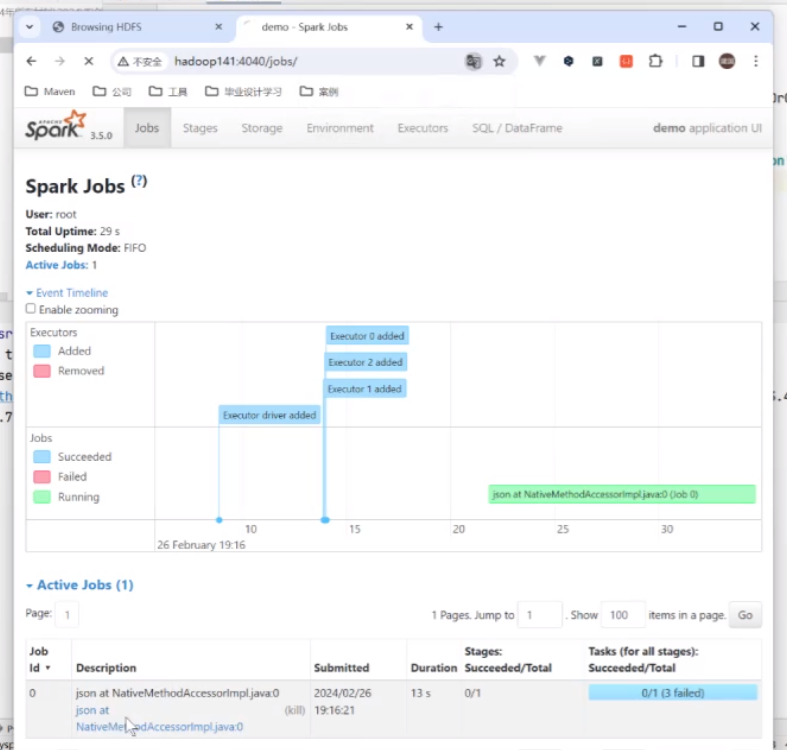
这里就有进程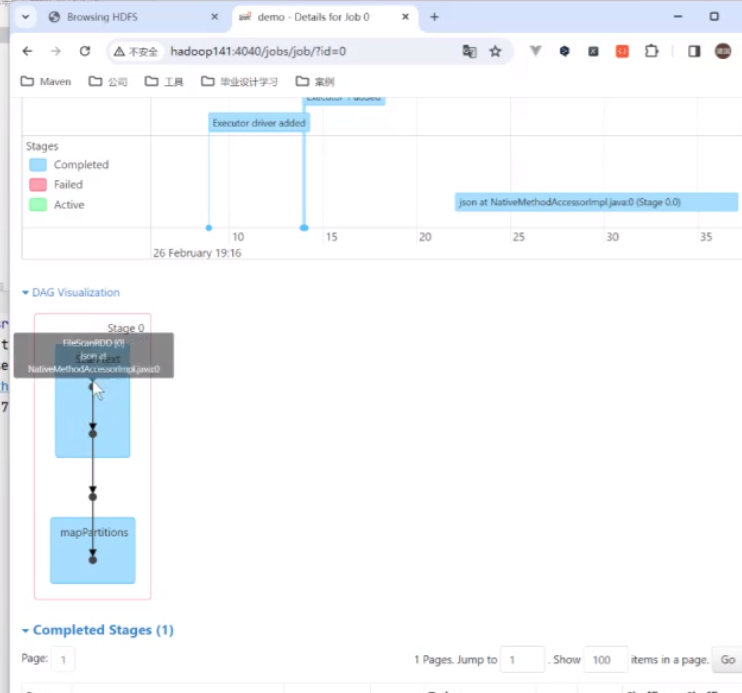

版权归原作者 暗托涅瓦 所有, 如有侵权,请联系我们删除。