
参数设置如下,
--seq_len 是 96
--label_len 是 48
--pred_len 是 96
也就是说,输入是96的,预测96.
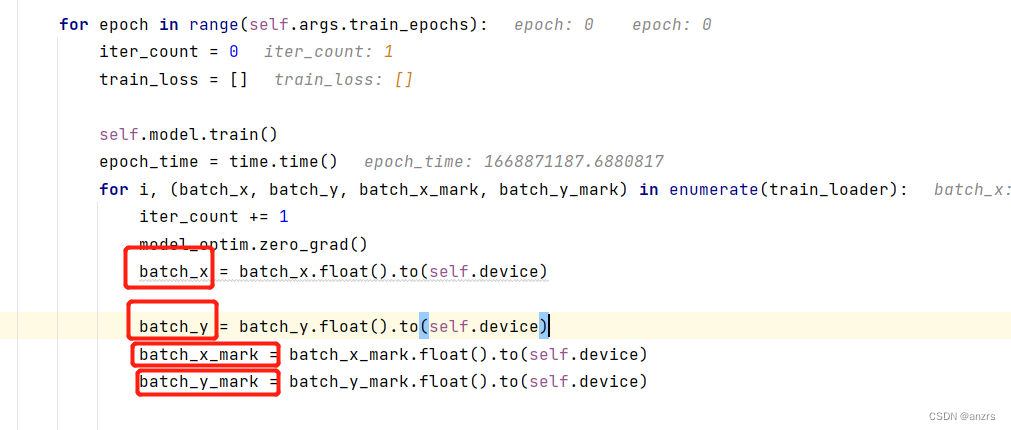
batch_x 是 (1,96,7)的维度的。
batch_x_mark 是(1,96,4)的维度的。
batch_y的维度是(1,144,7)的维度的。
batch_y_mark的维度是(1,144,4)的维度的。

然后,decoder的维度是, (1,96,7)的维度的,全都是0的元素。
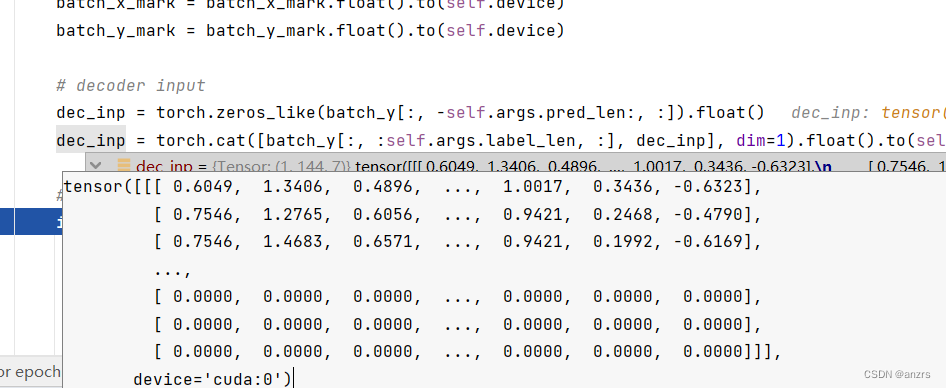
然后变成了(1,144,7)的维度,下面都是(1,96,7)的0元素。
为什么会有这种情况?
来看FEDformer的preliminary:

也就是说encoder的输入的尺寸是1,96,4,也就是输入是96的长度的。
而,decoder的输入的尺寸是输出的尺寸加上输入的一半的尺寸,也就是这些。96/2 + 96 = 144的尺寸的。
也就是,生成了一个和预测长度一样尺寸的东西。全都是0。

然后,他的输入又cat了一个新的东西,

这个新的东西是输入的一半的维度。

然后就进入到了模型里面,
第一步是生成一个mean,这个mean是基于x_enc生成的。
这个mean的意义是什么?
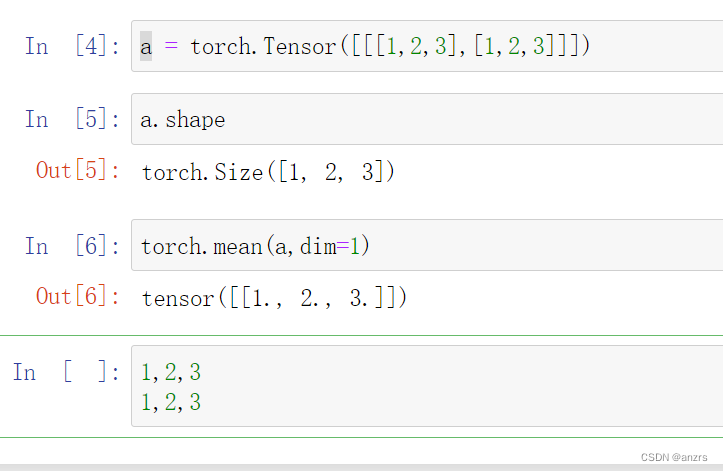
假设一个tensor的维度是(1,2,3),第二个维度是(1,2,3)(1,2,3),在dim=1上求平均,得出来的结果是1,2,3。
那么,在x_enc上求平均的结果就是在,(1,96,7)在96这个维度上求,
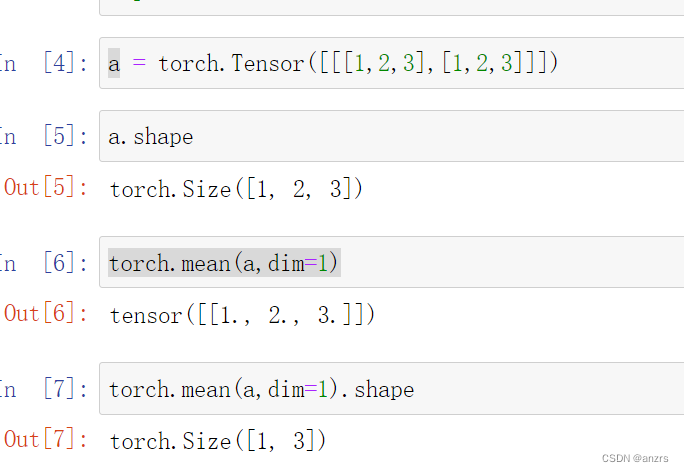
再看看这个维度,如果对于(1,2,3)这个维度的tensor求mean,在2这个维度上求,得出来的结果就是(1,3)的维度的。
那么,类比我们这个输入的向量,他是(1,96,7)的维度的tensor。
那么他的mean,就是(1,7)的维度的。需要repeat96遍。
这个的意义就是,好比输入是这样的
1,2,3,4,5,6,7;
1,2,3,4,5,6,7;
1,2,3,4,5,6,7;
1,2,3,4,5,6,7;
。。。
1,2,3,4,5,6,7;重复96个,也就是输入长度的96长度,对于这个长度每一个feature点都求mean。
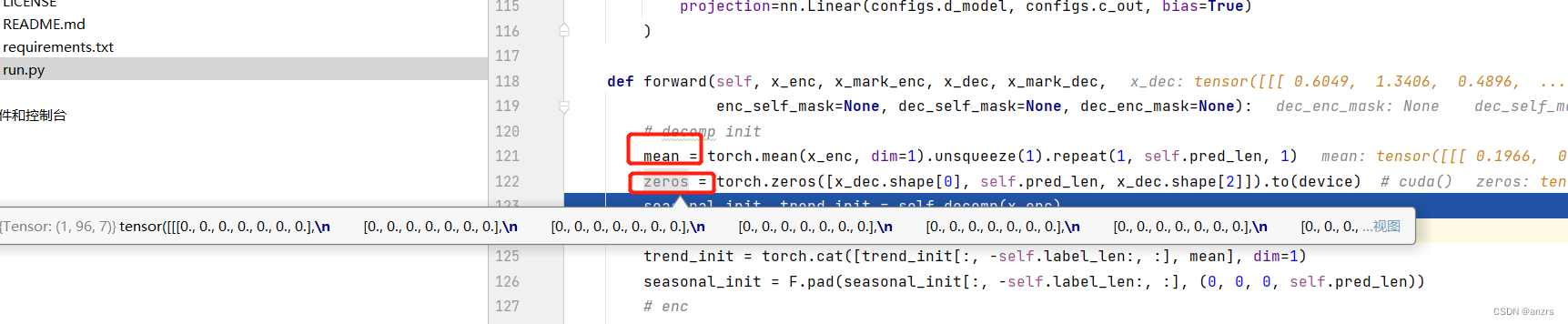
生成了两个tensor,都是(1,96,7)的维度的。

然后把x_enc扔到这个decomp里面能够得到两个东西,这两个东西主要就是创新的需要学习的东西。
我们记住这个x_enc的尺寸,是(1,96,7)的维度。
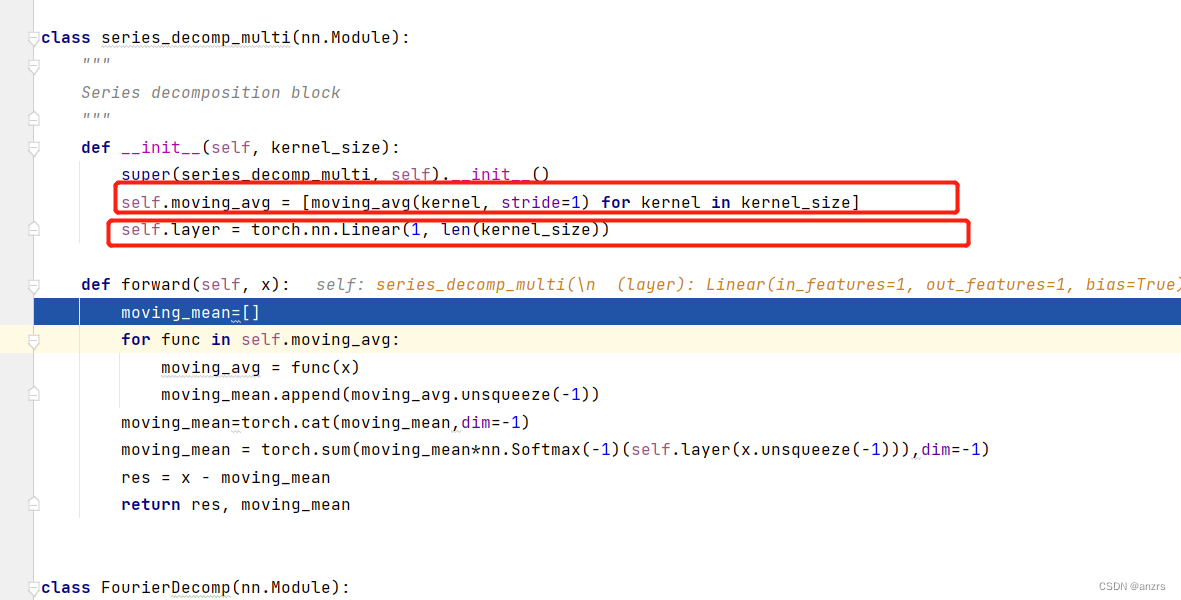
这个series_decomp_multi的里面有两个可学习的东西,一个是一个pooling,是kernel_size是24的大小的,另一个是一个linear,是一个1in,1out的。

这个moving_average看他的注释的意思是说,这个模块的功能是在强调时间序列的趋势。

可以看出,两个红色的东西,是通过x来分离出来的,
一个是(1,11,7)维度的,一个是(1,12,7)维度的。
而cat后的,x的维度是变大了的。
然后再通过avg进行池化。可以看到这个池化所进行的维度是变化了的。很显然这个部分是有操作的。
我们举个例子理解一下,
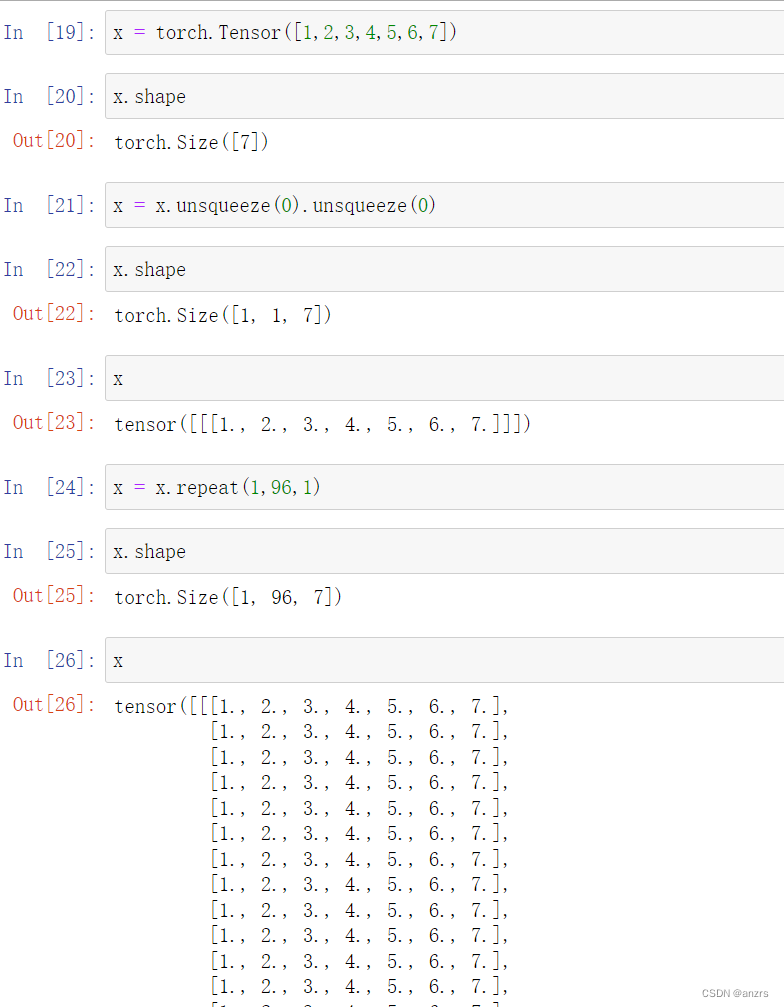
利用unsqueeze这个操作来使得这个,[1,2,3,4,5,6,7]的向量变成一个,(1,96,7)的向量。
然后我们开始下面的实例操作,

floor的意思是,返回一个小于等于这个数字的最大整数。

红色的地方是,也就是把这个x的向量的所有的第二个维度的第一个分量得到
也就是说,如果batch_size = 16的话,那么这里的,这个x的这个操作的维度,
就是(16,1,7)也就是仅仅截取第一个地方的量。
然后,这个会重复后面的这个的次数,

也就是说,他会重复12次,也就是说,这个操作的意思是,把所有batch里面的所有的单个unit的第一个time_stamp,也就是说本来这个序列的输入是
(batchsize,sequence_length,feature_map)的,
然后重复12次,是取这个sequence_length的第一个进行重复了12次,
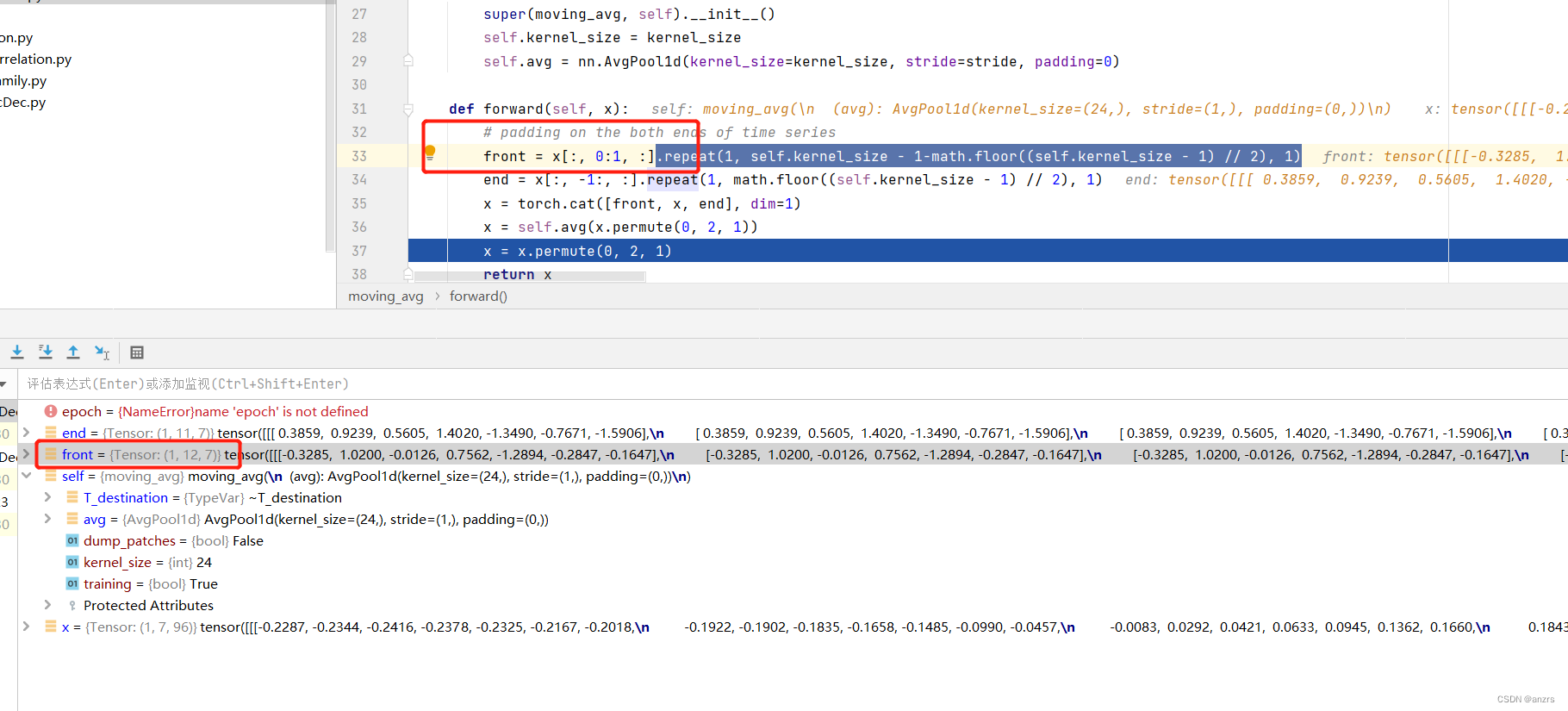
front就是将第一个维度重复这么多次,到最后变成了(1,12,7)的东西。
这个东西是从(1,96,7)里面操作出来的。也就是把(1,96,7)的第一个(1,1,7)重复了12次,然后得到了这个(1,12,7)这个东西。

这个end好像也是类似的操作,我们看一下他是怎么回事。

看下,这个红色部分前面的操作,也是和第一个类似,他是把最后一个序列点取到。

然后,这个x是用x和得到的front和end进行cat,他的维度是(1,119,7)的维度的。
也就是说,加上这个11和12后是这个维度的。也就是说加上23维度的才是这个维度的,也就是本来的x是(1,96,7)的维度的,前面拼接上front,后面拼接上end后,变成了(1,119,7)这个维度的了。
然后接下来就是会对这个得到的新的拼接向量做pooling,来看看他是怎么pooling的。
这个pooling的详细的参数是,kernel_size是24,步长是1。
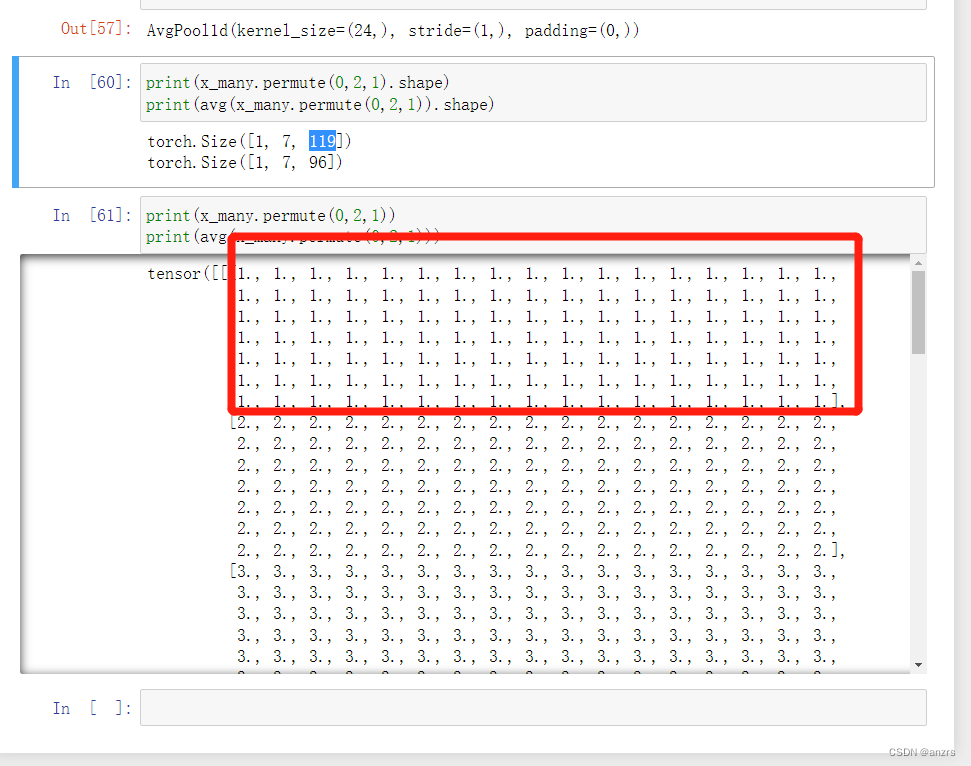
然后,在这个时间戳上做pooling,这个是有意义的。

因为一开始定义的一个戳就是1234567,也就是一个时间点上他拓展为7个单位的feature。
而,现在permute后, 是在这个1,2,3,4,5,6,7上做pooling,也就是说,是对于119这个时间戳的单位来说做pooling。因为这个pooling的大小是24,所以,119-96是一个pooling,97,98,99,100,101,...,119这是23个,所以第一个pooling的单位是96-119这个范围做pooling。

这一步的意思并不是很懂,他的kernel的大小是24,前后都要填充上,这个操作并不是特别能理解。
1-12,1-12,也就是 第一个stride是在做这个pooling,
2-12,1-13,第二个stride是在做这个pooling,
3-12,1-14,第三个stride是在做这个pooling,
4-12,1-15,第四个stride是在做这个pooling。
我们对比一下不加cat的做法,
1-24,
2-25,
3-26,
4-27.
很明显的一个区别就是,上述的这个做法,1这个东西,也就是1这个序列点,在pooling的时候存在了很久,很明显会存在12步,因为他前面有12个点stride是1。利用这种做法,所以每一个点都会在序列中存在很长一段时间。这个做法应该就是顾虑这个问题。
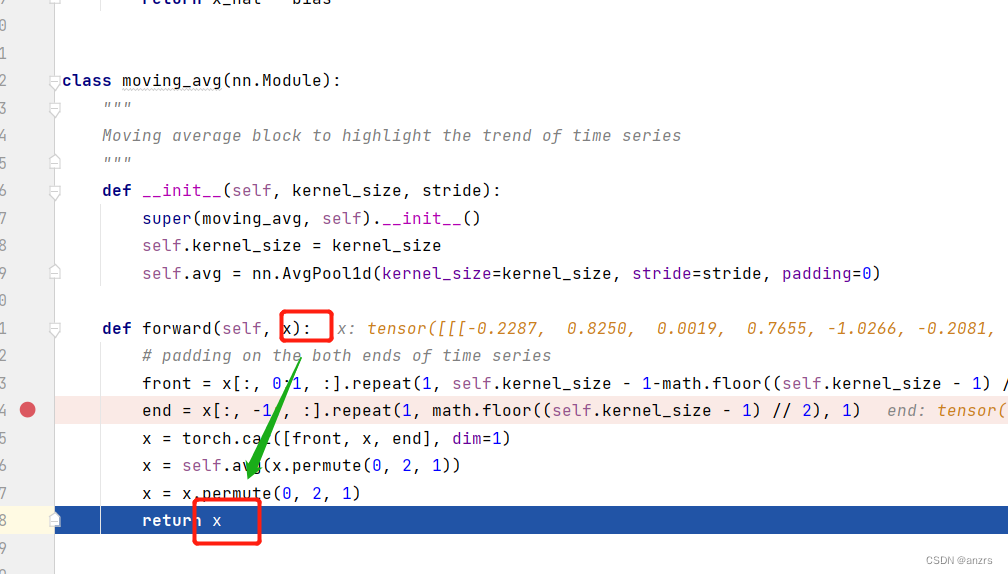
然后我们来回过头来看这个moving_avg是把x进入后加了一个前一个后,然后做池化,加前和后的目的是为了使得每个序列点都能够充分地做pooling。
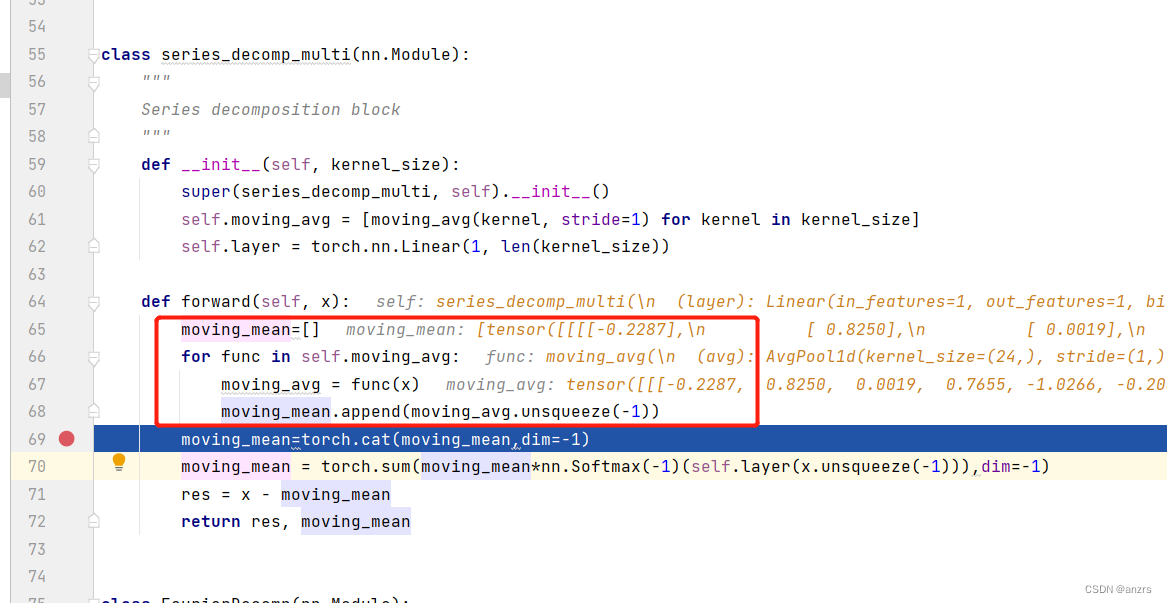
到了上面这一步,这个moving_mean这个列表的意思是存取这通过上面的pooling得到的新的x。
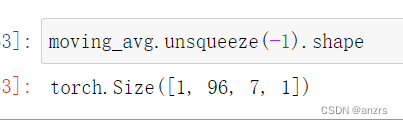
这个unsqueeze后的moving_avg的维度是上面这样的。也就是说这个列表里面存的都是这个样子的。

我们测试一下这个操作,cat后,这个里面的东西是这个维度的,那么如果我们里面不止有一个呢?他会是什么样的效果呢?

我们发现,他里面的东西就有两个了。
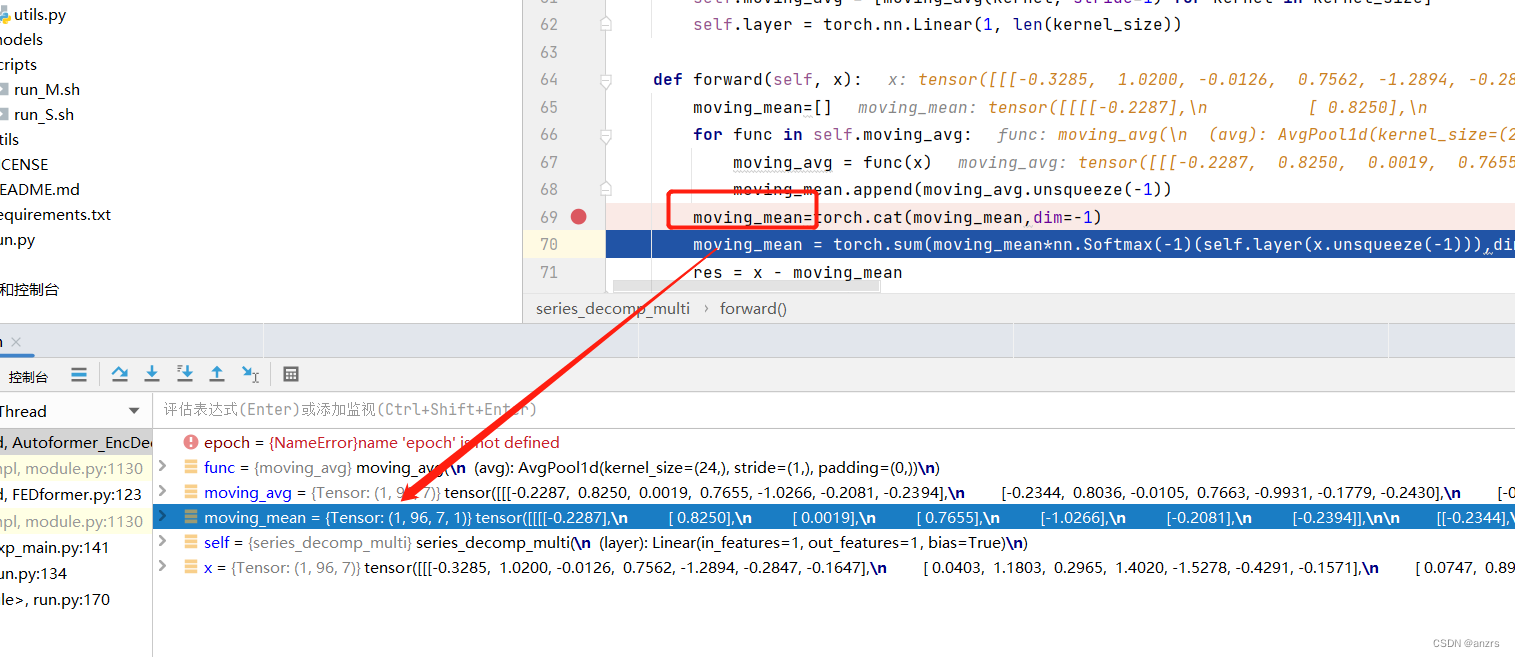
我们发现,他是这个维度的。

然后经过绿色的这个操作,里面的东西又变成恶了(1,96,7)这个维度的了。
我们来看看绿色的这个东西是有什么效果,
 最外面的操作是在dim-1上对mean,进行求和。
最外面的操作是在dim-1上对mean,进行求和。

x的维度是(1,96,7)。
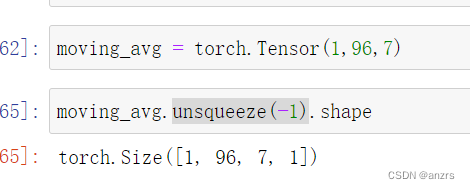
然后,x.unsqueeze(-1),后的维度就是(1,96,7,1)这个维度。

这里可以看到,通过layer后的这个tensor,就是对他每一个点进行了一个learning。
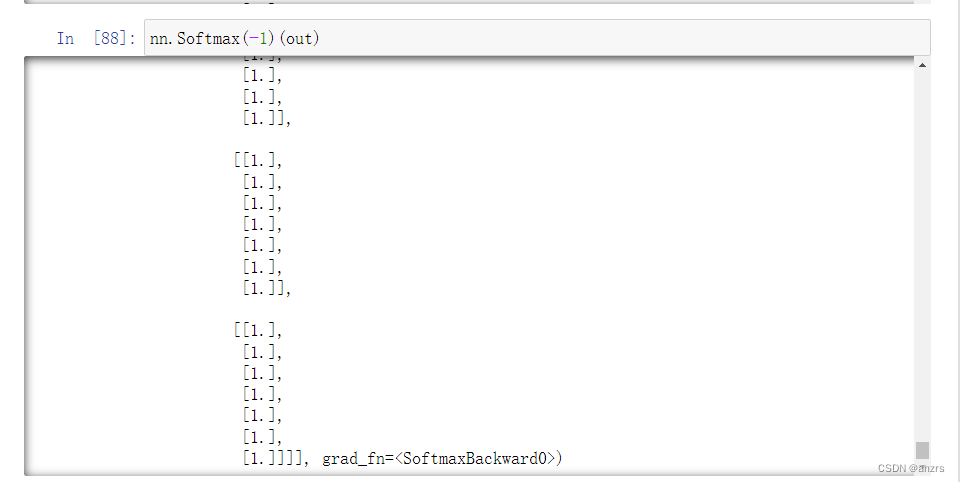
经过softmax后的是这个,然后再乘moving_mean。
总结一下,这个整体的操作如下。
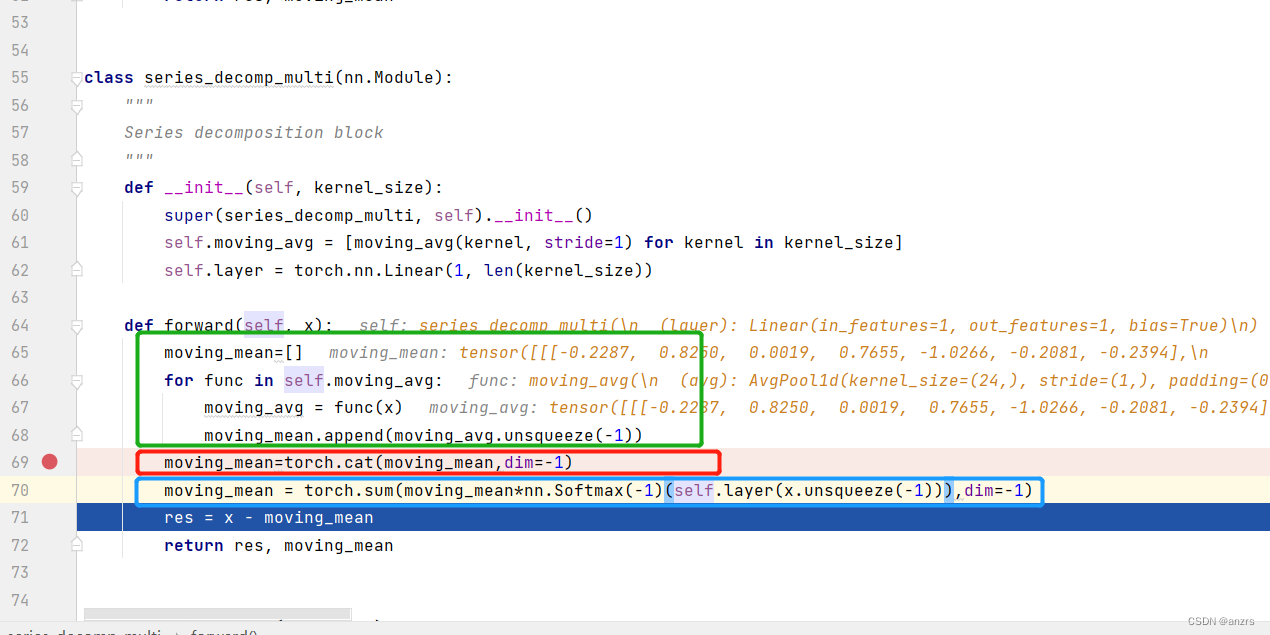
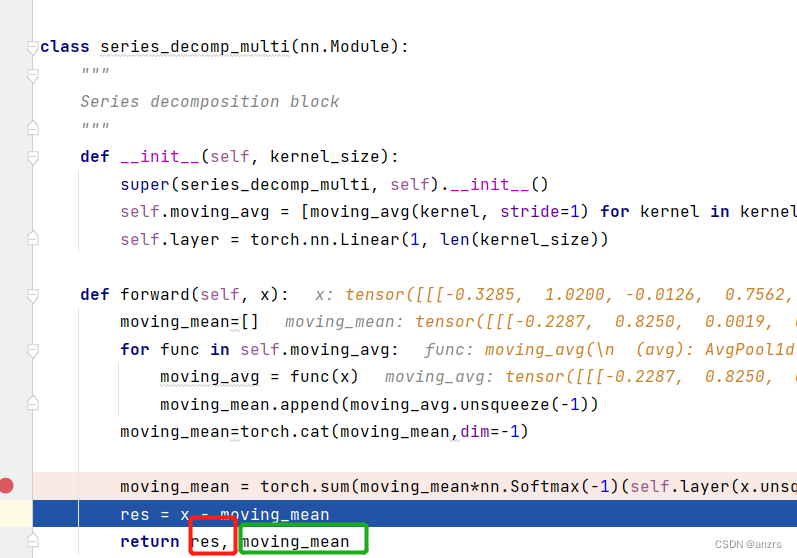
然后到最后返回了两个东西,
一个是res,也就是利用x-moving_mean。
另一个是moving_mean,也就是利用对x的pooling所得到的东西。
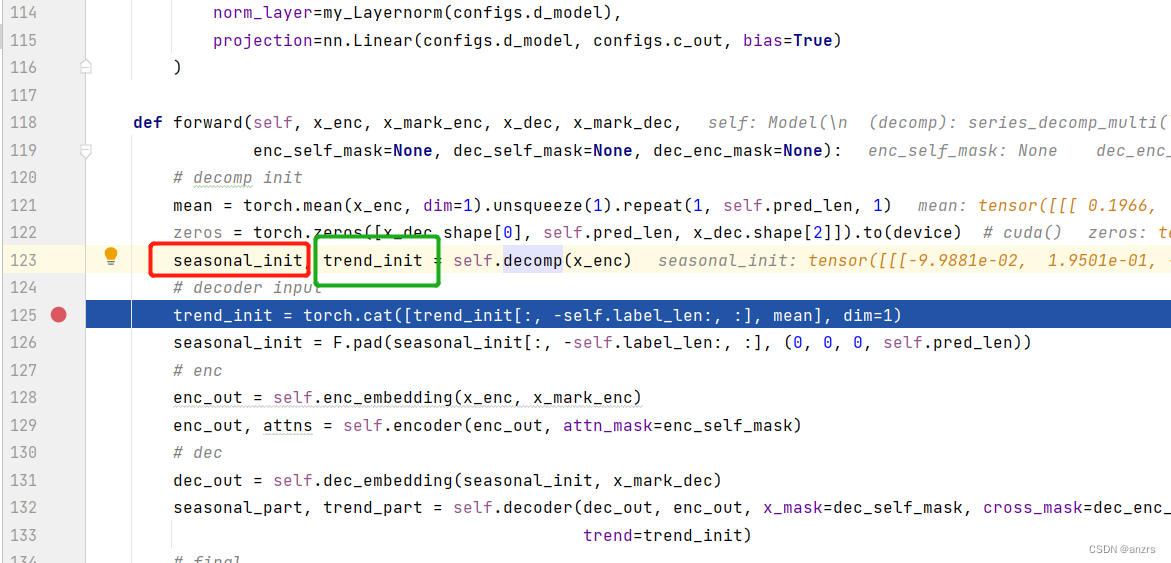 然后到了最外面的模型的层面,
然后到了最外面的模型的层面,
一个是seasonal_init,也就是上面说的用x - moving_mean,
另一个是trend_init,也就是上面的moving_mean的东西。
这两个都是和输入 一个尺寸的 ,也就是(1,96,7)这个维度的东西。
然后到模型的层面,他是用trend_init这个东西,也就是moving_mean这个东西进行和mean,进行交互,这个mean这个东西是利用x_enc得到的。上面写了这个mean的意义,现在又忘了。我们回过头来重新探讨一下。
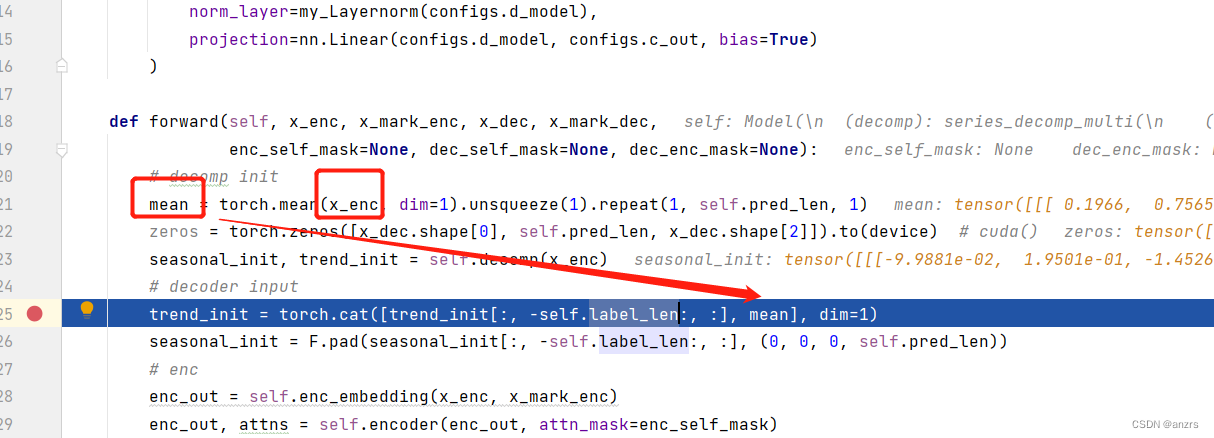
输入的x_enc的维度是(1,96,7)这个维度的,

对这个96这个维度求均值,dim=1,也就是输出的mean是(1,7)
也就是
1,2,3,4,5,6,7这样的序列条有96个,
然后对第一个feature点求mean,第二个feature点求mean这样。
所以才得到了(1,7)的维度的tensor。
也就是说,这个mean是这个输入序列的每一个feature点的均值,然后repeat了几十遍。
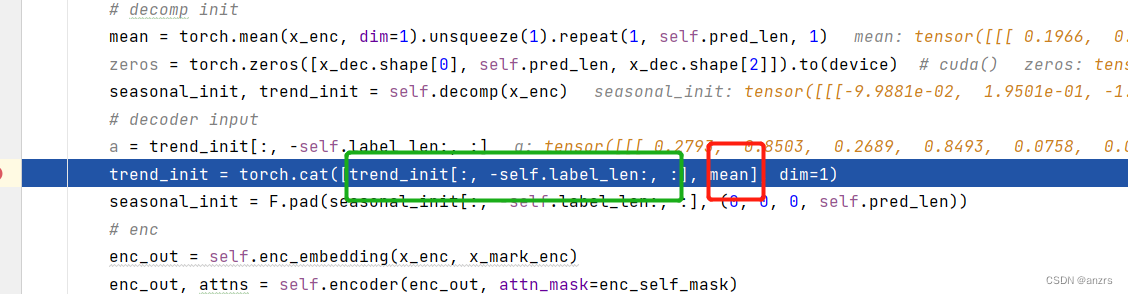
这个绿色的部分是(1,48,7)的维度的。
这个红色的是(1,96,7)的维度的。
因此,得到的trend_init的向量是(1,144,7)的维度的。
然后这里做了一个pad,这个pad也需要仔细研究一下的。这个原来的东西,

也就是这个红色的东西,他的维度是(1,48,7)的维度的,也就是这个x-moving的前一半。
然后对他做了pad。他变成了,(1,144,7)的维度的东西。下面的都是0,只有前面的才是sesonal的东西。
版权归原作者 anzrs 所有, 如有侵权,请联系我们删除。