
一、认识hadoop
hadoop是一个由Apache基金会所开发的分布式系统基础架构。[1]
hadoop的框架最核心的设计就是HDFS和MapReduce,HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算。[2]
hadoop具有高容错性,常部署在低廉的硬件上,而且它拥有高吞吐量,可以更好地访问应用程序中的数据,适合有着大数据集的应用程序,可以使用户在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
二、搭建Hadoop集群
- 从安全性等方面考虑。hadoop集群搭建在Linux系统上安全性更有保障。因为个人计算机大部分是windows系统,所以需要安装一个虚拟机软件VMware Workstation并创建一个Linux操作系统的虚拟机。
- 在Linux虚拟机下安装Java。
- 再搭建及配置Hadoop完全分布式集群环境,要求搭建的hadoop集群有一个主节点和三个子节点。
三、HDFS分布式文件系统
1.认识Hadoop安全模式
- 安全模式是Hadoop的保护机制,保障系统不受侵害。当处于安全模式时,文件系统只接受读数据的请求,而不接受删除、修改等变更请求。
- 而在非安全模式的时,则存在以下三种安全风险:
- Hadoop服务将不验证用户或者其他用户
- 攻击者可以伪装成Hadoop服务
- DateNode节点不会对节点上的数据块的访问实施任何访问控制
2.查看安全模式
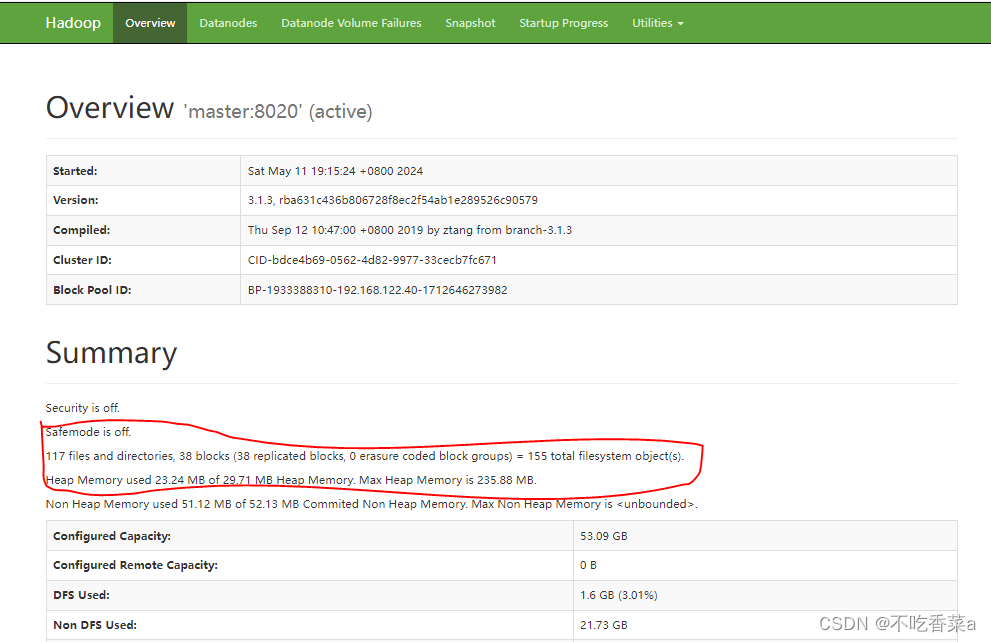
- 当启动Hadoop集群时,首先会进入安全模式,主要为了检查系统中DataNode节点上的数据块数量和有效性。在Linux系统上启动Hadoop集群,启动完成可以在本机浏览器输入“http://master:9870”网址,查看HDFS的监控服务。
3.解除和开启安全模式
- 当启动Hadoop 集群时集群会开启安全模式,原因是 DataNode的数据块数没有达到总块数的阈值。如果没有先关闭Hadoop集群时,而直接关闭了虚拟机,那么 Hadoop 集群也会进入安全模式,保护系统。当再次开启 Hadoop集群时,系统会一直处于安全模式不会自动解除, 这时使用“hdfs dfsadmin-safemode leave”令可以解除安全模式。

4.查询集群的储存系统信息
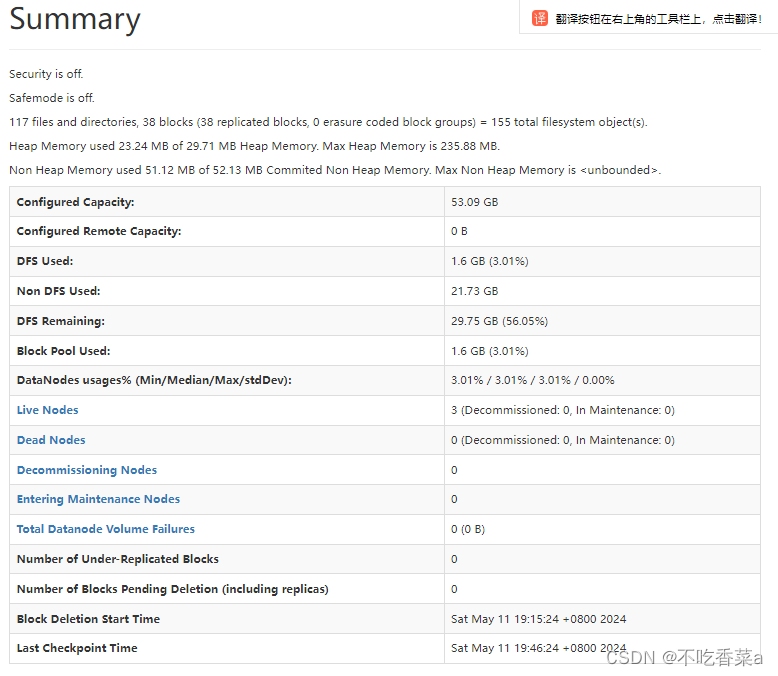
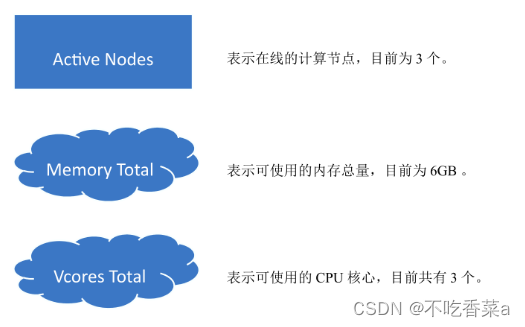
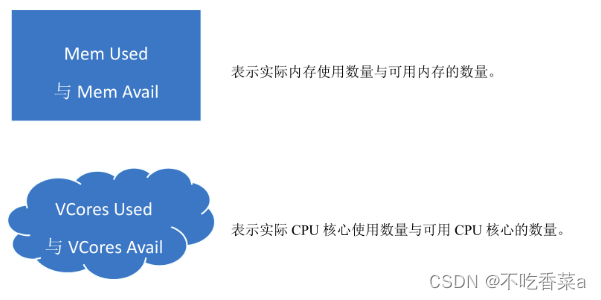
- 当 HDFS 文件系统完成启动时,在服务器集群上也将启动相关的监控服务。通过这些监控服务,即可查询到大量相与 HDFS 文件系统相关的信息。HDFS的监控服务默认是通过NameNode节点的 9870端口进行访问。
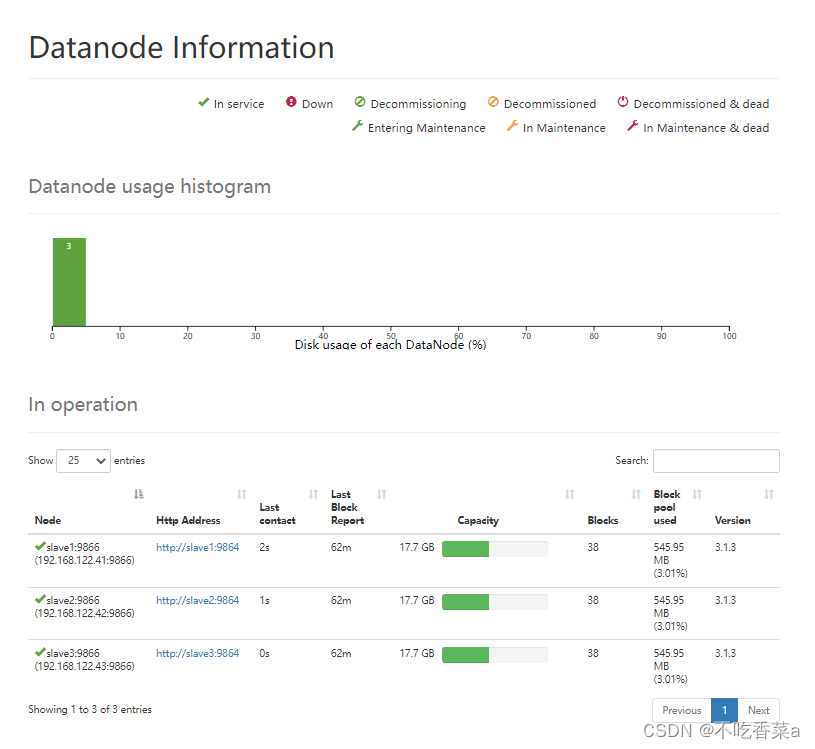
- 继续单击页面中的“Datanodes”标签栏,可以显示出各数据节点的信息。在图中显示了组成 HDFS的3个 Datanode节点的状态与各自的存储使用情况。在HDFS中,数据是被分块进行存储的,每个数据块默认有3个副本,即每个数据节点上存储一份数据副本,因此各节点的存储用量是大致相等的。
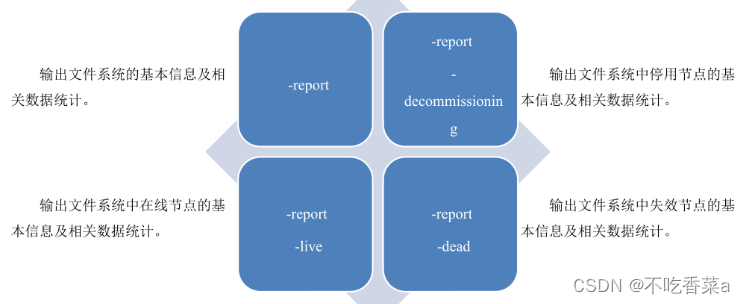
5.查询集群的计算资源信息
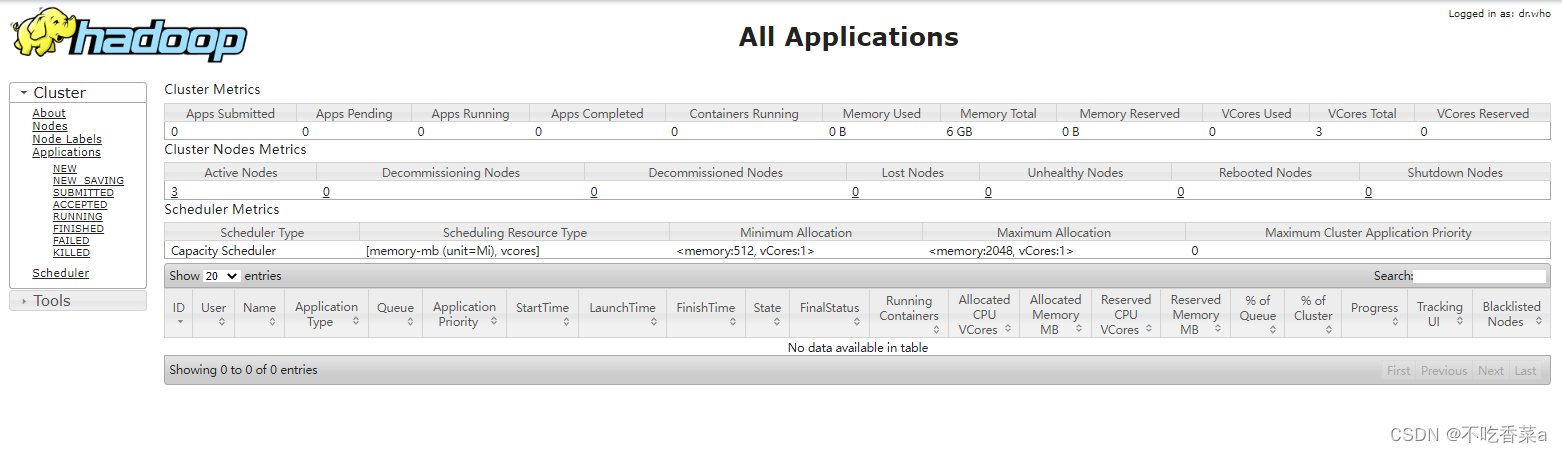
- Hadoop 集群的计算资源,是由 YARN 资源管理器的 ResourceManager进行管理的。通过 ResourceManager的监控服务,可以方便地查询目前集群上的计算资源信息。在本机浏览器的地址栏输入“http:/master:8088/clusternodes”网址,查看当前集群的计算资源信息。
四、了解HDFS

1.掌握HDFS的基本操作
- 创建目录
在集群服务器的终端,输入“hdfsd”命令,按“Enter”键回车后即可看到HDFS基础操作命令的使用
帮助。
“[-mkdir [-p]<path>..]”的命令可用于创建目录,参数<path>用以指定创建的新目录。在 HDFS 中创建/user/dfstest 目录,查看在 HDFS 文件目录 /user/ 下的文件列表,可查看到新创建的目录。
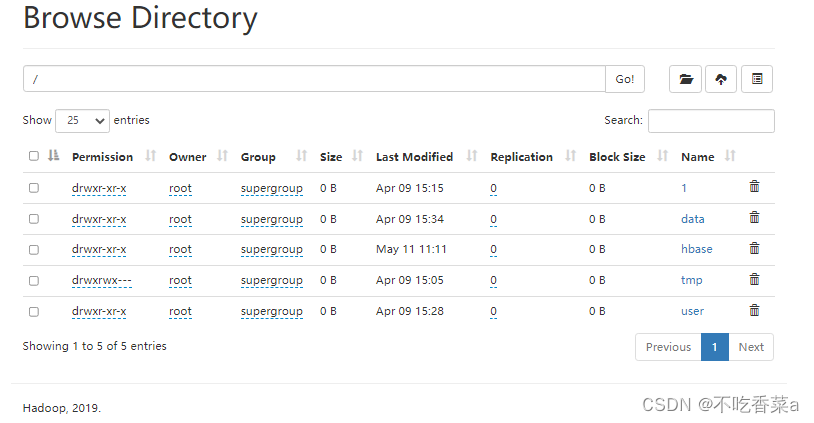
- 上传与下载文件

- 查看文件内容
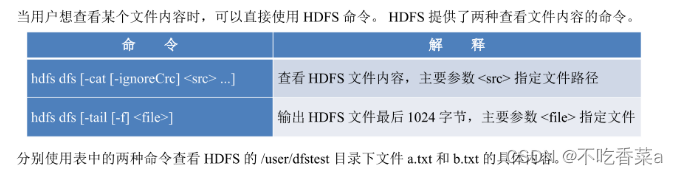
[root@master hdfs_test]# hdfs dfs -cat /user/dfstest/a.txt
I have a pen
I have an apple
[root@master hdfs_test]# hdfs dfs -tail /user/dfstest/b.txt
I have a pen
I have an apple
- 删除文件或者目录

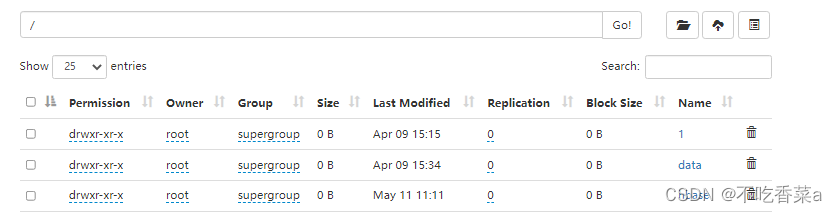
先在 HDFS 的 /user/dfstest 目录下创建一个测试目录rmdir ,再分别删除 /user/dfstest目录下的c.txt 文件和新创建的 rmdir 目录。
在执行删除命令后,查看HDFS的 huser/dfstest目录下的内容,已成功删除 c.txt文件和mmdir 目录。
Hadoop的优点总结
- Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
- Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
- Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。
- Hadoop 还是可伸缩的,能够处理PB级数据。
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如C++。
hadoop大数据处理的意义
Hadoop 集群一般构建在通过高速网络连接的单一数据中心内,集群计算机都具有体系结构、平台一致的特点,而网格计算需要在互联网接入环境下使用,网络带宽等都没有保证。因此Hadoop可以跨大量的计算节点运行非常巨大的数据集,能大大提高效率。
本文转载自: https://blog.csdn.net/2301_78172425/article/details/138709220
版权归原作者 不吃香菜a 所有, 如有侵权,请联系我们删除。
版权归原作者 不吃香菜a 所有, 如有侵权,请联系我们删除。