
一、JDK的安装
Spark是一个用于大数据处理的开源框架,它是用Scala编写的,而Scala是一种运行在Java虚拟机(JVM)上的编程语言,因此它依赖于Java的运行环境。所以首先需要安装JDK(JavaTM Platform Standard Edition Development Kit),并将环境变量配置好。
可参考我的另一篇博客:http://t.csdnimg.cn/6Kj8w
二、Spark的安装
1.下载Spark
从Spark官网进行下载:Apache Spark™ - Unified Engine for large-scale data analytics,点击Download
这里我下载2.2.0版本,滑到下面,选择Archived releases,点击Spark release archives
找到2.2.0版本

选择带有Hadoop版本的Spark: spark-2.2.0-bin-hadoop2.7.tgz
意思是Spark版本是2.2.0,还需安装hadoop2.7版本
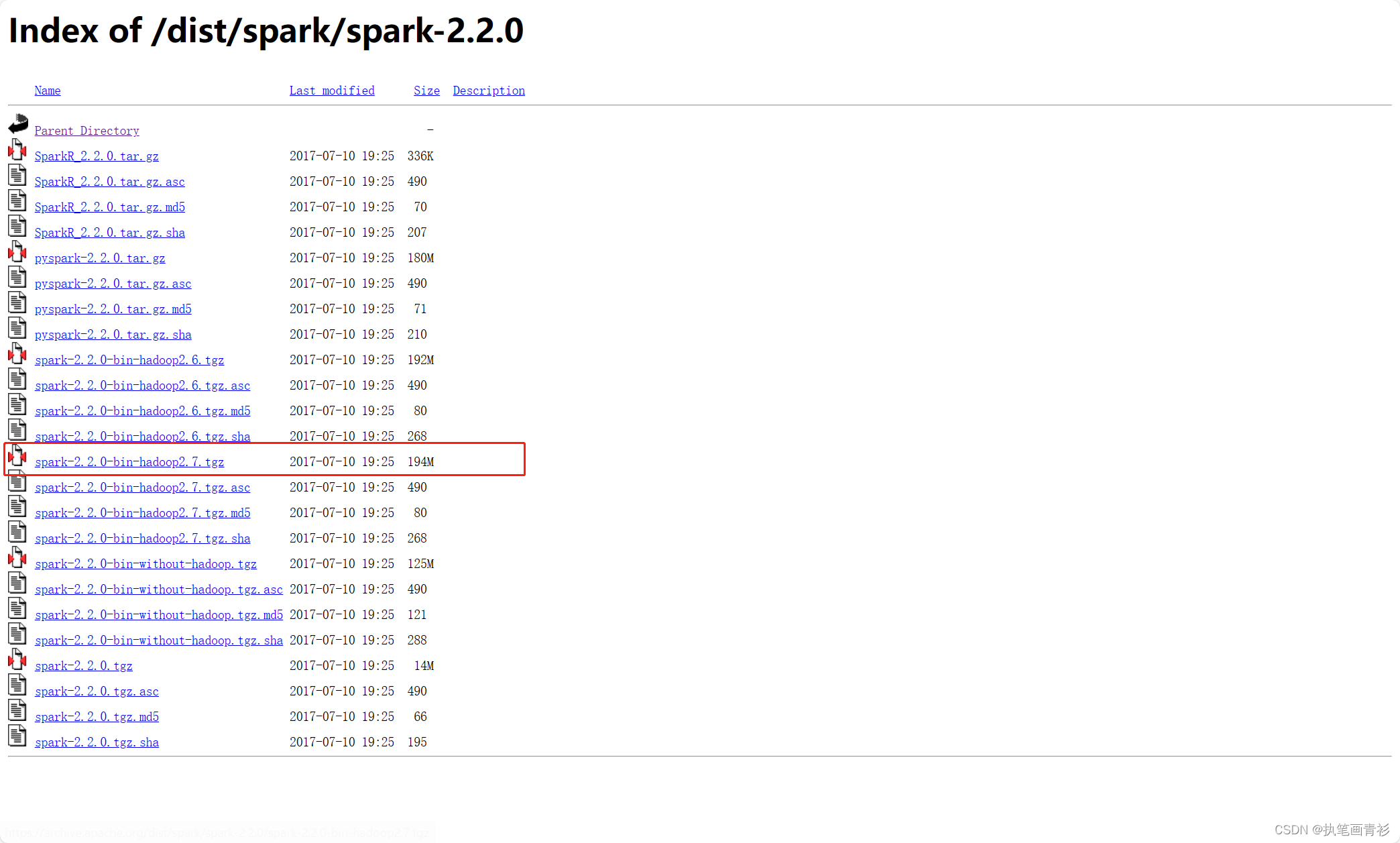
单击即可下载
下载完成后将文件进行解压,得到大约200M的文件: spark-2.2.0-bin-hadoop2.7
最好解压到一个盘的根目录下,并重命名为Spark,简单不易出错。并且需要注意的是,在Spark的文件目录路径名中,不要出现空格和中文,类似于“Program Files”这样的文件夹名是不被允许的,我放的位置是D:\Spark
2.配置环境变量
系统变量创建SPARK_HOME:D:\Spark\spark-2.2.0-bin-hadoop2.7

系统变量中的Path添加:%SPARK_HOME%\bin
3.测试是否安装成功
Win+R键打开运行窗口,输入cmd,命令行串口输入spark-shell
出现下图即安装成功
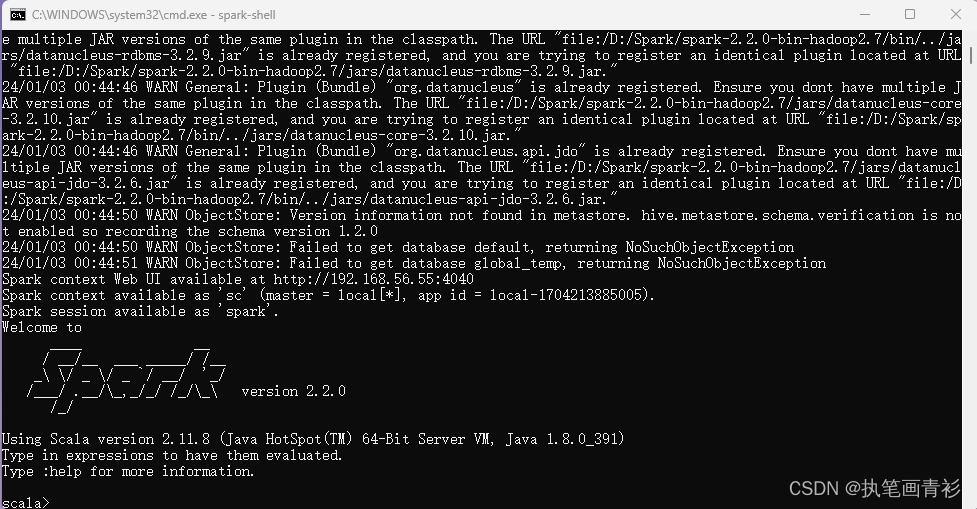
这时开启的是Spark的交互式命令行模式,但直接使用很有可能会碰到各种错误,如下图,这里主要是因为Spark是基于hadoop的,所以这里还需配置一个Hadoop的运行环境。
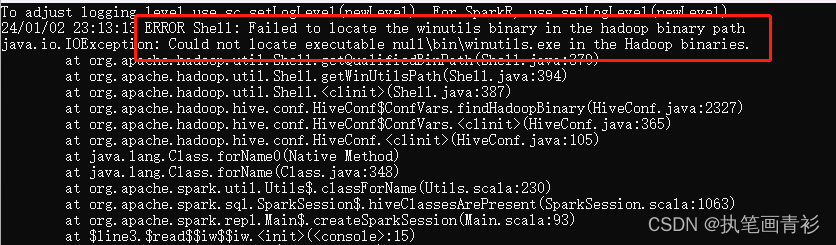
三、Hadoop的安装
1.下载Hadoop
下载上面spark对应版本的hadoop 2.7:Hadoop Releases
我这里选择2.7.1版本

选择好相应版本并点击后,进入详细的下载页面,如下图所示

上面的src版本就是源码,需要对Hadoop进行更改或者想自己进行编译的可以下载对应src文件,我这里下载的就是已经编译好的版本,即图中的“hadoop-2.7.1.tar.gz”文件
下载并解压到指定目录,我这里是D:\Hadoop

2.配置环境变量
系统变量创建HADOOP_HOME:D:\Hadoop\hadoop-2.7.1
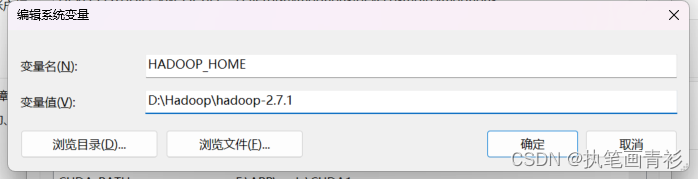
系统变量中的Path添加:%HADOOP_HOME%\bin
3.安装winutils.exe
winutils.exe是在window系统上安装hadoop时必要的文件,可在github上下载
github下载地址:https://github.com/steveloughran/winutils
选择对应安装的Hadoop版本号
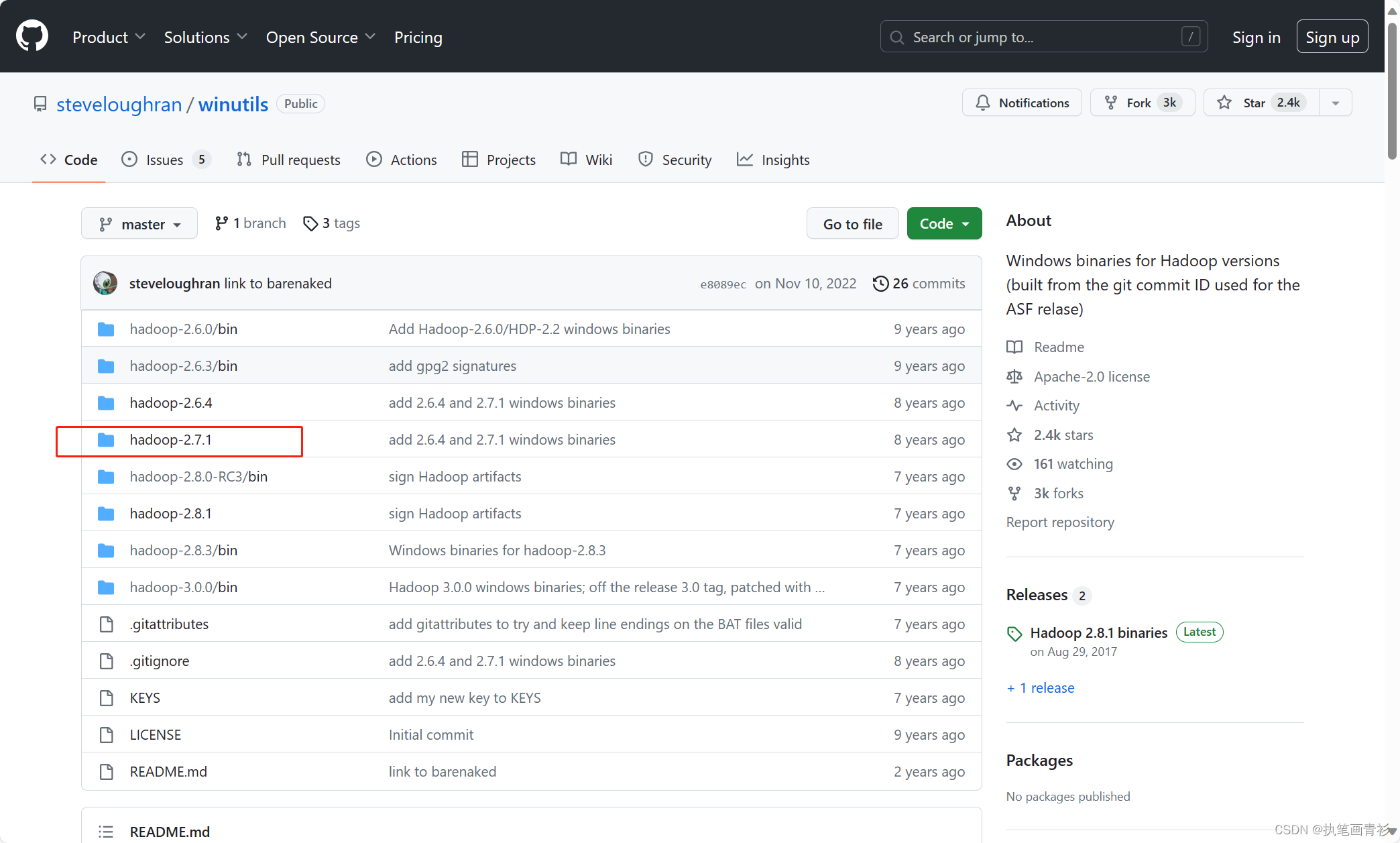
进入到bin目录下
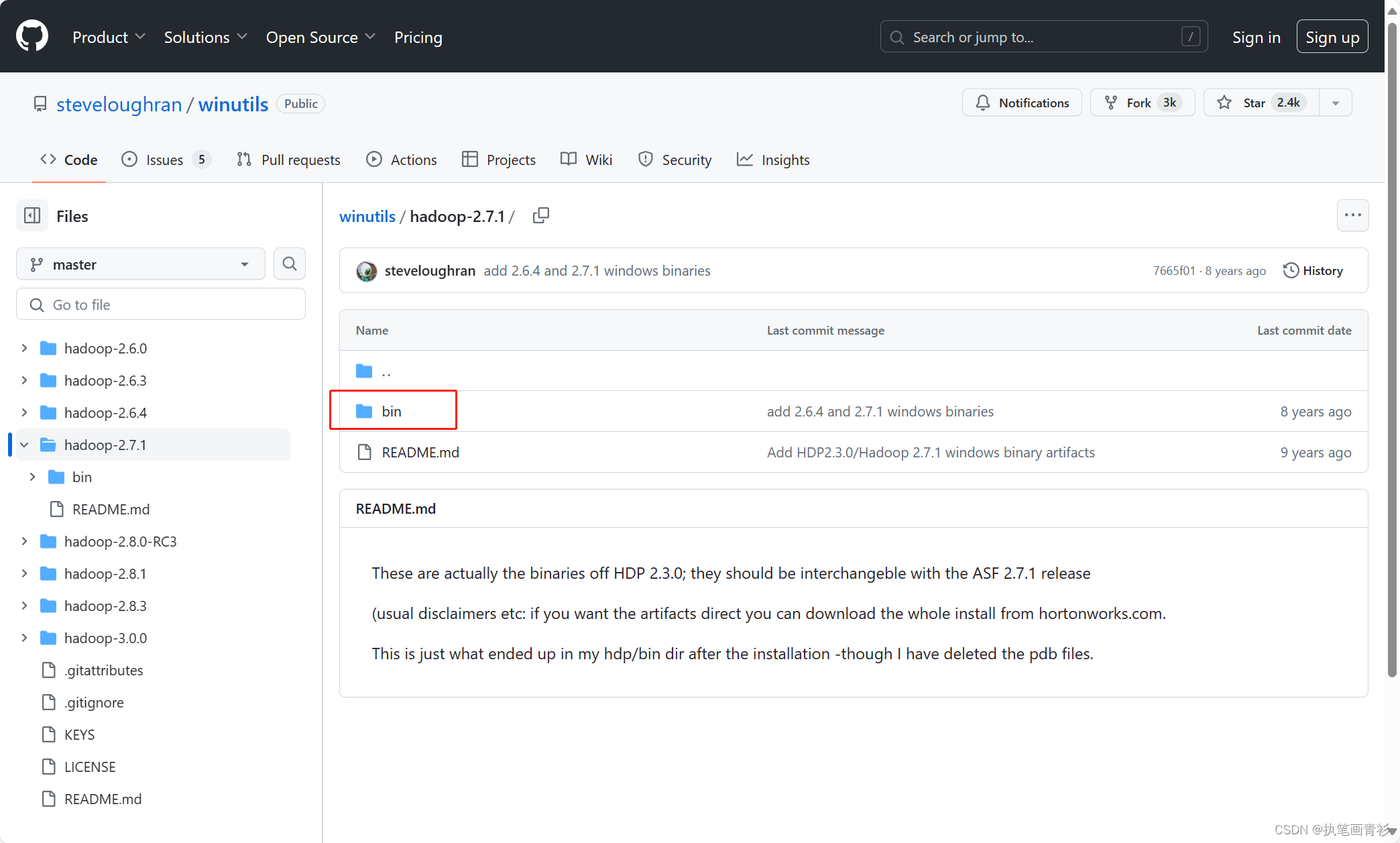
找到winutils.exe文件,单击下载
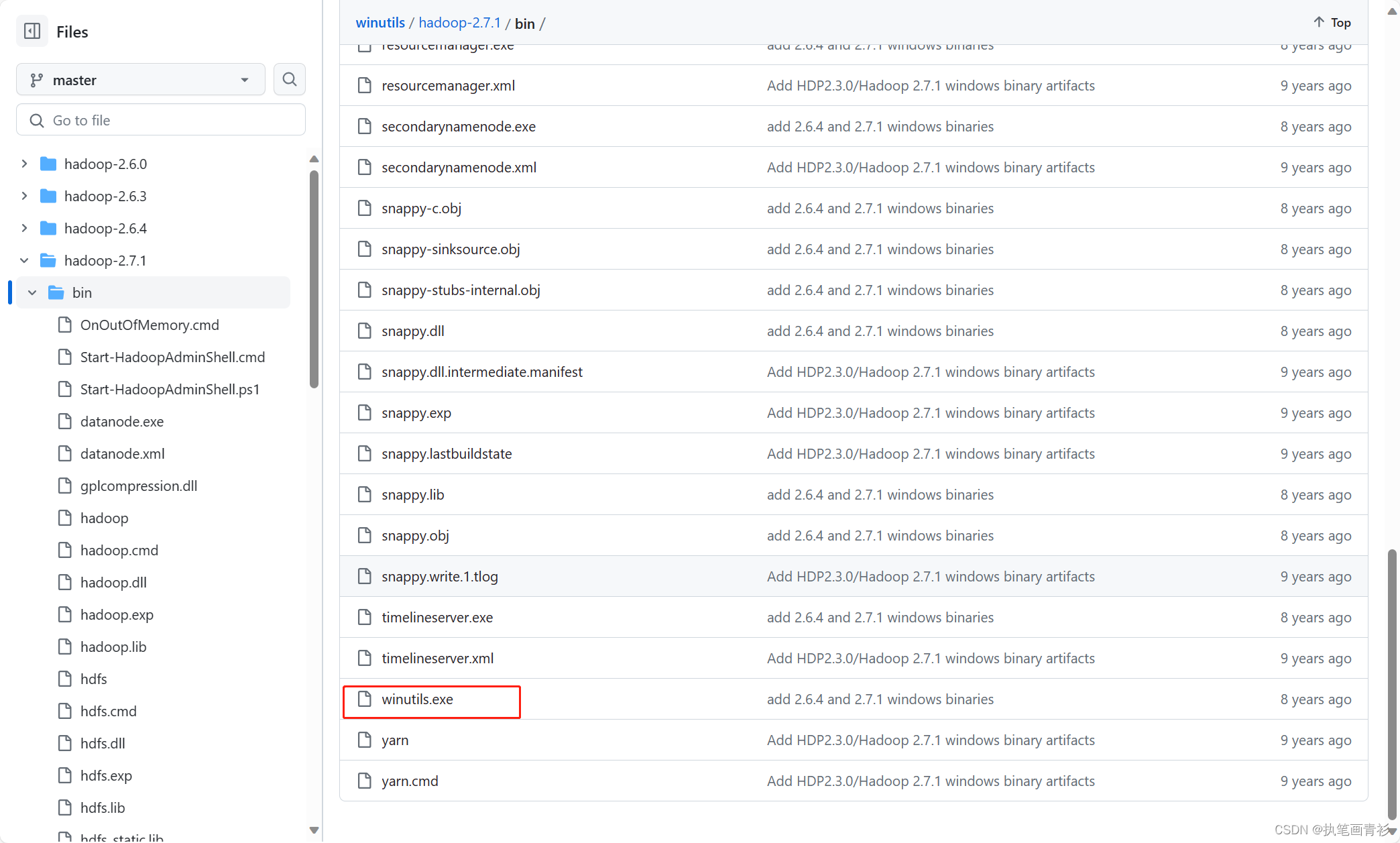
将下载好的winutils.exe文件放入到Hadoop的bin目录下,我是D:\Hadoop\hadoop-2.7.1\bin
4.测试是否安装成功
Win+R键打开运行窗口,输入cmd,命令行串口输入hadoop

四、常见问题
正常情况下是可以运行成功并进入到Spark的命令行环境下的,但是可能会遇到如下错误:
<console>:14: error: not found: value spark
import spark.implicits._
^
<console>:14: error: not found: value spark
import spark.sql
^
** 解决办法是:**
用以下命令创建 C:\tmp\hive diroctory 并授予访问权限(777是获取所有权限)
C:\Hadoop\winutils-master\hadoop-2.7.1\bin>winutils.exe chmod -R 777 C:\tmp\hive
删除C盘的本地元存储metastore_db目录(如果存在的话)
C:\Users\<User_Name>\metastore_db
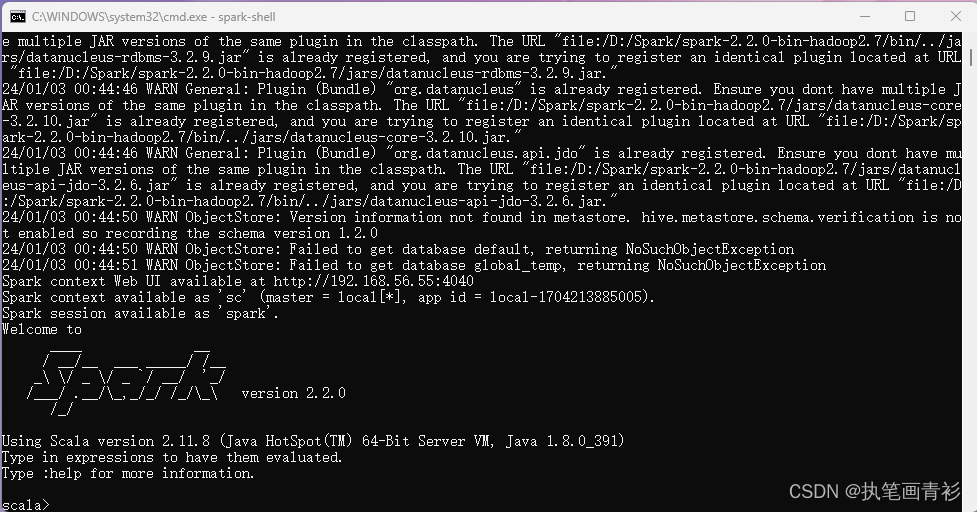
然后再次开启一个新的cmd窗口,如果正常的话,应该就可以通过直接输入spark-shell来运行Spark了。正常的运行界面应该如下图所示:
五、Python下Spark开发环境搭建
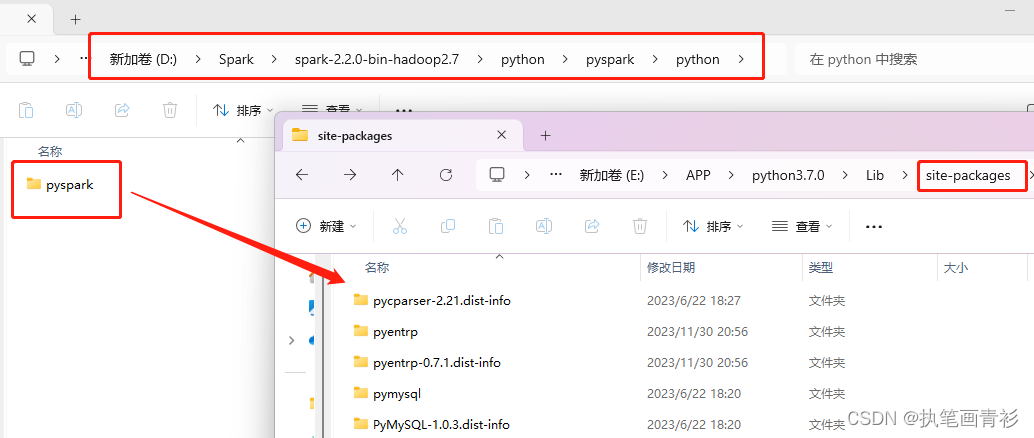
1、将Spark目录下的pyspark文件夹(D:\Spark\spark-2.2.0-bin-hadoop2.7\python\pyspark)复制到要使用的python环境的安装目录(E:\APP\python3.7.0\Lib\site-packages)里。如图所示:
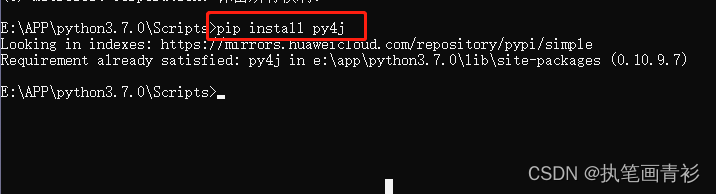
2.cmd进入目录(python环境下的Scripts)E:\APP\python3.7.0\Scripts,运行pip install py4j安装py4j库。如图所示:
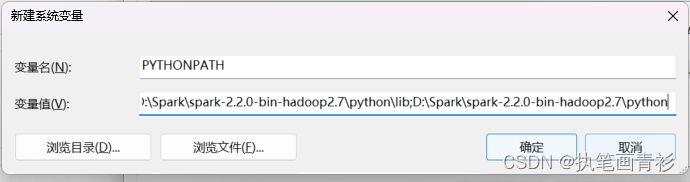
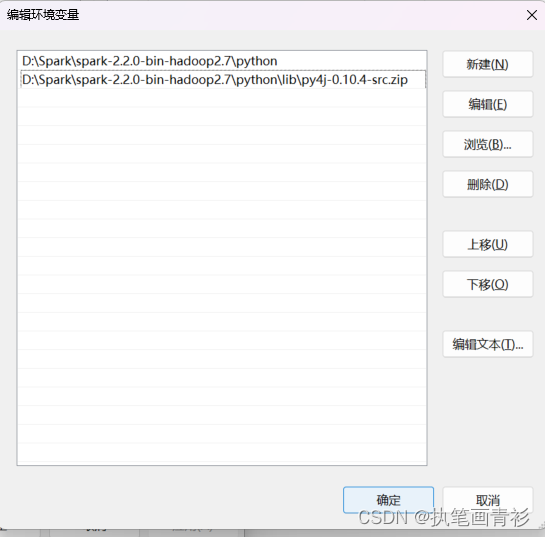
3.在系统变量中新建一个PYTHONPATH的系统变量,然后设置好下面变量值
D:\Spark\spark-2.2.0-bin-hadoop2.7\python(根据自己目录更改)
D:\Spark\spark-2.2.0-bin-hadoop2.7\python\lib\py4j-0.10.4-src.zip(根据自己目录更改)
后面就可以在VScode或者PyCharm等IDE中使用PySpark了!
参考文献:
Why does spark-shell fail with “error: not found: value spark”? - Stack Overflow
http://t.csdnimg.cn/UHP0E
版权归原作者 执笔画青衫 所有, 如有侵权,请联系我们删除。