
在阅读本文之前,请确保您已经有了一定的神经网络基础(具体的介绍可以看西瓜书)。
本文采用的是标准的BP算法,即每次仅针对一个样例更新权重和阈值。
本文将搭建用于分类的双隐层BP神经网络
一、理论部分
1.1 正向计算
符号说明
设我们的双隐层BP神经网络有m个输入神经元,n个输出神经元,第一个隐层有p个隐层神经元,第二个隐层有q个隐层神经元。
- 权重:第
个输入神经元到第
个第一个隐层的神经元的权重记为
, 第
,第
;
- 阈值:第
,第
,第
个输出神经元的阈值记为
;
- 输入:第
,第
,第
,第
;
- 输出:第
,第
,第
。
记,激活函数为
,我们定义:
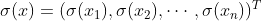
公式推导
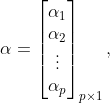 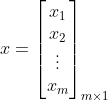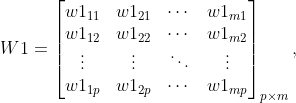
则有
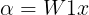
再令,
,从而
同理可得,为第一个隐层与第二个隐层之间的权重矩阵,且有
进一步有。
最后,为第二个隐层和输出层之间的权重矩阵,且有
进一步有。
综上所述,我们成功得到了神经网络的输出。
1.2 反向传播
对于给定的样例,神经网络的输出为
,从而误差为
我们采用梯度下降的策略来最小化误差,即
其中
令,则可知
。
另一方面
因此。
记,于是得到权重和阈值的更新公式:
此外,对于另外的两个权重矩阵以及阈值和梯度项,我们可以根据以上过程以及链式法则推导得到(注:激活函数采用Sigmoid函数):
同时我们也可以得到其他权重和阈值的更新公式:
二、实现部分
2.1 算法伪码
基于以上的推导过程,为了便于我们后续的编程实现,我们了可以尝试写出算法的伪码:
输入:训练集D, 学习率
过程 :
1.随机初始化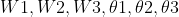
2.**repeat**
3. **for all 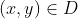 do**
4. 计算输入和输出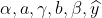
5. 计算梯度项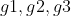
6. 计算改变量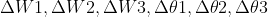
7. 更新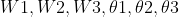
8. **end for**
9.**until 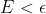 **或迭代次数达到某个值
** 输出:**训练好的神经网络
经过了以上的推导,想必大家更希望看到一种更为简洁的方式来表示神经网络的输出过程,以及各个变量所对应的位置,于是我们可以将双隐层按如下简化:

2.2 算法实现
2.2.1初始化
首先我们要创建一个神经网络类:
import numpy as np
class Neural_Network():
"""定义一个神经网络类"""
def __init__(self):
pass
接下来我们要对神经网络类需要初始化的数据做一个分析,显然,输入层的结点数m,隐层结点数p和q,输出层的结点数n都是需要初始化的,它们决定了神经网络的结构。
此外,根据算法伪码,我们可以看到还需初始化注意到权重矩阵和阈值向量由前面结点参数决定,剩下的参数是需要我们人工输入的
当然,容忍度tol,最大迭代次数 max_iter,也需要人工输入,这两个参数决定了我们的神经网络进行训练的时间和次数。
def __init__(self, X, y, hiddennodes1, hiddennodes2, learningrate=0.01, tol=1e-3, max_iter=1000):
self.X, self.y = X, y
self.classes = np.unique(self.y)
#结点数
self.ins, self.hns1, self.hns2, self.ons = len(X[0]), hiddennodes1, hiddennodes2, len(self.classes)
#学习率
self.lr = learningrate
#容忍度
self.tol = tol
#最大迭代次数
self.max_iter = max_iter
权重矩阵和阈值向量都是在(0,1)范围内初始化:
#权重矩阵
self.W1 = np.random.rand(self.hns1, self.ins)
self.W2 = np.random.rand(self.hns2, self.hns1)
self.W3 = np.random.rand(self.ons, self.hns2)
#阈值向量
self.theta1 = np.random.rand(self.hns1)
self.theta2 = np.random.rand(self.hns2)
self.theta3 = np.random.rand(self.ons)
当然,还有激活函数,我们用Python的匿名函数来做初始化:
#Sigmoid
self.sigmoid = lambda x: 1 / (1 + np.power(np.e, -x))
到此为止,我们的**init()**函数算是完成了 :
def __init__(self, X, y, hiddennodes1, hiddennodes2, learningrate=0.01, tol=1e-3, max_iter=1000):
self.X, self.y = X, y
self.classes = np.unique(self.y)
self.ins, self.hns1, self.hns2, self.ons = len(X[0]), hiddennodes1, hiddennodes2, len(self.classes)
self.lr = learningrate
self.tol = tol
self.max_iter = max_iter
self.W1 = np.random.rand(self.hns1, self.ins)
self.W2 = np.random.rand(self.hns2, self.hns1)
self.W3 = np.random.rand(self.ons, self.hns2)
self.theta1 = np.random.rand(self.hns1)
self.theta2 = np.random.rand(self.hns2)
self.theta3 = np.random.rand(self.ons)
self.sigmoid = lambda x: 1 / (1 + np.power(np.e, -x))
2.2.2 正向传播
我们需要定义一个函数来实现正向的传播,该函数需要一个样本(x,y)作为输入,我们用(inputs, targets) 来表示,输出的用outputs来表示。
当然,我们还需要计算误差E,用error来表示。
def propagate(self, inputs, targets):
#计算输入和输出
alpha = np.dot(self.W1, inputs)
a = self.sigmoid(alpha - self.theta1)
gamma = np.dot(self.W2, a)
b = self.sigmoid(gamma - self.theta2)
beta = np.dot(self.W3, b)
outputs = self.sigmoid(beta - self.theta3)
#计算误差
error = np.linalg.norm(targets - outputs, ord=2) ** 2 / 2
return alpha, a, gamma, b, beta, outputs, error
2.2.3 反向传播
反向传播需要先计算三个梯度项,然后进行参数更新,可以看出我们需要如下参数
,由此我们定义一个反向传播的函数:
def back_propagate(self, inputs, targets, alpha, a, gamma, b, beta, outputs):
#计算三个梯度项
g3 = (targets - outputs) * outputs * (np.ones(len(outputs)) - outputs)
g2 = np.dot(self.W3.T, g3) * b * (np.ones(len(b)) - b)
g1 = np.dot(self.W2.T, g2) * a * (np.ones(len(a)) - a)
#更新参数
self.W3 += self.lr * np.outer(g3, b)
self.theta3 += -self.lr * g3
self.W2 += self.lr * np.outer(g2, a)
self.theta2 += -self.lr * g2
self.W1 += self.lr * np.outer(g1, inputs)
self.theta1 += -self.lr * g1
2.2.4 训练
训练需要传入数据集,假设数据集的表示形式为 X , y 。
我们需要对传入的数据集做一些处理。在遍历数据集时,X[i] 是向量,即 inputs,y[i] 是向量对应的标签,它仅仅是一个数,而非像 targets 这样的向量。
那么如何将 y[i] 处理成 **targets **呢?
考虑像手写数字识别这样的十分类任务,对应的神经网络的输出层有十个神经元,每个神经元对应着一个数字。例如,当我们输入一张 5 的图片时,5 对应的神经元的输出值应该是最高的,其他神经元的输出值应该是最低的。
因为激活函数是Sigmoid函数,它的输出区间为(0,1)。我们将输出层神经元按照其对应的数字从小到大进行排列,从而输出层的情况应当十分接近下面这个样子:
[0,0,0,0,0,1,0,0,0,0]
y 中包含了所有向量的标签,若要判断我们面临的问题是一个几分类问题,我们需要对 y 进行去重,再将结果从小到大进行排序:
self.classes = np.unique(self.y)
获取targets的步骤如下:
inputs, targets = self.X[idx], np.zeros(len(self.classes))
targets[list(self.classes).index(self.y[idx])] = 1
我们前面已经提到,训练停止当且仅当下面两个条件满足其中之一:
- 迭代收敛,即
:
- 迭代次数达到最大值,即训练了max_iter次
如果第一个条件先达到,则我们应立刻停止训练;如果第二个条件达到,说明我们训练了max_iter次也没有收敛,此时应当抛出一个错误。
def train(self):
#初始时未收敛
convergence = False
#开始迭代 max_iter 次
for _ in range(self.max_iter):
#遍历数据集
for idx in range(len(self.X)):
inputs, targets = self.X[idx], np.zeros(len(self.classes))
targets[list(self.classes).index(self.y[idx])] = 1
#正向计算
alpha, a, gamma, b, beta, outputs, error = self.propagate(inputs, targets)
#若误差不超过容忍度,则判定收敛
if error <= self.tol:
convergence = True
break
else:
# 反向传播
self.back_propagate(inputs, targets, alpha, a, gamma, b, beta, outputs)
if convergence:
break
if not convergence:
raise RuntimeError('神经网络未收敛,请调大max_iter的值')
2.2.5 预测
训练好的神经网络应该能对单个样本完成分类,我们选择outputs中输出最高的神经元对应的类别标签作为我们对样本的标签:
def predict(self, sample):
alpha = np.dot(self.W1, sample)
a = self.sigmoid(alpha - self.theta1)
gamma = np.dot(self.W2, a)
b = self.sigmoid(gamma - self.theta2)
beta = np.dot(self.W3, b)
outputs = self.sigmoid(beta - self.theta3)
#直接输出最高的神经元在outputs中的索引
return self.classes[idx = list(outputs).index(max(outputs))]
完整的双隐层神经网络代码如下:
import numpy as np
class Neural_Network():
"""定义一个神经网络类"""
def __init__(self, X, y, hiddennodes1, hiddennodes2, learningrate=0.01, tol=1e-3, max_iter=1000):
self.X, self.y = X, y
self.classes = np.unique(self.y)
self.ins, self.hns1, self.hns2, self.ons = len(X[0]), hiddennodes1, hiddennodes2, len(self.classes)
self.lr = learningrate
self.tol = tol
self.max_iter = max_iter
self.W1 = np.random.rand(self.hns1, self.ins)
self.W2 = np.random.rand(self.hns2, self.hns1)
self.W3 = np.random.rand(self.ons, self.hns2)
self.theta1 = np.random.rand(self.hns1)
self.theta2 = np.random.rand(self.hns2)
self.theta3 = np.random.rand(self.ons)
self.sigmoid = lambda x: 1 / (1 + np.power(np.e, -x))
def propagate(self, inputs, targets):
alpha = np.dot(self.W1, inputs)
a = self.sigmoid(alpha - self.theta1)
gamma = np.dot(self.W2, a)
b = self.sigmoid(gamma - self.theta2)
beta = np.dot(self.W3, b)
outputs = self.sigmoid(beta - self.theta3)
error = np.linalg.norm(targets - outputs, ord=2) ** 2 / 2
return alpha, a, gamma, b, beta, outputs, error
def back_propagate(self, inputs, targets, alpha, a, gamma, b, beta, outputs):
g3 = (targets - outputs) * outputs * (np.ones(len(outputs)) - outputs)
g2 = np.dot(self.W3.T, g3) * b * (np.ones(len(b)) - b)
g1 = np.dot(self.W2.T, g2) * a * (np.ones(len(a)) - a)
self.W3 += self.lr * np.outer(g3, b)
self.theta3 += -self.lr * g3
self.W2 += self.lr * np.outer(g2, a)
self.theta2 += -self.lr * g2
self.W1 += self.lr * np.outer(g1, inputs)
self.theta1 += -self.lr * g1
def train(self):
convergence = False
for _ in range(self.max_iter):
for idx in range(len(self.X)):
inputs, targets = self.X[idx], np.zeros(len(self.classes))
targets[list(self.classes).index(self.y[idx])] = 1
alpha, a, gamma, b, beta, outputs, error = self.propagate(inputs, targets)
if error <= self.tol:
convergence = True
break
else:
self.back_propagate(inputs, targets, alpha, a, gamma, b, beta, outputs)
if convergence:
break
if not convergence:
raise RuntimeError('神经网络未收敛,请调大max_iter的值')
def predict(self, sample):
alpha = np.dot(self.W1, sample)
a = self.sigmoid(alpha - self.theta1)
gamma = np.dot(self.W2, a)
b = self.sigmoid(gamma - self.theta2)
beta = np.dot(self.W3, b)
outputs = self.sigmoid(beta - self.theta3)
return self.classes[idx = list(outputs).index(max(outputs))]
我们将其保存在tnn.py里面。
三、 实战模拟
在此,我们仅用sklearn中的鸢尾花数据集来训练并测试神经网络
完整的代码如下:
from dnn import Neural_Network #导入我们的神经网络
from sklearn.model_selection import train_test_split #划分数据集和测试集
from sklearn.metrics import accuracy_score #计算分类准确率
from sklearn.datasets import load_iris #鸢尾花数据集
from sklearn.preprocessing import MinMaxScaler #数据预处理
import numpy as np
def test(bpnn, X_test, y_test):
y_pred = [bpnn.predict(X_test[i]) for i in range(len(X_test))]
return accuracy_score(y_test, y_pred)
X, y = load_iris(return_X_y=True)
scaler = MinMaxScaler().fit(X)
X_scaled = scaler.transform(X)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
bpnn = Neural_Network(X_train, y_train, 10, 8, max_iter=3000)#将第一个隐层神经元数据设为10,将第二个隐层神经元的数目设为8
bpnn.train()
print(test(bpnn, X_test, y_test))
#0.9666666666666667
最后我们得到神经网络在测试集上的分类准确率达96.666666...%
尽管后续的调参采用了多个数据,但是分类准确率均为96.666...%,可能双隐层神经网络在小数据规模的数据集上分类效果并没有单隐层的神经网络好。也欢迎各位大佬在评论区提供改进建议以及分享不同思路。
Reference
[1]机器学习. 周志华
版权归原作者 萌新bohr 所有, 如有侵权,请联系我们删除。