
🍅程序员小王的博客:程序员小王的博客
🍅 欢迎点赞 👍 收藏 ⭐留言 📝
🍅 如有编辑错误联系作者,如果有比较好的文章欢迎分享给我,我会取其精华去其糟粕
🍅java自学的学习路线:java自学的学习路线
一、视图
- 视图就是封装了一条复杂查询的语句。
1、语法 1.:CREATE VIEW 视图名称 AS 子查询
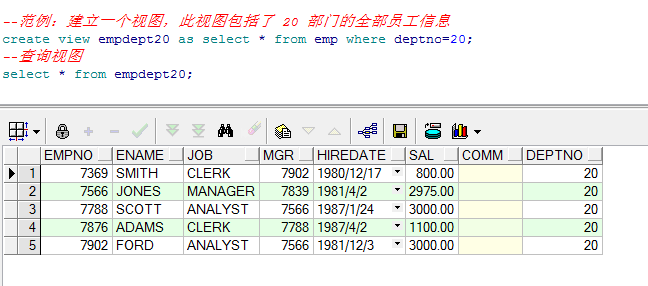
- 范例:建立一个视图,此视图包括了 20 部门的全部员工信息
--范例:建立一个视图,此视图包括了 20 部门的全部员工信息
create view empdept20 as select * from emp where deptno=20;
视图创建完毕就可以使用视图来查询,查询出来的都是 20 部门的员工
--查询视图
select * from empdept20;
2、语法 2:CREATE OR replace VIEW 视图名称 AS 子查询
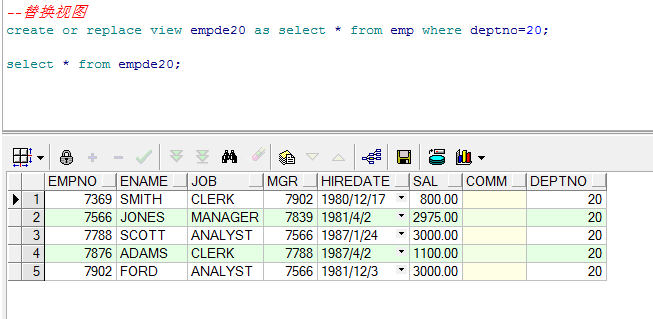
- 如果视图已经存在我们可以使用语法 2 来创建视图,这样已有的视图会被覆盖。
--替换视图
create or replace view empde20 as select * from emp where deptno=20;
select * from empde20;
3、优点:
- 视图是给sql查询语句定义名称,方便复用,简化SQL
- 安全性,对开发人员屏蔽掉表和字段信息.
4、注意:
- 视图相当于查询语句,不存储实际数据,视图基本不会占用硬盘空间 在效率上没有得到提高
- 删除视图: drop view 视图名;
二、索引
1、什么是索引?
- 理解:类似于书前面的目录,用于提高查询效率。索引是用于加速数据存取的数据对象。合理的使用索引可以大大降低 i/o 次数,从而提高数据访问性能。
- 注意:索引里存储数据(索引列数据和rowid),并且按照索引列升序
- 创建索引:
CREATE [UNIQUE] | [BITMAP] INDEX index_name --unique表示唯一索引
ON table_name([column1 [ASC|DESC],column2 --bitmap,创建位图索引
[ASC|DESC],…] | [express])
[TABLESPACE tablespace_name]
[PCTFREE n1] --指定索引在数据块中空闲空间
[STORAGE (INITIAL n2)]
[NOLOGGING] --表示创建和重建索引时允许对表做DML操作,默认情况下不应该使用
[NOLINE]
[NOSORT]; --表示创建索引时不进行排序,默认不适用,如果数据已经是按照该索引顺序排列的可以使用
- 使用: 不需要手动使用, 默认使用索引字段为条件进行查询时,数据库会自动使用索引查找数据
- 注意:
1. 索引不是创建的越多越好,索引占空间(有数据);增删改数据时,同时需要维护索引中的数据
2. 通常在经常被查询的列上创建索引
3. 主键和唯一约束的列,数据库会自动添加索引.
4. 删除索引:drop index 索引名;
2、单列索引
- 单列索引是基于单个列所建立的索引,比如:
CREATE index 索引名 on 表名(列名)
- 案例:给 person 表的 name 建立索引
create index pname_index on person(name);
3、 复合索引
复合索引是基于两个列或多个列的索引。在同一张表上可以有多个索引,但是
要求列的组合必须不同,比如:
Create index emp_idx1 on emp(ename,job);
Create index emp_idx1 on emp(job,ename);
- 案例:给 person 表创建一个 name 和 gender 的索引
create index pname_gender_index on person(name,gender)
4、索引的使用原则:
- 在大表上建立索引才有意义
- 在 where 子句后面或者是连接条件上的字段建立索引
- 表中数据修改频率高时不建议建立索引
5、索引原理
- 若没有索引,搜索某个记录时(例如查找name='whj')需要搜索所有的记录,因为不能保证只有一个whj,必须全部搜索一遍
- 若在name上建立索引,oracle会对全表进行一次搜索,将每条记录的name值哪找升序排列,然后构建索引条目(name和rowid),存储到索引段中,查询name为whj时即可直接查找对应地方
- 创建了索引并不一定就会使用,oracle自动统计表的信息后,决定是否使用索引,表中数据很少时使用全表扫描速度已经很快,没有必要使用索引
三、约束
1、主键约束:primary key
- 作用:用于唯一标识表中的一行数据,如学号、工号
- 特点:唯一、非空
- 语法:字段名 数据类型 primary key
- 注意:开发时,通常常每一张表都会有一个主键约束
2、唯一约束:unique
- 作用:标识该字段的值不允许重复。如身份证号、手机号
- 特点:唯一、可以为空
- 语法:字段名 数据类型 unique
3、非空约束:not null
- 作用:标识该字段的必须有内容,不允许为null;如学生姓名
- 特点:非空、可以重复
- 语法:字段名 数据类型 not null
4、检查约束:check(表达式)
- 作用:根据自定义规则限制该字段的内容。例如性别只能是男或女
- 语法:字段名 数据类型 check(检查约束的表达式)
- 常见使用场景:
性别只能是 男或女:check( sex in ('男','女')) 或是
check(sex = '男' or sex='女')
手机号码必须是11位:phone char(11) check(phone like '_____')或
phone char(11) check(length(pone)=11)
邮箱必须有@:check (email like '%@%')
5、外键约束
- 作用:标识该字段的值不允许随便输入,必须是另一个表中的主键或唯一键中存在的值。 (标识当前表 [从表] 和另一个表 [主表] 之间的关系)
- 特点:可以重复、可以是null
- 语法:字段名 数据类型 references 主表名(主键/唯一键的字段名)

6、默认约束
- 默认值:default
- 作用:标识该字段在不填写任意内容,系统默认分配的内容
- 语法:字段名 数据类型 defualt 值 约束
- 注意:给定的默认值的类型必须和该字段的数据类型一致
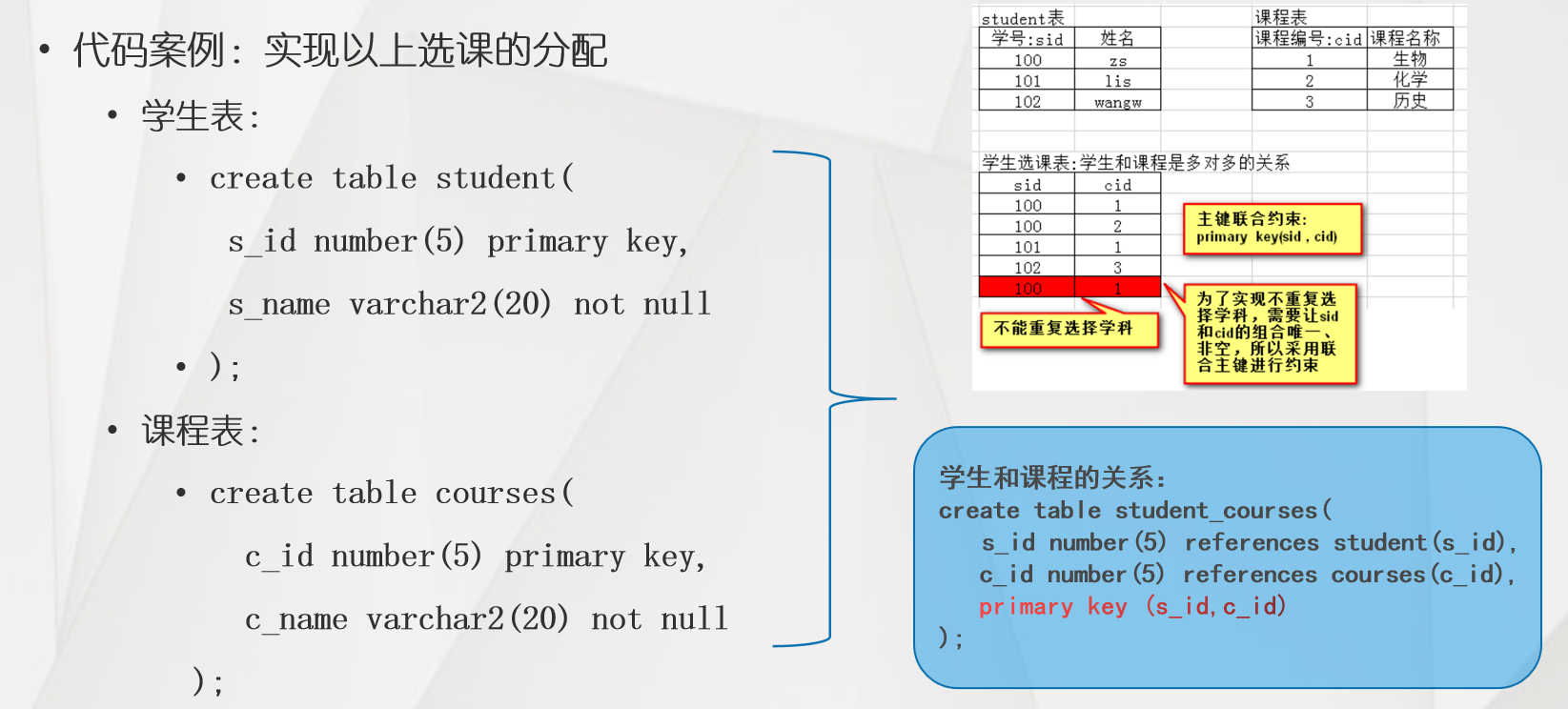
7、联合约束
- 联合约束:使用表的任意一个字段无法标识主键或唯一约束时,使用多个键的组合来进行约束
- 常见联合约束:联合主键、联合唯一约束
- 语法:
1. 联合主键:primary key(字段名1 , 字段名2)
2. 联合唯一约束:unique(字段名1 , 字段名2)
(1)创建班级表
--学生表
create table t_class(
cls_id number(10) primary key,
cls_name varchar2(20) not null
);
(2)创建学生表
- 学生学号-主键、姓名、邮箱(必须有@)、出生日期(默认当前日期)、身份证号-唯一、所在班级编号
--学生表
--学生学号-主键、姓名、邮箱(必须有@)、出生日期(默认当前日期)、身份证号-唯一、所在班级编号
create table t_student(
stu_id number(5) primary key,
stu_name varchar2(20) not null,
email varchar2(50) not null check(email like '%@%'),
birthday date default sysdate,
card_id char(18) unique,
cls_id number(5) references t_class(cls_id)
);

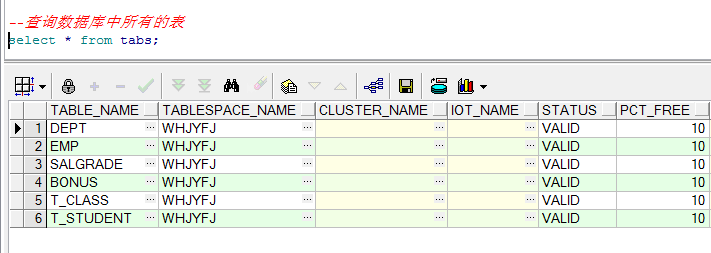
(3)查询用户下所有的表
- 注意:查询库中所有的表:select * from tabs;
--查询数据库中所有的表
select * from tabs;
(4)联合约束案例
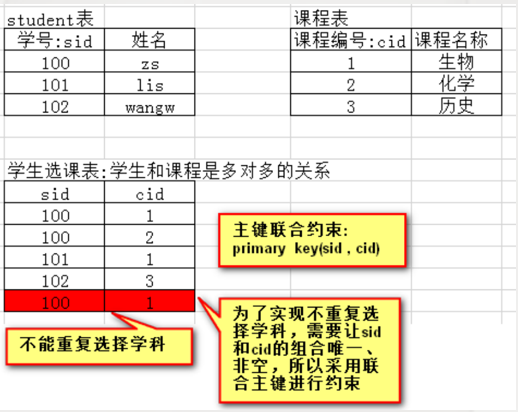
-- 学生表
create table t_student(
s_id number(5) primary key,
s_name varchar2(30) not null
);
-- 课程表
create table t_course(
c_id number(5) primary key,
c_name varchar2(30) not null
);
-- 描述:一个学生可以选择多门课程,定义关系表
create table t_sc(
s_id number(5) references t_student(s_id),
c_id number(5) references t_course(c_id),
primary key(s_id,c_id)
);
-- 插入数据
create sequence stud_seq
insert into t_student values(stud_seq.nextval,'大宝贝')
select * from t_student
create sequence cour_seq start with 100
insert into t_course values(cour_seq.nextval,'oracle')
select * from t_course
-- 往关系表中插入数据
insert into t_sc values(2,101);
-- 查询学生选课情况
select s.s_id,s_name,c.c_name from t_student s join t_sc sc on s.s_id=sc.s_id join t_course c on sc.c_id=c.c_id
where s.s_name='佳明'
四、事务(transaction)
1、什么是事务?
- 概念:数据库中最小的执行单元,通常由一条或是多条sql组成,所有sql都执行成功,事务才成功,则提交事务(commit);只要有一条sql执行失败,则事务失败,则事务回滚(rollback)
- 事务的大小取决于业务
(1) 实际开发时,一个业务对应不同条数的sql,这多条sql的组成被称为事务
(实现业务需要控制事务)
(2) 案例:
转账业务:一个账户的钱转向另一个账户
update account set balance=balance-money where id = 894893
update account set balance=balance+money where id = 242546
注意:转账的业务至少2条sql,构成一个事务(2条sql)
开户: 往account表中添加信息
insert into .....
注意:开户的业务1条sql,构成一个事务(1条sql)
- 事务的边界
(1) 开始:从第一天sql开始执行,事务开始
(2) 结束:
a. DML语句(insert/delete/update)需要明确指定结束的边界:
I. 遇到:commit,提交事务,事务成功
II.遇到: rollback,回滚事务,事务失败
b. DDL语句:创建表的语句(create table/create sequence),自动提交事务
2、回滚段:
- 数据库服务器DBServer会为每一个连接上的client,开辟一小块内存空间(称为回滚段),用于暂时存储sql语句的执行结果,所有的sql都执行成功,则提交事务(commit),会把自己回滚的数据真正的写入DB中;如果有一条sql执行失败,则事务回滚(rollback)时,则会清空自己回滚段里的数据,恢复到事务之前的结果。
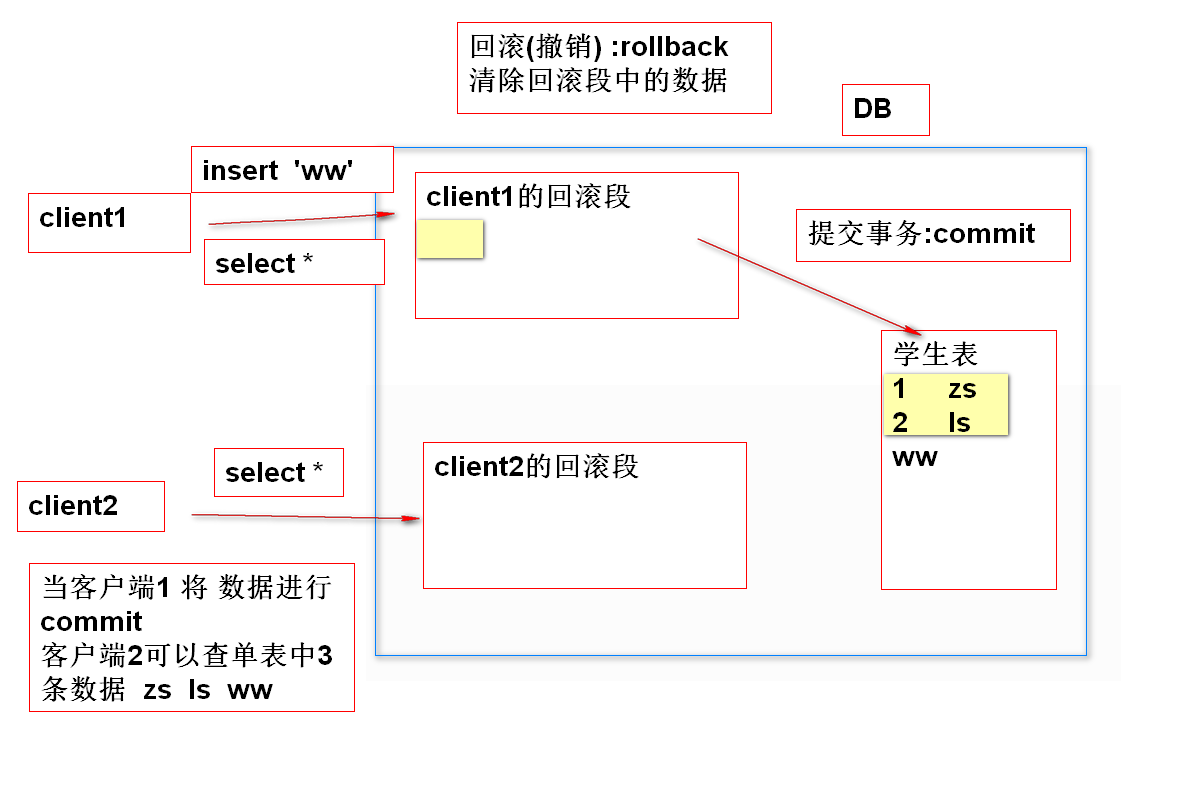
3、锁
(1) 事务的底层采用锁的机制保证数据的安全性
(2) 数据库对每条数据分配一个锁,如果一个客户端执行为insert/delete/update操作时,获取当前操作数据锁标记,只要执行到commit或是rollback时,才释放锁标记,其他的客户端才能操作当前条数据
- 注意:select 查询操作无需考虑事务。
4、事务的特点:(ACID)
(1)事务的原子性(Atomic):事务中的多个sql语句是一个整体, 要么全部成功,要么全部失
败.
(2)事务的一致性(Consistency):(数据的合理性),事务执行前后(无论失败还是成功),最
终数据是合理的.
(3) 事务的隔离型(Isolation):多个事务并发时,事务之间相互独立,互不影响
(4) 事务的持久性(Durability):事务结束(成功或失败),对数据库的数据修改时永久的.
五、数据库范式
1、什么是范式?
简单的讲,范式就是在设计数据库时应当遵循的一些规范,可以在建表时起一些指导性作用。设计数据库表时遵循范式,能够减少冗余数据,使得对数据的管理更为科学。
2、第一范式
- 第一范式的要点是字段不可再分
- 案例:对于爱好属性,实际存储的数据可能为:
编号姓名爱好1王恒杰打篮球,唱歌,打游戏2杨福君唱歌,看电影,跳舞
比如现在有需求需要修改所有电影爱好为影视,再有需求希望删除所有跳舞爱好,这些操作势必转换为对字符串的拼接、查询操作,非常不方便。
解决方法是将属性再次分割,分离到另外一张表中,变为这样
编号姓名1王恒杰2杨福君编号爱好1唱歌1打篮球1打游戏2唱歌2看电影3跳舞
3、第二范式
- 第二范式是指属性不能部分依赖主属性
- 例如:
学号 学生姓名 课程编号 课程名称 成绩
s001 张三 c001 java 90
s001 张三 c002 oracle 80
s002 李四 c002 oracle 60
s003 李四 c001 java 50
s003 王五 c002 oracle 100
如果这样设计一个表示学员选课的成绩表,表中能够起唯一标识的属性称之为主要属性,这张表中学号不能单独作为主属性,同样课程编号也不能单独作为主属性。因此有两个主要属性学号和课程编号。
成绩属性同时依赖于这两个主要属性,而学生姓名和课程名称只能部分依赖于主要属性。称学生姓名和课程名称属性为部分依赖,应当从本表分离出去。
现有表结构存在这样一些问题,例如,添加新学员会存在问题新加学员如果还没有选修课程,那么一些列必须留空;修改学员一样会有问题,张三改名张四,需要修改多条记录…
这些问题分别被成为添加异常、修改异常、删除异常,如果将这些部分依赖的属性分离出去,这些问题都可以避免,如:
学号 学生姓名
s001 张三
s002 李四
s003 王五
课程编号 课程名称
c001 java
c002 oracle
学号 课程编号 成绩
s001 c001 90
s001 c002 80
s002 c002 60
s003 c001 50
s003 c002 100
首先去除了学员和课程的一些冗余信息,其次,添加修改删除学员也不会产生异常,对于课程也是同样道理。
4、第三范式
- 第三范式是指属性不能间接依赖于主属性
- 例如:
empno ename deptno dname
7369 Smith 10 财务部
7499 Scott 10 财务部
7869 King 10 财务部
如果存在如上表结构,dname直接依赖于deptno属性,deptno直接依赖于empno主属性,这种情况称dname间接依赖于empno。
这种依赖带来的问题是,要添加一个新部门,这个部门添加到哪里呢,类似的也存在修改异常与删除异常,解决办法还是将间接依赖于主属性(empno)的属性(dname)从此表分离出去。如下所示:
empno ename deptno
7369 Smith 10
7499 Scott 10
7869 King 10
deptno dname
10 财务部
版权归原作者 小王java 所有, 如有侵权,请联系我们删除。