
一、软件准备
虚拟机(操作系统为Linux)中已有MySQL、已部署Hive。
本地主机(操作系统为Windows)中下载navicat(我用的是navicat premium 15)。
PS:其实用sqlyog也是可以连接虚拟机的Hive数据的。
在决定用navicat还是sqlyog之前,可以思考这两个问题:
①MySQL和hive的区别;
②sqlyog和navicat的区别。
对于第一个问题,我理解的最直接的区别是:MySQL的数据可以存储在本地,但是hive的数据一定是存储在分布式文件系统上的。尽管hive的操作数据的命令语法与MySQL非常接近,但hive不是MySQL。
对于第二个问题,我理解的最直接的区别是:sqlyog只支持MySQL数据库,navicat支持各种数据库。但是hive本身跟MySQL有关系(这一方面我的理解还不是很透彻,只是从查询语言的角度上去理解,因为两者的确很接近),所以连接hive要建立的是MySQL连接。
二、连接步骤
2.1 配置文件
**
/etc/ssh/sshd_config
文件**
在虚拟机中编辑/etc/ssh/sshd_config文件,将PasswordAuthentication设置成yes(如果这一行前面有#,把#删除即可)。然后使用下述命令重启sshd服务(注意:不是ssh,是sshd)。
service sshd restart
**
hive-site.xml
文件**
(此文件的位置根据每台虚拟机安装hive路径的不同而有区别。我的是/home/hive/conf/hive-site.xml)
在虚拟机中编辑hive-site.xml文件,注意要有如下内容。

其中,
ConnectionURL
表示Hive数据存储的URL链接。我的文件中写明了是在HiveDB下;
ConnectionUserName
表示登录的用户名。我的文件中写明了是root;
ConnectionPassword
表示登录的密码。我的文件中写明了是123456;
metastore.warehouse.dir
表示元数据在分布式文件系统(不是虚拟机中的文件路径)中存储的路径。我的文件中写明了是在/user/hive/warehouse。
2.2 软件操作
- 在虚拟机中开启集群。
- 在虚拟机中开启Hive。
- 打开本地主机上安装的navicat,按照如下步骤完成连接。
文件→新建连接→MySQL。
随后出现如下图所示的窗口。
先点击SSH选项卡,勾选“使用SSH通道”,然后在“主机”输入虚拟机的IP地址,“端口”保持默认的22不变;“用户名”输入虚拟机的用户名(我的是root),“密码”输入虚拟机的用户登录的密码。
然后点击测试连接。此时只填写了SSH选项卡的内容,会出现如下图所示的报错。先暂时不管。

点击这个报错信息的“确认”后,在SSH选项卡上方看到navicat能够连到SSH服务器,但是SSH服务器到数据库的连接还不成功。

注意:如果这里的密码填写错误了,不能连接到SSH服务器,会弹出如下窗口。
选项卡中也会显示如下连接情况。


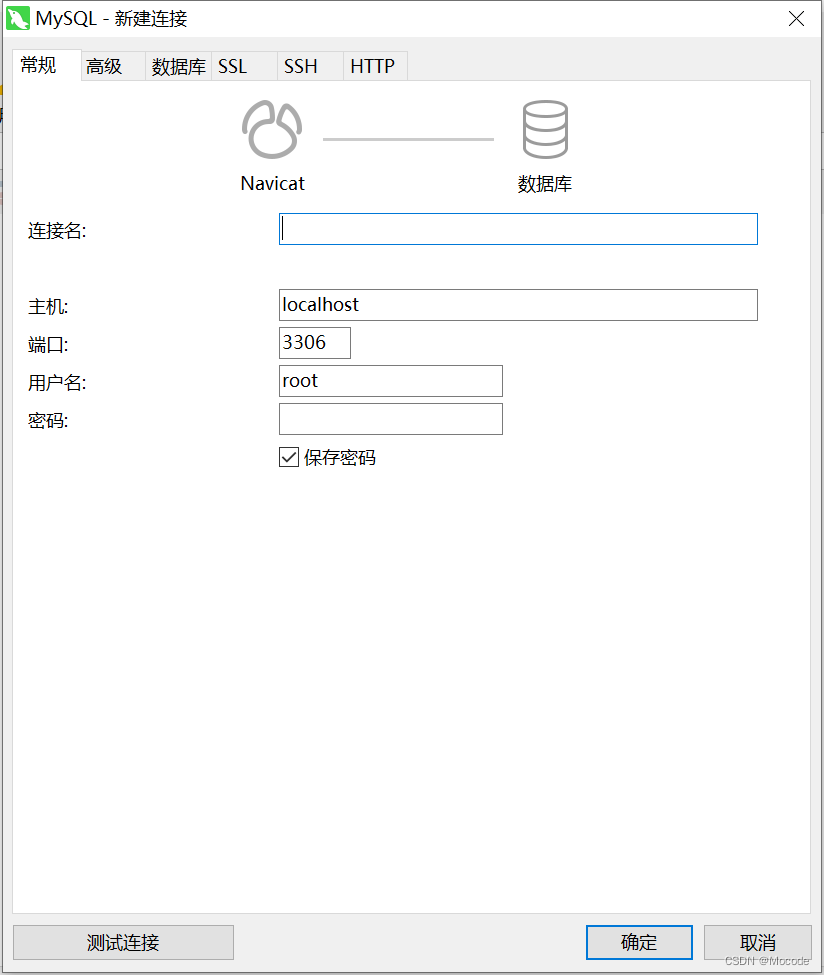
切换回“常规”选项卡,在“连接名”随便起一个名字,描述一下这个连接(比如这个连接我是用来查看虚拟机的hive数据的,那这里我就起名为“Hive”);“主机”填写虚拟机的IP地址;“端口”保持默认的3306不变;“用户名”是数据库的用户名;“密码”是登录数据库的密码(区别于登录虚拟机用户的密码,除非你的这两个密码是设置成一样的了)。

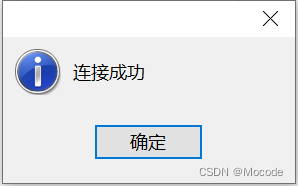
然后在“常规”选项卡点击“测试连接”,弹出如下窗口则说明连接成功。
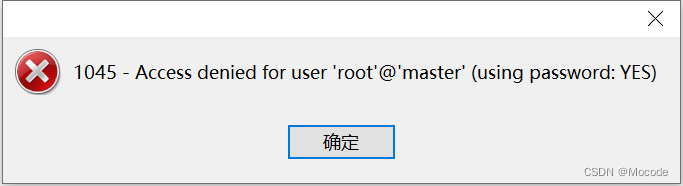
注意:如果这一步的密码写错,会弹出如下窗口。
选项卡中也会显示如下连接情况。
所以要确保两个选项卡的用户名、密码都填写正确了。

参考
有Mysql数据库的情况下为什么要用Hive数据库?
sqlyog和navicat的区别
Navicat连接虚拟机的MySQL时 提示“Password authentication failed”
Navicat连接Hive
版权归原作者 Mocode 所有, 如有侵权,请联系我们删除。