
文章目录
本文简单记录一下使用selenium webdriver和mitmproxy代理模拟用户点击抓包的过程。
用于模拟真实的用户访问网站,达到抓包的目的。
作者水平有限,可用于入门教程
安装Python
Mac
在 macOS 上,通常情况下,Python 2.x 是预安装的。要在 macOS 上安装 Python 3,您可以使用 Homebrew 软件包管理器。如果您尚未安装 Homebrew,请按照以下步骤操作:
- 打开终端(可以在 Spotlight 中搜索 “Terminal”)。
- 输入以下命令并按 Enter 键:
/bin/bash -c"$(curl-fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- 按照提示完成 Homebrew 的安装。
安装完成后,您可以使用以下命令安装 Python 3:
brew install python3
安装完成后,您可以在终端中使用
python3
命令来运行 Python 3 解释器。
Windows
- 访问官网下载页面:https://www.python.org/downloads/ 选择最新的版本或者你想要下载的版本
 根据你的系统选择安装包。
根据你的系统选择安装包。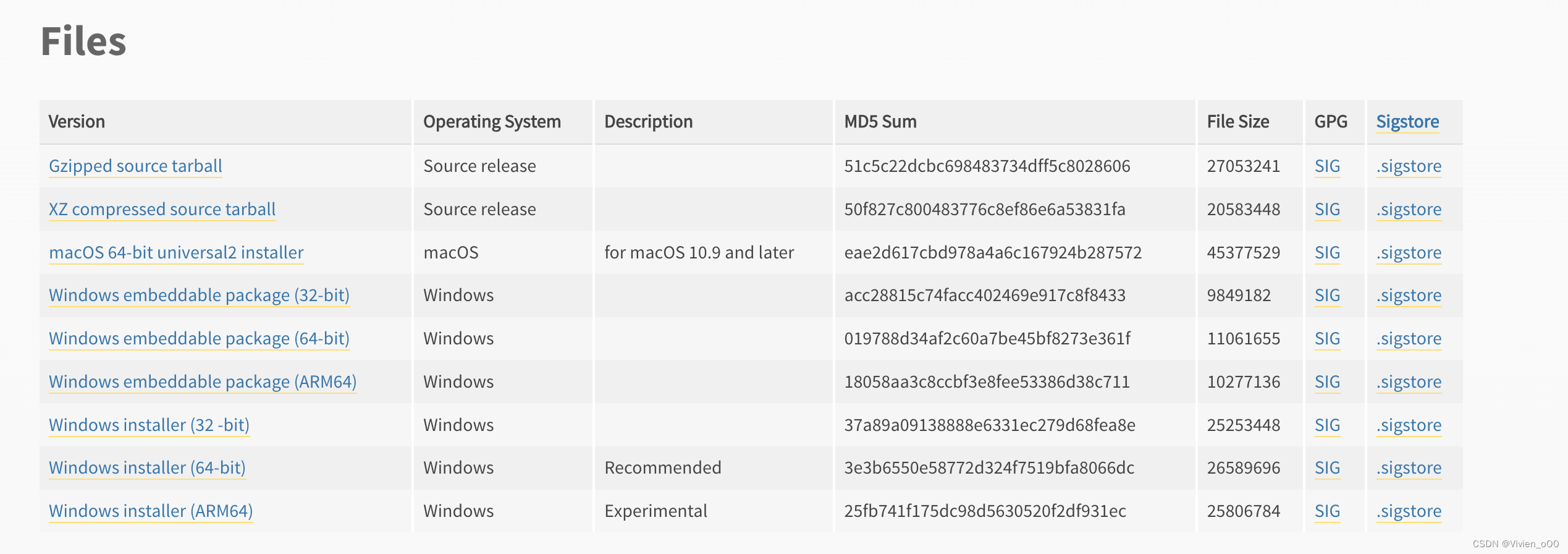
- 下载完成后,进行安装,环境变量需要勾选上。
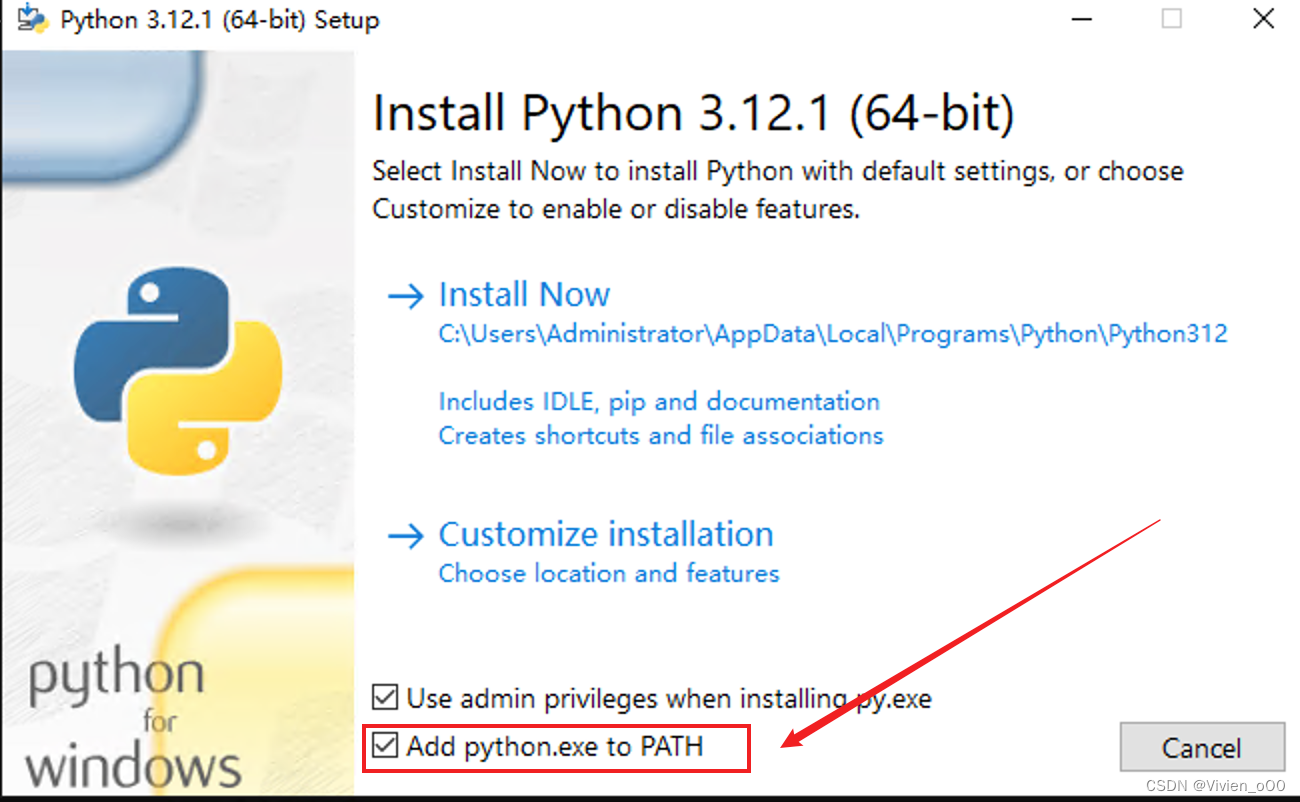
- 安装完成后,打开命令提示符(按 Win + R 键,输入
cmd并按 Enter 键),然后输入python --version检查 Python 是否已成功安装。如果看到类似 “Python 3.x.x” 的输出,则表示安装成功。
安装程序需要的依赖
安装程序需要的依赖,未列出来的可根据实际程序自行安装
pip install mitmproxy
pip install selenium
pip install requests
安装chorm驱动
与对应的chorm版本对应,浏览器版本可在设置中关于chrome查看
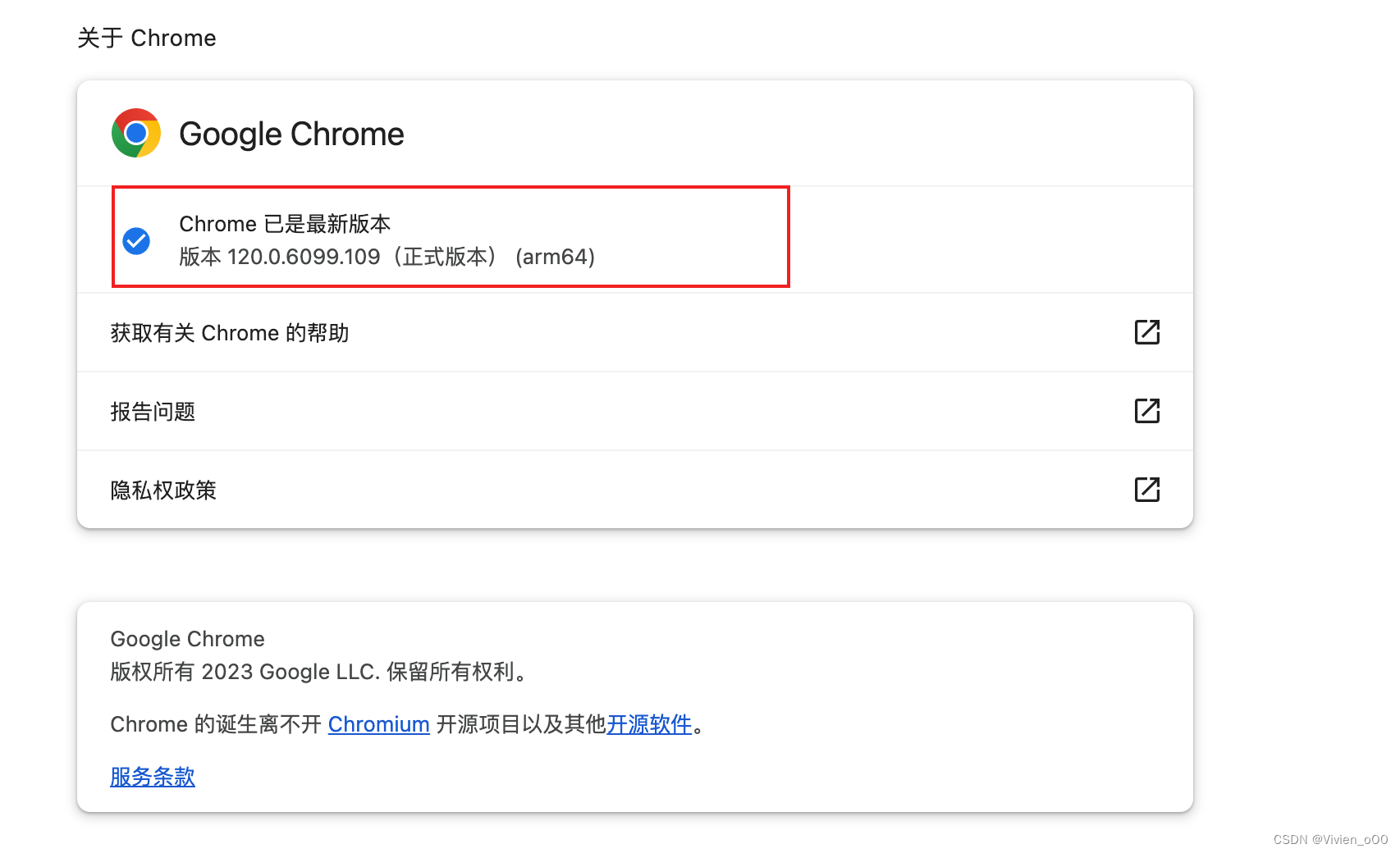
下载地址:https://chromedriver.chromium.org/downloads
编写代码
这里模拟抓取华为应用商城的app信息,可以作为参考代码 地址: https://appgallery.huawei.com/Games
自动化程序
import tab_info as tab_map 这是游戏页面所有的标签 这里手机来方便模拟点击

tab_map ={"角色扮演":{"1":"热门","2":"卡牌","3":"魔幻","4":"回合制","5":"传奇","6":"仙侠","7":"武侠"},"体闲益智":{"1":"热门","2":"体闲","3":"IO","4":"音乐节奏","5":"消除","6":"解谜","7":"益智"},"经营策略":{"1":"热门","2":"古代谋略","3":"现代战略","4":"养成","5":"塔防","6":"经营","7":"MOBA"},"体育竞速":{"1":"热门","2":"赛车","3":"运动","4":"篮球","5":"足球"},"动作射击":{"1":"热门","2":"跑酷","3":"射击","4":"格斗","5":"打飞机"},"棋牌桌游":{"1":"热门","2":"斗地主","3":"麻将","4":"桌游与棋牌","5":"纸牌","6":"捕鱼"}}
tab_arr =["角色扮演","体闲益智","经营策略","体育竞速","动作射击","棋牌桌游"]
主启动程序 tab_test.py
import tab_info as tab
import subprocess
defstart():#tab.txt 其中存储的就是索引值 1 2 3 表示取那个主分类 ,具体就是上面的tab_arrwithopen('tab.txt','r')as f:
index = f.read()
i =int(index)if i ==6:return
key = tab.tab_arr[i]
tab_base = tab.tab_map[key]for k in tab_base:print("%s"% k)print("%s"% tab_base[k])
sub_tab = tab_base[k]#这里启动具体的自动化页面
result = subprocess.run(['python','app_test.py', key, k], capture_output=True, text=True)withopen('tab.txt','w')as f:
f.write(str(i +1))if __name__ =='__main__':
start()
自动化页面 app_test.py
import asyncio
import random
import sys
import time
from selenium.webdriver import ActionChains
from selenium.webdriver.chrome.options import Options
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import tab_info as tab_map
# 这一段的含义就是模拟点击每一个标签print(sys.argv[1])print(sys.argv[2])
tab =str(sys.argv[1])
sub_tab_key =str(sys.argv[2])if tab notin tab_map.tab_map:raise"tab not exist"if sub_tab_key notin tab_map.tab_map[tab]:raise"sub_tab not exist"
sub_tab = tab_map.tab_map[tab][sub_tab_key]
chrome_options = Options()
chrome_options.add_argument("--remote-debugging-port=9222")# 忽略证书检查错误
chrome_options.add_argument("--ignore-certificate-errors")# 就是这一行告诉chrome去掉了webdriver痕迹
chrome_options.add_argument("--disable-blink-features=AutomationControlled")
chrome_options.add_argument('user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36')# 去除chrome正在受到自动测试软件的控制这句提示
chrome_options.add_experimental_option("excludeSwitches",['enable-automation']);# 配置代理服务器 这个和下载的chromedriver有关
proxy ="http://localhost:8080"# 根据实际代理服务器地址和端口进行修改
chrome_options.add_argument(f"--proxy-server={proxy}")
driver = webdriver.Chrome(options=chrome_options)# 设置浏览器窗口大小
driver.set_window_size(1600,1024)asyncdefget_list():# 打开网页 这里替换成自己想要抓的页面
url ="https://appgallery.huawei.com/Games"
driver.get(url)print(123)# try:#这一段是关闭loginbox这个类 也就是关闭登录框 没有可忽略# close_button = driver.find_element(by=By.CLASS_NAME, value="close-loginbox")# print(close_button)# close_button.click()# time.sleep(3)# except Exception as err:# print(err)## 等待span所有的标签都取出来
wait = WebDriverWait(driver,100)# 这里是取出所有的 childtab 这里的childtab是根据页面实际的class去的具体看下面图解
span_elements = wait.until(EC.presence_of_all_elements_located((By.CLASS_NAME,"childtab")))# 点击# span_elements = driver.find_elements(by=By.CLASS_NAME, value="childtab")# 先点击进分类for span in span_elements:
s = span.text
print(s)if s in tab:
ActionChains(driver).move_to_element(span).perform()
span.click()breakprint("点击了%s"% tab)
time.sleep(10)
wait = WebDriverWait(driver,100)
sub_span_elements = wait.until(EC.presence_of_all_elements_located((By.CLASS_NAME,"childtab")))# print("sub_span_elements", sub_span_elements)# 点击进子分类for sub_span in sub_span_elements:
sub = sub_span.text
print(sub)if sub in sub_tab:
ActionChains(driver).move_to_element(sub_span).perform()
sub_span.click()print("点击了%s"% sub)
time.sleep(10)break# 滚动到页面底部# driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")# print(1111111)# time.sleep(5)
count =10whileTrue:# for i in range(10):# try:# list_element = driver.find_element(by=By.CLASS_NAME, value="list-item-target")# list_element.is_selected()# driver.execute_script("arguments[0].remove()", list_element)# except Exception as err:# print(err)# 滚动到页面底部print("滚动了")
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")# try:# # submit_button = driver.find_element(by=By.CLASS_NAME, value="btn-box")# # submit_button.text# # ActionChains(driver).move_to_element(submit_button).perform()# ## # submit_button.click()# #span_element = driver.find_element(by=By.XPATH, value="//span[@class='childtab']")# span_elements = driver.find_elements(by=By.CLASS_NAME, value="childtab")# for span in span_elements:# s = span.text# print(s)# if s == '电视':# ActionChains(driver).move_to_element(span).perform()# span.click()## # print(span_element.text)# except Exception as err:# print(err)# count = count - 1# if count == 0:# driver.close()# returnwhileTrue:print("hahahahha-----1")
is_at_bottom = driver.execute_script("return window.innerHeight + window.scrollY >= document.body.scrollHeight;")if is_at_bottom:
count = count -1print("hahahahha-----2")if count ==0:
driver.close()returnbreakelse:print("hahahahha-----3")
count =10
driver.execute_script("window.scrollTo(0, window.scrollY + 100);")
num = random.randint(4,7)
time.sleep(num)asyncdefmain():
coros =[get_list()]await asyncio.gather(*coros)
asyncio.run(main())
如何查看分类标签的class?
右键选中你需要查看的标签,点击检查
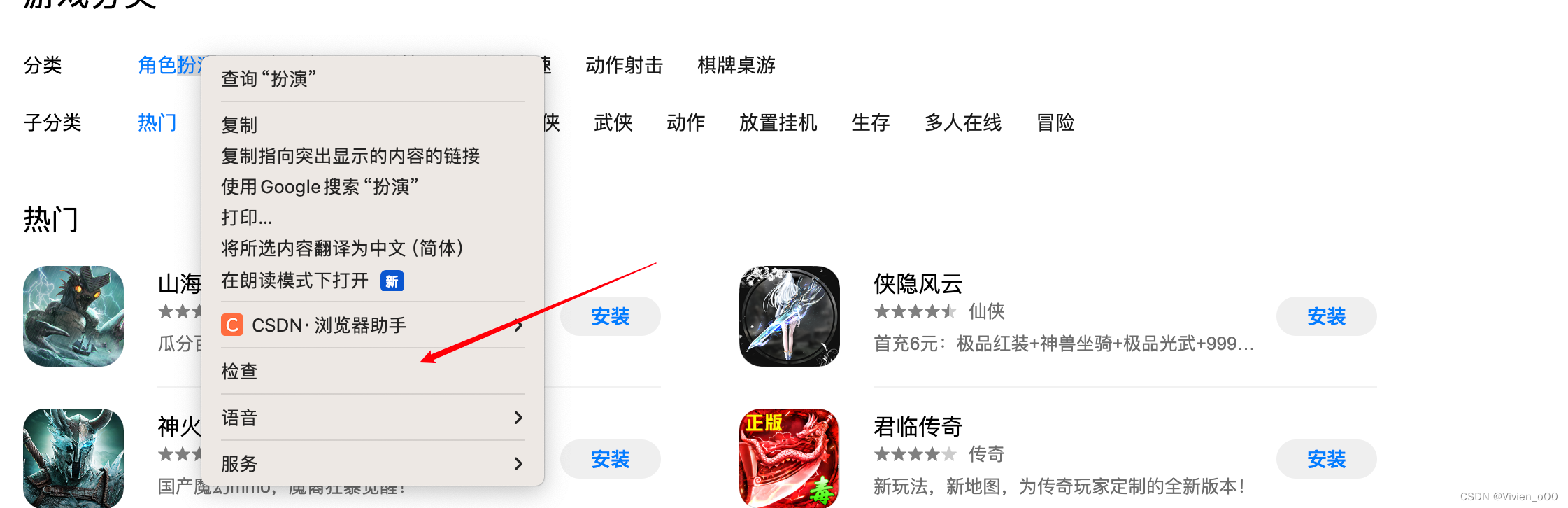
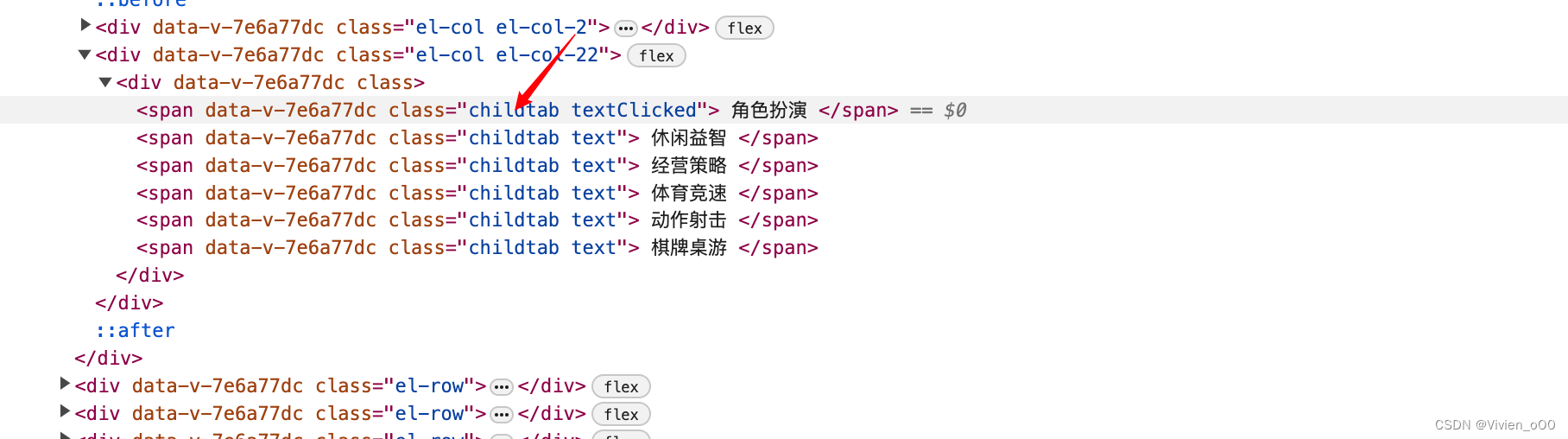
现在有一个问题就是页面却是可以自动进行滚动了,那么页面的数据有如何抓取到呢?
还记得我们之前引入的 mitmproxy包,下面我们先看具体的解析包程序。
真正抓包程序 app_joker.py
import json
from concurrent.futures import ThreadPoolExecutor
from urllib.parse import urlparse, parse_qs
from mitmproxy import http
import logging
import pymysql
import datetime
logging.basicConfig(filename='test.log', level=logging.DEBUG,format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')# logger = logging.getLogger(__name__)
pool = ThreadPoolExecutor(2)# mysql
DB_DATA_dev ={'host':'','port':3306,'connect_timeout':30,'read_timeout':10,'write_timeout':30,'user':'root','passwd':'','database':'test','charset':'utf8mb4','autocommit':True}
DB = DB_DATA_dev
hotel_count ={'count':0,}# 解析请求defrequest(flow: http.HTTPFlow):
url = flow.request.url
if'getTabDetail'notin url:return
logging.info("++++++++++++++++++ %s %s "%(type(url), url))if'appid'notin url:returnif flow.request.method !="GET":return# parsed_url = urlparse(url)# query_params = parse_qs(parsed_url.query)# page_num = query_params["reqPageNum"][0]# logger.info(# "++++++++++++++++++ ============================================================page_num:%s" % page_num)## logging.info("++++++++++++++++++ ============================================================url:%s" % url)# logging.info("++++++++++++++++++ ============================================================flow.request"# ".method:%s" % flow.request.method)# body = json.loads(flow.request.content)# json_data = flow.request.get_text()# new_json_data = json_data.replace('"pageNo: 1"', '"new_value"')# flow.request.set_text(new_json_data)# request_body = json.loads(flow.request.content)# request_body['searchCondition']['pageNo'] = hotel_count['pageIndex']# request_body['deduplication'] = []# str_req = json.dumps(request_body, ensure_ascii=False)# flow.request.set_text(str_req)# hotel_count['pageIndex'] = hotel_count['pageIndex'] + 1# flow.request.content = flow.request.content.replace('deduplication', )# 解析响应defresponse(flow: http.HTTPFlow):# 下面就是过滤你需要抓取的url 和你需要抓取的具体数据,后面我会进行说明
url = flow.request.url
# logging.info("++++++++++++++++++ %s %s " % (type(url), url))if'getTabDetail'notin url:returnif flow.request.method !="GET":returnif'appid'notin url:return# request_body = json.loads(flow.request.content)#
request_query = flow.request.query
logging.info(request_query)
logging.info("++++++++++++++++++++++++++++++++++")
logging.info(request_query['appid'])
response_body = json.loads(flow.response.content)# layout_data = response_body["layoutData"]# for value in layout_data:# data_list = value['dataList']# for data in data_list:# logging.info(data)# now = datetime.datetime.now()# now_str = now.strftime("%Y-%m-%d %H:%M:%S")# val = {## 'name': "",# "kindName": "",# "appid": "",# # 应用包id未知字段# "bundleId": "",# "sizeDesc": "",# "appVersionName": "",# "downCountDesc": "",# "score": "",# "memo": "",## # 开发者# "developer": "",# # 软件更新时间# "release_date": "",# "create_time": now_str,# }# if 'name' in data and data['name']:# val['name'] = data['name']# if 'kindName' in data and data['kindName']:# val['kindName'] = data['kindName']# if 'appid' in data and data['appid']:# val['appid'] = data['appid']# if 'sizeDesc' in data and data['sizeDesc']:# val['sizeDesc'] = data['sizeDesc']# if 'appVersionName' in data and data['appVersionName']:# val['appVersionName'] = data['appVersionName']# if 'downCountDesc' in data and data['downCountDesc']:# val['downCountDesc'] = data['downCountDesc']# if 'score' in data and data['score']:# val['score'] = data['score']# if 'memo' in data and data['memo']:# val['memo'] = data['memo']# logging.info(val)## logging.info("插入进数据库")# create_hotal(val)# logging.info(layoutData)# logging.info(json.dumps(layoutData, indent=2))
pool.submit(parse_resp, request_query, response_body)# 这里其实就是解析具体的参数 插入数据库defparse_resp(request_query, response_body):
appid = request_query['appid']# page_size = request_query['maxResults']# 分类名# kind_name = response_body['name']# sub_kind_name = ""
layout_data = response_body["layoutData"]iflen(layout_data)<9:return# 如果 layout_data 不包含索引 8 的元素,直接返回
data = layout_data[8]
data_list = data["dataList"]for data in data_list:try:
vals ={"developer":"","releaseDate":""}if'developer'in data and data['developer']:
vals['developer']= data['developer']else:continueif'releaseDate'in data and data['releaseDate']:
vals['releaseDate']= data['releaseDate']
logging.error("++++++++++++++++++vals:%s"% vals)
update_app_info(appid, vals)except Exception as err:
logging.error("++++++++++++++++++parse_resp insert test table error:%s"% err)
data = layout_data[7]
data_list = data["dataList"]for data in data_list:try:
vals ={"developer":"","releaseDate":""}if'developer'in data and data['developer']:
vals['developer']= data['developer']else:continueif'releaseDate'in data and data['releaseDate']:
vals['releaseDate']= data['releaseDate']
logging.error("++++++++++++++++++vals:%s"% vals)
update_app_info(appid, vals)except Exception as err:
logging.error("++++++++++++++++++parse_resp insert test table error:%s"% err)# for value in layout_data:# # 子分类# sub_kind_name = value['name']## data_list = value['dataList']## for data in data_list:# try:# vals = {# "app_id": "",# "developer": "",# "release_date": ""# }# if 'app_id' in data and data['app_id']:# vals['app_id'] = data['app_id']# if 'developer' in data and data['developer']:# vals['developer'] = data['developer']# if 'release_date' in data and data['release_date']:# vals['release_date'] = data['release_date']## if vals['app_id'] == "":# break## update_app_info(vals)# except Exception as err:# logging.error("++++++++++++++++++parse_resp insert test table error:%s" % err)# 创建插入日志# create_hotel_request_log(page_num, page_size, kind_name, sub_kind_name)# def create_hotel_request_log(page, size, kind_name, sub_kind_name):# global cursor, conn# insert_id = 0# try:# now = datetime.datetime.now()# now_str = now.strftime("%Y-%m-%d %H:%M:%S")# mysql = {'host': DB['host'], 'port': DB['port'], 'user': DB['user'],# 'passwd': DB['passwd'], 'db': DB['database'], 'charset': DB['charset']}# conn = pymysql.connect(**mysql)# cursor = pymysql.cursors.SSCursor(conn)# sql = "insert into t_app_info_log( page,size,kind_name,sub_kind_name,create_time) " \# "values ('%s', '%s','%s','%s','%s')" % (page, size, kind_name, sub_kind_name, now_str)# cursor.execute(sql)# conn.commit()# insert_id = cursor.lastrowid## except Exception as err:# logging.error("sql:%s" % err)# logging.error("++++++++++++++++++ response insert t_hotel_request_log error:%s" % err)# cursor.close()# conn.close()# return insert_iddefcreate_hotel_request_log(page, size, kind_name, sub_kind_name):global cursor, conn
insert_id =0try:
now = datetime.datetime.now()
now_str = now.strftime("%Y-%m-%d %H:%M:%S")
mysql ={'host': DB['host'],'port': DB['port'],'user': DB['user'],'passwd': DB['passwd'],'db': DB['database'],'charset': DB['charset'],'autocommit': DB['autocommit'],'connect_timeout': DB['connect_timeout']}
conn = pymysql.connect(**mysql)
cursor = pymysql.cursors.SSCursor(conn)
sql ="INSERT INTO t_app_info_log(page, size, kind_name, sub_kind_name, create_time) VALUES (%s, %s, %s, %s, %s)"
cursor.execute(sql,(page, size, kind_name, sub_kind_name, now_str))
conn.commit()
insert_id = cursor.lastrowid
except Exception as err:
logging.error("++++++++++++++++++ response insert t_hotel_request_log error:%s"% err)finally:
cursor.close()
conn.close()return insert_id
# def create_hotal(vals):# global cursor, conn# insert_id = 0## try:# mysql = {'host': DB['host'], 'port': DB['port'], 'user': DB['user'],# 'passwd': DB['passwd'], 'db': DB['database'], 'charset': DB['charset']}# conn = pymysql.connect(**mysql)# cursor = conn.cursor()# # cursor = pymysql.cursors.SSCursor(conn)# sql = "insert into t_app_info(name,kind_name,appid,bundle_id,size,app_version,down_count," \# "score,memo,developer,release_data,create_time) " \# "values ('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')"## cursor.execute(sql, (# vals['name'], vals['kindName'], vals['appid'], vals['bundleId'], vals['sizeDesc'],# vals['appVersionName'],# vals['downCountDesc'], vals['score'], vals['memo'], vals['developer'], vals['release_date'],# vals['create_time']))# conn.commit()# insert_id = cursor.lastrowid# logging.debug("++++++++++++++++++ response insert t_hotel_info success insert_id %d" % insert_id)## except Exception as err:# logging.error("sql:%s" % sql)# logging.error("++++++++++++++++++ response insert test table error:%s" % err)# finally:# cursor.close()# conn.close()# return insert_iddefcreate_hotal(vals):# global cursor, conn
insert_id =0try:
mysql ={'host': DB['host'],'port': DB['port'],'user': DB['user'],'passwd': DB['passwd'],'db': DB['database'],'charset': DB['charset'],'autocommit': DB['autocommit'],'connect_timeout': DB['connect_timeout']}
conn = pymysql.connect(**mysql)
cursor = conn.cursor()
sql ="INSERT INTO t_app_info(name, platform,kind_name, appid, bundle_id, size, " \
"app_version, " \
"down_count, score, memo, developer, release_data, " \
"create_time,app_market,icon,developer_address) VALUES (%s,%s, %s, %s, %s, " \
"%s," \
" %s, %s, %s, %s, %s," \
" %s, %s,%s,%s,%s)"# {'name': '快手极速版', 'kindName': '影音娱乐', 'appid': 'C100404489',# 'bundleId': '', 'sizeDesc': '55.3 MB', 'appVersionName': '11.10.40.6934',# 'downCountDesc': '185 亿次安装', 'score': '4', 'memo': '看视频看直播领红包',# 'developer': '', 'release_date': '', 'create_time': '2023-11-30 17:24:34'}
cursor.execute(sql,(
vals['name'], vals['platform'], vals['kindName'], vals['appid'], vals['bundleId'], vals['sizeDesc'],
vals['appVersionName'],
vals['downCountDesc'], vals['score'], vals['memo'], vals['developer'], vals['release_date'],
vals['create_time'], vals['app_market'], vals['icon'],vals['developer_address']))
conn.commit()
insert_id = cursor.lastrowid
logging.debug("++++++++++++++++++ response insert t_hotel_info success insert_id %d"% insert_id)except Exception as err:
logging.error("++++++++++++++++++ response insert test table error:%s"% vals)
logging.error("++++++++++++++++++ response insert test table error:%s"% err)finally:
cursor.close()
conn.close()return insert_id
defget_app_info(code):
result =Nonetry:
mysql ={'host': DB['host'],'port': DB['port'],'user': DB['user'],'passwd': DB['passwd'],'db': DB['database'],'charset': DB['charset']}
conn = pymysql.connect(**mysql)
cursor = pymysql.cursors.SSCursor(conn)
sql ="SELECT * FROM t_app_info WHERE appid = '%s'"% code
cursor.execute(sql)
result = cursor.fetchone()except Exception as err:
logging.error("++++++++++++++++++ query test table error:%s"% err)finally:
cursor.close()
conn.close()return result isnotNonedefupdate_app_info(appid, vals):try:
mysql ={'host': DB['host'],'port': DB['port'],'user': DB['user'],'passwd': DB['passwd'],'db': DB['database'],'charset': DB['charset'],'autocommit': DB['autocommit'],'connect_timeout': DB['connect_timeout']}
conn = pymysql.connect(**mysql)
cursor = conn.cursor()
sql ="UPDATE t_app_info SET developer=%s,release_data=%s WHERE appid = %s"# {'name': '快手极速版', 'kindName': '影音娱乐', 'appid': 'C100404489',# 'bundleId': '', 'sizeDesc': '55.3 MB', 'appVersionName': '11.10.40.6934',# 'downCountDesc': '185 亿次安装', 'score': '4', 'memo': '看视频看直播领红包',# 'developer': '', 'release_date': '', 'create_time': '2023-11-30 17:24:34'}
cursor.execute(sql,(vals['developer'], vals['releaseDate'], appid))
conn.commit()
insert_id = cursor.lastrowid
print(appid)print(vals)print("++++++++++++++++++ response update table success insert_id %d"% insert_id)except Exception as err:print("++++++++++++++++++ response update test table error:%s"% vals)print("++++++++++++++++++ response update test table error:%s"% err)finally:
cursor.close()
conn.close()return insert_id
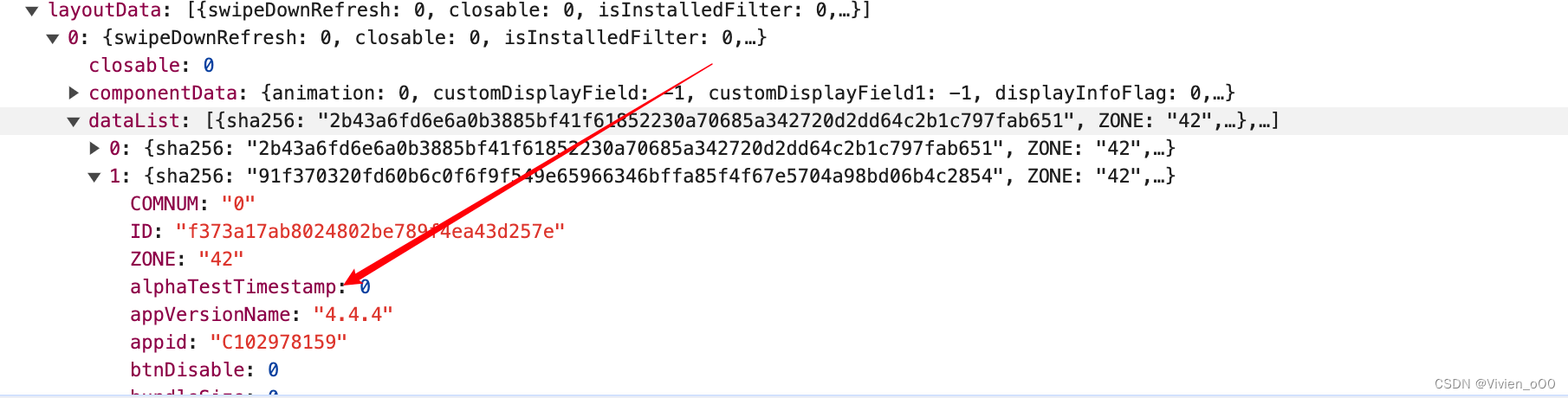
比如我们这里需要抓取的是app的数据,那么在页面按下F12点击Netword,刷新页面
左边会有一些请求的url,找到我们需要的那一个

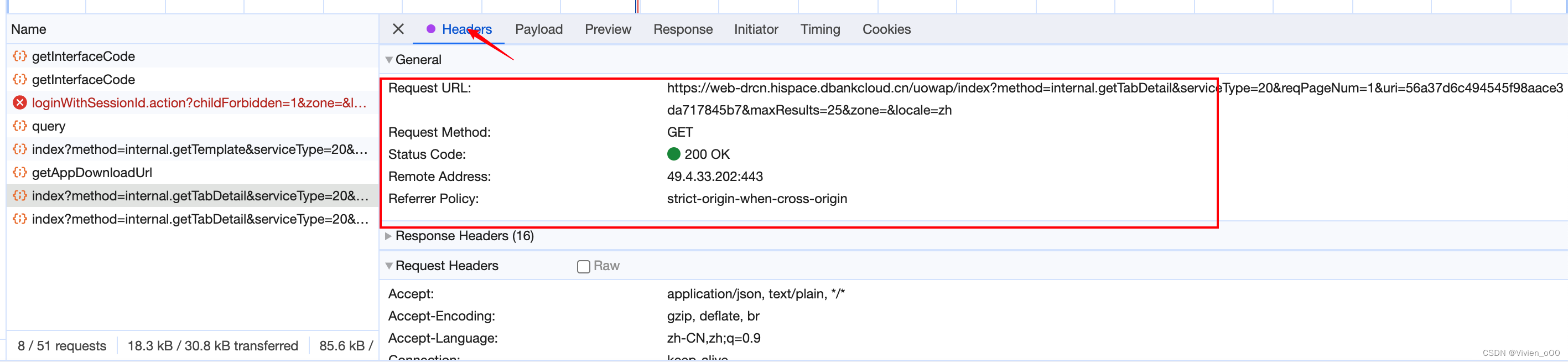
head中会显示方法的请求方式POST、Get,以及url中的关键词,我们可以根据这些过滤一些包,这个在程序中也有体现。
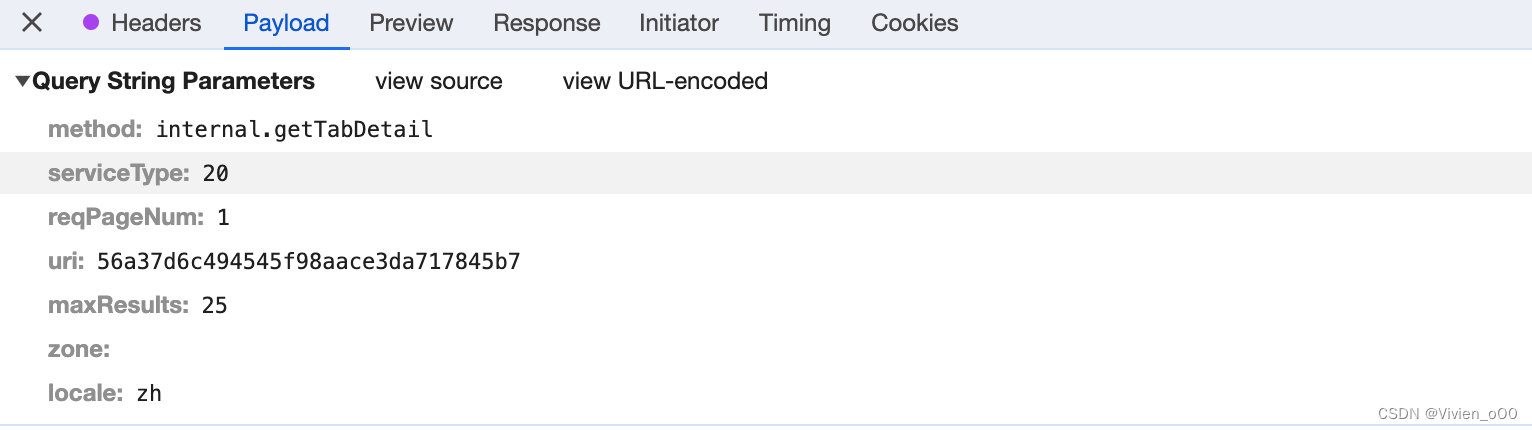
Payload就是一些请求参数,有需要的也可以拿下来
preview/Response就是我们真正需要关注的地方,这里是响应的包。然后找到你需要的包体,进行解析,然后保存下来,保存下来即可,可以参考上面的代码和这里方便理解。
开始抓包
- 首先打开chromedriver,双击运行即可,成功运行可以显示具体的提示。

- mitmweb -s app_joker.py 这里就是启动抓包的程序,这里会将我们请求的响应就行解析处理。

- 启动主程序 使用 python 直接启动即可. python3 tab_test.py 我这里是python3程序会直接打开浏览器模拟用户
可以看到代理也抓到了具体的请求
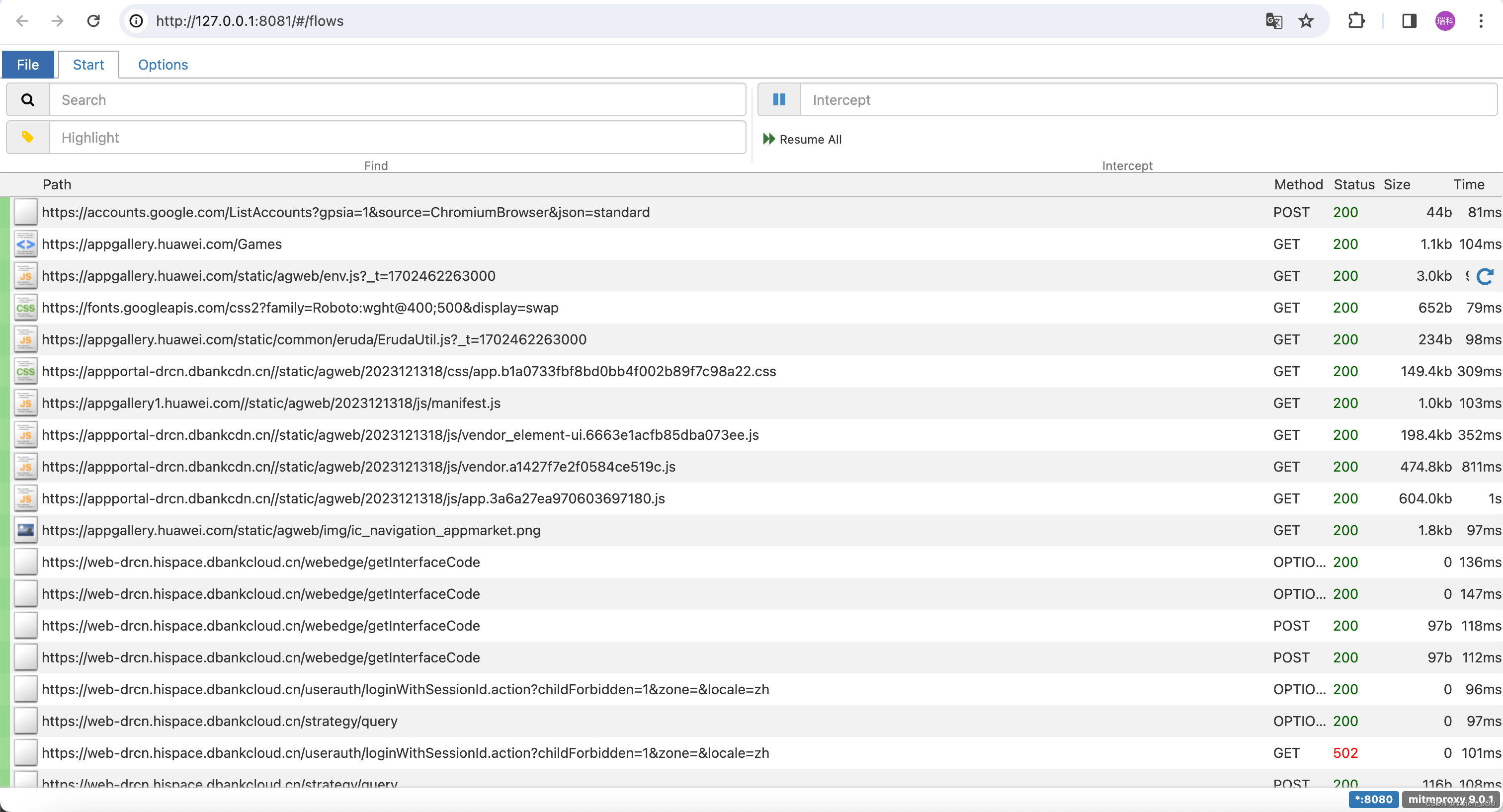
抓到的数据

问题处理
如果在运行其中遇到具体的问题,可以多打点日志,配合报错信息进行观察查看
版权归原作者 Vivien_oO0 所有, 如有侵权,请联系我们删除。