
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
最近公司在搞大数据数字化,有MES,CIM,WorkFlow等等N多的系统,不同的数据源DB,需要将这些不同的数据源DB里的数据进行整治统一中间库,这就需要用到ETL
提示:以下是本篇文章正文内容,下面案例可供参考
一、ETL工具是什么?
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据, ETL是BI(商业智能)项目重要的一个环节。ETL工具有DataX,Kettle,Sqoop等
Kettle组成部分:
二、使用步骤
1.Kettle软件环境
操作系统:Windows Server 2012
虚机机:Java JDK
ETL工具:Kettle
2.ETL工具Kettle组件
Kettle中有两种脚本文件,transformation(转换)和job(作业),transformation完成针对数据的基础转换,job则完成整个工作流的控制
Transformation(转换):
是由一系列被称之为step(步骤)的逻辑工作的网络。转换本质上是数据流。下图是一个转换的例子,这个转换从文本文件中读取数据,过滤,然后排序,最后将数据加载到数据库。本质上,转换是一组图形化的数据转换配置的逻辑结构,转换的两个相关的主要组成部分是step(步骤)和hops(节点连接),转换文件的扩展名是.ktr。
Jobs(作业):
是基于工作流模型的,协调数据源、执行过程和相关依赖性的ETL活动,Jobs(工作)将功能性和实体过程聚合在了一起,工作由工作节点连接、工作实体和工作设置组成,工作文件的扩展名是.kjb。
三、实例-增量同步数据
1.配置表的设计
CIM_ETL_TABLE
首先我们需要一张配置表,来保存我们要增量同步的表的基本信息
一些基础表
-- 源表
VM_STATE_HISTORYS
-- 中间表
CIM_STAGING_STATE_HISTORYS
-- 目标表
CIM_STATE_HISTORYS
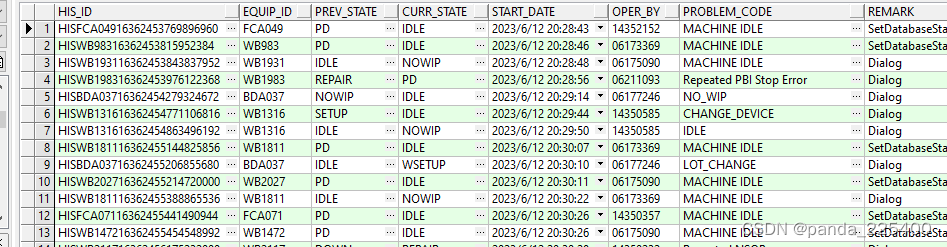
2.创建Transformation(转换)
这边我是创建了两个Transformation(转换)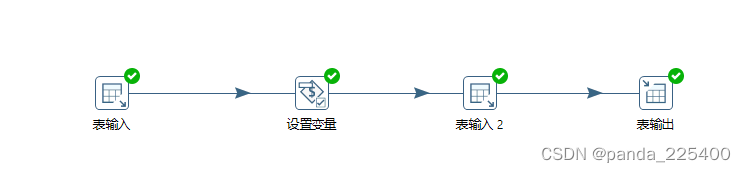
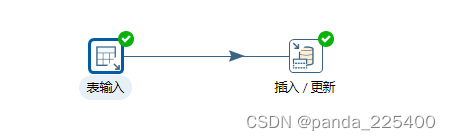
3.Jobs(作业)
1、创建Job
2、设置定时执行(双击Start)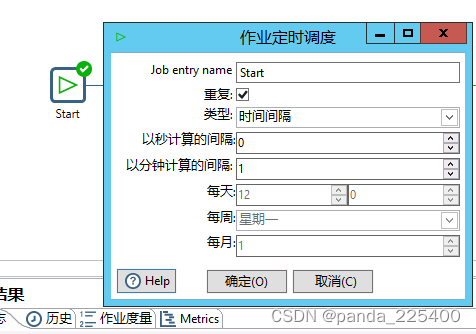
4.设置变量
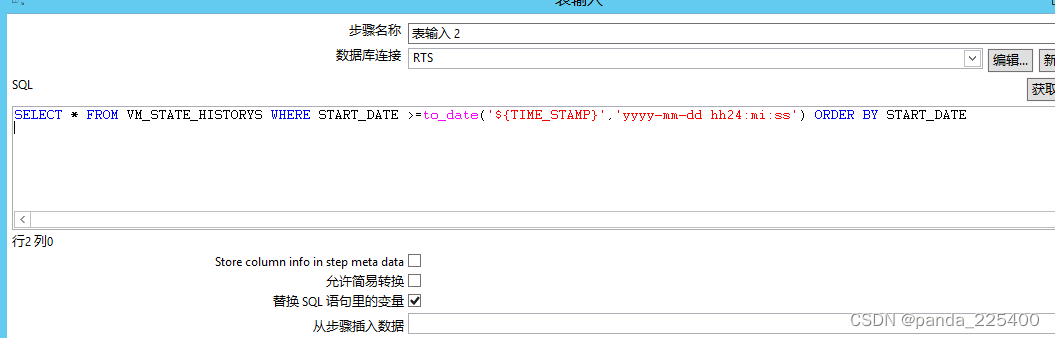
5.执行成功
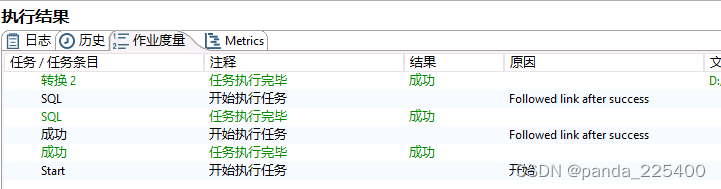
总结
记录点滴滴,这ETL工具还支持hadoop Hbase,
本文转载自: https://blog.csdn.net/panda_225400/article/details/131177154
版权归原作者 panda_225400 所有, 如有侵权,请联系我们删除。
版权归原作者 panda_225400 所有, 如有侵权,请联系我们删除。