
文章目录
一、【SparkCore篇】项目实战—电商用户行为分析
前言:数据准备
我们看看在实际的工作中如何使用这些 API 实现具体的需求。这些需求是电商网站的真实需求,所以在实现功能前,咱们必须先将数据准备好。

上面的数据图是从数据文件中截取的一部分内容,表示为电商网站的用户行为数据,主要包含用户的 4 种行为:搜索,点击,下单,支付。
1、数据规则如下:
- 数据文件中每行数据采用下划线分隔数据
- 每一行数据表示用户的一次行为,这个行为只能是 4 种行为的一种
- 如果搜索关键字为 null,表示数据不是搜索数据
- 如果点击的品类 ID 和产品 ID 为-1,表示数据不是点击数据
- 针对于下单行为,一次可以下单多个商品,所以品类 ID 和产品 ID 可以是多个,id 之间采用逗号分隔,如果本次不是下单行为,则数据采用 null 表示
- 支付行为和下单行为类似
2、详细字段说明:
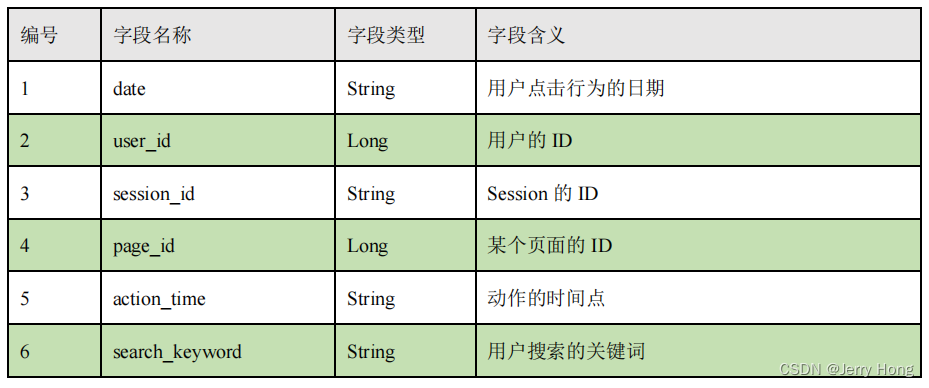
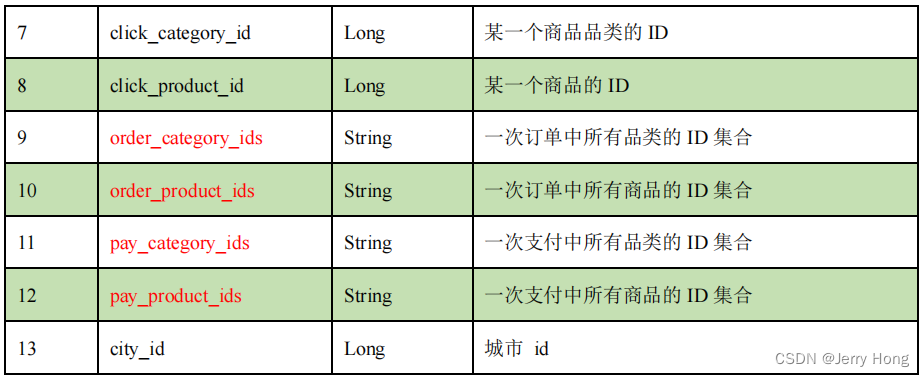
3、样例类
//用户访问动作表caseclass UserVisitAction(
date:String,//用户点击行为的日期
user_id:Long,//用户的 ID
session_id:String,//Session 的 ID
page_id:Long,//某个页面的 ID
action_time:String,//动作的时间点
search_keyword:String,//用户搜索的关键词
click_category_id:Long,//某一个商品品类的 ID
click_product_id:Long,//某一个商品的 ID
order_category_ids:String,//一次订单中所有品类的 ID 集合
order_product_ids:String,//一次订单中所有商品的 ID 集合
pay_category_ids:String,//一次支付中所有品类的 ID 集合
pay_product_ids:String,//一次支付中所有商品的 ID 集合
city_id:Long)//城市 id
(一)需求1:TOP10热门品类

1、需求说明
不同的公司可能对热门的定义不一样。我们按照每个品类的点击、下单、支付的量来统计热门品类。
本项目需求优化为:先按照点击数排名,靠前的就排名高;如果点击数相同,再比较下单数;下单数再相同,就比较支付数。
2、代码实现方案1
packagereqimportorg.apache.spark.rdd.RDD
importorg.apache.spark.{SparkConf, SparkContext}object Spark01_req01_HotCategeryTop10 {def main(args: Array[String]):Unit={//TODO 热门品类val sparkconf: SparkConf =new SparkConf().setAppName("hotCategery").setMaster("local[*]")val sc: SparkContext =new SparkContext(sparkconf)//1、读取原始日志数据val actionRDD: RDD[String]= sc.textFile("data/user_visit_action.txt")
actionRDD.cache()//调用缓存//2、统计品类的点击数量:(品类id,点击数量)val clickActionRDD: RDD[String]= actionRDD.filter(
action =>{val datas = action.split("_")
datas(6)!="-1"})val clickcountRDD: RDD[(String,Int)]= clickActionRDD.map(
action =>{val datas = action.split("_")(datas(6),1)}).reduceByKey(_ + _)
clickcountRDD.sortBy(_._2,false).take(10).foreach(println)//3、统计品类的下单数量:(品类id,下单数量)val orderActionRDD: RDD[String]= actionRDD.filter(
action =>{val datas = action.split("_")
datas(8)!="null"//下单不为null值})//orderid=>1,2,3 【(1,1),(2,1),(3,1)】//1个order拆分成多个商品val ordercountRdd: RDD[(String,Int)]= orderActionRDD.flatMap(
action =>{val datas = action.split("_")val cid:String= datas(8)val cids: Array[String]= cid.split(",")
cids.map(id =>(id,1))}).reduceByKey(_ + _)
ordercountRdd.sortBy(_._2).take(10).foreach(println)//4、统计品类的支付数量:(品类id,支付数量)val payActionRDD: RDD[String]= actionRDD.filter(
action =>{val datas = action.split("_")
datas(10)!="null"//下单不为null值})//orderid=>1,2,3 【(1,1),(2,1),(3,1)】val paycountRdd: RDD[(String,Int)]= payActionRDD.flatMap(
action =>{val datas = action.split("_")val cid:String= datas(10)val cids: Array[String]= cid.split(",")
cids.map(id =>(id,1))}).reduceByKey(_ + _)
paycountRdd.sortBy(_._2).take(10).foreach(println)//5、将品类进行排序,并且取前10名// 点击数量排序,下单数量排序,支付数量排序 => 使用元组排序:先比较第1个,再比较第2个,再比较第3个// (品类ID,(点击数量,下单数量,支付数量)),后面的括号构成一个元组//join:从原则上,点击、下单、支付并非一定存在,会出现一些商品点击数很多,但是没有支付的情况,所以不用join//leftoutjoin:有些商品可能没有浏览页点击,直接通过下单进入,所以leftoutjoin也不合适// cogroup=connect+groupval cogroupRDD: RDD[(String,(Iterable[Int], Iterable[Int], Iterable[Int]))]=
clickcountRDD.cogroup(ordercountRdd, paycountRdd)val analysisRDD = cogroupRDD.mapValues {case(clickIter, orderIter, payIter)=>{var clickcnt =0val iter1 = clickIter.iterator //Iterator(迭代器)itif(iter1.hasNext){//it.hasNext() 用于检测集合中是否还有元素
clickcnt = iter1.next()//it.next() 会返回迭代器的下一个元素}var ordercnt =0val iter2 = orderIter.iterator
if(iter2.hasNext){
ordercnt = iter2.next()}var paycnt =0val iter3 = payIter.iterator
if(iter3.hasNext){
paycnt = iter3.next()}(clickcnt, ordercnt, paycnt)}}val resultRDD: Array[(String,(Int,Int,Int))]= analysisRDD.sortBy(_._2,false).take(10)//6、将结果采集到控制台打印出来
resultRDD.foreach(println)
sc.stop()}}
(二)需求2:TOP10热门品类中每个品类的TOP10活跃Session统计
1、需求说明
在需求1的基础上,增加每个品类用户session的点击统计
2、需求分析
- 过滤原始数据,保留点击和前10品类ID
- 根据品类ID和sessionID进行点击量的统计
- 将统计结果进行结构转换:((品类ID,sessionID),sum)=> (品类ID,(sessionID,sum))
- 相同品类进行分组groupByKey
- 将分组后的数据进行点击量的排序,取前10名
3、代码实现
packagereqimportorg.apache.spark.rdd.RDD
importorg.apache.spark.{SparkConf, SparkContext}object Spark05_req02_HotTop10Session {def main(args: Array[String]):Unit={//TODO 热门品类val sparkconf: SparkConf =new SparkConf().setAppName("hotCategery").setMaster("local[*]")val sc: SparkContext =new SparkContext(sparkconf)//1、读取原始日志数据val actionRDD: RDD[String]= sc.textFile("data/user_visit_action.txt")
actionRDD.cache()//调用缓存val top10IDS: Array[String]= top10category(actionRDD)//1、过滤原始数据,保留点击和前10品类IDval filteractionRDD: RDD[String]= actionRDD.filter(
action =>{val datas: Array[String]= action.split("_")if(datas(6)!="-1"){
top10IDS.contains(datas(6))}else{false}})//2、根据品类ID和sessionID进行点击量的统计val reduceRDD: RDD[((String,String),Int)]= filteractionRDD.map(
action =>{val datas: Array[String]= action.split("_")((datas(6), datas(2)),1)}).reduceByKey(_ + _)//3、将统计结果进行结构转换//((品类ID,sessionID),sum)=> (品类ID,(sessionID,sum))val mapRDD: RDD[(String,(String,Int))]= reduceRDD.map {case((cid, sid), sum)=>{(cid,(sid, sum))}}//4、相同品类进行分组val groupRDD: RDD[(String, Iterable[(String,Int)])]= mapRDD.groupByKey()//5、将分组后的数据进行点击量的排序,取前10名val resultRDD: RDD[(String, List[(String,Int)])]= groupRDD.mapValues(
iter =>{
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(10)})
resultRDD.collect().foreach(println)
sc.stop()}def top10category(actionRDD: RDD[String])={val flatRDD: RDD[(String,(Int,Int,Int))]= actionRDD.flatMap(
action =>{val datas = action.split("_")if(datas(6)!="-1"){//点击的场合
List((datas(6),(1,0,0)))}elseif(datas(8)!="null"){//下单的场合val ids = datas(8).split(",")
ids.map(id =>(id,(0,1,0)))}elseif(datas(10)!="null"){//支付的场合val ids = datas(10).split(",")
ids.map(id =>((id,(0,0,1))))}else{
Nil
}})val analysisRDD = flatRDD.reduceByKey((t1, t2)=>{(t1._1 + t2._1, t1._2 + t2._2, t1._3 + t2._3)})
analysisRDD.sortBy(_._2,false).take(10).map(_._1)}}
(三)需求 3:页面单跳转换率统计
1、需求说明
1)页面单跳转化率
- 计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次 Session 过程中,访问的页面路径 3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳,那么单跳转化率就是要统计页面点击的概率。
- 比如:计算 3-5 的单跳转化率,先获取符合条件的 Session 对于页面 3 的访问次数(PV) 为 A,然后获取符合条件的 Session 中访问了页面 3 又紧接着访问了页面 5 的次数为 B,那么 B/A 就是 3-5 的页面单跳转化率。

2)指标意义
- 这个指标可以用来分析,整个网站,产品,各个页面的表现怎么样,是不是需要去优化产品的布局;吸引用户最终可以进入最后的支付页面。
2、需求分析
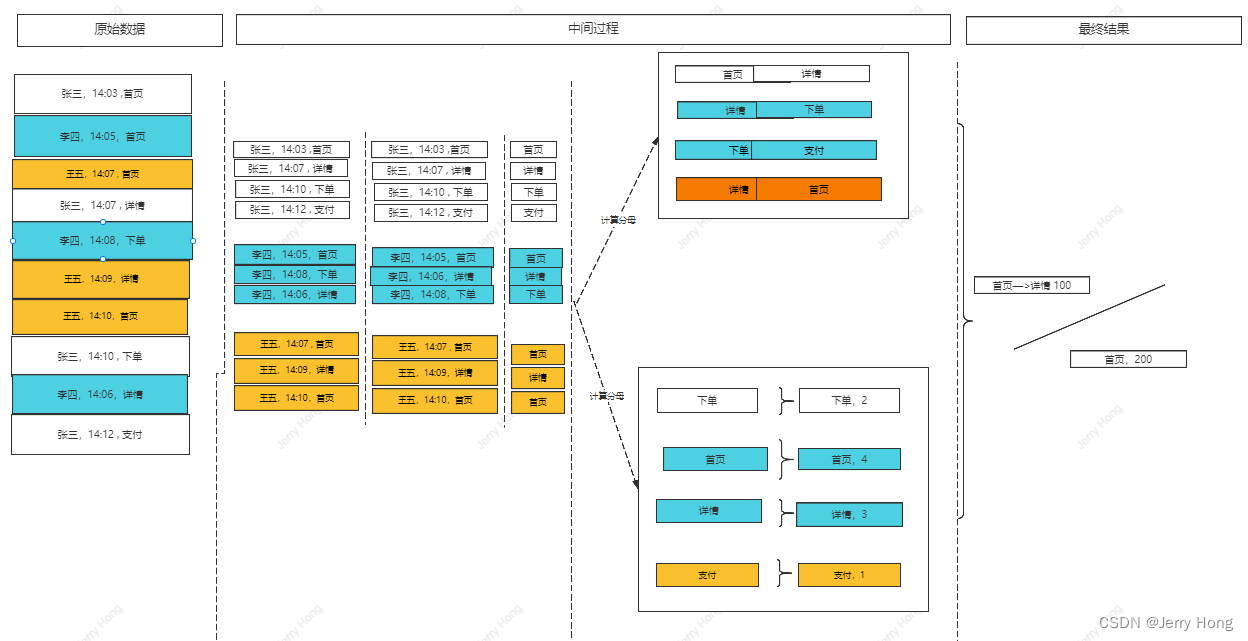
3、功能实现
packagereqimportorg.apache.spark.rdd.RDD
importorg.apache.spark.{SparkConf, SparkContext}object Spark06_req03_PageflowAnalysis {def main(args: Array[String]):Unit={//TODO 热门品类val sparkconf: SparkConf =new SparkConf().setAppName("hotCategery").setMaster("local[*]")val sc: SparkContext =new SparkContext(sparkconf)//读取原始日志数据val actionRDD: RDD[String]= sc.textFile("data/user_visit_action.txt")
actionRDD.cache()//调用缓存val actiondataRDD= actionRDD.map(
action =>{val datas= action.split("_")
UserVisitAction(
datas(0),
datas(1).toLong ,
datas(2),
datas(3).toLong ,
datas(4),
datas(5),
datas(6).toLong,
datas(7).toLong ,
datas(8),
datas(9),
datas(10),
datas(11),
datas(12).toLong,)})//TODO 对指定的页面连续跳转进行统计;统计页面1-6的跳转率// 1-2,2-3,3-4,4-5,5-6,6-7val ids: List[Int]= List(1,2,3,4,5,6,7)val okflowids = ids.zip(ids.tail)//TODO 计算分母val pageidcount= actiondataRDD.filter(
action =>{
ids.init.contains(action.page_id)}).map(
action =>{(action.page_id,1L)}).reduceByKey(_ + _).collect().toMap
//TODO 计算分子//根据session进行分组val sessionRDD: RDD[(String, Iterable[UserVisitAction])]= actiondataRDD.groupBy(_.session_id)//分组后,根据访问时间进行排序(升序)val mvRDD = sessionRDD.mapValues(
iter =>{val sortList: List[UserVisitAction]= iter.toList.sortBy(_.action_time)//[1,2,3,4]//[1,2].[2,3],[3,4] => 滑窗slidingval flowids: List[Long]= sortList.map(_.page_id)val pageflowids: List[(Long,Long)]= flowids.zip(flowids.tail)//将不合法的页面过滤
pageflowids.filter(
t=>{
okflowids.contains(t)}).map(
t =>{(t,1)})})//((1,2),1)val flatRDD: RDD[((Long,Long),Int)]= mvRDD.map(_._2).flatMap(list => list)//((1,2),1) => ((1,2),sum)val dataRDD: RDD[((Long,Long),Int)]= flatRDD.reduceByKey(_ + _)//TODO 计算单跳转换率:分子/分母
dataRDD.foreach{case((pageid1,pageid2),sum)=>{val lon= pageidcount.getOrElse(pageid1,0L)
println(s"页面${pageid1}跳转到页面${pageid2}单跳转换率为:"+( sum.toDouble / lon))}}
sc.stop()}caseclass UserVisitAction(
date:String,//用户点击行为的日期
user_id:Long,//用户的 ID
session_id:String,//Session 的 ID
page_id:Long,//某个页面的 ID
action_time:String,//动作的时间点
search_keyword:String,//用户搜索的关键词
click_category_id:Long,//某一个商品品类的 ID
click_product_id:Long,//某一个商品的 ID
order_category_ids:String,//一次订单中所有品类的 ID 集合
order_product_ids:String,//一次订单中所有商品的 ID 集合
pay_category_ids:String,//一次支付中所有品类的 ID 集合
pay_product_ids:String,//一次支付中所有商品的 ID 集合
city_id:Long)//城市 id}
本文转载自: https://blog.csdn.net/weixin_42570840/article/details/125333253
版权归原作者 Jerry Hong 所有, 如有侵权,请联系我们删除。
版权归原作者 Jerry Hong 所有, 如有侵权,请联系我们删除。