
** 深拷贝与浅拷贝:**
在开始之前我们需要先了解一下什么是浅拷贝和深拷贝,其实深拷贝和浅拷贝都是针对的引用类型,JS中的变量类型分为值类型(基本类型)和引用类型;对值类型进行复制操作会对值进行一份拷贝,而对引用类型赋值,则会进行地址的拷贝,最终两个变量指向同一份数据。
// 基本类型
var a = 1;
var b = a;
a = 2;
console.log(a, b); // 2, 1 ,a b指向不同的数据
// 引用类型指向同一份数据
var a = {c: 1};
var b = a;
a.c = 2;
console.log(a.c, b.c); // 2, 2 全是2,a b指向同一份数据
对于引用类型,会导致a b指向同一份数据,此时如果对其中一个进行修改,就会影响到另外一个,有时候这可能不是我们想要的结果,如果对这种现象不清楚的话,还可能造成不必要的bug.
那么如何切断a和b之间的关系呢,可以拷贝一份a的数据,根据拷贝的层级不同可以分为浅拷贝和深拷贝,浅拷贝就是只进行一层拷贝,深拷贝就是无限层级拷贝。
var a1 = {b: {c: {}}};
var a2 = shallowClone(a1); // 浅拷贝
a2.b.c === a1.b.c // true
var a3 = clone(a1); // 深拷贝
a3.b.c === a1.b.c // false
这里认为shallowClone是指浅拷贝,clone是指深拷贝,a1对象是一个三层嵌套对象。浅拷贝只能拷贝第一层,b属性是一个对象,b里面存放的是这个对象的引用地址,因此a1.b.c===a2.b.c ; 深拷贝则是拷贝每一层,a1.b和a3.b的引用地址不同,完全独立,因此a3.b.c!=a1.b.c.
对于浅拷贝的实现来说非常简单,我们对要拷贝的对象或数组进行一次遍历,并赋值给创建的新对象或新数组,就可完成浅拷贝,这里不再多说。 下面我们将讨论深拷贝应该如何实现。这里介绍四种深拷贝方法。
1.递归法:
实现深拷贝最常用的方法便是递归法,原理就是通过递归的方式遍历要拷贝的对象或数组。首先对要拷贝的对象或数组进行类型判断,然后创建相应的一个空对象或空数组,然后和浅拷贝一样,通过循环遍历这个对象或数组,若发现某个属性是引用数据类型的话,就递归调用深拷贝函数,若该属性是基本数据类型,则直接进行赋值操作,直至遍历完所有子对象的所有属性。递归遍历本质上是深度优先遍历,在进行深拷贝时,若一个属性的值为对象,则优先对这个子对象进行拷贝,而不是拷贝与这个属性相邻的下一个属性。待这个属性所对应的子对象整体拷贝完毕后,才会拷贝下一个属性。下面放上递归法的代码:
//递归遍历每个属性进行深拷贝
function clone(source) {
let target = Array.isArray(source) ? [] : {};
if(typeof(source)!="object") {
target = source;
return target;
}
if(source instanceof Array) {
for(var i=0;i<source.length;i++) {
if(typeof source[i] == "object") {
target[i] = clone(source[i]);
}else {
target[i] = source[i];
}
}
}
else {
for(let key in source) {
if(source.hasOwnProperty(key)) {
if(typeof source[key] == "object") {
target[key] = clone(source[key]);
}else {
target[key] = source[key];
}
}
}
}
return target;
}
在这里用一个包含多层的对象数组进行测试,并将深拷贝的属性进行修改,看看是否会影响到原始数据。
let e = [{a:'1',b:'2',c:'3'},{aa:'11',bb:'22',cc:'33'},{aaa:'111',bbb:'222',ccc:'333'}];
let f = clone(e);
f[2].ccc='444';
console.log(e);
console.log(f);
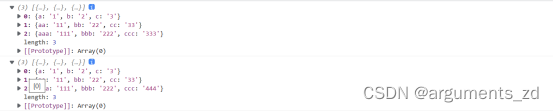
可以看到打印后的结果,修改拷贝数组第三个元素的ccc属性后,原数组并没有发生变化,说明深拷贝实现成功。
- JSON深拷贝法:
利用系统自带的JSON也可以实现深拷贝。
JSON.parse(JSON.stringify(a));
实际上是将要拷贝的对象先转换为JSON字符串,再将字符串转换为对象。JSON对象与字符串转换的原理实际上也是做递归遍历,只不过需要做两次,因此在算法效率上递归法要比JSON转换高一倍。
但使用递归法和JSON进行深拷贝有一个弊端,就是在每次执行递归函数时,都会调用内存空间,所以当要拷贝的对象深度非常大时,使用递归函数会出现爆栈的问题。下面来模拟下这种情况。
//构造指定深度和广度的对象
function createData(deep,num) {
var data = {};
var temp = data;
for(var i=0;i<deep;i++) {
temp.data = {};
temp = temp.data;
for(var j = 0;j<num;j++) {
temp[j] = j;
}
}
return data;
}
这个createData函数用来构造一个深度为deep,广度为num的对象。例如createData(3,3),创建出的对象为{data:{‘0’:0,’1’:1,’2’:2,data:{‘0’:0,’1’:1,’2’:2,data:{‘0’:0,’1’:1,’2’:2,}}}}。此时用createData创建一个深度为10000的对象,并用递归法clone()和JSON拷贝这个对象,会发现内存溢出报错。
let d = createData(10000,0);
let e = clone(d);
console.log(e);

let d = createData(10000,0);
let e = JSON.parse(JSON.stringify(d));
console.log(e);

可见碰到层级很多的对象时,这两种方法就不管用了,下面就来介绍第三种方法,循环递归深拷贝,这种方法可以很好的解决内存溢出的问题。
2.循环遍历法:
如果我们可以使用循环来遍历对象所有层级的属性,就可以省去递归调用函数时占用的内存空间,从而解决爆栈的问题。那么该如何运用循环的思想实现多层次遍历呢。下面来看一个数据结构
var a = {
a1: {
a11: 1,
},
a2: {
b1: 1,
b2: {
c1: 1
}
}
}
a对象是一个嵌套对象,如果我们把它竖着来看,会发现它是一个树形的数据结构。
a
/ \
a1 a2
| / \
a11 b1 b2
| | |
1 1 c1
|
1
我们可以把对象中引用数据类型的属性看作是这颗树里面的子节点,基本数据类型的属性看作是叶子节点的父节点。会发现我们只需要遍历这颗树的每个节点,就可以实现深拷贝了。用循环遍历这棵树,我们需要借助一个栈,把子节点(除叶子节点和其父节点外)放入到这个栈中,表示这些节点需要拷贝,每次拷贝从栈中放出一个节点进行拷贝,当栈为空时,则表示这棵树已经遍历完并完成拷贝。循环遍历本质上就是对栈中的元素进行循环,栈空循环自然结束。下面来模拟一下利用栈循环遍历的这个过程。
在循环前我们先构造这个栈,栈是一个具有后进先出特点的数组,我们要将需要遍历的节点放入到栈中,在刚开始拷贝时,因为不知道要拷贝的对象里面的属性如何,所以先往栈里放入一个种子数据。栈中存放的元素需要有三个属性来描述节点信息,parent 表示当前所处的节点,也就是要做循环遍历的当前节点,key用来存放当前节点中属性名为key的子元素,表示需要拷贝的子对象,data表示要拷贝子对象的内容。
{
parent: root,
key: undefined,
data: x,
}
拿要拷贝的a对象来举例,我们想把它拷贝到root中,先构造root空对象,然后将上面这个种子数据放入到栈中,遍历前我们处在root节点,所以parent为root,因为不知道拷贝的对象结构如何,所以key为undefined,data表示要拷贝的内容,也就是整个a对象。
第一轮循环开始,种子数据出栈,循环遍历当前parent节点下的节点,发现a1 a2都是引用数据类型,是要拷贝的节点,所以把他们对应的节点信息存入栈中,此时parent为root,key为a1和a2 data分别为 a1 对象和a2对象。因为a2在a1之后存入,则a2先出栈。
第二轮循环:循环遍历a2下的节点,b2为引用类型,b2对应节点信息存入到栈中,因为在a2下进行遍历,所以parent为a2。
第三轮循环:b2出栈,遍历b2下的节点,发现没有引用类型,直接拷贝。
第四轮循环:a1出栈,遍历a1下的节点,发现a11不是引用类型,直接拷贝。此时栈为空,并且没有需要入栈的引用类型,则表示已经遍历完毕,循环结束。
通过这个过程我们可以发现循环遍历的次数取决于要拷贝的数据中引用数据类型的个数,嵌套了多少个对象,就循环多少次。并且由于栈后进先出的特点,循环遍历同递归遍历一样也属于深度优先遍历。即先访问子元素,再访问兄弟元素。
下面贴出循环遍历深拷贝方法的代码
//循环遍历对象实现深拷贝
function cloneLoop(x) {
const root = {};
// 栈 后进先出
const loopList = [
{
parent: root,
key: undefined,
data: x,
}
];
while(loopList.length) {
// 深度优先
const node = loopList.pop();
const parent = node.parent;
const key = node.key;
const data = node.data;
// 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素
let res = parent;
if (typeof key !== 'undefined') {
res = parent[key] = {};
}
for(let k in data) {
if (data.hasOwnProperty(k)) {
if (typeof data[k] === 'object') {
// 下一次循环
loopList.push({
parent: res,
key: k,
data: data[k],
});
} else {
res[k] = data[k];
}
}
}
}
return root;
}
这里为了方便,只考虑对象情况,若要考虑数组情况,则需要对拷贝类型进行判断,根据类型构造空对象或空数组。具体实现参考递归法。
通过循环遍历,我们可以破解递归爆栈,利用循环深拷贝法cloneLoop()对刚才的10000层对象进行拷贝,发现没有报栈溢出的错误,说明此方法有效。
let d = createData(10000,0);
let e = cloneLoop(d);
console.log(e);

尽管循环遍历法可以解决拷贝层级很多对象时内存溢出的问题,但对于某些特殊情况依然无法应对。如循环引用对象或是属性间存在引用关系的对象。例如 :
a={};
a.a=a;
var obj = {};
var obj1 = {a1: obj, a2: obj};
a是循环引用对象,obj1是属性间存在引用关系的对象。像这样的对象上述三种方法都无法实现深拷贝后仍然保持引用关系,也无法破解循环引用。我们拿obj1来用这三种方法进行拷贝测试,结果如图:
var obj = {};
var obj1 = {a1: obj, a2: obj};
console.log(obj1.a1 === obj1.a2) // true
var obj3 = cloneLoop(obj1);
console.log(obj3.a1 === obj3.a2) //false
var obj4 = JSON.parse(JSON.stringify(obj1));
console.log(obj4.a1 ===obj4.a2) //false
var obj5 = clone(obj1);
console.log(obj5.a1 === obj5.a2) //false
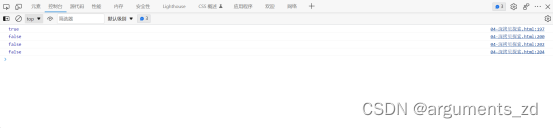
这里就要介绍第四种方法,它可以解决循环引用和属性间存在引用关系的问题。
3.破解循环引用法:
第四种方法其实是在循环遍历法的基础上进行改进。在每轮循环开始前如果我们发现个新对象就把这个对象和他的拷贝存下来,每次拷贝对象前,都先看一下这个对象是不是已经拷贝过了,如果拷贝过了,就不需要拷贝了,直接用原来的,这样我们就能够保留引用关系了。
引入一个数组uniqueList用来存储已经拷贝过的对象,每次循环遍历时,先判断本次要拷贝的对象是否在uniqueList中了,如果在的话就不执行拷贝逻辑了,直接将上次拷贝的对象的引用直接赋值给该要拷贝的属性。如果不在则表示要拷贝对象第一次出现,将这个对象和拷贝后的对象的引用存入uniqueList中。 代码如下:
/ 保持引用关系
function cloneForce(x) {
// =============
const uniqueList = []; // 用来去重
// =============
let root = {};
// 循环数组
const loopList = [
{
parent: root,
key: undefined,
data: x,
}
];
while(loopList.length) {
// 深度优先
const node = loopList.pop();
const parent = node.parent;
const key = node.key;
const data = node.data;
// 初始化赋值目标,key为undefined则拷贝到父元素,否则拷贝到子元素
let res = parent;
if (typeof key !== 'undefined') {
res = parent[key] = {};
}
// =============
// 数据已经存在
let uniqueData = uniqueList.find((item) => item.source === data);
if (uniqueData) {
parent[key] = uniqueData.target;
continue; // 中断本次循环
}
// 数据不存在
// 保存源数据,再拷贝数据中对应的引用
uniqueList.push({
source: data,
target: res,
});
// =============
for(let k in data) {
if (data.hasOwnProperty(k)) {
if (typeof data[k] === 'object') {
// 下一次循环
loopList.push({
parent: res,
key: k,
data: data[k],
});
} else {
res[k] = data[k];
}
}
}
}
return root;
}
运用改进后的循环遍历法cloneForce()对obj1进行测试,发现深拷贝后的对象里仍然保留了属性间的引用关系,说明该方法对于破解循环引用有效。
var obj = {};
var obj1 = {a1: obj, a2: obj};
console.log(obj1.a1 === obj1.a2) // true
var obj2 = cloneForce(obj1);
console.log(obj2.a1 === obj2.a2) // true
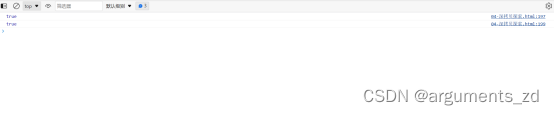
由于没拷贝过的新对象都要进入uniqueList数组,在每次拷贝前都要遍历uniqueList数组检查要拷贝的对象是否出现,当要拷贝的子对象过多并且只有较少量的属性间存在引用关系时,每次遍历uniqueList数组都会做无意义的判断从而导致算法效率降低。因此该方法只适用于数据量不大并且需要保持属性间的引用关系且符合这种关系的属性数量多。对于数据量较大的对象拷贝在不要求保持引用关系的情况下还是用第三种方法更好。
以上就是关于实现深拷贝的四种方法。
版权归原作者 arguments_zd 所有, 如有侵权,请联系我们删除。