
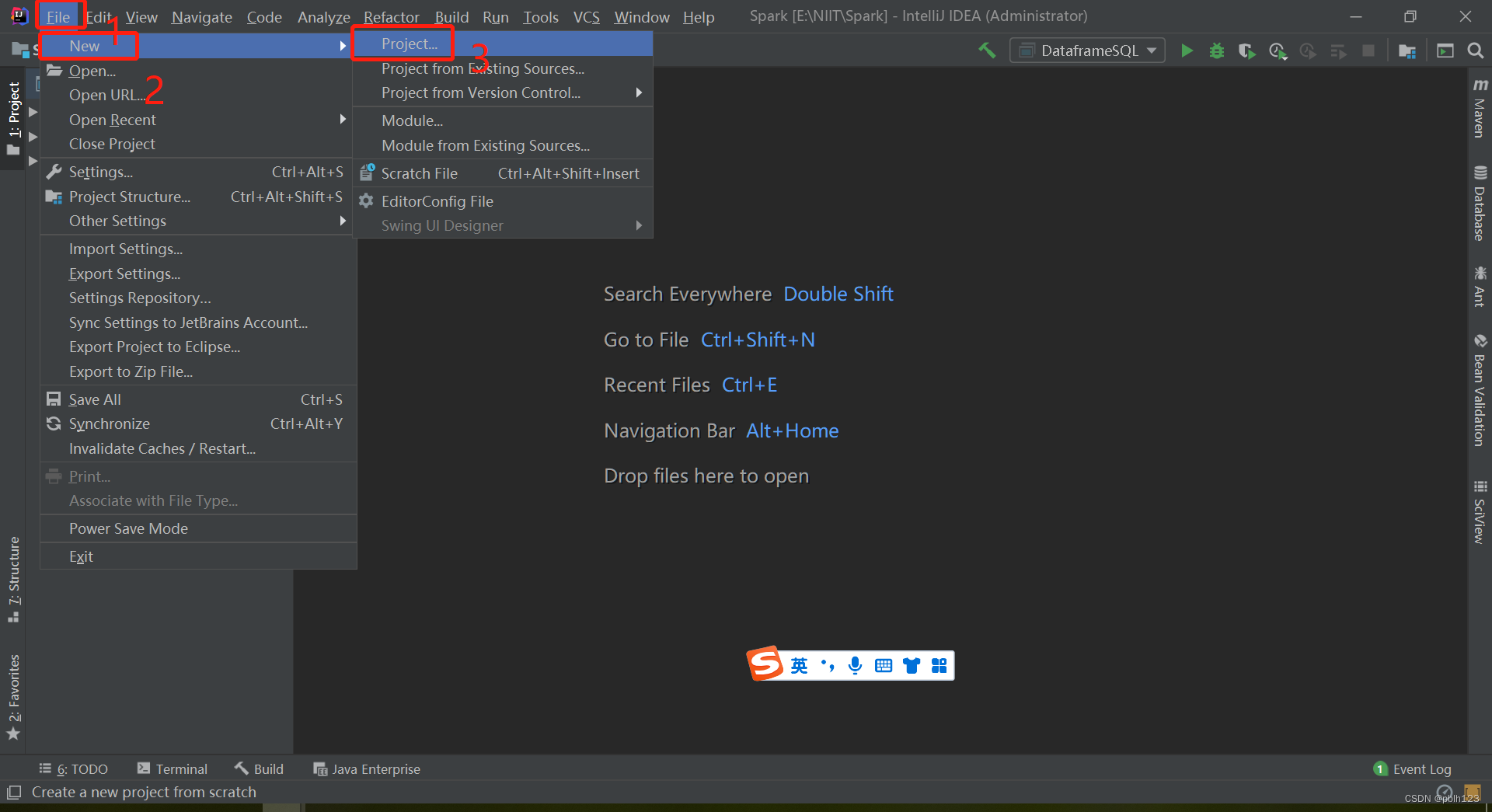
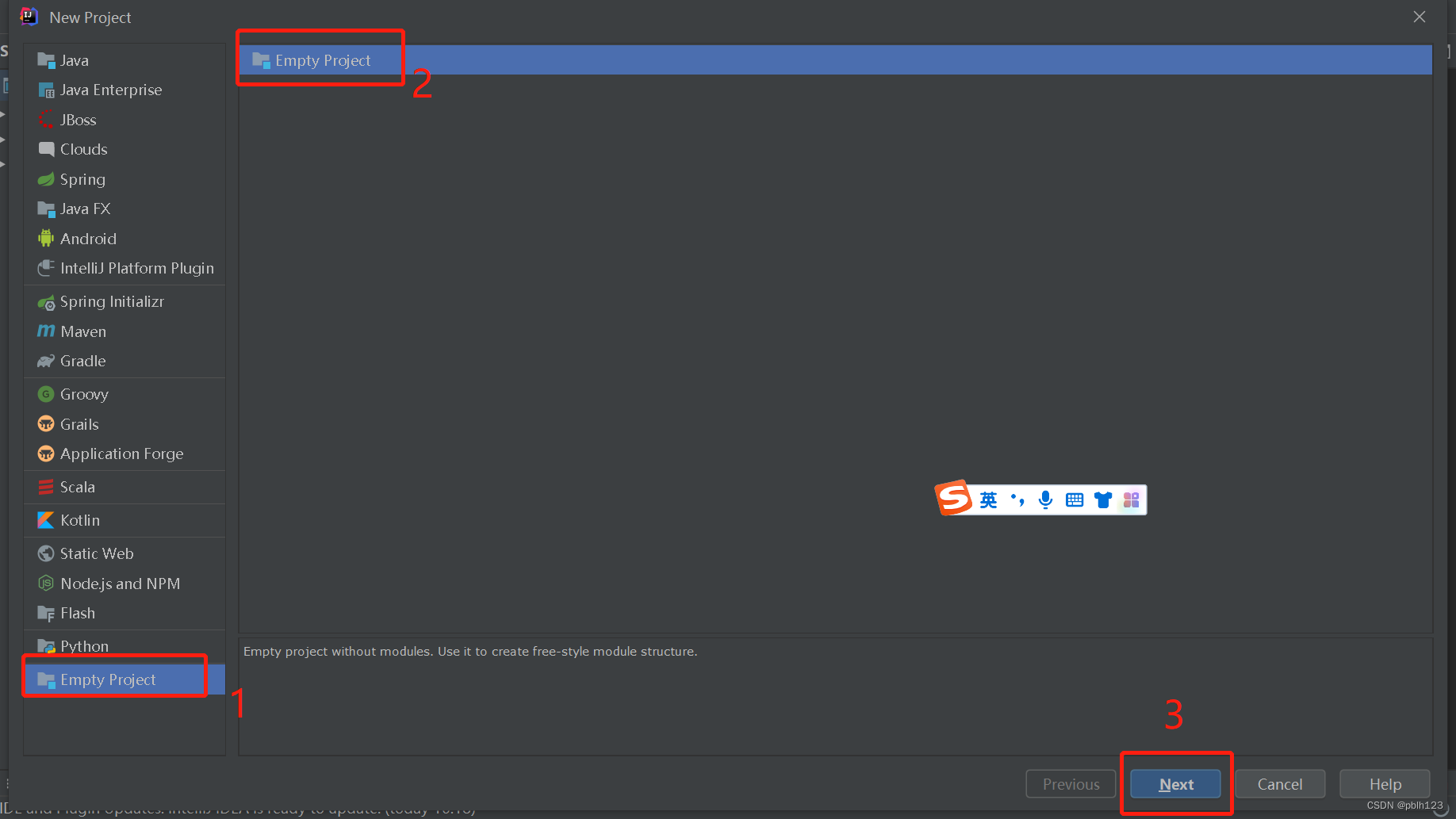
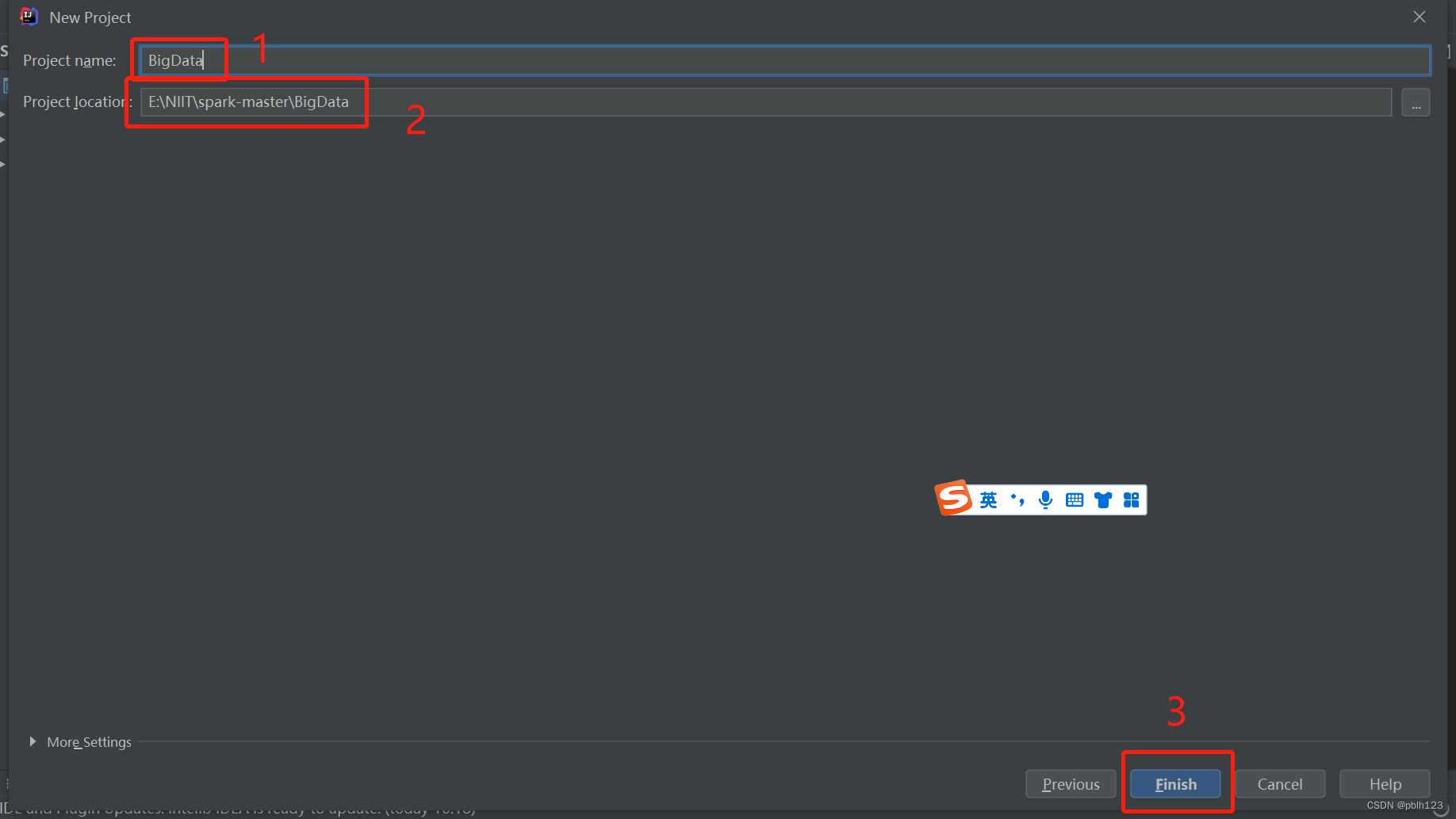
一、创建一个空项目,作为整个项目的基本框架

二、创建SparkStudy模块,用于学习基本的Spark基础
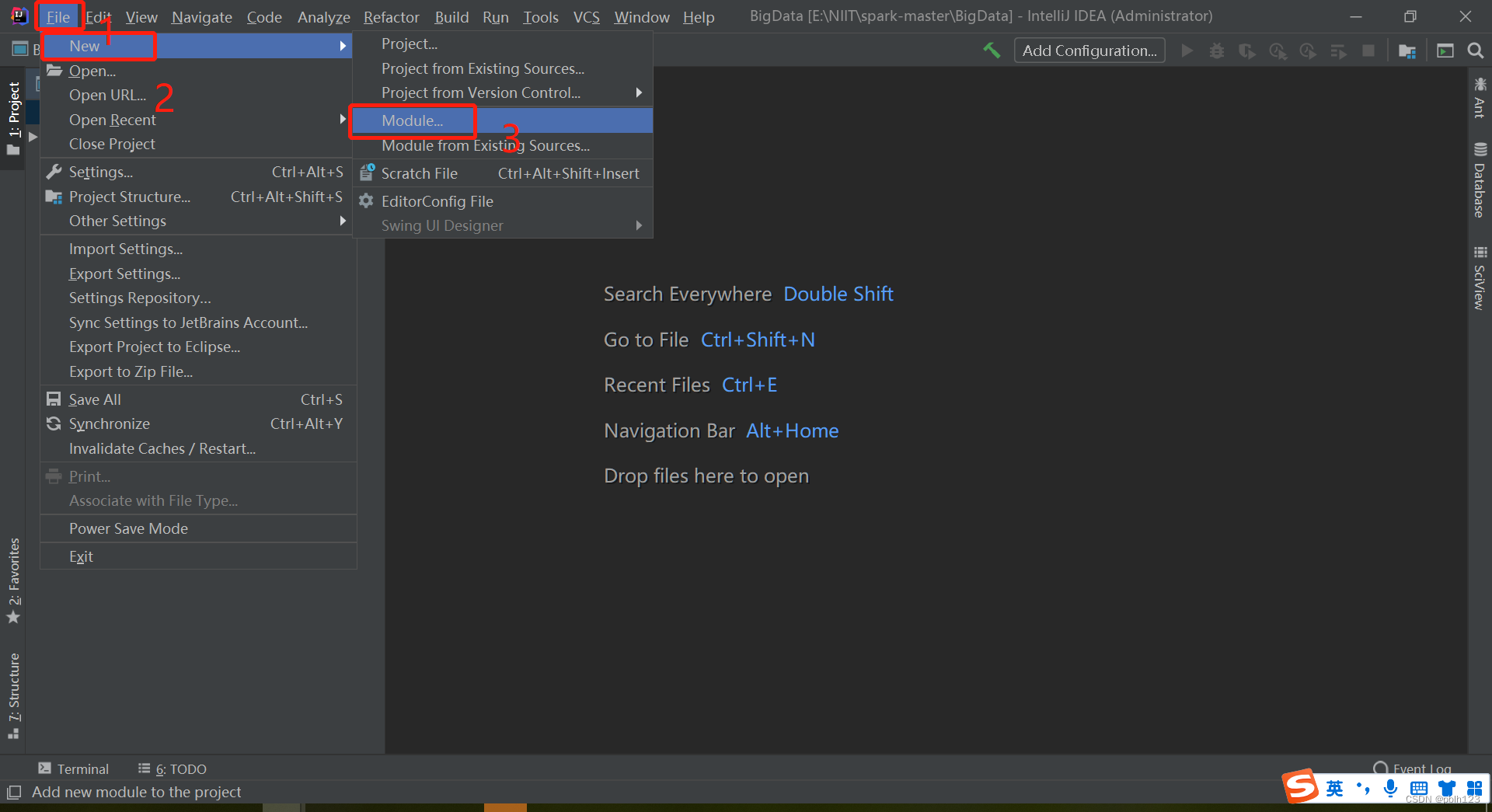
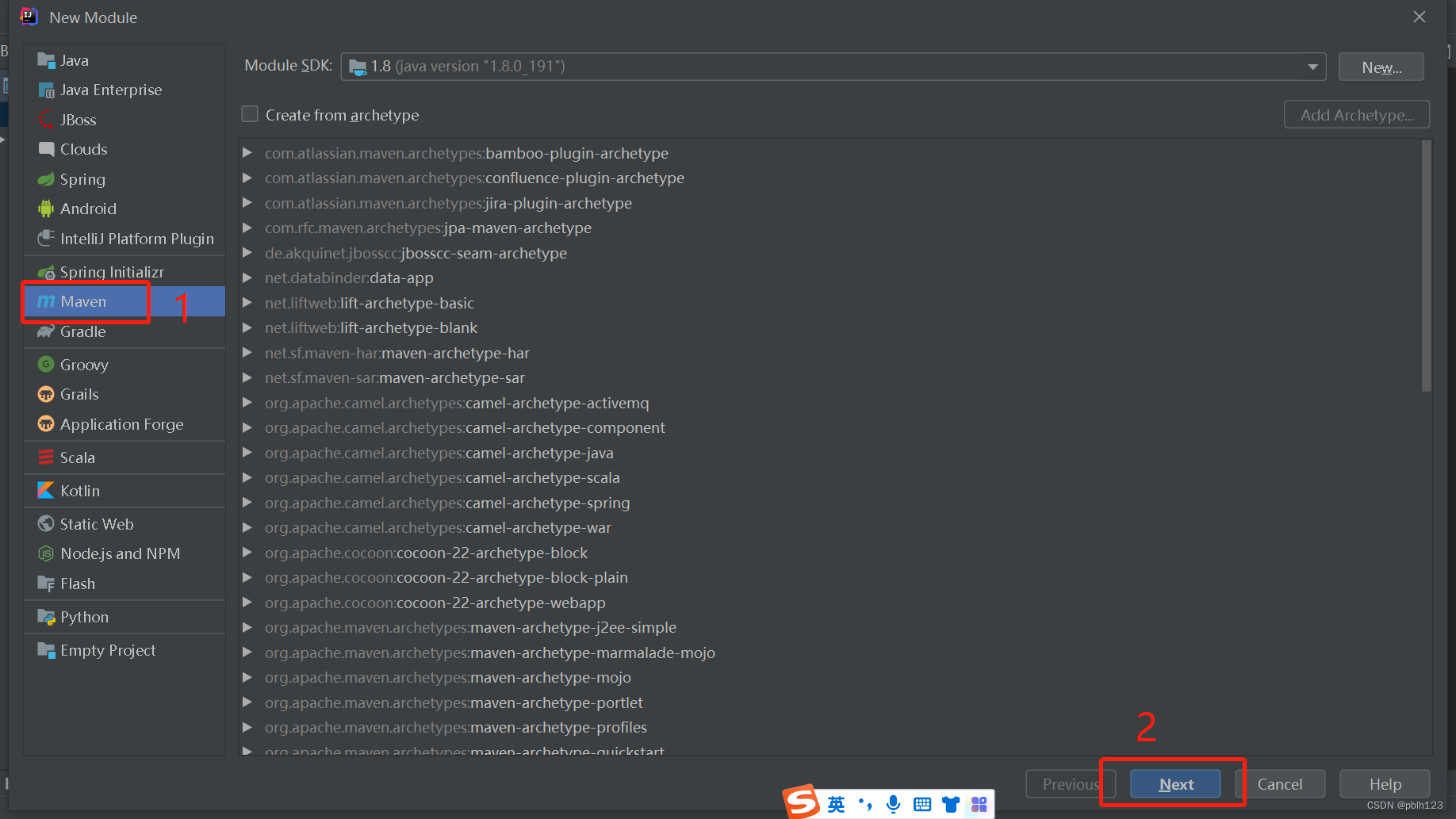
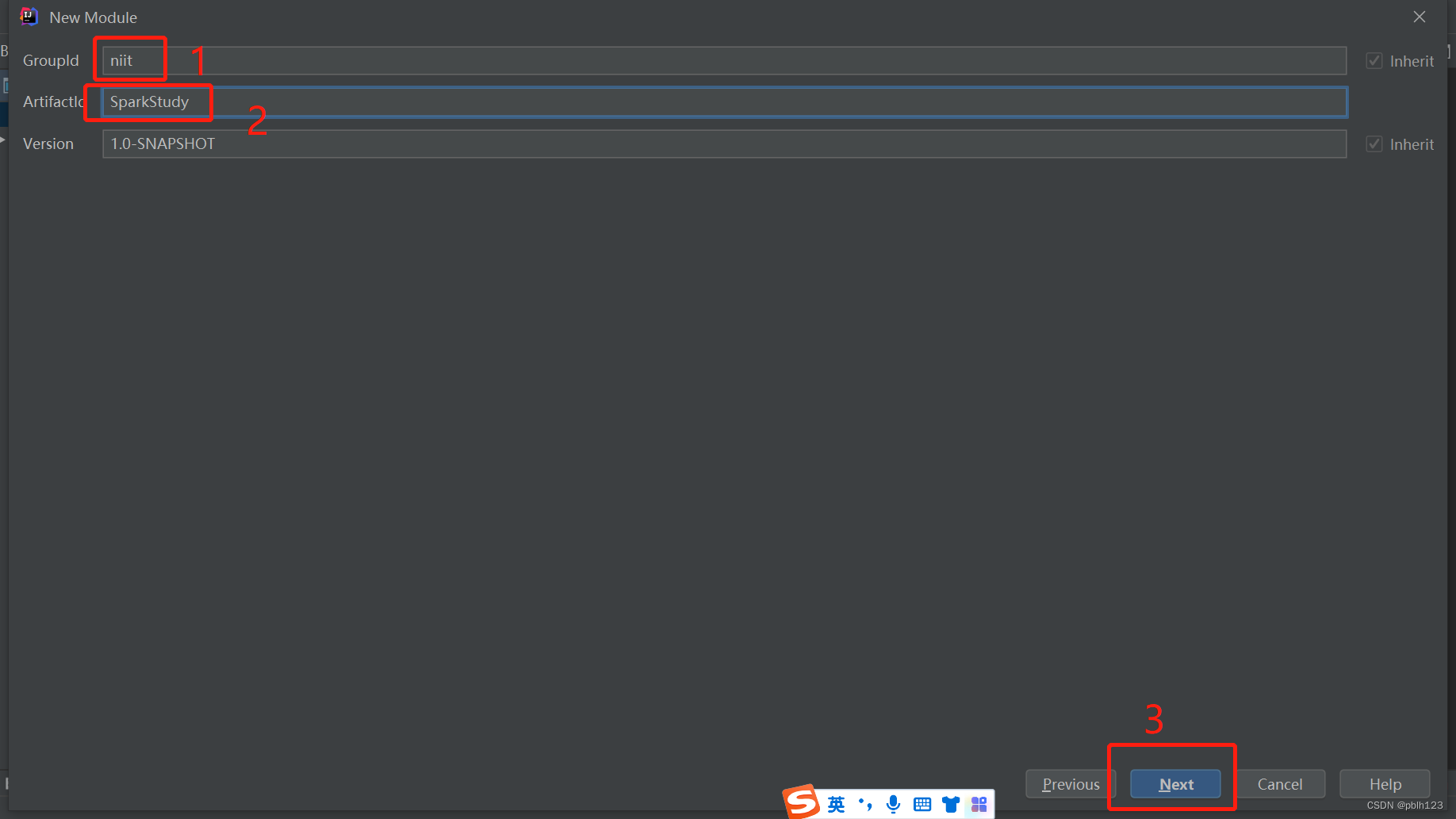
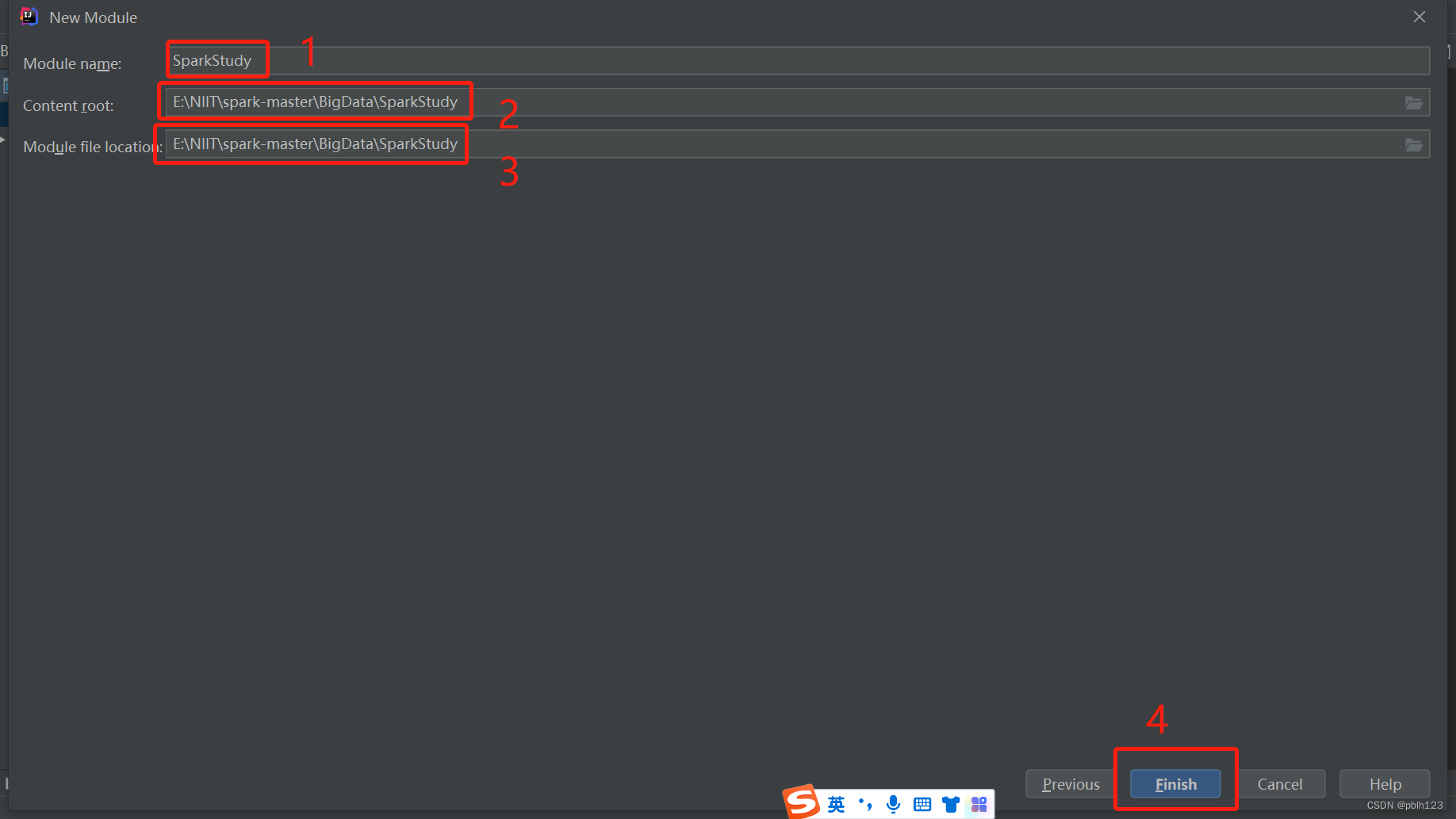
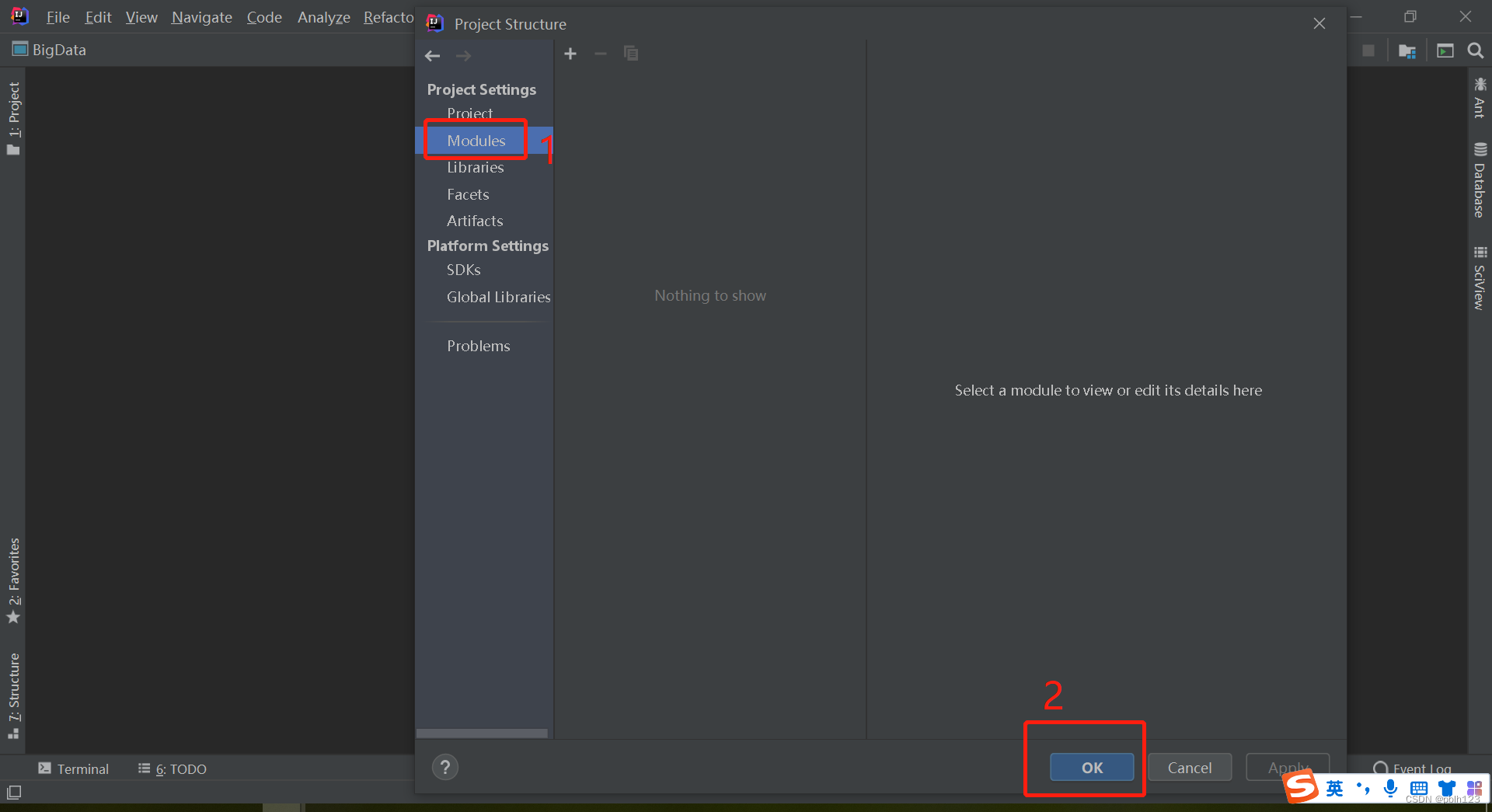
三、创建项目结构
1、在SparkStudy模块下的pom.xml文件中加入对应的依赖,并等待依赖包下载完毕。
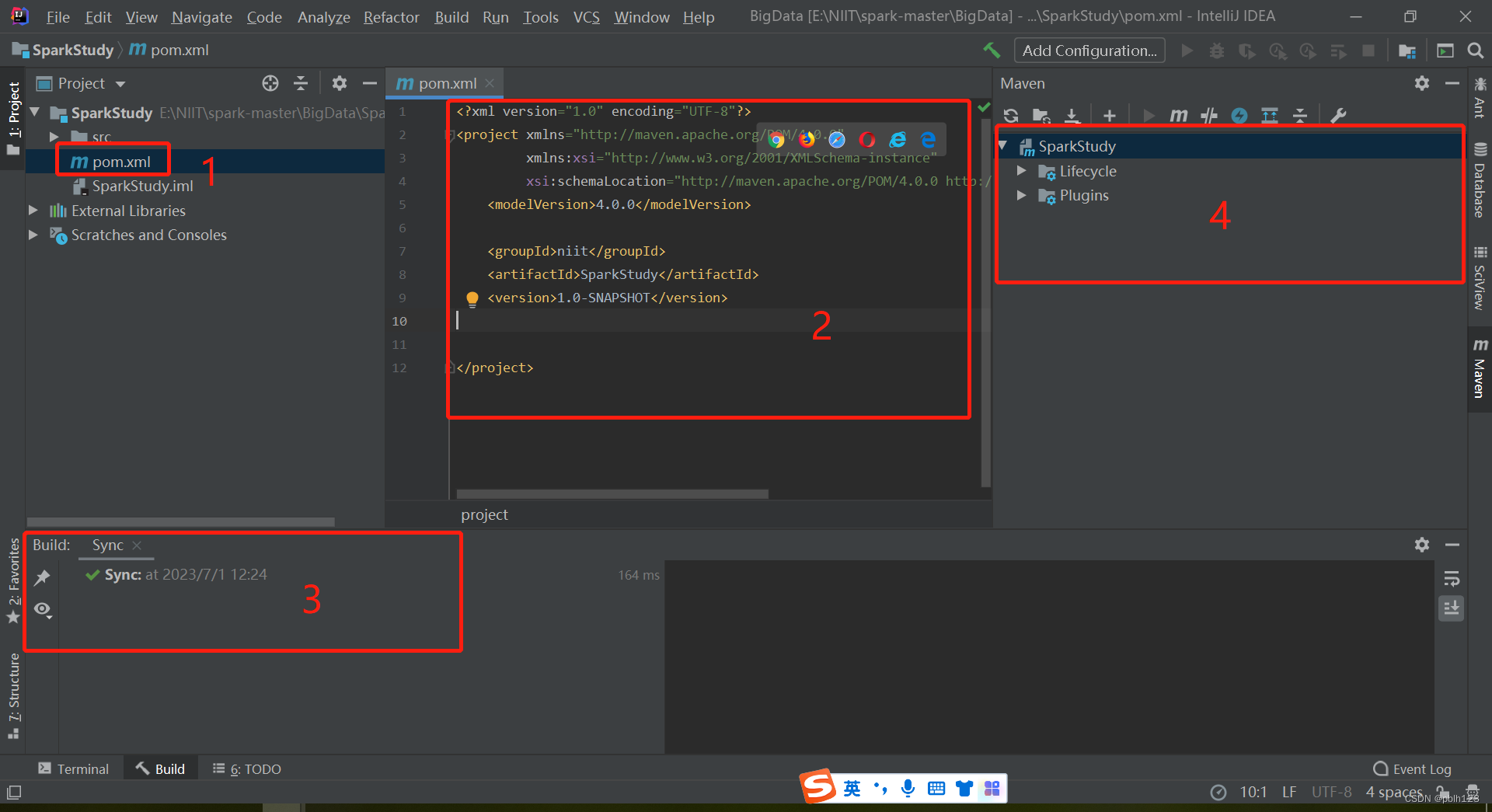
在pom.xml文件中加入对应的依赖
<!-- Spark及Scala的版本号 -->
<properties>
<scala.version>2.11</scala.version>
<spark.version>2.1.1</spark.version>
</properties>
<!-- Mysql组件
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.7.22.1</version>
</dependency> 的依赖 -->
<!-- Spark各个组件的依赖 -->
<dependencies>
<!-- https://mvnrepository.com/artifact/com.thoughtworks.paranamer/paranamer -->
<dependency>
<groupId>com.thoughtworks.paranamer</groupId>
<artifactId>paranamer</artifactId>
<version>2.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_${scala.version}</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>net.jpountz.lz4</groupId>
<artifactId>lz4</artifactId>
<version>1.3.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.18</version>
</dependency>
<dependency>
<groupId>org.apache.flume.flume-ng-clients</groupId>
<artifactId>flume-ng-log4jappender</artifactId>
<version>1.7.0</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.apache.spark</groupId>-->
<!-- <artifactId>spark-streaming-flume-sink_2.10</artifactId>-->
<!-- <version>1.5.2</version>-->
<!-- </dependency>-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>2.4.8</version>
</dependency>
</dependencies>
<!-- 配置maven打包插件及打包类型 -->
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
</plugins>
</build>

等待依赖包下载完毕
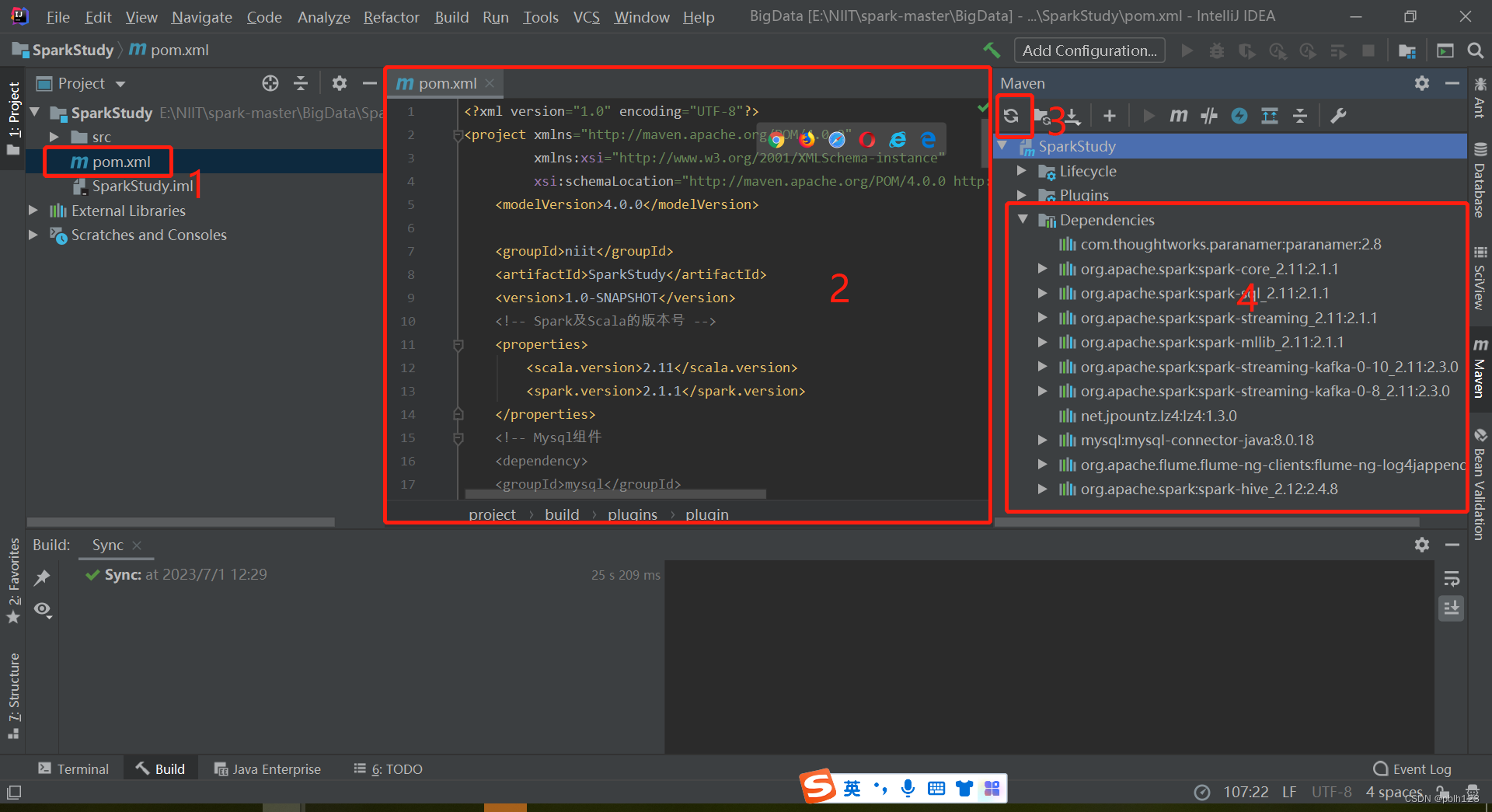
2、若不能自动下载依赖包,则按以下步骤操作
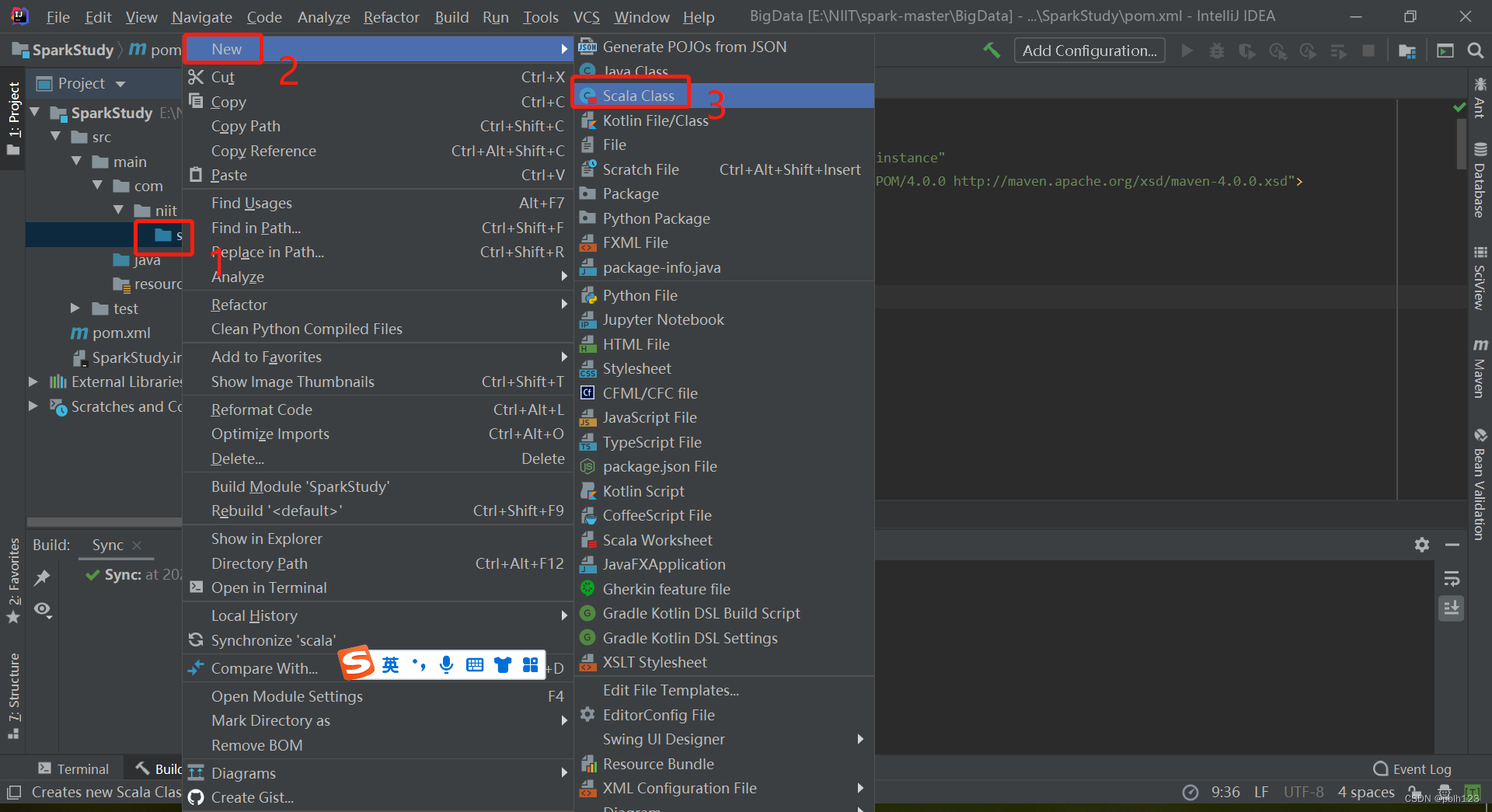
四、创建SCALA目录
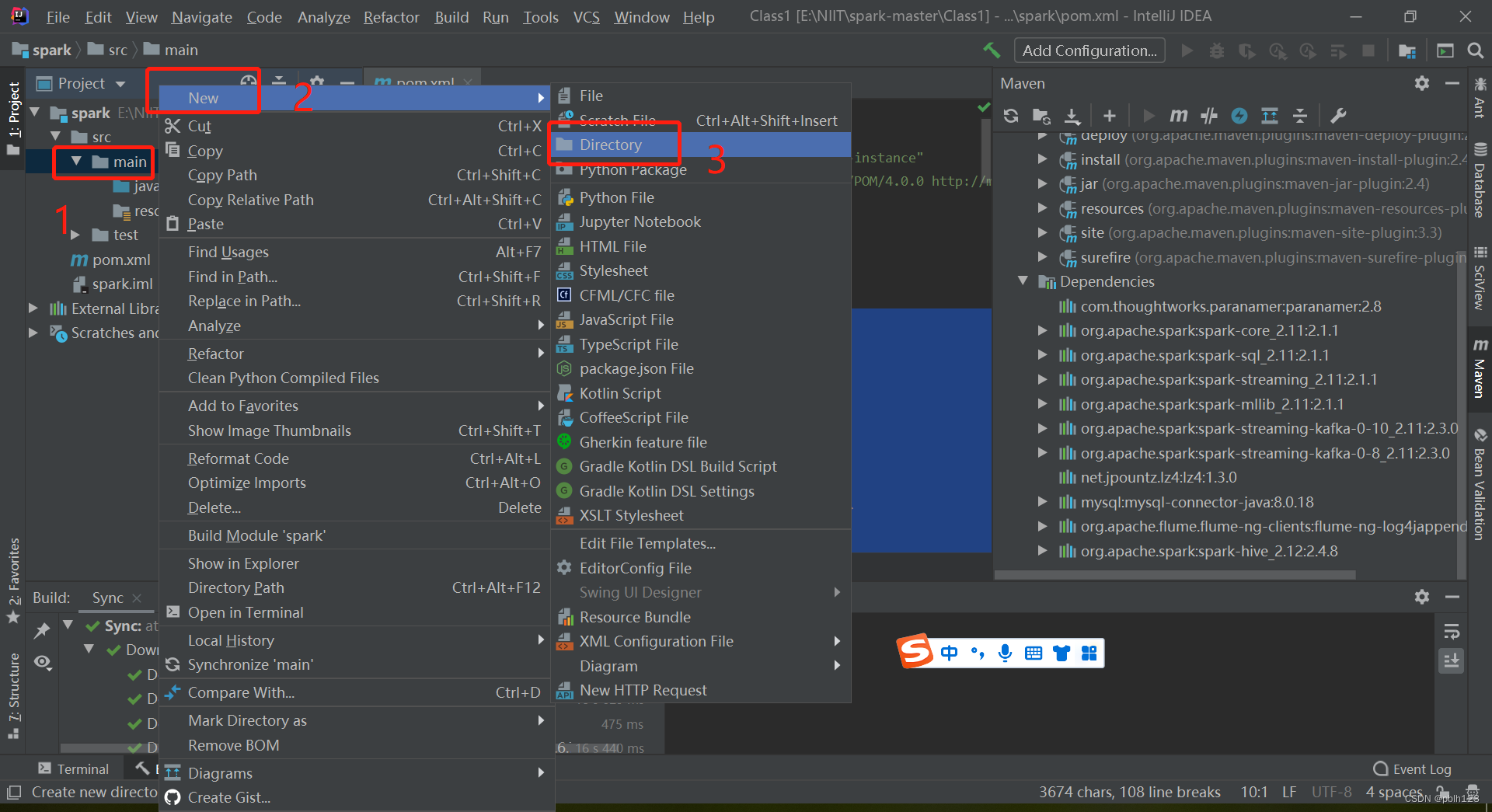
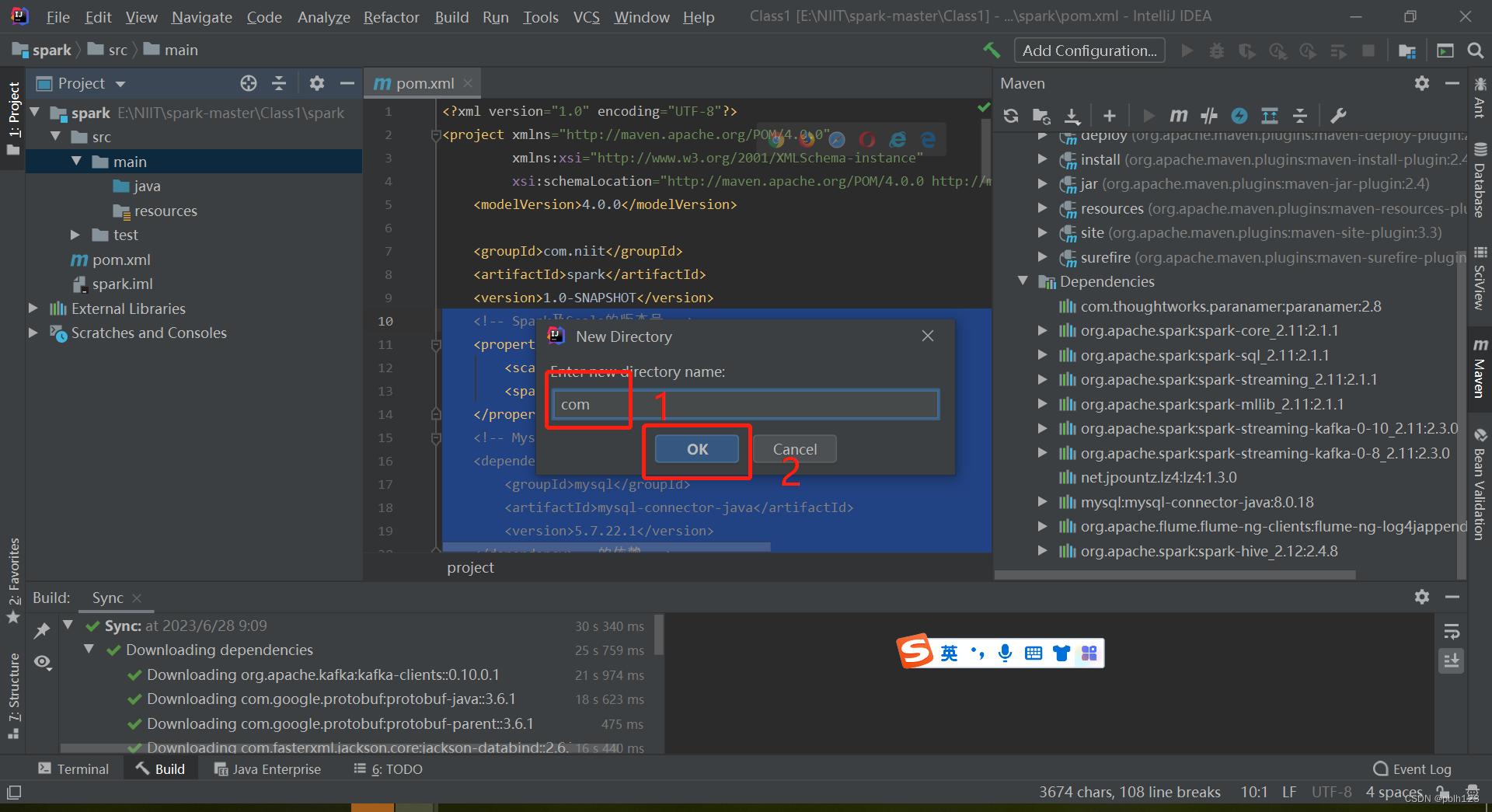
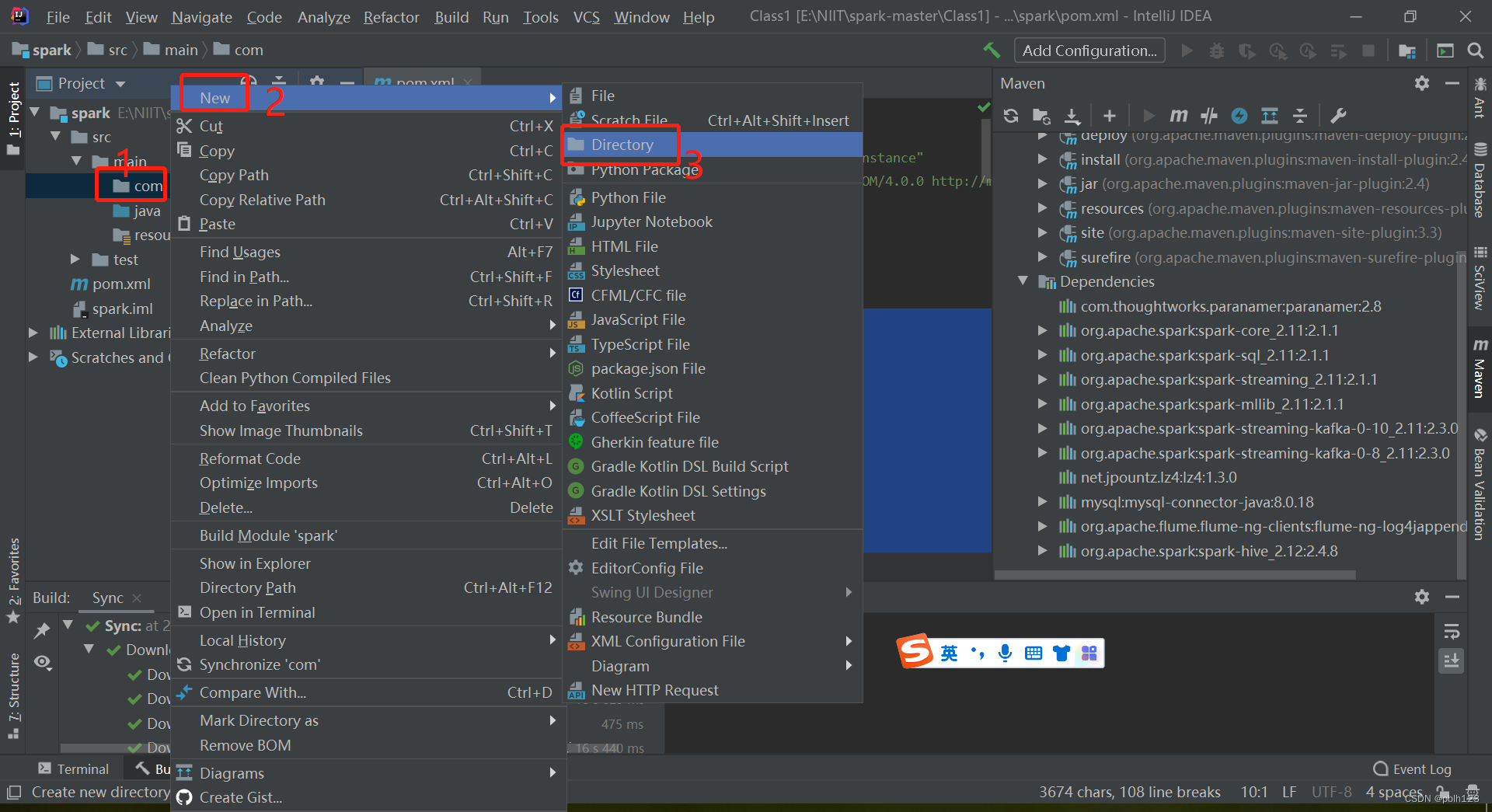

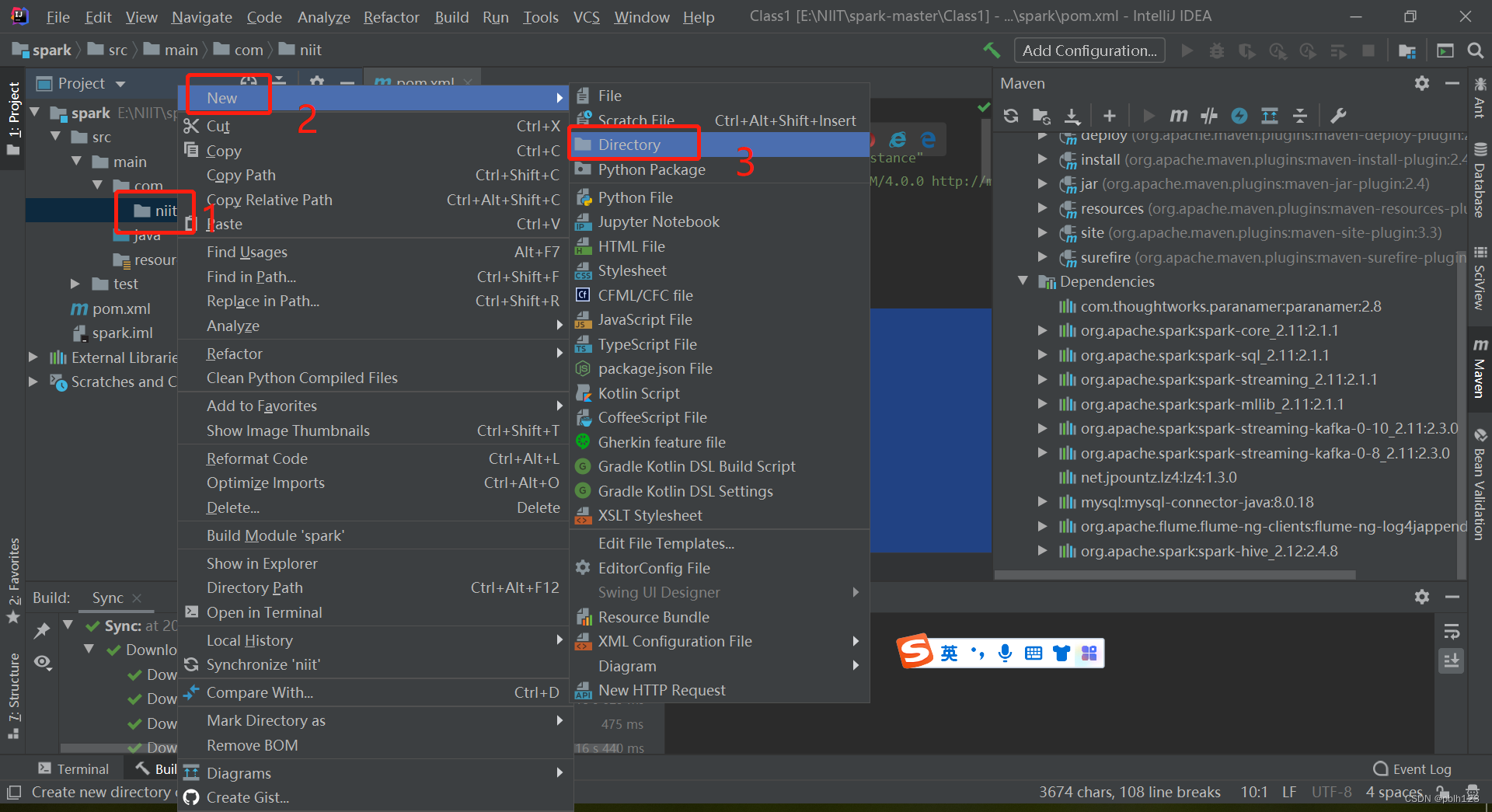

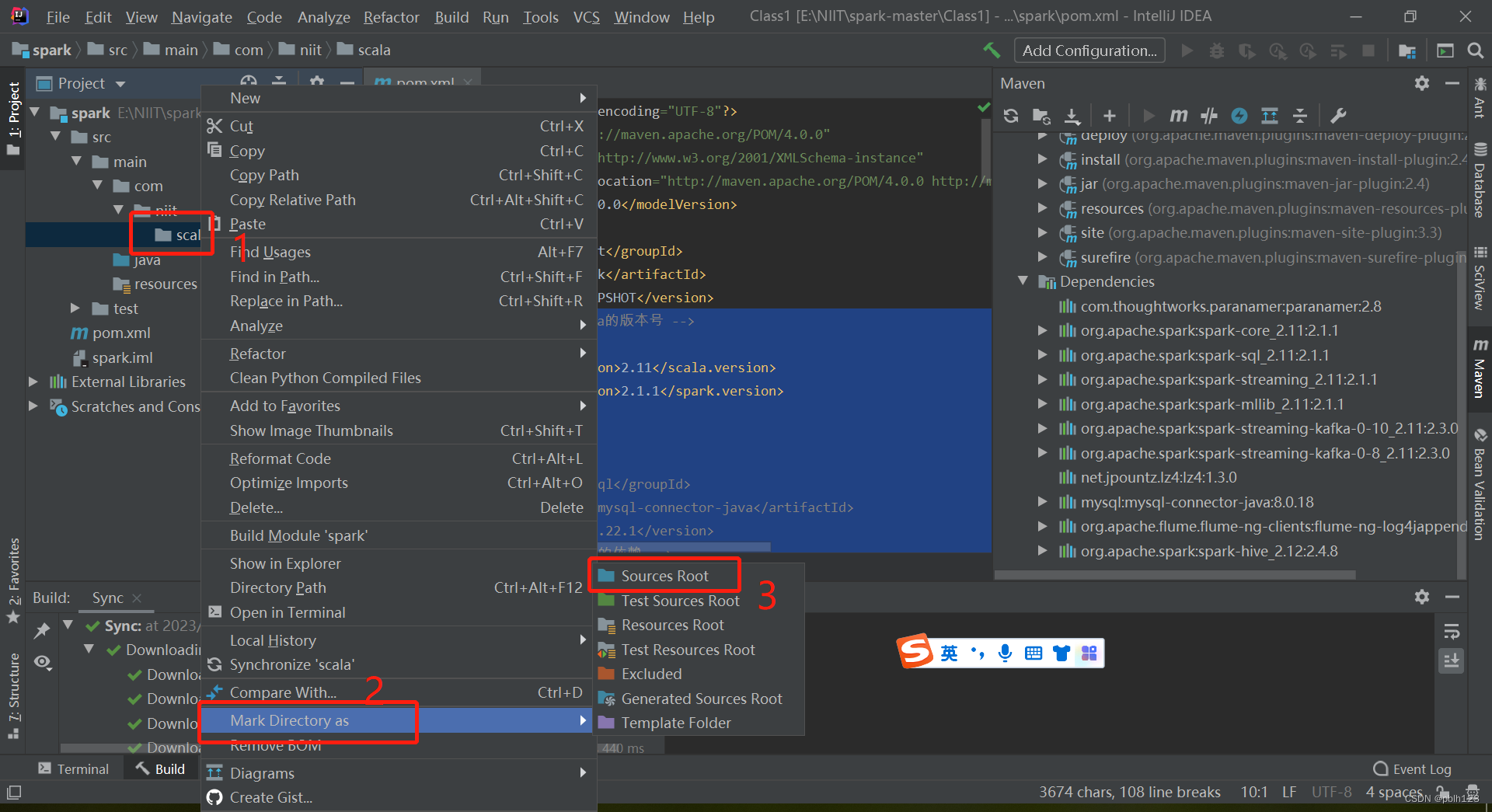
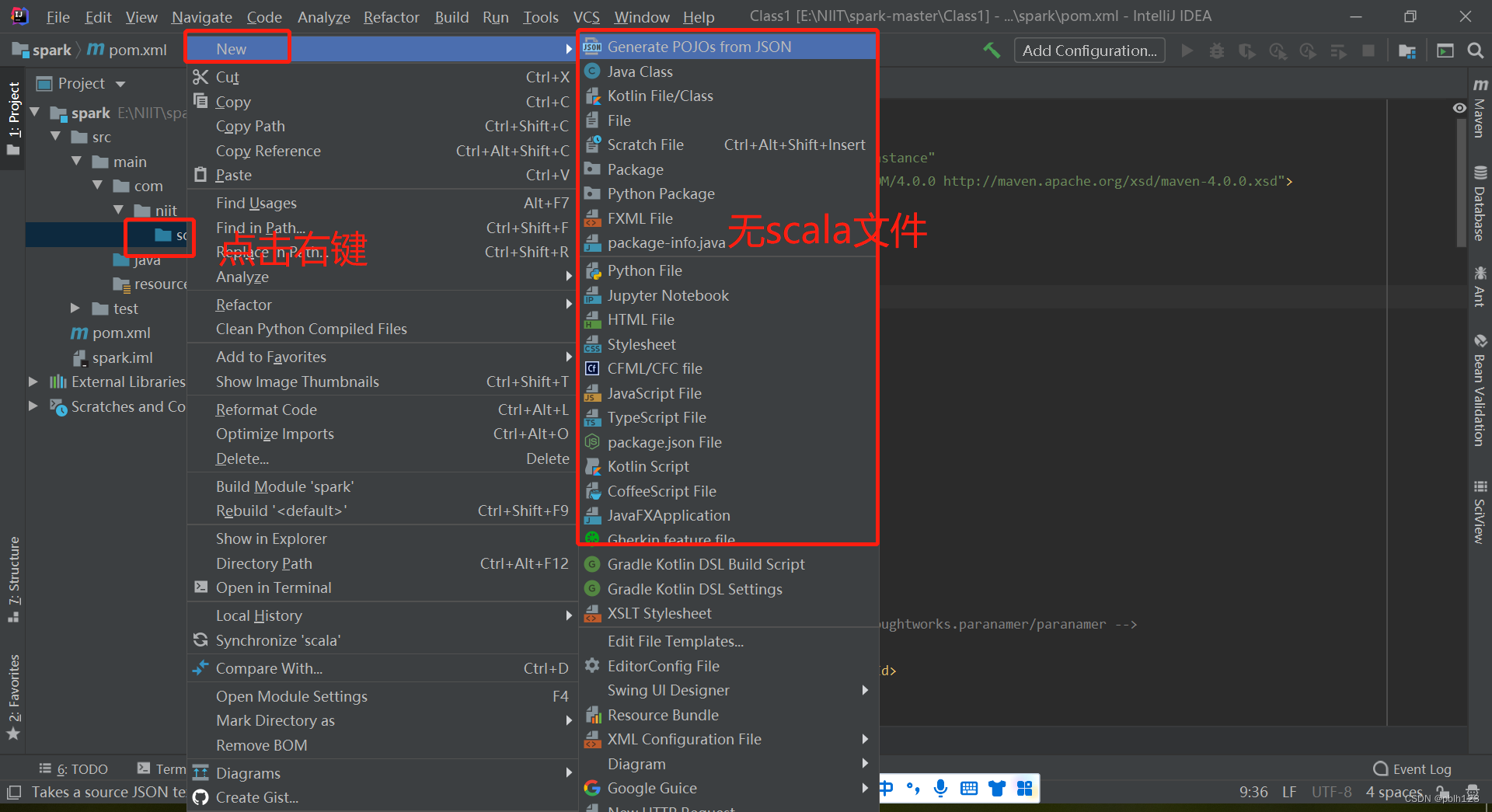
四、解决无法创建scala文件问题
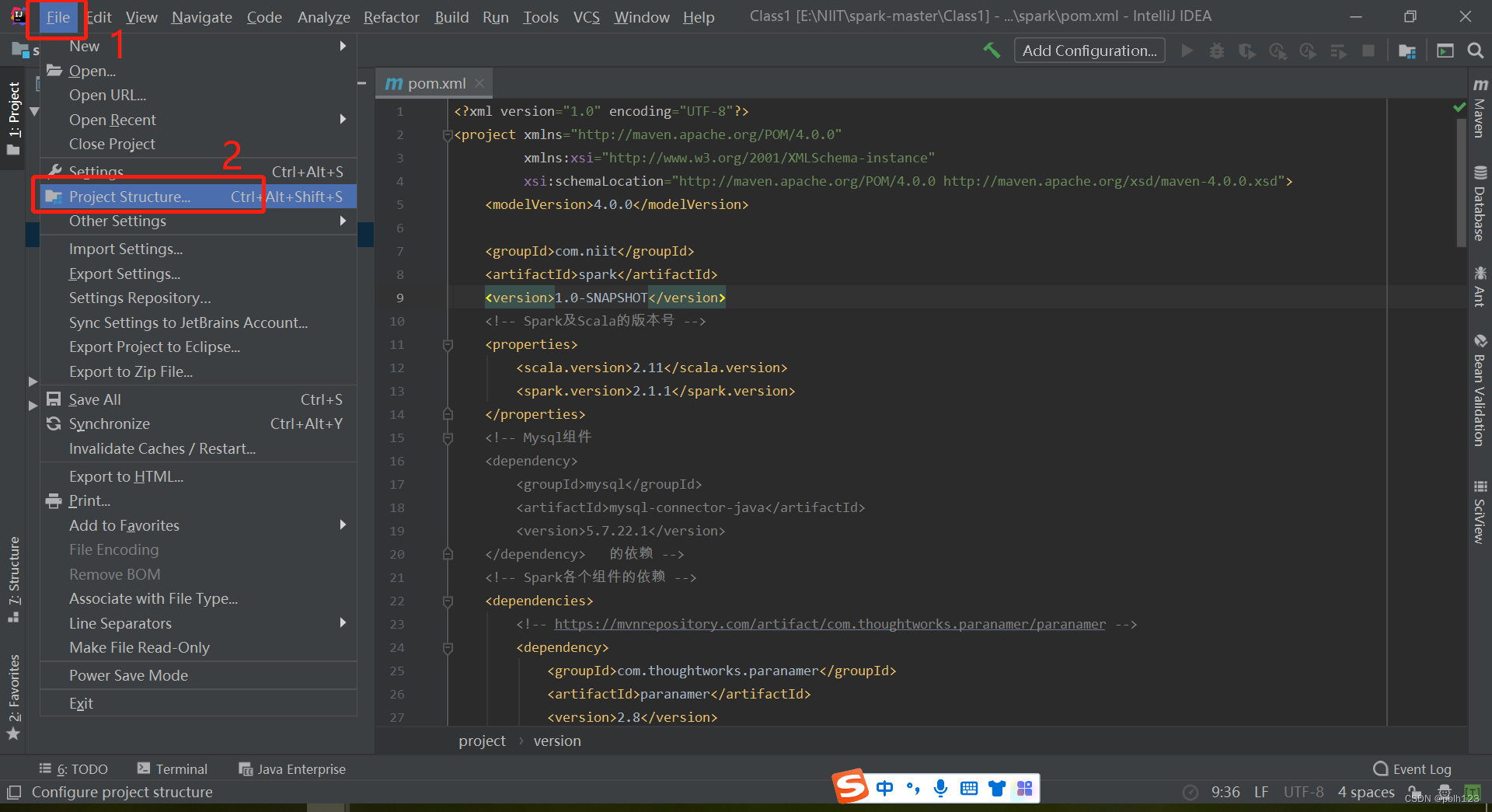
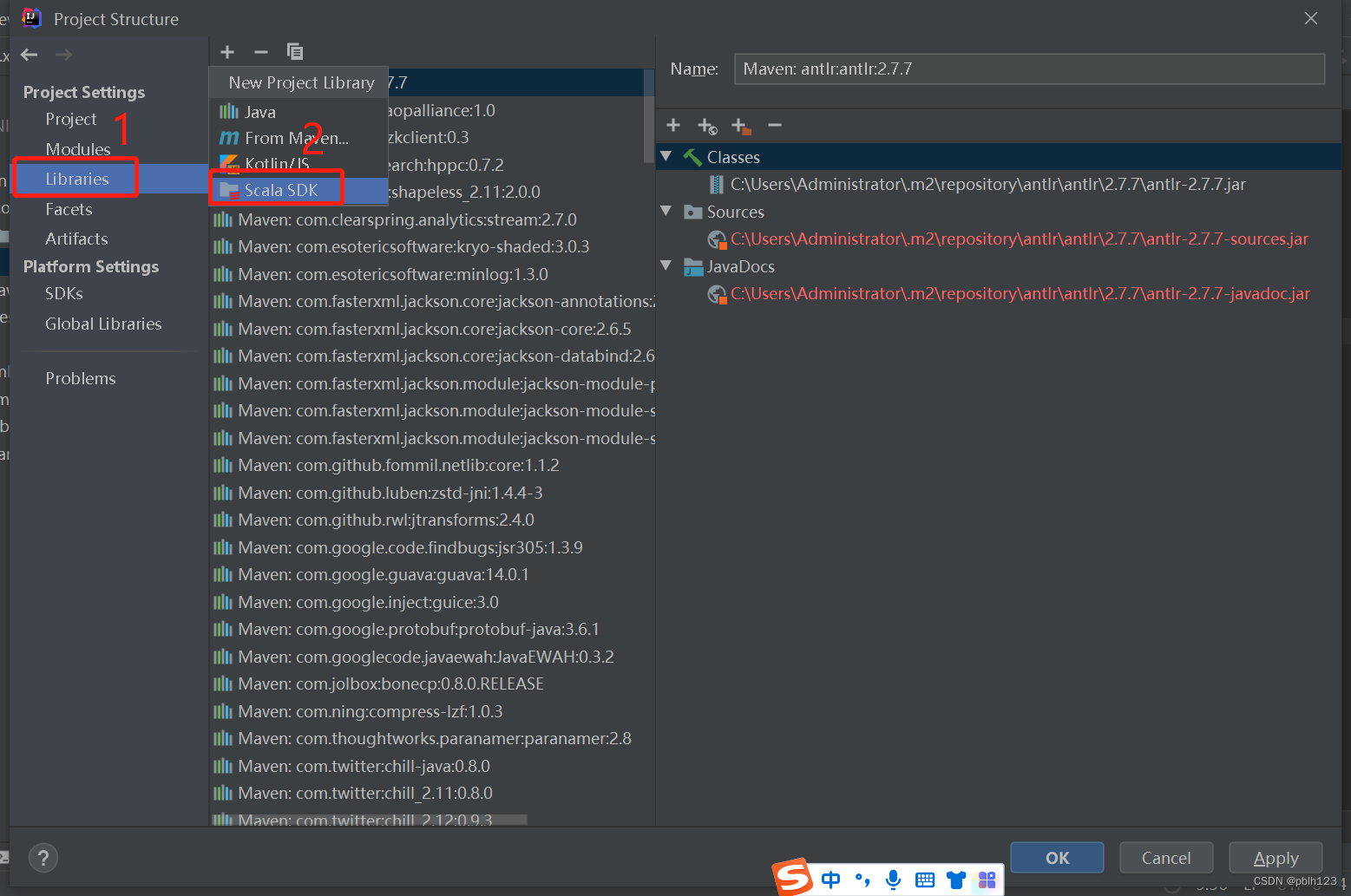


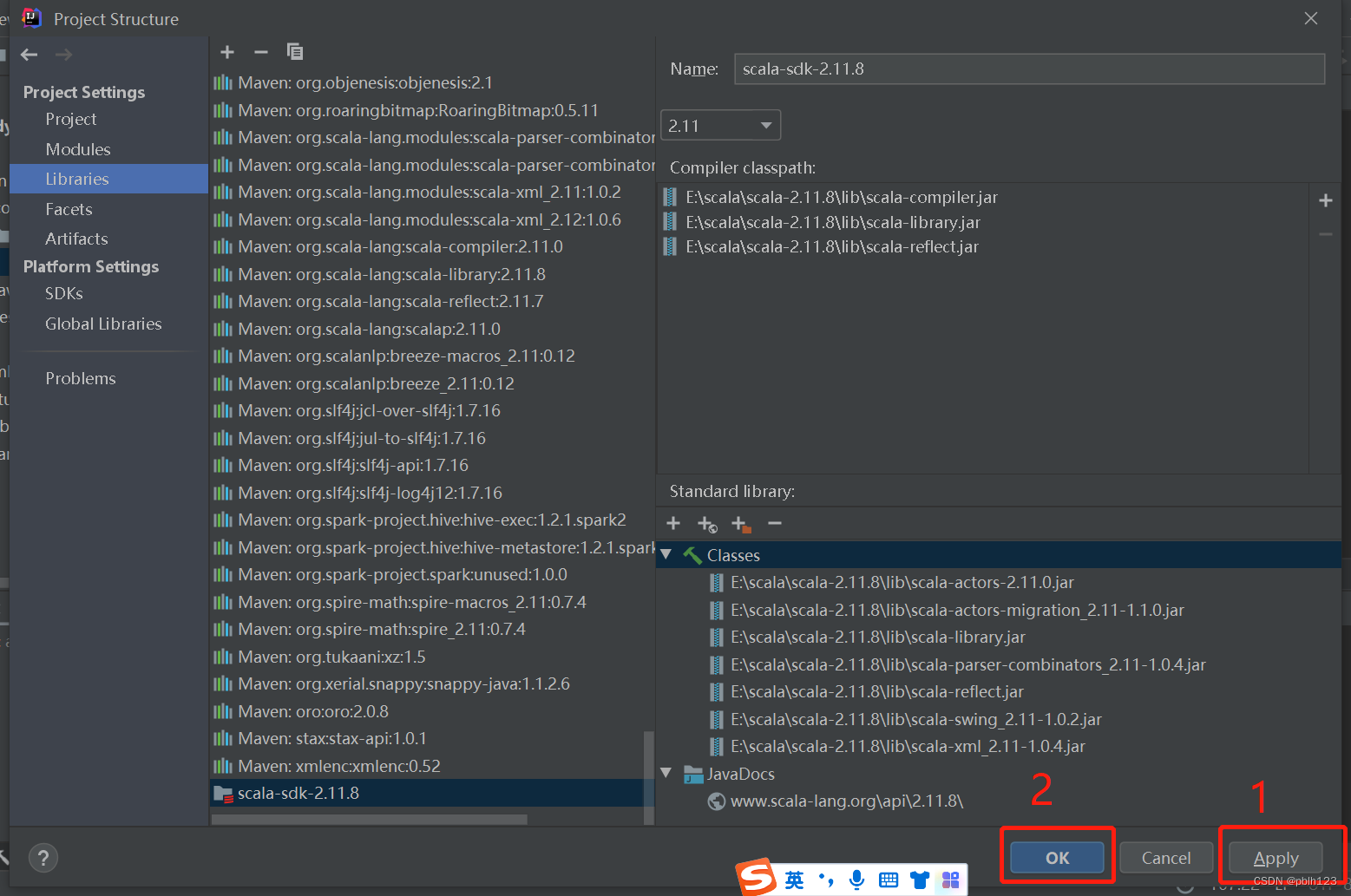
验证:
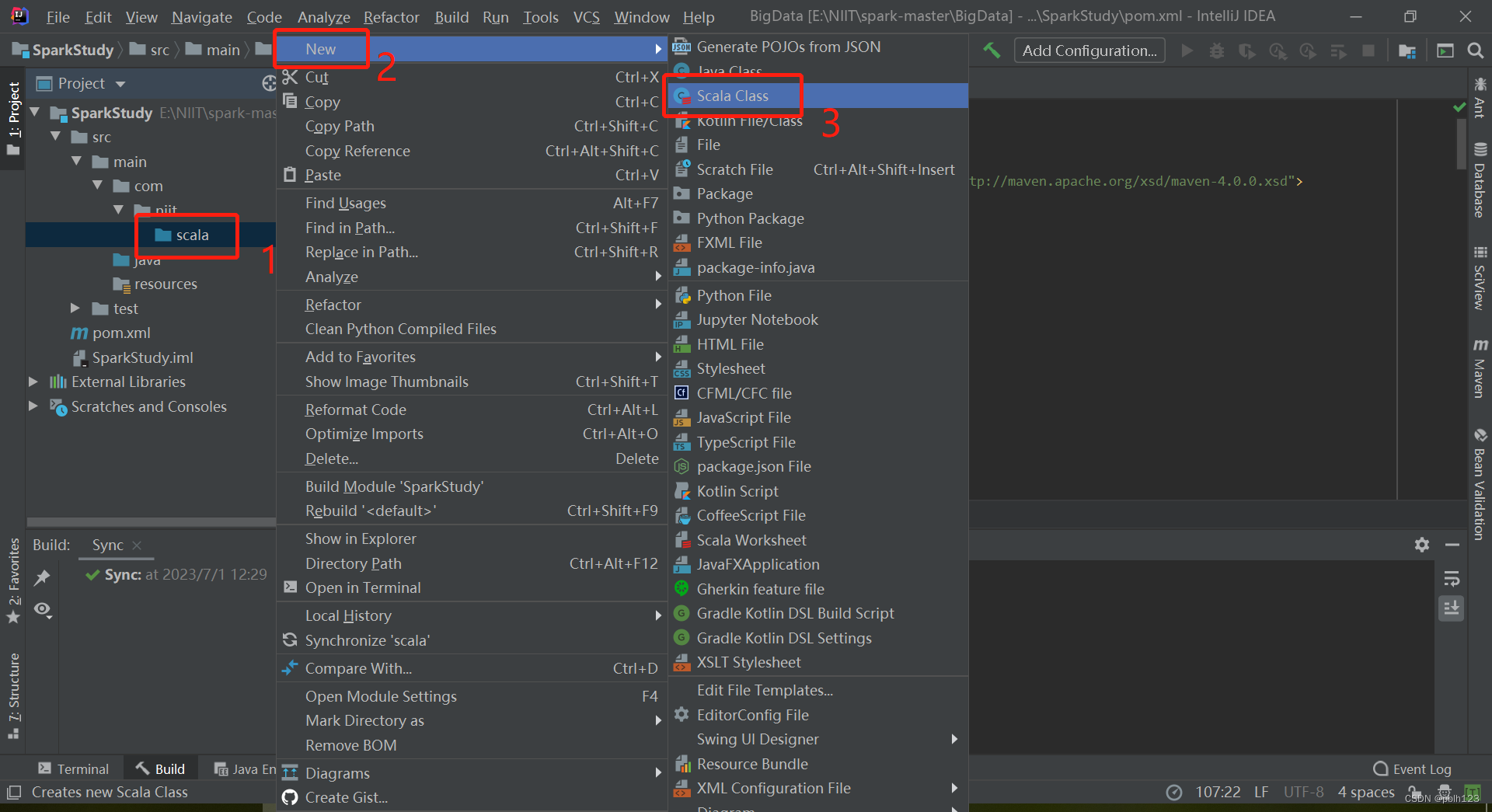
问题解决!
五、编写第一个SCALA程序

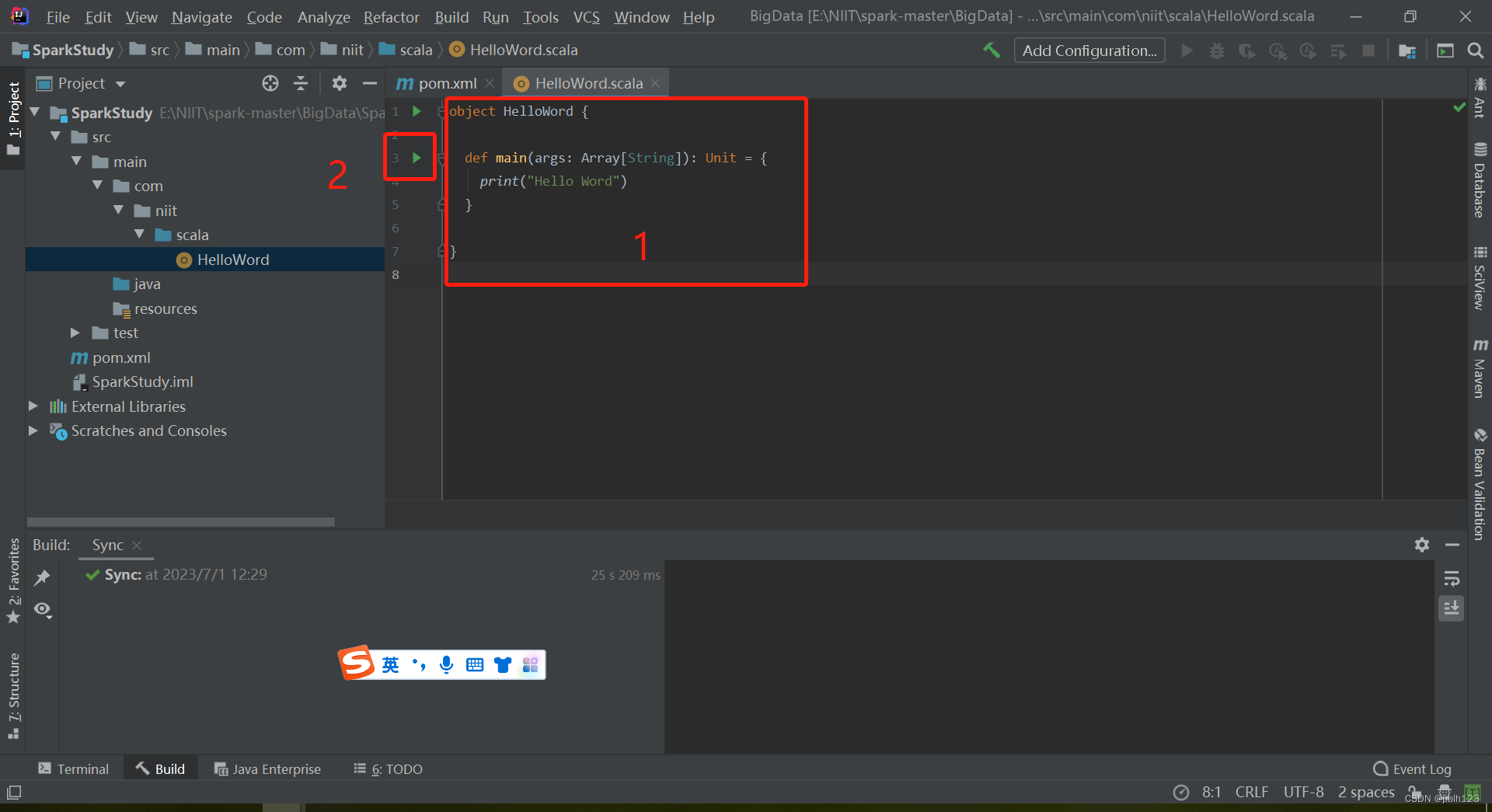
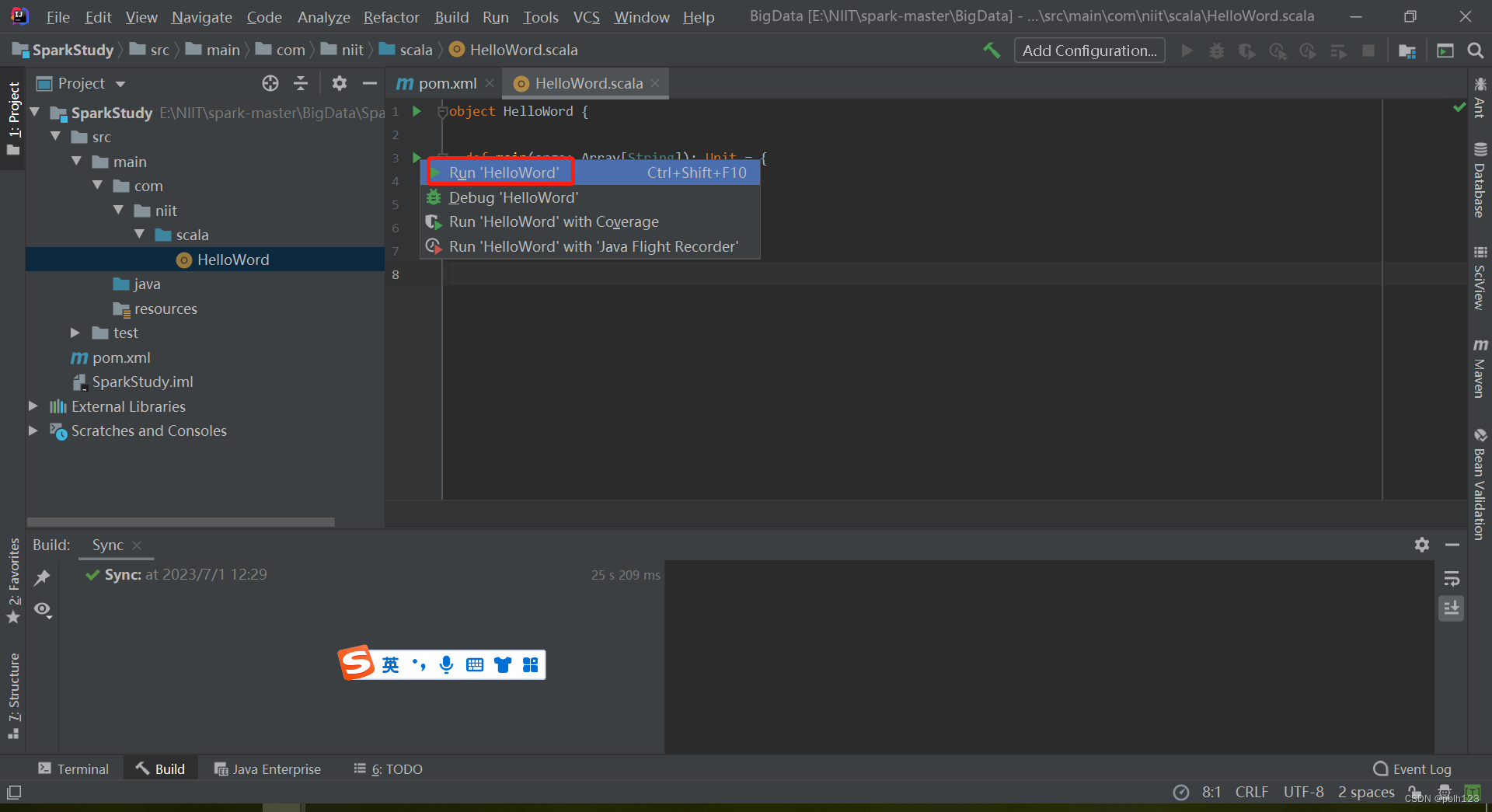
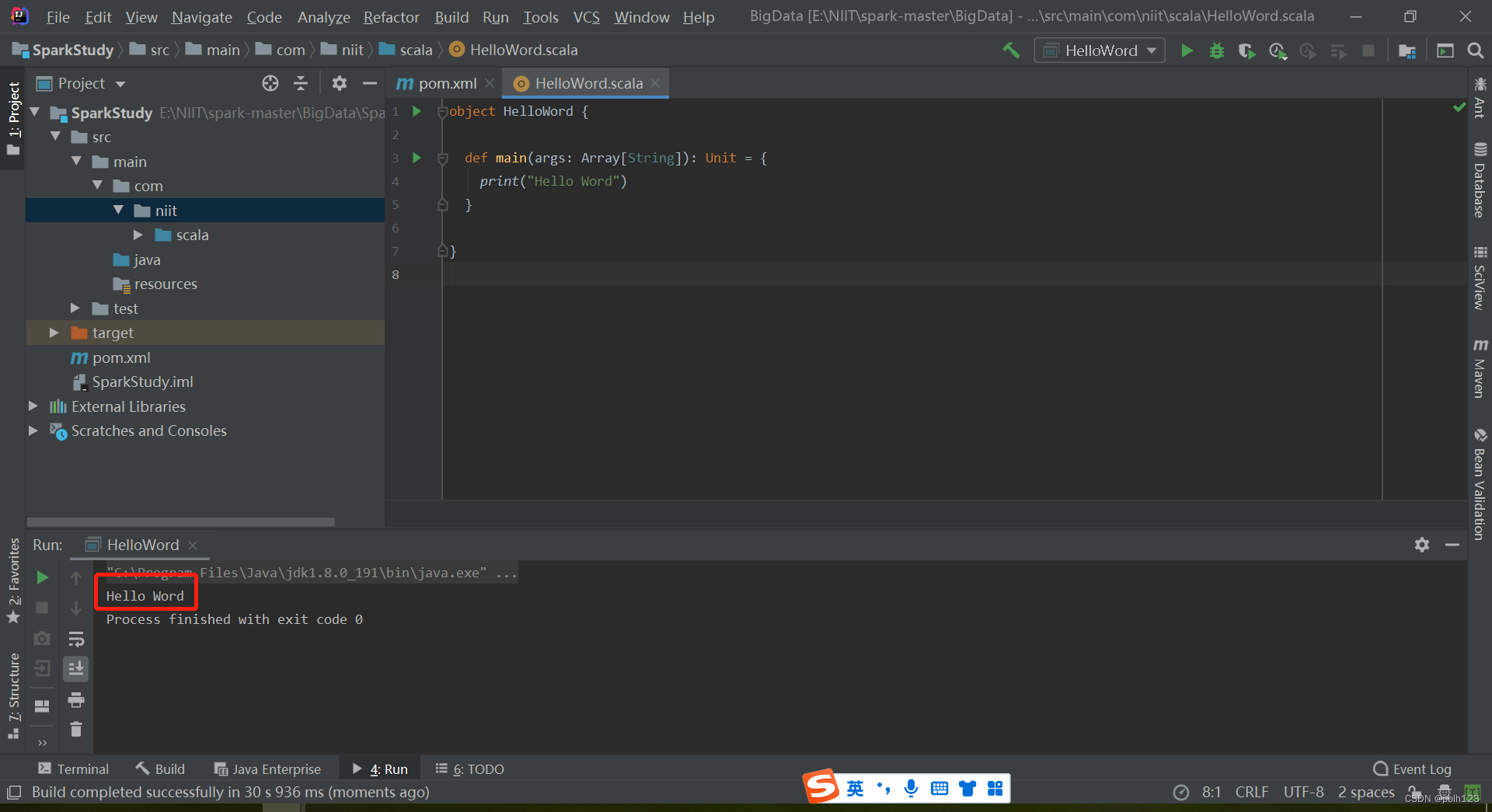
成功!
本文转载自: https://blog.csdn.net/pblh123/article/details/132586982
版权归原作者 pblh123 所有, 如有侵权,请联系我们删除。
版权归原作者 pblh123 所有, 如有侵权,请联系我们删除。