
一,集群和分布式的概念
hadoop+java1.8:链接:https://pan.baidu.com/s/1yTlgLGzz6Ow-YWU-CeF68w
提取码:aoag
–来自百度网盘超级会员V4的分享
集群:所有的机器都配置相同的组件
分布式:不同的机器配置的组件不同
共同点:都依赖多台机器运行
二,Linux知识点的补充学习
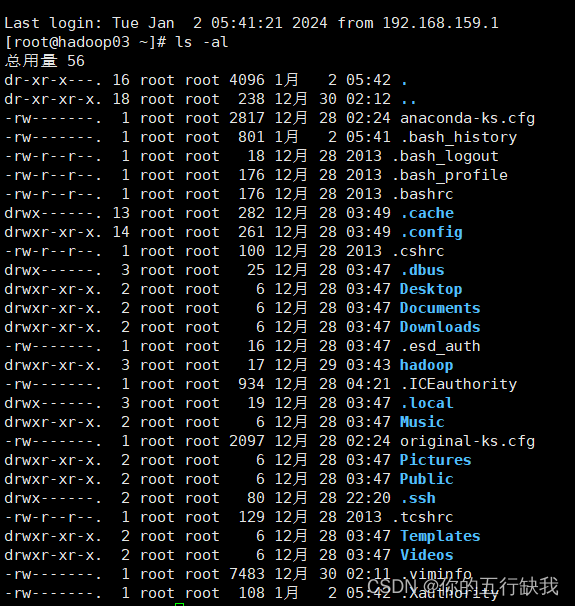
ls命令,显示指定工作目录之下内容
-a 显示所有文件及目录(.开头的隐藏文件也会列出)
-l显示详细的信息(如文件型态,权限,拥有者)
以下为二者的组合,显示所有的文件的纤细信息
cd命令,切换当前的工作目录
ps:~:表示用户目录,如果是root用户就在root目录下
/:表示根目录
…表示当前目录的上一级目录
文件相关的操作命令
mkdir命令:用于在指定目录下创建目录。
-p 确保父目录名称存在,不存在的就创建一个
touch命令:创建一个空文件,无任何内容。
rm命令:用于删除一个文件或目录。
-f 强制删除,无需用户确认
-r 将目录及以下所有递归逐一删除
cp命令:用于复制文件或目录
-r若给出的源文件是一个目录文件,此时将复制该目录下所有的子目录和文件
mv命令:用来为文件或目录改名,获将文件或目录移入其他位置。(可以理解为,在同一个目录下移动并重命名)
cat(concatenate)命令:
用于连接文件并打印到标准输出设备如console控制台上。适合小文件内容查看
more 命令:类似cat,不过会以一页一页的形式显示,更方便使用者逐页阅读,翻页结束自动退出。适合大文件查看。按space键翻下一页,按b往回( back)上一页
tail 命令:用于查看文件的结尾部分的内容
-n 用于显示行数,默认为10,即显示10行的内容
-f(非常重要,可以用于实时日志采集)用于实时显示文件动态追加的内容。会把文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要+文件有更新,就可以看到最新的文件内容
| 管道命令:将前一个命令执行的结果作为内容交给下一个命令处理。可以形成多级管道操作命令1命令2可以将命令1的结果通过命令2作进一步的外理
实例如下(以下命令ps查询系统的进程通过管道给grep查询sshd相关的进程)
echo 命令:用于内容的输出,将内容输出到console控制台上。
‘’>''输出重定向(覆盖)命令
command >file 执行command然后将输出的内容存入file,file内已经存在的内容将被新内容覆盖替代
'>>'输出重定向(追加)命令
command >>file 执行command然后将输出的内容存入file,新内容追加在文件未尾
tar命令
常用于备份文件。是用来建立,还原备份文件的工具程序,它可以加入,解开备份文件内的文件。
-c或–create建立新的备份文件
-x或–extract或–get 从备份文件中还原文件
-v或–verbose显示指令执行过程
-f<备份文件>或–file=<备份文件>指定备份文件。
如果加上-g表示会对文件进行压缩
也可在末尾加上-C(大写)解压到指定的目录
vim命令
方向键控制移动
翻页 pageup pagedown
行尾(end $)行首(home 0)
跳到文件的最后一行 G
跳到文件的第一行 gg
三,Hadoop配置
hadoop介绍
Hadoop核心组件
Hadoop HDFS(分布式文件存储系统):解决海量数据存储
Hadoop YARN(集群资源管理和任务调度框架):解决资源任务调度
Hadoop MapReduce(分布式计算框架):解决海量数据计算
Hadoop特性优点
扩容能力:Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可方便灵活的方式扩展到数以千计的节点
成本低:Hadoop集群允许通过部署普通廉价的机器组成集群来处理大数据,以至于成本很低看重的是集群整体能力。
效率高:通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。
可靠性:能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy )计算任务。所以Hadoop的按位存储和处理数据的能力值得人们信赖。
Hadoop集群整体概述
Hadoop集群包括两个集群:HDFS集群YARN集群
两个集群逻辑上分离、通常物理上在一起
HDFS集群(分布式存储):
主角色:NameNode
从角色:DataNode
主角色辅助角色:SecondaryNameNode
YARN(集群资源管理、调度):
主角色:ResourceManager
从角色:NodeManager
Hadoop的配置
1.配置静态ip,关闭防火墙并设置开机自启动(不展示),修改主机名,修改hosts映射
2.配置Java环境变量
1.下载jdk1.8并且将它存放在/opt/software
2.解压到/opt/module/
3.修改环境变量(在头部加入以下代码)
export JAVA_HOME=/opt/modules/jdk8
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools
4.验证是否成功
输入 java -version
输出版本信息,证明成功
3.将进行过如上配置的虚拟机复制两台
!!!记得修改IP,和主机名等信息
记得同步时间,输入
ntpdate ntp4.aliyun.com即可将主机的时间同步
4.为机器配置免密登录
1.通过命令生成公钥
ssh-keygen -t rsa
2.将生成的公钥发给目标机器,就可以登陆对方的机器
如果要设置本地免密登录,记得将公钥发送给本地
ssh-copy-id -i ~/.ssh/id_rsa.pub root@hadoop02
5.环境搭建成功,开始修改配置文件
(记得创建一个/opt/data/hadoop作为hdfs的存储目录)
以下配置文件在/hadoop/etc/hadoop目录下
1.第一类配置文件
hadoop-env.sh
export JAVA_HOME=/opt/modules/jdk8 #指明java所在的环境变量
#指明各个节点角色使用的用户
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
2.第二类配置文件(4个,:xxxxsite.xml,site表示的是用户定义的配置,会覆盖default中的默认配置)
(1)core-site.xml
vim core-site.xml
<property><!--设置默认的文件系统,这里选择的是hdfs,hadopp支持多种文件系统-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<property><!-- 设置Hadoop本地保存数据路径 ,指定的文件路径一定要存在-->
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
(2)hdfs-site.xml,hdfs文件系统模块配置
<property><!--指定secondarynamenode的位置-->
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:9868</value>
</property>
(3)mapred-site.xml,MapReduce模块配置
vim mapred-site.xml
mapreduce.framework.name
yarn
<property><!-- MR程序历史服务器端地址 -->
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property><!-- 历史服务器web端地址 -->
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
(4)yarn-site.xml yarn模块配置
vim yarn-site.xml
<property><!-- 设置YARN集群主角色运行机器位置 -->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property><!-- 是否将对容器实施物理内存限制 -->
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property><!-- 是否将对容器实施虚拟内存限制。 -->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property><!-- 开启日志聚集 -->
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property><!-- 设置yarn历史服务器地址 -->
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value>
</property>
<property><!-- 保存的时间7天 -->
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
3.第三类配置文件
vim workers
hadoop01
hadoop02
hadoop03
6.修改完成后,向其他节点,分发配置文件
scp -r hadoop root@hadoop02:/opt/modules
7.修改hadoop环境变量,并且将它分发给其他机器
vim /etc/profile
export HADOOP_HOME=/opt/modules/hadoop
export PATH=
P
A
T
H
:
PATH:
PATH:HADOOP_HOME/bin:$HADOOP_HOME/sbin
source vim /etc/profile使配置文件生效
scp -r /etc/profile root@hadoop02:/opt/modules
8.在NameNode节点格式化
hdfs namenode -format
如果出现了,说明成功了
9.将启动hadoop
NameNode节点是输入
1.start-dfs.sh
2.start-yarn.sh
没有什么报错后,在浏览器输入,访问查看节点和文件系统是否正常
http://hadoop01:9870/
http://hadoop01:8088/
到此,配置完成
版权归原作者 你的五行缺我 所有, 如有侵权,请联系我们删除。