
提示:最近有个新需求,需要在mysql数据库中插入亿级数据,同时在查询时要求秒级返回。我的想法是第一步要在数据库中插入亿级数据,第二步给字段加索引以达到查询秒级返回的效果。
文章目录
前言
亿级数据的秒级返回,比较困难的是快速在数据库中插入亿级数据,所以这一步花了很多时间来处理。下面分两步来进行,第一步插入亿级数据,第二步给字段增加索引。注意,建表时不要加索引,这样会让insert执行时慢很多。
提示:以下是本篇文章正文内容,下面案例可供参考
一、在mysql数据库中建表,并插入亿级数据
假设插入1000W条数据,如果没有索引,可能只需要生成1G的空间,如果有了索引,那么可能额外再生成0.5G的索引数据,同时mysql服务器还要计算这些索引,因此,如果表存在索引,插入数据时,受CPU计算索引数据及硬盘写入索引数据的影响,会更慢。所以先建表。
1.建表语句
代码如下(示例):
DROP TABLE IF EXISTS `k_user`;
CREATE TABLE `k_user` (
`id` int(0) NOT NULL AUTO_INCREMENT,
`name` varchar(45) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL COMMENT '账号',
`pass_word` varchar(45) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '密码',
`nick_name` varchar(45) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '昵称',
`create_time` datetime(0) DEFAULT NULL COMMENT '创建时间',
`phone` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '手机号码',
PRIMARY KEY(`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT =356 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
2.插入亿级数据
首先尝试过用java插入数据,结果非常慢,代码就不贴了;后面选择的用python来造数据,前提要有python环境。
代码如下(示例):
# 向mysql的数据库表中插入1亿条数据
import MySQLdb
import MySQLdb.cursors
import random
import time
# 批量插的次数
loop_count =10000
# 每次批量查的数据量
batch_size =10000
success_count =0
fails_count =0
# 数据库的连接
# 使用 SSCursor(流式游标),避免客户端占用大量内存。(这个 cursor 实际上没有缓存下来任何数据,它不会读取所有所有到内存中,它的做法是从储存块中读取记录,并且一条一条返回给你。)
conn = MySQLdb.connect(host="{IP}",
user="{帐号}",
passwd="{密码}",
db="{数据库名}",
port="{端口}",
cursorclass=MySQLdb.cursors.SSCursor)
chars = 'AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz'
digits ='0123456789'
def random_generate_string(length):return''.join(random.sample(chars, length))
def random_generate_number(length):if length >len(digits):
digit_list = random.sample(digits,len(digits))
digit_list.append(random.choice(digits))return''.join(digit_list)return''.join(random.sample(digits, length))
def random_generate_data(num):
c =[num]
phone_num =13100000000
def _random_generate_data():
c[0]+=1return(c[0],"name_"+str(random.randrange(100000)),random_generate_string(20),"nick_name_"+str(random.randrange(100000)),
time.strftime("%Y-%m-%d %H:%M:%S"),
phone_num + c[0],)return _random_generate_data
def execute_many(insert_sql, batch_data):
global success_count, fails_count
cursor = conn.cursor()
try:
cursor.executemany(insert_sql, batch_data)
except Exception as e:
conn.rollback()
fails_count = fails_count +len(batch_data)print(e)
raise
else:
conn.commit()
success_count = success_count +len(batch_data)print(str(success_count)+" commit")
finally:
cursor.close()
try:#user表列的数量
column_count =6
# 插入的SQL
insert_sql ="replace into k_user(id, name, pass_word, nick_name, create_time, phone) values ("+",".join(["%s"for x in range(column_count)])+")"
batch_count =0
begin_time = time.time()for x in range(loop_count):
batch_count = x * batch_size +1#print(batch_count)
gen_fun =random_generate_data(batch_count)
batch_data =[gen_fun()for x in range(batch_size)]execute_many(insert_sql, batch_data)
end_time = time.time()
total_sec = end_time - begin_time
qps = success_count / total_sec
print("总共生成数据: "+str(success_count))print("总共耗时(s): "+str(total_sec))print("QPS: "+str(qps))
except Exception as e:print(e)
raise
else:
pass
finally:
pass
二、亿级数据插入完毕后,按需添加索引
1.按需增加索引
1.添加primary key(主键索引)
alter table k_user add primary key(id);
2.添加unique(唯一索引)
alter table k_user add unique(name);
3.添加index(普通索引)
alter table k_user add index (index_name) (nick_name);
4.添加fulltext(全文索引)
alter table k_user add fulltext (create_time);
5.添加多列索引
alter table 表名 add index 索引名(index_name) (列名1,列名2…);
2.秒级返回
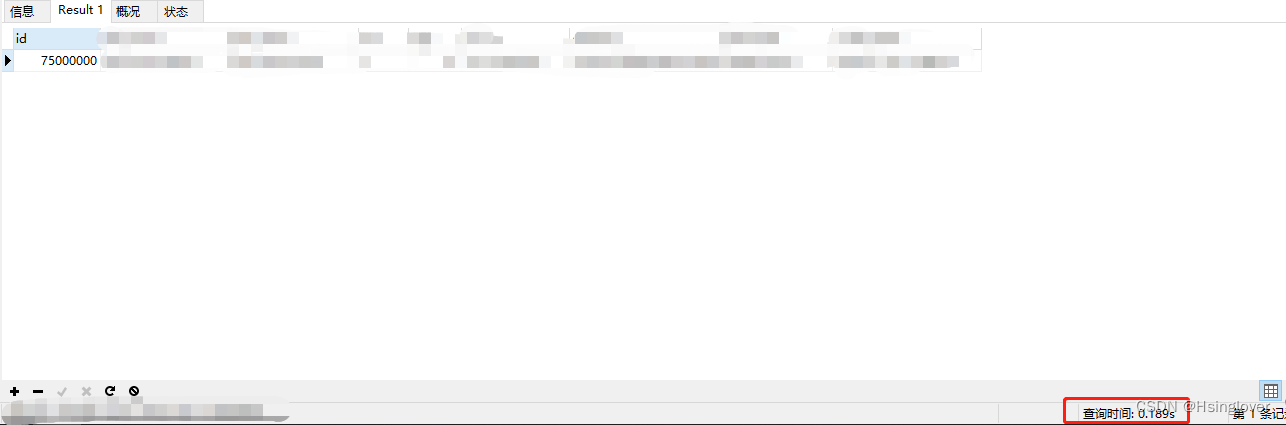
总结
以上就是今天要讲的内容,本文简单介绍了亿级数据秒级返回的实现,希望能对大家有所帮助。
本文参考的原文链接:https://blog.csdn.net/weixin_44984864/article/details/107141534
原文建表加了索引,insert非常慢,此文已经改良,能较快实现数据库中insert亿级数据。
版权归原作者 Hsinglover 所有, 如有侵权,请联系我们删除。