
一、Spark是什么
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。主要用于数据计算,经常被认为是Hadoop框架的升级版。
二、Spark的特点
1、速度快
小生根据官方数据统计,与Hadoop相比,Spark基于内存的运算效率要快100倍以上,基于硬盘的运算效率也要快10倍以上。Spark实现了高效的DAG执行引擎,能够通过内存计算高效地处理数据流。
2、易用性
Spark编程支持Java、Python、Scala及R语言,并且还拥有超过80种高级算法,除此之外,Spark还支持交互式的Shell操作,开发人员可以方便地在Shell客户端中使用Spark集群解决问题。
3、通用性
Spark提供了统一的解决方案,适用于批处理、交互式查询(SparkSQL)、实时流处理(SparkStreaming)、机器学习(SparkMLlib)和图计算(GraphX),它们可以在同一个应用程序中无缝地结合使用,大大减少大数据开发和维护的人力成本和部署平台的物力成本。
4、兼容性
Spark开发容pSpark可以运行在Hadoop模式、Mesos模式、Standalone独立模式或Cloud中,并且还可以访问各种数据源,包括本地文件系统、HDFS、Cassandra、HBase和Hive等。
三、什么是RDD,宽依赖、窄依赖
RDD:是一个容错的、只读的、可进行并行操作的数据结构,是一个分布在集群各个节点中的存放元素的集合。RDD的创建有3种不同的方法。 第一种是将程序中已存在的Seq集合(如集合、列表、数组)转换成RDD。 第二种是对已有RDD进行转换得到新的RDD,这两种方法都是通过内存中已有的集合创建RDD的。 第三种是直接读取外部存储系统的数据创建RDD。
窄依赖:表现为一个父RDD的分区对应于一个子RDD的分区或者多个父RDD的分区对应于一个子RDD的分区。
宽依赖:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。
四、定义与使用数组
数组是Scala中常用的一种数据结构,数组是一种存储了相同类型元素的固定大小的顺序集合。
(1).scala定义一个数组的方法

**(2).数组常用的方法 **
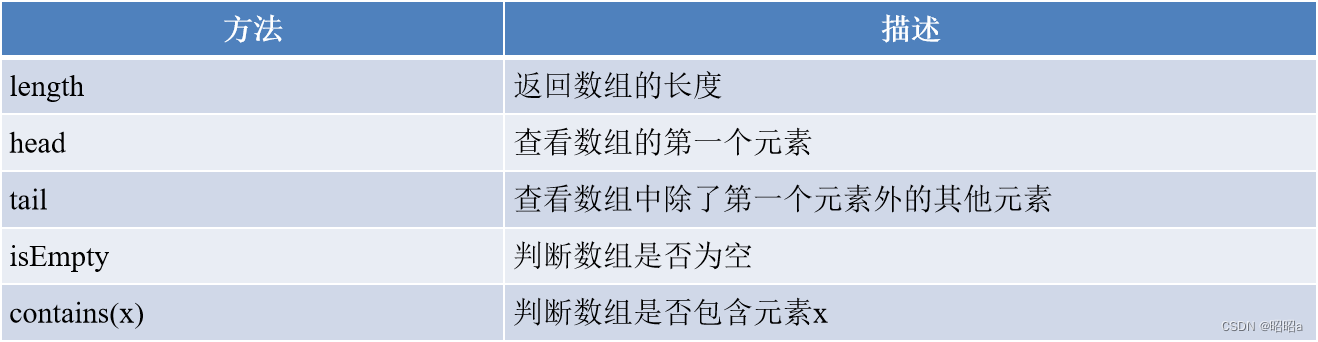
**扩展:Scala可以使用range()方法创建区间数组 **
(3).定义与使用函数
函数是Scala的重要组成部分,Scala作为支持函数式编程的语言,可以将函数作为对象.
定义函数的语法格式如下:

匿名函数:
- 匿名函数即在定义函数时不给出函数名的函数。
- Scala中匿名函数是使用箭头“=>”定义的,箭头的左边是参数列表,箭头的右边是表达式,表达式将产生函数的结果。
- 通常可以将匿名函数赋值给一个常量或变量,再通过常量名或变量名调用该函数。
- 若函数中的每个参数在函数中最多只出现一次,则可以使用占位符“_”代替参数。
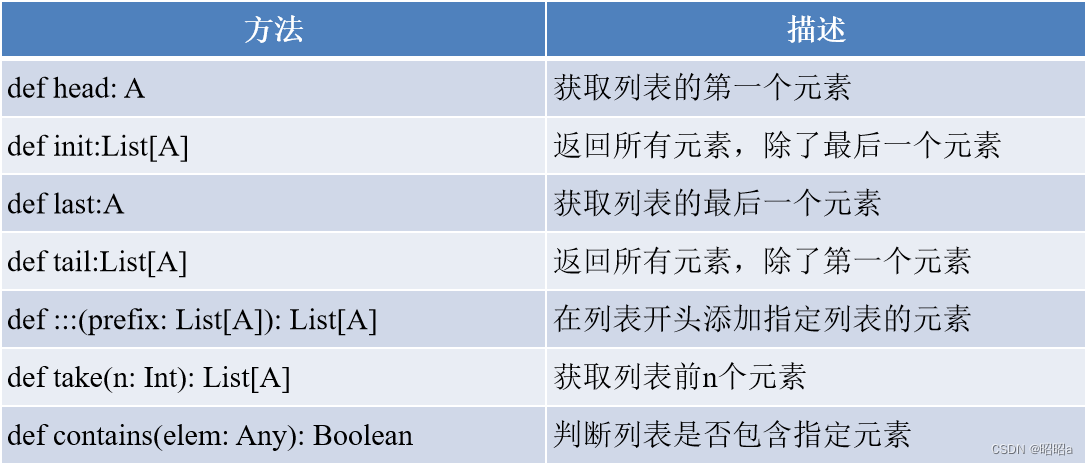
**Scala中常用的查看列表元素的方法有head、init、last、tail和take()**。
•head:查看列表的第一个元素。
•tail:查看第一个元素之后的其余元素。
•last:查看列表的最后一个元素。
•Init:查看除最后一个元素外的所有元素。
•take():查看列表前n个元素。
合并两个列表还可以使用concat()方法。
用户可以使用contains()方法判断列表中是否包含某个元素,若列表中存在指定的元素则返回true,否则返回false。
Scala Set(集合)是没有重复的对象集合,所有的元素都是唯一的。
(4).集合操作常用方法:
Scala合并两个列表时使用的是:::()或concat()方法,而合并两个集合使用的是++()方法。
(5).用函数组合器
map()方法
可通过一个函数重新计算列表中的所有元素,并且返回一个包含相同数目元素的新列表。
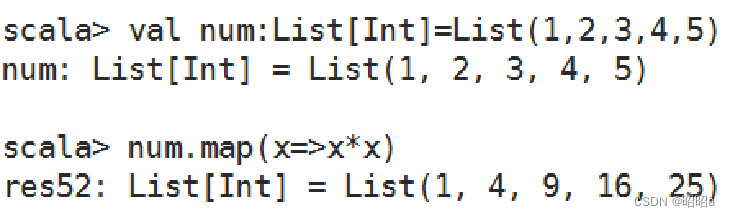
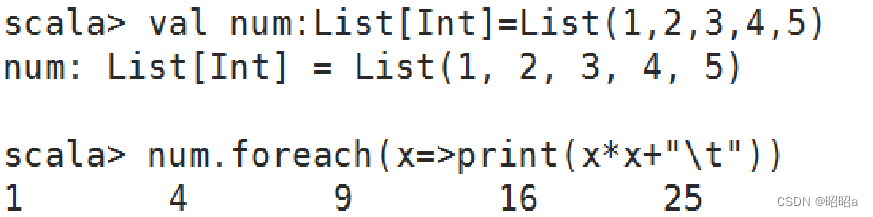
**foreach()**方法
和**map()**方法类似,但是foreach()方法没有返回值,只用于对参数的结果进行输出。
**filter()**方法
可以移除传入函数的返回值为false的元素

**flatten()**方法
可以将嵌套的结构展开,即flatten()方法可以将一个二维的列表展开成一个一维的列表。

**flatMap()**方法
结合了map()方法和flatten()方法的功能,接收一个可以处理嵌套列表的函数,再对返回结果进行连接。

groupBy()方法
可对集合中的元素进行分组操作,返回的结果是一个映射。

五、创建RDD
从内存中读取数据创建RDD
(1).parallelize()
parallelize()方法有两个输入参数,说明如下:
- 要转化的集合,必须是Seq集合。Seq表示序列,指的是一类具有一定长度的、可迭代访问的对象,其中每个数据元素均带有一个从0开始的、固定的索引。
- 分区数。若不设分区数,则RDD的分区数默认为该程序分配到的资源的CPU核心数。
可以使用
SparkContext
的
parallelize
方法将一个已有的集合转换为RDD。
基本语法:
parallelize(collection, numSlices=None)
示例:
import org.apache.spark.{SparkConf, SparkContext}
val conf = new SparkConf().setAppName("ParallelizeExample").setMaster("local")
val sc = new SparkContext(conf)
val data = Array(1, 2, 3, 4, 5)
val rdd = sc.parallelize(data)
rdd.foreach(println)
sc.stop()
效果展示:

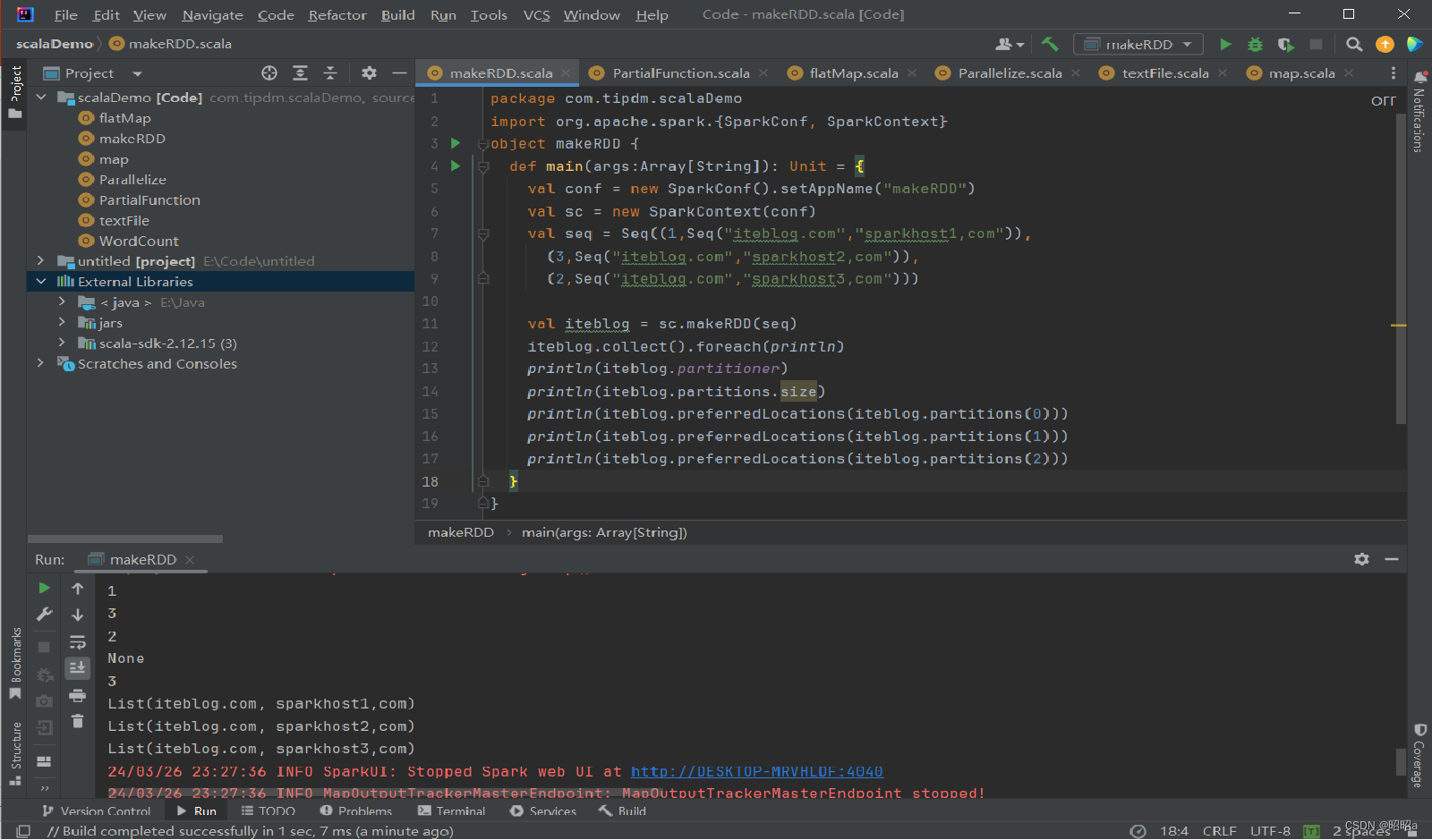
(2).makeRDD()
makeRDD()方法有两种使用方式:
- 第一种方式的使用与parallelize()方法一致;
- 第二种方式是通过接收一个是Seq[(T,Seq[String])]参数类型创建RDD。
从外部存储系统中读取数据创建RDD
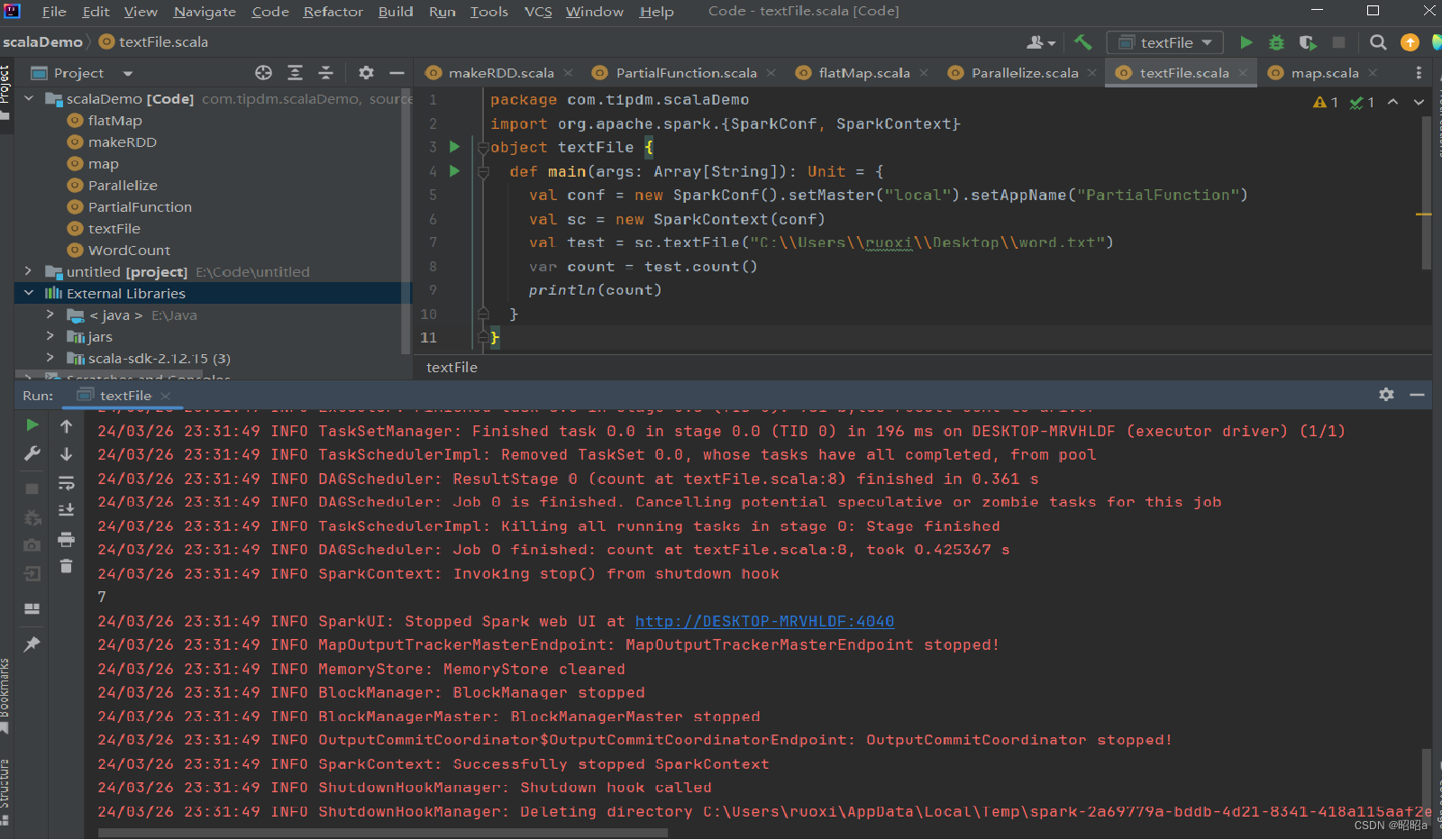
(1)通过HDFS文件创建RDD
直接通过textFile()方法读取HDFS文件的位置即可。
(2)通过Linux本地文件创建RDD
本地文件的读取也是通过sc.textFile("路径")的方法实现的,在路径前面加上“file://”表示从Linux本地文件系统读取。在IntelliJ IDEA开发环境中可以直接读取本地文件;但在spark-shell中,要求在所有节点的相同位置保存该文件才可以读取它.
示例:
六、操作方法
1.map()方法
是一种基础的RDD转换操作,可以对RDD中的每一个数据元素通过某种函数进行转换并返回新的RDD。map() 方法用于对集合(如列表、数组、映射等)中的每个元素应用一个函数,并返回结果的新集合。
示例:
val list = List(1, 2, 3, 4, 5)
val incremented = list.map(x => x + 1)

2.sortBy() 方法:
用于对标准RDD进行排序,有3个可输入参数
- 第1个参数是一个函数f:(T) => K,左边是要被排序对象中的每一个元素,右边返回的值是元素中要进行排序的值。
- 第2个参数是ascending,决定排序后RDD中的元素是升序的还是降序的,默认是true,即升序排序,如果需要降序排序那么需要将参数的值设置为false。
- 第3个参数是numPartitions,决定排序后的RDD的分区个数,默认排序后的分区个数和排序之前的分区个数相等,即this.partitions.size。
- 第一个参数是必须输入的,而后面的两个参数可以不输入
示例:
val list = List(3, 1, 4, 1, 5, 9, 2, 6)
val sortedList = list.sortBy(x => x)
// sortedList: List[Int] = List(1, 1, 2, 3, 4, 5, 6, 9)

3.
collect()
方法
是一种行动操作,可以将RDD中所有元素转换成数组并返回到Driver端,适用于返回处理后的少量数据。
因为需要从集群各个节点收集数据到本地,经过网络传输,并且加载到Driver内存中,所以如果数据量比较大,会给网络传输造成很大的压力。 因此,数据量较大时,尽量不使用collect()方法,否则可能导致Driver端出现内存溢出问题。
collect()方法有以下两种操作方式:
1.collect:直接调用collect返回该RDD中的所有元素,返回类型是一个Array[T]数组。

2.collect[U: ClassTag](f: PartialFunction[T, U]):RDD[U]。这种方式需要提供一个标准的偏函数,将元素保存至一个RDD中。首先定义一个函数one,用于将collect方法得到的数组中数值为1的值替换为“one”,将其他值替换为“other”。
 4.flatMap()方法
4.flatMap()方法
将函数参数应用于RDD之中的每一个元素,将返回的迭代器(如数组、列表等)中的所有元素构成新的RDD。
示例:

5.take()方法
用于获取RDD的前N个元素,返回数据为数组
take()与collect()方法的原理相似,collect()方法用于获取全部数据,take()方法获取指定个数的数据。
示例:获取RDD的前5个元素

七、转换操作和行动操作
对于RDD有两种计算方式:
转换操作(返回值还是一个RDD)---也叫懒操作,不是立即执行
执行操作(返回值不是一个RDD)---立即执行
转换操作
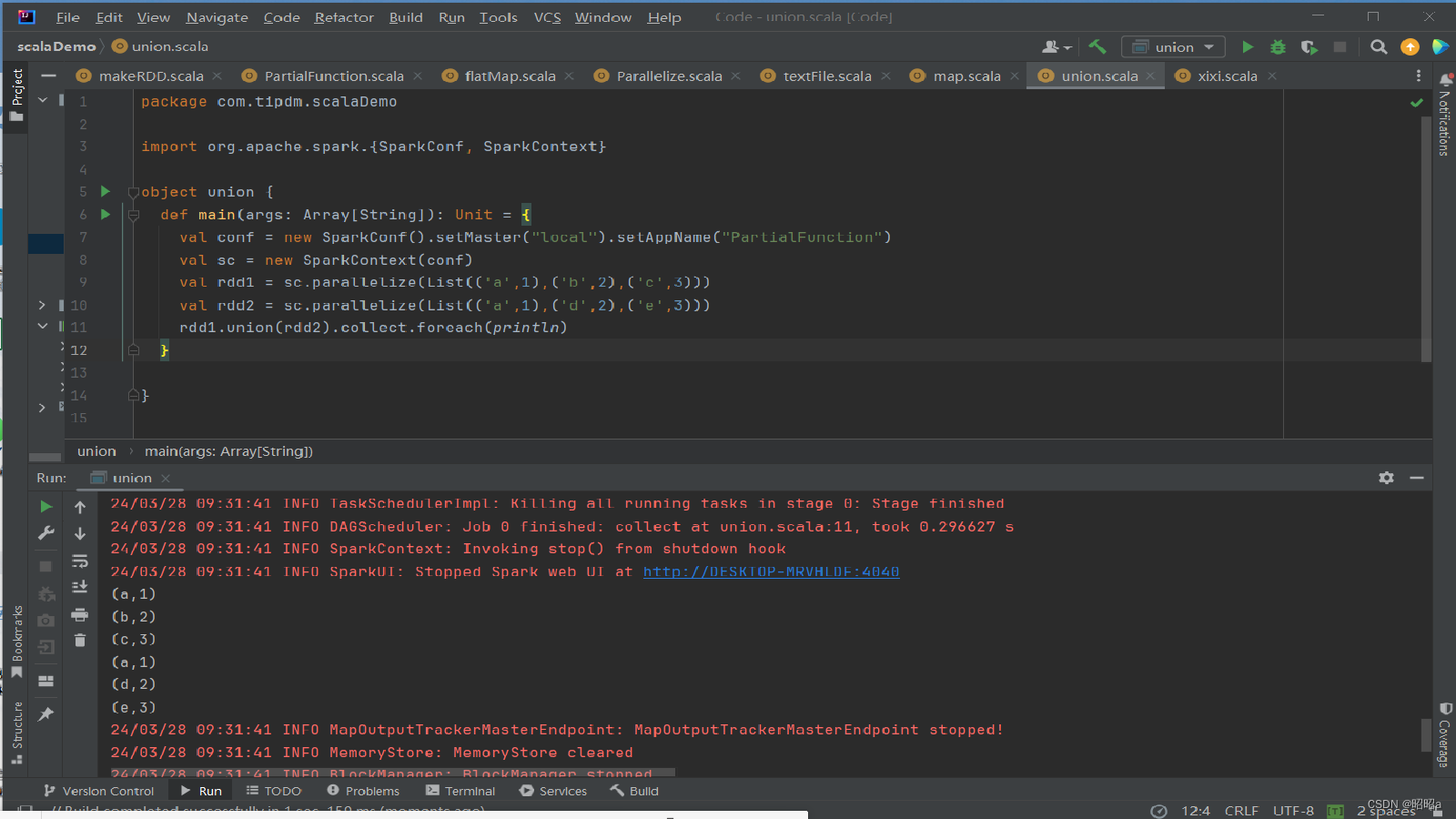
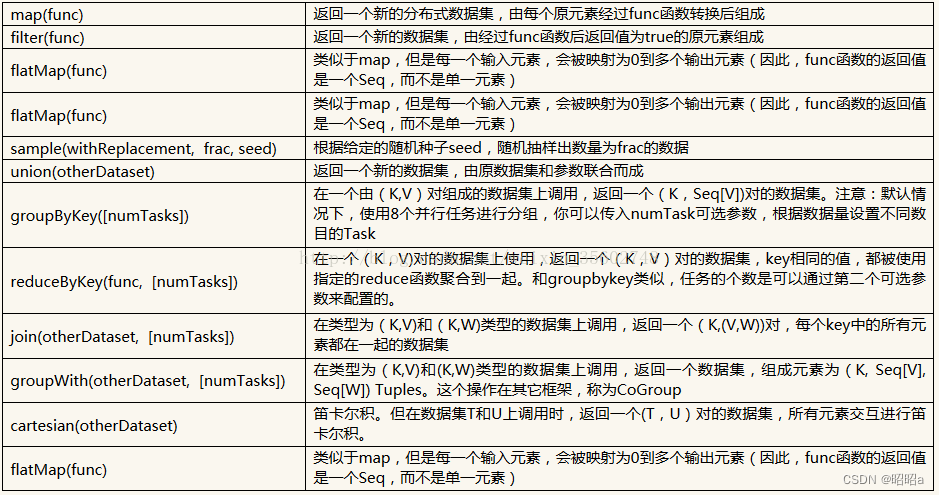
(1)union()方法
用于将两个RDD合并成一个,不进行去重操作,而且两个RDD中每个元素中的值的个数、数据类型需要保持一致。
示例:
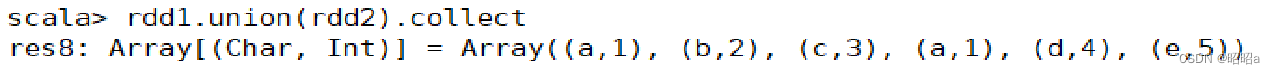
(2)filter()方法
用于过滤RDD中的元素
filter()方法需要一个参数,这个参数是一个用于过滤的函数,该函数的返回值为Boolean类型。 filter()方法将返回值为true的元素保留,将返回值为false的元素过滤掉,最后返回一个存储符合过滤条件的所有元素的新RDD。
示例:创建一个RDD,并且过滤掉每个元组第二个值小于等于1的元素。
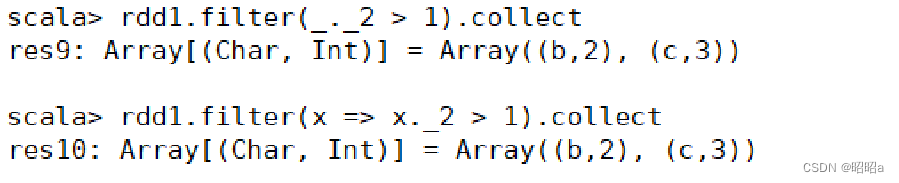
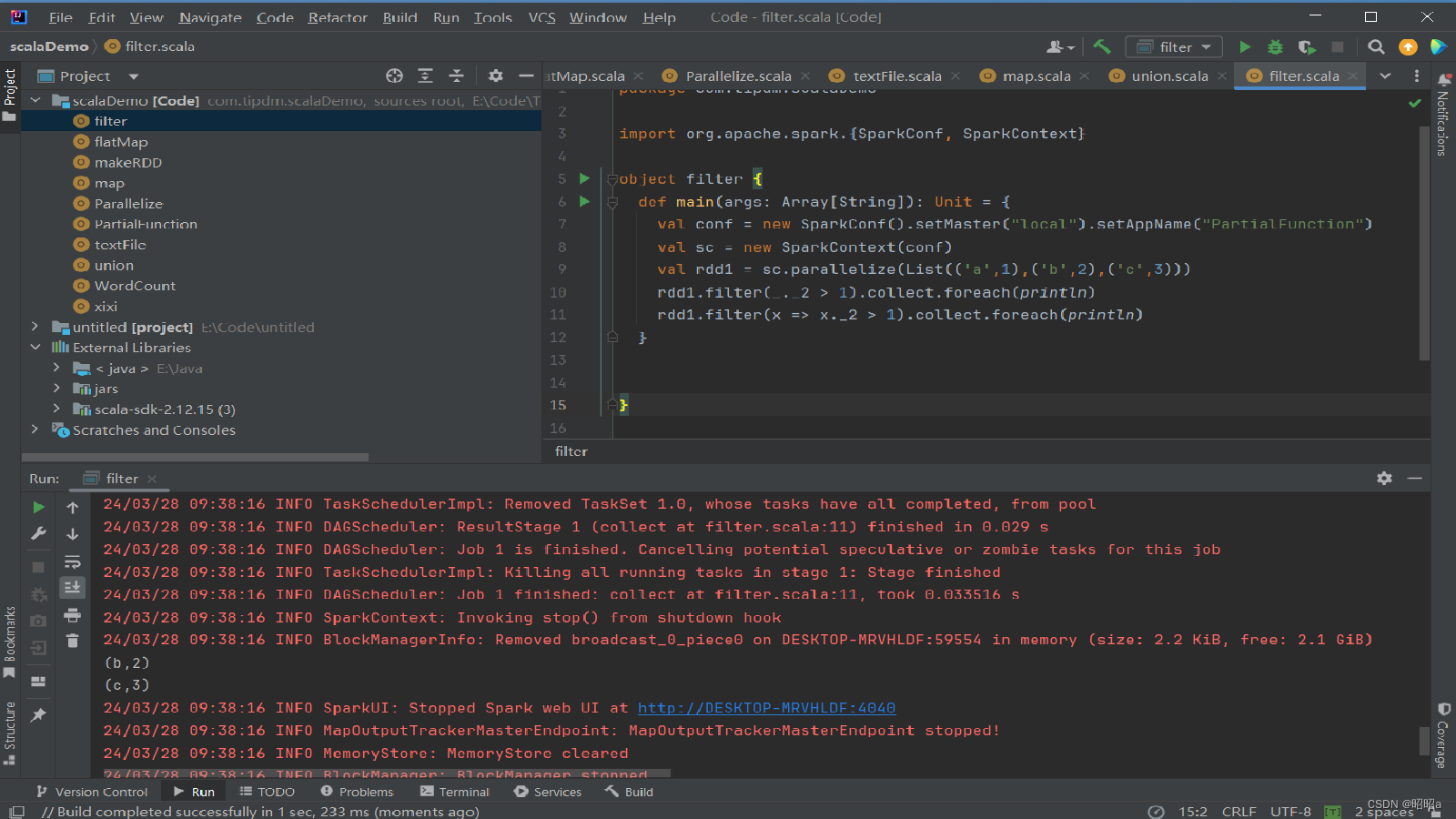
(3)distinct()方法
用于RDD的数据去重,去除两个完全相同的元素,没有参数。
示例:创建一个带有重复数据的RDD,并使用distinct()方法去重。

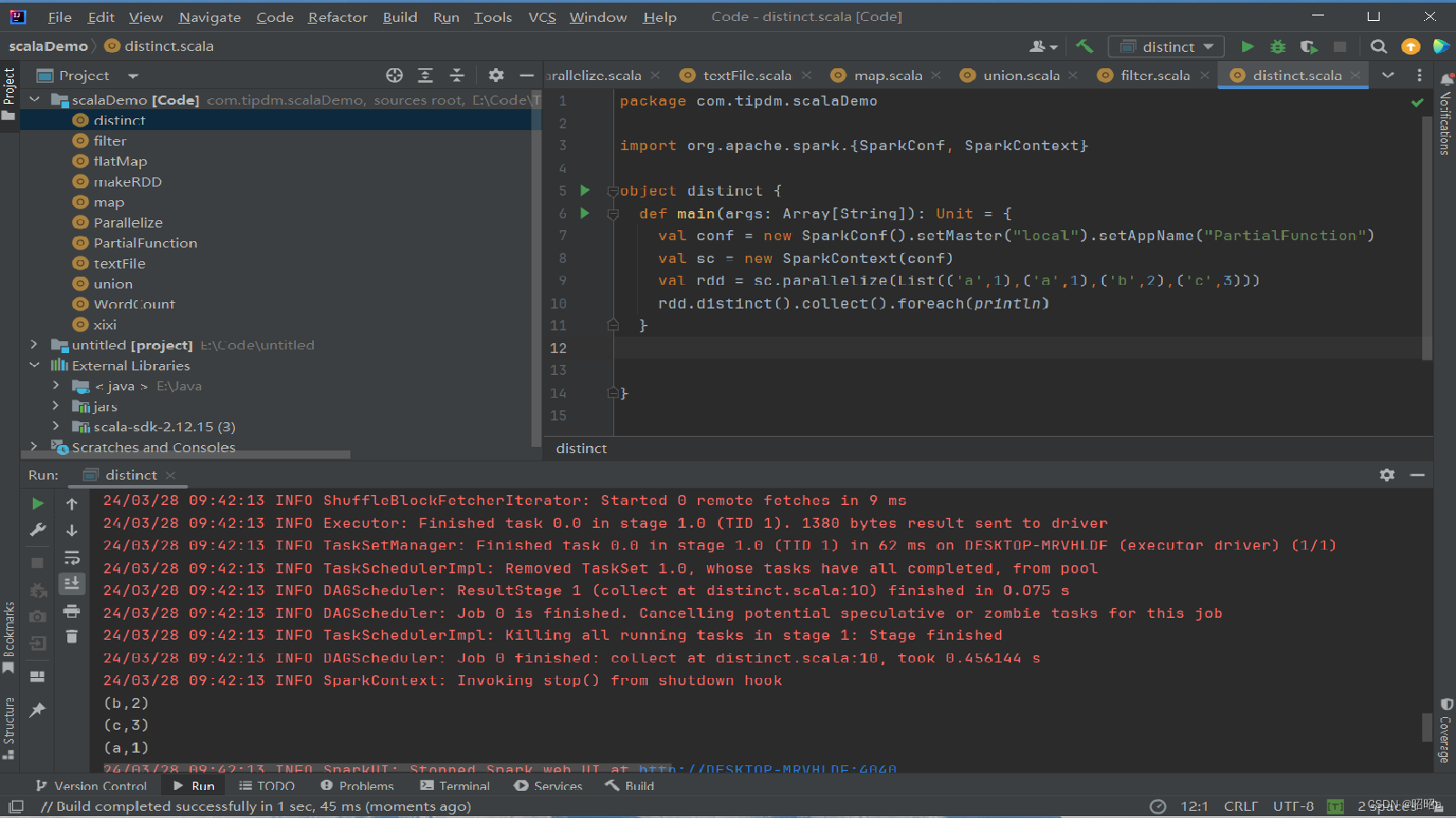
(4)
intersection()
方法
用于求出两个RDD的共同元素,即找出两个RDD的交集,参数是另一个RDD,先后顺序与结果无关。
示例:创建两个RDD,其中有相同的元素,通过intersection()方法求出两个RDD的交集


(5)subtract()方法
用于将前一个RDD中在后一个RDD出现的元素删除,可以认为是求补集的操作,返回值为前一个RDD去除与后一个RDD相同元素后的剩余值所组成的新的RDD。两个RDD的顺序会影响结果。
示例:创建两个RDD,分别为rdd1和rdd2,包含相同元素和不同元素,通过subtract()方法求rdd1和rdd2彼此的补集。

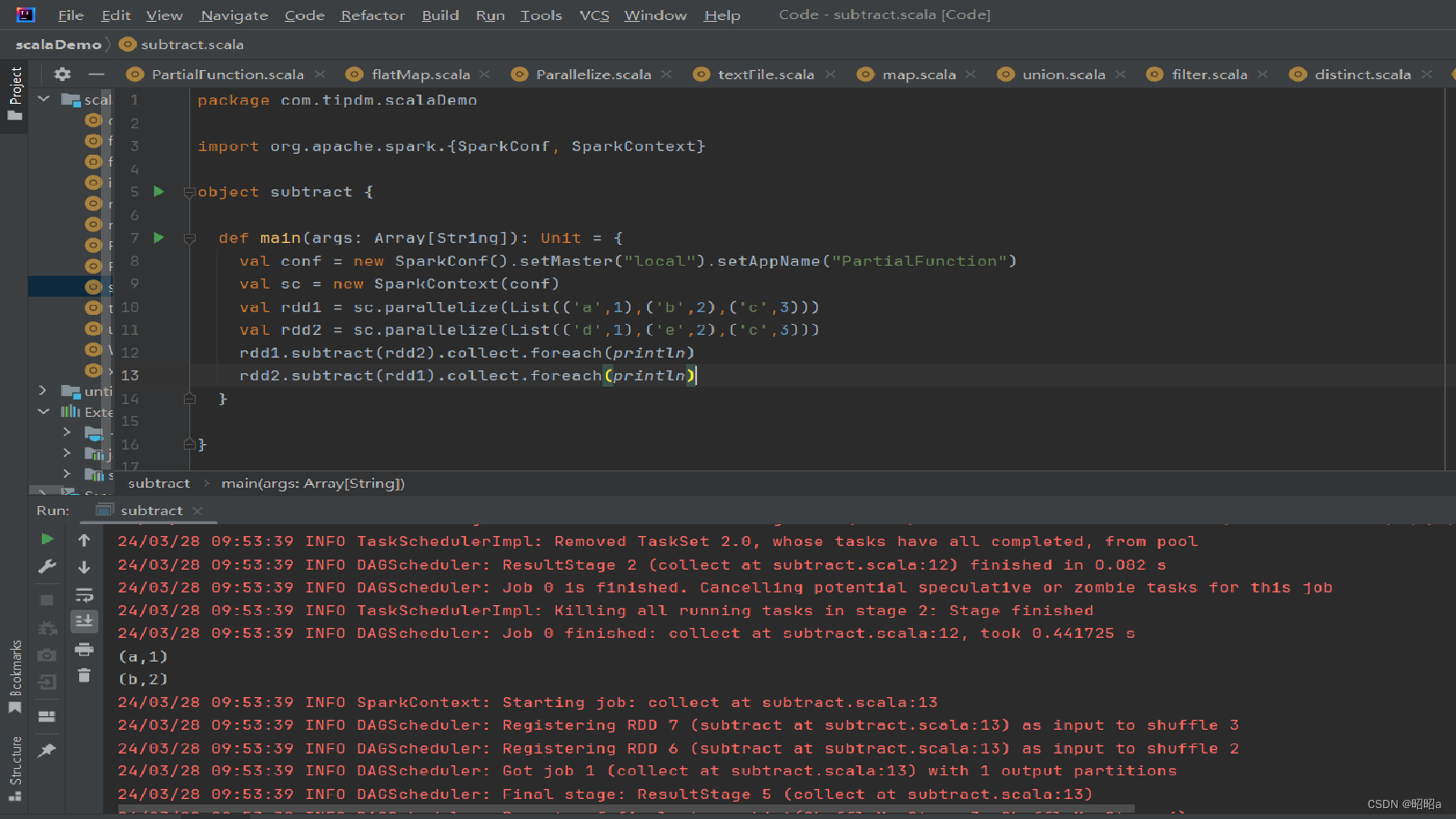
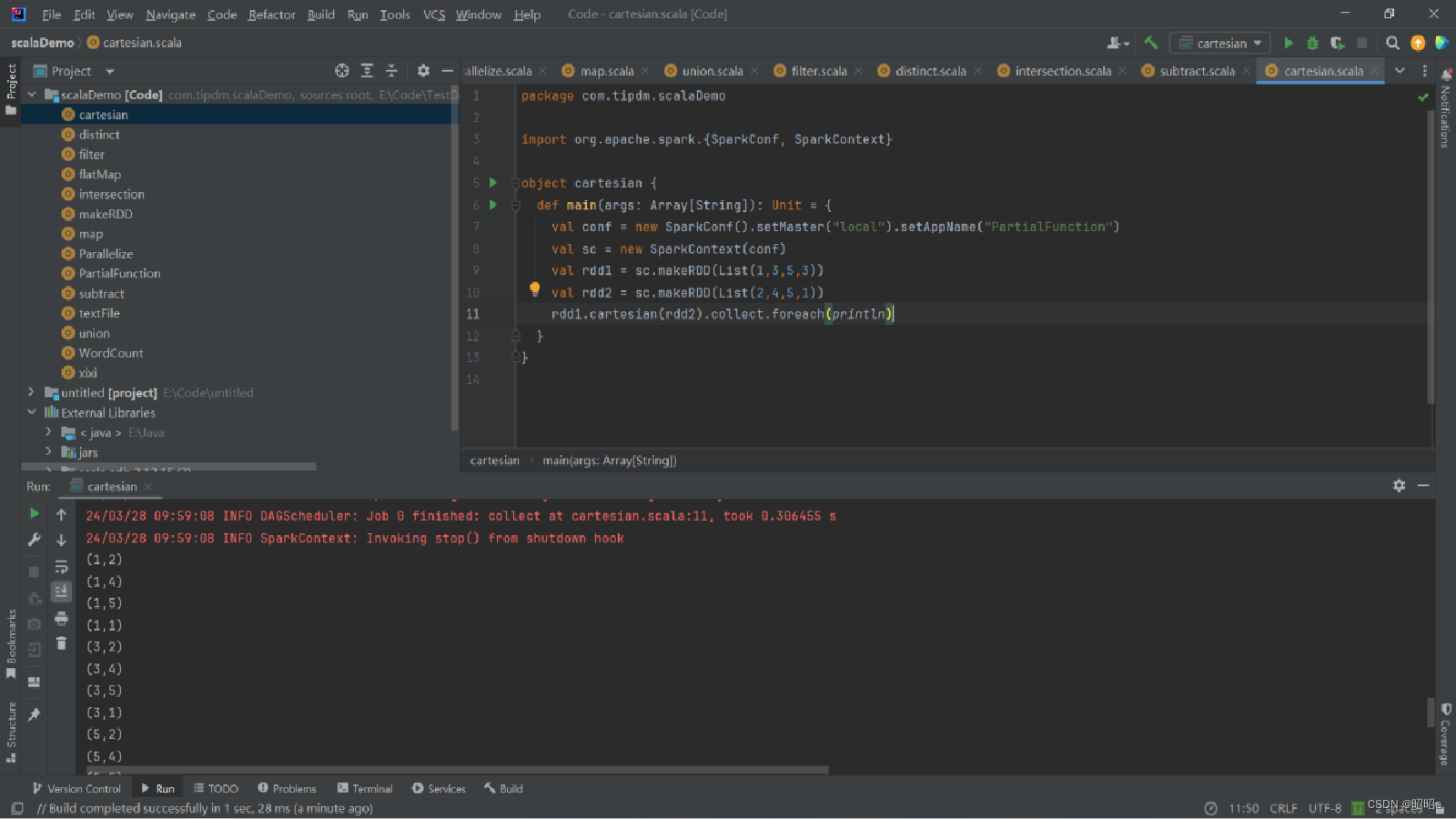
(6)cartesian()方法
可将两个集合的元素两两组合成一组,即求笛卡儿积。
示例:创建两个RDD,分别有4个元素,通过cartesian()方法求两个RDD的笛卡儿积。

(7)其他方法
行动操作
执行操作会返回结果或把RDD数据写到存储系统中。Actions是触发Spark启动计算的动因。

八、创建键值对RDD的方法
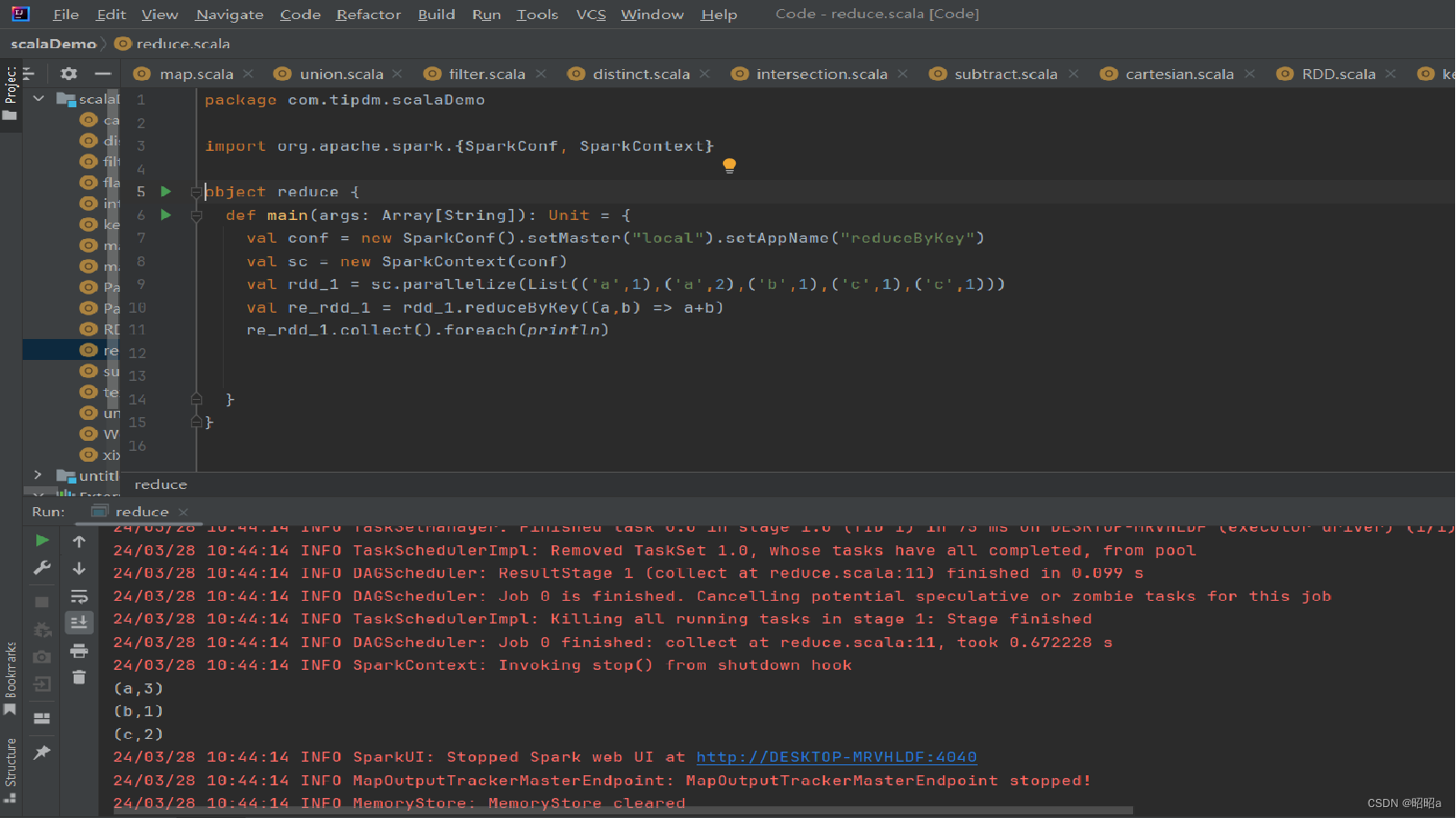
1.reduceByKey()方法
用于合并具有相同键的值,作用对象是键值对,并且只对每个键的值进行处理,当RDD中有多个键相同的键值对时,则会对每个键对应的值进行处理。
示例:
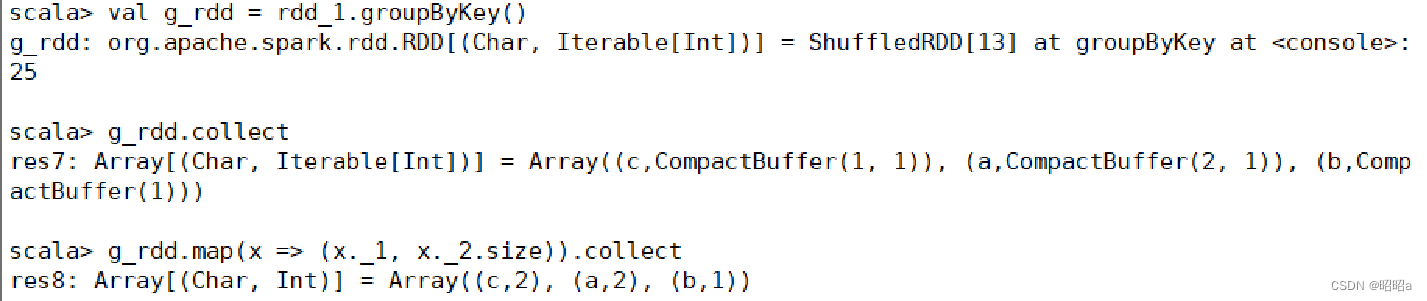
2.groupByKey()方法
用于对具有相同键的值进行分组,可以对同一组的数据进行计数、求和等操作。 对于一个由类型K的键和类型V的值组成的RDD,通过groupByKey()方法得到的RDD类型是[K,Iterable[V]]。
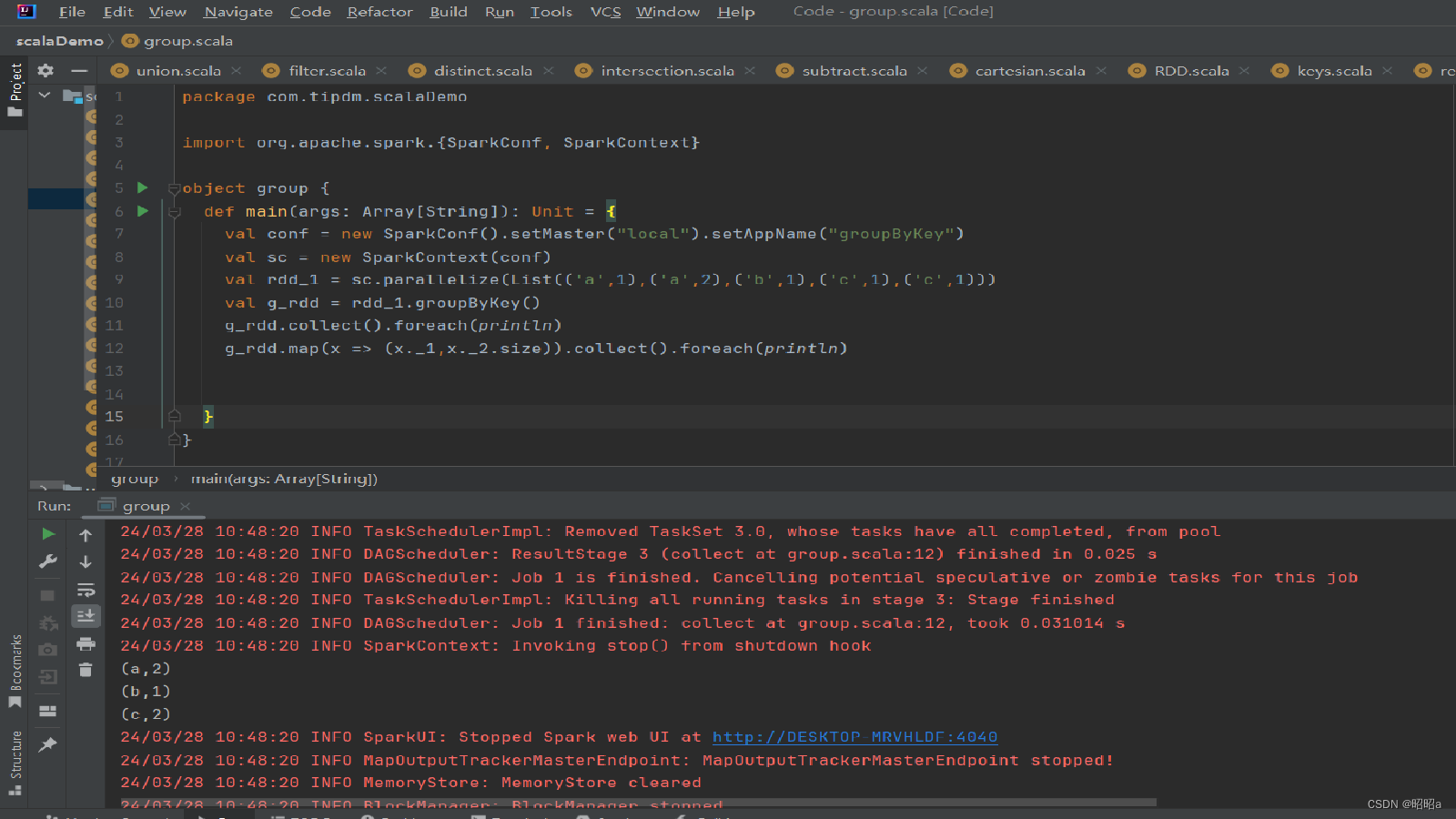
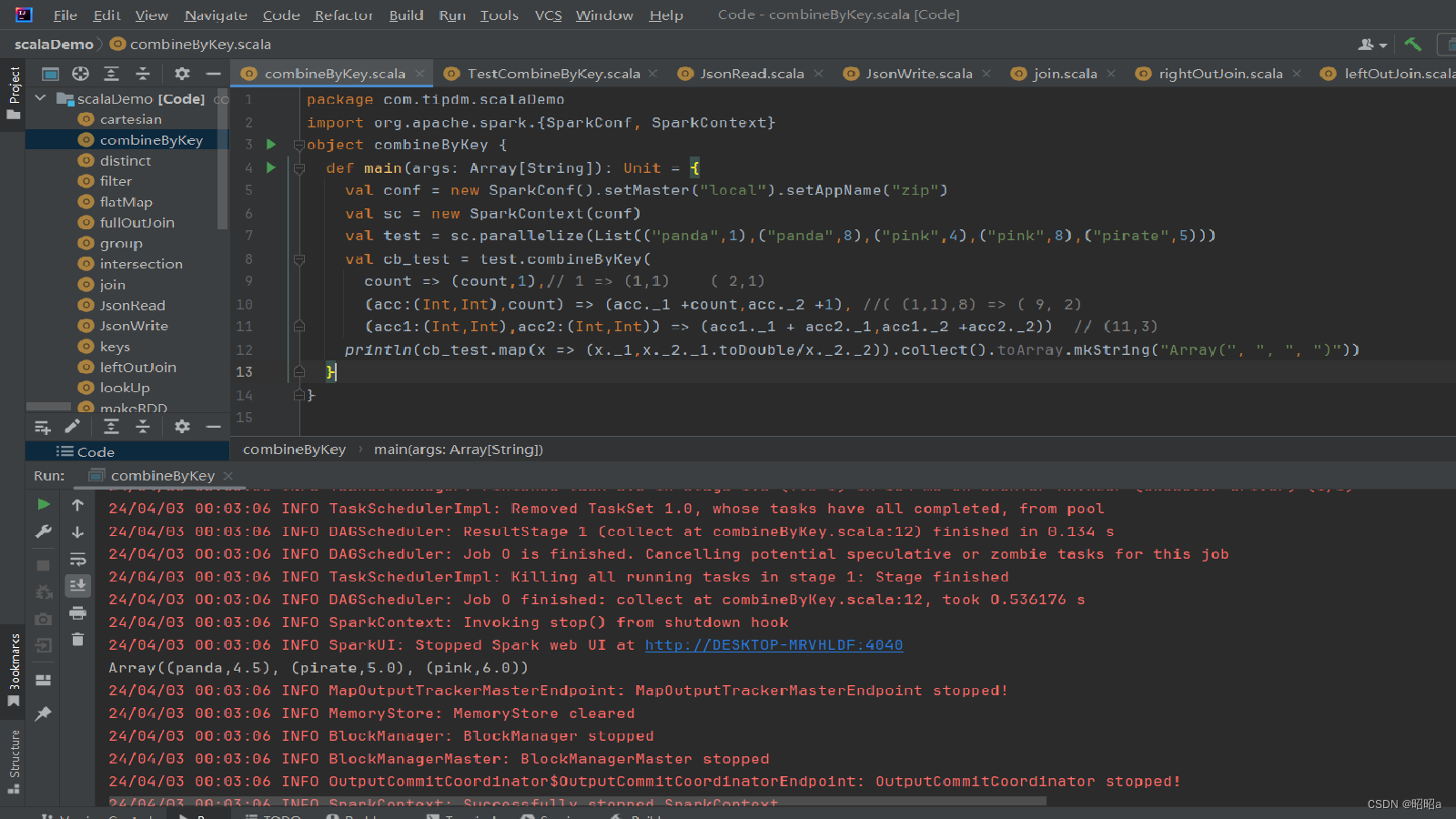
3.combineByKey()
方法
用于执行基于键的聚合操作的高级转换函数之一。它提供了一种灵活的方式来对每个键的值进行聚合,而不需要事先进行预先聚合或排序。
import org.apache.spark.{SparkConf, SparkContext}
object CombineByKeyExample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("CombineByKeyExample").setMaster("local[*]")
val sc = new SparkContext(conf)
// 创建一个包含键值对的RDD
val rdd = sc.parallelize(Seq(("apple", 3), ("banana", 5), ("apple", 7), ("banana", 2), ("orange", 1)))
// 使用combineByKey方法进行基于键的聚合操作
val aggregatedRDD = rdd.combineByKey(
createCombiner = (v: Int) => (v, 1), // 初始化值为(v, 1),其中v是值,1表示计数
mergeValue = (acc: (Int, Int), v: Int) => (acc._1 + v, acc._2 + 1), // 将新值合并到已存在的聚合值中,并更新计数
mergeCombiners = (acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2) // 合并不同分区的聚合值,并更新计数
)
// 打印结果
aggregatedRDD.collect().foreach(println)
sc.stop()
}
}
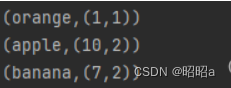
九、RDD连接方法
(1)join()方法
用于根据键对两个RDD进行内连接,将两个RDD中键相同的数据的值存放在一个元组中,最后只返回两个RDD中都存在的键的连接结果。
例如,在两个RDD中分别有键值对(K,V)和(K,W),通过join()方法连接会返回(K,(V,W))。
示例:创建两个RDD,含有相同键和不同的键,通过join()方法进行内连接。

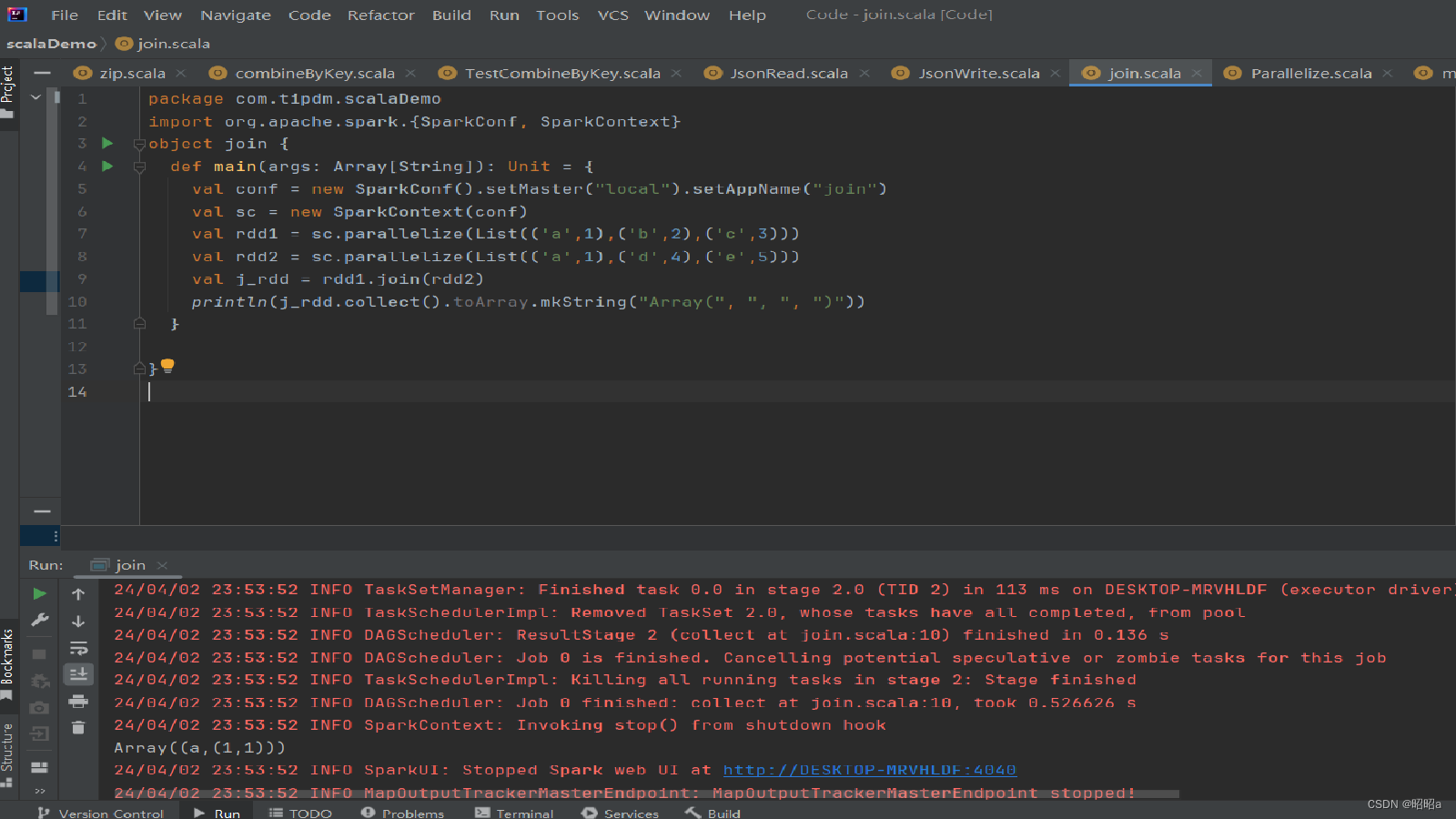
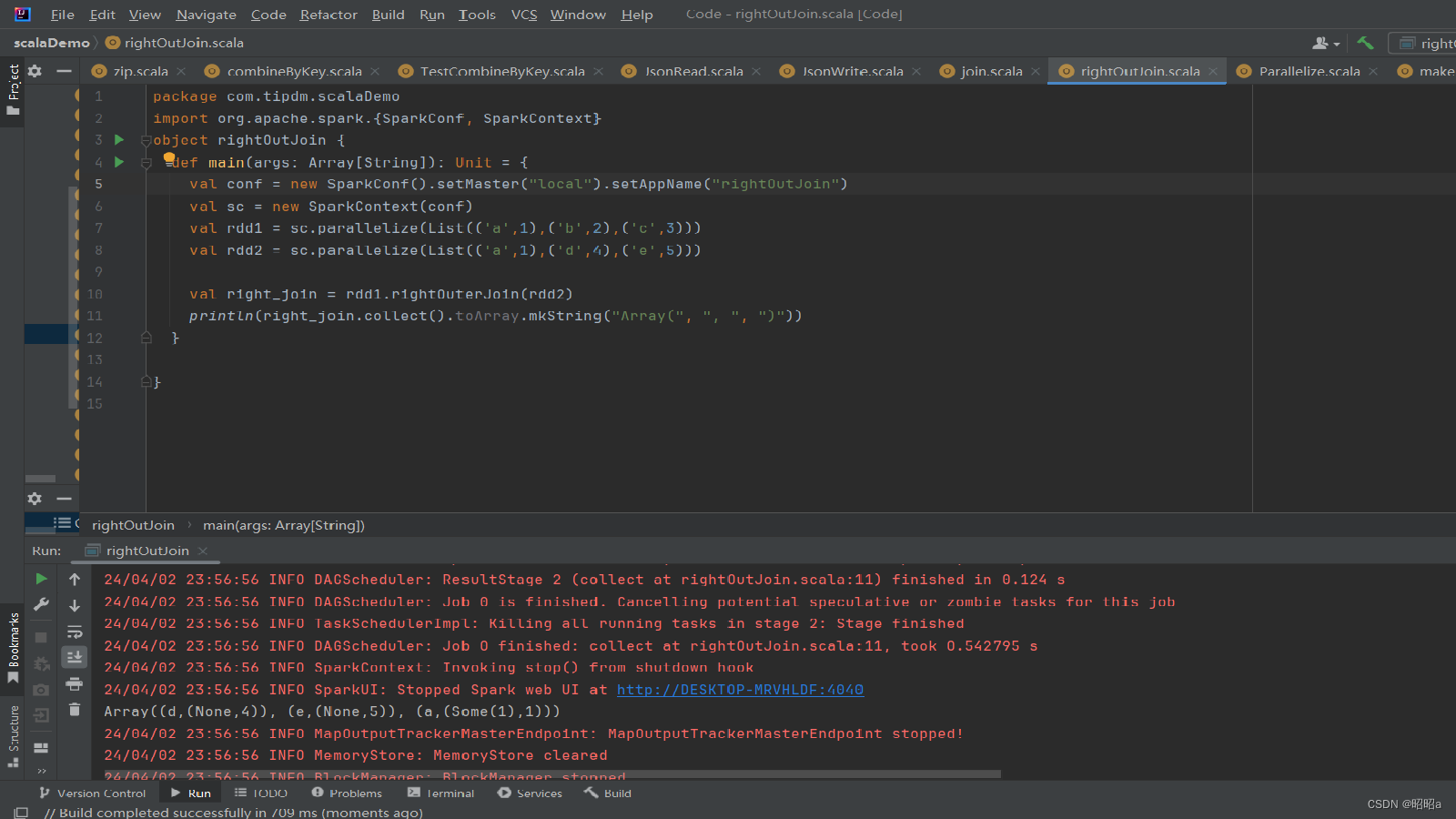
(2)rightOuterJoin()方法
用于根据键对两个RDD进行右外连接,连接结果是右边RDD的所有键的连接结果,不管这些键在左边RDD中是否存在。
在rightOuterJoin()方法中,如果在左边RDD中有对应的键,那么连接结果中值显示为Some类型值;如果没有,那么显示为None值。
示例:

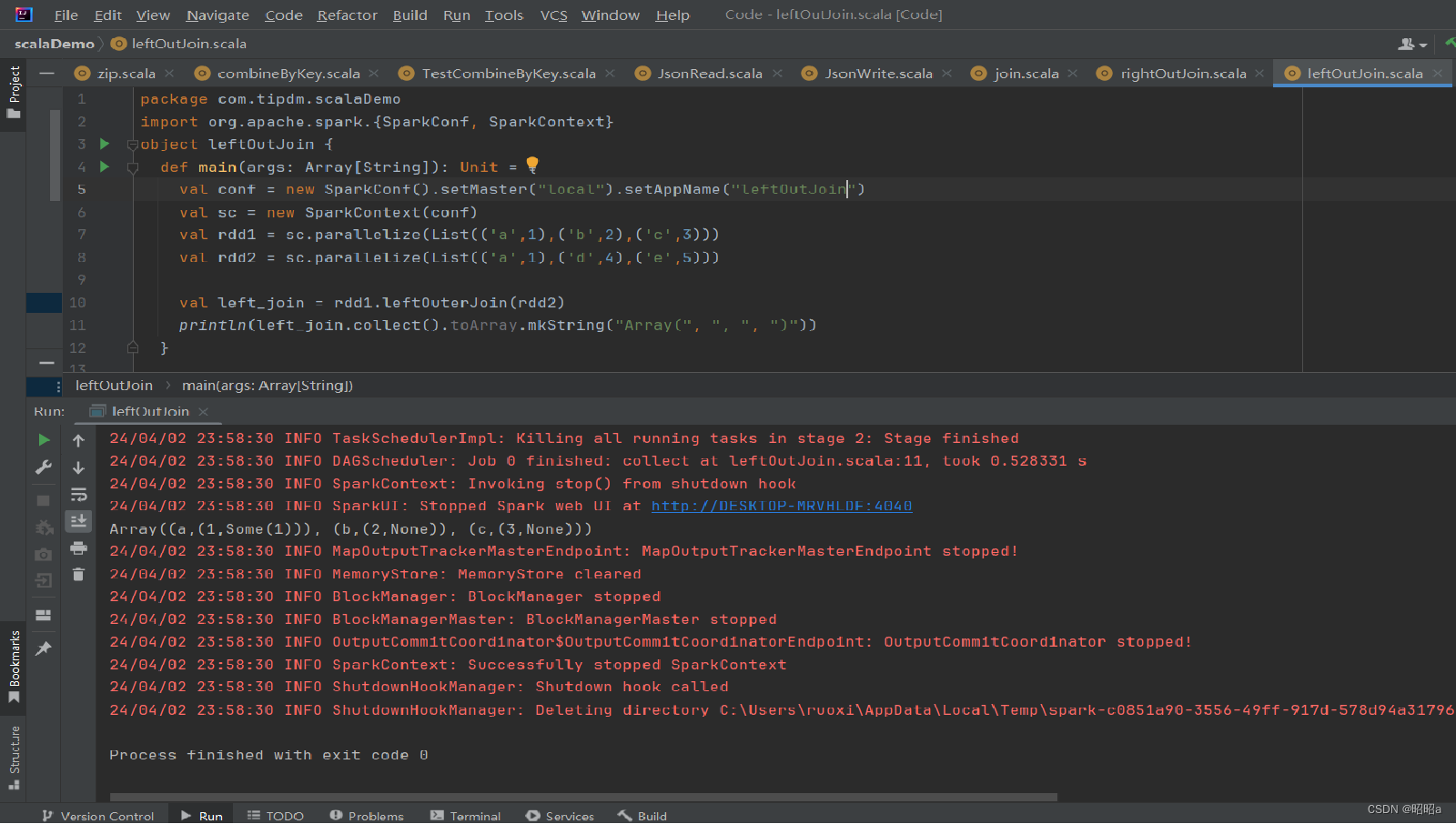
(3)leftOuterJoin()方法
用于根据键对两个RDD进行左外连接,与rightOuterJoin()方法相反,返回结果保留左边RDD的所有键。
示例:
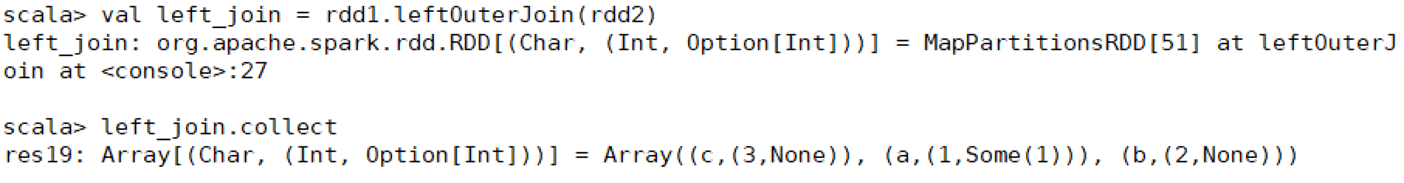
(4)fullOuterJoin()方法
用于对两个RDD进行全外连接,保留两个RDD中所有键的连接结果。
示例:

(5) zip()方法
**用于将两个RDD组合成键值对RDD,要求两个RDD的分区数量以及元素数量相同,否则会抛出异常。 **将两个RDD组合成Key/Value形式的RDD,这里要求两个RDD的partition数量以及元素数量都相同,否则会抛出异常。

(6)combineByKey()方法
合并相同键的值 ,是Spark中一个比较核心的高级方法,键值对的其他一些高级方法底层均是使用combineByKey()方法实现的,如groupByKey()方法、reduceByKey()方法等。
combineByKey()方法用于将键相同的数据聚合,并且允许返回类型与输入数据的类型不同的返回值。
combineByKey()方法的使用方式如下:
combineByKey(createCombiner,mergeValue,mergeCombiners,numPartitions=None)
- 由于合并操作会遍历分区中所有的元素,因此每个元素(这里指的是键值对)的键只有两种情况:以前没出现过或以前出现过。对于这两种情况,3个参数的执行情况描述如下。
- 如果以前没出现过,则执行的是createCombiner()方法,createCombiner()方法会在新遇到的键对应的累加器中赋予初始值,否则执行mergeValue()方法。
- 对于已经出现过的键,调用mergeValue()方法进行合并操作,对该键的累加器对应的当前值(C)与新值(V)进行合并。
- 由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()方法对各个分区的结果(全是C)进行合并。
(7)lookup()方法
查找指定键的值 ,用于键值对RDD,返回指定键的所有值。lookup()方法查找指定键的值

十、查看DataFrame数据
查看及获取数据的常用函数或方法
**将movies.dat电影数据上传至HDFS中,加载数据为RDD并将其转换为DataFrame. **
*1. printSchema:输出数据模式*
printSchema函数查看数据模式,打印出列的名称和类型

**2. show()**:查看数据

show()方法与show(true)方法一样,只显示前20条记录并且最多只显示20个字符
若是要显示所有字符,需要使用show(false)方法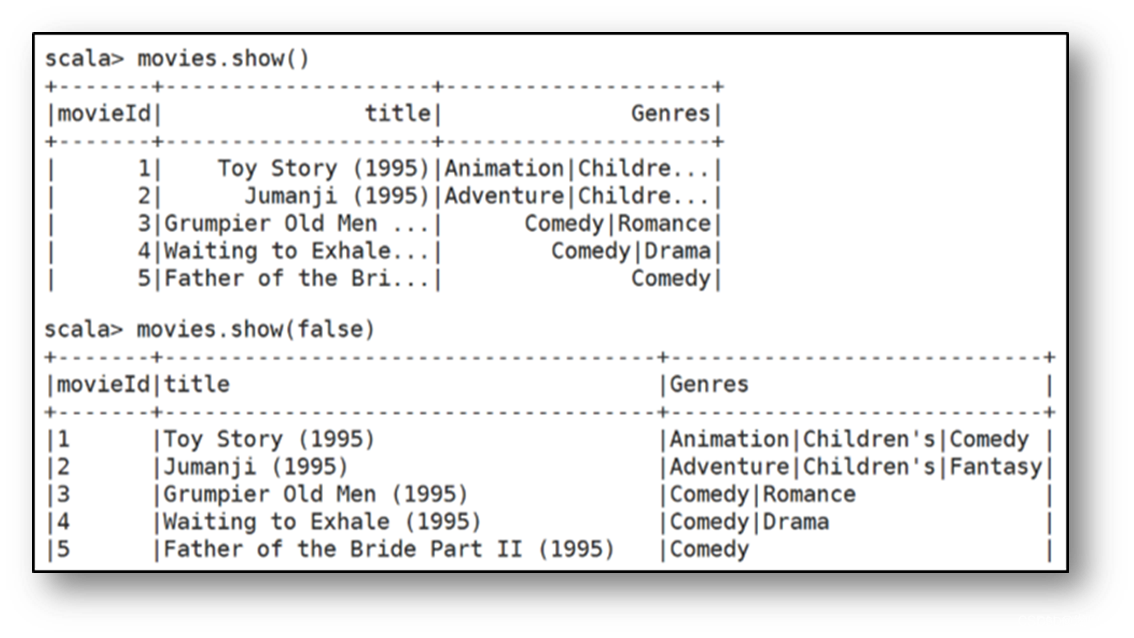
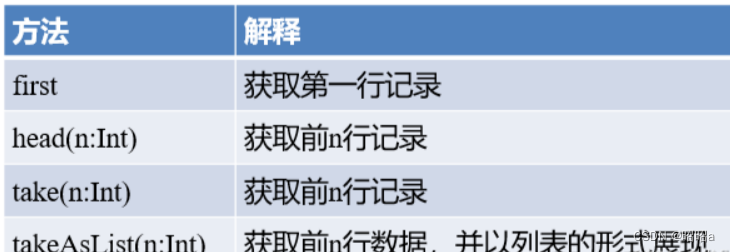
*3.*first()/head()/take()/takeAsList()**:获取若干条记录

*4.*collect()/collectAsList()**:获取所有数据
collect方法可以将DataFrame中的所有数据都获取到,并返回一个数组。
collectAsList方法可以获取所有数据,返回一个列表。
十一、将DataFrame注册成为临时表,然后通过SQL语句进行查询
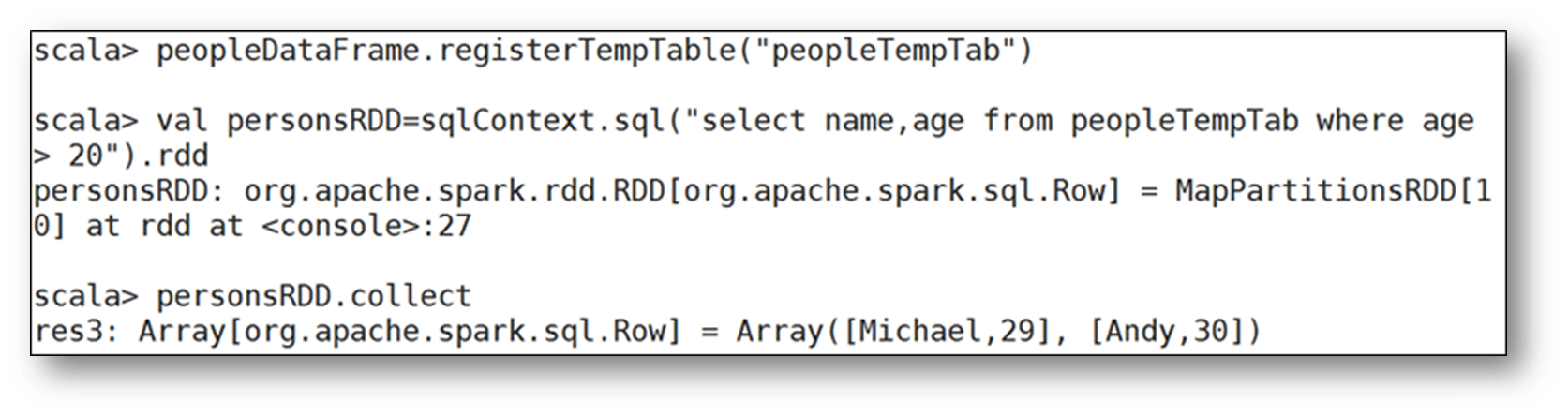
直接在DataFrame对象上进行查询,DataFrame提供了很多查询的方法
*1.*where()/filter()**方法
a.where()方法
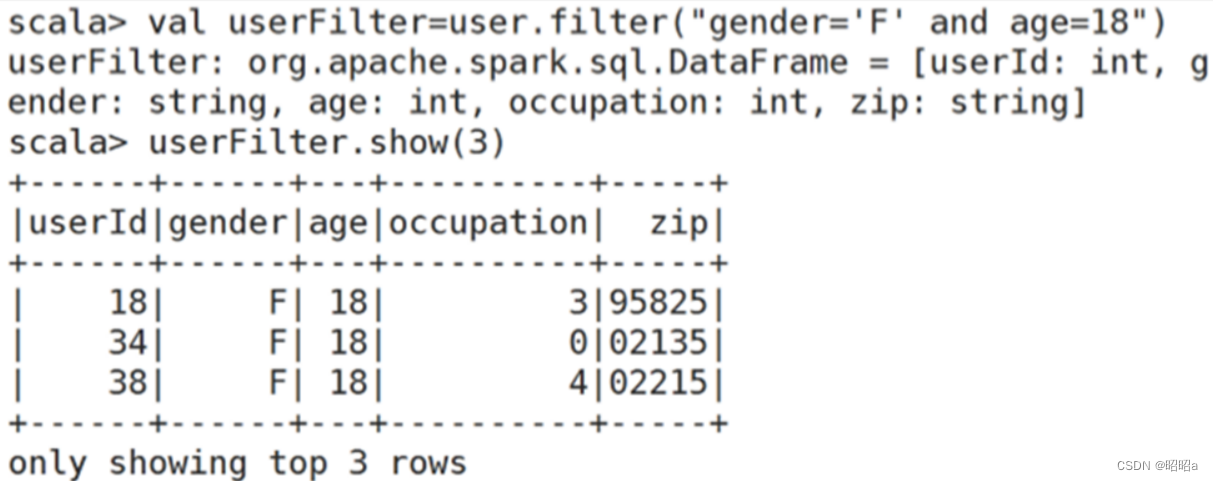
DataFrame可以使用where(conditionExpr: String)根据指定条件进行查询
参数中可以使用and或or
该方法的返回结果仍然为DataFrame类型

b.filter()方法
DataFrame还可使用filter筛选符合条件的数据
*2.*select()/selectExpr()/col()/apply()**方法
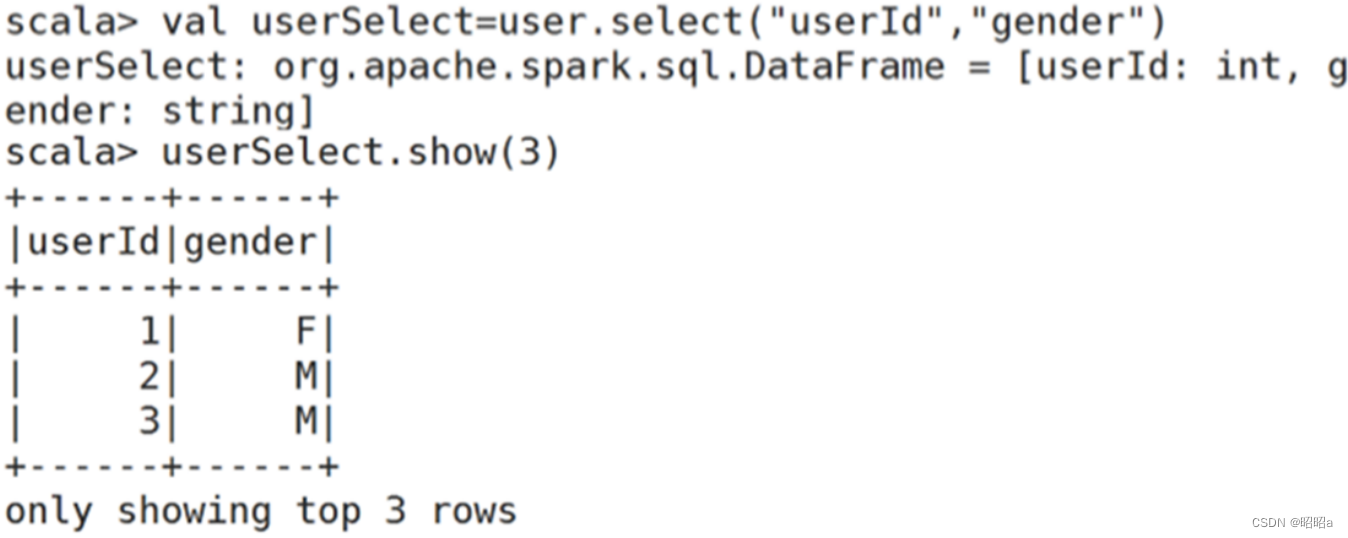
a.select()方法:获取指定字段值
select方法根据传入的string类型字段名,获取指定字段的值,以DataFrame类型返回
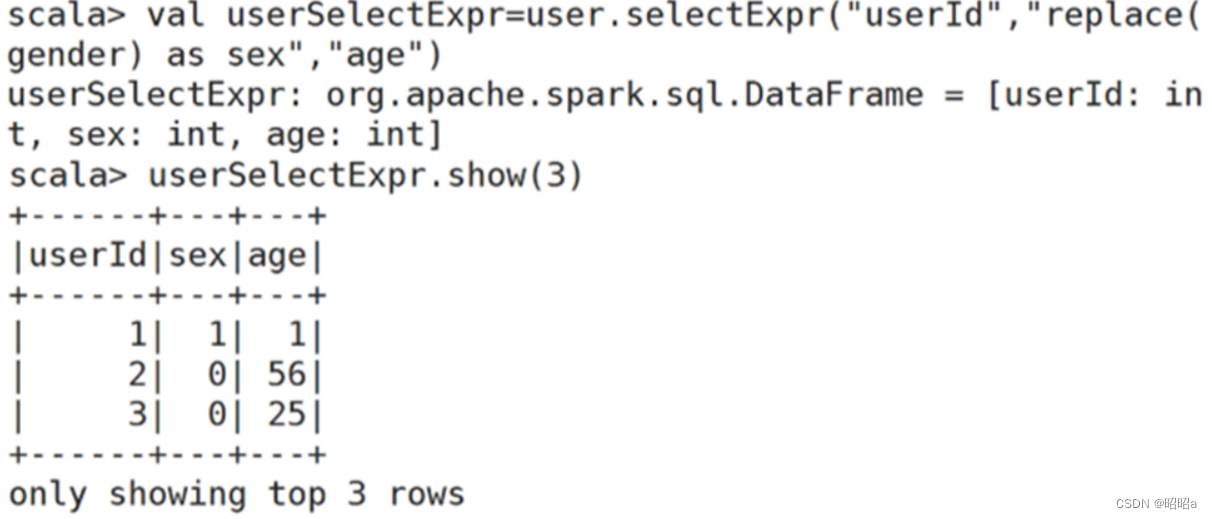
b.selectExpr()方法:对指定字段进行特殊处理
selectExpr:对指定字段进行特殊处理,可以对指定字段调用UDF函数或者指定别名。
selectExpr传入String类型的参数,返回DataFrame对象。
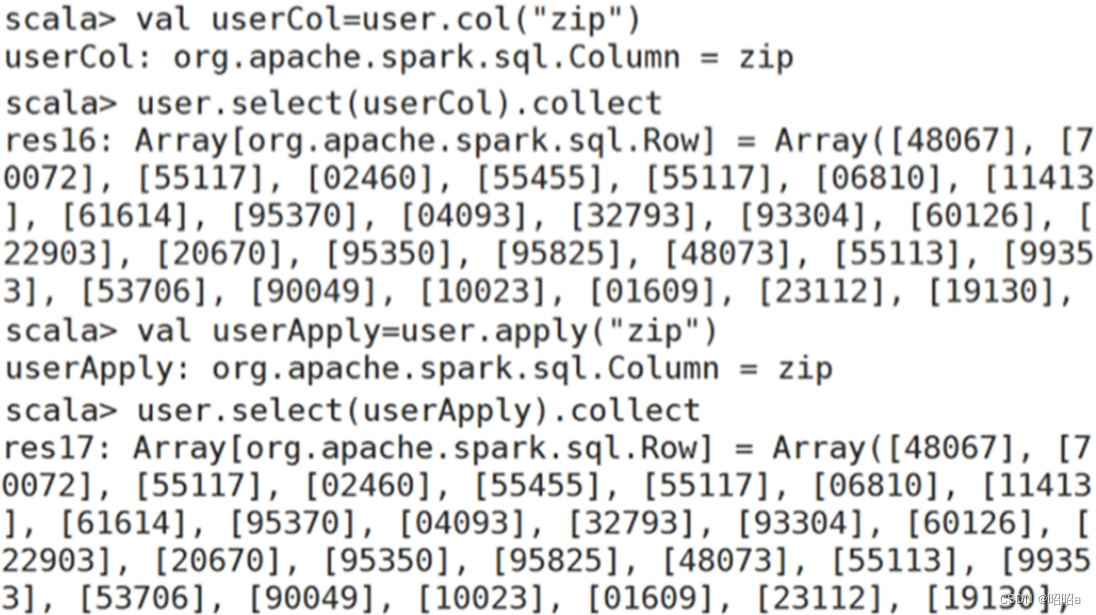
c.col()/apply()方法
col或者apply也可以获取DataFrame指定字段
col或者apply只能获取一个字段,并且返回对象为Column类型
3.orderBy()/sort()方法
orderBy()方法用于根据指定字段对数据进行排序,默认为升序排序。若要求降序排序, orderBy(方法的参数可以使用“desc("字段段名称")”或“$"字段名称".desc”,也可以在指定字段前面加“-”。使用orderBy()方法根据u serId 字段对 user对象进行降序排序,如代码下:
使用 orderBy()方法根据 userId字段对寸user 对象进行降序排序
val userOrderBy = user.orderBy(deesc("userId"))
val userOrderBy = user.orderBy($" userId".desc)
val userOrderBy =u iser.orderBy(-user("userId"))
版权归原作者 昭昭a 所有, 如有侵权,请联系我们删除。