
一、介绍
HPA的全称为(Horizontal Pod Autoscaling)它可以根据当前pod资源的使用率(如CPU、磁盘、内存等),进行副本数的动态的扩容与缩容,以便减轻各个pod的压力。
当pod负载达到一定的阈值后,会根据扩缩容的策略生成更多新的pod来分担压力,当pod的使用比较空闲时,在稳定空闲一段时间后,还会自动减少pod的副本数量。
二、 HPA 的工作原理
k8s中的某个Metrics Server(Heapster或自定义Metrics Server)持续采集所有Pod副本的指标数据。
HPA控制器通过Metrics Server的API(Heapster的API或聚合API)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标Pod副本数量。
当目标Pod副本数量与当前副本数量不同时,HPA控制器就访问Pod的副本控制器(Deployment 、RC或者ReplicaSet)发起scale操作,调整Pod的副本数量,完成扩缩容操作。
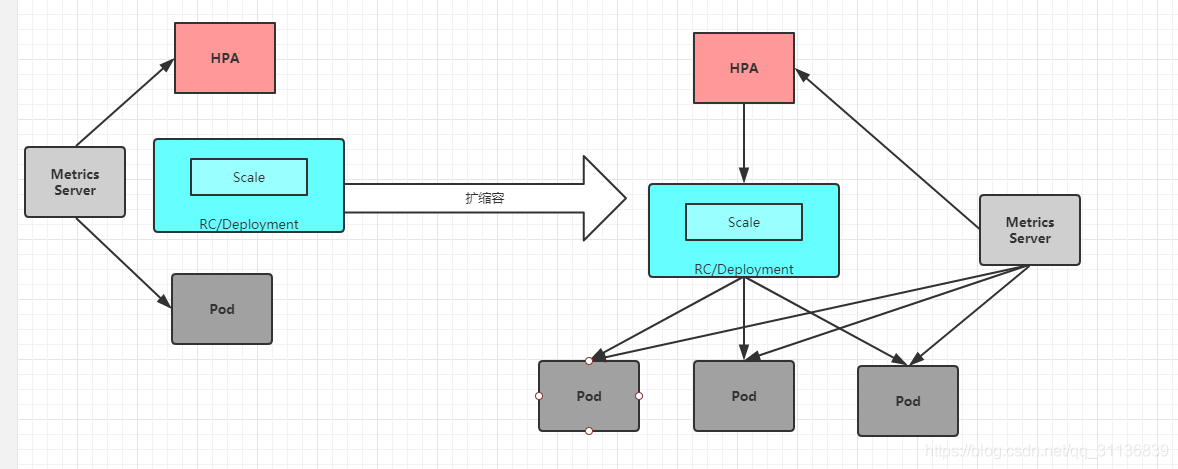
三、 指标的类型
Master的kube-controller-manager服务持续监测目标Pod的某种性能指标,以计算是否需要调整副本数量。目前k8s支持的指标类型如下。
◎ Pod资源使用率:Pod级别的性能指标,通常是一个比率值,例如CPU使用率。
◎ Pod自定义指标:Pod级别的性能指标,通常是一个数值,例如接收的请求数量。
◎ Object自定义指标或外部自定义指标:通常是一个数值,需要容器应用以某种方式提供,例如通过HTTP URL“/metrics”提供,或者使用外部服务提供的指标采集URL。
k8s从1.11版本开始,弃用基于Heapster组件完成Pod的CPU使用率采集的机制,全面转向基于Metrics Server完成数据采集。Metrics Server将采集到的Pod性能指标数据通过聚合API(Aggregated API)如metrics.k8s.io、custom.metrics.k8s.io和external.metrics.k8s.io提供给HPA控制器进行查询。关于聚合API和聚合器(API Aggregator)的概念我们后面详细讲解。
四、扩缩容策略
通过 ** 伸缩系数 ** 判断是否要进行扩容或缩容。
** HPA会根据获得的指标数值,应用相应的算法算出一个伸缩系数,此系数是指标的期望值与目前值的比值,如果大于1表示扩容,小于1表示缩容。 **
容忍度
--horizontal-pod-autoscaler-tolerance:容忍度
它允许一定范围内的使用量的不稳定,现在默认为0.1,这也是出于维护系统稳定性的考虑。
例如,设定HPA调度策略为cpu使用率高于50%触发扩容,那么只有当使用率大于55%或者小于45%才会触发伸缩活动,HPA会尽力把Pod的使用率控制在这个范围之间。
算法
具体的每次扩容或者缩容的多少Pod的算法为: 期望副本数 = ceil[当前副本数 * ( 当前指标 / 期望指标 )]
举个栗子
- 当前metric值是200m,期望值是100m,那么pod副本数将会翻一倍,因为 比率为 200.0 / 100.0 = 2.0;
- 如果当前值是
50m,我们会将pod副本数减半,因为50.0 / 100.0 == 0.5 - 如果比率接近1.0,如0.9或1.1(即容忍度是0.1),将不会进行缩放(取决于内置的全局参数容忍度,–horizontal-pod-autoscaler-tolerance,默认值为0.1)。
此外,存在几种Pod异常的情况,如下所述。
◎ Pod正在被删除(设置了删除时间戳):将不会计入目标Pod副本数量。
◎ Pod的当前指标值无法获得:本次探测不会将这个Pod纳入目标Pod副本数量,后续的探测会被重新纳入计算范围。
◎ 如果指标类型是CPU使用率,则对于正在启动但是还未达到Ready状态的Pod,也暂时不会纳入目标副本数量范围。可以通过kube-controller-manager服务的启动参数--horizontal-pod-autoscaler-initial-readiness-delay设置首次探测Pod是否Ready的延时时间,默认值为30s。另一个启动参数--horizontal-pod-autoscaler-cpuinitialization-period设置首次采集Pod的CPU使用率的延时时间。
注意:
- 每次最大扩容pod数量不会超过当前副本数量的2倍
- 如果某些pod的容器没有需要的的资源metrics,自动伸缩将不会根据这些metrics进行伸缩。
- 如果指定了targetAverageValue 或者 targetAverageUtilization,currentMetricValue是所有目标pod的metric取均值。在检查容忍度和确定最终值之前,会结合参考pod是否就绪、是否丢失metrics。
- 设置了删除时间戳的所有Pod(即处于关闭状态的Pod)和所有失败的Pod将被丢弃。
冷却和延迟机制
使用HPA管理一组副本时,有可能因为metrics动态变化而导致副本数频繁波动,这种现象叫做 “颠簸”。
想象一种场景:
当pod所需要的CPU负荷过大,从而在创建一个新pod的过程中,系统的CPU使用量可能会同样在有一个攀升的过程。所以,在每一次作出决策后的一段时间内,将不再进行扩展决策。对于扩容而言,这个时间段为3分钟,缩容为5分钟
- -- horizontal-pod-autoscaler-downscale- delay :这个参数用于告诉autoscaler做完缩容操作后需要等多久才能进行下一次缩容,默认值是5分钟。
- --horizontal-pod-autoscaler-upscale-delay: 这个参数用于告诉autoscaler做完扩容操作后需要等多久才能进行下一次扩容,默认值是3分钟。
注意:使用者需要知道调整这个参数可能造成的影响。设置得太长,HPA对负载变化的响应也会变长;太短又会导致自动伸缩“颠簸”。
Pod延迟探测机制
如果指标类型是CPU使用率,则对于正在启动但是还未达到Ready状态的Pod,也暂时不会纳入目标副本数量范围。
- 可以通过kube-controller-manager服务的启动参数--horizontal-pod-autoscaler-initial-readiness-delay设置首次探测Pod是否Ready的延时时间,默认值为30s。
- 另一个启动参数--horizontal-pod-autoscaler-cpuinitialization-period设置首次采集Pod的CPU使用率的延时时间。
五、HPA获取自定义指标(Custom Metrics)的底层实现(基于Prometheus)
Kubernetes是借助Agrregator APIServer扩展机制来实现Custom Metrics。Custom Metrics APIServer是一个提供查询Metrics指标的API服务(Prometheus的一个适配器),这个服务启动后,kubernetes会暴露一个叫custom.metrics.k8s.io的API,当请求这个URL时,请求通过Custom Metics APIServer去Prometheus里面去查询对应的指标,然后将查询结果按照特定格式返回。
参考:
带你玩转kubernetes-k8s
自动伸缩容算法
版权归原作者 小魏的博客 所有, 如有侵权,请联系我们删除。