
0x00 Selenium库的作用
模拟真实浏览器获取相关数据,比如有些网站检测token等值的时候,可以通过selenium库进行绕过
0x01 环境搭建
1、安装selenium库
pip3 install selenium
2、查看浏览器版本
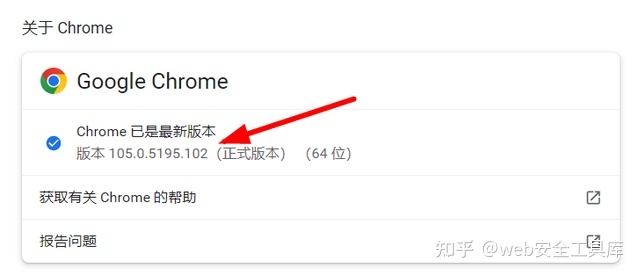
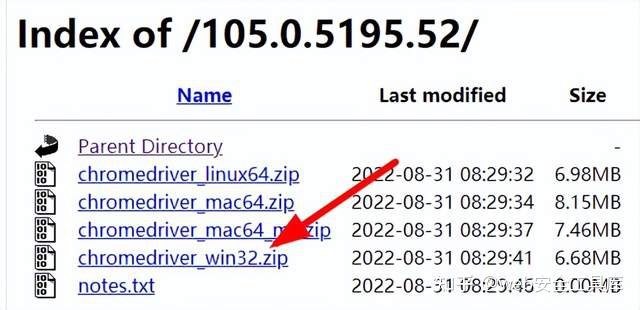
3、下载浏览器驱动,以谷歌为例,最后一位数字无所谓
http://chromedriver.storage.googleapis.com/index.html

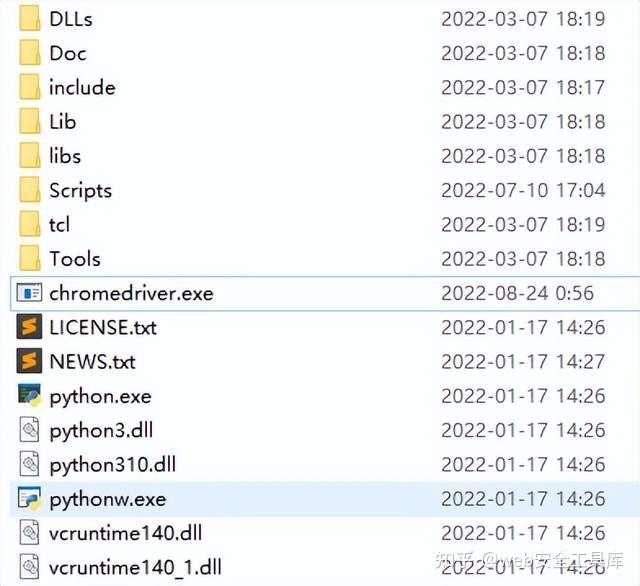
4、将解压的chromedriver.exe,复制到python的根目录
0x02 初始化浏览器对象
支持Chrome、Firefox、Edge、Safari等电脑端的浏览器
bs=webdriver.Chrome()
0x03 访问网站
bs.get('https://www.baidu.com')
0x04 获取编辑框的id,并输入我们想要搜索的数据
sr=bs.find_element('id','kw')
sr.send_keys('python')
sr.send_keys(Keys.ENTER)
0x05 等待出现结果,然后再获取数据
wt=WebDriverWait(bs,10)#创建一个等待的对象,等待10秒
wt.until(EC.presence_of_element_located((By.ID,'content_left')))#当节点id是content_left出现的时候获取数据
print(bs.page_source[:100]) #获取源码 前100个字节
0x06 关闭创建的浏览器
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
bs=webdriver.Chrome()
bs.get('https://www.baidu.com')
sr=bs.find_element('id','kw')
sr.send_keys('python')
sr.send_keys(Keys.ENTER)
wt=WebDriverWait(bs,10)
wt.until(EC.presence_of_element_located((By.ID,'content_left')))
print(bs.page_source[:100])
bs.close()
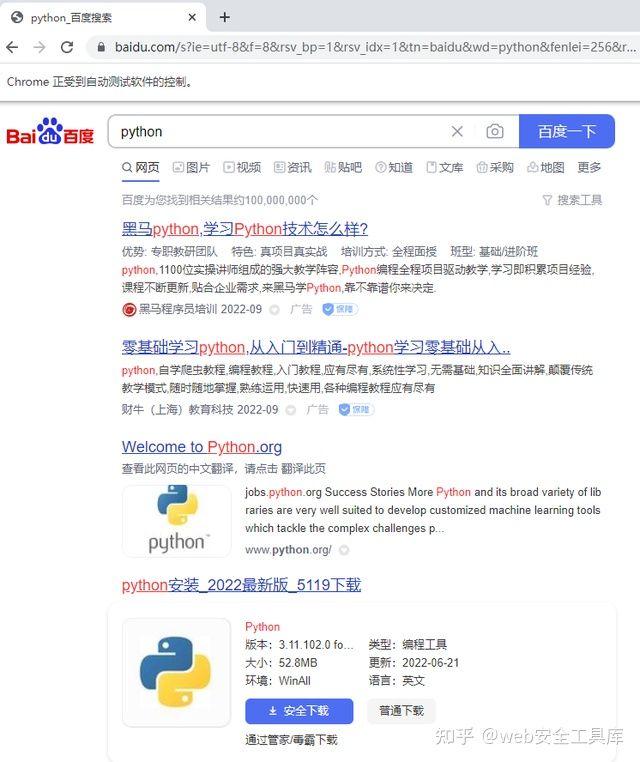
0x07 运行效果
自动启动浏览器,输入python,并获取搜索到的界面,然后自动关闭
0x08 声明
仅供安全研究与学习之用,若将工具做其他用途,由使用者承担全部法律及连带责任,作者不承担任何法律及连带责任。
欢迎关注公众号编程者吧

本文转载自: https://blog.csdn.net/weixin_41489908/article/details/126892780
版权归原作者 web安全工具库 所有, 如有侵权,请联系我们删除。
版权归原作者 web安全工具库 所有, 如有侵权,请联系我们删除。