

导读:本文主要介绍顺网科技在使用 Flink 计算引擎中遇到的一些挑战,基于 StreamPark 作为实时数据平台如何来解决这些问题,从而大规模支持公司的业务。
- 公司业务介绍
- 遇到的挑战
- 为什么用 StreamPark
- 落地实践
- 带来的收益
- 未来规划
公司业务介绍
杭州顺网科技股份有限公司成立于 2005 年,秉承科技连接快乐的企业使命,是国内具有影响力的泛娱乐技术服务平台之一。多年来公司始终以产品和技术为驱动,致力于以数字化平台服务为人们创造沉浸式的全场景娱乐体验。
自顺网科技成立以来,随着业务快速发展,顺网科技服务了 8 万家线下实体店,拥有超过 5000 万互联网用户,年触达超 1.4 亿网民,每 10 家公共上网服务场所有 7 家使用顺网科技产品。
在拥有庞大的用户群体的情况下,顺网科技为了给用户提供更加优质的产品体验,实现企业的数字化转型,从 2015 年开始大力发展大数据, Flink 在顺网科技的实时计算中一直扮演着重要的角色。在顺网科技,实时计算大概分为 4 个应用场景:
- 用户画像实时更新:包括网吧画像和网民画像。
- 实时风控:包括活动防刷、异地登录监测等。
- 数据同步:包括 Kafka 数据同步到 Hive / Iceberg / ClickHouse 等。
- 实时数据分析:包括游戏、语音、广告、直播等业务实时大屏。
到目前为止,顺网科技每日需要处理 TB 级别的数据,总共拥有 700+ 个实时任务,其中 FlinkSQL 任务占比为 95% 以上。随着公司业务快速发展和数据时效性要求变高,预计在今年年底 Flink 任务会达到 900+。
遇到的挑战
Flink 作为当下实时计算领域中最流行的技术框架之一,拥有高吞吐、低延迟、有状态计算等强大的特性。在探索中我们发现 Flink 虽然拥有强大的计算能力,但是对于作业开发管理和运维问题,社区并没有提供有效的解决方案。我们对 Flink 作业开发管理上遇到的一些痛点大概总结为 4 个方面,如下:
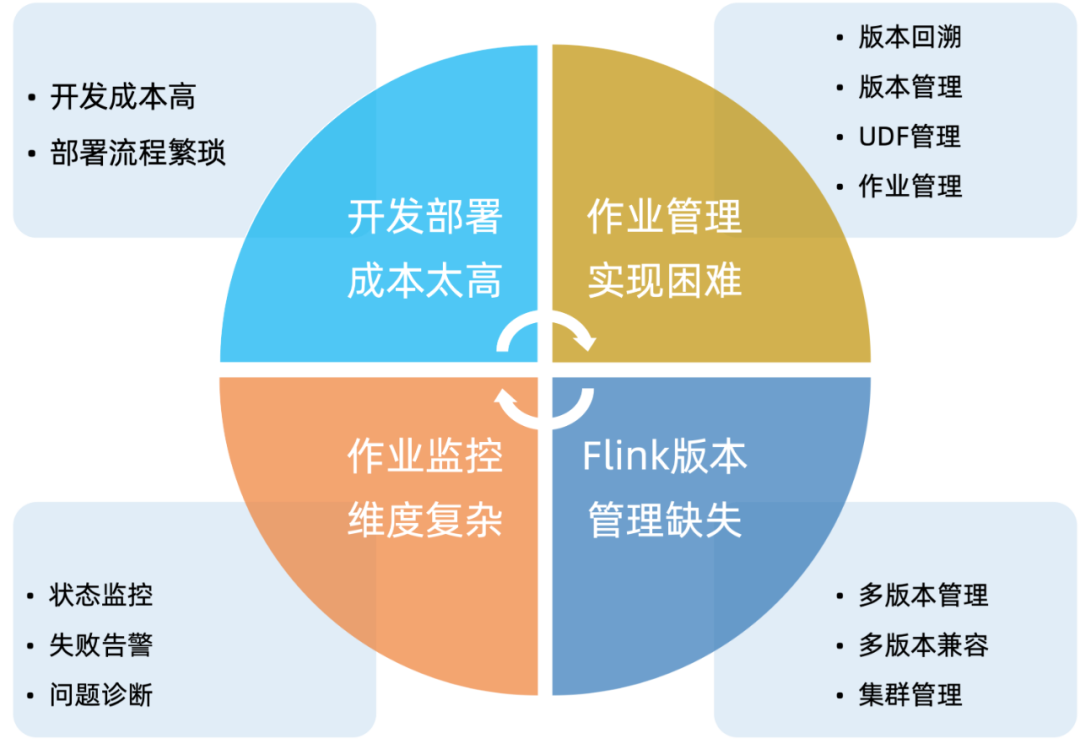
在面对 Flink 作业管理和运维上的的一系列痛点后,我们一直在寻找合适的解决方案来降低开发同学使用 Flink 门槛,提高工作效率。
在没有遇到 StreamPark 之前,我们调研了部分公司的 Flink 管理解决方案,发现都是通过自研实时作业平台的方式来开发和管理 Flink 作业。于是,我们也决定自研一套实时计算管理平台,来满足了开发同学对于 Flink 作业管理和运维的基础需求,我们这套平台叫 Streaming-Launcher,大体功能如下:
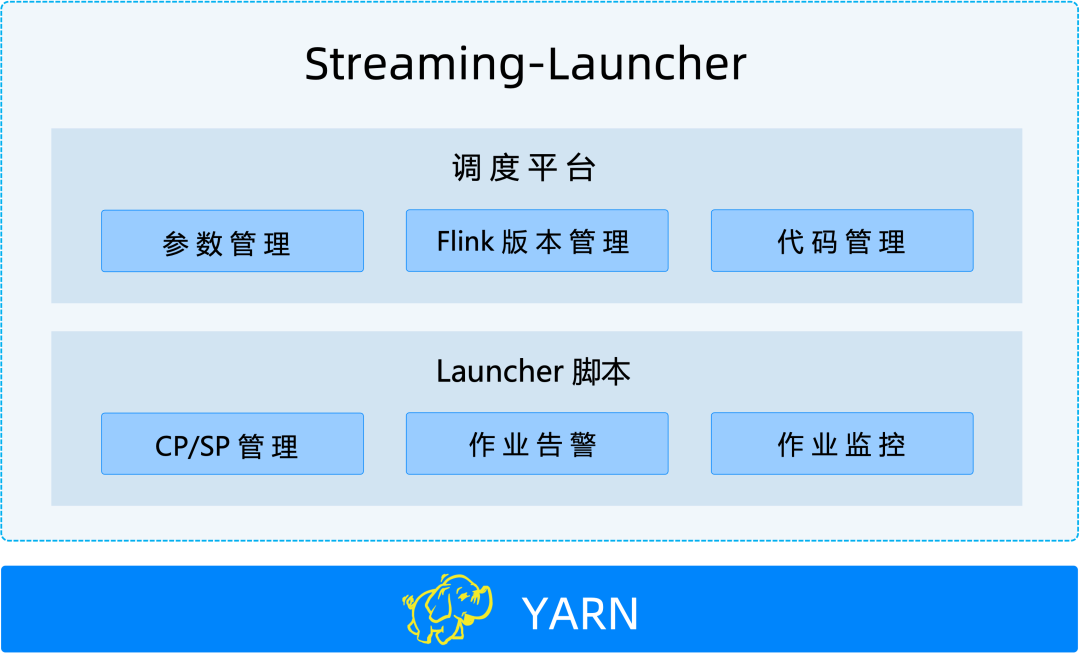
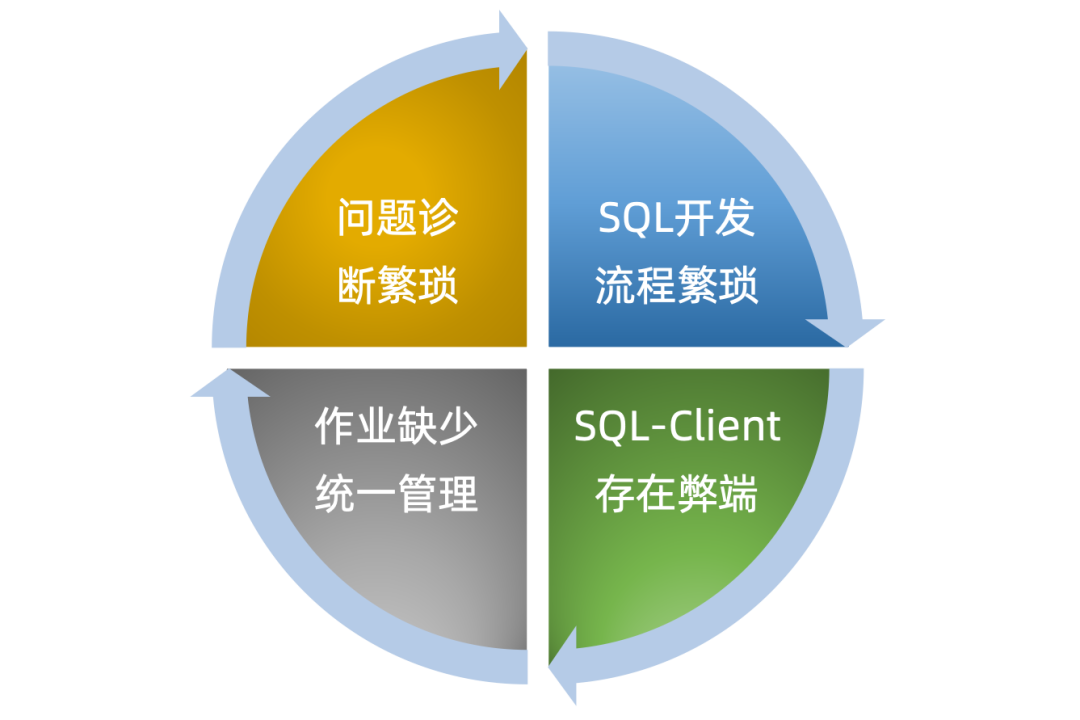
但是后续开发同学在使用过程中,发现 Streaming-Launcher 存在比较多的缺陷:Flink 开发成本依然过高、工作效率低下、问题排查困难。我们总结了 Streaming-Launcher 存在的缺陷,大致如下:
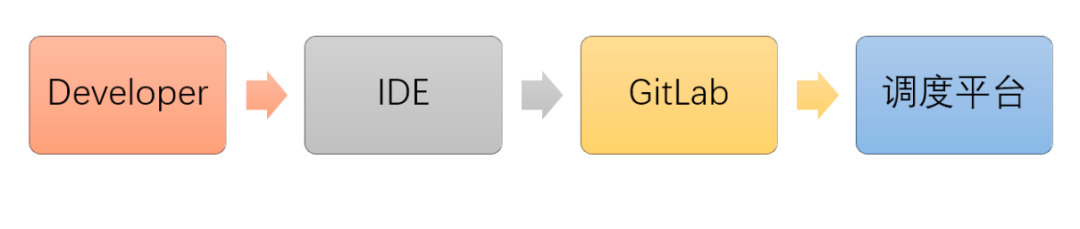
1. SQL开发流程繁琐
作业务开发需要多个工具完成一个 SQL 作业开发,提高了开发同学的使用门槛。
2. SQL-Client 存在弊端
Flink 提供的 SQL-Client 目前对作业运行模式支持上,存在一定的弊端。

3. 作业缺少统一管理
Streaming-Launcher 中,没有提供统一的作业管理界面。开发同学无法直观的看到作业运行情况,只能通过告警信息来判断作业运行情况,这对开发同学来说非常不友好。如果因为 Yarn 集群稳定性问题或者网络波动等不确定因素,一下子失败大批量任务,在开发同学手动恢复作业的过程中,很容易漏恢复某个任务而造成生产事故。
4. 问题诊断流程繁琐
一个作业查看日志需要通过多个步骤,一定程度上降低了开发同学工作效率。

为什么用 StreamPark
面对自研平台 Streaming-Launcher 存在的缺陷,我们一直在思考如何将 Flink 的使用门槛降到更低,进一步提高工作效率。考虑到人员投入成本和时间成本,我们决定向开源社区求助寻找合适的开源项目来对我们的 Flink 任务进行管理和运维。
一. StreamPark 解决 Flink 问题的利器
很幸运在 2022 年 6 月初,我们在 GitHub 机缘巧合之间认识到了 StreamPark,我们满怀希望地对 StreamPark 进行了初步的探索。发现 StreamPark 具备的能力大概分为三大块:用户权限管理、作业运维管理和开发脚手架。
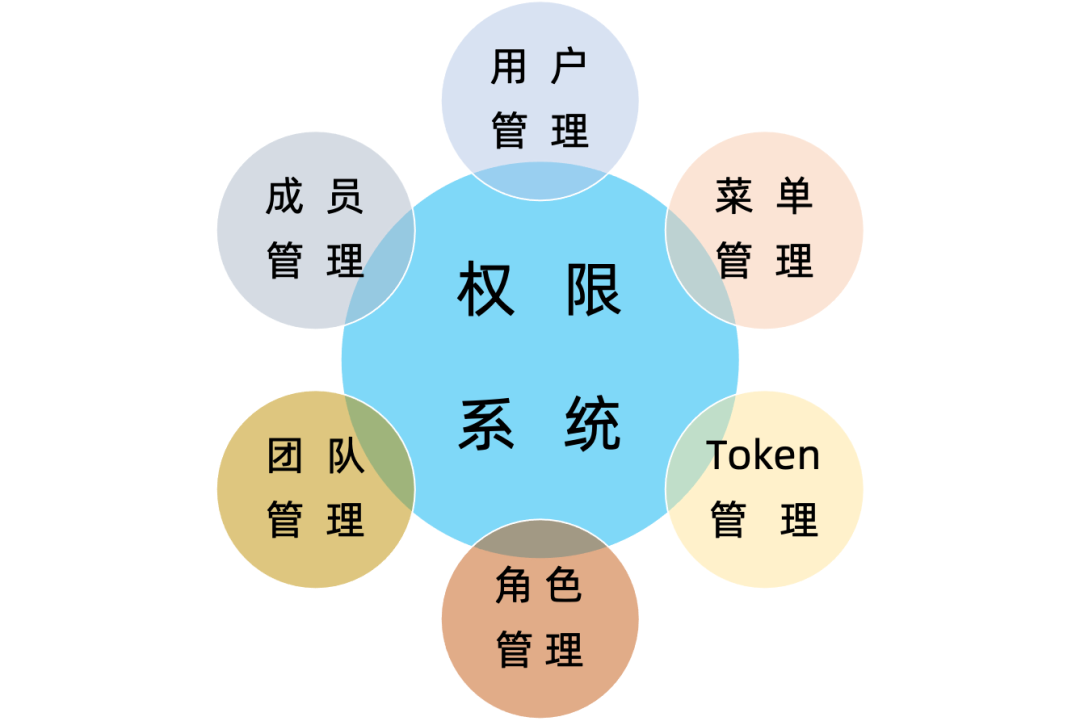
1. 用户权限管理
在 StreamPark 平台中为了避免用户权限过大,发生一些不必要的误操作,影响作业运行稳定性和环境配置的准确性,提供了相应的一些用户权限管理功能,这对企业级用户来说,非常有必要。
2. 作业运维管理
我们在对 StreamPark 做调研的时候,最关注的是 StreamPark 对于作业的管理的能力。StreamPark 是否有能力管理作业一个完整的生命周期:作业开发、作业部署、作业管理、问题诊断等。很幸运,StreamPark 在这一方面非常优秀,对于开发同学来说只需要关注业务本身,不再需要特别关心 Flink 作业管理和运维上遇到的一系列痛点。在 StreamPark 作业开发管理管理中,大致分为三个模块:作业管理基础功能,Jar 作业管理,FlinkSQL 作业管理。如下:
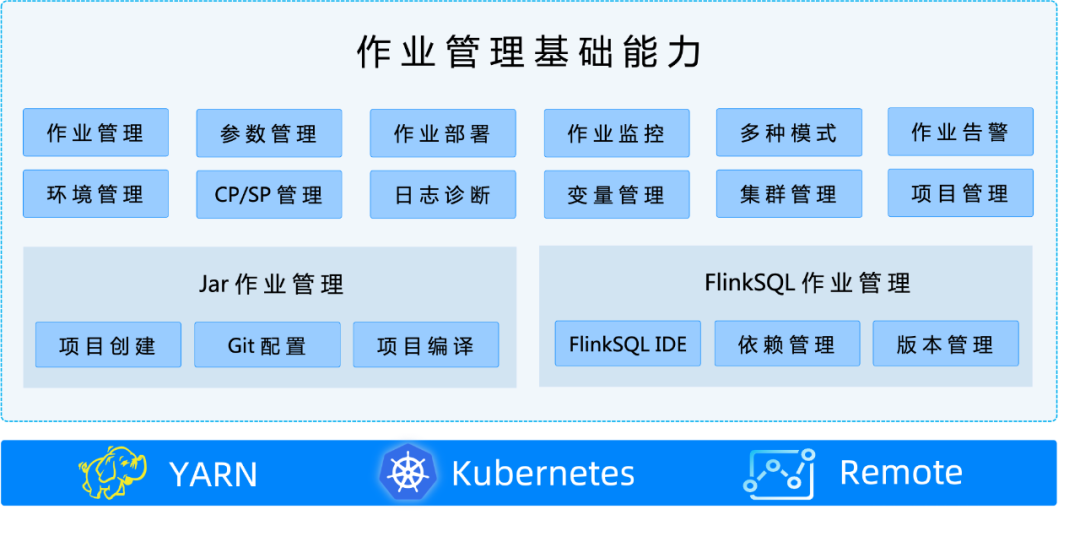
3. 开发脚手架
通过进一步的研究发现,StreamPark 不仅仅是一个平台,还包含 Flink 作业开发脚手架, 在 StreamPark 中,针对编写代码的 Flink 作业,提供一种更好的解决方案,将程序配置标准化,提供了更为简单的编程模型,同时还提供了一些列 Connectors,降低了 DataStream 开发的门槛。
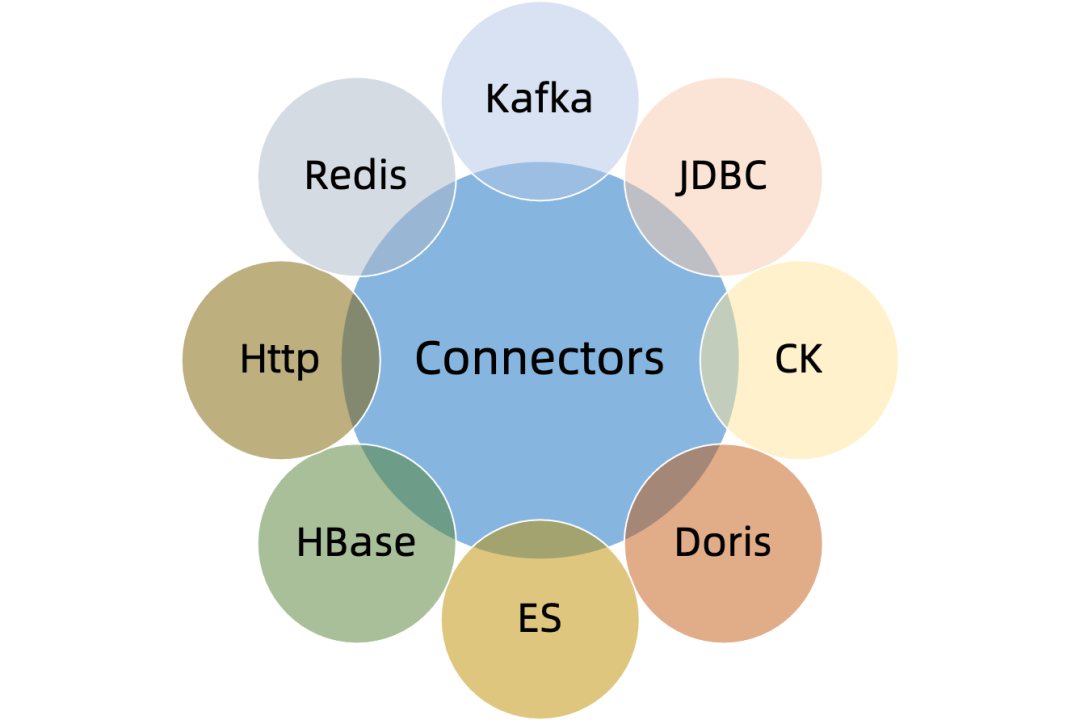
二. StreamPark 解决自研平台的问题
上面我们简单介绍了 StreamPark 的核心能力。在顺网科技的技术选型过程中,我们发现 StreamPark 所具备强大的功能不仅包含了现有 Streaming-Launcher 的基础功能,还提供了更完整的对应方案解决了 Streaming-Launcher 的诸多不足。在这部分,着重介绍下 StreamPark 针对我们自研平台 Streaming-Launcher 的不足所提供的解决方案。
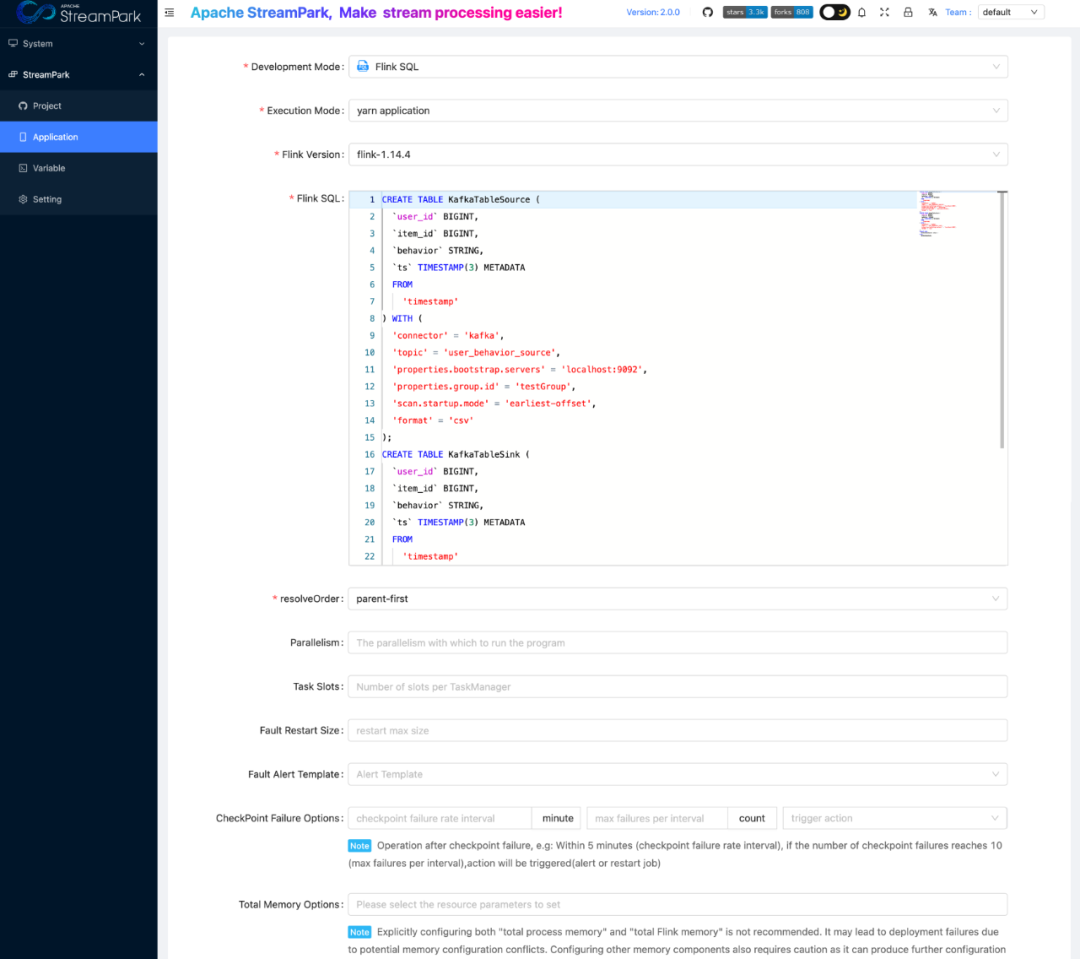
01. Flink 作业一站式的开发能力
StreamPark 为了降低 Flink 作业开发门槛,提高开发同学工作效率,提供了 FlinkSQL IDE、参数管理、任务管理、代码管理、一键编译、一键作业上下线等使用的功能。在调研中,我们发现 StreamPark 集成的这些功能可以进一步提升开发同学的工作效率。在某种程度上来说,开发同学不需要去关心 Flink 作业管理和运维的难题,只要专注于业务的开发。同时,这些功能也解决了 Streaming-Launcher 中 SQL 开发流程繁琐的痛点。
02. 支持多种部署模式
在 Streaming-Launcher 中,由于只支持 Yarn Session 模式,对于开发同学来说,其实非常不灵活。StreamPark 对于这一方面也提供了完善的解决方案。StreamPark 完整的支持了Flink 的所有部署模式:Remote、Yarn Per-Job、Yarn Application、Yarn Session、K8s Session、K8s Application****,可以让开发同学针对不同的业务场景自由选择合适的运行模式。
03. 作业统一管理中心
对于开发同学来说,作业运行状态是他们最关心的内容之一。在 Streaming-Launcher 中由于缺乏作业统一管理界面,开发同学只能通过告警信息和 Yarn 中Application 的状态信息来判断任务状态,这对开发同学来说非常不友好。StreamPark 针对这一点,提供了作业统一管理界面,可以一目了然查看到每个任务的运行情况。
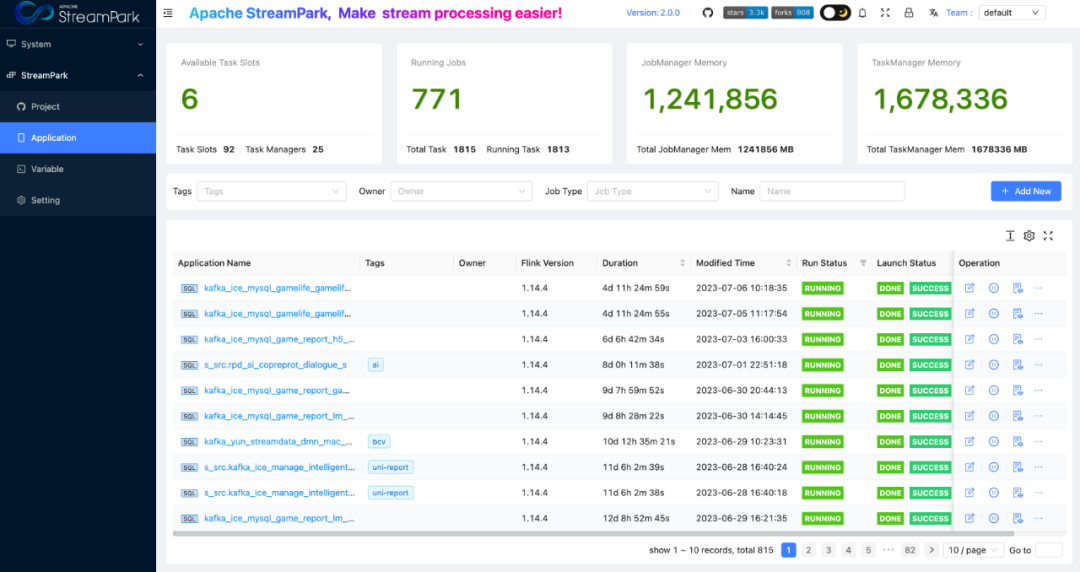
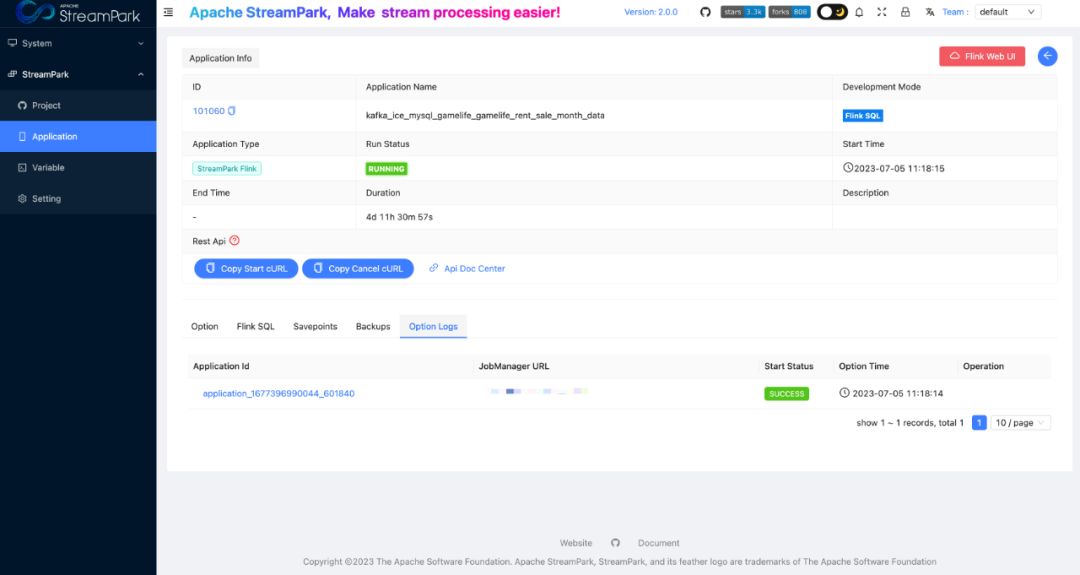
在 Streaming-Launcher 中,开发同学在作业问题诊断的时候,需要通过多个步骤才能定位作业运行日志。StreamPark 提供了一键跳转功能,能快速定位到作业运行日志。
落 地 实 践
在 StreamPark 引入顺网科技时,由于公司业务的特点和开发同学的一些定制化需求,我们对 StreamPark 的功能做了一些增加和优化,同时也总结了一些在使用过程中遇到的问题和对应的解决方案。
01. 结合 Flink-SQL-Gateway 的能力
在顺网科技,我们基于 Flink-SQL-Gateway 自研了 ODPS 平台来方便业务开发同学管理 Flink 表的元数据。业务开发同学在 ODPS 上对 Flink 表进行 DDL 操作,然后在 StreamPark 上对创建的 Flink 表进行分析查询操作。在整个业务开发流程上,我们对 Flink 表的创建和分析实现了解耦,让开发流程显得比较清晰。
开发同学如果想在 ODPS 上查询实时数据,我们需要提供一个 Flink SQL 的运行环境。我们使用 StreamPark 运行了一个 Yarn Session 的 Flink 环境提供给 ODPS 做实时查询。
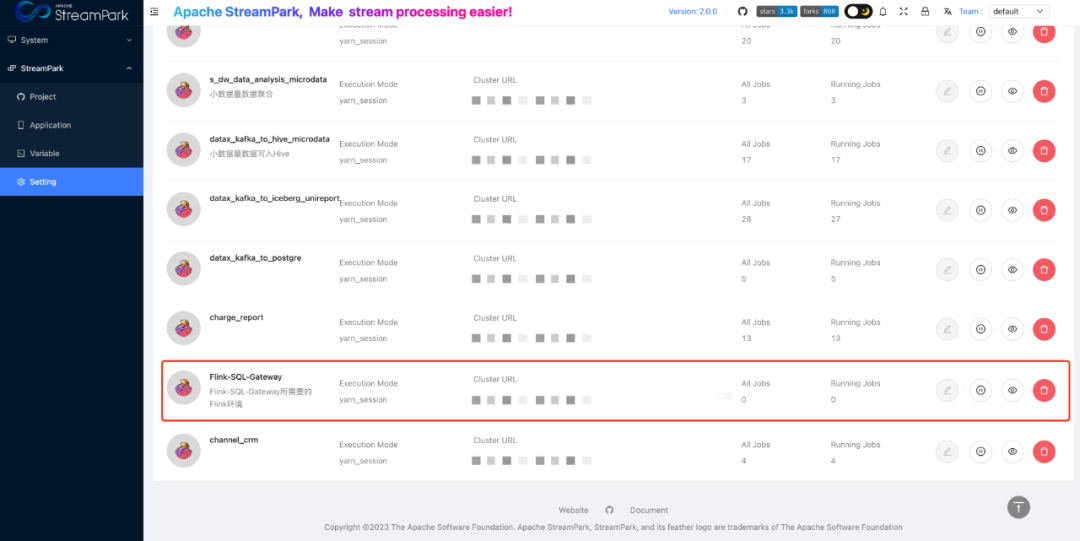
目前 StreamPark 社区为了进一步降低实时作业开发门槛,正在对接 Flink-SQL-Gateway。
[Feature][WIP] Integrate StreamPark with Sql Gateway · Issue #2274 · apache/incubator-streampark · GitHub
02. 增强 Flink 集群管理能力
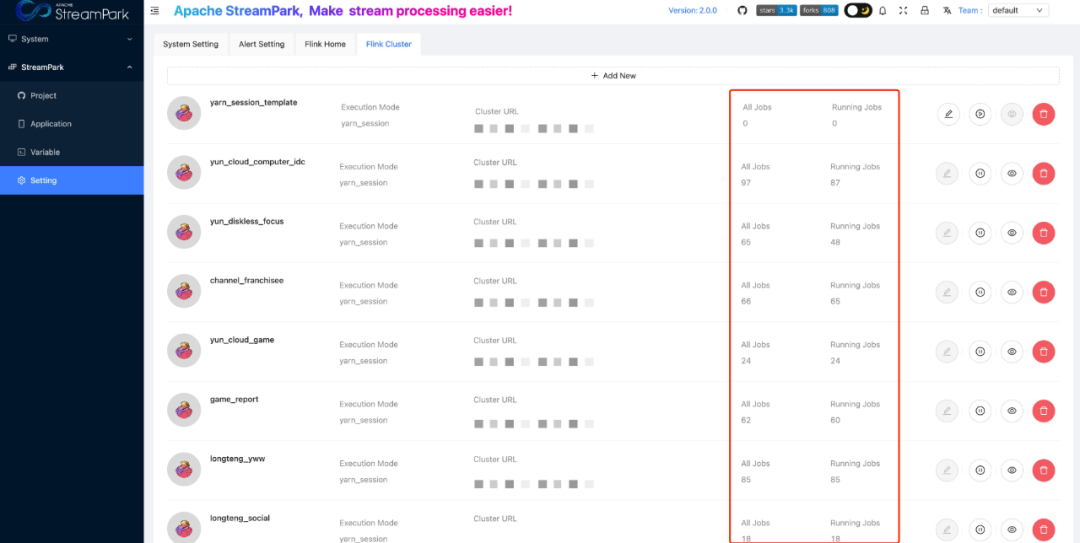
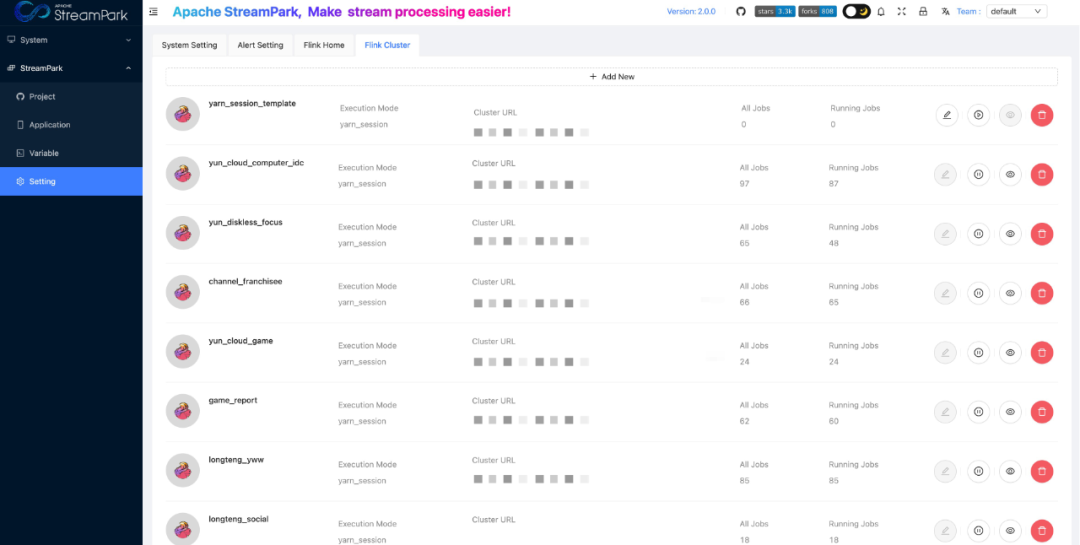
在顺网科技,存在大量从 Kafka 数据同步到 Iceberg / PG / Clickhouse / Hive 的作业。这些作业需要的 Yarn 对于资源要求和时效性要求不高,但是如果全部使用 Yarn Application 和 per-job 模式,每个任务都会启动 JobManager,那么会造成 Yarn 资源的浪费。对此,我们决定使用 Yarn Session 模式运行这些大量的数据同步作业。
在实践中我们发现业务开发同学很难直观的知道在每个 Yarn Session 中运行了多少个作业,其中包括作业总数和正在运行中的作业数量。基于这个原因,我们为了方便开发同学可以直观地观察到 Yarn Session 中的作业数量,在 Flink Cluster 界面增加了 All Jobs 和 Running Jobs 来表示在一个 Yarn Session 中总的作业数和正在运行的作业数。
03. 增强告警能力
因为每个公司的短信告警平台实现都各不相同,所以 StreamPark 社区并没有抽象出统一的短信告警功能。在此,我们通过 Webhook 的方式,自己实现了短信告警功能。

04. 增加阻塞队列解决限流问题
在生产实践中,我们发现在大批量任务同时失败的时候,比如 Yarn Session 集群挂了,飞书 / 微信等平台在多线程同时调用告警接口时会存在限流的问题,那么大量的告警信息因为飞书 / 微信等平台限流问题,StreamPark 只会发送一部分的告警信息,这样非常容易误导开发同学排查问题。在顺网科技,我们增加了一个阻塞队列和一个告警线程,来解决限流问题。
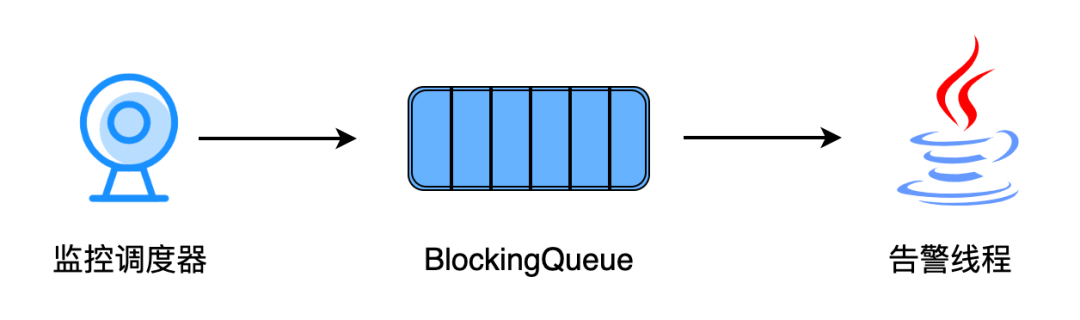
当作业监控调度器检测到作业异常时,会产生一条作业异常的消息发送的阻塞队列中,在告警线程中会一直消费阻塞队列中的消息,在得到作业异常消息后则会根据用户配置的告警信息单线程发送到不同的平台中。虽然这样做可能会让用户延迟收到告警,但是我们在实践中发现同时有 100+ 个 Flink 作业失败,用户接受到告警的延迟时间小于 3s。对于这种延迟时间,我们业务开发同学完全是可以接受的。该改进目前已经记录 ISSUE,正在考虑贡献到社区中。
[Feature] Solve alarm current limiting · Issue #2142 · apache/incubator-streampark · GitHub
带来的收益
我们从 StreamX 1.2.3(StreamPark 前身)开始探索和使用,经过一年多时间的磨合,我们发现 StreamPark 真实解决了 Flink 作业在开发管理和运维上的诸多痛点。
StreamPark 给顺网科技带来的最大的收益就是降低了 Flink 的使用门槛,提升了开发效率。我们业务开发同学在原先的 Streaming-Launcher 中需要使用 vscode、GitLab 和调度平台等多个工具完成一个 FlinkSQL 作业开发,从开发到编译到发布的流程中经过多个工具使用,流程繁琐。StreamPark 提供一站式服务,可以在 StreamPark 上完成作业开发编译发布,简化了整个开发流程。
目前 StreamPark 在顺网科技已经大规模在生产环境投入使用,StreamPark 从最开始管理的 500+ 个 FlinkSQL 作业增加到了近 700 个 FlinkSQL作业,同时管理了 10+ 个 Yarn Sesssion Cluster。
未 来 规 划
顺网科技作为 StreamPark 早期的用户之一,在 1 年期间内一直和社区同学保持交流,参与 StreamPark 的稳定性打磨,我们将生产运维中遇到的 Bug 和新的 Feature 提交给了社区。在未来,我们希望可以在 StreamPark 上管理 Flink 表的元数据信息,基于 Flink 引擎通过多 Catalog 实现跨数据源查询分析功能。目前 StreamPark 正在对接 Flink-SQL-Gateway 能力,这一块在未来对于表元数据的管理和跨数据源查询功能会提供了很大的帮助。
由于在顺网科技多是已 Yarn Session 模式运行的作业,我们希望 StreamPark 可以提供更多对于 Remote集群、Yarn Session 集群和 K8s Session 集群功能支持,比如监控告警,优化操作流程等方面。
考虑到未来,随着业务发展可能会使用 StreamPark 管理更多的 Flink 实时作业,单节点模式下的 StreamPark 可能并不安全。所以我们对于 StreamPark 的 HA 也是非常期待。
对于 StreamPark 对接 Flink-SQL-Gateway 能力、丰富 Flink Cluster 功能和 StreamPark HA,我们后续也会参与建设中。
非常感谢 StreamPark 团队一直以来对我们的技术支持,祝 Apache StreamPark 越来越好,为实时计算平台建设舔砖加瓦。
💻 项目地址:GitHub - apache/incubator-streampark: StreamPark, Make stream processing easier! easy-to-use streaming application development framework and operation platform
🧐 提交问题和建议:Issues · apache/incubator-streampark · GitHub
🥁 贡献代码:Pull requests · apache/incubator-streampark · GitHub
*📮 Proposal:StreamPark Proposal - INCUBATOR - Apache Software Foundation*
📧 订阅社区开发邮件列表:dev@streampark.apache.org
版权归原作者 Apache StreamPark 所有, 如有侵权,请联系我们删除。