
Flink中的序列化应用场景
程序通常使用(至少)两种不同的数据表示形式[2]:
1. 在内存中,数据保存在对象、结构体、列表、数组、哈希表和树等结构中。
2. 将数据写入文件或通过网络发送时,必须将其序列化为字节序列。
从内存中的表示到字节序列的转化称为序列化,反之称为反序列化。
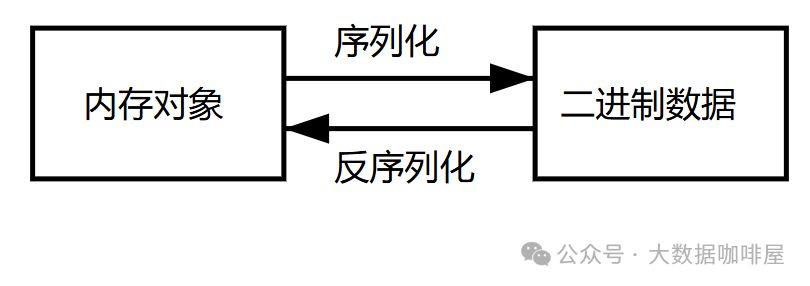
Flink中,下述的场景需要进行序列化和反序列化[1]。
1. F1ink中上下游算子之间可能分布在不同的节点上,不同算子的subTask会通过网络传输数据
2. Flink的Source和sink算子消费和写入Kafka Topic
3. F1ink中进行checkPoint将内存中的状态持久化到HDFs和从checkPoint恢复时从HDFS上加载状态数据
Flink未直接使用Java序列化,而是自研了一套高效的序列化机制。
比如我们要在算子间传递一个Tuple3<Integer, Long, Person>的数据(其中Preson为由id和name组成的pojo类),则subTask对其进行序列化的关键步骤如下。
分析识别算子间传输数据的数据类型
根据数据类型创建对应的序列化器
使用序列化器将数据写入到内中(即内存段MemorySegment中)
1. 分析识别算子间传输数据的数据类型
2. 根据数据类型创建对应的序列化器
3. 使用序列化器将数据写入到内中(即内存段MemorySegment中)

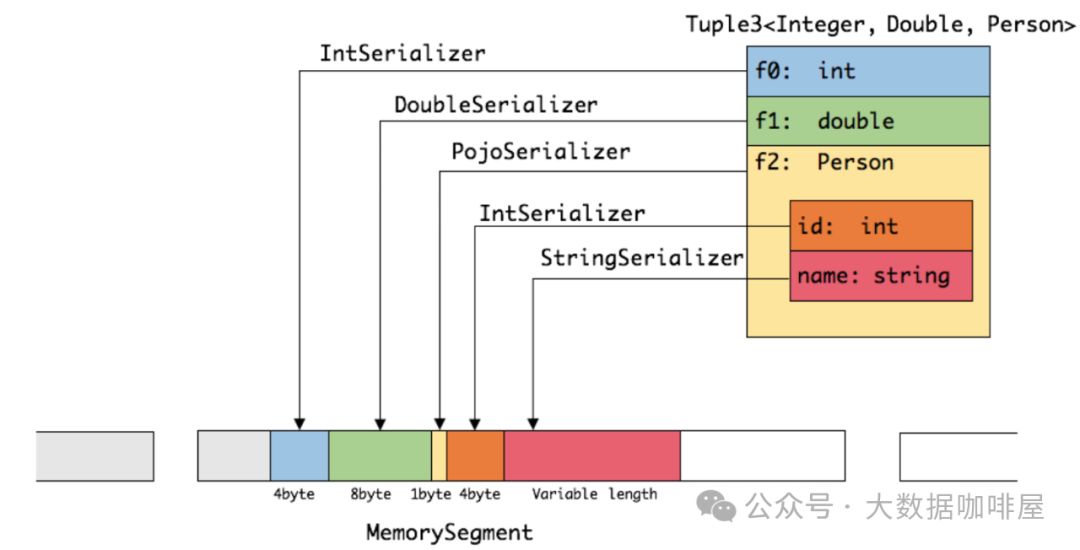
Flink支持的类型有以下几种[3],基本覆盖了大部分的用户使用场景,所以一般不用再自定义序列化器。

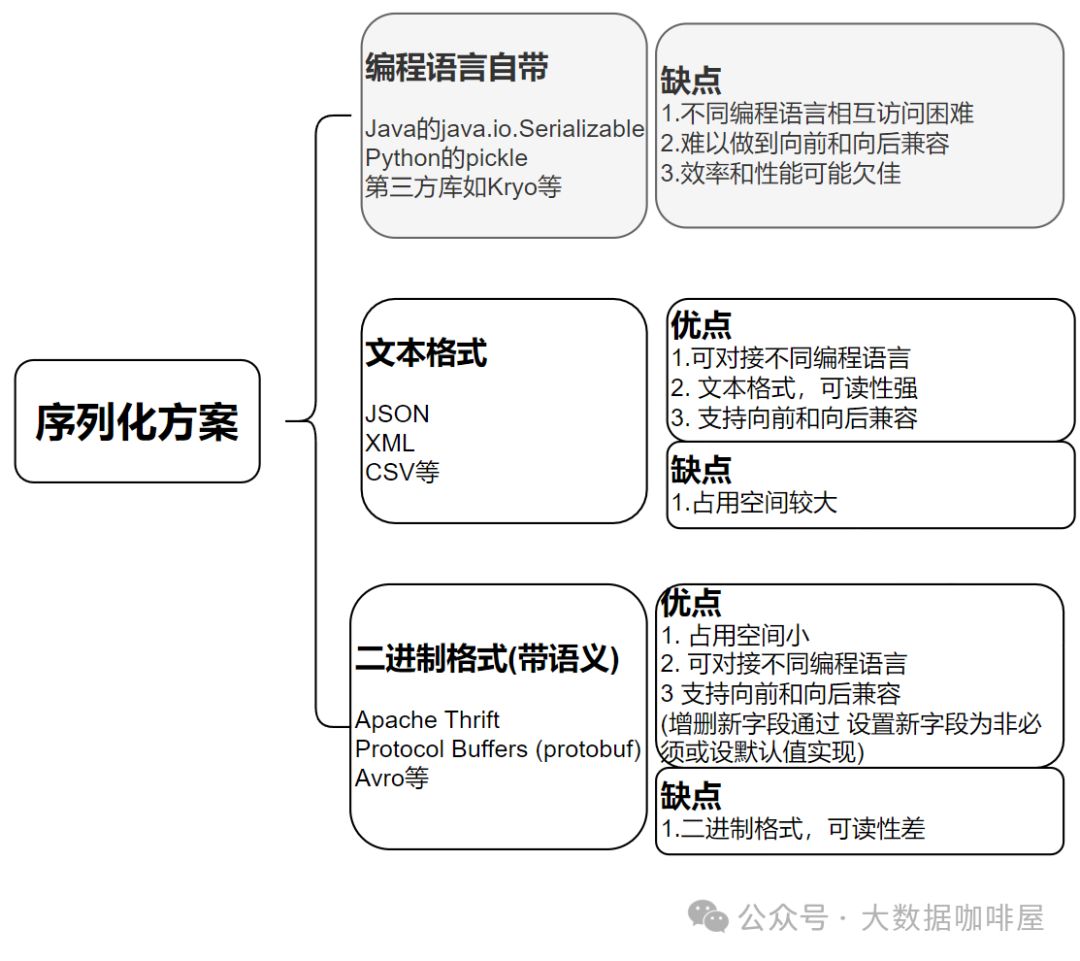
序列化方案的选择
如上节所述,很多场景(比如下面的场景)中数据在内存和文件/网络间传递时需要考虑序列化。
1. [数据库] 将数据写入到数据库需要进行序列化,从数据库读取的时候需要进行反序列
2. [服务调用(REST和远程调用RPC)] 客户端对请求进行序列化,服务器端对请求就行反序列化并将响应进行序列化,客户端最终对响应进行反序列化
3. [消息传递(消息代理Kafka和分布式Actor框架)] 节点之间通过互发消息进行通信,消息由由发送者进行序列化并由接收者反序列化。
生产环境中,许多服务需要支持滚动升级,即每次将新版本部署到几个节点,而非所有节点。
这种情况下,必须假设不同的节点正在运行应用代码的不同版本。
这意味着新旧版本的代码,以及新旧数据格式,可能会同时在系统内共存。
为了使系统继续顺利运行,需要保持双向的兼容性。
向后兼容:较新的代码可以读取由旧代码编写的数据。
向前兼容:较旧的代码可以读取由新代码编写的数据。
这种情况下,需要选择合适的序列化方案以支持双向兼容性就比较重要。
很多系统会选择Json/XML等文本格式和Avro等二进制格式的方案[2]。
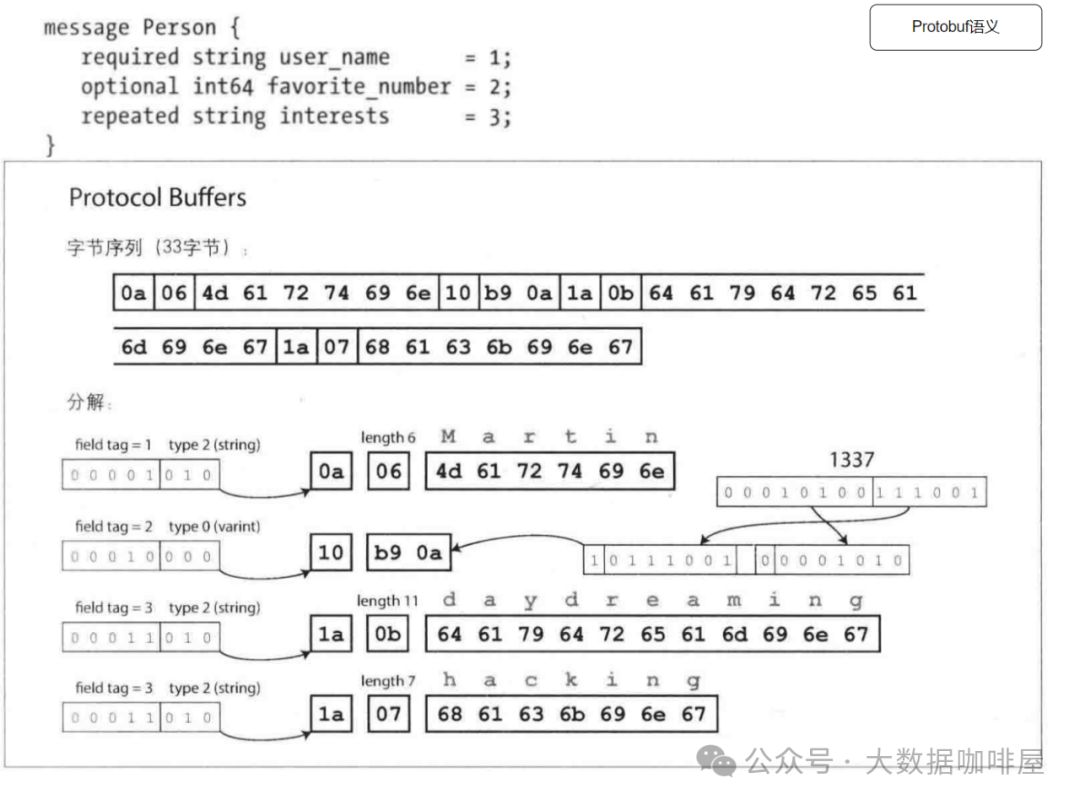
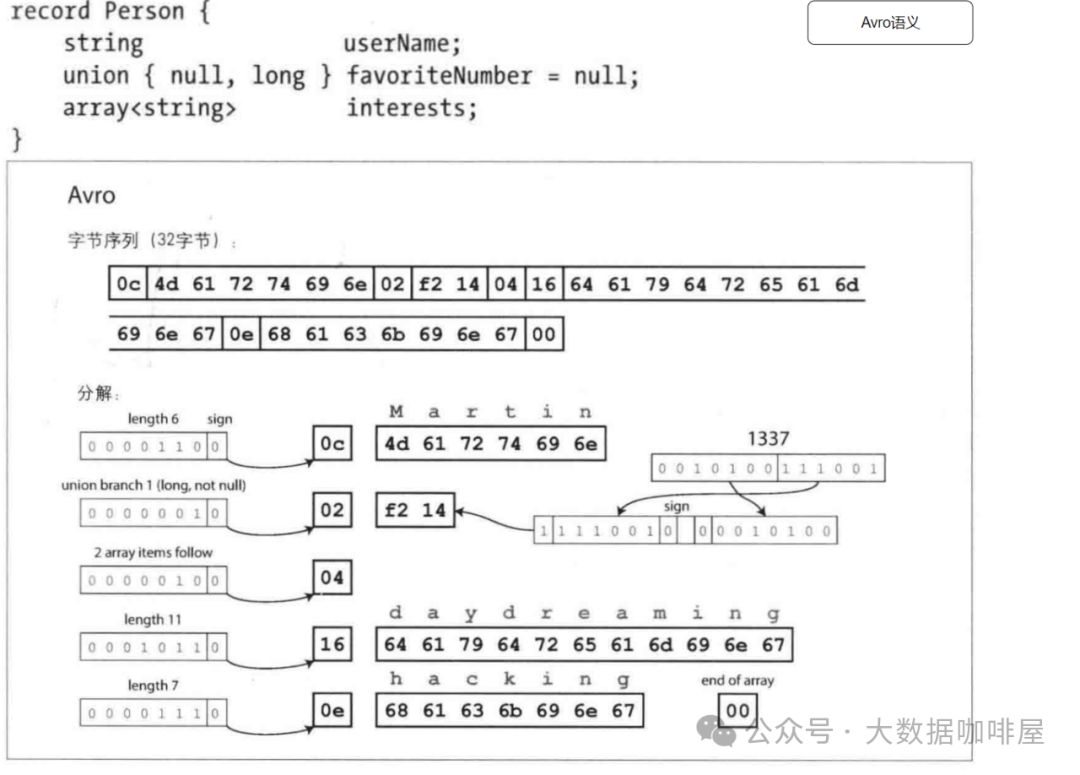
此处以一条json数据为例,可以看到json的文本格式和Protobuf&Avro两种二进制格式的区别。

参考
1.《Flink SQL与DataStream 入门、进阶与实践》 羊艺超著 P121-P127
2.《数据密集型应用系统设计》 Martin Kleppmann 著 P109-P134
3. 数据类型以及序列化 https://nightlies.apache.org/flink/flink-docs-release-1.12/zh/dev/types_serialization.html
本文转载自: https://blog.csdn.net/HuailiShang/article/details/143454203
版权归原作者 HuailiShang 所有, 如有侵权,请联系我们删除。
版权归原作者 HuailiShang 所有, 如有侵权,请联系我们删除。