
文章目录
一、爬取目标
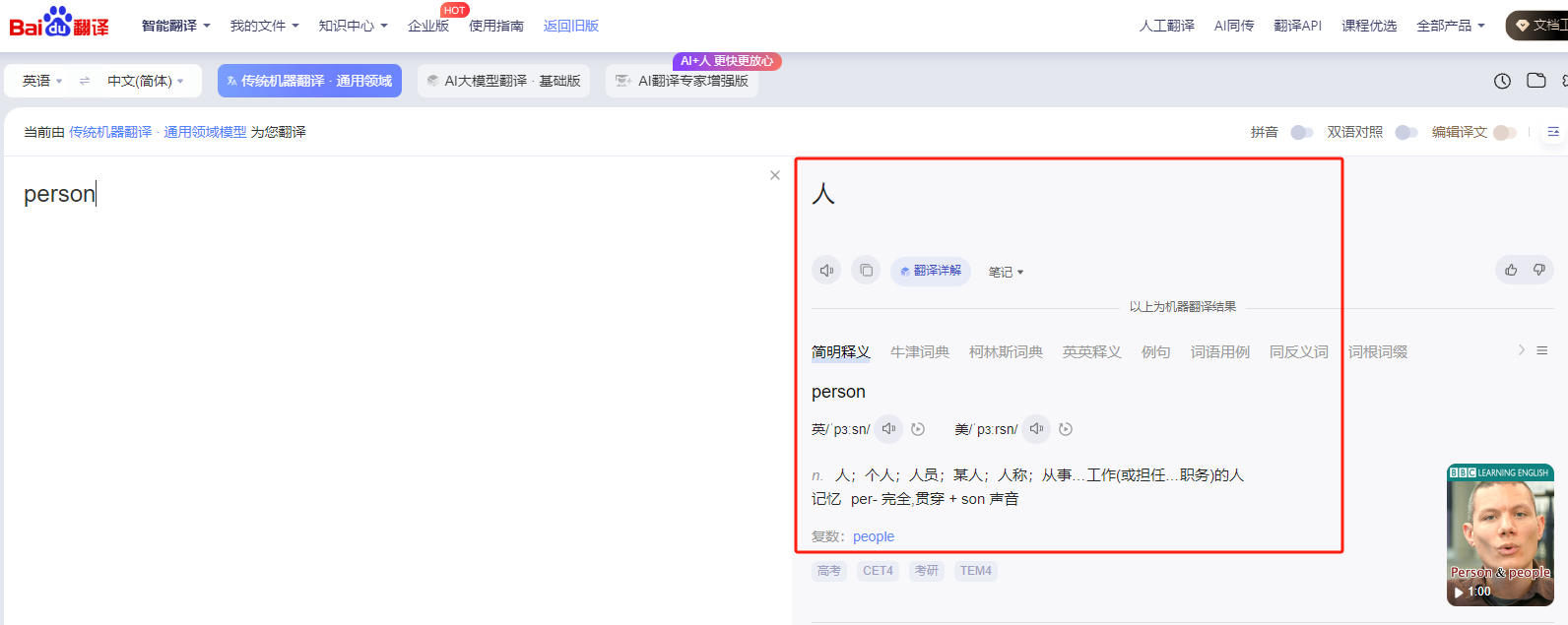
本次目标网站:百度翻译(https://fanyi.baidu.com/),输入一个关键词后返回翻译结果:
二、环境准备
Python:3.10
编辑器:PyCharm
第三方模块,自行安装:
pip install requests # 网页数据爬取
三、代理IP获取
由于百度翻译限制很严,为了能正常获取数据这里必须使用到代理IP。
3.1 爬虫和代理IP的关系
爬虫和代理IP之间的关系是相互依存的。代理IP为爬虫提供了绕过IP限制、隐藏真实IP、提高访问速度等能力,使得爬虫能够更有效地进行数据抓取。然而,在使用时也需要注意合法性、稳定性、成本以及隐私保护等问题。
3.2 巨量IP介绍
巨量IP提供免费HTTP代理IP和长效静态IP、短效IP、动态IP代理、隧道代理等服务,支持按时、按量、按时按量3种计费方式,根据业务场景需求,让套餐的选择变得更灵活:巨量IP官网
3.3 超值企业极速池推荐
博主经常写爬虫代码使用的是巨量IP家的企业极速池,每日500万去重IP,单IP低至0.005元 (按量计费),并且充值加赠50%,不得不说真的很香:
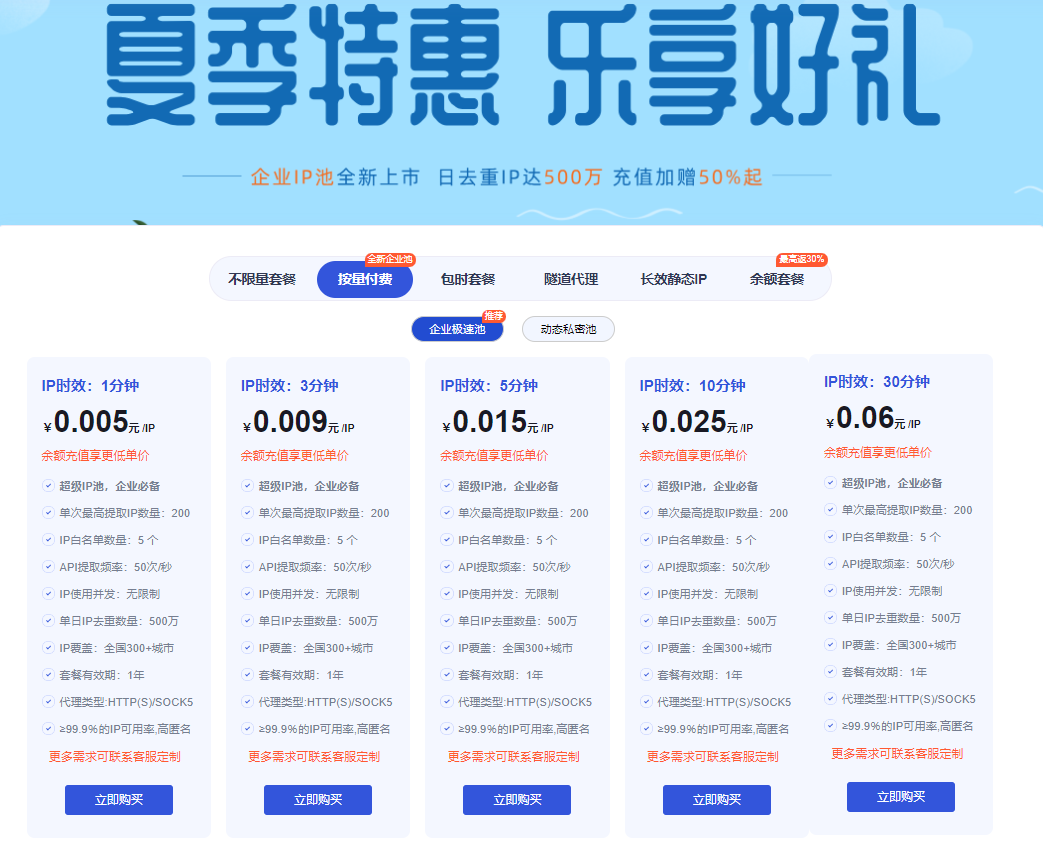
经常使用爬虫的小伙伴推荐使用IP时效:1分钟的套餐性价比超高。
3.4 IP领取
巨量IP还提供每日1000个免费IP供大家使用:代理IP免费领取
3.5 代码获取IP
1、点击产品管理找到我们 购买或者领取 的套餐:
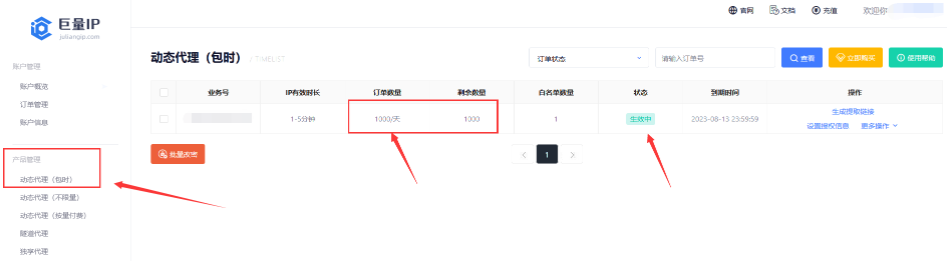
2、将自己电脑的IP添加为白名单能获取代理IP,点击授权信息:
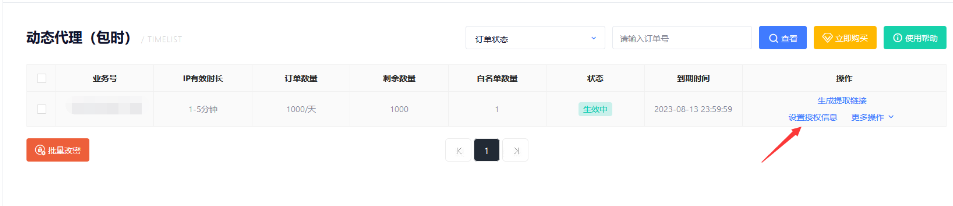
3、依次点击修改授权》快速添加》确定
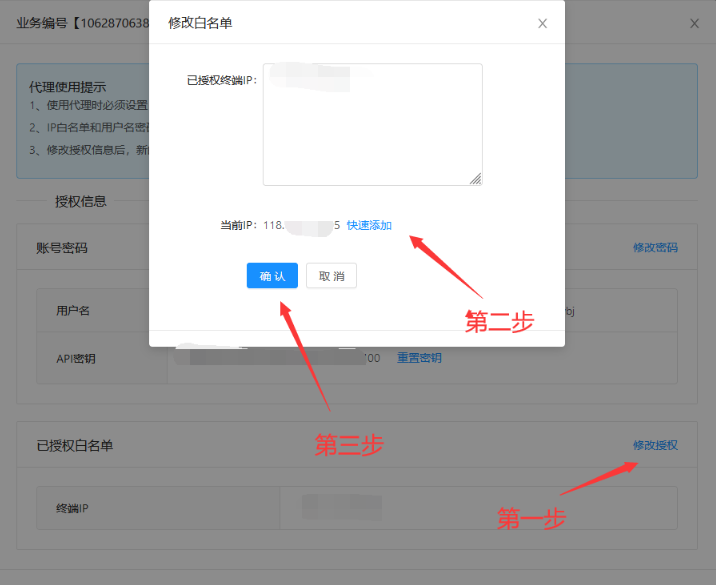
4、添加完成后,点击生成提取链接:
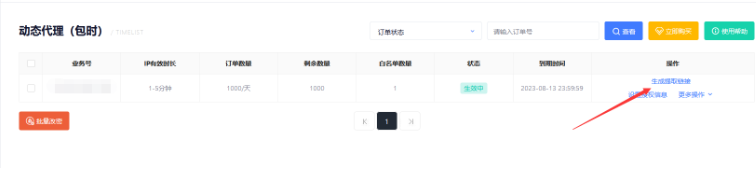 5、设置每次提取的数量,点击生成链接,并复制链接:
5、设置每次提取的数量,点击生成链接,并复制链接:
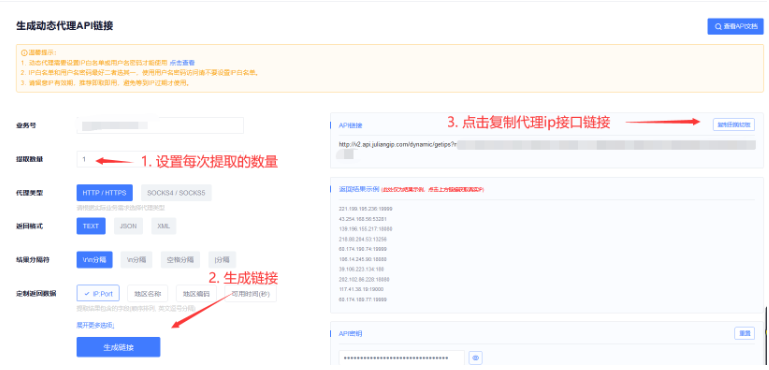
6、将复制链接,复制到地址栏就可以看到我们获取到的代理IP了:
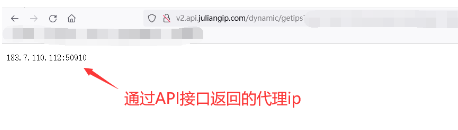
7、代理获取IP(注意:下面url需要换成你的链接):
import requests
import time
import random
defget_ip():
url ="这里放你自己的API链接"while1:try:
r = requests.get(url, timeout=10)except:continue
ip = r.text.strip()if'请求过于频繁'in ip:print('IP请求频繁')
time.sleep(1)continuebreak
proxies ={'https':'%s'% ip
}return proxies
if __name__ =='__main__':
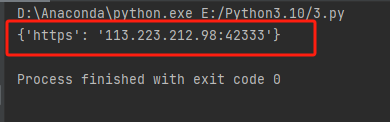
proxies = get_ip()print(proxies)
获取成功:
四、爬虫代码实战
4.1分析网页
在翻译栏左侧输入内容,并不需要刷新网页,翻译结果可实时返回,说明该翻译网站为进行Ajax加载的网站:
Ajax(Asynchronous JavaScript and XML)是一种在无需重新加载整个网页的情况下,能够更新部分网页内容的技术。它通过在后台与服务器交换数据,并允许网页异步更新,从而提升了用户体验。
4.2 寻找接口
1、鼠标右击》检查》选择XHR,输入翻译内容,找到对应的翻译接口:
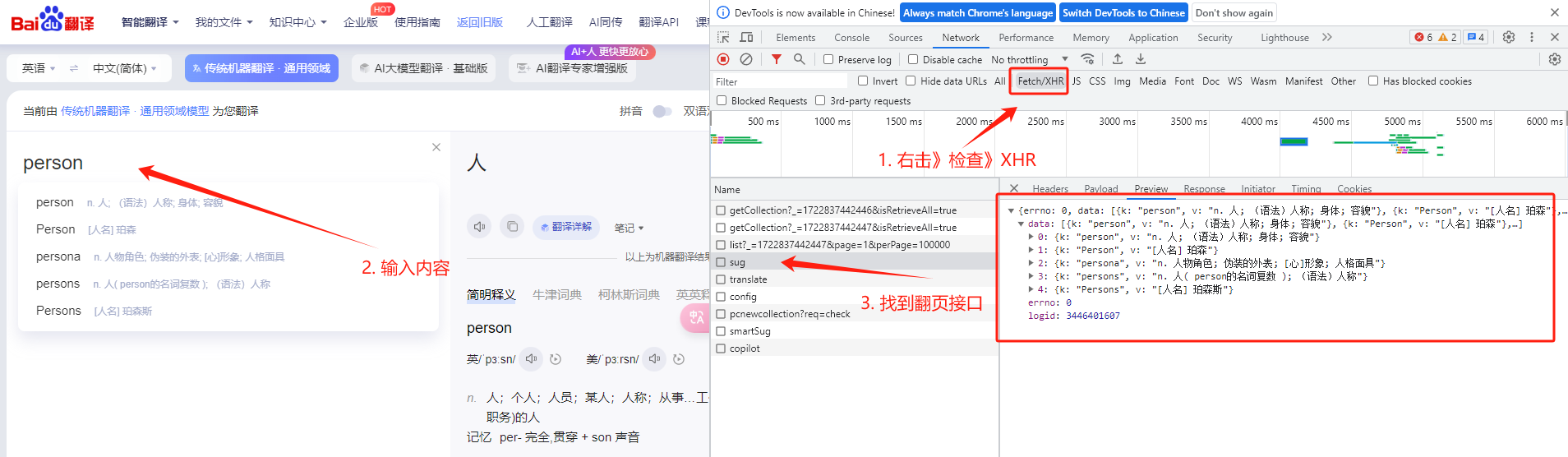
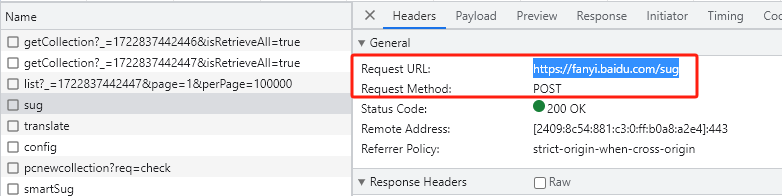
2、找到接口网址(https://fanyi.baidu.com/sug)和请求方式(Post请求):
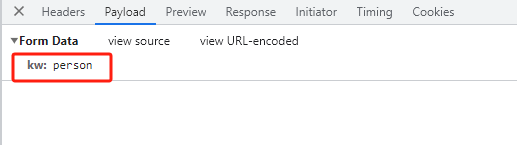
3、可以看到携带的参数就是我们输入的内容:
4.3 参数构建
下面代码构建一个携带参数的post请求:
# 1. 百度接口链接
post_url ='https://fanyi.baidu.com/sug'# 2. 创建post请求携带的参数,将手动输入需要翻译的单词传进去
data ={'kw': kw
}# 3. 携带请求头
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.51'}# 使用post 请求(和get类似)
data_json = requests.post(url=post_url, data=data, headers=headers).json()
4.4 完整代码
注意下面代码需要修改
get_ip()
函数中
url
添加你自己的代理IP接口url(防止被识别到为爬虫):
import requests
import time
defget_ip():
url ="这里换成自己的代理IP接口url"while1:try:
r = requests.get(url, timeout=10)#except:continue
ip = r.text.strip()if'请求过于频繁'in ip:print('IP请求频繁')
time.sleep(1)continuebreak
proxies ={'https':'%s'% ip
}return proxies
defget_data(kw):# 1. 百度接口链接
post_url ='https://fanyi.baidu.com/sug'# 2. 创建post请求携带的参数,将手动输入需要翻译的单词传进去
data ={'kw': kw
}# 3. 携带请求头
headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.51'}# 4. 获取代理IP
proxies = get_ip()# 使用post 请求
data_json = requests.post(url=post_url, data=data, headers=headers,proxies=proxies).json()# print(data_json)for key in data_json['data'][0]:print(key, data_json['data'][0][key])defmain():whileTrue:# 手动输入需要翻译的单词
kw =input("请输入需要翻译的单词:")
get_data(kw)if __name__ =='__main__':
main()
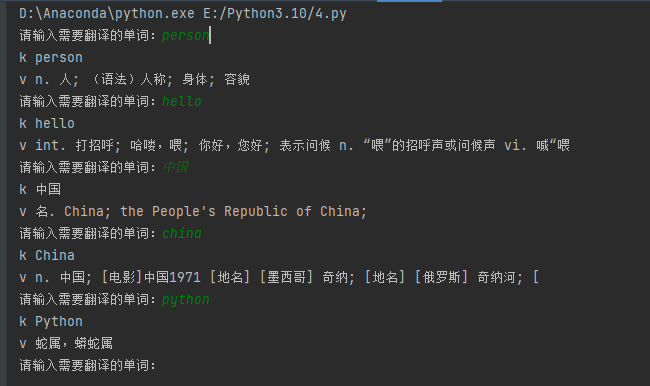
可以看到中文翻译为英文,英文翻译为中文都可以轻松实现:
版权归原作者 袁袁袁袁满 所有, 如有侵权,请联系我们删除。