

版权声明:本文为CSDN博主「开着拖拉机回家」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
主页地址:开着拖拉机回家的博客_CSDN博客-Linux,Java基础学习,MySql数据库领域博主
一、概述
1.1 Service
Service引入主要是解决Pod的动态变化,提供统一访问入口。Kubernetes Service定义了这样一种抽象: Service是一种可以访问 Pod逻辑分组的策略, Service通常是通过 Label Selector访问 Pod组。
Service能够提供负载均衡的能力,但是在使用上有以下限制:只提供 4 层负载均衡能力,而没有 7 层功能,但有时我们可能需要更多的匹配规则来转发请求,这点上 4 层负载均衡是不支持的。Service的作用:
• 防止Pod失联,准备找到提供同一个服务的Pod(服务发现)
• 定义一组Pod的访问策略(负载均衡)
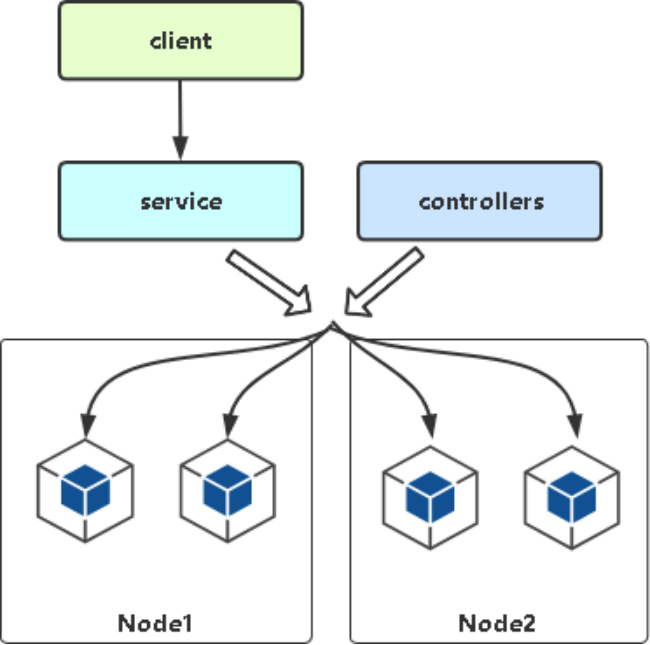
1.2 kube-proxy与Service
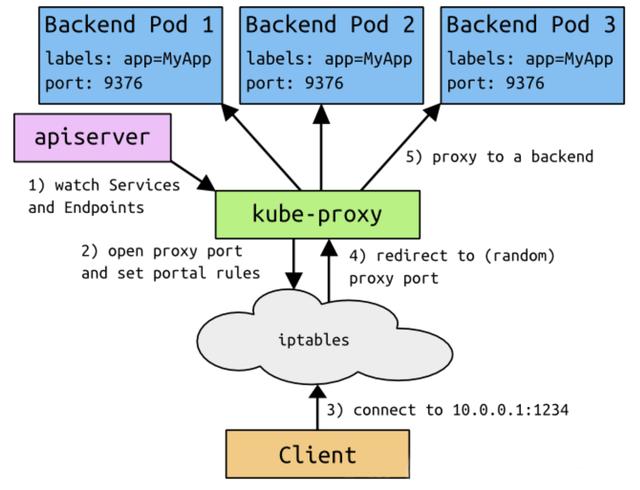
- 客户端访问节点时通过 iptables 实现的;
- iptables规则是通过 kube-proxy写入的;
- apiserver通过监控 kube-proxy去进行对服务和端点的监控;
- kube-proxy通过 pod的标签( lables)去判断这个断点信息是否写入到 Endpoints里
1.3VIP和Service代理
在 Kubernetes集群中,每个 Node运行一个 kube-proxy进程。** kube-proxy负责为 Service实现了一种 VIP(虚拟 IP)的形式**,而不是 ExternalName的形式。在 Kubernetes v1.0版本,代理完全在 userspace。在 Kubernetes v1.1版本,新增了 iptables代理,但并不是默认的运行模式。从 Kubernetes v1.2起,默认就是 iptables代理。在 Kubernetes v1.8.0-beta.0中,添加了 ipvs代理。
在 Kubernetes v1.0版本, Service是 4 层( TCP/ UDP over IP)概念。在 Kubernetes v1.1版本,新增了 Ingress API( beta版),用来表示 7 层( HTTP)服务为何不使用 round-robin DNS?
DNS会在很多的客户端里进行缓存,很多服务在访问 DNS进行域名解析完成、得到地址后不会对 DNS的解析进行清除缓存的操作,所以一旦有他的地址信息后,不管访问几次还是原来的地址信息,导致负载均衡无效。
二、Pod与Service 的关系
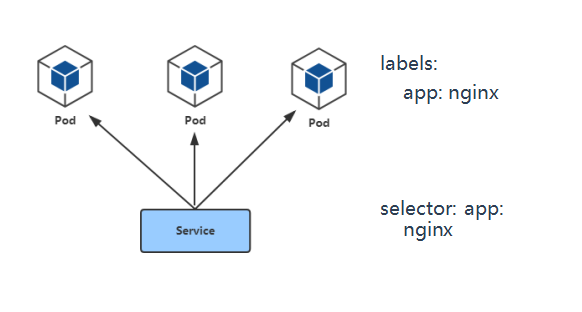
• Service通过标签关联一组Pod
• Service使用iptables或者ipvs为一组Pod提供负载均衡能力
三、Service类型
- ClusterIP:集群内部使用,默认类型,自动分配一个仅Cluster内部可以访问的虚拟IP
- NodePort:对外暴露应用(集群外),在ClusterIP基础上为Service在每台机器上绑定一个端口
- LoadBalancer:对外暴露应用,适用公有云
- ExternalName:把集群外部的服务引入到集群内部来,在集群内部直接使用。
四、代理模式分类
- iptables 代理模式
- userspace 代理模式
- ipvs 代理模式
ipvs代理模式中 kube-proxy会监视 Kubernetes Service对象和 Endpoints,调用 netlink接口以相应地创建 ipvs规则并定期与 Kubernetes Service对象和 Endpoints对象同步 ipvs规则,以确保 ipvs状态与期望一致。访问服务时,流量将被重定向到其中一个后端 Pod。
与 iptables类似, ipvs于 netfilter的 hook功能,但使用哈希表作为底层数据结构并在内核空间中工作。这意味着 ipvs可以更快地重定向流量,并且在同步代理规则时具有更好的性能。此外, ipvs为负载均衡算法提供了更多选项,例如:rr:轮询调度lc:最小连接数dh:目标哈希sh:源哈希sed:最短期望延迟nq:不排队调度
五、Service定义与创建
5.1 创建ClusterIP类型的Service
ClusterIP主要在每个node节点使用iptables,将发向ClusterIP对应端口的数据,转发到kube-proxy中。然后kube-proxy自己内部实现有负载均衡的方法,并可以查询到这个service下对应pod的地址和端口,进而把数据转发给对应的pod的地址和端口。
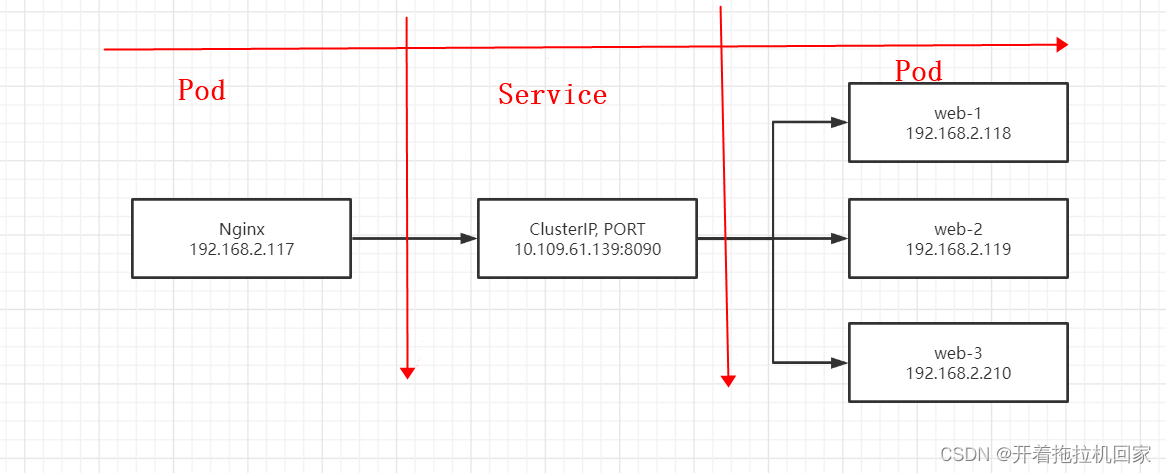
主要需要以下几个组件的协同工作:
apiserver:用户通过 kubectl命令向 apiserver发送创建 service的命令, apiserver接收到请求后将数据存储到 etcd中
kube-proxy: Kubernetes的每个节点中都有一个叫做 kube-porxy的进程,这个进程负责感知 service、 pod的变化,并将变化的信息写入本地的 iptables规则中
iptables:使用 NAT等技术将 virtualIP的流量转至 endpoint中
创建 service.yaml文件:
apiVersion: v1
kind: Service
metadata:
name: web
namespace: default
spec:
ports:
- port: 8090 # service端口
protocol: TCP # 协议
targetPort: 80 # 容器端口
selector: # 标签选择器
app: nginx # 指定关联Pod的标签
type: ClusterIP # 服务类型
###
kubectl apply -f service.yaml
### 查看service
kubectl get svc
### 查看pod 标签
kubectl get pods --show-labels
关联 Labels app=nginx 的pod,然后使用 service 提供的 IP 访问
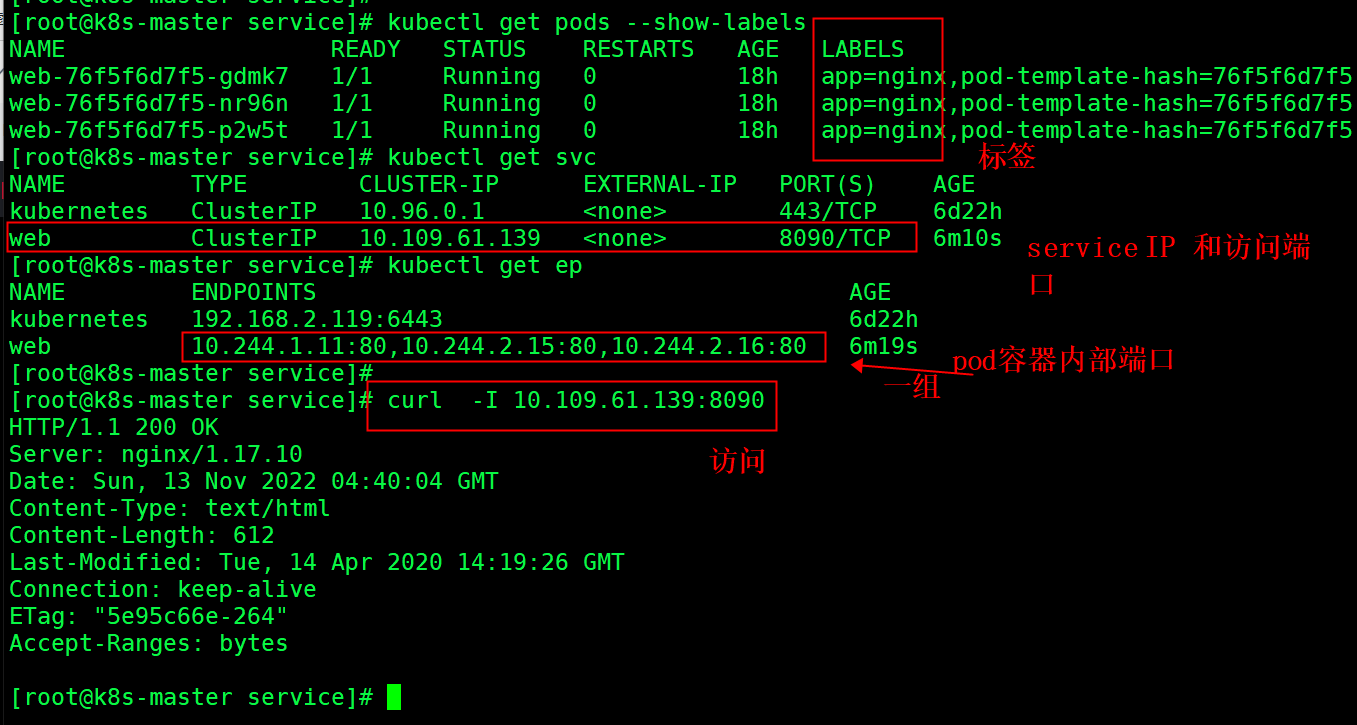
ClusterIP 默认分配一个稳定的IP地址,即VIP,只能在集群内部访问。
5.2 创建NodePort类型的Service
NodePort:在每个节点上启用一个端口来暴露服务,可以在集群外部访问,将向该端口的流量导入到 kube-proxy,然后由 kube-proxy进一步到给对应的 pod。。也会分配一个稳定内部集群IP地址。
访问地址:<任意NodeIP>:<NodePort> 端口范围:30000-32767
示例
apiVersion: v1
kind: Service
metadata:
name: web-nodeport
namespace: default
spec:
ports:
- port: 80 # service 端口
protocol: TCP # 协议
targetPort: 80 # 容器内部端口
nodePort: 30008 # NodePort端口
selector: # 标签选择器
app: nginx # 指定关联Pod的标签
type: NodePort # service类型
使用 NodePort类型的服务将nginx 的服务端口暴露出来。
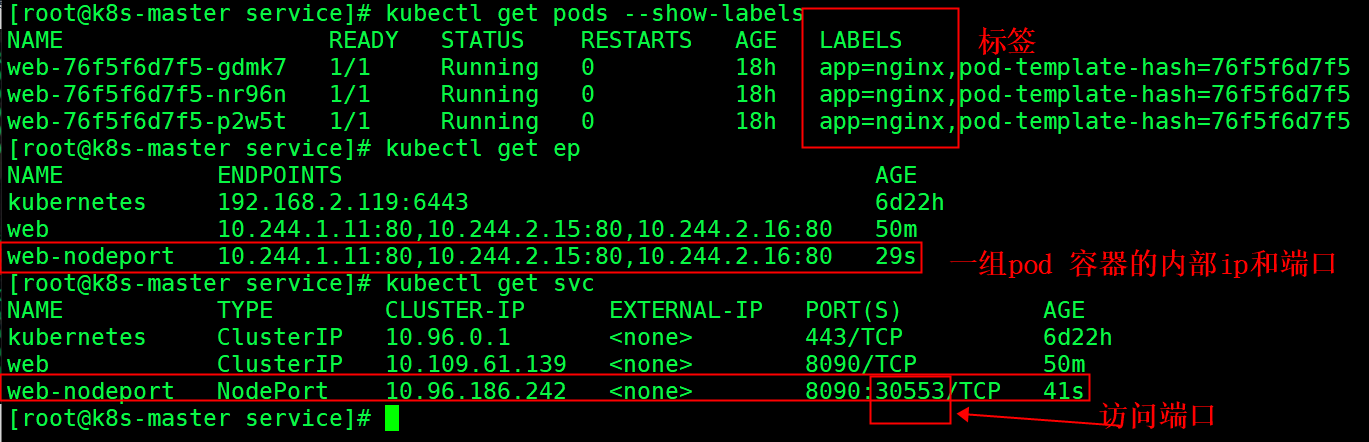
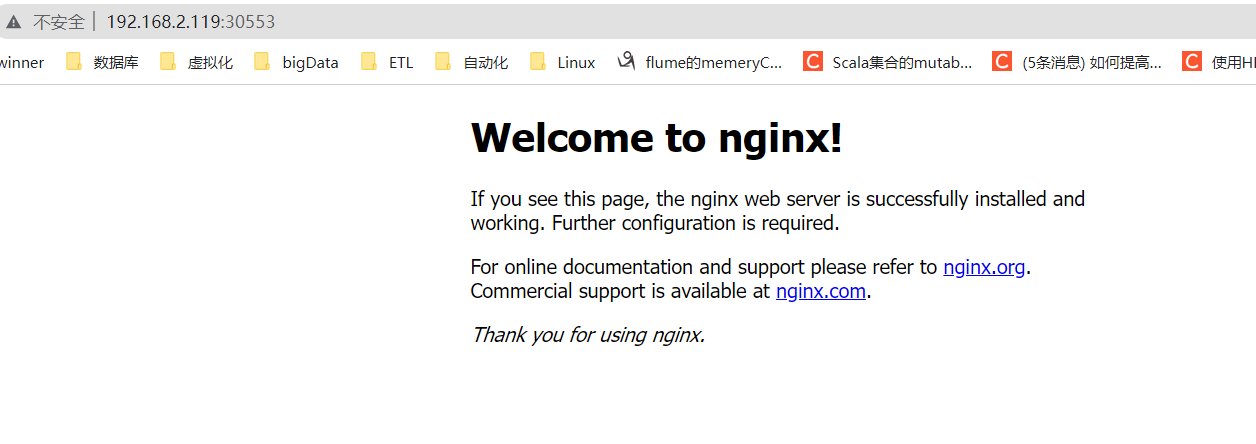
端口30553 加任意一台服务器IP成功访问
NodePort:会在每台Node上监听端口接收用户流量,在实际情况下,对用户暴露的只会有一个IP和端口,那这么多台Node该使用哪台让用户访问呢?
这时就需要前面加一个公网负载均衡器为项目提供统一访问入口了。

负载均衡器:
开源:Nginx 、LVS、haproxy
公有云:SLB
部署Nginx:
## 安装 nginx ,并启动
yum install epel-release -y
yum install nginx -y
systemctl start nginx
vim /etc/nginx/nginx.conf
#在server 的上面插入以下代码
upstream webservers {
server 192.168.2.118:30553;
server 192.168.2.210:30553;
}
server{
listen 8553;
location / {
proxy_pass http://webservers;
}
}
server {
listen 80 default_server;
listen [::]:80 default_server;
.....
## 配置关系重新 加载
[root@k8s-devops ~]# nginx -s reload
## 查看 8553 端口是否监听
[root@k8s-devops ~]# netstat -anlp | grep 8553
tcp 0 0 0.0.0.0:8553 0.0.0.0:* LISTEN 16715/nginx: master
[root@k8s-devops ~]#
监听端口如下:

IP+8553 端口访问 nginx 应用 :
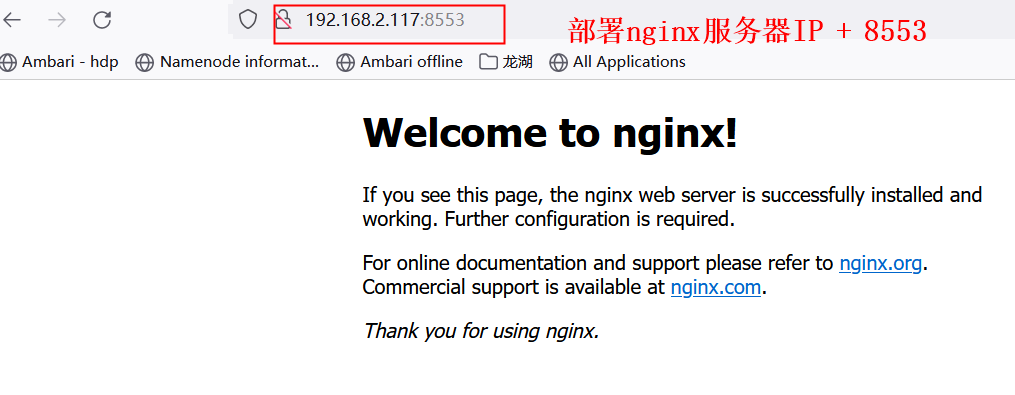
5.3创建LoadBalancer类型的Service
LoadBalancer:与NodePort类似,在每个节点上启用一个端口来暴露服务。除此之外,Kubernetes会请求底层云平台(例如阿里云、腾讯云、AWS等)上的负载均衡器,将每个Node
([NodeIP]:[NodePort])作为后端添加进去。
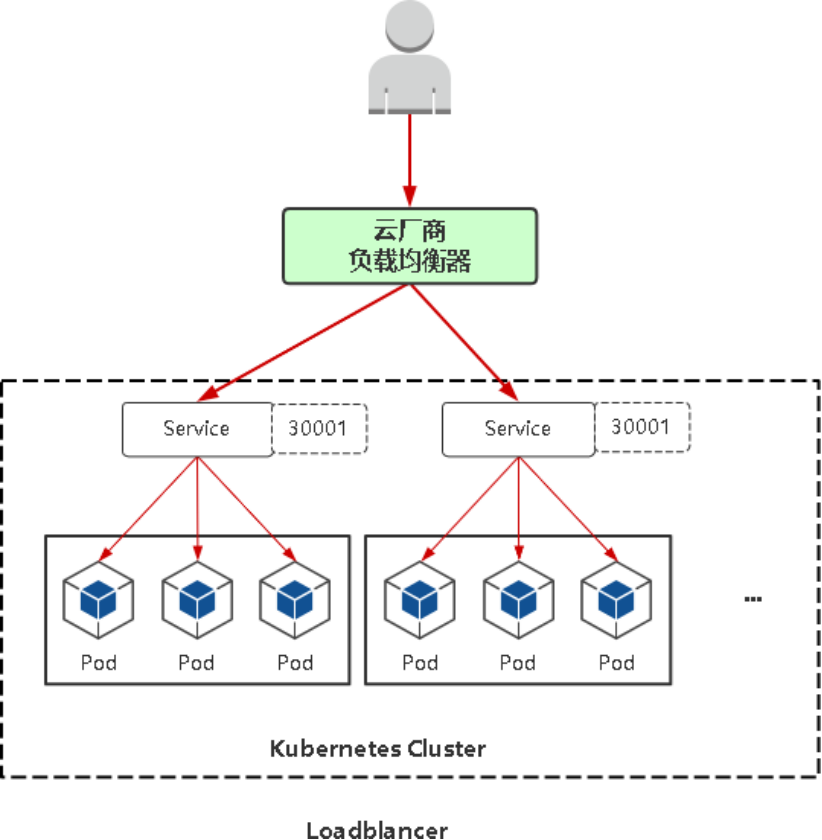
六、Service 代理模式
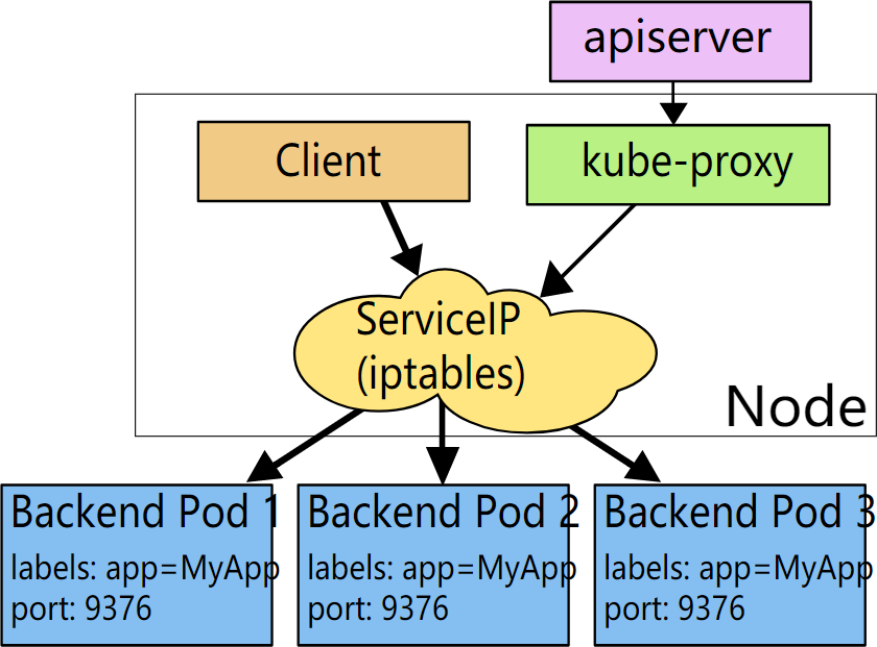
6.1iptables简介
表(tables)提供特定的功能,iptables内置了4个表,即filter表、nat表、mangle表和raw表,分别用于实现包过滤,网络地址转换、包重构(修改)和数据跟踪处理。
链(chains)是数据包传播的路径,每一条链其实就是众多规则中的一个检查清单,每一条链中可以有一 条或数条规则。当一个数据包到达一个链时,iptables就会从链中第一条规则开始检查,看该数据包是否满足规则所定义的条件。如果满足,系统就会根据 该条规则所定义的方法处理该数据包;否则iptables将继续检查下一条规则,如果该数据包不符合链中任一条规则,iptables就会根据该链预先定 义的默认策略来处理数据包。
使用-j可以指定动作,比如
-j ACCEPT
-j DROP
-j REJECT
原文链接:Iptables 详解与实战案例_开着拖拉机回家的博客-CSDN博客_iptables 实战
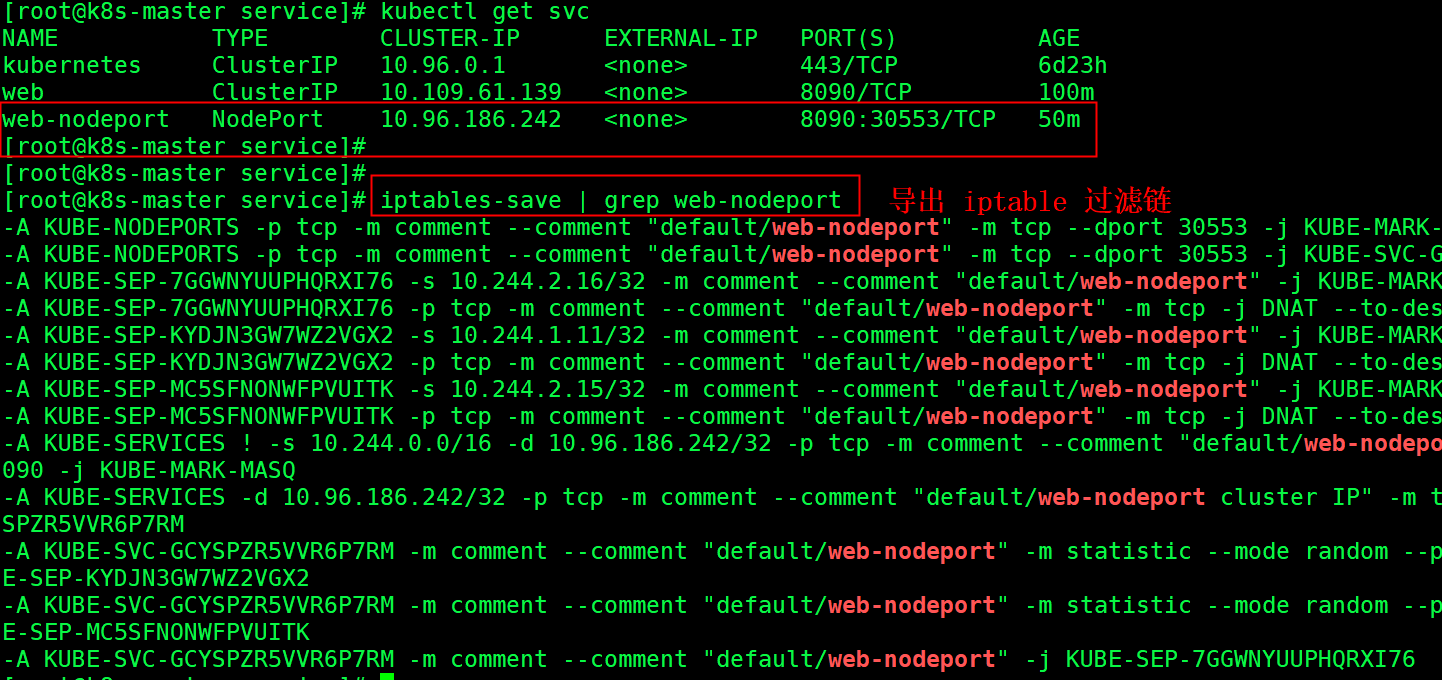
6.2iptables规则链在NodePort的应用
我们将 web-nodeport Service 的iptables 规则链 搜索出来。·
iptables规则链方位步骤:
第一步 :在浏览器访问
第二步 : 规则链重定向
### 数据包经过iptables规则匹配,重定向另一个链, KUBE-SVC-GCYSPZR5VVR6P7RM,
## -A 表示在指定链的末尾添加(append)一条新的规则
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/web-nodeport" -m tcp --dport 30553 -j KUBE-MARK-MASQ
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/web-nodeport" -m tcp --dport 30553 -j KUBE-SVC-GCYSPZR5VVR6P7RM
第三步 : 实现规则链转发负载
### 一组规则,有几个pod就会创建几条,我们这个三个 pod(这里实现了负载均衡器, probability 匹配到规则链的概率)
-A KUBE-SVC-GCYSPZR5VVR6P7RM -m comment --comment "default/web-nodeport" -m statistic --mode random --probability 0.33333333349 -j KUBE-SEP-KYDJN3GW7WZ2VGX2
-A KUBE-SVC-GCYSPZR5VVR6P7RM -m comment --comment "default/web-nodeport" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-MC5SFNONWFPVUITK
-A KUBE-SVC-GCYSPZR5VVR6P7RM -m comment --comment "default/web-nodeport" -j KUBE-SEP-7GGWNYUUPHQRXI76
第四步: 使用DNAT转发到具体的Pod
### 使用DNAT转发到具体的Pod
# 匹配链:KUBE-SEP-7GGWNYUUPHQRXI76, KUBE-SEP-MC5SFNONWFPVUITK,KUBE-SEP-MC5SFNONWFPVUITK
# -s 源服务器
# to-destination 目标服务器
# -j 指定动作 ACCEPT DROP
-A KUBE-SEP-7GGWNYUUPHQRXI76 -s 10.244.2.16/32 -m comment --comment "default/web-nodeport" -j KUBE-MARK-MASQ
-A KUBE-SEP-7GGWNYUUPHQRXI76 -p tcp -m comment --comment "default/web-nodeport" -m tcp -j DNAT --to-destination 10.244.2.16:80
-A KUBE-SEP-KYDJN3GW7WZ2VGX2 -s 10.244.1.11/32 -m comment --comment "default/web-nodeport" -j KUBE-MARK-MASQ
-A KUBE-SEP-KYDJN3GW7WZ2VGX2 -p tcp -m comment --comment "default/web-nodeport" -m tcp -j DNAT --to-destination 10.244.1.11:80
-A KUBE-SEP-MC5SFNONWFPVUITK -s 10.244.2.15/32 -m comment --comment "default/web-nodeport" -j KUBE-MARK-MASQ
-A KUBE-SEP-MC5SFNONWFPVUITK -p tcp -m comment --comment "default/web-nodeport" -m tcp -j DNAT --to-destination 10.244.2.15:80
针对ClusterIP实现的转发后面与nodeport一样,回到了上面第三步
#### 针对ClusterIP实现的转发,后面与nodeport一样,回到了上面第三步
-A KUBE-SERVICES ! -s 10.244.0.0/16 -d 10.96.186.242/32 -p tcp -m comment --comment "default/web-nodeport cluster IP" -m tcp --dport 8090 -j KUBE-MARK-MASQ
-A KUBE-SERVICES -d 10.96.186.242/32 -p tcp -m comment --comment "default/web-nodeport cluster IP" -m tcp --dport 8090 -j KUBE-SVC-GCYSPZR5VVR6P7RM
6.3IPVS

kube-proxy 是configmap 配置文件 部署的,我们修改下 kube-proxy 配置文件

编辑 修改 mode为IPVA:
## 编辑 kube-proxy 配置文件
kubectl edit configmap kube-proxy -n kube-system
40 tcpTimeout: 0s
41 udpTimeout: 0s
42 kind: KubeProxyConfiguration
43 metricsBindAddress: ""
44 mode: "ipvs" ## 修改 kube-proxy 配置中的mode为:ipvs
45 nodePortAddresses: null
46 oomScoreAdj: null
47 portRange: ""
48 showHiddenMetricsForVersion: ""
49 udpIdleTimeout: 0s
可以使用如下的命令查看 IPVS数据链
## 安装IPVS 命令
yum install ipvsadm
ipvsadm -L -n
### 删除POD kube-proxy-tg889
kubectl -n kube-system delete pod kube-proxy-tg889
删除node1 上的pod ,重新启动
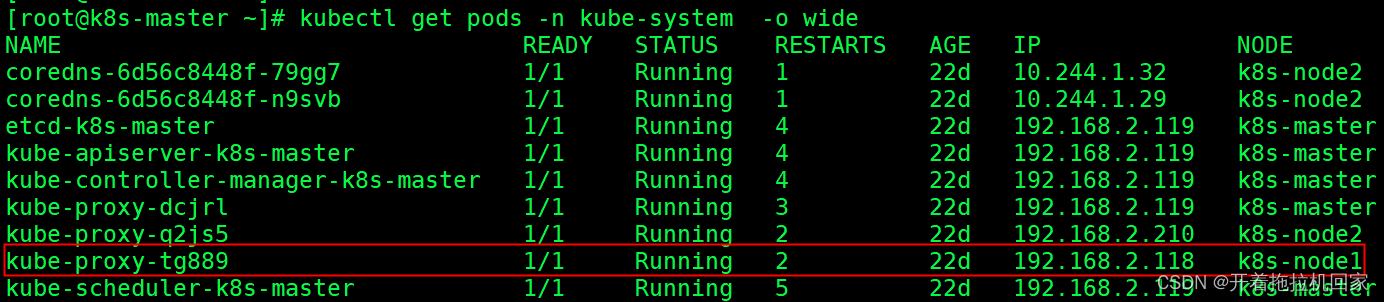 查看新的kube-proxy pod日志,显示“Using ipvs Proxier” 表示开启了ipvs模式:
查看新的kube-proxy pod日志,显示“Using ipvs Proxier” 表示开启了ipvs模式:
[root@node1 ~]# kubectl -n kube-system logs kube-proxy-tg889
I0512 20:46:39.128357 1 node.go:172] Successfully retrieved node IP: 192.168.2.118
I0512 20:46:39.128553 1 server_others.go:142] kube-proxy node IP is an IPv4 address (192.168.10.136), assume IPv4 operation
I0512 20:46:39.153956 1 server_others.go:258] Using ipvs Proxier.
I0512 20:46:39.166860 1 proxier.go:372] missing br-netfilter module or unset sysctl br-nf-call-iptables; proxy may not work as intended
E0512 20:46:39.167001 1 proxier.go:389] can't set sysctl net/ipv4/vs/conn_reuse_mode, kernel version must be at least 4.1
W0512 20:46:39.167105 1 proxier.go:445] IPVS scheduler not specified, use rr by default
I0512 20:46:39.167274 1 server.go:650] Version: v1.19.0
6.4iptables和IPVS对比
Iptables:
- 灵活,功能强大
- 规则遍历匹配和更新,呈线性时延
IPVS:
- 工作在内核态,为大型集群提供了更好的可扩展性和性能
- 调度算法丰富:最小负载、最少连接、加权等(rr,wrr,lc,wlc,ip hash...)
- ipvs 支持服务器健康检查和连接重试等功能
6.5Service工作流程
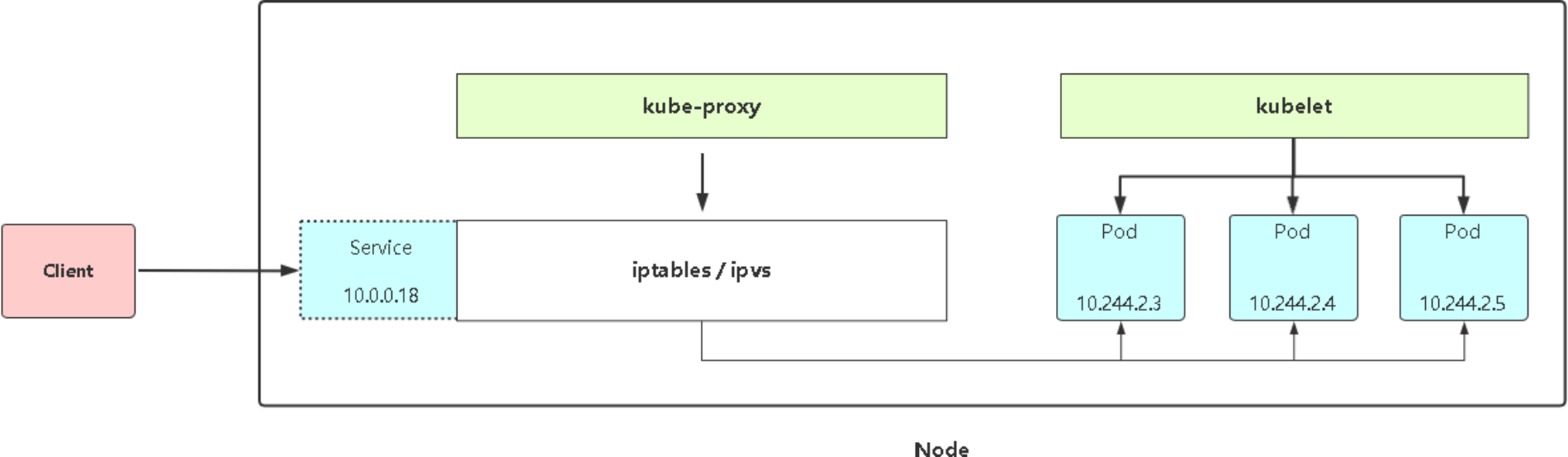
- 用户执行kubectl/userClient向apiserver发起一个命令,经过认证授权后,经过scheduler的各种策略,得到一个目标node,然后告诉apiserver,apiserver 会请求相关node的kubelet,通过kubelet把pod运行起来,apiserver还会将pod的信息保存在etcd;
- pod运行起来后,controllermanager就会负责管理pod的状态,如,若pod挂了,controllermanager就会重新创建一个一样的pod,或者像扩缩容等;
- pod有一个独立的ip地址,但pod的IP是易变的,如异常重启,或服务升级的时候,IP都会变,这就有了service;完成service工作的具体模块是kube-proxy,在每个node上都会有一个kube-proxy,在任何一个节点上访问一个service的虚拟ip,都可以访问到pod;
- service的IP可以在集群内部访问到,在集群外呢?service可以把服务端口暴露在当前的Node上,外面的请求直接访问到node上的端口就可以访问到service了
参考:一文讲透K8s的Service概念
版权声明:本文为CSDN博主「开着拖拉机回家」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
主页地址:开着拖拉机回家的博客_CSDN博客-Linux,Java基础学习,MySql数据库领域博主
版权归原作者 开着拖拉机回家 所有, 如有侵权,请联系我们删除。