
大家好,我是卷心菜。本篇主要讲解用SpringBoot整合Redis,如果您看完文章有所收获,可以三连支持博主哦~,嘻嘻。
文章目录
一、前言
🎁作者简介:在校大学生一枚,Java领域新星创作者,Java、Python正在学习中,期待和大家一起学习一起进步~
💗个人主页:我是一棵卷心菜的个人主页
🔶本文专栏:Redis理论和实战
📕自我提醒:多学多练多思考,编程能力才能节节高!
- 上一篇文章讲解了用Jedis来操作Redis数据库,今天就来看看如何使用springboot这个技术框架来整合redis!
二、基本介绍
- springboot在现在的版本中操作Redis数据库用到了lettuce,而不是Jedis,他们各有各的特点。
- Jedis以Redis命令作为方法名称,学习成本低,简单实用。但是Jedis实例是线程不安全的,多线程环境下需要基于连接池来使用。
- Lettuce是基于Netty实现的,支持同步、异步和响应式编程方式,并且是线程安全的。支持Redis的哨兵模式、集群模式和管道模式。
三、SpringDataRedis
- 在学习之前,我们先了解了解SpringDataRedis。它是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis。
- 它提供了RedisTemplate统一API来操作Redis、支持Redis的
发布订阅模型、支持Redis哨兵和Redis集群、支持基于JDK、JSON、字符串、Spring对象的数据序列化及反序列化等等,功能非常的多。
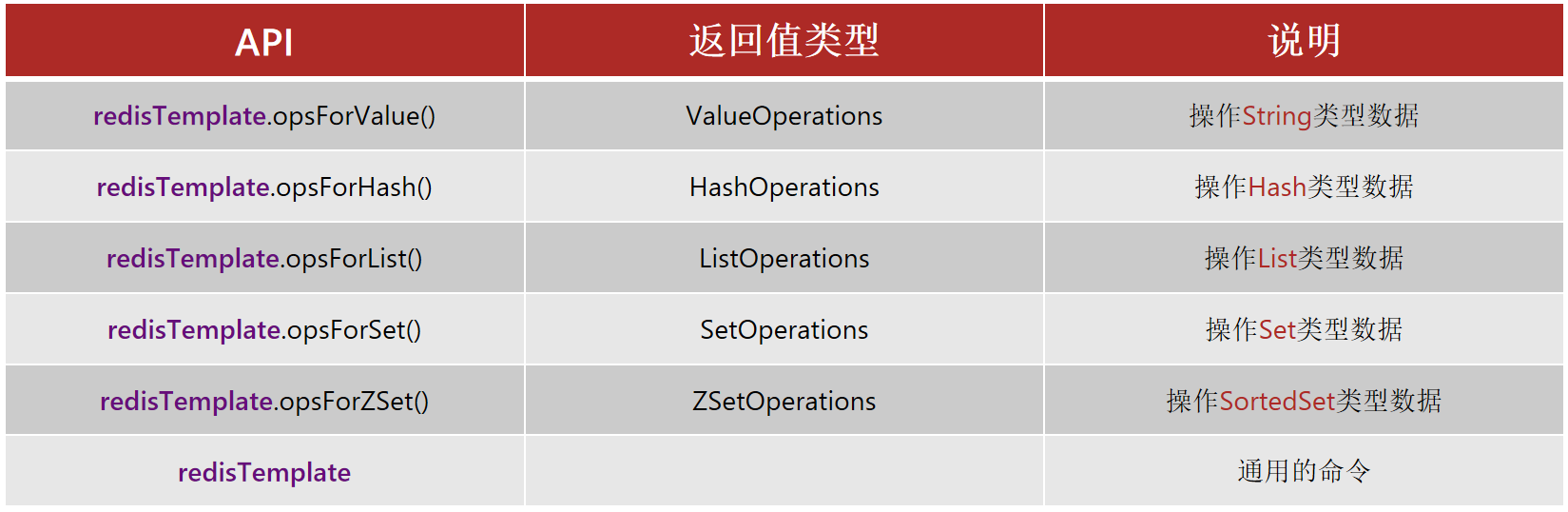
四、API的简单认识
五、快速入门
1、引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId></dependency>
2、配置文件
spring:redis:# Redis服务器地址host: 19.1.5.11
# Redis服务器端口号port:6379# 使用的数据库索引,默认是0database:0# 连接超时时间timeout:1800000# 设置密码password:"123456"lettuce:pool:# 最大阻塞等待时间,负数表示没有限制max-wait:-1# 连接池中的最大空闲连接max-idle:5# 连接池中的最小空闲连接min-idle:0# 连接池中最大连接数,负数表示没有限制max-active:20
3、代码实践
@TestvoidtestOne(){
redisTemplate.opsForValue().set("name","卷心菜");String name =(String) redisTemplate.opsForValue().get("name");System.out.println(name);//卷心菜}
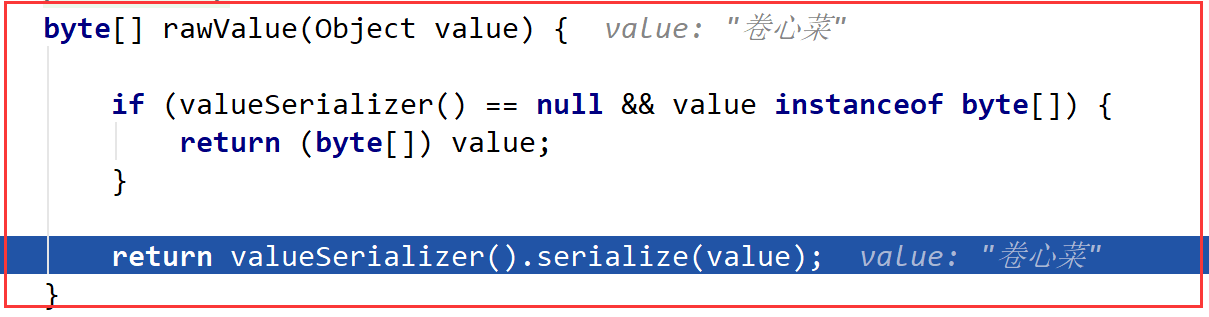
问题出现了:当我们使用Redis客户端查看刚刚存入Redis数据库的数据时,结果是这样的:

是因为在使用默认的对象
redisTemplate
时,会把value值序列化为byte类型,所以就出现了上图的结果。
六、自定义序列化方式
1、JSON序列化器
首先要编写一个配置类:
@ConfigurationpublicclassRedisConfig{@BeanpublicRedisTemplate<String,Object>redisTemplate(RedisConnectionFactory redisConnectionFactory)throwsUnknownHostException{// 创建模板RedisTemplate<String,Object> redisTemplate =newRedisTemplate<>();// 设置连接工厂
redisTemplate.setConnectionFactory(redisConnectionFactory);// 设置序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer =newGenericJackson2JsonRedisSerializer();// key和 hashKey采用 string序列化
redisTemplate.setKeySerializer(RedisSerializer.string());
redisTemplate.setHashKeySerializer(RedisSerializer.string());// value和 hashValue采用 JSON序列化
redisTemplate.setValueSerializer(jsonRedisSerializer);
redisTemplate.setHashValueSerializer(jsonRedisSerializer);return redisTemplate;}}
当配置好配置类后,再次执行上文的代码就不会出现上述情况了,但是问题又来了,当我们的key是一个对象时,代码如下:
voidtestTwo(){
redisTemplate.opsForValue().set("person",newPerson("卷心菜",21));}

问题是:为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销.
2、String序列化器
为了节省内存空间,我们并不会使用JSON序列化器来处理value,而是统一使用String序列化器,要求只能存储String类型的key和value。
当需要存储Java对象时,手动完成对象的序列化和反序列化
。
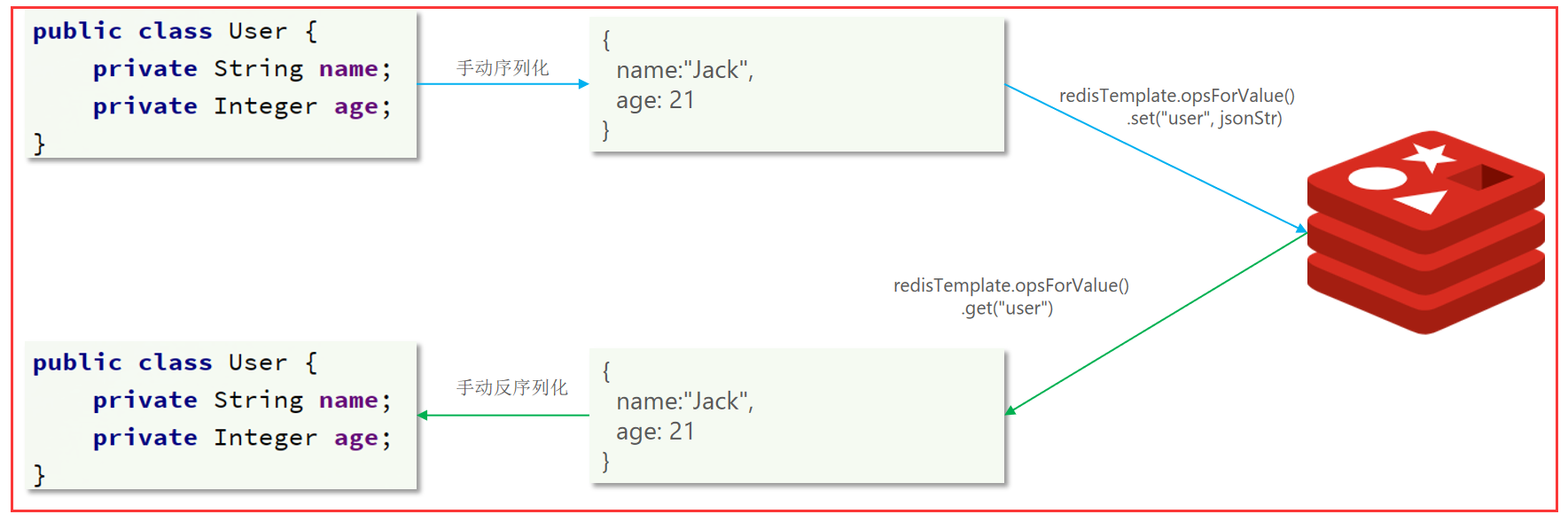
代码实践:
@AutowiredprivateStringRedisTemplate redisTemplate;// JSON工具privatestaticfinalObjectMapper mapper =newObjectMapper();@TestvoidtestOne(){
redisTemplate.opsForValue().set("name","卷心菜");}@TestvoidtestTwo()throwsIOException{Person person =newPerson("我是一棵卷心菜",21);// 手动序列化String json = mapper.writeValueAsString(person);
redisTemplate.opsForValue().set("person", json);String personJson = redisTemplate.opsForValue().get("person");// 反序列化Person person1 = mapper.readValue(personJson,Person.class);System.out.println(person1);}
当我们使用String序列化器时,就完美的解决了用Json序列化器的缺陷,运行结果如图所示:


感谢阅读,一起进步,嘻嘻~
本文转载自: https://blog.csdn.net/weixin_59654772/article/details/125692784
版权归原作者 我是一棵卷心菜 所有, 如有侵权,请联系我们删除。
版权归原作者 我是一棵卷心菜 所有, 如有侵权,请联系我们删除。