
HDFS组件
HDFS组件的基准测试
说明
一般在搭建完集群之后,运维人员需要对集群进行压力测试,对于HDFS来讲,主要是读写测试
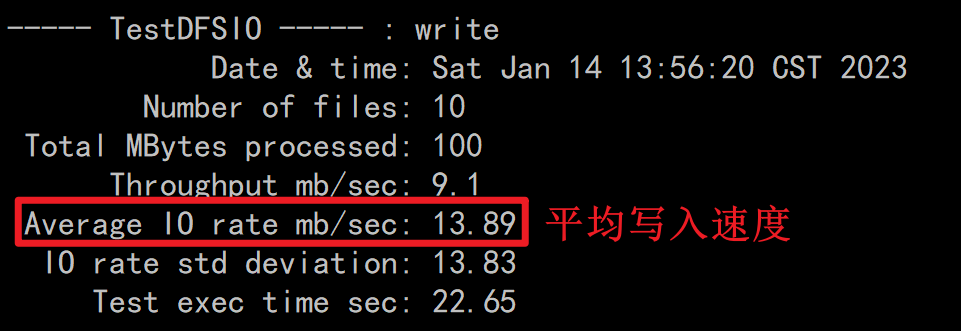
写入测试
hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.0-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 10MB
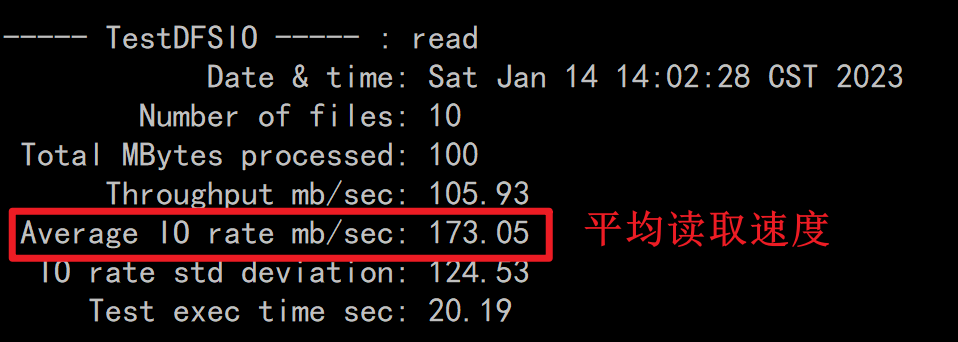
读取测试
hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.3.0-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 10MB
Hadoop的MapReduce历史服务查看
说明
如果你开启了历史服务器组件,则你跑过的所有的MapReduce任务都可以在19888端口查看,同时可以通过后台的日志先查看任务详细的执行流程,以便排查错误
http://node1:19888
打开方式
http://node1:19888/
文件系统
概念
文件系统是一个软件,通过这个软件,用户不用关系具体的文件内容存储在磁盘的什么位置,直接就可以对文件操作
文件系统的分类
- 本地磁盘文件系统
类Windows文件系统:盘符体系(D盘,E盘)NTFS类Unix文件系统: /目录 - 光盘文件系统
ISO镜像文件 - 网络文件系统
NFS: 使用网络来远程访问其他主机的文件,就像访问本机文件一样方便 - 分布式文件系统
1、分布式文件系统是由多态主机模拟出来的一个文件系统,文件是分散存储在不同的主机上2、分布式文件系统有很多种:1)、GFSGFS(Google File System)是Google公司为满足公司需求而开发的基于Linux的可扩展的分布式文件系统,用于大型的、分布式的、对大数据进行访问和应用,成本低,应用于廉价的普通硬件上,但不开源,暂不考虑。2)、TFSTFS(Taobao File System)是阿里巴巴为满足了淘宝对小文件存储的需求而开发的一个可扩展、高可用、高性能、面向互联网服务、开源的分布式文件系统,主要针对海量的非结构化数据,它构筑在普通的Linux机器集群上,可为外部提供高可靠和高并发的存储访问。TFS为淘宝提供海量小文件存储,通常文件大小不超过1M,这个也暂不考虑。3)、HDFSHDFS(Hadoop Distributed File System)。Hadoop分布式文件系统,适合运行在通用硬件上做分布式存储和计算,因为它具有高容错性和可扩展性的特点,可部署在廉价的机器上,适合大数据的处理,在离线批量处理大数据上有先天的优势。Hadoop是Apache Lucene创始人Doug Cutting开发的使用广泛的文本搜索库。它起源于Apache Nutch,后者是一个开源的网络搜索引擎,本身也是Luene项目的一部分。Aapche Hadoop架构是MapReduce算法的一种开源应用,是Google开创其帝国的重要基石。4)、MooseFSMooseFS 是来自波兰的开源且具备冗余容错功能的分布式 POSIX 文件系统,也是参照了 GFS 的架构,实现了绝大部分 POSIX 语义和 API,它支持通过FUSE方式将文件挂载操作,同时其提供的web管理界面非常方便查看当前的文件存储状态,对master服务器有单点依赖,用perl编写,用于中、大型文件应用,但性能相对较差,由于可能会实时访问所以暂不考虑。备注:POSIX表示可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX ),POSIX标准定义了操作系统应该为应用程序提供的接口标准5)、FastDFS由淘宝的余庆先生所开发的一个开源分布式文件系统。它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。适合以文件为载体的在线服务,如相册网站、视频网站等等。FastDFS为互联网量身定制,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标,使用FastDFS搭建一套高性能的文件服务器集群提供文件上传、下载等服务。但是FastDFS部署有点麻烦,且它的SKD是不全的。6)、MogileFSMogileFS是一套高效开源的文件自动备份组件,由Six Apart开发,广泛应用在包括LiveJournal等web2.0站点上。支持多节点冗余,可实现自动的文件复制。不需要RAID,应用层可以直接实现RAID,不共享任何东西,通过集群接口提供服务工作于应用层,没有特殊的组件要求。使用HTTP方式通信。7)、GridFSMongoDB是一种知名的NoSql数据库,GridFS是MongoDB的一个内置功能,它用于存储和恢复那些超过16M(BSON文件限制)的文件(如:图片、音频、视频等),是文件存储的一种方式,但是它是存储在MonoDB的集合中。它可以直接利用已建立的复制或分片机制,所以对于文件存储来说故障恢复和扩展都容易,且GridFS不产生磁盘碎片。8)、MinIOMinIO 是一个基于Apache License v2.0开源协议的对象存储服务。它兼容亚马逊S3云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小,从几kb到最大5T不等。它也是一个非常轻量的服务,可以很简单的和其他应用的结合。MinIO的特色在于简单、轻量级,对开发者友好,学习成本低,安装运维简单,开箱即用。9)、SeaweedFSSeaweedFS是基于go语言开发高度可扩展开源的分布式存储系统,能存储数十亿文件(最终受制于你的硬盘大小)、并且速度快,内存占用小。上手使用比fastDFS要简单很多,自带Rest API。对于中小型文件效率非常高,但是单卷最大容量被程序限制到30G,建议存储文件以100MB以内为主。10)、CephCeph是Red Hat旗下一个成熟的分布式文件系统,而且还是一个有企业级功能的对象存储生态环境。该系统具备高性能、高可用性、高可扩展性、实时存储性等特点。虽然ceph很强大,但是学习成本高、安装运维复杂。Ceph用C++编写,存储容量可轻松达到PB级别。11)、GlusterFSGlusterFS 是由美国的 Gluster 公司开发的 POSIX 分布式文件系统(以 GPL 开源),它主要应用在集群系统中,具有高扩展性、高可用性、高性能、可横向扩展等特点,并且其没有元数据服务器的设计,让整个服务没有单点故障的隐患。该系统主要是为中大型文件设计的,存储容量可轻松达到PB。它存在扩容缩容影响服务器较多、遍历目录下文件耗时、小文件性能较差的缺点。
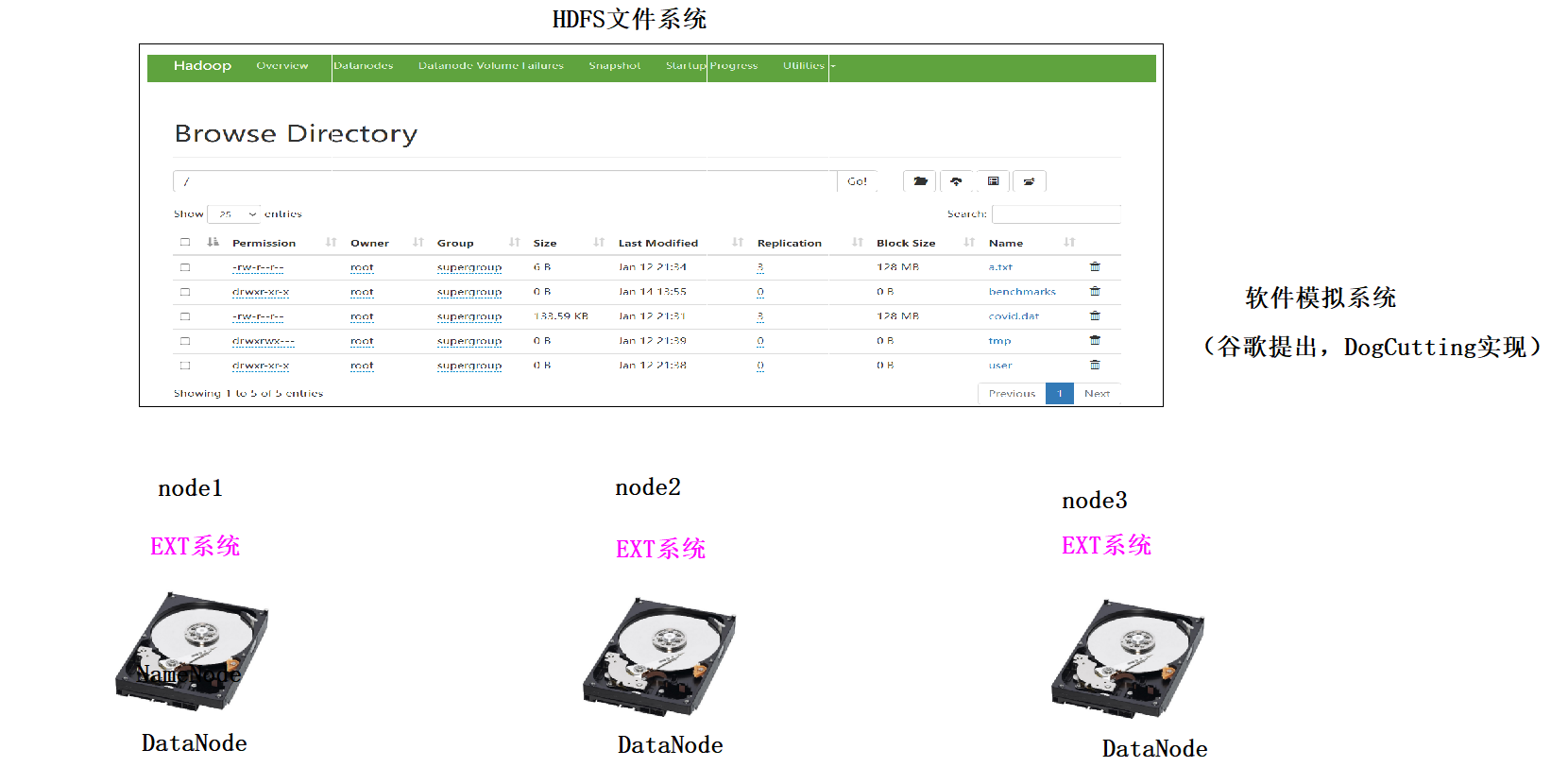
HDFS如何解决海量数据问题
存储方式
1、传统单机存储是纵向扩展存储空间(不断加硬盘),这种扩展是有限的
2、分布式存储是横向扩展存储空间(不断加主机),这种扩展几乎是无限的
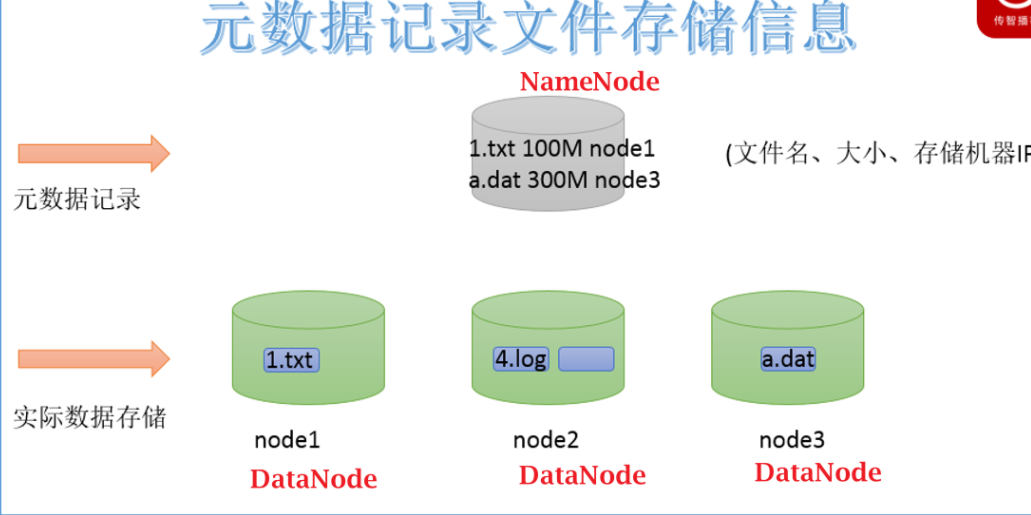
文件查询问题
NameNode: 存储HDFS的文件的元数据,NodeName工作时,这些元数据会被加载到内存中,同时也会被持久化存储到硬盘上
#元数据:类似派出所的户籍信息,描述文件除内容之外的额数据(文件的权限,大小,存储路径,Block信息)
DataNode: 具体存储文件数据的,这些数据最后分散在不同主机的硬盘上
HDFS的简介
1、HDFS(Hadoop Distributed File System) 是Hadoop分布式文件系统
2、HDFS主要是存储TB和PB,EB级别文件
3、HDFS上存储的文件只能追加写入(在尾部加入内容),不能随机修改(在中间修改),HDFS除了最后一个Bock之外,前边的所有的Block一旦定型,永远不能修改
4、HDFS的读写速度有延迟,不能保证实时,如果你对时效性要求比较高,则不要使用HDFS
5、HDFS适合存储大文件,不适合存储小文件:
5.1)一个文件,不管大小,都会占用一条元数据,一条元数据大概是150字节
5.2)在工作时,元数据是保存在NameNode主机的内存中,内存如果有限的情况下,保存的元数据数量也是有限的,NameNode主机内存固定的情况下,能存多少条元数据是固定的
5.3)如果你存储太多的小文件,这些小文件会占用大量的元数据,会占用namenode大量的内存空间,会导致 NameNode内存空间不够用的问题。
6、由于HDFS强调的是集群整体的性能,单机的性能可以很弱,机器可以很廉价(蚂蚁多了,力量也很强大)
HDFS的切片问题
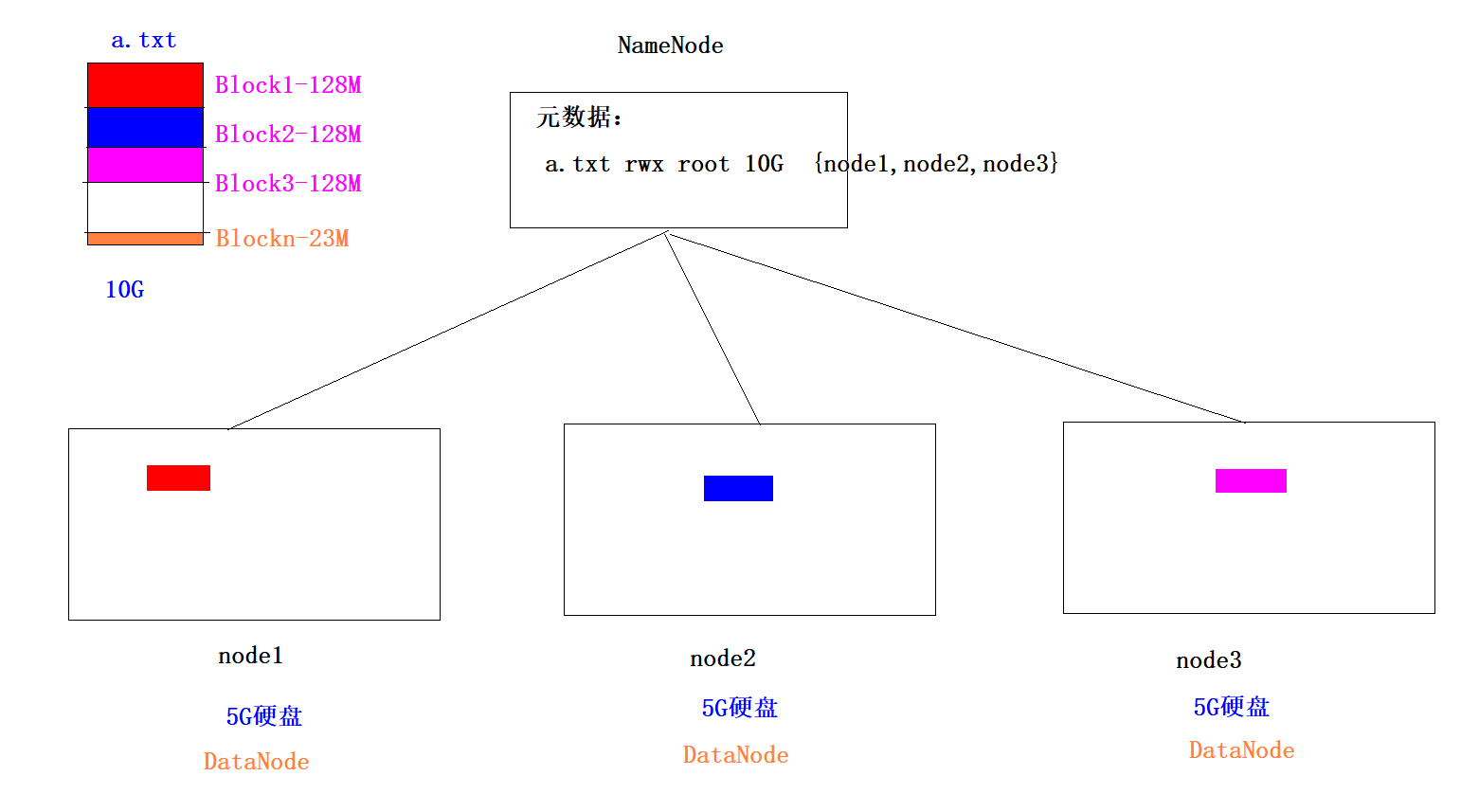
1、默认情况下,HDFS是以Block为单位进行存储,每一个Block最大是128M,如果一个文件不足128M,则默认也是一个Block,所以Block是一个逻辑单位
2、举例:1.txt 300M
Block1 128M
Block2 128M
Block3 44M
3、我们可以去修改每个Block的大小:dfs.blocksize 134217728 字节 在hdfs-site.xml中做如下配置:
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
在node1修改完之后,要将这个配置文件分发给node2和node3,然后重启hadoop
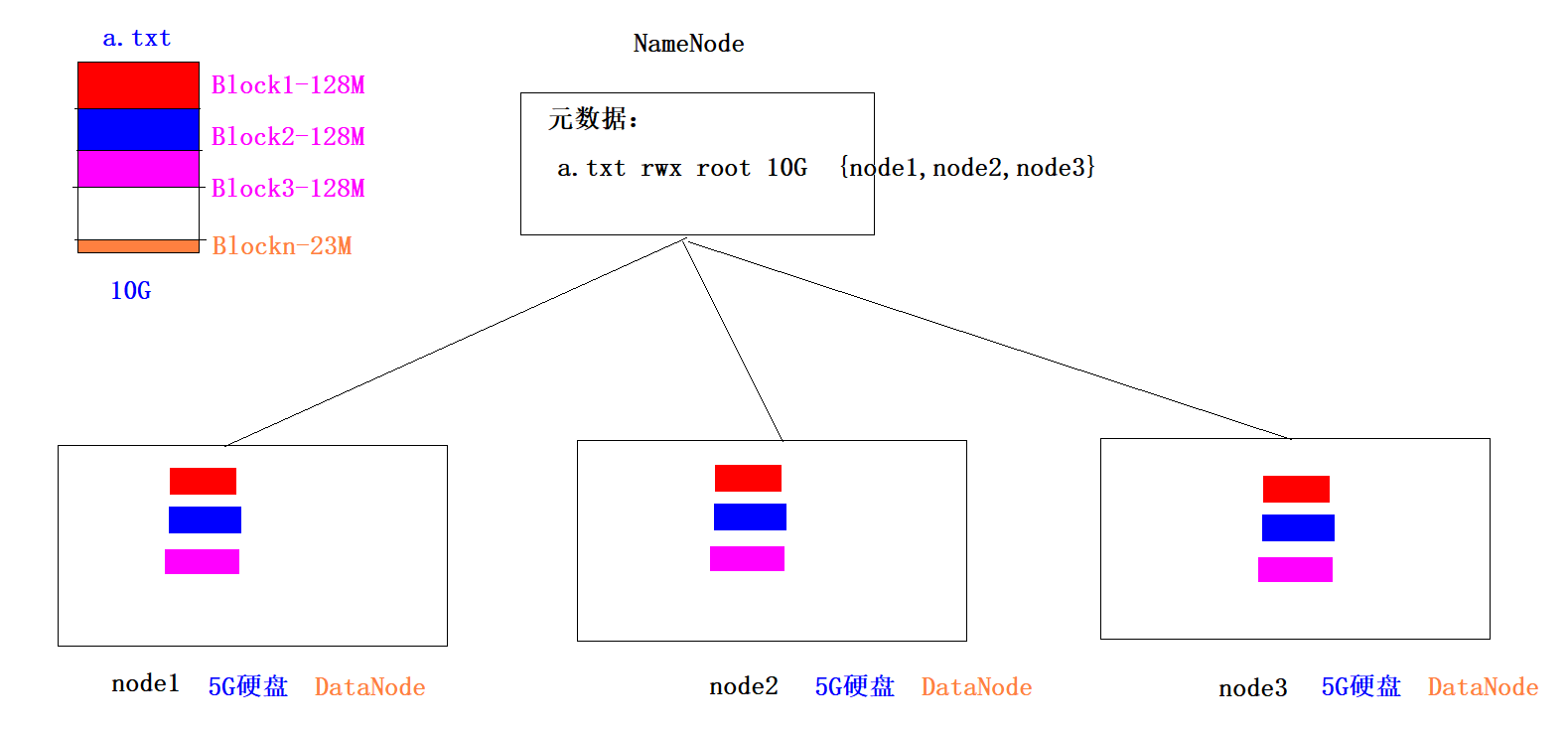
HDFS如何解决数据丢失问题-副本机制
1、每一个Block切片都会存储多个副本(默认是3个)
2、副本机制就是通过牺牲空间来换取数据的安全可靠性
3、我们可以通过dfs.replication参数来修改副本数量,在hdfs-site.xml中做如下配置:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
在node1修改完之后,要将这个配置文件分发给node2和node3,然后重启hadoop
#在Linux如何造一个任意大小的测试文件
dd if=/dev/zero of=my_file bs=1M count=300 #300M文件
dd if=/dev/zero of=my_file bs=1G count=1 #1G文件
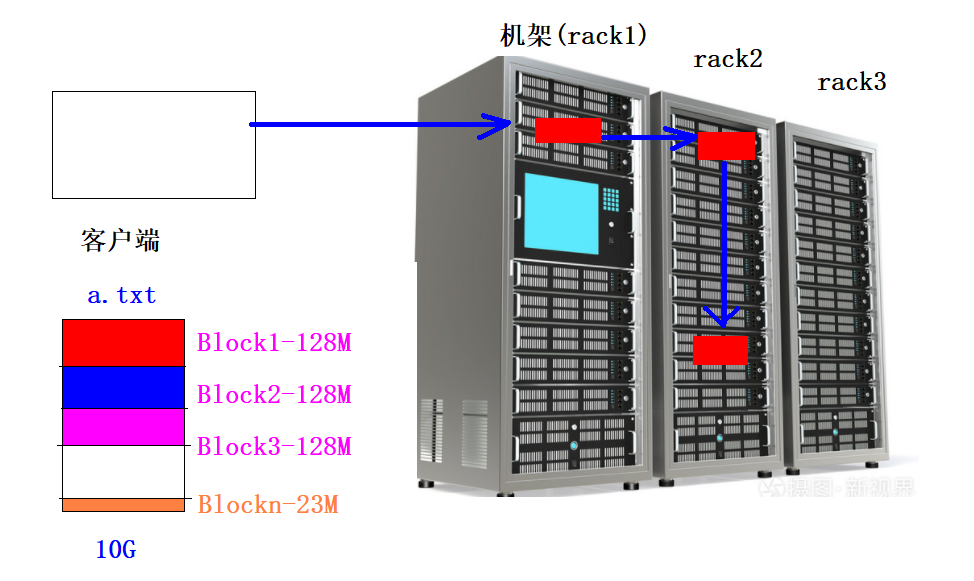
HDFS的机架感知
- 概念
1、一个Block默认有3个副本,当存一个BLock的时候,每一个副本应该存放到哪一台主机有一定的策略,这个策略就被称为机架感知/** * The class is responsible for choosing the desired number of targets * for placing block replicas. * The replica placement strategy is that if the writer is on a datanode, * the 1st replica is placed on the local machine, * otherwise a random datanode. The 2nd replica is placed on a datanode * that is on a different rack. The 3rd replica is placed on a datanode * which is on a different node of the rack as the second replica. */@InterfaceAudience.Privatepublic class BlockPlacementPolicyDefault extends BlockPlacementPolicy {2、机架感知策略 第一个副本如果客户端就是集群内部的某台主机,则第一个副本直接本地存储放在客户端主机上,否则随机选择一台主机 第二个副本放在和第一个副本不同的机架上 第三个副本放在和第二个副本同一个机架不同主机上
HDFS文件如何让用户访问-名称空间
1、为了让客户不去关心HDFS文件复杂的元数据管理,我们只需要给用户暴露一个唯一的目录树结构的访问路径鸡即可,这个被称为名称空间。
访问的主机本身就在集群内部:/benchmarks/TestDFSIO/io_data/test_io_0
访问的主机本身就在集群外部:hdfs://node1:8020/benchmarks/TestDFSIO/io_data/test_io_0
2、HDFS的路径和Linux主机的本地路径没有关系
HDFS的元数据
1、元数据是描述文件特征的数据,不是文件内容
2、元数据包含的信息:
2.1)文件自身属性信息
文件名称、权限,修改时间,文件大小,副本数,Block大小。
-rw-r--r-- root supergroup 6 B Jan 12 21:34 3 128 MB a.txt
2.2) 文件块位置映射信息
记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。
a.txt 300M
------------------------------
{
blk1:node2,node1,node3
blk2:node3,node1,node2
blk3:node1,node2,node3
}
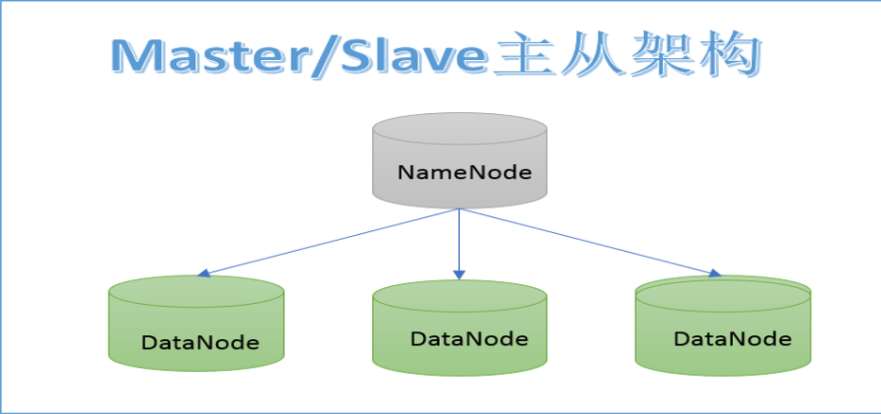
HDFS的架构
NameNode:
1、存储HDFS的文件的元数据,NodeName工作时,这些元数据会被加载到内存中,同时也会被持久化存储到硬盘
2、NameNode接受客户端读写请求,因为NameNode知道每一个文件都存在哪个DataNode上
3、NameNode接受各个DataNode的心跳信息、Block汇报信息、资源使用情况(硬盘)
4、如果NameNode一旦挂掉,整个集群将不能工作
DataNode:
1、存具体的文件数据
2、定时向NameNode汇报心跳信息、Block汇报信息、资源使用情况
3、如果某个DataNode挂掉,只要丢失Block的信息其他主机有,则不影响集群运行
HDFS的Shell命令
介绍
1、HDFS的网页页面在2.x版本时是没有任何操作菜单,只能查看,则必须使用Shell命令来操作
2、学习HDFS的Shell命令可以在不查看页面的情况下对HDFS上的文件进行增删改查
语法
hadoop fs 参数 #该方式可以操作任何文件系统:磁盘文件系统、HDFS文件系统
hdfs dfs 参数 #该方式只能操作HDFS文件系统
操作
#1、查看指定路径的当前目录结构
hadoop fs -ls /
hdfs dfs -ls /
#2、递归查看指定路径的目录结构
hadoop fs -lsr / #已淘汰
hadoop fs -ls -R / #用这个#3、查看目录下文件的大小
hadoop fs -du -h /
#4、文件移动(HDFS之间)
hadoop fs -mv /a.txt /dir1
#5、文件复制(HDFS之间)
hadoop fs -cp /dir1/a.txt /dir1/b.txt
#6、删除操作 !!!!!!!!!!!!!!!!!!
hadoop fs -rm /dir1/b.txt #删文件
hadoop fs -rm -r /dir1 #删目录 #7、文件上传(本地文件系统到HDFS文件系统) --- 复制操作 !!!!!!!!!!!!
hadoop fs -put a.txt /dir1
#8、文件上传(本地文件系统到HDFS文件系统) --- 剪切操作
hadoop fs -moveFromLocal test1.txt /
#8、文件下载(HDFS文件系统到本地文件系统) !!!!!!!!!!!
hadoop fs -get /aaa.txt /root
#9、文件下载(HDFS文件系统到本地文件系统)
hadoop fs -getmerge /dir/*.txt /root/123.txt
#10、将小文件进行合并,然后上传到HDFS
hadoop fs -appendToFile *.txt /hello.txt
hadoop fs -appendToFile 1.txt 2.txt 3.txt /hello.txt
hadoop fs -appendToFile /root/* /hello.txt
#11、查看HDFS文件内容
hadoop fs -cat /dir1/1.txt
#12、在HDFS创建文件夹 !!!!!!!!!!!!
hadoop fs -mkdir /my_dir
#13、修改HDFS文件的权限
hadoop fs -chmod -R 777 /dir1
#14、修改HDFS的所属用户和用户组useradd hadoop
passwd hadoop
hadoop fs -chown -R hadoop:hadoop /dir
回收站配置
#在每个节点的core-site.xml上配置为1天,1天之后,回收站的资源自动<property><name>fs.trash.interval</name><value>1440</value><description>minutes between trash checkpoints</description></property>#需要重启Hadoop
HDFS的安全模式
- 介绍
1、在HDFS启动时,HDFS会自动的进入安全模式,在该模式下进行Block数量的检测和自我修复,当BLock数量完整率达到99.9%时,会自动的离开安全模式2、安全模式停留多长时间不固定,你的Block数量越多,检测的时间越长,安全模式停留时间越长3、在安全模式状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。 - 操作命令
hdfs dfsadmin -safemode get #查看安全模式状态hdfs dfsadmin -safemode enter #进入安全模式hdfs dfsadmin -safemode leave #离开安全模式hdfs dfsadmin -safemode forceExit #强制离开安全模式
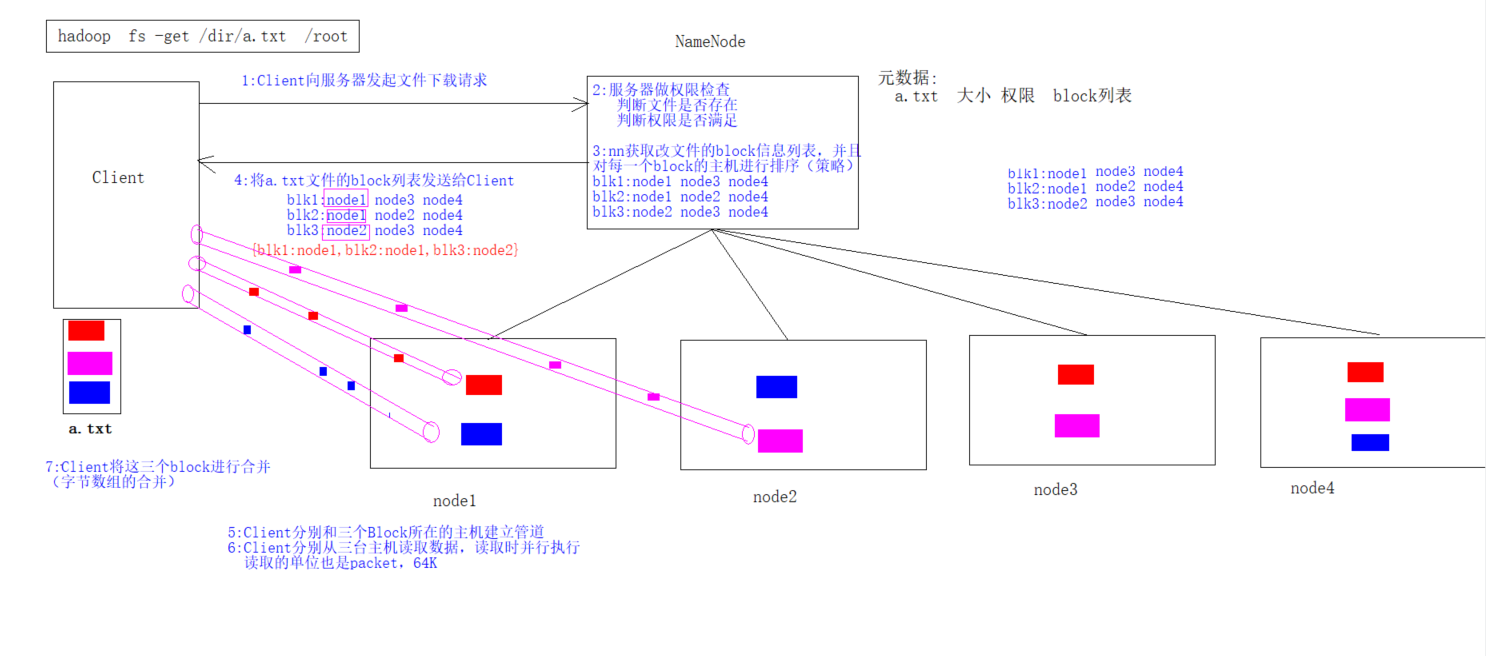
HDFS的读写流程
写入流程

读取流程
HDFS的元数据管理
- 原理
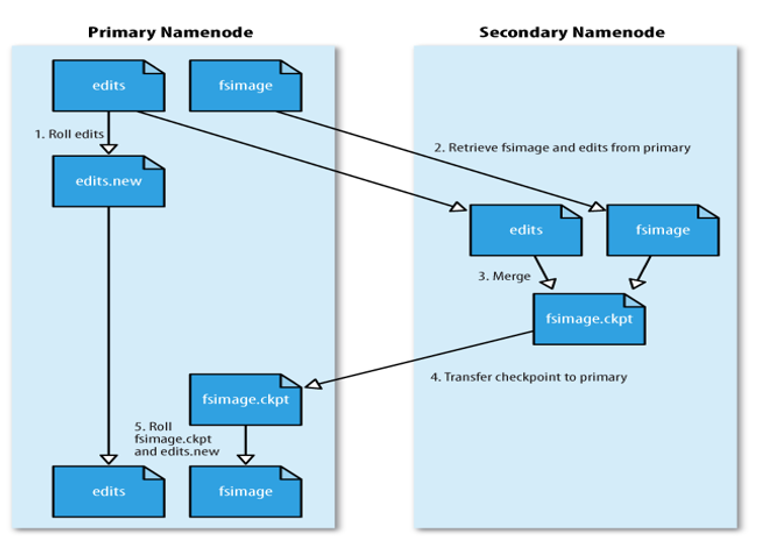
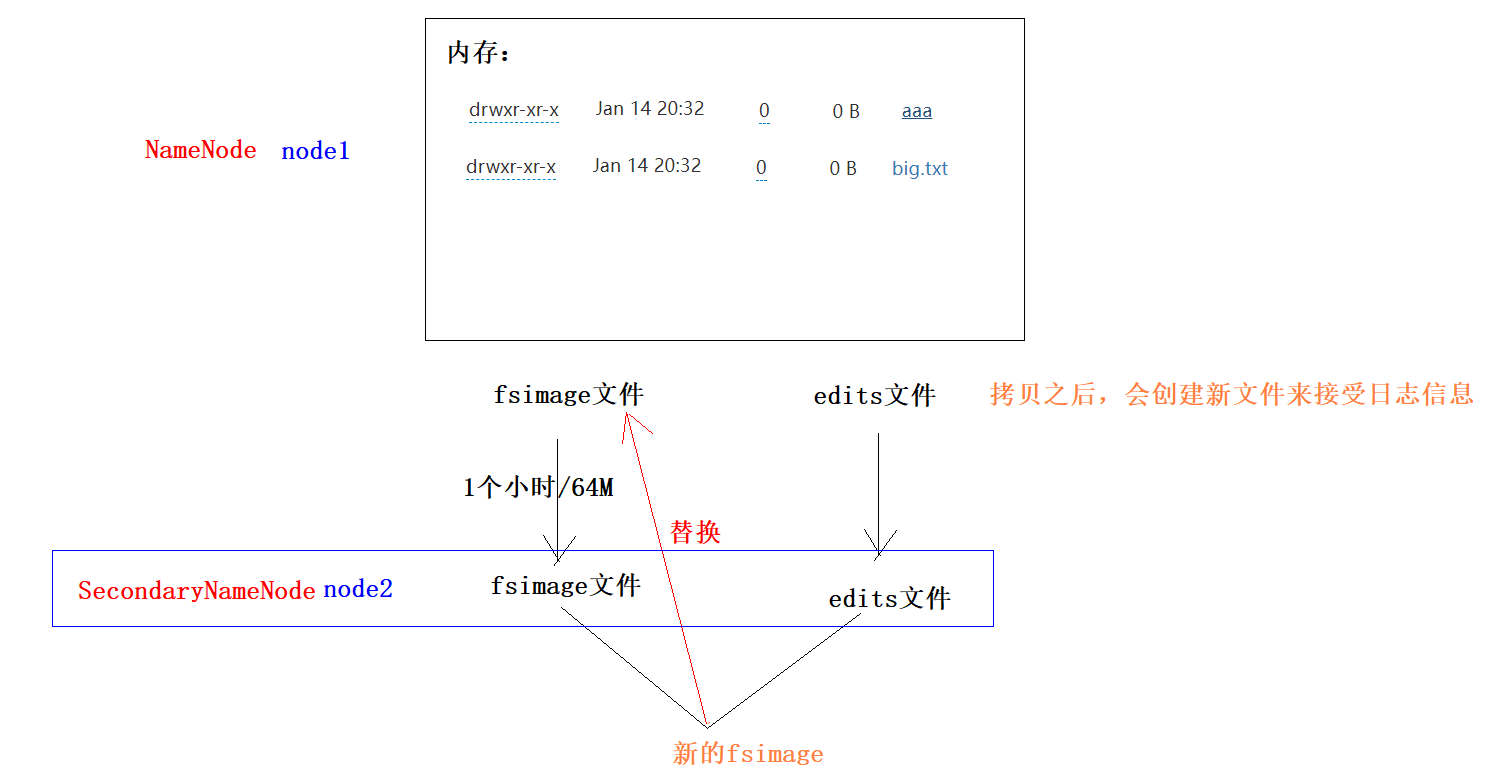
1)当触发checkpoint操作条件(每隔一个小时,或者edits文件达到64M)时,SNN发生请求给NN滚动edits log。然后NN会生成一个新的编辑日志文件:edits new,便于记录后续操作记录。
2)同时SNN会将edits文件和fsimage复制到本地(使用HTTP GET方式)。
3)SNN首先将fsimage载入到内存,然后一条一条地执行edits文件中的操作,使得内存中的fsimage不断更新,这个过程就是edits和fsimage文件合并。合并结束,SNN将内存中的数据dump生成一个新的fsimage文件。
3)SNN将新生成的Fsimage new文件复制到NN节点。
4)至此刚好是一个轮回,等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
- 查看日志文件内容
hdfs oev -i edits_0000000000000000011-0000000000000000025 -o edits.xml
HDFS的JavaAPI操作(重点)
- 介绍
使用Java提供的API来对HDFS上的文件进行增删查,相当于实现9870页面的鼠标操作和Shell命令操作 - 核心类
FileSystemConfiguration - 代码
packagepack01_hdfs;importorg.apache.commons.compress.utils.IOUtils;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.fs.*;importorg.junit.Test;importjava.io.File;importjava.io.FileInputStream;importjava.io.FileOutputStream;importjava.net.URI;importjava.net.URISyntaxException;importjava.util.Arrays;publicclassTest1HDFS{//文件的合并上传-方式2@Testpublicvoidtest9AppendToFile()throwsException{//1:获取FileSystem对象FileSystem fileSystem =FileSystem.get(newURI("hdfs://node1:8020"),newConfiguration());//2:获取HDFS目标文件的输出流-写FSDataOutputStream outputStream = fileSystem.create(newPath("/append2.txt"));//3:获取本地每一个小文件的输入流File file =newFile("E:\\input");File[] files = file.listFiles();for(File file1 : files){FileInputStream inputStream =newFileInputStream(file1);//4:实现文件的合并IOUtils.copy(inputStream,outputStream);IOUtils.closeQuietly(inputStream);}//5:关流IOUtils.closeQuietly(outputStream);}//文件的合并上传-方式1@Testpublicvoidtest8AppendToFile()throwsException{//1:获取FileSystem对象FileSystem fileSystem =FileSystem.get(newURI("hdfs://node1:8020"),newConfiguration());//2:获取HDFS目标文件的输出流-写FSDataOutputStream outputStream = fileSystem.create(newPath("/append.txt"));//3:获取本地每一个小文件的输入流FileInputStream inputStream1 =newFileInputStream("E:\\input\\a.txt");FileInputStream inputStream2 =newFileInputStream("E:\\input\\b.txt");FileInputStream inputStream3 =newFileInputStream("E:\\input\\c.txt");//4:实现文件的合并IOUtils.copy(inputStream1,outputStream);IOUtils.copy(inputStream2,outputStream);IOUtils.copy(inputStream3,outputStream);//5:关流IOUtils.closeQuietly(inputStream3);IOUtils.closeQuietly(inputStream2);IOUtils.closeQuietly(inputStream1);IOUtils.closeQuietly(outputStream);}//文件的下载-方式2@Testpublicvoidtest7Upload()throwsException{//1:获取FileSystem对象FileSystem fileSystem =FileSystem.get(newURI("hdfs://node1:8020"),newConfiguration());//2:文件的上传 fileSystem.copyFromLocalFile(newPath("E:\\big.txt"),newPath("/bigg.txt"));}//文件的下载-方式2@Testpublicvoidtest6Download2()throwsException{//1:获取FileSystem对象FileSystem fileSystem =FileSystem.get(newURI("hdfs://node1:8020"),newConfiguration());//2:文件的下载 fileSystem.copyToLocalFile(newPath("/big.txt"),newPath("E:\\big2.txt"));}//文件的下载-方式1@Testpublicvoidtest5Download1()throwsException{//1:获取FileSystem对象FileSystem fileSystem =FileSystem.get(newURI("hdfs://node1:8020"),newConfiguration());//2:获取HDFS文件的输入流-读FSDataInputStream inputStream = fileSystem.open(newPath("/big.txt"));//3:获取目标文件的输出流-写FileOutputStream outputStream =newFileOutputStream("E:\\big.txt");/* //4:完成文件的复制 byte[] bytes = new byte[1024]; while (true){ int len = inputStream.read(bytes); if(len == -1){ break; } outputStream.write(bytes,0,len); } //5:关流 outputStream.close(); inputStream.close(); *///4:完成文件的复制IOUtils.copy(inputStream,outputStream);//5:关流IOUtils.closeQuietly(inputStream);IOUtils.closeQuietly(outputStream);}//从HDFS删除文件@Testpublicvoidtest4Delete()throwsException{//1:获取FileSystem对象FileSystem fileSystem =FileSystem.get(newURI("hdfs://node1:8020"),newConfiguration());//2:从HDFS删除文件 fileSystem.delete(newPath("/itcast"),true);}//在HDFS上创建目录(递归创建)@Testpublicvoidtest3Mkdir()throwsException{//1:获取FileSystem对象FileSystem fileSystem =FileSystem.get(newURI("hdfs://node1:8020"),newConfiguration());//2:在HDFS创建目录 fileSystem.mkdirs(newPath("/itcast/ky7/hdfs"));}//遍历HDFS的文件信息@Testpublicvoidtest2ListFiles()throwsException{//1:获取FileSystem对象FileSystem fileSystem =FileSystem.get(newURI("hdfs://node1:8020"),newConfiguration());//2:获取指定目录下的所有文件元数据信息RemoteIterator<LocatedFileStatus> iterator = fileSystem.listFiles(newPath("/"),true);//3:遍历集合while(iterator.hasNext()){//4、获取每一个文件的元数据信息LocatedFileStatus fileStatus = iterator.next();//5、打印每一个文件的元数据信息-文件绝对路径System.out.print(fileStatus.getPath());//6、Block信息//6.1 获取每一个BLock信息BlockLocation[] blockLocations = fileStatus.getBlockLocations();System.out.println("----"+blockLocations.length);//输出每个文件的Block数 3for(BlockLocation blockLocation : blockLocations){//6.2获取每一个Block的副本存储主机位置String[] hosts = blockLocation.getHosts();System.out.println(Arrays.toString(hosts));}}}@Testpublicvoidtest1GetFileSytem()throwsException{FileSystem fileSystem =FileSystem.get(newURI("hdfs://node1:8020"),newConfiguration());System.out.println(fileSystem);}}
HDFS的远程拷贝命令
- 集群内部拷贝
#推数据scp -r /root/test/ [email protected]:/root/#拉数据scp [email protected]:/root/test.txt /root/test.txt - 集群之间拷贝
hadoop distcp hdfs://node1:8020/a.txt hdfs://hadoop1:8020/
HDFS的归档机制(面试题)
- 介绍
如果HDFS上有很多的小文件,会占用大量的NameNode元数据的内存空间,需要将这些小文件进行归档(打包),归档之后,相当于将多个文件合成一个文件,而且归档之后,还可以透明的访问其中的每一个文件 - 操作
#数据准备hadoop fs -mkdir /confighadoop fs -put /export/server/hadoop-3.3.0/etc/hadoop/*.xml /config#创建归档文件hadoop archive -archiveName test.har -p /config /outputdirhadoop fs -rm -r /config#查看合并后的小文件全部内容 hadoop fs -cat /outputdir/test.har/part-0#查看归档中每一个小文件的名字 hadoop fs -ls har://hdfs-node1:8020/outputdir/test.har#查看归档中其中的一个小文件内容hadoop fs -cat har:///outputdir/test.har/core-site.xml#还原归档文件hadoop fs -mkdir /confighadoop fs -cp har:///outputdir/test.har/* /config - 注意点
1. Hadoop archives是特殊的档案格式。一个Hadoop archive对应一个文件系统目录。Hadoop archive的扩展名是*.har;2. 创建archives本质是运行一个Map/Reduce任务,所以应该在Hadoop集群上运行创建档案的命令,要提前启动Yarn集群; 3. 创建archive文件要消耗和原文件一样多的硬盘空间;4. archive文件不支持压缩,尽管archive文件看起来像已经被压缩过;5. archive文件一旦创建就无法改变,要修改的话,需要创建新的archive文件。事实上,一般不会再对存档后的文件进行修改,因为它们是定期存档的,比如每周或每日;6. 当创建archive时,源文件不会被更改或删除;
HDFS的权限问题
- 操作
hadoop fs -chmod 750 /user/itcast/foo //变更目录或文件的权限位
hadoop fs -chown :portal /user/itcast/foo // 变更目录或文件的所属用户
hadoop fs -chgrp itcast _group1 /user/itcast/foo //变更用户组
- 原理
1、HDFS的权限有一个总开关,在hdfs-site.xml中配置,只有该参数的值为true,则HDFS的权限才可以起作用 dfs.permissions.enabled #在Hadoop3.3.0中该值默认是 true - Java代码权限问题
//如果在通过JavaAPI来访问HDFS,遇到权限问题,有3中解决方案1、关闭HDFS权限的总开关,设置 dfs.permissions.enabled 为 false2、使用 hadoop fs -chmod -R777/tmp 修改权限3、使用root用户的身份去获取FileSystem对象 FileSystem fileSystem =FileSystem.get(newURI("hdfs://node1:8020"),newConfiguration(),"root");
HDFS的动态上下线
动态扩容
纵向扩容:加硬盘
横向扩容:加主机
- 介绍
1、当集群的存储容量达到上限时,我们可以通过添加主机的方式来扩展DataNode节点,来横向增加集群的存储空间2、我们在动态扩容时,不要一影响当前集群的正常工作 - 操作
==================1、基础环境配置====================1、从node1克隆一台主机:node42、修改node4的Mac地址、IP地址为164,主机名为node43、关闭node4的防火墙、安装JDK,关闭Selinux (已做)4、node1、node2、node3、node4要修改域名映射192.168.88.161 node1 node1.itcast.cn192.168.88.162 node2 node2.itcast.cn192.168.88.163 node3 node3.itcast.cn192.168.88.164 node4 node4.itcast.cn5、node1、node2、node3、node4重新构建免密登录5.1)在node4上,生成一个密钥对:ssh-keygen -t rsa5.2)在node4上,将node4的公钥发送给node1:ssh-copy-id node15.3)将node1上,将所有公钥发送给:node2,node3,node4 scp /root/.ssh/authorized_keys node2:/root/.ssh scp /root/.ssh/authorized_keys node3:/root/.ssh scp /root/.ssh/authorized_keys node4:/root/.ssh 6、在node4上,删除Hadoop的所有痕迹 6.1)删除Hadoop安装包: rm -fr /export/server/hadoop-3.3.0/ 6.2)删除Hadoop数据: rm -fr /export/data/hadoop-3.3.0/ 6.3)删除Hadoop的环境变量:vim /etc/profile==================1、Hadoop上线核心配置====================7、在node1上修改namenode(node1)节点workers配置文件,增加新节点主机名 vim /export/server/hadoop-3.3.0/etc/hadoop/workers node1 node2 node3 node48、在node1上,将Hadoop分发给node4 scp -r /export/server/hadoop-3.3.0 node4:/export/server9、在node4上,新机器上配置hadoop环境变量vim /etc/profileexport HADOOP_HOME=/export/server/hadoop-3.3.0export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin最后:source /etc/profile10、在node4上启动datanodehdfs --daemon start datanode11、通过页面查看http://node1:9870/dfshealth.html#tab-datanode#---------------设置负载均衡---------------#设置在负载均衡期间DataNode在数据搬移时,能够使用的最大带宽(100M)hdfs dfsadmin -setBalancerBandwidth 104857600#当不同主机之间存储的比率超过5%时,会自动进行负载均衡操作hdfs balancer -threshold 5
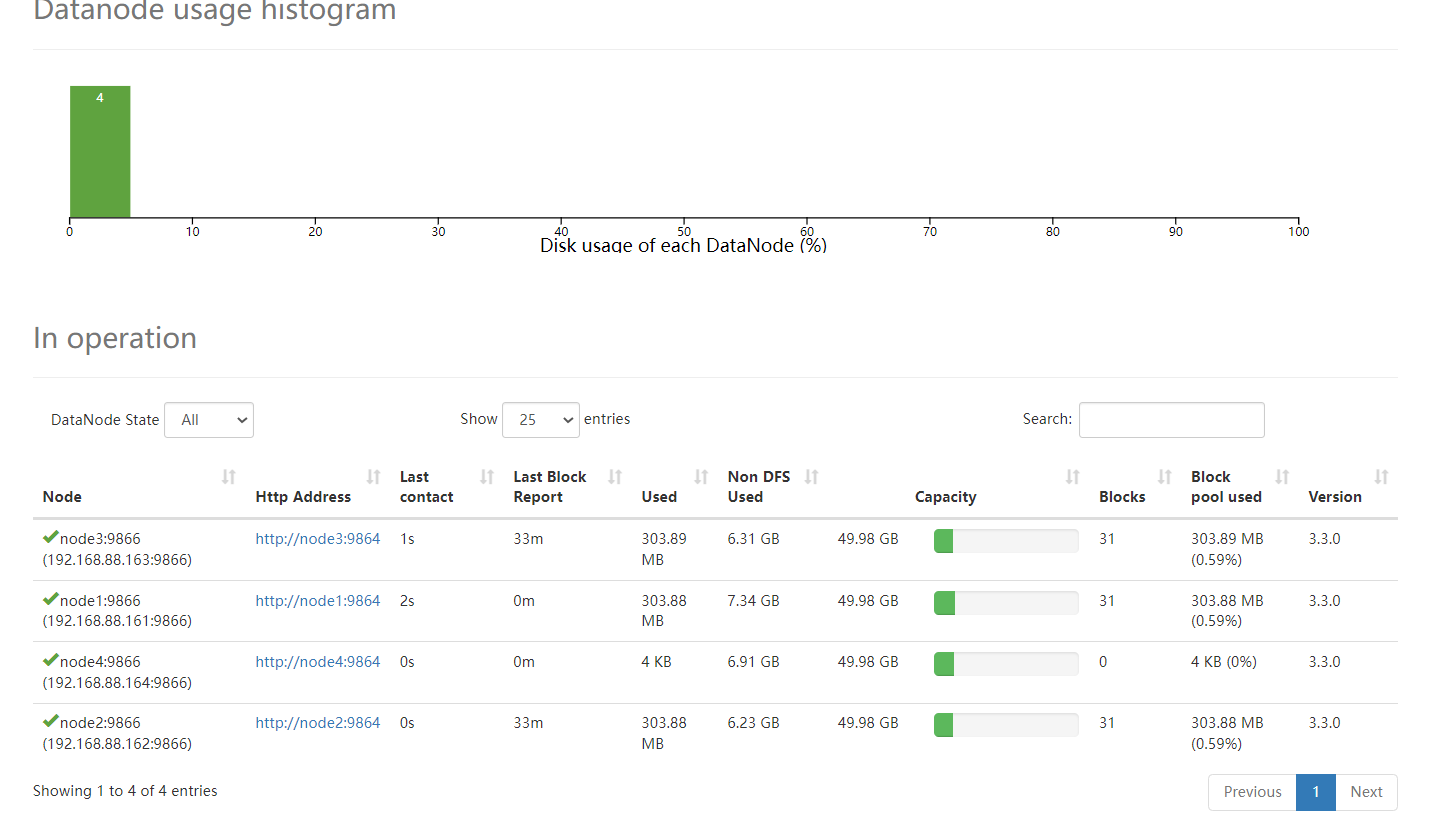
动态缩容
1、在node1上,保证你的hdfs-site.xml文件中有以下黑名单配置
<property>
<name>dfs.hosts.exclude</name>
<value>/export/server/hadoop-3.3.0/etc/hadoop/excludes</value>
</property>
2、在node1上,将你要退役的主机的主机名加入黑名单,编辑以下文件,加入node4
vim /export/server/hadoop-3.3.0/etc/hadoop/excludes
3、在ndoe1上,刷新集群
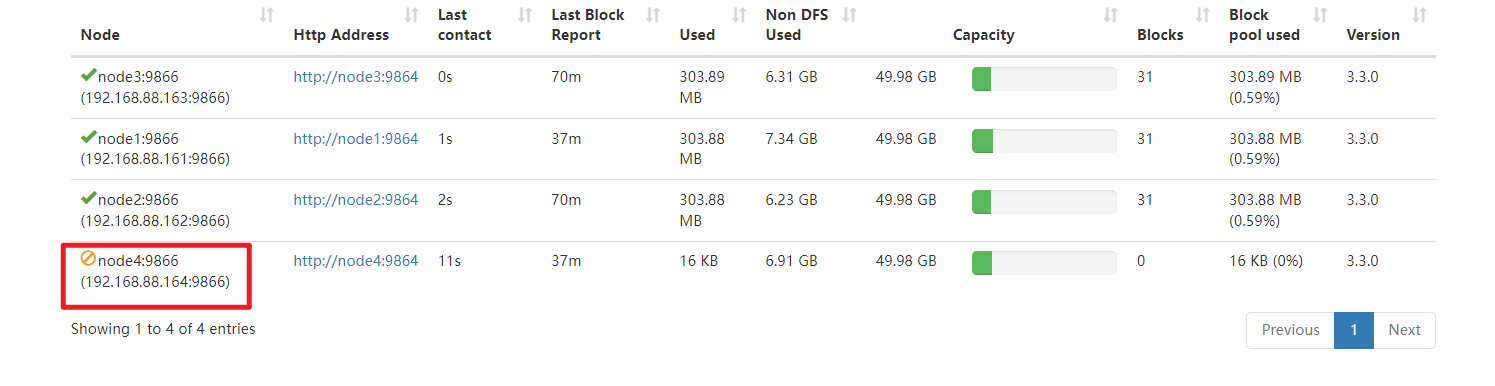
hdfs dfsadmin -refreshNodes
4、通过datanode页面查看node4的退役状态
http://node1:9870/dfshealth.html#tab-datanode
#---------------设置负载均衡---------------
#设置在负载均衡期间DataNode在数据搬移时,能够使用的最大带宽(100M)
hdfs dfsadmin -setBalancerBandwidth 104857600
#当不同主机之间存储的比率超过5%时,会自动进行负载均衡操作
hdfs balancer -threshold 5
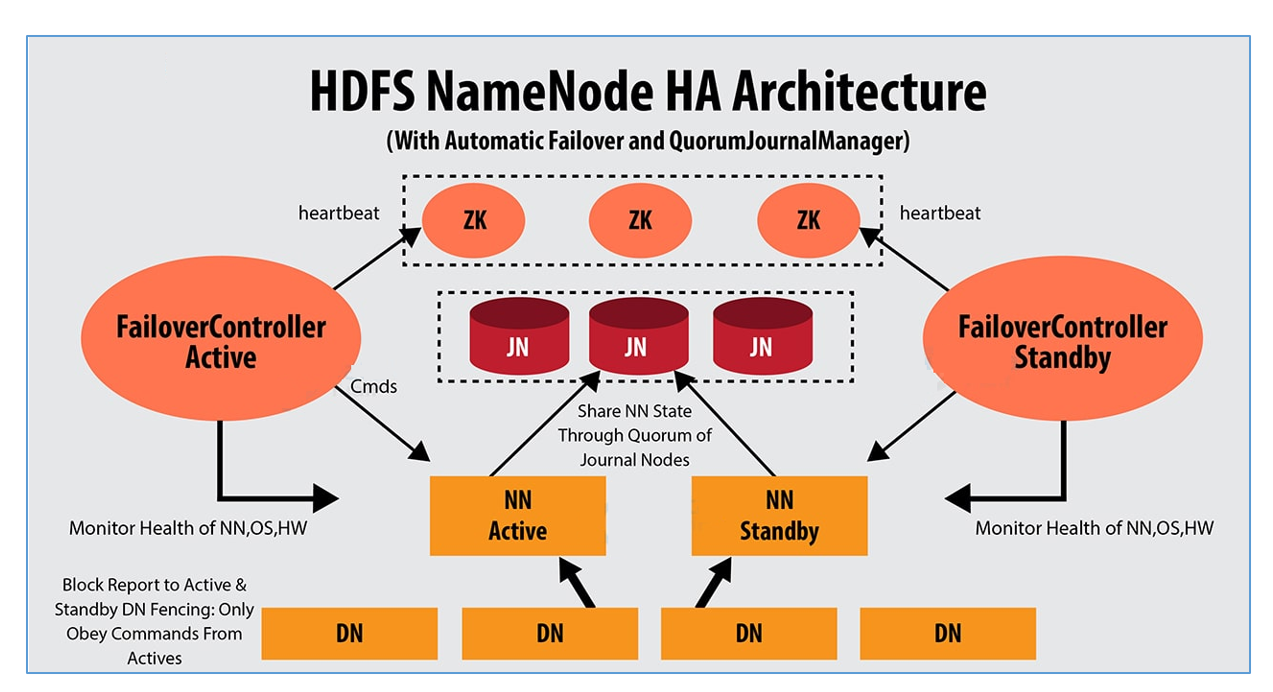
HDFS的高可用
介绍
1、HDFS的高可用是由NameNode组成,一个是Active状态的NameNode,一个是Standby状态的NameNode
2、Journal Node集群两个NamNode之间元数据的同步,同步的数据是日志文件Edits,由NameNode自己完成fsimage文件的生成,没有SecondaryNameNode
3、两个NameNode的主备切换,是由ZKFC和Zookeeper集群共同来完成
3.1 正常情况下由ZKFC来监控 Active NameNode的健康状态,一旦发现主NameNode健康不良,则立刻通知Zookeeper,Zookeeper会通知备ZKFC,然后备ZKFC会改变备NameNode状态由Standby改为Active,备NameNode成为新的主节点
脑裂问题
- 原因
由于极端情况下,主NameNode发生了假死现象,临时假死,后来又复活,这样原来的主NameNode状态是Active,后来的备用NameNode状态也改为Active,这样就会有两个Active状态的NameNode,会造成元数据的管理混乱,就相当于一个大脑被拆分了。 - 解决方案
方案1:调用旧Active状态的RPC接口中的相关方法,将其状态由Active强制改为StandBy方案2:如果方案1没有实现,则ZK会远程登录到旧Active的NameNode主机上,将NameNode进程杀死
环境搭建
- 搭建方案

- 操作步骤- 1、备份单节点Hadoop
#在node1,node2,node3主机上,分别执行以下操作:mv /export/server/hadoop-3.3.0 /export/server/hadoop-3.3.0_bak- 2、解压Hadooptar -xvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz -C /export/server/- 3、配置环境变量(可以不做)#在node1,node2,node3主机上,分别执行以下操作:vim /etc/profileexportHADOOP_HOME=/export/server/hadoop-3.3.0exportPATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbinsource /etc/profile- 4、配置hadoop-env.sh文件cd /export/server/hadoop-3.3.0/etc/hadoopvim hadoop-env.shexportJAVA_HOME=/export/server/jdk1.8.0_241exportHDFS_NAMENODE_USER=rootexportHDFS_DATANODE_USER=rootexportHDFS_SECONDARYNAMENODE_USER=rootexportYARN_RESOURCEMANAGER_USER=rootexportYARN_NODEMANAGER_USER=rootexportHDFS_JOURNALNODE_USER=rootexportHDFS_ZKFC_USER=root- 5、core-site.xml<configuration><!-- HA集群名称,该值要和hdfs-site.xml中的配置保持一致 --><property><name>fs.defaultFS</name><value>hdfs://mycluster</value></property><!-- hadoop本地磁盘存放数据的公共目录 --><property><name>hadoop.tmp.dir</name><value>/export/data/ha-hadoop</value></property><!-- ZooKeeper集群的地址和端口--><property><name>ha.zookeeper.quorum</name><value>node1:2181,node2:2181,node3:2181</value></property></configuration>- 6、配置 hdfs-site.xml<configuration><!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致 --><property><name>dfs.nameservices</name><value>mycluster</value></property><!-- mycluster下面有两个NameNode,分别是nn1,nn2 --><property><name>dfs.ha.namenodes.mycluster</name><value>nn1,nn2</value></property><!-- nn1的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn1</name><value>node1:8020</value></property><!-- nn1的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn1</name><value>node1:9870</value></property><!-- nn2的RPC通信地址 --><property><name>dfs.namenode.rpc-address.mycluster.nn2</name><value>node2:8020</value></property><!-- nn2的http通信地址 --><property><name>dfs.namenode.http-address.mycluster.nn2</name><value>node2:9870</value></property><!-- 指定NameNode的edits元数据在JournalNode上的存放位置 --><property><name>dfs.namenode.shared.edits.dir</name><value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value></property><!-- 指定JournalNode在本地磁盘存放数据的位置 --><property><name>dfs.journalnode.edits.dir</name><value>/export/data/journaldata</value></property><!-- 开启NameNode失败自动切换 --><property><name>dfs.ha.automatic-failover.enabled</name><value>true</value></property><!-- 指定该集群出故障时,哪个实现类负责执行故障切换 --><property><name>dfs.client.failover.proxy.provider.mycluster</name><value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value></property><!-- 配置隔离机制方法--><property><name>dfs.ha.fencing.methods</name><value>sshfence</value></property><!-- 使用sshfence隔离机制时需要ssh免登陆 --><property><name>dfs.ha.fencing.ssh.private-key-files</name><value>/root/.ssh/id_rsa</value></property><!-- 配置sshfence隔离机制超时时间 --><property><name>dfs.ha.fencing.ssh.connect-timeout</name><value>30000</value></property></configuration>- 配置mapred-site.xml<configuration><!-- 指定mr框架为yarn方式 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value></property></configuration>- 配置yarn-site.xml<configuration><!-- 开启RM高可用 --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!-- 指定RM的cluster id --><property><name>yarn.resourcemanager.cluster-id</name><value>yrc</value></property><!-- 指定RM的名字 --><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><!-- 分别指定RM的地址 --><property><name>yarn.resourcemanager.hostname.rm1</name><value>node1</value></property><property><name>yarn.resourcemanager.hostname.rm2</name><value>node2</value></property><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>node1:8088</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>node2:8088</value></property><!-- 指定zk集群地址 --><property><name>yarn.resourcemanager.zk-address</name><value>node1:2181,node2:2181,node3:2181</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 是否将对容器实施物理内存限制 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><!-- 是否将对容器实施虚拟内存限制。 --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property></configuration>- 配置workersnode1node2node3- 分发cd /export/serverscp -r hadoop-3.3.0 root@node2:$PWDscp -r hadoop-3.3.0 root@node3:$PWD
启动集群
#为防止主备切换失败,在node1,node2,node3安装以下软件包,保证不会发生脑裂
yum install psmisc -y
HA集群的初始化(只在第一次执行)- 启动zk集群
#在node1,node2,node3分别执行以下的命令/export/server/zookeeper-3.4.6/bin/zkServer.sh start- 手动提前启动JN进程(node1 node2 node3分别启动)hdfs --daemon start journalnode- 初始化namenode#在node1初始化namenodehdfs namenode -format#把node1初始化的数据完整复制一份给node2 保证两个nn初始化状态及数据是一致的#hdfs namenode –bootstrapStandbyscp -r /export/data/ha-hadoop/ root@node2:/export/data/- 格式化ZKFC(在node1上执行即可)> 首次启动谁是active取决于在哪台机器执行该命令> > 相当于首次选举是用户指定谁是老大hdfs zkfc -formatZKHA集群的启动- 在node1上,启动hdfs集群
start-dfs.sh- 在node1上,启动yarn集群start-yarn.sh- 在node1上,启动历史任务mapred --daemon start historyserver后续启动和关闭
1、以上的启动至用于刚搭建完集群的第一次启动使用2、以后高可用集群的启动和关闭直接使用以下命令: start-all.sh stop-all.sh
验证
- 验证HDFS高可用
1、网页访问NameNodehttp://node1:9870/http://node2:9870/2、文件上传hadoop fs -put a.txt /3、杀死主NameNode,观察备用NameNode是否称为主节点 kill -9 9024 - 验证Yarn高可用
1、网页访问NameNodehttp://node1:8088/http://node2:8088/#1、查看两个ResourceManager的状态yarn rmadmin -getServiceState rm1 #activeyarn rmadmin -getServiceState rm2 #standby#2、在状态为active的主机中,杀死ResourceManager进程kill -9 ResourceManager进程号#3、查看ResourceManager状态yarn rmadmin -getServiceState rm1/rm2#4、求PI值hadoop jar /export/server/hadoop-3.3.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 2 10000#19888和8088的区别?8088页面: Yarn集群的信息 + 正在运行的任务 + 已经执行完成的任务19888页面: 已经执行完成的任务#8020和9870的区别?8020端口: 是HDFS客户端和NameNode之间的内部数据通信端口9870端口: 是浏览器和网页服务器之间的访问端口
如何还原单节点
1:在node1中
stop-all.sh
cd /export/server/
mv hadoop-3.3.0 hadoop-3.3.0_ha
mv hadoop-3.3.0_bak hadoop-3.3.0
2:在node2中
cd /export/server/
mv hadoop-3.3.0 hadoop-3.3.0_ha
mv hadoop-3.3.0_bak hadoop-3.3.0
3:在node3中
cd /export/server/
mv hadoop-3.3.0 hadoop-3.3.0_ha
mv hadoop-3.3.0_bak hadoop-3.3.0
4:在node1中
start-all.sh
#可以将之前动态添加的node4的信息删除
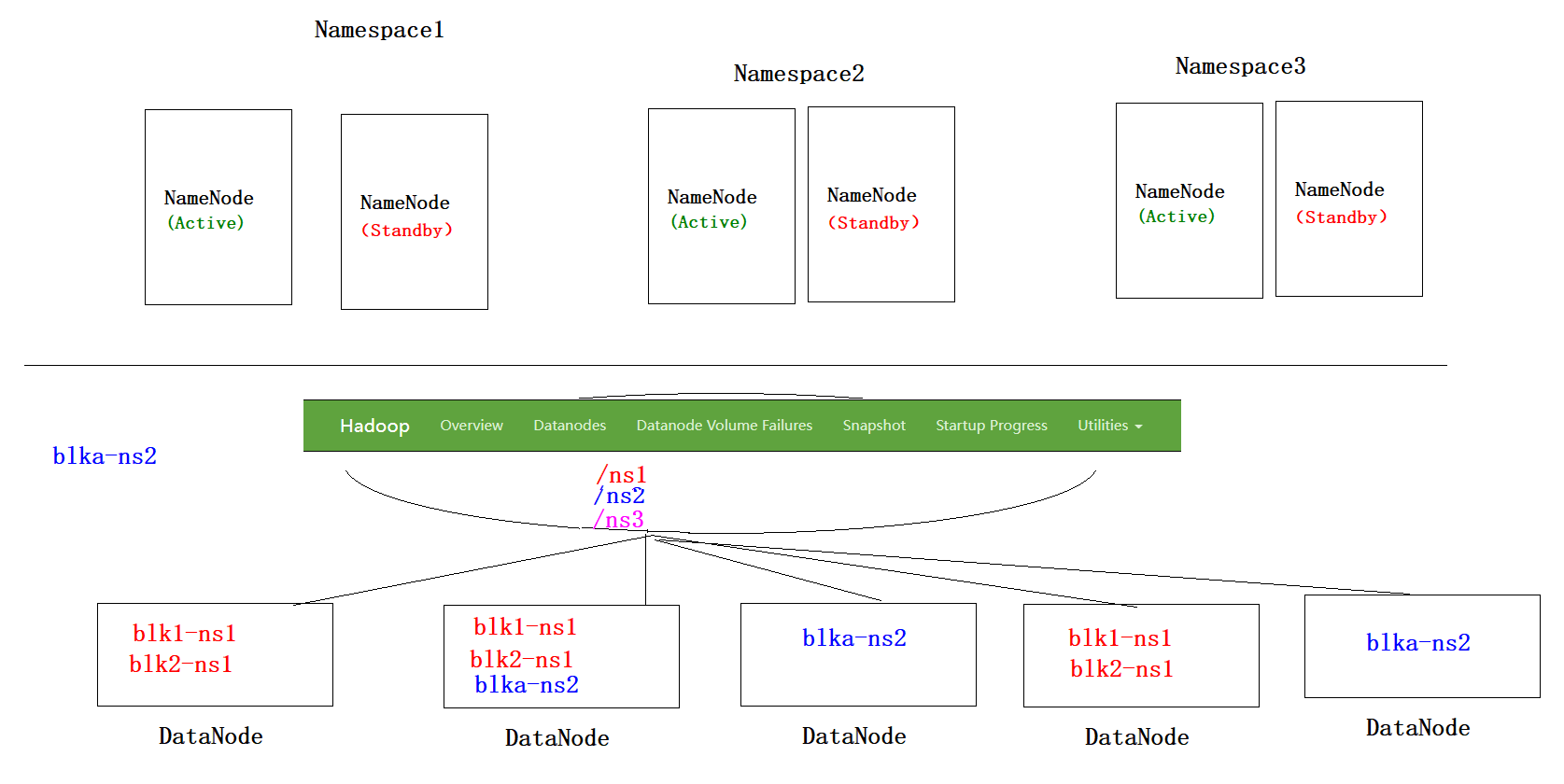
HA(高可用) + Federation*(联邦)
本文转载自: https://blog.csdn.net/manba_yqq/article/details/129412957
版权归原作者 纸留过往 所有, 如有侵权,请联系我们删除。
版权归原作者 纸留过往 所有, 如有侵权,请联系我们删除。