
文章目录
全文约 31372 字,预计阅读时长: 92分钟
项目描述
http协议被广泛使用,从移动端,pc端浏览器,http协议无疑是打开互联网应用窗口的重要协议,http在网络应用层中的地位不可撼动,是能准确区分前后台的重要协议。
目标:
对http协议(1.0)的理论学习,从零开始完成web服务器开发,坐拥下三层协议,从技术到应用,让网络难点无处遁形。
采用C(B:browser)/S模型,编写支持中小型应用的http,并结合mysql,理解常见互联网应用行为。做完该项目,可以从技术上完全理解从你上网开始,到关闭浏览器的所有操作中的技术细节。
技术特点:
网络编程(TCP/IP协议, socket流式套接字,http协议);多线程技术;cgi技术;线程池。开发环境:centos 7 + vim/gcc/gdb + C/C++。
Web与 http 发展史
万维网的发明:
1989 年,当时在 CERN 工作的 Tim Berners-Lee 博士写了一份关于建立一个通过网络传输超文本系统的报告。这个系统起初被命名为 Mesh,在随后的 1990 年项目实施期间被更名为万维网(World Wide Web)。它在现有的 TCP 和 IP 协议基础之上建立,由四个部分组成:
一个用来表示超文本文档的文本格式,超文本标记语言(HTML)。
一个用来交换超文本文档的简单协议,超文本传输协议(HTTP)。
一个显示(以及编辑)超文本文档的客户端,即网络浏览器。第一个网络浏览器被称为 WorldWideWeb。
一个服务器用于提供可访问的文档,即 httpd 的前身。
WWW也可以理解为访问互联网资源的一套生态:浏览器通过http(s)传输html,来访问服务器上的资源,服务器响应请求返回,浏览器渲染刷新。
Http发展史
DNS
DNS (Domain Name System) 域名系统,是一个层次化、分散化的 Internet 连接资源命名系统。DNS 维护着一个包含域名与对应资源例如IP 地址的列表。
DNS 最突出的功能是将易于记忆的域名 (例如 mozilla.org) 翻译成为数字化的 IP 地址 (例如 151.106.5.172)。这一从域名到 IP 地址的映射过程被称为DNS 查询 (DNS lookup),与之对应,**DNS 反向查询 (rDNS)**用来找到与 IP 地址对应的域名。浏览器自动帮助完成查询,也会自动填充端口号。
URI URL URN
- URN不常用:某种资源的命名。
- URI:全网内确认唯一性的资源。
- URL:既能确认资源的唯一性,还能确认资源的位置。

HTTP 概述
HTTP 是一种能够获取如 HTML 这样的网络资源的 protocol(通讯协议)。它是在 Web 上进行数据交换的基础,是一种 client-server 协议,也就是说,请求通常是由像浏览器这样的接受方发起的。一个完整的 Web 文档通常是由不同的子文档拼接而成的,像是文本、布局描述、图片、视频、脚本等等。
一个连接是由传输层来控制的,这从根本上不属于 HTTP 的范围。HTTP 并不需要其底层的传输层协议是面向连接的,只需要它是可靠的,或不丢失消息的(至少返回错误)。在互联网中,有两个最常用的传输层协议:TCP 是可靠的,而 UDP 不是。因此,HTTP 依赖于面向连接的 TCP 进行消息传递,但连接并不是必须的。
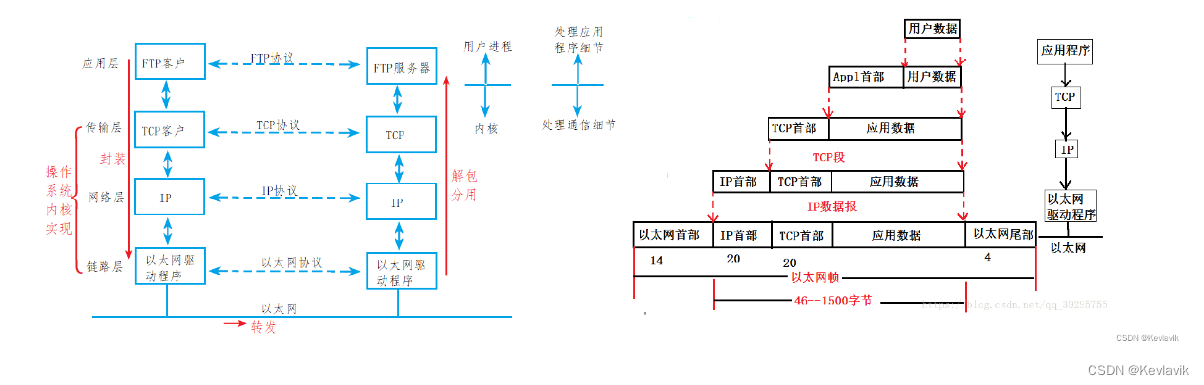
在客户端(通常指浏览器)与服务器能够交互(客户端发起请求,服务器返回响应)之前,必须在这两者间建立一个 TCP 链接,打开一个 TCP 连接需要多次往返交换消息(因此耗时)。HTTP/1.0 默认为每一对 HTTP 请求/响应都打开一个单独的 TCP 连接(短连接)。当需要连续发起多个请求时,这种模式比多个请求共享同一个 TCP 链接更低效。短连接:请求,响应,关闭连接。
为了减轻这些缺陷,HTTP/1.1 引入了流水线(被证明难以实现)和持久连接的概念:底层的 TCP 连接可以通过Connection头部来被部分控制。HTTP/2 则发展得更远,通过在一个连接复用消息的方式来让这个连接始终保持为暖连接。
当 HTTP 流水线启动时,后续请求都可以不用等待第一个请求的成功响应就被发送。然而 HTTP 流水线已被证明很难在现有的网络中实现,因为现有网络中有很多老旧的软件与现代版本的软件共存。因此,HTTP 流水线已被在有多请求下表现得更稳健的 HTTP/2 的帧所取代。
HTTP特点
- 简单快速,HTTP服务器的程序规模小,因而通信速度很快。
- 灵活,HTTP允许传输任意类型的数据对象,正在传输的类型由Content-Type加以标记。
- 无连接,每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。(http/1.0具有的功能,http/1.1兼容)
- 无状态:是指协议对于交互性场景没有记忆能力。什么是Http无状态?Session、Cookie、Token三者之间的区别
可是,随着web的发展,因为无状态而导致业务处理变的棘手起来。比如保持用户的登陆状态。http/1.1虽然也是无状态的协议,但是为了保持状态的功能,引入了cookie技术。绝大多数的Web开发,都是构建在HTTP协议之上的Web应用。
HTTP请求与响应
如果用户的URL没有指明要访问的某种资源路径。虽然浏览器会自动默认添加 ’ / ';但依旧没有告知服务器要访问什么资源,此时默认返回对应服务器的首页!还会将Linux下一个特定的路径作为Web根目录。
- 典型的 HTTP 会话:客户端首先建立连接,其次发送请求。服务端读取请求,分析请求,构建相应并返回。
项目纲要
- 套接字的封装:提供一个监听套接字,实现http底层与协议解耦。单例、端口复用。
- Http服务的启动:单例初始化,不停地获取连接、创建线程去解决客户端发来的请求。
- 添加日志信息:处理流程中一些信息的提示。
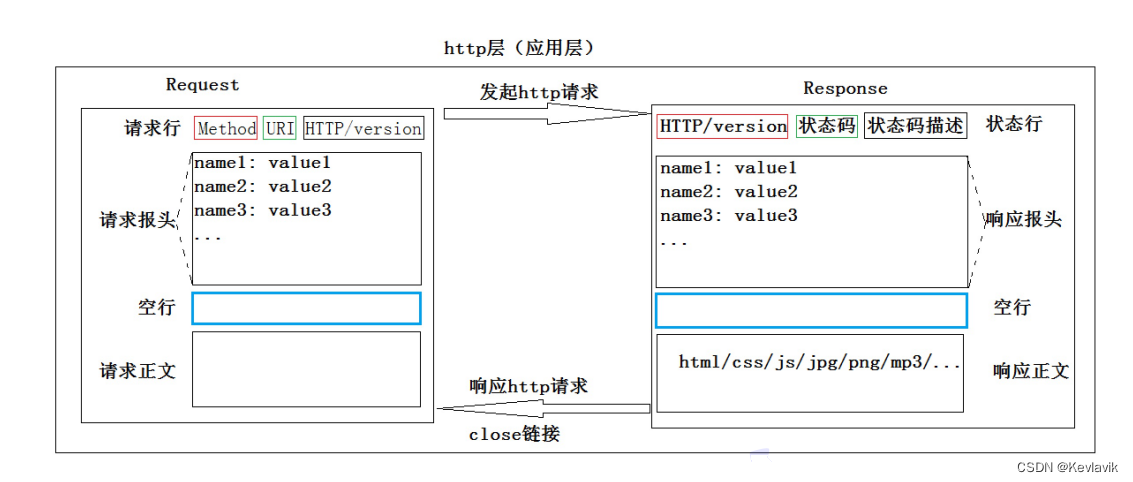
- 读取HTTP请求:读取请求行、请求报头、空行、正文。
- 响应HTTP请求:返回静态网页;有参数的调用cgi程序进行数据处理。
- CGI技术: CGI机制、数据处理、支持其他语言等
- 差错处理:读取出错、写入出错。
- 线程池的引入:设计任务、生产者消费者模型
- 网页表单数据的获取
- HTTP访问数据库
- 项目总结
项目架构
套接字的封装
- Sock.hpp
#pragmaonce#include<iostream>#include<sys/types.h>#include<sys/socket.h>#include<netinet/in.h>#include<pthread.h>#include<cstdlib>#include<arpa/inet.h>#include<cstring>#include<string>#include"Log.hpp"using std::cout;using std::string;using std::endl;staticconstint backlog =5;//单例,封装tcp套接字通信classTcpServer{private:int listen_sock;int _port;static TcpServer *svr;private:TcpServer(int potr):_port(potr),listen_sock(-1){}TcpServer(const TcpServer &)=delete;public:static TcpServer *GetInstanc(int port){static pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;if(svr ==nullptr){pthread_mutex_lock(&lock);if(svr ==nullptr){
svr =newTcpServer(port);
svr->Activate();}pthread_mutex_unlock(&lock);}return svr;}voidActivate()//激活{Establish();Bind();Monitoring();LOG(INFO,"Activate success");}voidEstablish()//创建{
listen_sock =socket(AF_INET, SOCK_STREAM,0);if(listen_sock <0){exit(1);}int opt =1;setsockopt(listen_sock,SOL_SOCKET,SO_REUSEADDR,&opt,sizeof(opt));//端口复用,服务器挂掉可以立即重启。}voidBind()//绑定{structsockaddr_in local;bzero(&local,sizeof(local));
local.sin_family = AF_INET;
local.sin_port =htons(_port);
local.sin_addr.s_addr = INADDR_ANY;if(bind(listen_sock,(structsockaddr*)&local,sizeof(local))<0){exit(2);}}voidMonitoring()//监听{if(listen(listen_sock,backlog)<0){exit(3);}}intSockListen()//供外部使用监听套接字 解耦{return listen_sock;}};
TcpServer *TcpServer::svr =nullptr;//单例模式
HTTP服务启动
- HttpSv.hpp
#pragmaonce #include"Sock.hpp"#include"Protocol.hpp"//线程处理HTTP请求与构建响应staticconst size_t PORT =8081;classHttpSever{private:
size_t _port;
TcpServer *tcp_svr;bool stop;//后期可以通过信号更改循环条件,而不是直接终止服务进程。public:HttpSever(int potr = PORT):_port(potr),tcp_svr(nullptr),stop(false){}~HttpSever(){}voidInitialize()//初始化获取单例。sock.hpp不用暴露在外面。{
tcp_svr =TcpServer::GetInstanc(_port);}voidLoopSever(){int listen_sock = tcp_svr->SockListen();while(!stop){structsockaddr_in peer;
socklen_t len =sizeof(peer);//输出型参数,记录请求方的一些信息int sock =accept(listen_sock,(sockaddr *)&peer,&len);if(sock <0){continue;}//需要线程去执行任务,传新获取到的sock的地址,在那里关闭sockint* psock =newint(sock);
pthread_t tid;pthread_create(&tid,nullptr,HandlerPetition::Entry,psock);//临时方案,后期改造成线程池pthread_detach(tid);}}};
日志信息与工具类
日志信息
方便项目调试。适当的日志信息,可以准确的定位到程序执到哪一步挂了,从而分析并解决BUG。
- Log.hpp
#pragmaonce#include<iostream>#include<string>#include<sys/time.h>#defineINFO1#defineWARNING2#defineERROR3#defineFATAL4#defineLOG(level, mesage)Log(#level, mesage,__FILE__,__LINE__)/*【日志级别】:【日志信息】【错误文件名称】【行数】-->可以根据编译器预定义符号获得
提示信息:info
警告: Warning
错误: Error
致命: FATAL
宏参数采用# 转换成字符串
*/voidLog(std::string level,std::string mes,std::string filename,size_t line){//timeval curr;// gettimeofday(&curr,nullptr); //时间戳 "[" << curr.tv_sec <<"]" <<
std::cout <<"[ "<< level <<" ]"<<"[ "<< mes <<" ]"<<"["<< filename <<"]"<<"["<< line <<"]"<< std::endl;}
工具类
在我们的工具类中,有两个函数在编写协议的时候经常会用到,一个是ReadLine()函数,一个是Cutstring函数()。
ReadLine()函数的作用是将sock中的数据一行一行的读取上来,当浏览器发送http请求给服务器的时候,请求行是为第一行,请求报头中的每种属性也是按行区分开来的,所以我们会用该函数去读取http请求。
其中,不同浏览器发送过来的http请求中行分隔符是不太一样的,有的是“\n",有的是"\r\n",有的是“\r",因此,我们可以将所有的行分隔符都处理成”\n".方便我们后续的处理。
#pragmaonce#include<iostream>#include<string>#include<sys/types.h>#include<sys/socket.h>using std::string;//小工具类:classUtil{public://读取处理换行符staticintReadLine(int sock, string &out)// \r\n,\r,\n{char ch ='x';while(ch !='\n')//每次只读一个字节,读到接近换行符{
ssize_t s =recv(sock,&ch,1,0);if(s >0){if(ch =='\r')//处理为'\n'{recv(sock,&ch,1, MSG_PEEK);//对文件缓冲区进行数据窥探if(ch =='\n'){recv(sock,&ch,1,0);}else{
ch ='\n';}}//普通字符或'\n'
out.push_back(ch);}elseif(s ==0){return0;}else{return-1;}}}staticboolCutString(string& obj,string& out1,string& out2,const string& sep){
size_t pos = obj.find(sep);if(pos != obj.npos)//左闭右开[){
out1 = obj.substr(0,pos);
out2 = obj.substr(pos+sep.size());returntrue;}returnfalse;}};
请求、响应类
- Protocol.hpp
classHandlerPetition{public:staticvoid*Entry(void*_sock)//线程的回调{int sock =*(int*)_sock;delete(int*)_sock;//cout<<" get a new link..."<<sock <<endl;//先看看你的请求是什么样子的 /* #ifndef DEBUG
#define DEBUG
cout<<" bb : ================"<<endl;
char buffer[4096];
recv(sock,buffer,sizeof(buffer),0);
cout<<buffer<<endl;
cout<<" ee: ================"<<endl;
#endif */
OppositeEnd *handle1 =newOppositeEnd(sock);
handle1->HttpRecvRequset();// handle1->HttpMakeRepsond();//handle1->HttpSendRespond();delete handle1;returnnullptr;}};
请求类与响应类。用于存储HTTP报文的各种信息。另外有什么需要记录的报文数据,可以随时添加。
#pragmaonce#include<iostream>#include<sys/types.h>#include<sys/stat.h>#include<sys/wait.h>#include<fcntl.h>#include<unistd.h>#include<vector>#include<cstdlib>#include"Tool.hpp"#include<sstream>#include<unordered_map>#include<algorithm>#include<sys/sendfile.h>#include"Log.hpp"using std::cerr;using std::cout;using std::endl;using std::unordered_map;using std::vector;#defineSEP": "#defineOK200#defineBAD_REQUEST400#defineNOT_FOUND404#defineSERVER_ERROR500#defineHTTP_VERSION"HTTP/1.0"#defineLINE_END"\r\n"#defineWEB_ROOT"webroot"#defineHOMEPAGE"index.html"#definePAGE_404"404.html"classHttpRequst// 分析请求报文,保存请求报文的各种数据{public:
string req_line;// 状态行
vector<string> req_head;// kv结构的请求行
string blank;// 空行
string req_body;// 请求正文 post方法的参数在正文// 存放解析完毕之后的结果
string method;// 方法
string version;// http版本
string url;// 请求的资源路径?参数
unordered_map<string, string> kv_head;// 拆分kv结构的请求报头int cont_length;// 正文大小
string path;// 资源路径
string query_string;// 参数bool cgi;// 是否请求的是可执行程序int size;// 请求资源文件的html的大小
string suffix;// 资源后缀,根据资源后缀确定发送时content type 的 描述属性public:HttpRequst():cont_length(0),cgi(false){}~HttpRequst(){}};classHttpRespond// 记录响应报文的各种属性{public:
string respond_line;// 响应行
vector<string> respond_head;// 响应报头
string blank;// 响应空行
string respond_body;// 响应正文int status_code;// 状态码int fd;// 默认首页的文件描述符public:HttpRespond():blank(LINE_END),status_code(OK),fd(-1){}~HttpRespond(){}};
与此同时提供一个类,对如下功能的封装:读取分析报文、构建相应、发送响应报文,关闭套接字。
classOppositeEnd{private:int sock;
HttpRespond hp_respond;
HttpRequst hp_request;bool stop;//后期差错处理public:OppositeEnd(int _sock):sock(_sock){}~OppositeEnd(){close(sock);}voidHttpRecvRequset()//请求报文的读取加分析{ReadRequestLine();// 读取状态行ReadRequestHead();// 读取请求报头HttpAnalyseRequestLine();// 分析状态行AnalyseRequestHead();// 拆分kv报头RecvReqBody();// 读取正文}voidHttpMakeRepsond(){}voidHttpSendRespond(){}
测试一下:
netstat -nltp
:查看服务是否启动。
对于Telnet的认识,可以把Telnet当成一种通信协议,但是对于入侵者而言,Telnet只是一种远程登录的工具。一旦入侵者与远程主机建立了Telnet连接,入侵者便可以使用目标主机上的软、硬件资源,而入侵者的本地机只相当于一个只有键盘和显示器的终端而已。
为什么需要telnet?telnet就是查看某个端口是否可访问。我们在搞开发的时候,经常要用的端口就是 8080。那么你可以启动服务器,用telnet 去查看这个端口是否可用。
Telnet协议是TCP/IP协议家族中的一员,是Internet远程登陆服务的标准协议和主要方式。它为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用telnet程序,用它连接到服务器。终端使用者可以在telnet程序中输入命令,这些命令会在服务器上运行,就像直接在服务器的控制台上输入一样。可以在本地就能控制服务器。要开始一个telnet会话,必须输入用户名和密码来登录服务器。Telnet是常用的远程控制Web服务器的方法。
[root@VM-12-7-centos output]# telnet 127.0.0.18081
Trying 127.0.0.1...
Connected to 127.0.0.1.
Escape character is '^]'.^]
telnet>
get /b/a http/1.0
读取请求
voidHttpRecvRequset()// 请求报文的读取加分析{ReadRequestLine();// 读取状态行ReadRequestHead();// 读取请求报头HttpAnalyseRequestLine();// 分析状态行AnalyseRequestHead();// 拆分kv报头RecvReqBody();// 读取正文 }
读取请求行
boolReadRequestLine()// 读取状态行{if(Util::ReadLine(sock, hp_request.req_line)>0){
hp_request.req_line.resize(hp_request.req_line.size()-1);LOG(INFO, hp_request.req_line);}else{
stop =true;}
cout <<"ReadRequestLine() "<< stop << endl;return stop;}
读取请求报头
boolReadRequestHead()// 读取报头{
string line;while(true){
line.clear();if(Util::ReadLine(sock, line)<=0){
stop =true;break;// 出错}if(line =="\n"){
hp_request.blank = line;break;}
line.resize(line.size()-1);
hp_request.req_head.push_back(line);}
cout <<"ReadRequestHead() "<< stop << endl;return stop;}
分析请求行
我们需要将读取到的请求行拆分成三个部分:请求方法,URI,请求版本,以便我们后续根据请求方法,URI和版本构建响应。
在请求行中,method,uri和version它们之间都隔着空格,所以可以使用streamstring将请求行拆分成method,uri,version。由于http请求的方法没有规定大小写,于是这里将其进行字符串大小写转换,转换成大写。算法头文件中的
transform
。
voidHttpAnalyseRequestLine()// 分析请求行 GET /a/b http/1.0{auto&line = hp_request.req_line;
std::stringstream ss(line);
ss >> hp_request.method >> hp_request.url >> hp_request.version;// 默认按照空格分割字符串
std::transform(hp_request.method.begin(), hp_request.method.end(), hp_request.method.begin(),::toupper);
cout <<"AnalyseRequestLine() method.."<< hp_request.method << endl;/* LOG(INFO,hp_request.method);
LOG(INFO,hp_request.url);
LOG(INFO,hp_request.version); */}
分析请求报头
请求报头中包含了请求中的各种信息,但是它们都是以 ”属性名:属性信息“ 的形式存储在vector中,例如:“Content-Length: 10",为了方便我们找到请求报头中的各种信息,我们需要将请求报头中的每种属性拆分成属性名-属性信息键对值存放在unordered_map。
每种报头中每种属性里,属性名和属性信息都是用 “:”分隔开的。因此我们需要根据”:“将属性名和属性信息分隔开来。
voidAnalyseRequestHead()// 拆分kv结构的报头{
string key1;
string val1;for(auto&iter : hp_request.req_head){if(Util::CutString(iter, key1, val1, SEP)){
hp_request.kv_head.insert({key1, val1});}}}
读取正文
当解析请求行和请求报头完后,我们就可以知道method和Content-Length,我们就可以判断请求正文中有内容。如果请求正文中有内容,那么就需要读取多少?
在GET方法中,请求正文是被设置为空,所以GET方法是不需要读取请求正文的。如果是POST方法,它的请求正文有可能为空,也有可能存在。
如果POST方法中的请求正文存在,Content-Length是不等于0的,在sock读取多少个字节呢?根据Content-Length判断即可。如果POST方法中的请求正文不存在,那么Content-Length是为0,因此是不需要读取请求正文的。阻塞式的一个字节一个字节的读,防止粘包等问题。
boolRecvReqBody()// 读取正文{if(IsGetBody()){int ct_len = hp_request.cont_length;
cout <<" ct_len : "<< ct_len << endl;char ch =0;while(ct_len){
ssize_t s =recv(sock,&ch,1,0);0if(s >0){
hp_request.req_body.push_back(ch);
ct_len--;}else{
stop =true;break;}}LOG(INFO,"bool RecvReqBody() "+hp_request.req_body);}return stop;}boolIsGetBody()// 确认正文是否需要读取,有则读取多少个字节。{auto&method = hp_request.method;if(method =="POST")// 通过Content-Length 找到它的val值。{auto&kv_head = hp_request.kv_head;auto it = kv_head.find("Content-Length");if(it != kv_head.end()){LOG(INFO,"Post Method, Content-Length: "+it->second);
hp_request.cont_length =atoi(it->second.c_str());returntrue;}}returnfalse;}
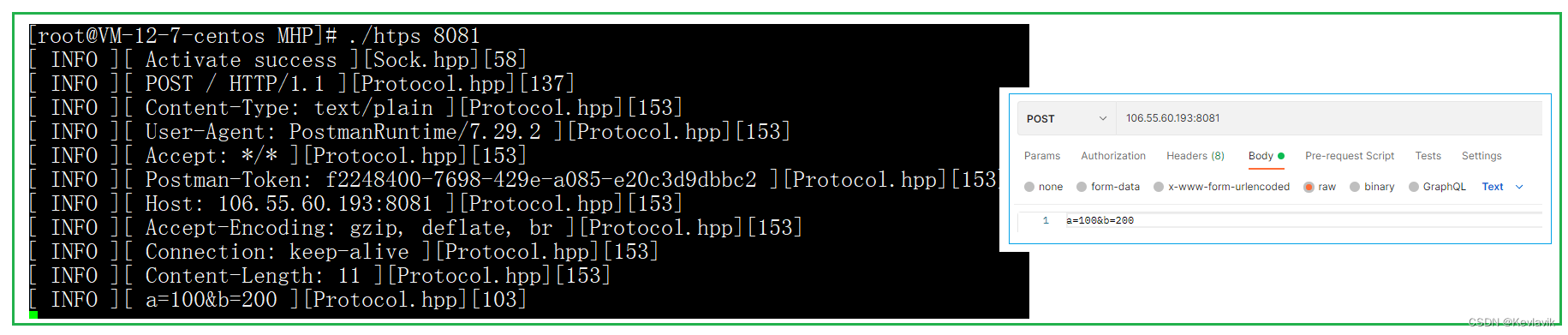
构建响应预处理
浏览器给服务器发出一个http请求目的是让服务器完成某种任务,可能是想访问服务器上的某种资源(文本文件,视频,音频等等),也可能让服务器处理某些数据等等,服务器完成的结果是需要返回给我们的浏览器,文本文件的内容,视频,音频,或数据处理的结果都需要返回给浏览器,但服务器的处理结果是不能直接返回给浏览器,是需要构建一个http响应返回浏览器的,处理结果就放在http的响应正文中。
http响应的构建需要包含:响应行,响应报头,响应空行,响应正文。
构建响应行:版本 响应状态码 响应状态码描述
构建响应报头:构建响应报头至少需要构建 Content-Type 和Content-Length属性。
Content-Type:服务器返回资源是什么类型
Content-Length:服务器返回的资源的大小。每种属性都以空行作为结尾。构建响应行:将响应报头和响应正文分隔开。 构建响应正文:存放文本文件的内容,视频,音频或数据的处理结果。
在我们构建响应之前,我们需要根据浏览器发出的http请求来找到我们服务器上的资源,也就是我们的请求路径path。path在解析URI中就已经处理好了,接下来我们直接用就可以了。

我们解析看到的path都是以 / 开头,此时就有一个问题,浏览器访问资源的路径是从服务器上的根目录下开始找的吗?答案是不一定,在哪里找资源取决于我们把所有资源放在哪一个目录下。举个例子:我将我的服务器上所有的资源都放在webroot目录下,那么浏览器想要访问的服务器上的资源,就需要到webroot目录下去寻找资源。
可是浏览器发送过来的路径都是以根路径最开始的呀,http进程是怎么到webroot目录下去寻找资源呢?答案是http进程在接收到浏览器的访问路径时,首先会对该路径进行修饰的,例如,我的资源目录是webroot,它与http进程是在同一个目录下,所以我的http进程是可以通过相对路径去访问wwwroot目录,因此在编码的时候,我会让我的http进程在路径的前面加上webroot,例如请求路径是/test_cgi,修饰后的路径就变为webroot/test_cgi,这样我们的http进程就会去webroot目录下查找资源。
接下来我们就需要判断该路径下的资源是否存在,如果不存在,那么将状态码设置为404,也就是找不到的意思,如果该资源存在,那么我们还需要再一步判断,如果访问的资源是一个文本文件, 我们需要记录该文件的大小,然后将该文本文件去构建一个http响应,如果是一个可执行程序,那么我们将标识cgi为真,对其进行cgi处理(下面会讲,不懂的可以先跳动下面看以下cgi处理),如果访问的资源是一个目录呢?是不是就不用进行处理呢?或者有什么办法可以解决这个问题?
其中一个解决办法就是在每一个目录下都建立一个index.html文件,这个文件代表的是该目录的首页,如果访问到该目录,并且没指明访问该目录的哪一个资源时,htpt进程就会直接将该目录下的index.html中的内容返回给浏览器。举个例子:如果访问的路径是 /,http进程会将/路径修饰成wwwroot/html,那么http进程就会找到wwwroot下的index.html中并将其文本内容返回给浏览器,如果访问的路径是/dir1, http进程会将/dir路径修饰成wwwroot/dir1/index.html,那么http进程就会找到dir1目录下index.html文件并将其文本内容返回给浏览器。
除此之外,我们还需要构建响应报头中的Content-Type,所以再拿去已经找到的资源的后缀将其放进suffix中,如果没有后缀,则统一设置为".html",然后根据后缀去构建Content-Type。
代码
voidHttpMakeRepsond(){auto&code = hp_respond.status_code;auto&method = hp_request.method;
size_t sufix =0;structstat st;
string path1;if(hp_request.method !="POST"&& hp_request.method !="GET"){LOG(WARNING,"method is not right");
code = NOT_FOUND;goto END;}if(method =="GET")// 有参进行调用cgi,进行数据处理{
size_t pos = hp_request.url.find("?");if(pos != string::npos)// 切分 url{// /tcg?a=10&b=20Util::CutString(hp_request.url, hp_request.path, hp_request.query_string,"?");
hp_request.cgi =true;}else{
hp_request.path = hp_request.url;}}elseif(method =="POST")// post已经把正文读上来了{
hp_request.cgi =true;
hp_request.path = hp_request.url;}else{// do nothing}// /
path1 = hp_request.path;
hp_request.path = WEB_ROOT;// 添加前缀
hp_request.path += path1;// webroot/LOG(INFO,"debug: path "+ hp_request.path);// webroot/tcg /if(hp_request.path[hp_request.path.size()-1]=='/'){
hp_request.path += HOMEPAGE;}// webroot/tcgif(stat(hp_request.path.c_str(),&st)==0)// 资源存在{if(S_ISDIR(st.st_mode))// 若是目录,则返回该目录下的默认首页{
hp_request.path +="/";
hp_request.path += HOMEPAGE;stat(hp_request.path.c_str(),&st);// 重新获取目录下首页文件的大小}if(st.st_mode & S_IXUSR || st.st_mode & S_IXGRP || st.st_mode & S_IXOTH)// 具有可执行权限{
hp_request.cgi =true;}
hp_request.size = st.st_size;// 首页的html文件多大}else// 资源不存在{LOG(WARNING, hp_request.path +="Not Found");
code = NOT_FOUND;goto END;}LOG(INFO, hp_request.req_body);// 找后缀
sufix = hp_request.path.rfind(".");if(sufix == string::npos){
hp_request.suffix +=".html";}else{
hp_request.suffix = hp_request.path.substr(sufix);}// 说明资源存在,合法请求if(hp_request.cgi){
code =GoCgi();
cout <<"cgi返回的状态码: "<< code << endl;}else{
code =NoCgi();}
END:BuildResponseHelper();// 根据状态码构建对应的响应// 上面出错的地方就设置状态码值,返回404页面,还可以添加一些不同状态码系列的描述页面}
stat()函数作用:查看一个文件是否存在,并将文件的属性存放在struct stat变量中。返回值:成功返回0,失败返回-1。
structstat{2 dev_t st_dev;//device 文件的设备编号3 ino_t st_ino;//inode 文件的i-node4 mode_t st_mode;//protection 文件的类型和存取的权限5 nlink_t st_nlink;//number of hard links 连到该文件的硬连接数目, 刚建立的文件值为1.6 uid_t st_uid;//user ID of owner 文件所有者的用户识别码 7 gid_t st_gid;//group ID of owner 文件所有者的组识别码 8 dev_t st_rdev;//device type 若此文件为装置设备文件, 则为其设备编号 9 off_t st_size;//total size, in bytes 文件大小, 以字节计算 10unsignedlong st_blksize;//blocksize for filesystem I/O 文件系统的I/O 缓冲区大小. 11 u nsigned long st_blocks;//number of blocks allocated 占用文件区块的个数, 每一区块大小为512 个字节. 12 time_t st_atime;//time of lastaccess 文件最近一次被存取或被执行的时间, 一般只有在用mknod、 utime、read、write 与tructate 时改变.13 time_t st_mtime;//time of last modification 文件最后一次被修改的时间, 一般只有在用mknod、 utime 和write 时才会改变14 time_t st_ctime;//time of last change i-node 最近一次被更改的时间, 此参数会在文件所有者、组、 权限被更改时更新 15};
其中st_size属性是查看文件的大小,以字节为单位,st_mode存储了文件的类型和权限。 S_ISDIR (st_mode) 是一个宏定义,作用判断文件是否为目录。st.st_mode&S_IXGRP、st.st_mode&S_IXOTH、st.st_mode&S_IXUSR,分别判断文件所属组,文件的其他人,文件所属人是否具有可执行权限,如果其中有一个为真,那么该文件具有可执行权限。先前所描述的st_mode 则定义了下列数种情况:
1、S_IFMT 0170000 文件类型的位遮罩
2、S_IFSOCK 0140000 scoket
3、S_IFLNK 0120000 符号连接
4、S_IFREG 0100000 一般文件
5、S_IFBLK 0060000 区块装置
6、S_IFDIR 0040000 目录
7、S_IFCHR 0020000 字符装置
8、S_IFIFO 0010000 先进先出
9、S_ISUID 04000 文件的 (set user-id on execution)位
10、S_ISGID 02000 文件的 (set group-id on execution)位
11、S_ISVTX 01000 文件的sticky 位
12、S_IRUSR(S_IREAD)00400 文件所有者具可读取权限
13、S_IWUSR(S_IWRITE)00200 文件所有者具可写入权限
14、S_IXUSR(S_IEXEC)00100 文件所有者具可执行权限
15、S_IRGRP 00040 用户组具可读取权限
16、S_IWGRP 00020 用户组具可写入权限
17、S_IXGRP 00010 用户组具可执行权限
18、S_IROTH 00004 其他用户具可读取权限
19、S_IWOTH 00002 其他用户具可写入权限
20、S_IXOTH 00001 其他用户具可执行权限上述的文件类型在 POSIX 中定义了检查这些类型的宏定义
21、S_ISLNK(st_mode) 判断是否为符号连接
22、S_ISREG(st_mode) 是否为一般文件
23、S_ISDIR(st_mode) 是否为目录
24、S_ISCHR(st_mode) 是否为字符装置文件
25、S_ISBLK(s3e) 是否为先进先出
26、S_ISSOCK(st_mode) 是否为socket 若一目录具有sticky 位 (S_ISVTX), 则表示在此目录下的文件只能 被该文件所有者、此目录所有者或root 来删除或改名.
返回静态网页
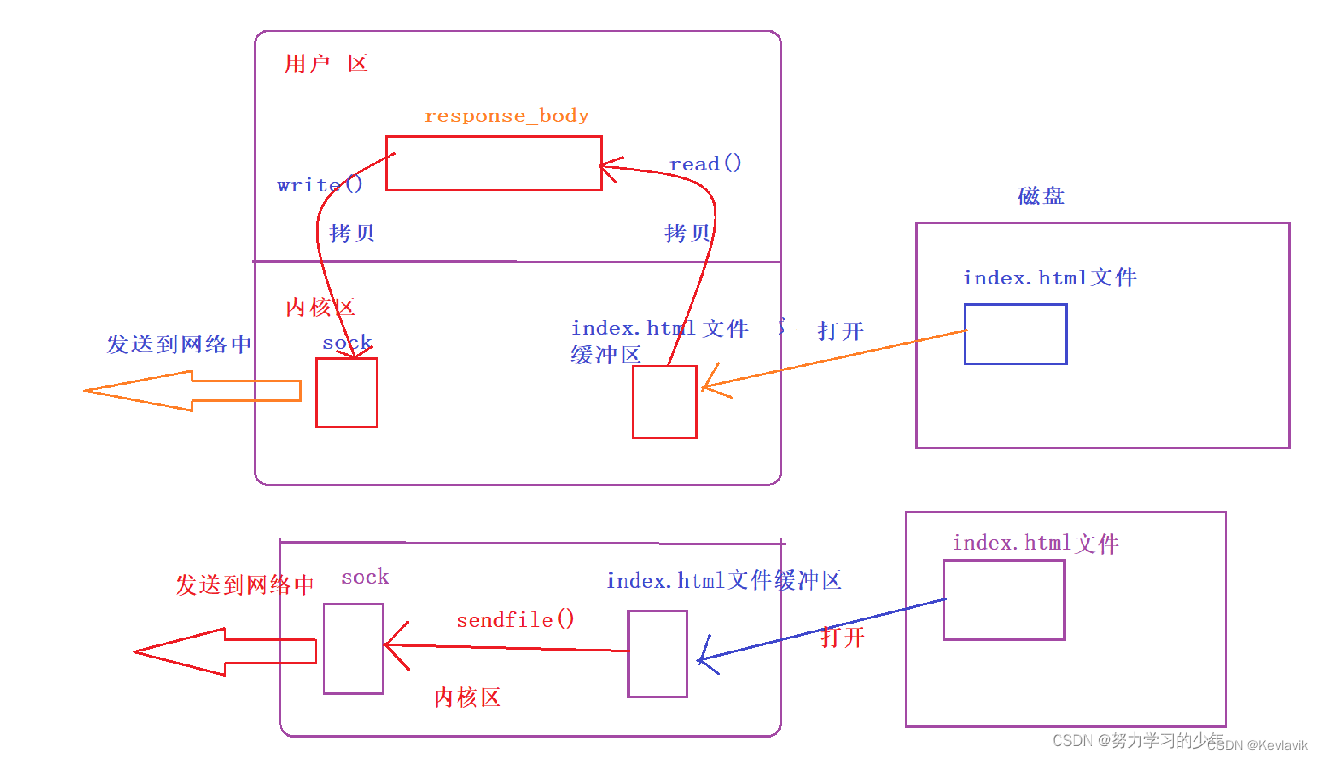
网页本质是一个超文本文件,也就是我们的前端代码,当返回这些代码给浏览器的时候,浏览器就会解析成一个网页。因此如果浏览器访问的资源是是一个文件,那么http进程就直接将该文本文件直接打开,等到发送的响应的时候直接通过sendfile将文件的内容发送给浏览器即可。
为什么非cgi处理(返回错误页面,或者返回请求网页)不直接将文件内容存放到响应正文response_body中,而是使用sendfile()函数发送给浏览器呢?
如果使用read()函数将index.html的文件缓冲区中的内容拷贝到用户去中的response_body,再使用write()函数拷贝给sock缓冲区,数据就会经过三个步骤:内核区->用户区->内核区,相比较sendfile()函数,效率会慢一些,因此我们就使用sendfile()函数将响应正文发送给sock().
intNoCgi()// 简单的网页返回,返回静态网页,只需要打开即可{
hp_respond.fd =open(hp_request.path.c_str(), O_RDONLY);// 先打开,发送后再完毕if(hp_respond.fd >0){LOG(INFO, hp_request.path +="OPEN SUCCESS!");return OK;}return NOT_FOUND;}
CGI机制
CGI机制的基本概念
CGI(Common Gateway Interface) 是WWW技术中最重要的技术之一,有着不可替代的重要地位。CGI是外部应用程序(CGI程序)与WEB服务器之间的接口标准,是在CGI程序和Web服务器之间传递信息的过程。所谓的CGI程序就是部署在服务器上的一个一个的可执行程序,这些可执行程序具有处理数据的功能。
为了大家能够更好的理解cgi机制,我就举一个具体的情况,如果浏览器使用GET方法或者POST方法中访问的资源是一个可执行程序。
首先http进程就会通过fork创建一个子进程,其次通过execl将可执行程序替换子进程,再次http进程就把参数通过传递给子进程,接着子进程就会解析该参数,例如”a=100&b=200“字符串解析成a=100,b=200。随后子进程将参数处理的结果返回给http进程,最后http进程在通过网络返回给浏览器。这种http进程去调用CGI处理数据的方式就叫做CGI机制。(GET方法和POST传进来的参数需要与调用的CGI程序能解析的参数互相匹配,例如:如果调用的CGI程序只能解析两个参数,那么GET方法和POST方法传进来的就必须是两个参数)
CGI函数的实现
http进程本身是不会处理参数的,他的功能只是与浏览器互相进行数据的传输,如果要想让服务器具有处理各种参数的功能,那么就需要在服务器上部署各种各样的参数处理的CGI程序,这样就能够使我们的服务器有多种处理数据的功能。
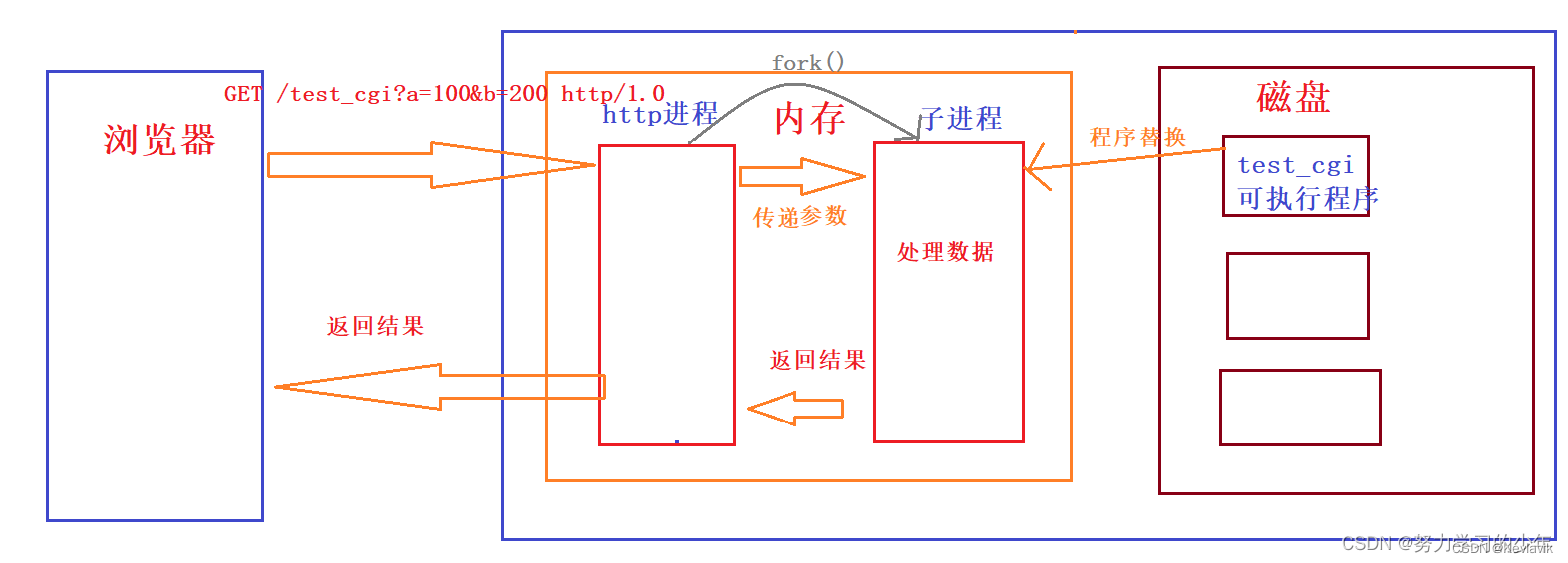
进程间通信
http进程给CGI进程之间需要互相通信,http进程需要传递参数给子进程,而CGI进程需要返回结果给http进程。因为http进程和CGI进程是父子进程,所以在互相通信的时候,创建匿名管道是最方便的,但管道的数据传输是单向的,为了能够使http进程和子进程之间都能互相传递数据,因此需要创建两个匿名管道。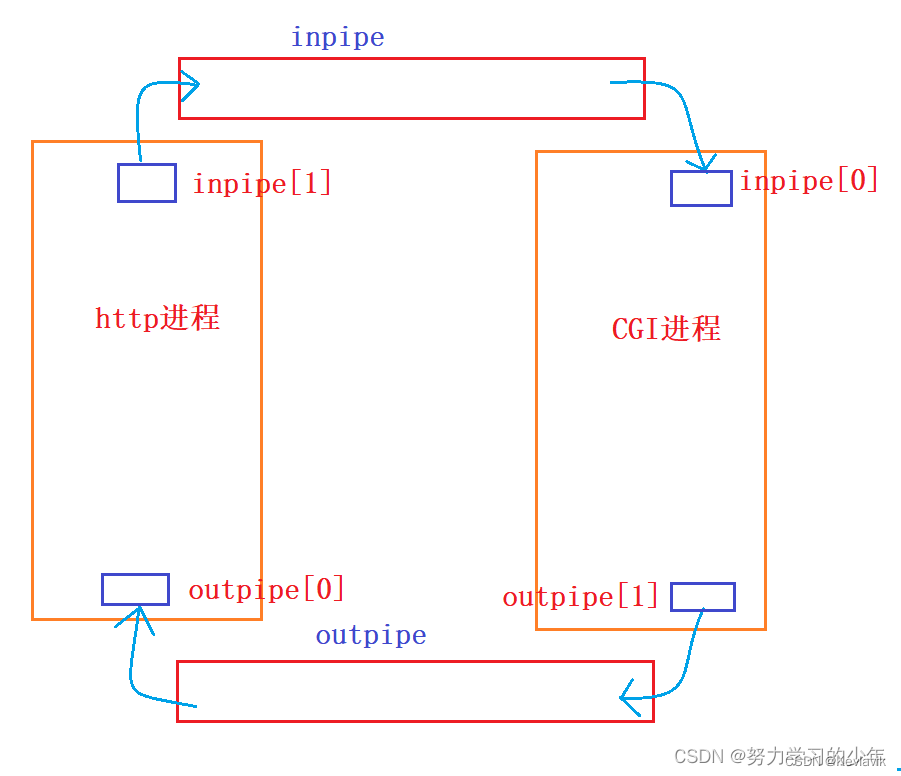
重定向、进程替换
对于子进程来说,如果子进程被程序替换后,那么它拿到两个管道的文件描述符的数据也会被替换掉,此时子进程就不知道两个管道的文件描述符,就无法去input管道中读取数据,不能再outpipe中的写入数据。
因为cin是一直往0号文件描述符中的file文件读入数据,cout一直往1号文件描述符中的file文件写入数据,所以在程序替换之前将子进程inpipe[0]的file*重定向到0号文件符,将子进程的outpipe[1]文件描述符就替换到1号文件描述符中去,所以,子进程据可以通过cin去inpipe管道中读取数据,通过cout往outpipe中写入数据。
Linux中fork子进程后再exec新程序时文件描述符的问题? - Napoleon的回答 - 知乎默认情况下,由exec()的调用程序所打开的所有文件描述符在exec()的执行过程中会保持打开状态,且在新程序中依然有效。这通常很实用,因为调用程序可能会以特定的描述打开文件,而在新程序中这些文件将自动有效,无需再去了解文件名或是把它们重新打开。
内核为每个文件描述符提供了执行时关闭标志。如果设置了这一标志,那么在成功执行exec()时,会自动关闭该文件描述符,如果调用exec()失败,文件描述符则会保持打开状态。可以通过系统调用fcntl()来访问执行时关闭标志。fcntl()的F_GETFD操作可以获得文件描述符标志的一份拷贝。获取这些标志之后,可以对FD_CLOEXEC位进行修改,再调用fcntl()的F_SETFD操作使其生效。
进程替换本质上就是去替换一个进程pcb在内存中的对应的代码和数据:操作系统把老程序的PCB中,程序文件(磁盘中的)代码段的起始地址和数据段地址更换成新程序的…(加载新程序到内存——>更新页表信息——>初始化虚拟地址空间),然后这个进程pcb重新开始执行这个新的程序。
创建管道对应的文件描述符:
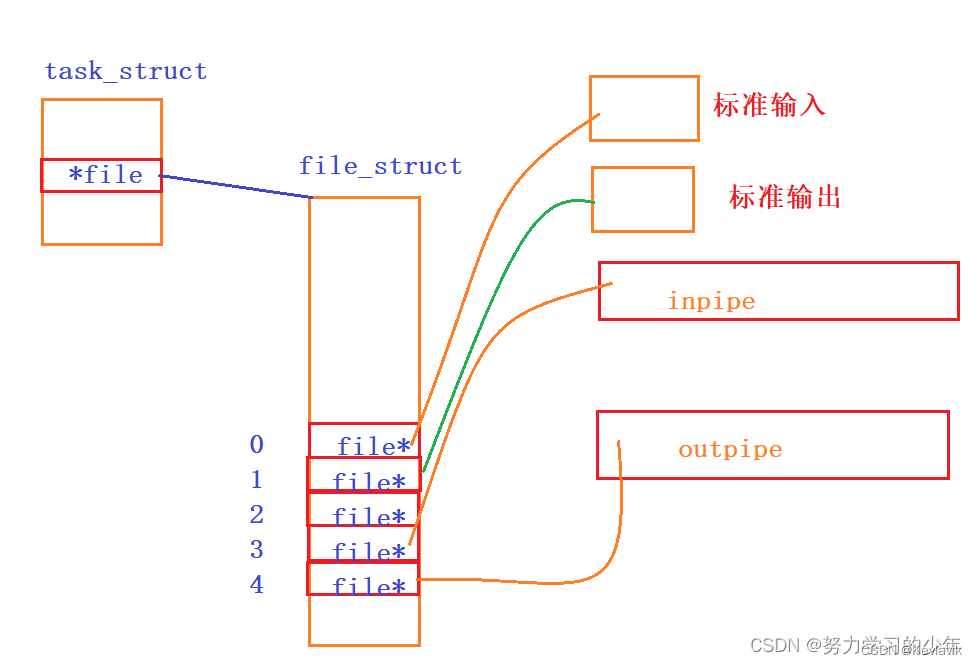
dup2重定向后,0号文件描述符标识的是inpipe管道,1号文件描述符标识的outpipe管道。所以子进程cin写入数据,就是往inpipe中写入数据,cou输出数据,就是往outpipe输出数据。
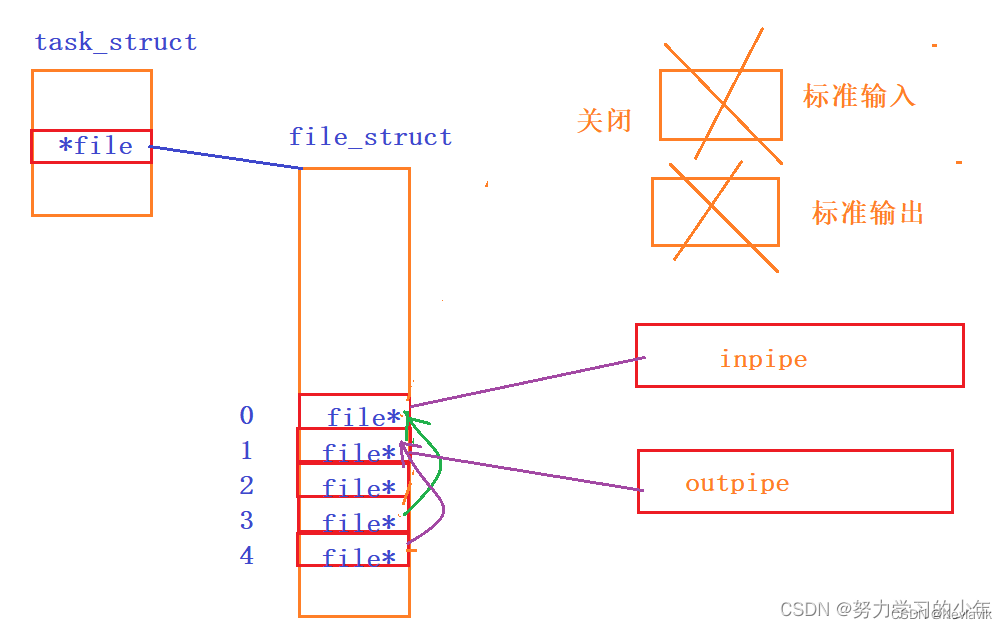
http进程给子进程传参的时候,GET请求和POST请求传参方式是不同的。
- 如果是GET方法,传递参数给子进程是通过设置环境变量的方式给子进程,因为URI中参数是有大小限制,一般都不会太长,并且程序替换,只替换进程的代码和数据,不会替换环境变量,因此在子进程被execl之前,提前设置一个PATAMETER的环境变量。
- 如果是POST方法,传递参数给子进程是通过管道的方式给子进程,因为POST中的请求正文的参数是没有限制的。但是子进程怎么知道要在管道中读取多少个字符呢?此时就需要将通过设置一个环境变量Content-Length来标识参数的大小,让子进程知道需要从管道中读取多少个字符。
- 可是子进程怎么知道要是GET请求还是POST请求,此时就需要在设置一个环境变量METHOD来标识请求方法。 http进程就从ouput[0]中读取到的结果放进response_body中。
CGI代码的实现:
intGoCgi(){int code = OK;auto&method = hp_request.method;// 方法auto&route = hp_request.path;// 目标程序-替换auto&query_str = hp_request.query_string;// GET 参数auto&req_body = hp_request.req_body;// POST 参数在正文int cont_length = hp_request.cont_length;// 正文大小auto&resp_body = hp_respond.respond_body;// 读取cgi的结果
string method_env;
string agr_env;// GET压入环境变量让cgi获取参数
string len_env;// post压入环境变量正文字节数的大小 管道读,读多少int intput[2];// 父进程 写入int output[2];// 父进程 读取if(pipe(intput)<0){LOG(ERROR,"pipe input error");
code = SERVER_ERROR;return code;}if(pipe(output)<0){LOG(ERROR,"pipe output error");
code = SERVER_ERROR;return code;}
pid_t pid =fork();if(pid ==0)// 子进程{close(intput[1]);// 子进程 intput[0]读取close(output[0]);// outpu[1] 写入
method_env ="METHOD=";
method_env += method;putenv((char*)method_env.c_str());if(method =="GET"){
agr_env ="ARG_STRING=";
agr_env += query_str;
cout <<"debug.. ARG_STRING: "<< agr_env.c_str()<< endl;putenv((char*)agr_env.c_str());LOG(INFO,"Get Method, Add Arg_str Env");}elseif(method =="POST"){
len_env ="CONTENT_LENGTH=";
len_env += std::to_string(cont_length);putenv((char*)len_env.c_str());LOG(INFO,"POST Method, Add Content-Length Env");}else{/* code */}// 重定向 当调用dup2(int oldfd,int newfd)之后,若newfd原来已经打开了一个文件,// 则先关闭这个文件,然后newfd和oldfd指向了相同的文件;若newfd原来没有打开一个文件,则newfd直接指向和oldfd指向相同的文件。
cout <<"debug: before redirect path "<< route << endl;dup2(output[1],1);dup2(intput[0],0);execl(route.c_str(), route.c_str(),NULL);LOG(ERROR,"EXECL FAILED...");exit(1);}elseif(pid <0){LOG(ERROR,"fork error!");
code = SERVER_ERROR;return code;}else// 父进程{close(intput[0]);// 读close(output[1]);// 写if(method =="POST"){constchar*start = req_body.c_str();
cerr <<"f write to req_body .."<< start << endl;int total =0;
ssize_t size =0;while(total < cont_length &&(size =write(intput[1], start + total, req_body.size()- total))>0){
total += size;// 防止管道在对方没有读走时,数据覆盖}}char ch =0;while(read(output[0],&ch,1)>0){
resp_body.push_back(ch);}// cerr << "debug: resp_body.. " << resp_body << endl;int status =0;
pid_t ret =waitpid(pid,&status,0);if(ret == pid){if(WIFEXITED(status)){if(WIFSIGNALED(status)==0){
code = OK;}else{
code = BAD_REQUEST;}}else{
code = SERVER_ERROR;}}close(intput[1]);close(output[0]);}return code;}
子CGI程序
子cgi程序
#include"common.hpp"intmain(){
string args;GetArgsString(args);
cerr <<"args: "<< args << endl;
string argk1;
string argk2;// a=10&b=20CutString(args, argk1, argk2,"&");
string left1, value1;
string left2, value2;CutString(argk1, left1, value1,"=");CutString(argk2, left2, value2,"=");// 网页显示 获取到的参数
cout << left1 <<": "<< value1 << endl;
cout << left2 <<": "<< value2 << endl;// 服务端看一下参数
cerr << left1 <<": "<< value1 << endl;
cerr << left2 <<": "<< value2 << endl;int x =atoi(value1.c_str());int y =atoi(value2.c_str());// 需要自己按html的样式cout,往管道里写入
cout <<"<html>";
cout <<"<head><meta charset=\"utf-8\"></head>";
cout <<"<body>";
cout <<"<h3>"<< x <<" + "<< y <<" = "<< x + y <<"</h3>";
cout <<"<h3>"<< x <<" - "<< y <<" = "<< x - y <<"</h3>";
cout <<"<h3>"<< x <<" * "<< y <<" = "<< x * y <<"</h3>";
cout <<"<h3>"<< x <<" / "<< y <<" = "<< x / y <<"</h3>";
cout <<"</body>";
cout <<"</html>";return0;}
公共头文件,其他的cgi程序都要用到的功能。
#pragmaonce#include<iostream>#include<string>#include<cstdlib>#include<unistd.h>using std::cerr;using std::cout;using std::endl;using std::string;/* getenv()用来取得参数name环境变量的内容。
参数name为环境变量的名称,如果该变量存在则会返回指向该内容的指针。环境变量的格式为name=value。 */boolGetArgsString(string &arg_string){bool result =false;// 成功获取参数返回真
string metohd =getenv("METHOD");
cerr <<"cgi method : .. "<< metohd << endl;if(metohd =="GET"){
arg_string =getenv("ARG_STRING");
cerr<<"arg_steing ..."<<arg_string<<endl;
result =true;}elseif(metohd =="POST"){char ch =0;auto content_length =atoi(getenv("CONTENT_LENGTH"));while(content_length){read(0,&ch,1);
arg_string.push_back(ch);
content_length--;}
result =true;}else{
result =false;}return result;}voidCutString(string &dest, string &str1, string &str2,const string &sep){auto pos = dest.find(sep);if(pos != string::npos){
str1 = dest.substr(0, pos);
str2 = dest.substr(pos + sep.size());}}
CGI总结
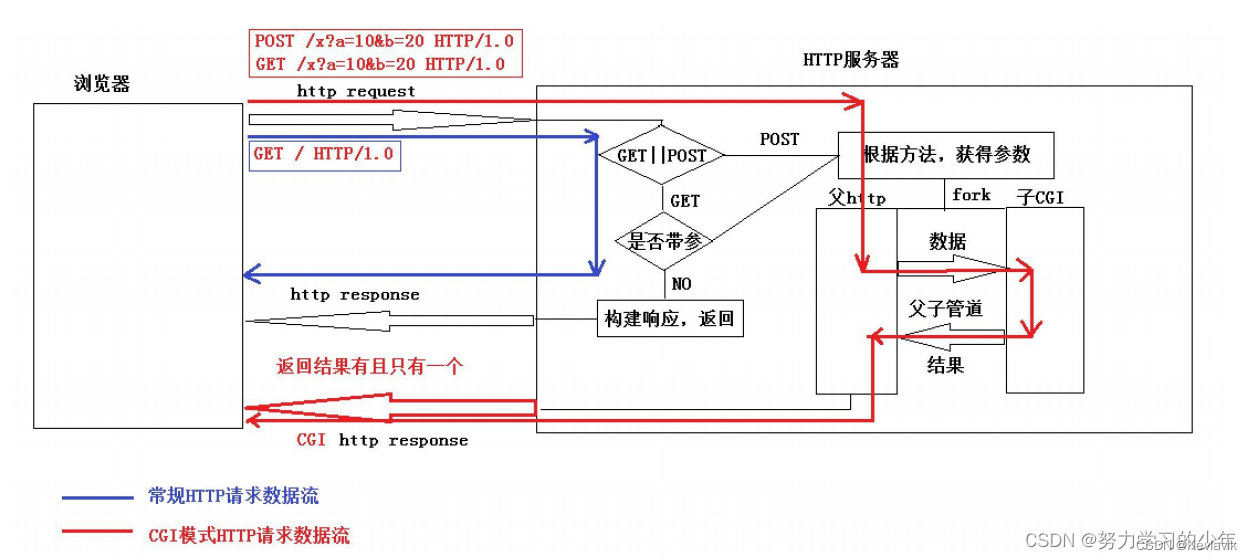
在我们编写cgi子程序的时候,我们可以忽略浏览器和子CGI之间的通信细节,我们可以认为子cgi中的cgi是读取浏览器中的参数,cout是往浏览器中输出数据,这样就大大减低了理解cgi子程序的 成本。
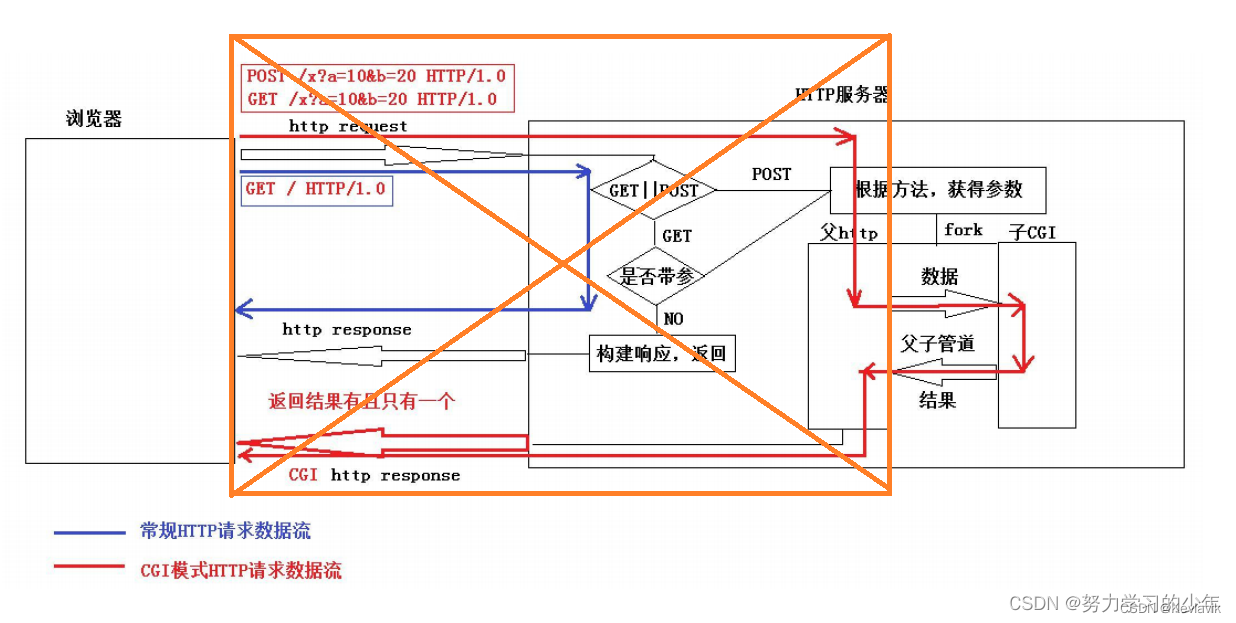
构建响应
当我们处理完cgi函数后和非cgi函数后,我们就已经确定状态码,可以根据状态码统一构建响应的前三行。除了成功的状态码外,其他状态码都会返回一个错误页面。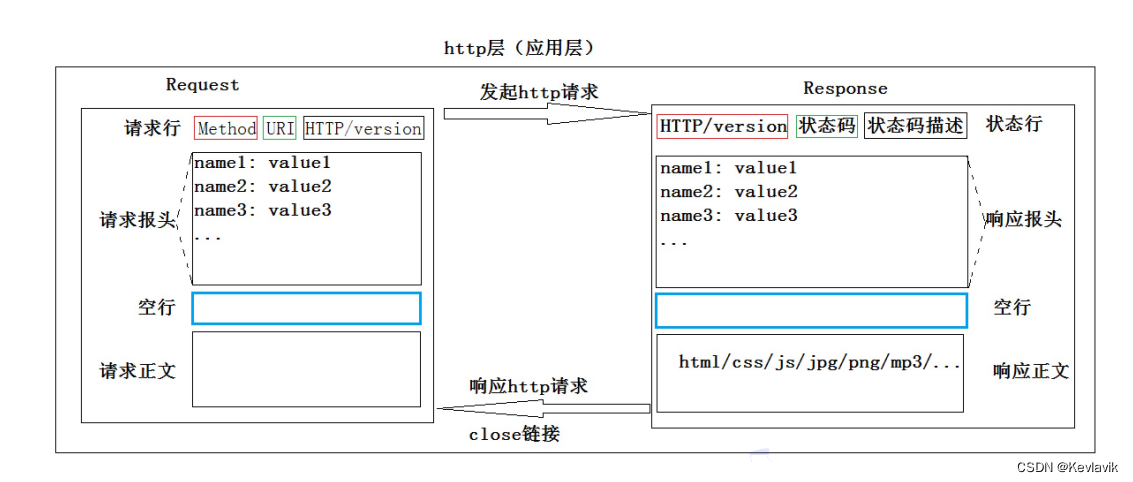
在响应行中,版本,状态码和状态码描述两两之间是以空格分隔开的,最后响应行以\r\n结尾。另外根据响应报文,将状态码转换为状态码描述,如200转换为“OK"。 根据之前解析出来的资源后缀,我们就可以通过后缀判断出返回的资源是一个什么样的类型,接下来就可以构建出报头中的Content-Type,最后在以”\r\n"结尾
状态码描述、后缀网页类型
//状态码转描述static string CodeDesc(int code){
string desc;switch(code){case200:
desc ="OK";break;case404:
desc ="Not Found";break;case400:
desc ="BAD REQUEST";break;case500:
desc ="Server Error";default:break;}return desc;}//根据请求后缀确定响应报文Content-Type的属性static string SuffixDesc(const string &suffix)// 只会被初始化一次{
unordered_map<string, string> _sd ={{".html","text/html"},{".css","text/css"},{".js","application/javascript"},{".jpg","application/x-jpg"},{".xml","application/xml"}};auto itr = _sd.find(suffix);if(itr != _sd.end()){return itr->second;}return"text/html";}
响应报文助手
voidBuildResponseHelper()// 响应行的封装 调用不同的响应报头的封装。{auto&code = hp_respond.status_code;
cout <<"构建响应时的状态码:"<< code << endl;// 响应行auto&line = hp_respond.respond_line;
line += HTTP_VERSION;
line +=" ";
line += std::to_string(hp_respond.status_code);
line +=" ";
line +=CodeDesc(hp_respond.status_code);
line += LINE_END;
string path = WEB_ROOT;
path +="/";
path += PAGE_404;switch(code){case OK:LOG(INFO,"OK page Return!!..");MakeOkRsponse();break;case NOT_FOUND:MakeErrorResponse(path);// 出错就返回web根目录下的404页面。break;case SERVER_ERROR:MakeErrorResponse(path);break;case BAD_REQUEST:MakeErrorResponse(path);break;default:break;// 1xx 2xx 3xx 4xx 5xx系列的状态码都可以设置一个响应页面}}
OK响应报文构建
voidMakeOkRsponse(){
string phead ="Content-Type: ";
phead +=SuffixDesc(hp_request.suffix);
phead += LINE_END;
hp_respond.respond_head.push_back(phead);
phead ="Content-Length: ";if(hp_request.cgi){
phead += std::to_string(hp_respond.respond_body.size());// cgi结果读到了body中。}else{
phead += std::to_string(hp_request.size);}
phead += LINE_END;
hp_respond.respond_head.push_back(phead);}
错误响应报文构建
voidMakeErrorResponse(string path){
hp_request.cgi =false;// CGI程序出错 退出码404后续发送就不读取body了// 返回404
cout <<"404 url-> .. "<< path.c_str()<< endl;
hp_respond.fd =open(path.c_str(), O_RDONLY);if(hp_respond.fd >0)//"Content-Type: text/html" "Content-Length: ";{structstat st;stat(path.c_str(),&st);
hp_request.size = st.st_size;
string line ="Content-Type: text/html";
line += LINE_END;
hp_respond.respond_head.push_back(line);
line ="Content-Length: ";
line += std::to_string(hp_request.size);
line += LINE_END;
hp_respond.respond_head.push_back(line);}}
发送响应报文
构建完响应后,我们就需要响应中的响应行,响应报头,响应空行,和响应正文依次发送给浏览器。在发送响应正文的时候,如果是cgi处理,cgi的处理结果已经放进响应正文中,所以直接将其发送给sock即可。
如果是非cgi处理(返回错误页面,返回请求网页)。之前未构建响应正文,但我们已经将需要返回的网页已经打开。所以在发送响应行,响应报头,响应空行后,我们最后再将文件中的内容发送出去。
voidHttpSendRespond()// 状态行填充了,响应报头也有了, 空行也有了,正文有了{send(sock, hp_respond.respond_line.c_str(), hp_respond.respond_line.size(),0);// 发送响应行for(auto it : hp_respond.respond_head){send(sock, it.c_str(), it.size(),0);// 响应报头}send(sock, hp_respond.blank.c_str(), hp_respond.blank.size(),0);// 空行if(hp_request.cgi){LOG(INFO,"HttpSendRespond cgi....");auto&response_body = hp_respond.respond_body;
ssize_t size =0;
size_t total =0;constchar*start = response_body.c_str();while(total < response_body.size()&&(size =send(sock, start + total, response_body.size()- total,0)>0)){
total += size;}}else{/* cout << "....." << hp_respond.fd << endl;
cout << "...." << hp_request.size << endl; */sendfile(sock, hp_respond.fd,nullptr, hp_request.size);// 静态网页close(hp_respond.fd);}}
错误处理
处理HTTP的时候,有两种类型的错误:
一、逻辑错误 - 读取完毕 - 要给对方回应。
二、读取错误 - 读取是否完毕,不一定 - 不给对方回应,退出即可。
如果是服务器处理的逻辑错误,例如创建子进程失败,http请求路径错误等,那么我们直接返回一个错误页面即可。如果是服务器在读http请求的时候,服务器读到一半请求,浏览器就将连接关掉。无意义的写入,浪费系统资源,写进程会被OS终止掉。HTTP进程收到一个SIGPIPE的信号,因此在初始化服务器的时候需要忽略该SIGPIPE信号。
staticvoid*Entry(void*_sock)//线程的回调{int sock =*(int*)_sock;delete(int*)_sock;LOG(INFO,"....CallBack()..begin...");
OppositeEnd *handle1 =newOppositeEnd(sock);
handle1->HttpRecvRequset();if(!handle1->IsStop()){LOG(INFO,"RecvRequset No Error");
handle1->HttpMakeRepsond();
handle1->HttpSendRespond();}else{LOG(ERROR,"RecvRequset Error !");}delete handle1;LOG(INFO,"...CallBack()...end...");}voidInitialize()// 初始化获取单例。sock.hpp不用暴露在外面。{signal(SIGPIPE, SIG_IGN);
tcp_svr =TcpServer::GetInstanc(_port);}
MakeFile
HTTP所在目录
bin=ht
cc=g++
LD_FLAGS=-std=c++11 -lpthread
curr =$(shell pwd)src=main.cc
.PHONY:ALL
ALL:$(bin) CGI
$(bin):$(src)$(cc)-o$@ $^ $(LD_FLAGS)
CGI:
cd$(curr)/cgi;\make;\cd -;
.PHONY:clean
clean:
rm-f$(bin)rm-rf output
cd$(curr)/cgi;\make clean;\cd -
.PHONY:output #新建项目发布的目录
output:
mkdir-p output
cp$(bin) output
cp-rf webroot output
cp ./cgi/tcg output/webroot
CGI目录下
.PHONY:ALL
ALL:tcg
tcg:test_cgi.cc
g++ -o$@ $^ -std=c++11
.PHONY:clean
clean:
rm-f tcg
自动化编译脚本 xxx.sh ;运行:./xxx.sh
#!/bin/bashmake clean
makemake output
线程池改造
如果来了海量的请求,那么需要海量线程,这样不但服务器效率降低,甚至导致http进程挂掉。解决方法就是:硬件不行加硬件,负载均衡等;软件不行加软件,epoll模式等。线程池是一个在硬件和软件中间做平衡的适中方案。
设计任务
Task.hpp:任务类
把此前单线程的回调函数所在的
class HandlerPetition
改造为回调类,增加一个仿函数。首先当线程池中的线程从任务队列中取到一个任务后,其次通过任务类中的接口,接着调用回调类对象的仿函数,与上面写的那一堆进行无缝衔接。
#pragmaonce#include"Protocol.hpp"classTaskQue{private:int _sock;
CallBack _handle;//回调对象public:TaskQue():_sock(-1){}TaskQue(int sock):_sock(sock){}voidMultitasking()//任务处理{_handle(_sock);}};
CallBack回调类
classCallBack{public:CallBack(){}voidoperator()(int sock){HandlerRequest(sock);}voidHandlerRequest(int sock){LOG(INFO,"....CallBack()..begin...");
OppositeEnd *handle1 =newOppositeEnd(sock);
handle1->HttpRecvRequset();if(!handle1->IsStop()){LOG(INFO,"RecvRequset No Error");
handle1->HttpMakeRepsond();
handle1->HttpSendRespond();}else{LOG(INFO,"RecvRequset Error !");}delete handle1;LOG(INFO,"...CallBack()...end...");};
HTTP服务器的循环获取新连接
voidLoopSever(){int listen_sock = tcp_svr->SockListen();while(!stop){structsockaddr_in peer;
socklen_t len =sizeof(peer);// 输出型参数,记录请求方的一些信息int sock =accept(listen_sock,(sockaddr *)&peer,&len);if(sock <0){continue;}// 需要线程去执行任务,传新获取到的sock的地址,在那里关闭sock/* int *psock = new int(sock);
pthread_t tid;
pthread_create(&tid, nullptr, HandlerPetition::Entry, psock);
pthread_detach(tid); */LOG(INFO,"Get a new link");
TaskQue t(sock);ThreadPool::GetSingleIns()->PushTask(t);}}
线程池
线程池是一个生产消费者模型,调用方向任务队列中放任务,创建的线程从任务队列中去任务。任务队列就是一个临界资源,消费者与消费者之间是互斥关系,生产者与消费者(同步与互斥的关系)。消费者来消费,等待生产者生产以后,才能消费;生产者,在没有消费者的同时,也在等待。一般会与懒汉模式相结合,形成一个单例模式的线程池。和套接字通信一样,是固定的套路
#include"Task.hpp"#include<queue>#defineNUM5classThreadPool{private:int _num;//bool _stop; //检测线程池是否在运行
std::queue<TaskQue> _taskque;
pthread_mutex_t _lock;
pthread_cond_t _cond;ThreadPool(int num = NUM):_num(num){pthread_mutex_init(&_lock,nullptr);pthread_cond_init(&_cond,nullptr);}ThreadPool(const ThreadPool &){}static ThreadPool *single_instance;public:static ThreadPool *GetSingleIns(){static pthread_mutex_t _mtx = PTHREAD_MUTEX_INITIALIZER;if(single_instance ==nullptr){pthread_mutex_lock(&_mtx);if(single_instance ==nullptr){
single_instance =newThreadPool();
single_instance->InitThreadPool();LOG(INFO,"ThreadPool *GetSingleIns()..Success");}pthread_mutex_unlock(&_mtx);}return single_instance;}voidLock(){pthread_mutex_lock(&_lock);}voidUnlock(){pthread_mutex_unlock(&_lock);}voidCondWait(){pthread_cond_wait(&_cond,&_lock);// 不满足某种条件时时释放锁 再将cond条件变量加锁 不占用任何CPU周期}voidCondSignal(){pthread_cond_signal(&_cond);// 该线程又自动获得该mutex。}boolIsEmpty(){return _taskque.size()==0?true:false;}voidPopTask(TaskQue &t){
t = _taskque.front();
_taskque.pop();}voidPushTask(const TaskQue& t)//生产消费互斥{Lock();
_taskque.push(t);Unlock();CondSignal();}staticvoid*HnadlerThread(void*tmp){pthread_detach(pthread_self());
ThreadPool *tpol =(ThreadPool *)tmp;while(true)//始终检测任务队列中是否有任务{
TaskQue t;
tpol->Lock();while(tpol->IsEmpty()){
tpol->CondWait();}// 不为空就pop,释放锁,处理任务
tpol->PopTask(t);
tpol->Unlock();LOG(INFO,"线程获取任务,前去处理。。");
t.Multitasking();}}boolInitThreadPool(){
pthread_t pid;for(size_t i =0; i < _num; i++){if(pthread_create(&pid,nullptr, HnadlerThread,this)!=0)// 失败返回错误码{LOG(FATAL,"create thread pool error!");returnfalse;}}LOG(INFO,"create thread pool success!");returntrue;}~ThreadPool(){pthread_mutex_destroy(&_lock);pthread_cond_destroy(&_cond);}};
ThreadPool *ThreadPool::single_instance =nullptr;
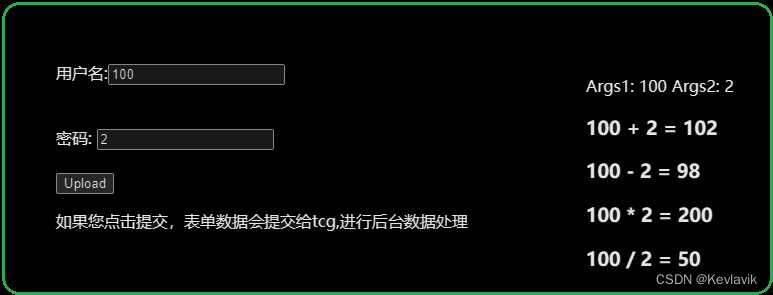
表单测试
了解前后端是如何结合到一起的。html里提供网页里都有啥:按钮、输入框等;css决定框的大小、按钮什么样式等等;js:按钮的动态效果等。
<!DOCTYPEhtml><html><head><metacharset="utf-8"></head><body><formaction="/tcg"method="POST">
用户名:<inputtype="text"name="Args1"><br><br><br>
密码: <inputtype="text"name="Args2"><br><br><inputtype="submit"value="Upload"></form><p>如果您点击提交,表单数据会提交给tcg,进行后台数据处理</p></body></html>
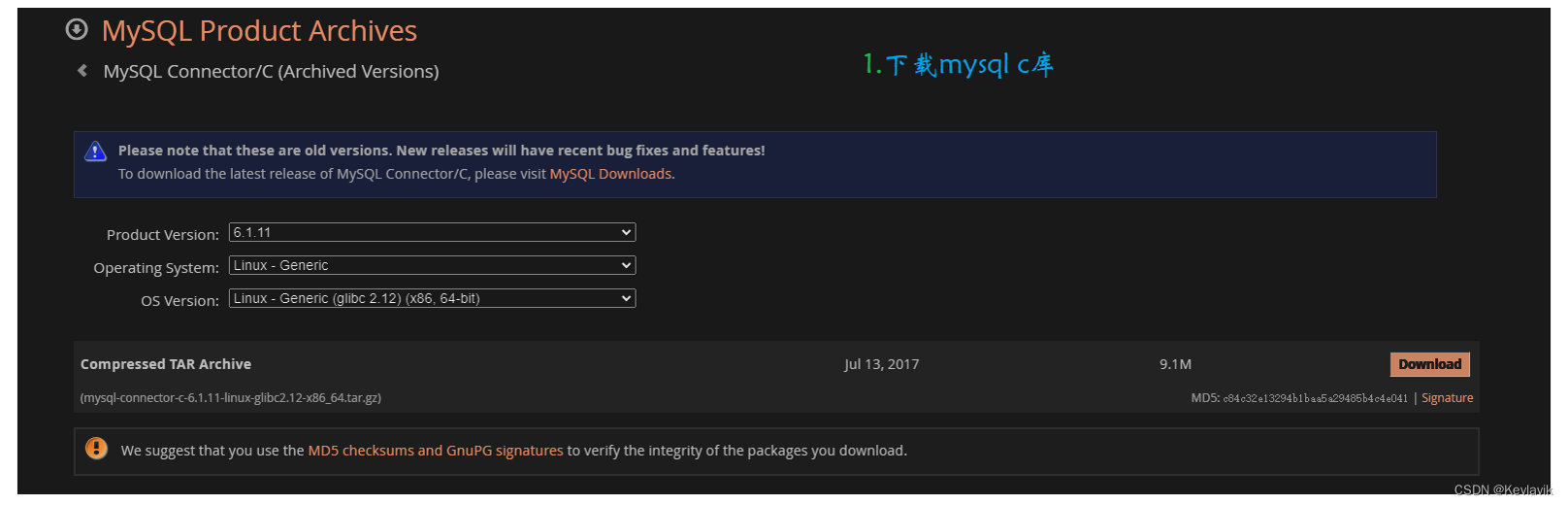
使用Mysql第三方库
1、官网下载mysql第三方库,历史版本6.1.11-Linux_通用,c库。
2、rz传到cgi目录下

3、 解压

4、查看解压好的库。开发只需要lib库文件、和include头文件;为了不影响使用,可以将其他文件删除



5、创建源文件以后,进行使用测试。
#include<iostream>#include"mysql.h"usingnamespace std;intmain(){
cout<<"mysql: .."<<mysql_get_client_info()<<endl;return0;}
6、动态链接
使用g++编译
g++ -o sql mysqlt1.cc -I include/ -L lib/ -lmysqlclient
前;需要将动态库所在的目录,添加到
LD_LIBRARY_PATH
环境变量。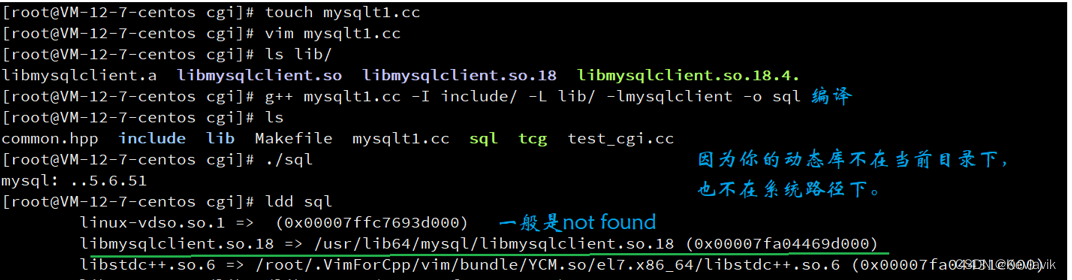

接下来试一试静态库,比较方便后期处理。
静态链接
使用:
g++ -o sql mysqlt1.cc -I include/ -L lib/ -lmysqlclient -lpthread -ldl -static
,可能依然会很多警告,可以忽略。
若是新系统,可能会有下面的报错:
解决:
还有安装c++的标准静态库:
yum install -y libstdc++-static
。
总结与参考
项目的重点在于HTTP服务器后端的处理逻辑,主要完成的是GET和POST请求方法,以及CGI机制的搭建。但依然有很多可扩展的内容,比如:其他请求方法、http/1.1、长连接、epoll模型、请求转发代理功能等等。
参考:
- 【(项目)Web服务器的实现】——自主实现一个Web服务器项目,通过该服务器搭建个人网站(保姆级教程),可写在简历上
- 【项目设计】自主HTTP服务器
- Linux:gcc编译器 | 动静态库的创建与使用
- Linux:基础I/O | FD文件描述符 | 重定向 | 文件系统 | 动、静态库的制作与使用
- Linux:进程管理 | 进程创建 | 进程终止 | 进程等待 | 进程替换
- Linux:多线程概念 | Windows下的线程 | 线程的优缺点 | 进程与线程 | 线程创建、终止、取消、等待、分离 | 原生线程库NPTL
- Linux网络:HTTP协议 | URL | 协议格式 | HTTP方法 | HTTP状态码 | Cookie与Session
版权归原作者 Kevlavik 所有, 如有侵权,请联系我们删除。