
chunjun 是一款基于flink的数据同步工具,支持多种数据源的source和sink。有四种方式,local方式、standalone、yarn session、yarn pre-job 。
详情官网链接:QuickStart | ChunJun 纯钧
由于flinkx更改了名字和打包脚本,但是官网文档并没有全部更新完整,阅读起来会有点困难;这里简单整理下,方便以后使用。
推荐官网的阅读顺序:
1. QuickStart | ChunJun 纯钧 本章节为快速入门,介绍了四种提交任务的方式,但命令是过时的不能用;
2. ChunJun 通用配置详解 | ChunJun 纯钧
3. Connectors 本章节为各种存储介质的source和 sink
下载和安装
官网有编译好的工具包,可以直接使用 :Releases · DTStack/chunjun · GitHub
该压缩包解压后包含4个目录,config目录是我单独创建的:

bin 目录:相比旧版的flinkx 封装了各个类型的脚本;下面这种方式可以放弃:
sh ./bin/flinkx -mode yarn-per-job -jobType sync -job $CHUNJUN_DIST/flinkx-examples/json/stream/stream.json -flinkxDistDir $CHUNJUN_DIST/flinkx-dist -flinkConfDir $FLINK_CONF_DIR -hadoopConfDir $HADOOP_CONF_DIR -flinkLibDir $FLINK_HOME/lib -jobName chunjun-pre-job
比如我想执行mysql 同步到hdfs;只需要增加一个 -job 参数即可,同理如果想执行其他提交方式,选择对应的脚本即可:
命令为:
sh bin/chunjun-local.sh -job config/mysql_hdfs_polling.json
执行该命令可能会出现取不到环境变量的问题,只需要手动添加到 bin/submit.sh,如下为手动添加的flink_home 和hadoop_home。
例如: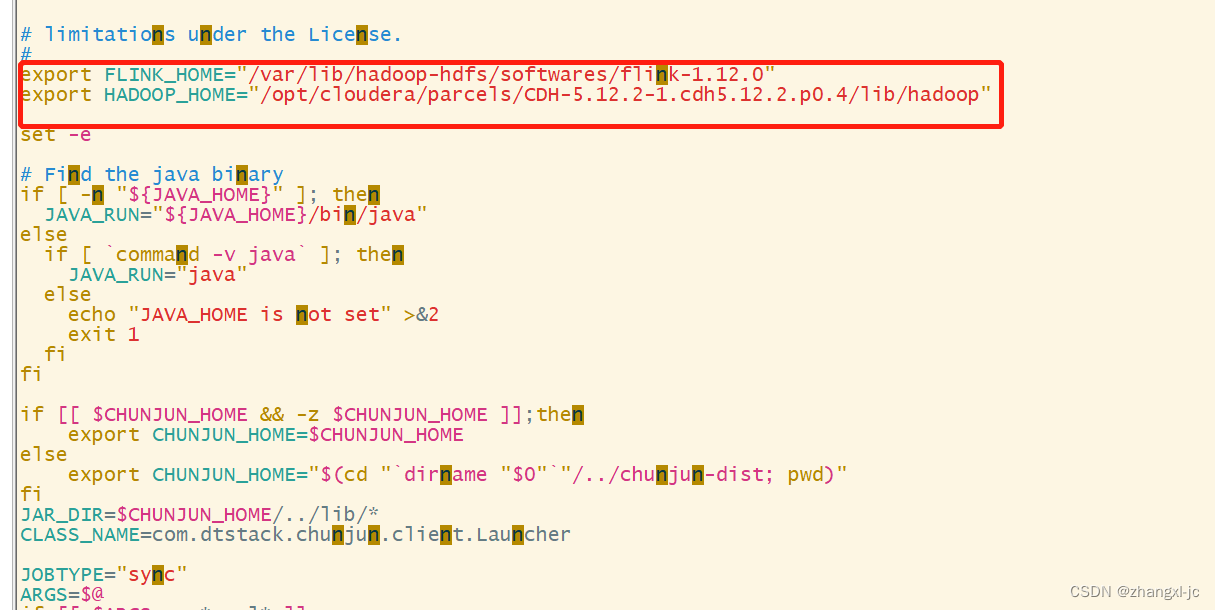
mysql 到hdfs 同步数据
采用的json 方式的配置文件为:
{
"job":{
"content":[
{
"reader":{
"name":"mysqlreader",
"parameter":{
"column":[
{
"name":"group_id",
"type":"varchar"
},
{
"name":"company_id",
"type":"varchar"
},
{
"name":"group_name",
"type":"varchar"
}
],
"username":"root",
"password":"123456",
"queryTimeOut":2000,
"connection":[
{
"jdbcUrl":[
"jdbc:mysql://192.168.33.23:5580/sobot_db?characterEncoding=UTF-8&autoReconnect=true&failOverReadOnly=false"
],
"table":[
"cus_group_info"
]
}
],
"polling":false,
"pollingInterval":3000
}
},
"writer":{
"name":"hdfswriter",
"parameter":{
"fileType":"text",
"path":"hdfs://192.168.33.92:8020/data/zjcTmp/sobot_db/",
"defaultFS":"192.168.33.92:8020",
"fileName":"cus_group_info",
"fieldDelimiter":",",
"encoding":"utf-8",
"writeMode":"overwrite",
"column":[
{
"name":"group_id",
"type":"VARCHAR"
},
{
"name":"company_id",
"type":"VARCHAR"
},
{
"name":"group_name",
"type":"VARCHAR"
}
]
}
}
}
],
"setting":{
"speed":{
"readerChannel":1,
"writerChannel":1
}
}
}
}
开始执行命令:
sh bin/chunjun-local.sh -job config/mysql_hdfs_polling.json
执行成功返回:
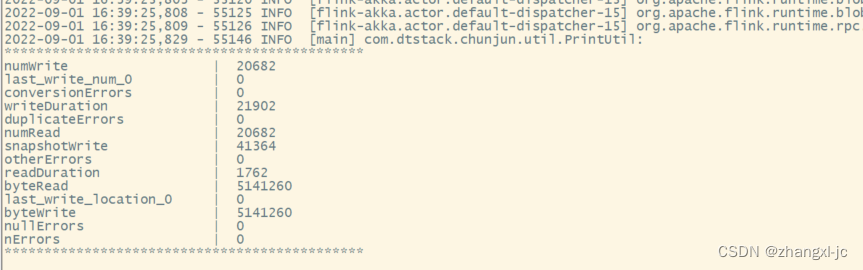
查看hdfs对应的目录,同步成功。

标签:
大数据
本文转载自: https://blog.csdn.net/zhangjiaxx/article/details/126645528
版权归原作者 zhangxl-jc 所有, 如有侵权,请联系我们删除。
版权归原作者 zhangxl-jc 所有, 如有侵权,请联系我们删除。