
📢📢📢📣📣📣
哈喽!大家好,我是【一心同学】,一位上进心十足的【Java领域博主】!😜😜😜
✨【一心同学】的写作风格:喜欢用【通俗易懂】的文笔去讲解每一个知识点,而不喜欢用【高大上】的官方陈述。
✨【一心同学】博客的领域是【面向后端技术】的学习,未来会持续更新更多的【后端技术】以及【学习心得】。
✨如果有对【后端技术】感兴趣的【小可爱】,欢迎关注【一心同学】💞💞💞
❤️❤️❤️感谢各位大可爱小可爱!❤️❤️❤️
一、为什么需要集群?
在我们的实际开发当中,只使用一台Redis运用于工程项目中是不可以的,原因如下:
(1)从结构上,单个Redis服务器会发生单点故障,并且一台服务器需要处理所有的请求负载,压力较大;
(2)从容量上,单个Redis服务器内存容量有限,就算一台Redis服务器内存容量为256G,也不能将所有内存用作Redis存储内存,一般来说,单台Redis最大使用内存不应该超过20G。
(3)单台Redis服务器的读写性能有限,利用集群可以提高读写能力。
二、主从模式
🌴 介绍
目前,Redis有三种集群模式,分别是:主从模式,哨兵模式,Cluster模式;主从模式是三种模式中最简单的,在主从复制中,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master/leader),后者称为从节点(slave/follower)。
🔥 注意:
(1)数据的复制是单向的,只能由主节点到从节点。Master以写为主,Slave 以读为主。
(2)默认情况下,每台Redis服务器都是主节点;
(3)一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。

🌴 作用
1、数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
2、故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
3、高可用(集群)基石:主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
4、负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
例如在我们的电商网站可以发现,对于一个商品只需要上传一次,但其却能够被用户浏览多次,也就是“写少读多”这种情况,我们可以利用主从复制进行读写分离,减缓服务器的压力:
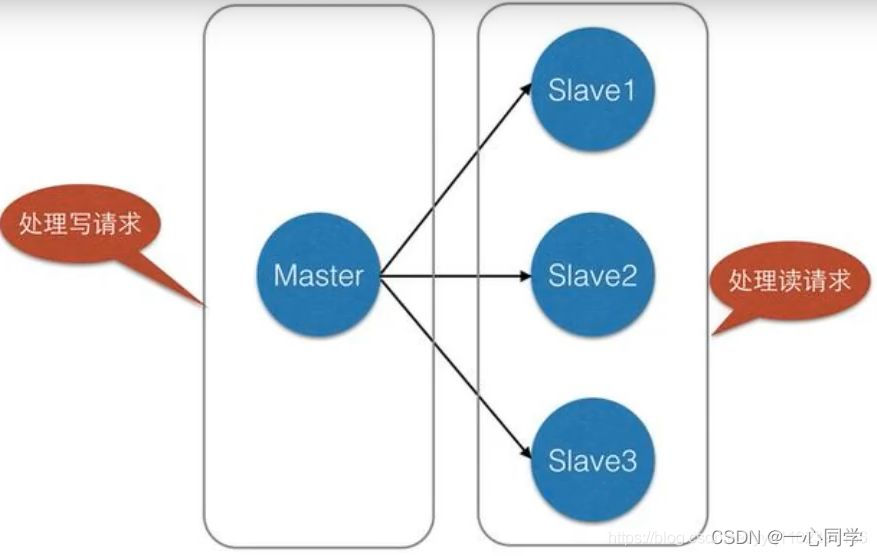
三、搭建主从集群
3.1、准备工作
1、复制三个配置文件(原名:redis.conf),并分别重命名为:redis79.conf,redis80.conf,redis81.conf。

2、修改配置文件
(1)修改redis79.conf
修改端口号
port 6379
设置为后台运行
daemonize:yes
设置日志文件的名字
logfile “6379.log"
设置db文件名字
dbfilename dump6379.rdb
(2)修改redis80.conf
修改端口号
port 6380
** 设置为后台运行**
daemonize:yes
设置记录进程Id文件名字
pidfile /var/run/redis_6380.pid
** 设置日志文件的名字**
logfile “6380.log"
设置db文件名字
dbfilename dump6380.rdb
(3)修改redis81.conf
修改端口号
port 6381
设置为后台运行
daemonize:yes
设置记录进程Id文件名字
pidfile /var/run/redis_6381.pid
** 设置日志文件的名字**
logfile “6381.log"
设置db文件名字
dbfilename dump6381.rdb
这几个属性的作用如下:
pid(port ID):记录了进程的 ID,文件带有锁。可以防止程序的多次启动。
logfile:明确日志文件的位置
dbfilename:dumpxxx.file #持久化文件位置
port:进程占用的端口号
3.2、搭建一主二从
🌵 启动Redis服务器
注意:默认情况下,每台Reids服务器都是主节点,而我们要搭建主从只需要在从机那本搭建即可。
现在分别启动redis79,redis80,redis81服务器。
redis-server redis79.conf
redis-server redis80.conf
redis-server redis81.conf
使用以下命令,查看是否启动成功:
ps -ef|grep redis

打开三个客户端窗口,分别对应操作三个Redis服务器。
输入命令:
注意要指定端口,才知道我们要打开哪一个Redis。
窗口一:
redis-cli -p 6379
窗口二:
redis-cli -p 6380
窗口三:
redis-cli -p 6381
🌵 设置主从关系
我们将redis79设置为主节点,而将redis80和redis81设置为从结点。
配置主机的IP地址和端口号,相当于想认其为自己的老大。
** redis80:**
#SLAVEOF IP地址 端口
127.0.0.1:6380> slaveof 127.0.0.1 6379
OK
redis81:
#SLAVEOF IP地址 端口
127.0.0.1:6381> slaveof 127.0.0.1 6379
OK
这个时候,我们在从机使用INFO命令就可以查看主从关系了:
info replication
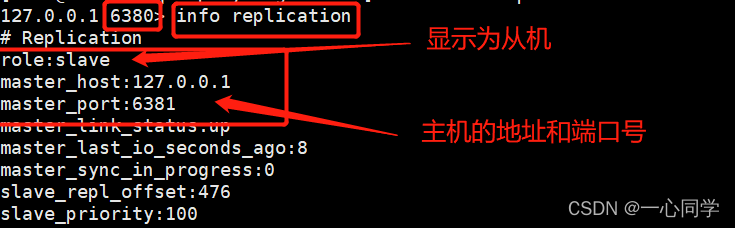
而此时我们去主机redis79中使用同样的命令进行查看:
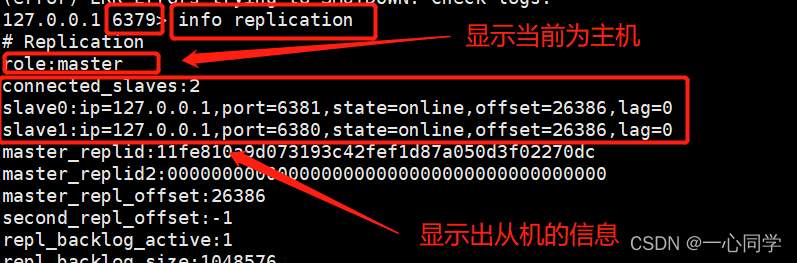
现在我们的一主二从的关系就成功搭建好了!
提示:如果要将从机变成主机,我们只需要在从机执行以下命令,即可让自己变为主机。
SLAVEOF no one
四、知识讲解
🔥 知识一
**主机可以进行读写操作,而从机只能读操作。 **
注意:主机中的所有信息和数据,都会自动被从机保存。
主机:
127.0.0.1:6379> set key1 v1
OK
127.0.0.1:6379> get key1
"v1"
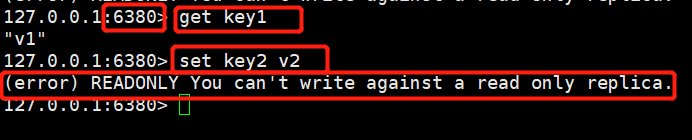
从机:
127.0.0.1:6380> get key1
"v1"
127.0.0.1:6380> set key2 v2 #进行写操作就会报错,提示从机只能进行读操作
(error) READONLY You can't write against a read only replica.
🔥 知识二
主机如果宕机了,从机依旧可以读取到主机宕机前的数据,但仍然没有写操作,如果主机恢复过来了,从机依旧可以获取到主机写的数据。
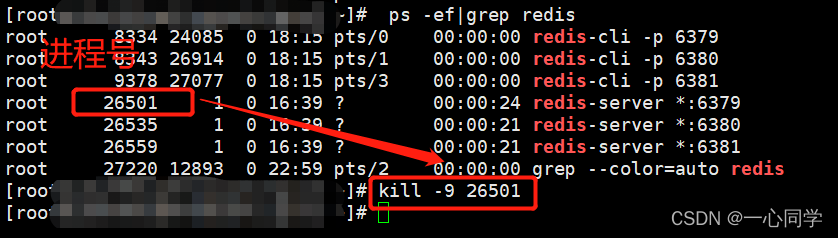
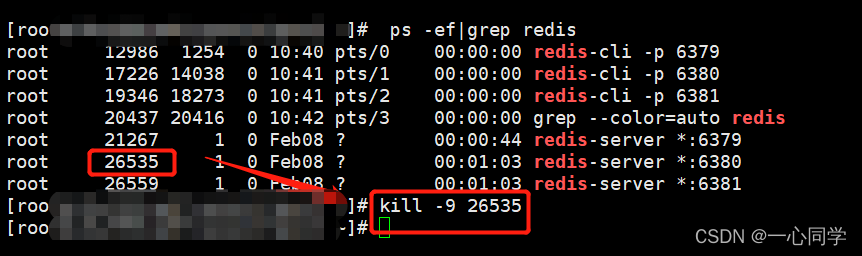
(1)停止主机进程(演示主机宕机了)
停止进程的命令:
kill -9 pid #pid为redis进程号
(2)从机获取宕机前主机写入的数据
可以发现,能够顺利拿到,但仍然是无法进行写操作的。
** (3)恢复主机**
redis-server redis79.conf
(4)主机重新写入数据,从机获取最新数据。
主机写入数据:
127.0.0.1:6379> set k2 yixin
OK
从机读取最新数据:
127.0.0.1:6380> get k2
"yixin"
🔥 知识三
两种配置方式下的从机断开情况
a、命令行设置主从关系
从机断开了,其重新连接后变为主机,能拿到断开之前的数据,但拿不到主机新写入的值,如果重新设置主从关系,就可以拿到主机全部的数据了。
(1)停止从机进程。
** (2)主机写入新数据。**
127.0.0.1:6379> set k3 new
OK
(3)重新启动从机服务器。
redis-server redis80.conf
(4)尝试获取从机宕机前主机写入的数据,发现可以拿到。
127.0.0.1:6380> get k1
"v1"
(5)尝试获取从机宕机期间主机写入的数据,发现无法拿到了。
127.0.0.1:6380> get k3
(nil)
此次我们可以进行查看主从关系,由于是命令行配置的,所以重启之后又变回主机了。
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
**(6)如果要拿到主机的所有数据,只要执行以下命令重新配置主从关系就可以了。 **
slaveof 127.0.0.1 6379
b、配置文件设置的主从关系
从机断开后,重新连接,也是可以拿到主机的全部数据的。
(1)修改配置文件redis80.conf,添加主从关系。
#指定主机的ip与port
slaveof 127.0.0.1 6379
(2)主机添加新数据
127.0.0.1:6379> set k5 hello
OK
(3)重新启动redis80服务器。
redis-server redis80.conf
(4)获取从机宕机期间主机新写入的数据,发现现在可以顺利拿到了。
127.0.0.1:6380> get k5
"hello"
我们来查看6380的主从关系,可以发现在重启的时候就已经设置好主从关系了。

五、复制原理
(1)Slave 启动成功连接到 Master 后会发送一个sync同步命令
(2)Master 接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
(3)全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
(4)增量复制:Master 继续将新的所有收集到的修改命令依次传给slave,完成同步。
注意:只要是重新连接master,一次完全同步(全量复制)将被自动执行! 我们的数据一定可以在从机中看到。
六、主从模式的优缺点
🌵 优点
(1)同一个Master可以同步多个Slaves。
(2)Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。因此我们可以将Redis的Replication架构视为图结构。
(3)Master Server是以非阻塞的方式为Slaves提供服务。所以在Master-Slave同步期间,客户端仍然可以提交查询或修改请求。
(4)Slave Server同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据。
(5)为了分载Master的读操作压力,Slave服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成。即便如此,系统的伸缩性还是得到了很大的提高。
(6)Master可以将数据保存操作交给Slaves完成,从而避免了在Master中要有独立的进程来完成此操作。
(7)支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
🌵 缺点
(1) Redis 主从模式不具备自动容错和恢复功能,如果主节点宕机,Redis 集群将无法工作,此时需要人为干预,将从节点提升为主节点。
(2) 如果主机宕机前有一部分数据未能及时同步到从机,即使切换主机后也会造成数据不一致的问题,从而降低了系统的可用性。
(3) 因为只有一个主节点,所以其写入能力和存储能力都受到一定程度地限制。
(4) 在进行数据全量同步时,若同步的数据量较大可能会造卡顿的现象。
小结
以上就是【一心同学】对【Redis集群】的【主从模式】讲解,利用【主从模式】我们可以实现【读写分离】,让服务器【分压运作】,这样可以让我们的网站更加【稳定】,但其也存在不住,就是主节点宕机后,Redis集群将无法工作,需要【人为干预】,将从结点提升为主节点,对于这个问题的解决方案,【一心同学】将会在下一篇博客【哨兵模式】中进行讲解。
如果这篇【文章】有帮助到你,希望可以给【一心同学】点个赞👍,创作不易,相比官方的陈述,我更喜欢用【通俗易懂】的文笔去讲解每一个知识点,如果有对【后端技术】感兴趣的小可爱,也欢迎关注❤️❤️❤️ 【一心同学】❤️❤️❤️,我将会给你带来巨大的【收获与惊喜】💕💕!
版权归原作者 一心同学 所有, 如有侵权,请联系我们删除。