
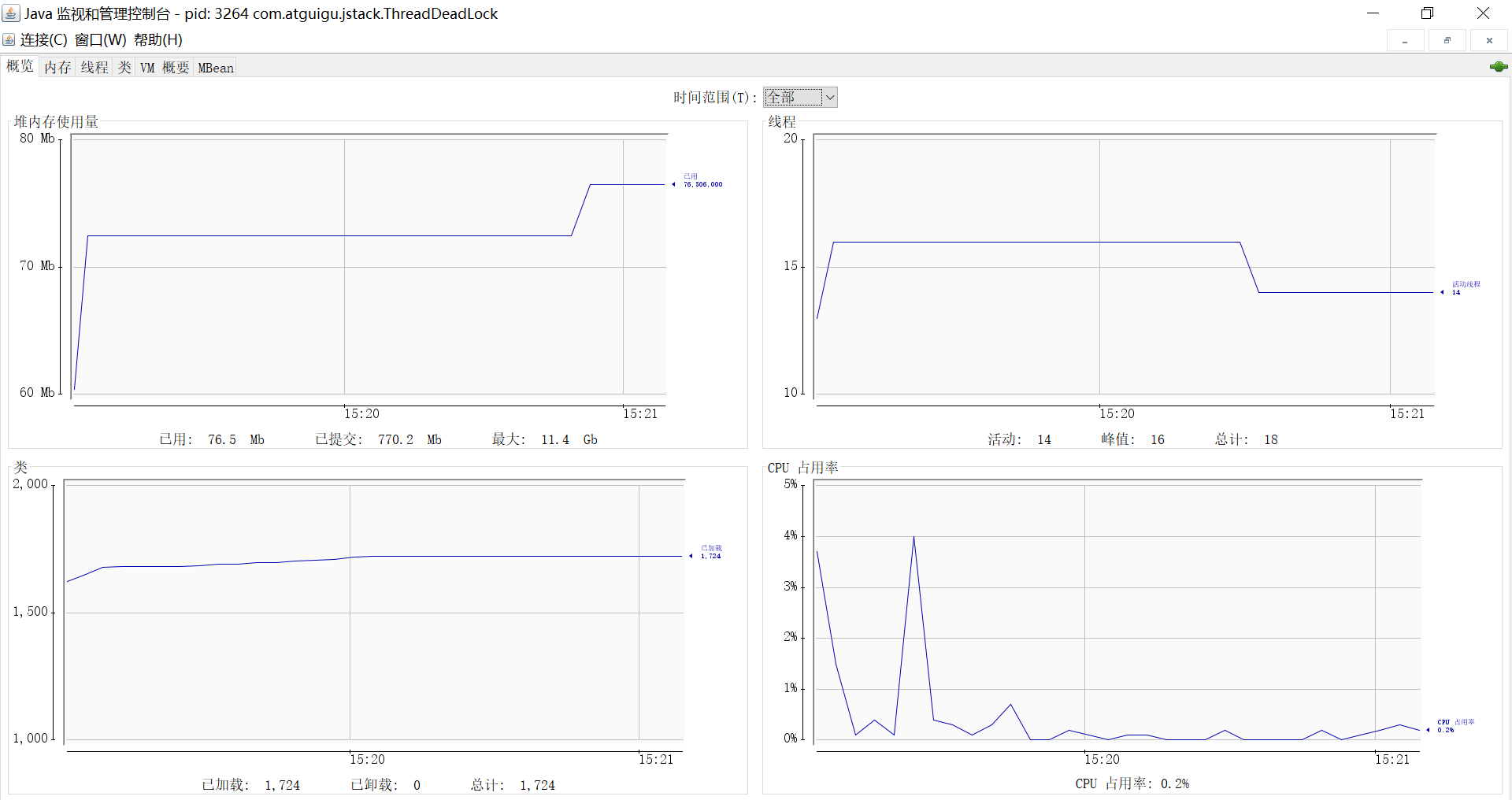
1、JConsole
jconsole:从Java5开始,在JDK中自带的java监控和管理控制台。用于对JVM中内存、线程和类等的监控,是一个基于JMX(java management extensions)的GUI性能监控工具。
官方地址:https://docs.oracle.com/javase/7/docs/technotes/guides/management/jconsole.html
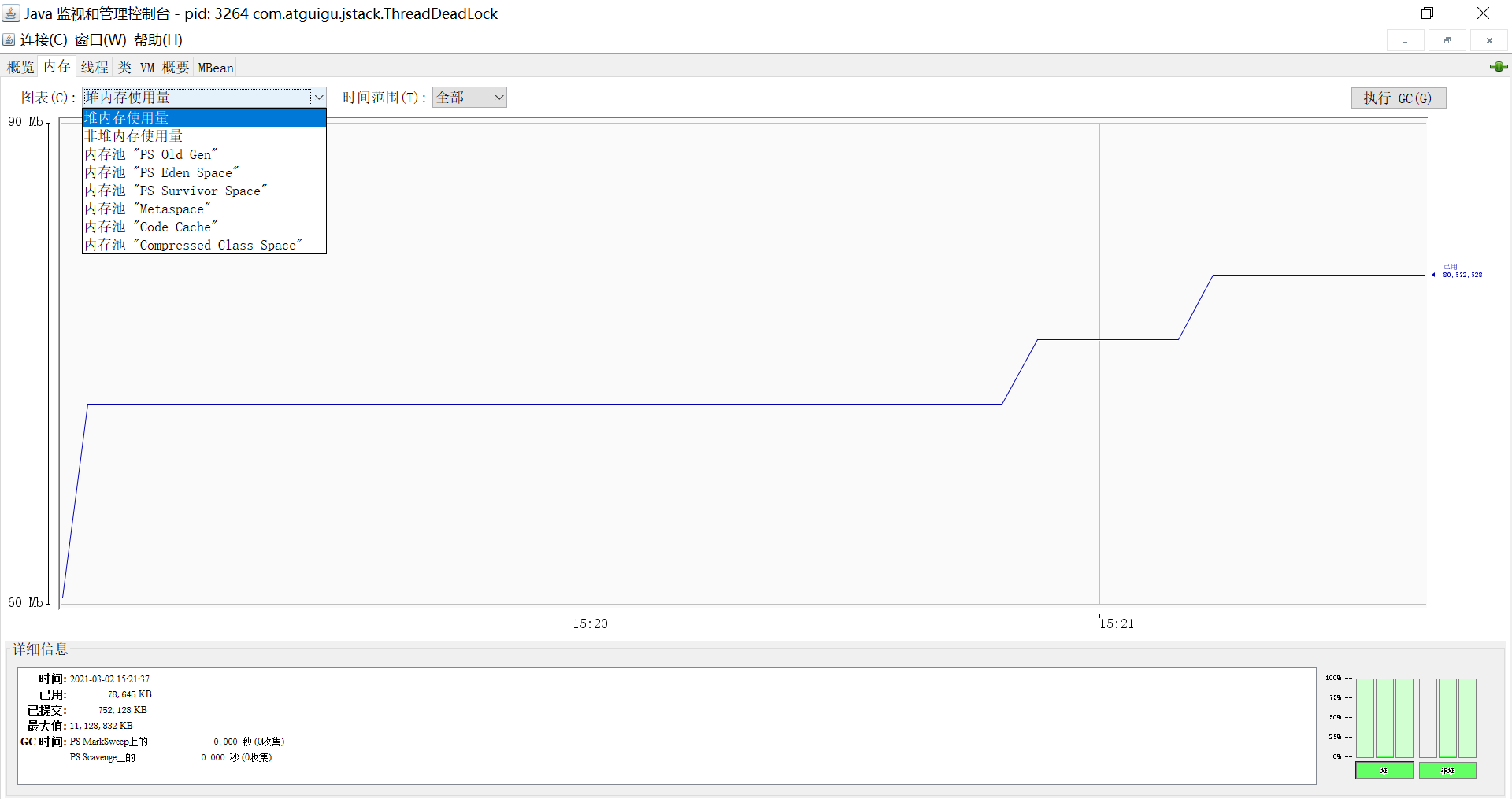
2、Visual VM
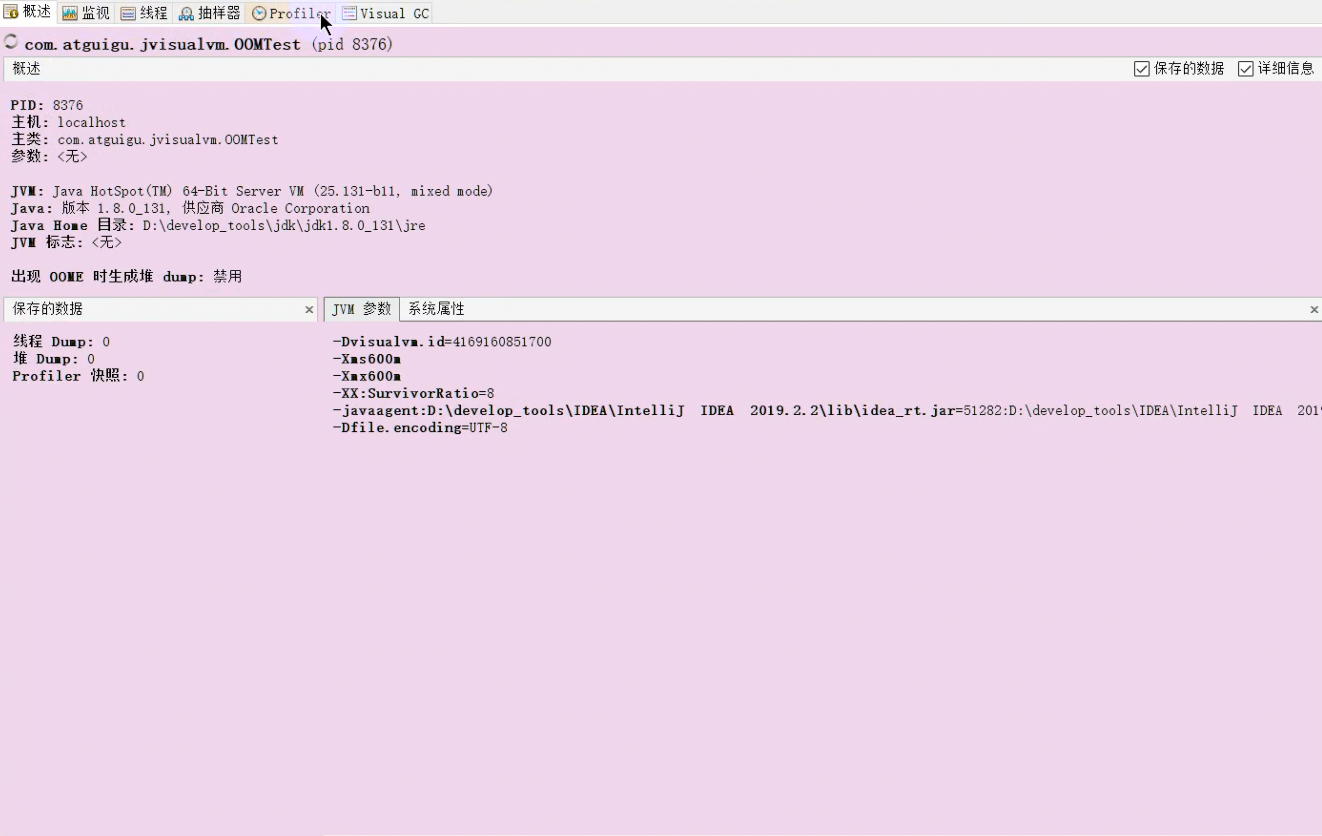
Visual VM是一个功能强大的多合一故障诊断和性能监控的可视化工具。它集成了多个JDK命令行工具,使用Visual VM可用于显示虚拟机进程及进程的配置和环境信息(jps,jinfo),监视应用程序的CPU、GC、堆、方法区及线程的信息(jstat、jstack)等,甚至代替JConsole。在JDK 6 Update 7以后,Visual VM便作为JDK的一部分发布(VisualVM 在JDK/bin目录下)即:它完全免费。
主要功能:
1.生成/读取堆内存/线程快照
2.查看JVM参数和系统属性
3.查看运行中的虚拟机进程
4.程序资源的实时监控
5.JMX代理连接、远程环境监控、CPU分析和内存分析
官方地址:VisualVM: Home

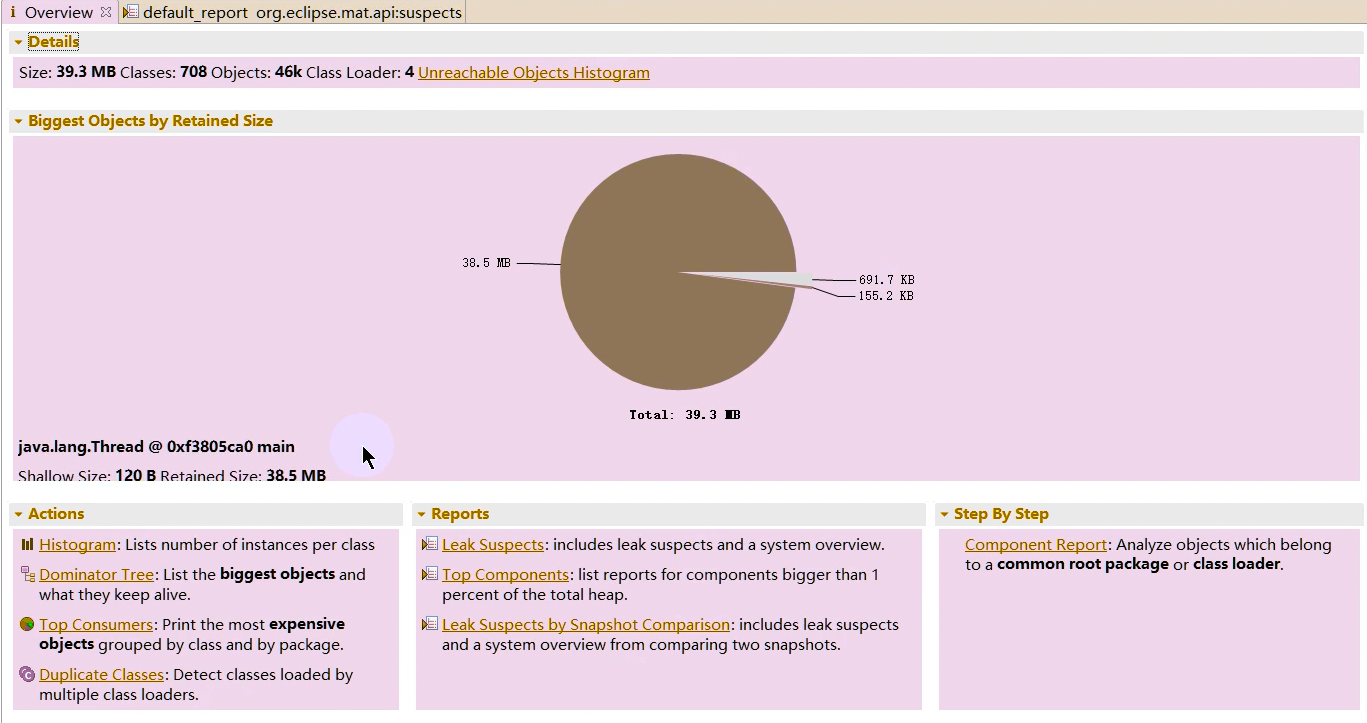
3、Eclipse MAT
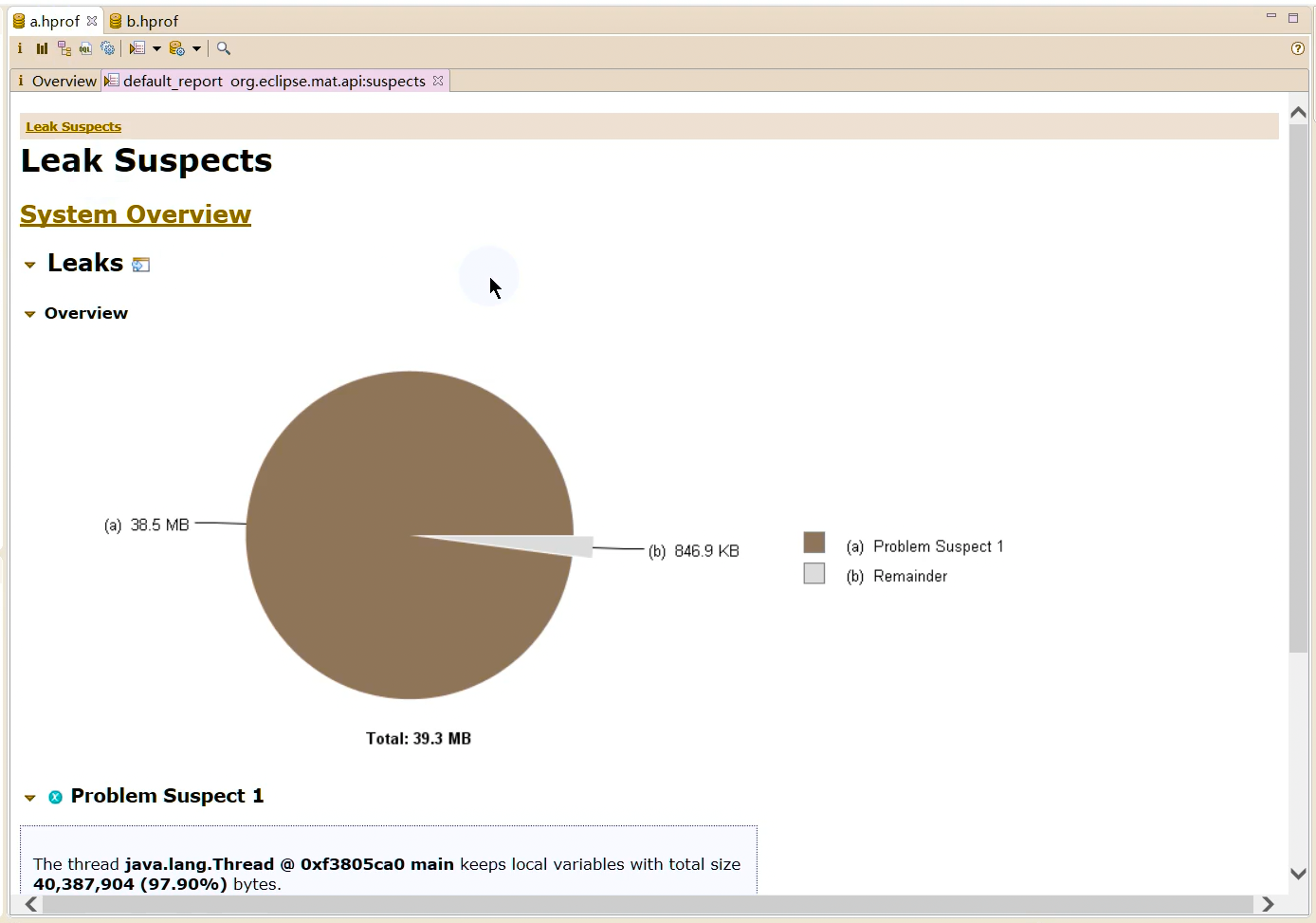
MAT(Memory Analyzer Tool)工具是一款功能强大的Java堆内存分析器。可以用于查找内存泄漏以及查看内存消耗情况。MAT是基于Eclipse开发的,不仅可以单独使用,还可以作为插件的形式嵌入在Eclipse中使用。是一款免费的性能分析工具,使用起来非常方便。
MAT可以分析heap dump文件。在进行内存分析时,只要获得了反映当前设备内存映像的hprof文件,通过MAT打开就可以直观地看到当前的内存信息。一般说来,这些内存信息包含:
所有的对象信息,包括对象实例、成员变量、存储于栈中的基本类型值和存储于堆中的其他对象的引用值。
所有的类信息,包括classloader、类名称、父类、静态变量等
GCRoot到所有的这些对象的引用路径
线程信息,包括线程的调用栈及此线程的线程局部变量(TLS)
MAT 不是一个万能工具,它并不能处理所有类型的堆存储文件。但是比较主流的厂家和格式,例如Sun,HP,SAP 所采用的 HPROF 二进制堆存储文件,以及 IBM的 PHD 堆存储文件等都能被很好的解析。
最吸引人的还是能够快速为开发人员生成内存泄漏报表,方便定位问题和分析问题。虽然MAT有如此强大的功能,但是内存分析也没有简单到一键完成的程度,很多内存问题还是需要我们从MAT展现给我们的信息当中通过经验和直觉来判断才能发现。
官方地址: Eclipse Memory Analyzer Open Source Project | The Eclipse Foundation
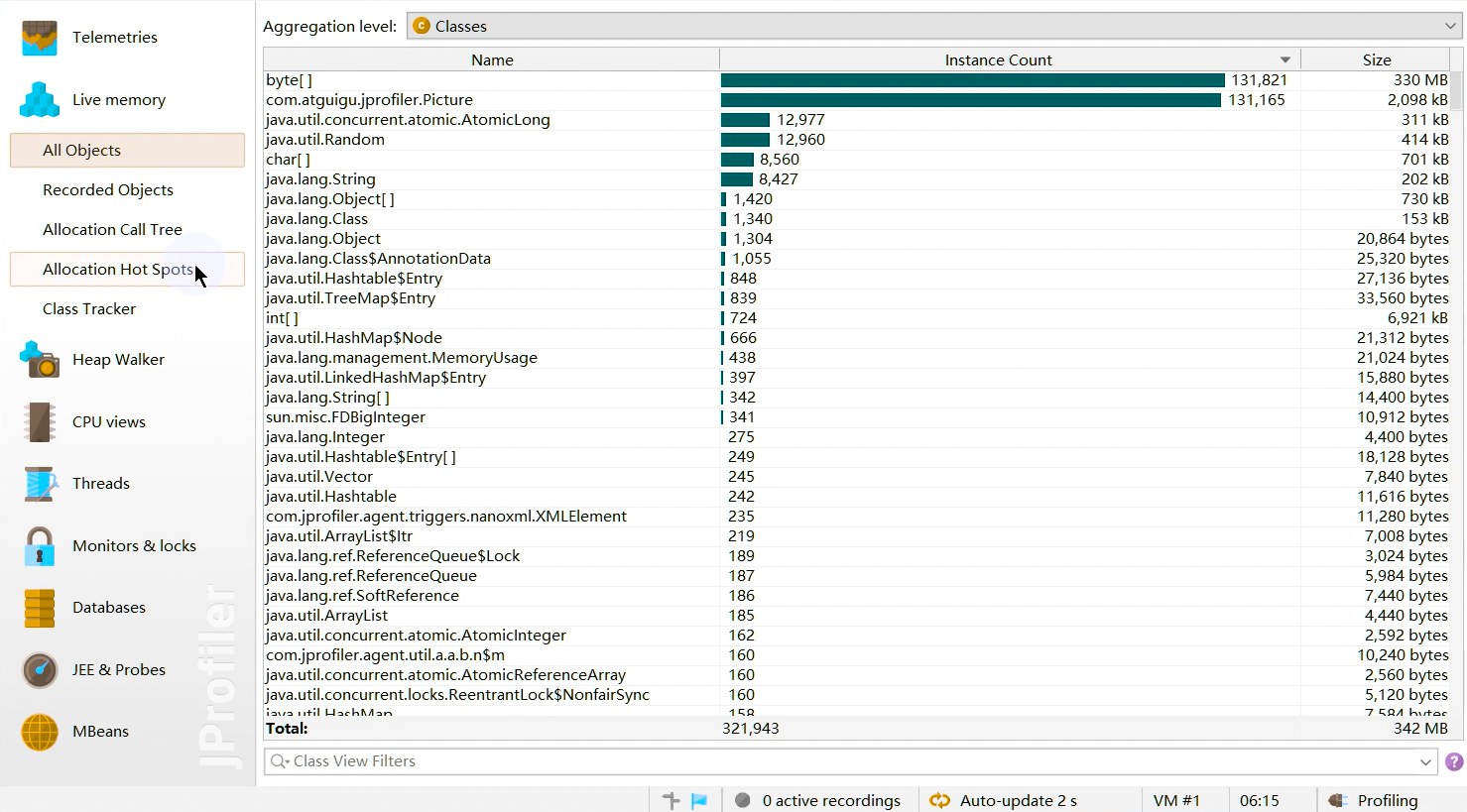
4、JProfiler
在运行Java的时候有时候想测试运行时占用内存情况,这时候就需要使用测试工具查看了。在eclipse里面有 Eclipse Memory Analyzer tool(MAT)插件可以测试,而在IDEA中也有这么一个插件,就是JProfiler。JProfiler 是由 ej-technologies 公司开发的一款 Java 应用性能诊断工具。功能强大,但是收费。
特点:
使用方便、界面操作友好(简单且强大)
对被分析的应用影响小(提供模板)
CPU,Thread,Memory分析功能尤其强大
支持对jdbc,noSql,jsp,servlet,socket等进行分析
支持多种模式(离线,在线)的分析
支持监控本地、远程的JVM
跨平台,拥有多种操作系统的安装版本
主要功能:
1-方法调用:对方法调用的分析可以帮助您了解应用程序正在做什么,并找到提高其性能的方法
2-内存分配:通过分析堆上对象、引用链和垃圾收集能帮您修复内存泄露问题,优化内存使用
3-线程和锁:JProfiler提供多种针对线程和锁的分析视图助您发现多线程问题
4-高级子系统:许多性能问题都发生在更高的语义级别上。例如,对于JDBC调用,您可能希望找出执行最慢的SQL语句。JProfiler支持对这些子系统进行集成分析
官网地址:Java Profiler - JProfiler
数据采集方式:
JProfier数据采集方式分为两种:Sampling(样本采集)和Instrumentation(重构模式)
Instrumentation:这是JProfiler全功能模式。在class加载之前,JProfier把相关功能代码写入到需要分析的class的bytecode中,对正在运行的jvm有一定影响。
优点:功能强大。在此设置中,调用堆栈信息是准确的。
缺点:若要分析的class较多,则对应用的性能影响较大,CPU开销可能很高(取决于Filter的控制)。因此使用此模式一般配合Filter使用,只对特定的类或包进行分析
Sampling:类似于样本统计,每隔一定时间(5ms)将每个线程栈中方法栈中的信息统计出来。
优点:对CPU的开销非常低,对应用影响小(即使你不配置任何Filter)
缺点:一些数据/特性不能提供(例如:方法的调用次数、执行时间)
注:JProfiler本身没有指出数据的采集类型,这里的采集类型是针对方法调用的采集类型。因为JProfiler的绝大多数核心功能都依赖方法调用采集的数据,所以可以直接认为是JProfiler的数据采集类型。
遥感监测 Telemetries
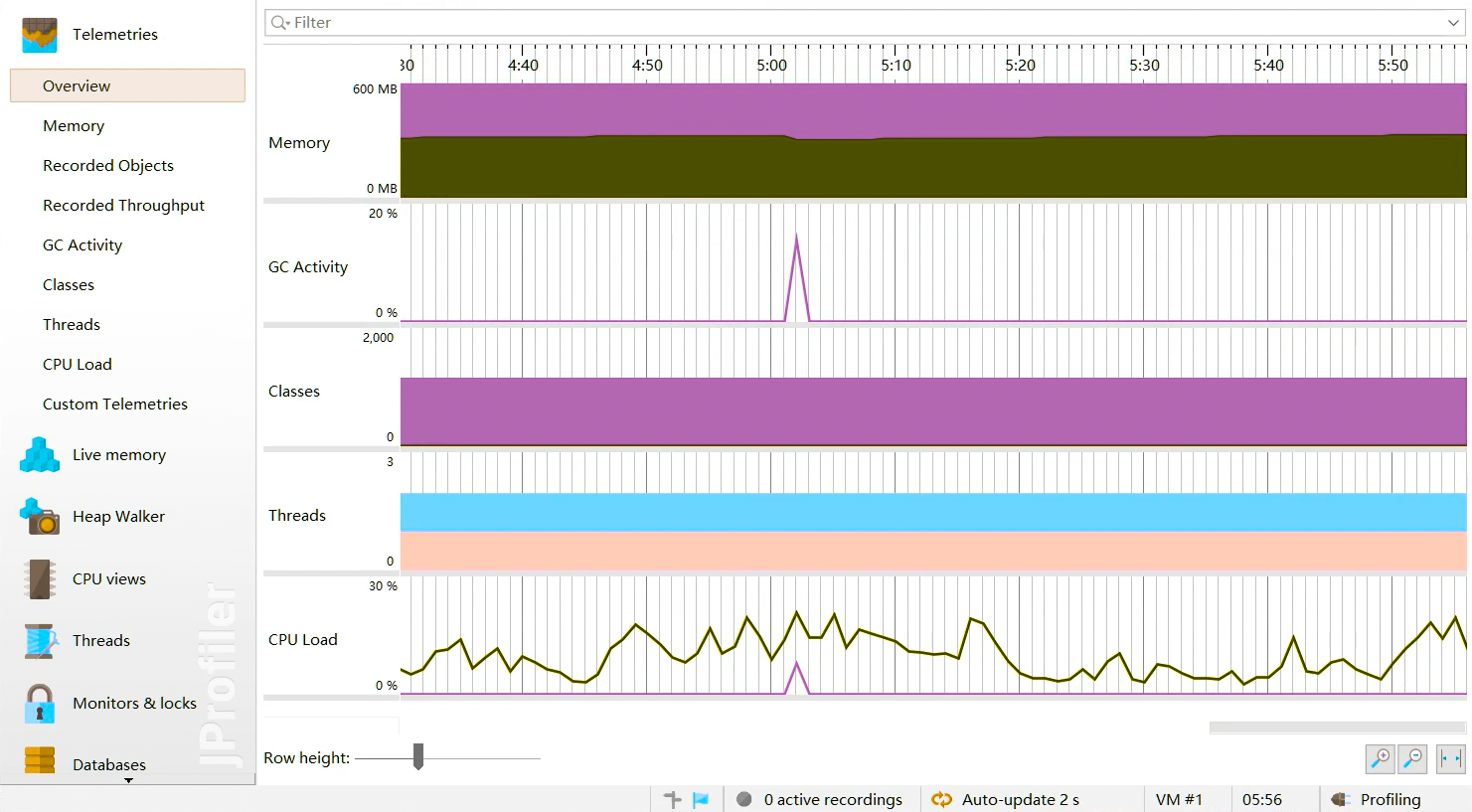
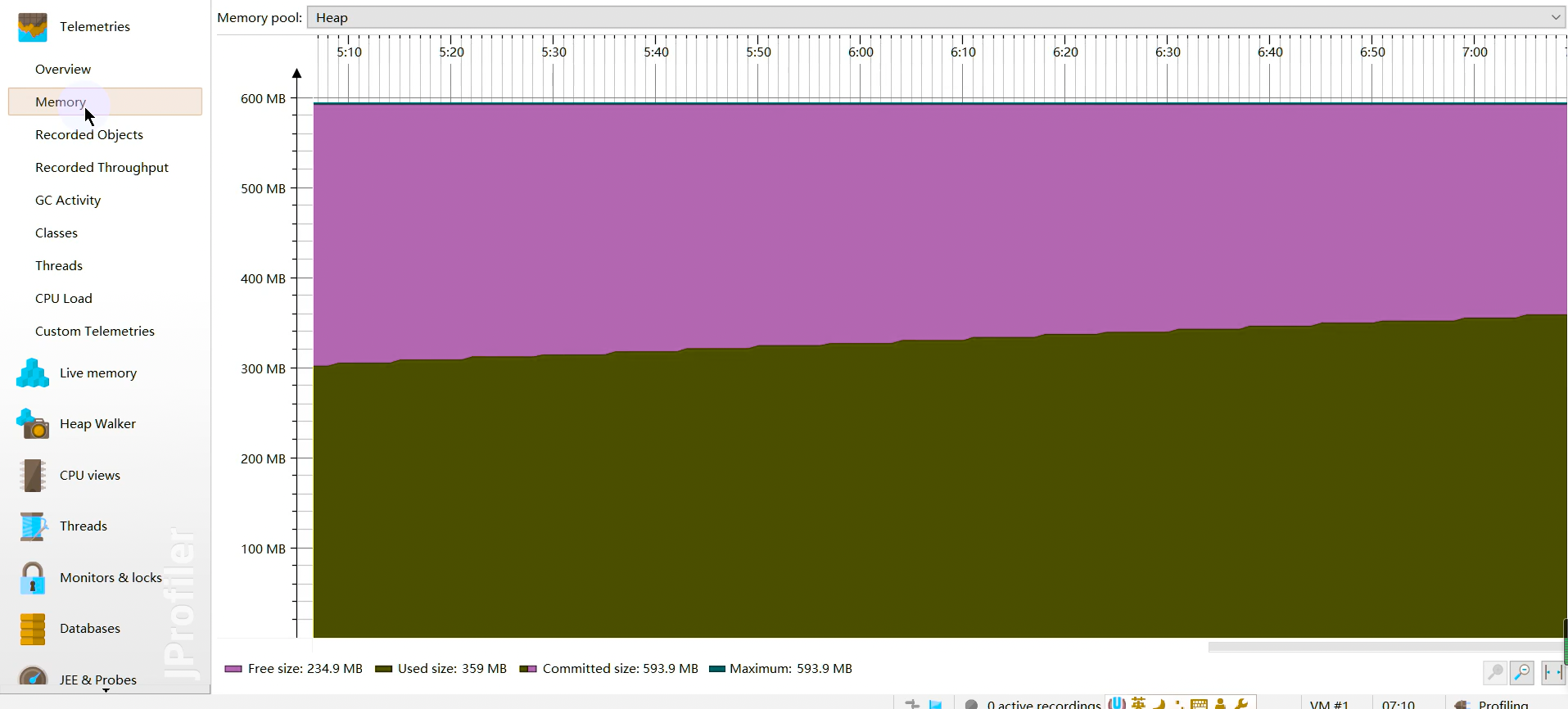
内存视图 Live Memory
Live memory 内存剖析:class/class instance的相关信息。例如对象的个数,大小,对象创建的方法执行栈,对象创建的热点。
所有对象 All Objects:显示所有加载的类的列表和在堆上分配的实例数。只有Java 1.5(JVMTI)才会显示此视图。
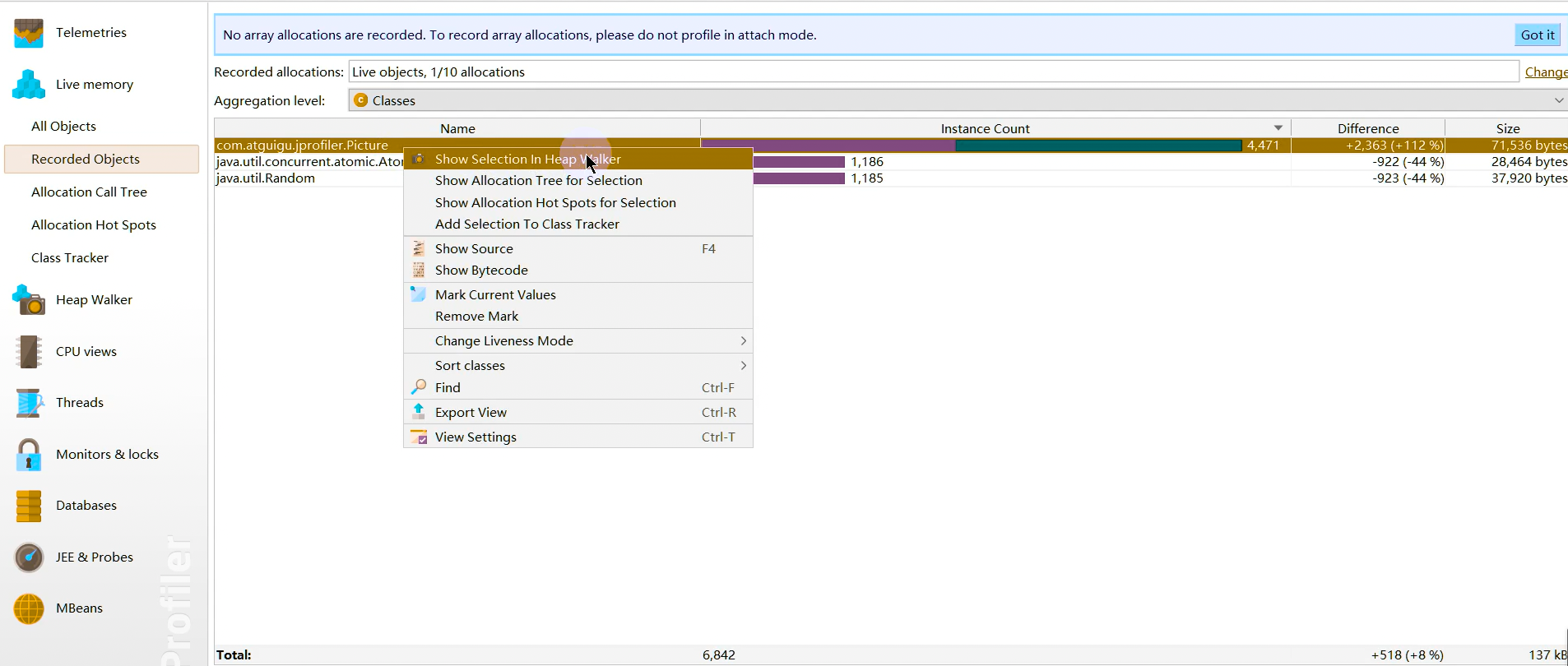
记录对象 Record Objects:查看特定时间段对象的分配,并记录分配的调用堆栈。
分配访问树 Allocation Call Tree:显示一棵请求树或者方法、类、包或对已选择类有带注释的分配信息的J2EE组件。
分配热点 Allocation Hot Spots:显示一个列表,包括方法、类、包或分配已选类的J2EE组件。你可以标注当前值并且显示差异值。对于每个热点都可以显示它的跟踪记录树。
类追踪器 Class Tracker:类跟踪视图可以包含任意数量的图表,显示选定的类和包的实例与时间。
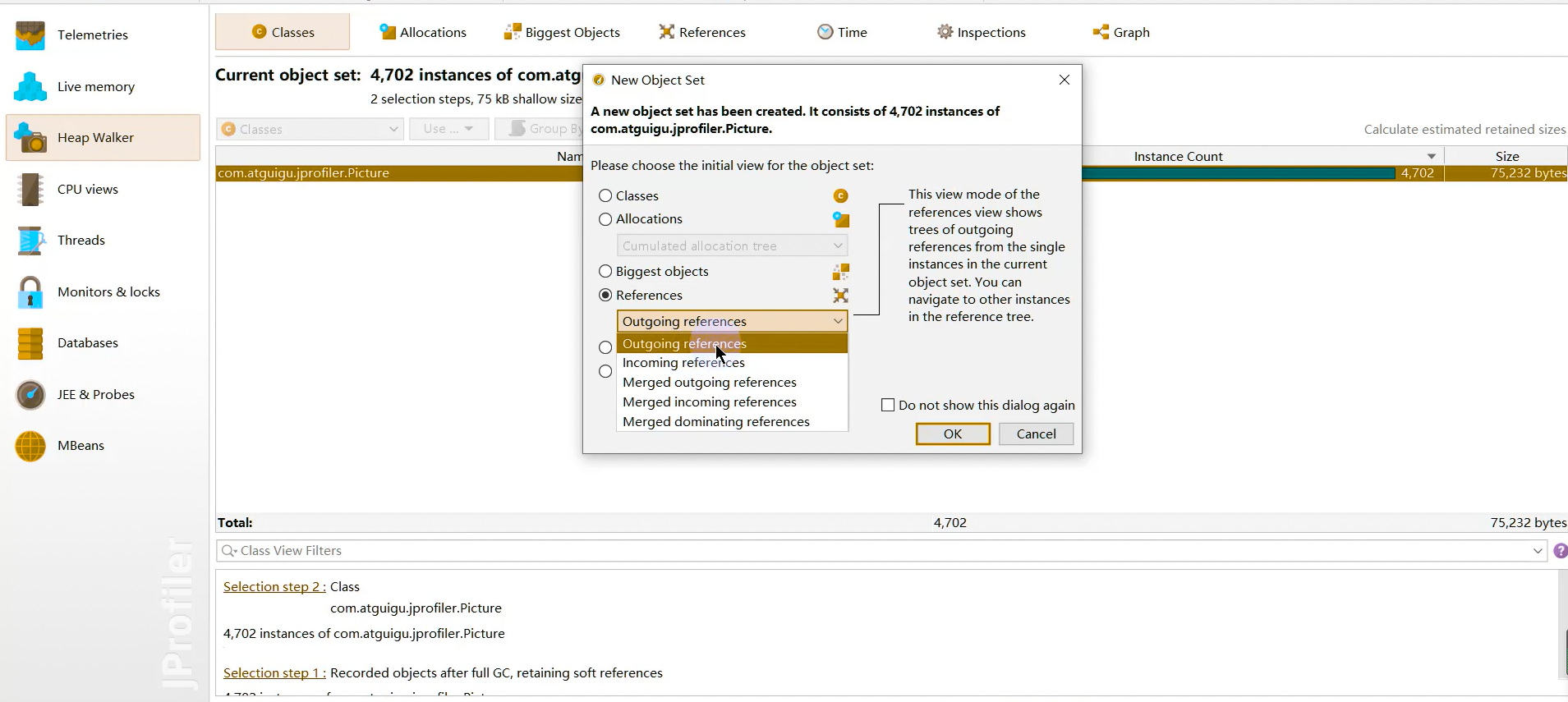
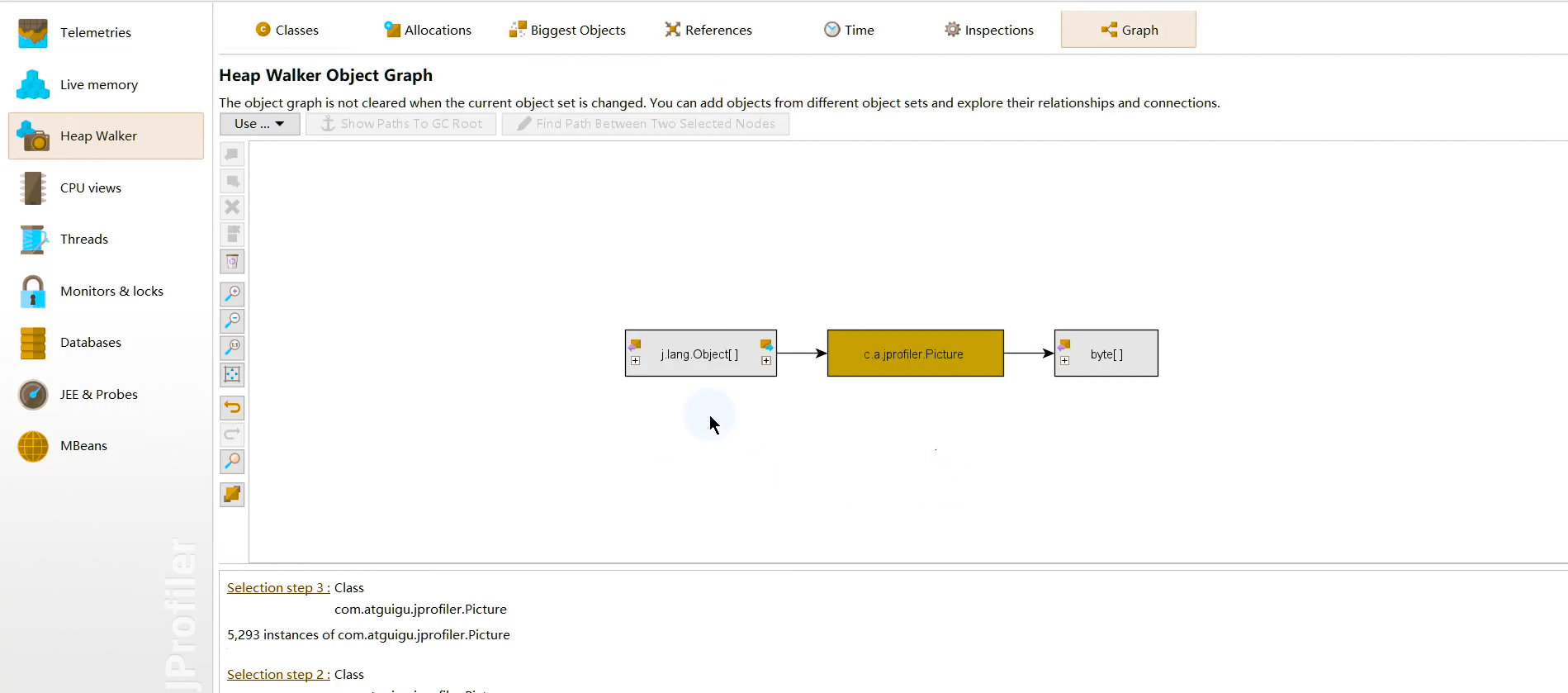
堆遍历 heap walker
cpu视图 cpu views
JProfiler 提供不同的方法来记录访问树以优化性能和细节。线程或者线程组以及线程状况可以被所有的视图选择。所有的视图都可以聚集到方法、类、包或J2EE组件等不同层上。
访问树 Call Tree:显示一个积累的自顶向下的树,树中包含所有在JVM中已记录的访问队列。JDBC,JMS和JNDI服务请求都被注释在请求树中。请求树可以根据Servlet和JSP对URL的不同需要进行拆分。
热点 Hot Spots:显示消耗时间最多的方法的列表。对每个热点都能够显示回溯树。该热点可以按照方法请求,JDBC,JMS和JNDI服务请求以及按照URL请求来进行计算。
访问图 Call Graph:显示一个从已选方法、类、包或J2EE组件开始的访问队列的图。
方法统计 Method Statistis:显示一段时间内记录的方法的调用时间细节。
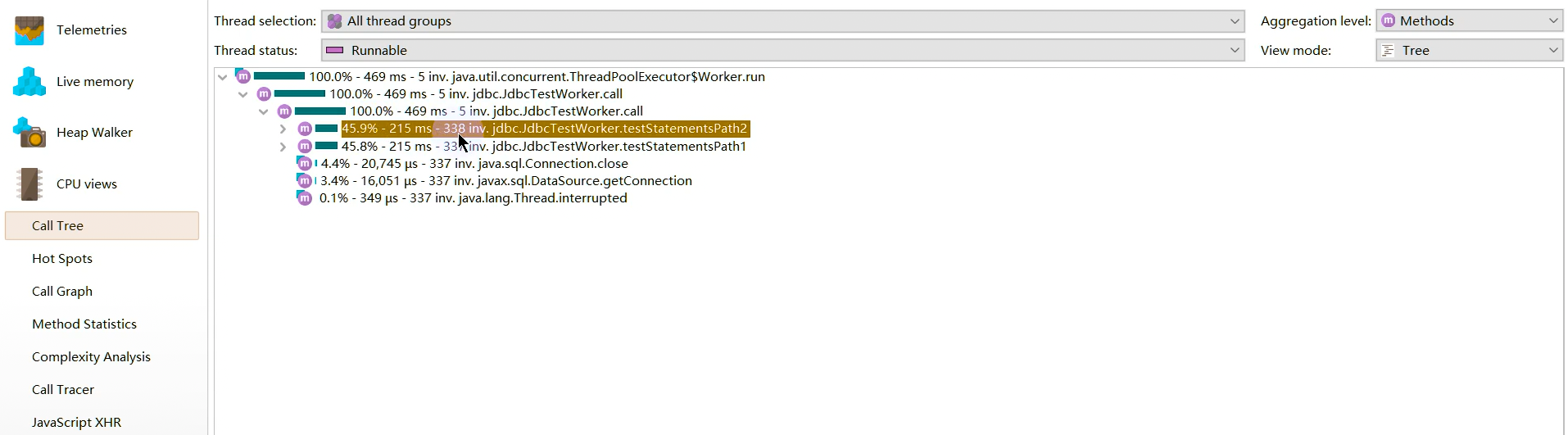
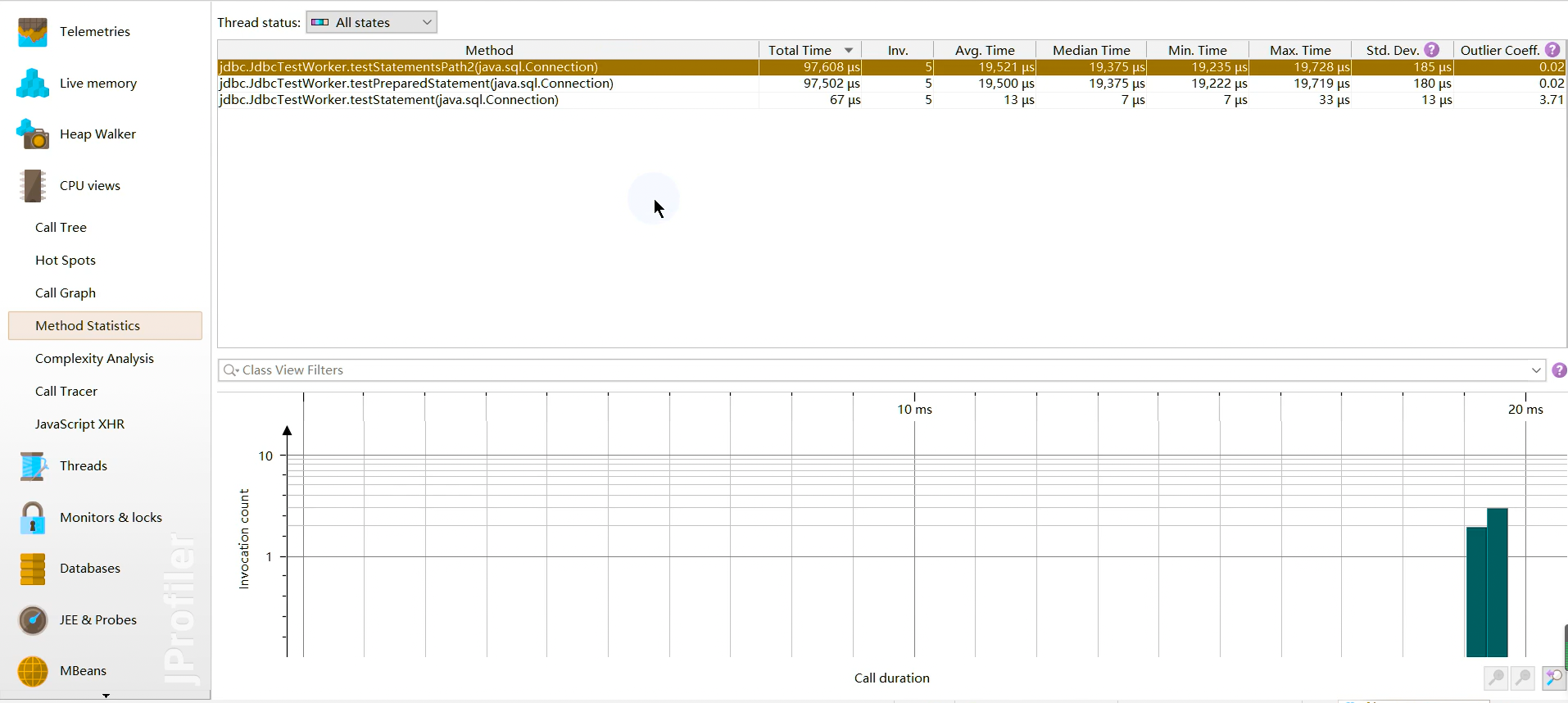
线程视图 threads
JProfiler通过对线程历史的监控判断其运行状态,并监控是否有线程阻塞产生,还能将一个线程所管理的方法以树状形式呈现。对线程剖析。
线程历史 Thread History:显示一个与线程活动和线程状态在一起的活动时间表。
线程监控 Thread Monitor:显示一个列表,包括所有的活动线程以及它们目前的活动状况。
线程转储 Thread Dumps:显示所有线程的堆栈跟踪。
线程分析主要关心三个方面:
1.web容器的线程最大数。比如:Tomcat的线程容量应该略大于最大并发数。
2.线程阻塞
3.线程死锁
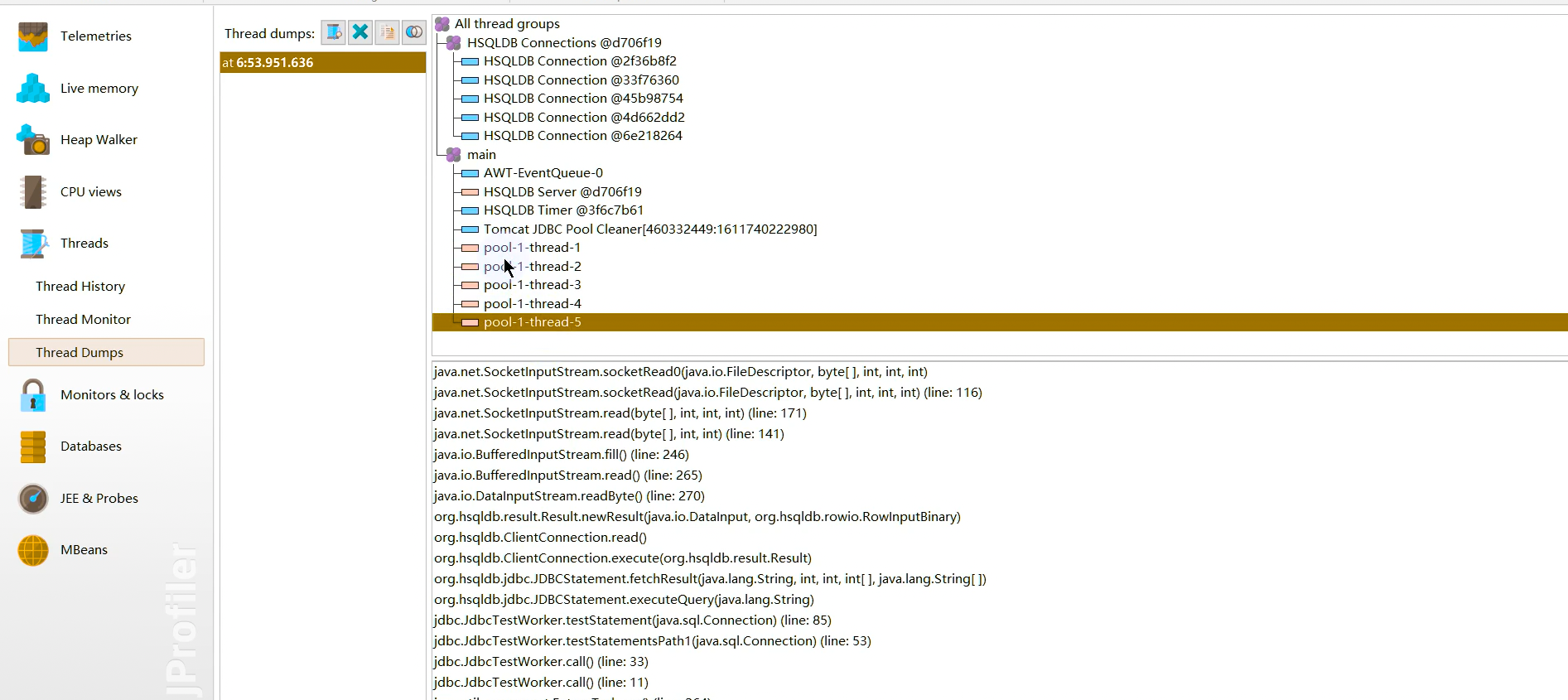
监控和锁 Monitors &Locks
所有线程持有锁的情况以及锁的信息。观察JVM的内部线程并查看状态:
死锁探测图表 Current Locking Graph:显示JVM中的当前死锁图表。
目前使用的监测器 Current Monitors:显示目前使用的监测器并且包括它们的关联线程。
锁定历史图表 Locking History Graph:显示记录在JVM中的锁定历史。
历史检测记录 Monitor History:显示重大的等待事件和阻塞事件的历史记录。
监控器使用统计 Monitor Usage Statistics:显示分组监测,线程和监测类的统计监测数据
5、Arthas
上述工具都必须在服务端项目进程中配置相关的监控参数,然后工具通过远程连接到项目进程,获取相关的数据。这样就会带来一些不便,比如线上环境的网络是隔离的,本地的监控工具根本连不上线上环境。并且类似于Jprofiler这样的商业工具,是需要付费的。
那么有没有一款工具不需要远程连接,也不需要配置监控参数,同时也提供了丰富的性能监控数据呢?
阿里巴巴开源的性能分析神器Arthas应运而生。
Arthas是Alibaba开源的Java诊断工具,深受开发者喜爱。在线排查问题,无需重启;动态跟踪Java代码;实时监控JVM状态。Arthas 支持JDK 6+,支持Linux/Mac/Windows,采用命令行交互模式,同时提供丰富的 Tab 自动补全功能,进一步方便进行问题的定位和诊断。当你遇到以下类似问题而束手无策时,Arthas可以帮助你解决:
这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
是否有一个全局视角来查看系统的运行状况?
有什么办法可以监控到JVM的实时运行状态?
怎么快速定位应用的热点,生成火焰图?
官方地址:快速入门 | arthas
安装方式:如果速度较慢,可以尝试国内的码云Gitee下载。
wget https://io/arthas/arthas-boot.jar
wget https://arthas/gitee/io/arthas-boot.jar
Arthas只是一个java程序,所以可以直接用java -jar运行。
除了在命令行查看外,Arthas目前还支持 Web Console。在成功启动连接进程之后就已经自动启动,可以直接访问 http://127.0.0.1:8563/ 访问,页面上的操作模式和控制台完全一样。
基础指令
quit/exit 退出当前 Arthas客户端,其他 Arthas喜户端不受影响
stop/shutdown 关闭 Arthas服务端,所有 Arthas客户端全部退出
help 查看命令帮助信息
cat 打印文件内容,和linux里的cat命令类似
echo 打印参数,和linux里的echo命令类似
grep 匹配查找,和linux里的gep命令类似
tee 复制标隹输入到标准输出和指定的文件,和linux里的tee命令类似
pwd 返回当前的工作目录,和linux命令类似
cls 清空当前屏幕区域
session 查看当前会话的信息
reset 重置增强类,将被 Arthas增强过的类全部还原, Arthas服务端关闭时会重置所有增强过的类
version 输出当前目标Java进程所加载的 Arthas版本号
history 打印命令历史
keymap Arthas快捷键列表及自定义快捷键
jvm相关
dashboard 当前系统的实时数据面板
thread 查看当前JVM的线程堆栈信息
jvm 查看当前JVM的信息
sysprop 查看和修改JVM的系统属性
sysem 查看JVM的环境变量
vmoption 查看和修改JVM里诊断相关的option
perfcounter 查看当前JVM的 Perf Counter信息
logger 查看和修改logger
getstatic 查看类的静态属性
ognl 执行ognl表达式
mbean 查看 Mbean的信息
heapdump dump java heap,类似jmap命令的 heap dump功能
class/classloader相关
sc 查看JVM已加载的类信息
-d 输出当前类的详细信息,包括这个类所加载的原始文件来源、类的声明、加载的Classloader等详细信息。如果一个类被多个Classloader所加载,则会出现多次
-E 开启正则表达式匹配,默认为通配符匹配
-f 输出当前类的成员变量信息(需要配合参数-d一起使用)
-X 指定输出静态变量时属性的遍历深度,默认为0,即直接使用toString输出
sm 查看已加载类的方法信息
-d 展示每个方法的详细信息
-E 开启正则表达式匹配,默认为通配符匹配
jad 反编译指定已加载类的源码
mc 内存编译器,内存编译.java文件为.class文件
retransform 加载外部的.class文件, retransform到JVM里
redefine 加载外部的.class文件,redefine到JVM里
dump dump已加载类的byte code到特定目录
classloader 查看classloader的继承树,urts,类加载信息,使用classloader去getResource
-t 查看classloader的继承树
-l 按类加载实例查看统计信息
-c 用classloader对应的hashcode来查看对应的 Jar urls
monitor/watch/trace相关
monitor 方法执行监控,调用次数、执行时间、失败率
-c 统计周期,默认值为120秒
watch 方法执行观测,能观察到的范围为:返回值、抛出异常、入参,通过编写groovy表达式进行对应变量的查看
-b 在方法调用之前观察(默认关闭)
-e 在方法异常之后观察(默认关闭)
-s 在方法返回之后观察(默认关闭)
-f 在方法结束之后(正常返回和异常返回)观察(默认开启)
-x 指定输岀结果的属性遍历深度,默认为0
trace 方法内部调用路径,并输出方法路径上的每个节点上耗时
-n 执行次数限制
stack 输出当前方法被调用的调用路径
tt 方法执行数据的时空隧道,记录下指定方法每次调用的入参和返回信息,并能对这些不同的时间下调用进行观测
其他
jobs 列出所有job
kill 强制终止任务
fg 将暂停的任务拉到前台执行
bg 将暂停的任务放到后台执行
grep 搜索满足条件的结果
plaintext 将命令的结果去除ANSI颜色
wc 按行统计输出结果
options 查看或设置Arthas全局开关
profiler 使用async-profiler对应用采样,生成火焰图
6、Java Misssion Control
在Oracle收购Sun之前,Oracle的JRockit虚拟机提供了一款叫做 JRockit Mission Control 的虚拟机诊断工具。
在Oracle收购sun之后,Oracle公司同时拥有了Hotspot和 JRockit 两款虚拟机。根据Oracle对于Java的战略,在今后的发展中,会将JRokit的优秀特性移植到Hotspot上。其中一个重要的改进就是在Sun的JDK中加入了JRockit的支持。
在Oracle JDK 7u40之后,Mission Control这款工具己经绑定在Oracle JDK中发布。
自Java11开始,本节介绍的JFR己经开源。但在之前的Java版本,JFR属于Commercial Feature通过Java虚拟机参数-XX:+UnlockCommercialFeatures 开启。
Java Mission Control(简称JMC) , Java官方提供的性能强劲的工具,是一个用于对 Java应用程序进行管理、监视、概要分析和故障排除的工具套件。它包含一个GUI客户端以及众多用来收集Java虚拟机性能数据的插件如 JMX Console(能够访问用来存放虚拟机齐个于系统运行数据的MXBeans)以及虚拟机内置的高效 profiling 工具 Java Flight Recorder(JFR)。
JMC的另一个优点就是:采用取样,而不是传统的代码植入技术,对应用性能的影响非常非常小,完全可以开着JMC来做压测(唯一影响可能是 full gc 多了)。
官方地址:GitHub - JDKMissionControl/jmc: This mirror is deprecated - please start using https://github.com/openjdk/jmc
Java Flight Recorder
Java Flight Recorder是JMC的其中一个组件,能够以极低的性能开销收集Java虚拟机的性能数据。与其他工具相比,JFR的性能开销很小,在默认配置下平均低于1%。JFR能够直接访问虚拟机内的敌据并且不会影响虚拟机的优化。因此它非常适用于生产环境下满负荷运行的Java程序。
Java Flight Recorder 和 JDK Mission Control共同创建了一个完整的工具链。JDK Mission Control 可对 Java Flight Recorder 连续收集低水平和详细的运行时信息进行高效、详细的分析。
当启用时 JFR将记录运行过程中发生的一系列事件。其中包括Java层面的事件如线程事件、锁事件,以及Java虚拟机内部的事件,如新建对象,垃圾回收和即时编译事件。按照发生时机以及持续时间来划分,JFR的事件共有四种类型,它们分别为以下四种:
瞬时事件(Instant Event) ,用户关心的是它们发生与否,例如异常、线程启动事件。
持续事件(Duration Event) ,用户关心的是它们的持续时间,例如垃圾回收事件。
计时事件(Timed Event) ,是时长超出指定阈值的持续事件。
取样事件(Sample Event),是周期性取样的事件。
取样事件的其中一个常见例子便是方法抽样(Method Sampling),即每隔一段时问统计各个线程的栈轨迹。如果在这些抽样取得的栈轨迹中存在一个反复出现的方法,那么我们可以推测该方法是热点方法
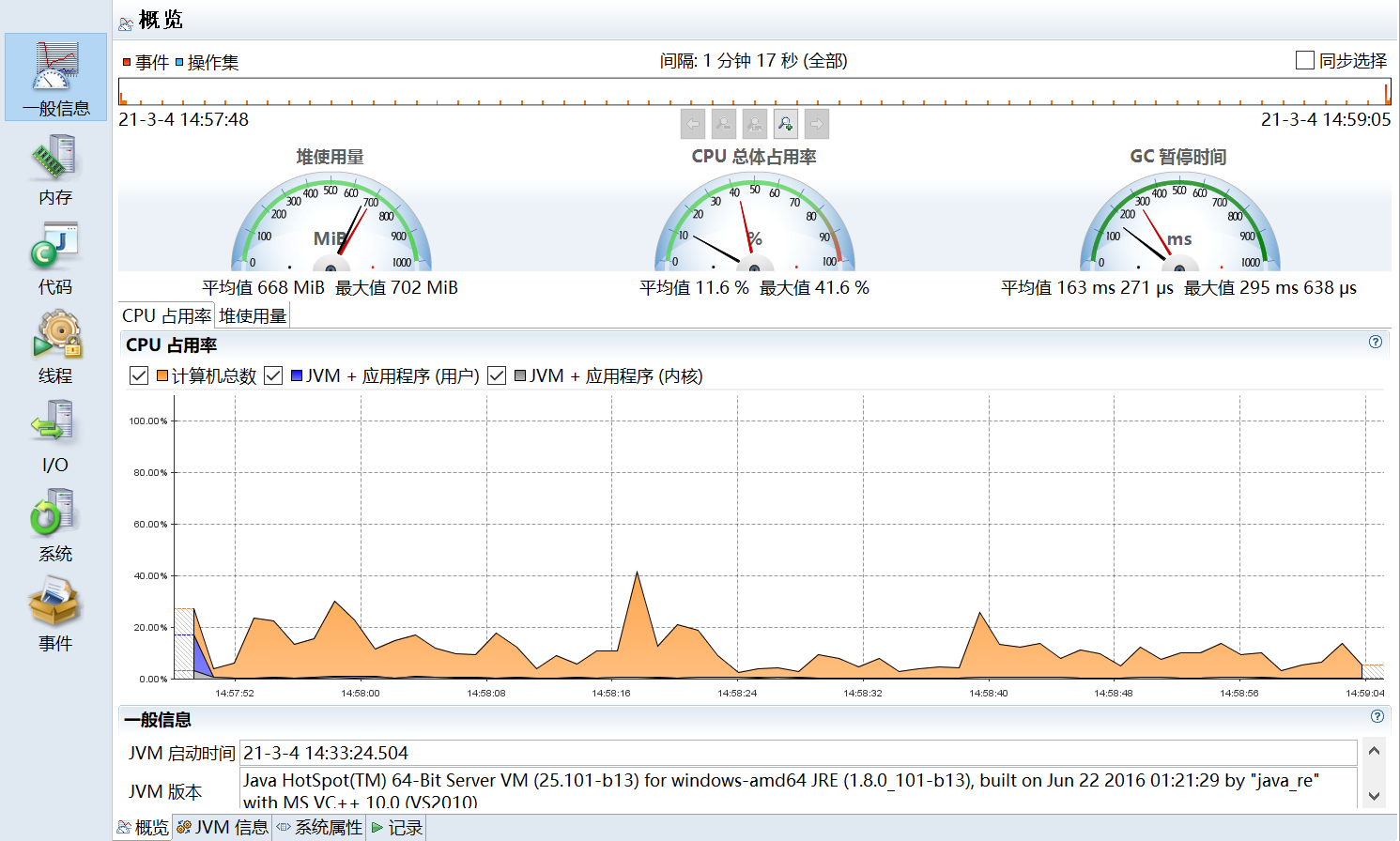
7、其他工具
Flame Graphs(火焰图)
在追求极致性能的场景下,了解你的程序运行过程中cpu在干什么很重要,火焰图就是一种非常直观的展示CPU在程序整个生命周期过程中时间分配的工具。火焰图对于现代的程序员不应该陌生,这个工具可以非常直观的显示出调用找中的CPU消耗瓶颈。
网上的关于Java火焰图的讲解大部分来自于Brenden Gregg的博客 http://new.brendangregg.com/flamegraphs.html

火焰图,简单通过x轴横条宽度来度量时间指标,y轴代表线程栈的层次。
Tprofiler
案例: 使用JDK自身提供的工具进行JVM调优可以将下 TPS 由2.5提升到20(提升了7倍),并准确 定位系统瓶颈。
系统瓶颈有:应用里释态对象不是太多、有大量的业务线程在频繁创建一些生命周期很长的临时对象,代码里有问题。
那么,如何在海量业务代码里边准确定位这些性能代码?这里使用阿里开源工具 Tprofiler 来定位 这些性能代码,成功解决掉了GC 过于频繁的性能瓶预,并最终在上次优化的基础上将 TPS 再提升了4倍,即提升到100。
Tprofiler配置部署、远程操作、 日志阅谈都不太复杂,操作还是很简单的。但是其却是能够 起到一针见血、立竿见影的效果,帮我们解决了GC过于频繁的性能瓶预。
Tprofiler最重要的特性就是能够统汁出你指定时间段内 JVM 的 top method 这些 top method 极有可能就是造成你 JVM 性能瓶颈的元凶。这是其他大多数 JVM 调优工具所不具备的,包括 JRockit Mission Control。JRokit 首席开发者 Marcus Hirt 在其私人博客《 Lom Overhead Method Profiling cith Java Mission Control》下的评论中曾明确指出 JRMC 井不支持 TOP 方法的统计。
官方地址:GitHub - alibaba/TProfiler: TProfiler是一个可以在生产环境长期使用的性能分析工具
Btrace
常见的动态追踪工具有BTrace、HouseHD(该项目己经停止开发)、Greys-Anatomy(国人开发 个人开发者)、Byteman(JBoss出品),注意Java运行时追踪工具井不限干这几种,但是这几个是相对比较常用的。
BTrace是SUN Kenai 云计算开发平台下的一个开源项目,旨在为java提供安全可靠的动态跟踪分析工具。先看一卜日Trace的官方定义:

大概意思是一个 Java 平台的安全的动态追踪工具,可以用来动态地追踪一个运行的 Java 程序。BTrace动态调整目标应用程序的类以注入跟踪代码(“字节码跟踪“)。
版权归原作者 全栈行动派 所有, 如有侵权,请联系我们删除。