
- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,Java领域新星创作者
- 📕系列专栏:Java设计模式、数据结构和算法、Kafka从入门到成神、Kafka从成神到升仙
- 📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2022计划中:以梦为马,扬帆起航,2022追梦人

文章目录
Kafka从成神到成仙系列
- 【Kafka从成神到升仙系列 一】Kafka源码环境搭建
- 【Kafka从成神到升仙系列 二】生产者如何将消息放入到内存缓冲区
- 【Kafka从成神到升仙系列 三】你真的了解 Kafka 的元数据嘛
- 【Kafka从成神到升仙系列 四】你真的了解 Kafka 的缓存池机制嘛
- 【Kafka从成神到升仙系列 五】面试官问我 Kafka 生产者的网络架构,我直接开始从源码背起…
服务端的网络架构
初学一个技术,怎么了解该技术的源码至关重要。
对我而言,最佳的阅读源码的方式,那就是:不求甚解,观其大略
你如果进到庐山里头,二话不说,蹲下头来,弯下腰,就对着某棵树某棵小草猛研究而不是说先把庐山的整体脉络研究清楚了,那么你的学习方法肯定效率巨低而且特别痛苦。
最重要的还是慢慢地打击你的积极性,说我的学习怎么那么不 happy 啊,怎么那么没劲那,因为你的学习方法错了,大体读明白,先拿来用,用着用着,很多道理你就明白了。
先从整体上把关源码,再去扣一些细节问题。
举个简单的例子:
如果你刚接触 HashMap,你刚有兴趣去看其源码,在看 HashMap 的时候,有一个知识:当链表长度达到 8 之后,就变为了红黑树,小于 6 就变成了链表,当然,还和当前的长度有关。
这个时候,如果你去深究红黑树、为什么是 8 不是别的,又去查 泊松分布,最终会慢慢的搞死自己。
所以,正确的做法,我们先把这一部分给略过去,知道这个概念即可,等后面我们把整个庐山看完之后,再回过头抠细节。
当然,本章我们讲述 Kafka 服务端的网络架构
一、服务端网络整体架构
我们讲过了生产者整个的调用流程及发送流程,今天我们来讲一下服务端到底是怎么样处理客户端的连接的
我们都知道,
Kafka
作为一个吞吐量极高的中间件,其通信过程自然而然也起到了关键性的作用
之前我们聊过,
Kafka
并未用
Netty
作为其通信框架,而是自己自研的
那么,这个自研的框架到底怎么做的呢?和
Netty
相比又如何?
同样,还有一个前提的问题,希望大家在读本篇博客的时候,能够思考一下:Kafka 如何在高吞吐的状态下仍然能保证单 Partition 的有序性?
废话不多说,我们直接开车!
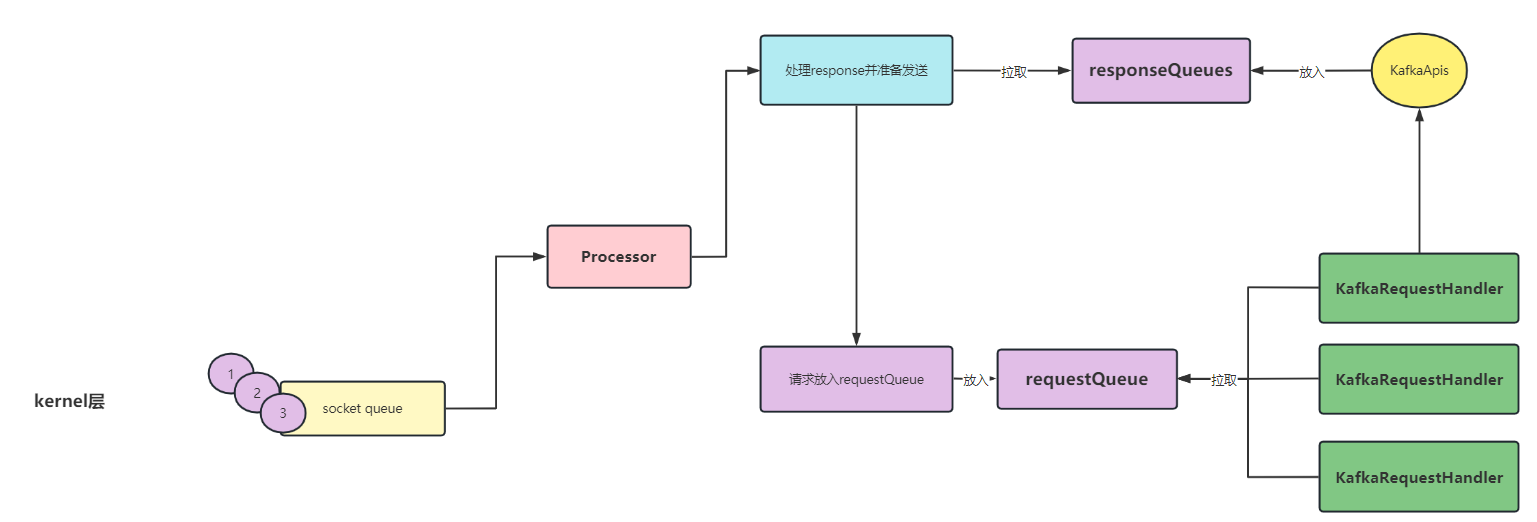
首先,我们看一下服务端的网络架构图:
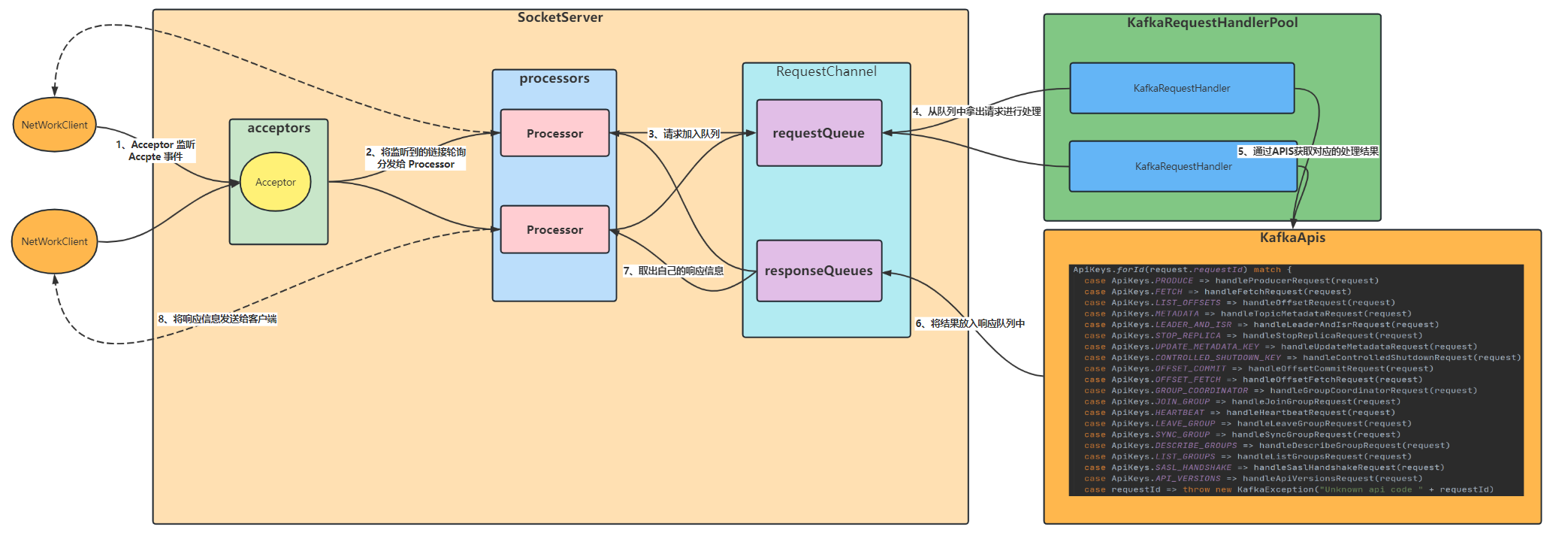
我们在这里先简单解释一下整体的流程:
Acceptor初始化的时候会注册OP_ACCEPT事件,当有客户端连接进来时,会触发该事件并将该事件轮询的方式分发给Processor处理。Processor收到Acceptor分发的连接时,会注册OP_READ事件并与内部的selector绑定,当下次客户端发送信息时,直接触发Processor的OP_READ事件进行处理。Processor将客户端的连接请求放入RequestQueue(仅有一个)里面,所有的Processor共用一个RequestQueueKafkaRequestHandler从RequestQueue中取出请求,通过调用KafkaApis得到响应结果,将响应结果放入到responseQueues,这里需要注意一点:Processor 有几个 responseQueueProcessor从对应的responseQueue中取出response,将其通过SockerChannel发送给对应的客户端、
这些就是
Kafka
服务端网络的整体架构
下面我们详细的拆解每一部分的实现细节
二、服务端源代码剖析
kafka
服务端的启动类为 kafka.scala,主要启动
KafkaServer
服务端
KafkaServer
的启动代码如下:
socketServer =new SocketServer(config, metrics, kafkaMetricsTime)
socketServer.startup()
实际上真正的服务启动是 **
SocketServer
**
1、SocketServer
class SocketServer(val config: KafkaConfig,val metrics: Metrics,val time: Time)extends Logging with KafkaMetricsGroup {privateval endpoints = config.listeners // 开放的端口数privateval numProcessorThreads = config.numNetworkThreads // 默认为 3个,即 processorprivateval maxQueuedRequests = config.queuedMaxRequests // request 队列中允许的最多请求数,默认是500privateval totalProcessorThreads = numProcessorThreads * endpoints.size // 每个端口会对应 N 个 processorval requestChannel =new RequestChannel(totalProcessorThreads, maxQueuedRequests)privateval processors =new Array[Processor](totalProcessorThreads)private[network]val acceptors = mutable.Map[EndPoint, Acceptor]()}// requestQueue:只有一个// responseQueues:每个 Processor 都对应一个class RequestChannel(val numProcessors:Int,val queueSize:Int)extends KafkaMetricsGroup {privateval requestQueue =new ArrayBlockingQueue[RequestChannel.Request](queueSize)privateval responseQueues =new Array[BlockingQueue[RequestChannel.Response]](numProcessors)for(i <-0 until numProcessors)
responseQueues(i)=new LinkedBlockingQueue[RequestChannel.Response]())
1.1 初始化
对于初始化来说,主要完成 Processor 和 acceptor 的创建
def startup(){this.synchronized {// 发送和接受的缓存区大小val sendBufferSize = config.socketSendBufferBytes
val recvBufferSize = config.socketReceiveBufferBytes
val brokerId = config.brokerId
var processorBeginIndex =0// endpoint:开放的端口数,默认一个 Broker 开放一个
endpoints.values.foreach { endpoint =>val protocol = endpoint.protocolType
val processorEndIndex = processorBeginIndex + numProcessorThreads
// Processor:默认为三个for(i <- processorBeginIndex until processorEndIndex 默认为 3
processors(i)= newProcessor(i, connectionQuotas, protocol)// Acceptor: 默认一个val acceptor =new Acceptor(endpoint, sendBufferSize, recvBufferSize, brokerId,
processors.slice(processorBeginIndex, processorEndIndex), connectionQuotas)
acceptors.put(endpoint, acceptor)// 等待线程的启动
acceptor.awaitStartup()
processorBeginIndex = processorEndIndex
}}
1.2 Acceptor 处理
上面我们创建完了Acceptor 和 Processor,首先看一下
Acceptor
的处理
- 首先向
nioSelector注册接受OP_ACCEPT事件,监听是否有新的连接请求 - 如果有新的连接请求接入,将该连接的
SocketChannel交于processors进行处理 - 由于
processor存在多个,以轮询的方式去交付,保证processor的负载均衡
def run(){// 注册OP_ACCEPT事件
serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT)// 线程启动完成
startupComplete()try{var currentProcessor =0// 死循环while(isRunning){try{// 查看有没有注册的连接进来val ready = nioSelector.select(500)if(ready >0){// 拿出所有的keys并遍历val keys = nioSelector.selectedKeys()val iter = keys.iterator()while(iter.hasNext && isRunning){try{val key = iter.next
// 用完即删
iter.remove()// 如果当前的是接受事件,则进行接受事件相应的处理if(key.isAcceptable)
accept(key, processors(currentProcessor))// 轮询的方式选择下一个Processor线程
currentProcessor =(currentProcessor +1)% processors.length
}}}}}}}
**交于
processors
处理的逻辑:**
- 拿到当前
ServerSocketChannel上的socketChannel并进行一些对应的配置 - 将
socketChannel放入newConnections中并唤醒我们的processor
/*
* 接受一个新连接
*/def accept(key: SelectionKey, processor: Processor){// accept 事件发生时,获取注册到 selector 上的 ServerSocketChannelval serverSocketChannel = key.channel().asInstanceOf[ServerSocketChannel]val socketChannel = serverSocketChannel.accept()try{// socketChannel的各种配置
connectionQuotas.inc(socketChannel.socket().getInetAddress)
socketChannel.configureBlocking(false)
socketChannel.socket().setTcpNoDelay(true)
socketChannel.socket().setKeepAlive(true)
socketChannel.socket().setSendBufferSize(sendBufferSize)
processor.accept(socketChannel)}}// 将新的 SocketChannel放入到newConnections中去def accept(socketChannel: SocketChannel){
newConnections.add(socketChannel)// 唤醒 Processor 的 selector(如果此时在阻塞的话)
wakeup()}
1.3 Processor 处理
前面我们讲过,
Acceptor
将
socketChannel
放到了
newConnections
队列中并唤醒我们的
Processor
线程
我们可以猜测到,
Processor
肯定是从
newConnections
中拿出
socketChannel
去处理
我们的猜测正不正确呢?来看看源码怎么说
overridedef run(){
startupComplete()while(isRunning){try{/**
* 从 newConnections 弹出当前的 channel
* 将当前的 channel 绑定到 nioSelector 并注册 OP_READ 事件
*/
configureNewConnections()/**
* 拿到属于自己的 responseQueues 并处理其中的 response
* 其中 response 分为三类:
* NoOpAction:如果这个请求不需要返回 response,再次注册 OP_READ 监听事件
* SendAction:需要发送,后续注册 OP_WRITE 监听事件,最终通过 poll 发送(类似我们的生产者消息发送)
* CloseConnectionAction:需要关闭的 response
*/
processNewResponses()/**
* 选择器轮询各种事件,请求和发送响应
* 比如上面我们需要发送的 response,就通过 poll 发送出去(代码逻辑和生产者类似,不再细讲)
*/
poll()/**
* 服务端处理器的运行方法在调用选择器的轮询后,处理已经完成的请求接收
* 请求接受:将请求放入到 requestQueue 中并删除掉 OP_READ 事件注册
*/
processCompletedReceives()/**
* 服务端处理器的运行方法在调用选择器的轮询后,处理已经完成的响应发送
* 响应发送:当有写请求时加入inflightResponses,当写请求完成后删除并添加 OP_READ 事件监听
*/
processCompletedSends()
processDisconnected()}}
swallowError(closeAll())
shutdownComplete()}
我们通过源码可以看到,总共分五个步骤:
Processor从newConnections取出socketChannel并注册OP_READ事件监听- 处理
responseQueues的response,总共分三个类型: - NoOpAction:如果这个请求不需要返回response,再次注册OP_READ监听事件- SendAction:需要发送,后续注册OP_WRITE监听事件,最终通过poll发送(类似我们的生产者消息发送)- seConnectionAction:需要关闭的response - 上面我们注册了
OP_WRITE事件,在poll阶段会被监听到并发送至客户端 - 处理客户端的一些请求,将其放入到
requestQueue并删除掉OP_READ事件监听 - 处理响应请求,当有写请求时加入
inflightResponses,当写请求完成后删除并添加OP_READ事件监听
当然,我们可以简单的理解一下整个流程:
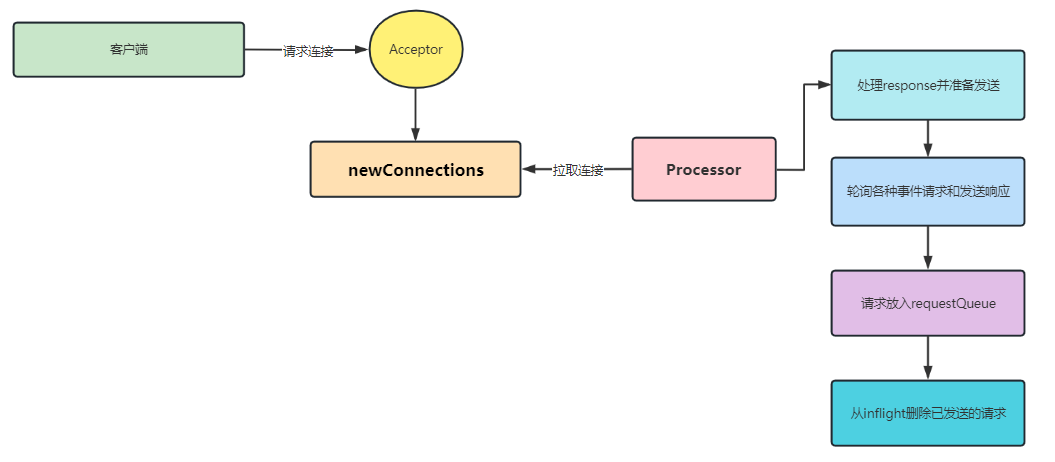
这里给大家留一个小问题:为什么要频繁的删除掉 OP_READ 事件监听、增加 OP_READ 事件监听?
2、KafkaRequestHandlerPool
按照我们架构图所示,不出所料的话,应该到
KafkaRequestHandlerPool
这一部分了
通过架构图我们可以得知这部分的主要功能:
- 获取
requestQueue中的请求,通过KafkaApis得到对应的结果 - 将结果放入到响应队列(responseQueues)中
2.1 初始化
KafkaRequestHandlerPool中创建numThreads个KafkaRequestHandler并启动- 在初始化
KafkaRequestHandler的时候,我们发现其入参有个requestChannel,这个入参是 Processor 存放 request 请求的地方,也是 Handler 处理完请求存放 response 的地方
class KafkaRequestHandlerPool(val brokerId:Int,val requestChannel: RequestChannel,val apis: KafkaApis,
numThreads:Int)extends Logging with KafkaMetricsGroup {privateval aggregateIdleMeter = newMeter("RequestHandlerAvgIdlePercent","percent", TimeUnit.NANOSECONDS)val threads =new Array[Thread](numThreads)val runnables =new Array[KafkaRequestHandler](numThreads)for(i <-0 until numThreads){// 开启 numThreads 个 KafkaRequestHandler 并启动
runnables(i)=new KafkaRequestHandler(i, brokerId, aggregateIdleMeter, numThreads, requestChannel, apis)
threads(i)= Utils.daemonThread("kafka-request-handler-"+ i, runnables(i))
threads(i).start()}}
2.2 KafkaRequestHandler
- 从
RequestChannel得到Requests并交由KafkaApis去处理
def run(){while(true){try{var req : RequestChannel.Request =nullwhile(req ==null){val startSelectTime = SystemTime.nanoseconds
req = requestChannel.receiveRequest(300)val idleTime = SystemTime.nanoseconds - startSelectTime
aggregateIdleMeter.mark(idleTime / totalHandlerThreads)}
req.requestDequeueTimeMs = SystemTime.milliseconds
apis.handle(req)}}}
3、KafkaApis
上面讲到
KafkaRequestHandler
从
RequestChannel
得到
Requests
并交由
KafkaApis
去处理
那么到底是一个怎么样的处理逻辑呢?
def handle(request: RequestChannel.Request){try{
format(request.requestDesc(true), request.connectionId, request.securityProtocol, request.session.principal))
ApiKeys.forId(request.requestId)match{case ApiKeys.PRODUCE => handleProducerRequest(request)case ApiKeys.FETCH => handleFetchRequest(request)case ApiKeys.LIST_OFFSETS => handleOffsetRequest(request)case ApiKeys.METADATA => handleTopicMetadataRequest(request)case ApiKeys.LEADER_AND_ISR => handleLeaderAndIsrRequest(request)case ApiKeys.STOP_REPLICA => handleStopReplicaRequest(request)case ApiKeys.UPDATE_METADATA_KEY => handleUpdateMetadataRequest(request)case ApiKeys.CONTROLLED_SHUTDOWN_KEY => handleControlledShutdownRequest(request)case ApiKeys.OFFSET_COMMIT => handleOffsetCommitRequest(request)case ApiKeys.OFFSET_FETCH => handleOffsetFetchRequest(request)case ApiKeys.GROUP_COORDINATOR => handleGroupCoordinatorRequest(request)case ApiKeys.JOIN_GROUP => handleJoinGroupRequest(request)case ApiKeys.HEARTBEAT => handleHeartbeatRequest(request)case ApiKeys.LEAVE_GROUP => handleLeaveGroupRequest(request)case ApiKeys.SYNC_GROUP => handleSyncGroupRequest(request)case ApiKeys.DESCRIBE_GROUPS => handleDescribeGroupRequest(request)case ApiKeys.LIST_GROUPS => handleListGroupsRequest(request)case ApiKeys.SASL_HANDSHAKE => handleSaslHandshakeRequest(request)case ApiKeys.API_VERSIONS => handleApiVersionsRequest(request)case requestId =>thrownew KafkaException("Unknown api code "+ requestId)}}finally
request.apiLocalCompleteTimeMs = SystemTime.milliseconds
}
- 根据
ApiKeys不同的类别,走不同的处理方式 - 这里的类别
PRODUCE(0,"Produce"), FETCH(1,"Fetch"), LIST_OFFSETS(2,"Offsets"), METADATA(3,"Metadata"), LEADER_AND_ISR(4,"LeaderAndIsr"), STOP_REPLICA(5,"StopReplica"), UPDATE_METADATA_KEY(6,"UpdateMetadata"), CONTROLLED_SHUTDOWN_KEY(7,"ControlledShutdown"), OFFSET_COMMIT(8,"OffsetCommit"), OFFSET_FETCH(9,"OffsetFetch"), GROUP_COORDINATOR(10,"GroupCoordinator"), JOIN_GROUP(11,"JoinGroup"), HEARTBEAT(12,"Heartbeat"), LEAVE_GROUP(13,"LeaveGroup"), SYNC_GROUP(14,"SyncGroup"), DESCRIBE_GROUPS(15,"DescribeGroups"), LIST_GROUPS(16,"ListGroups"), SASL_HANDSHAKE(17,"SaslHandshake"), API_VERSIONS(18,"ApiVersions");
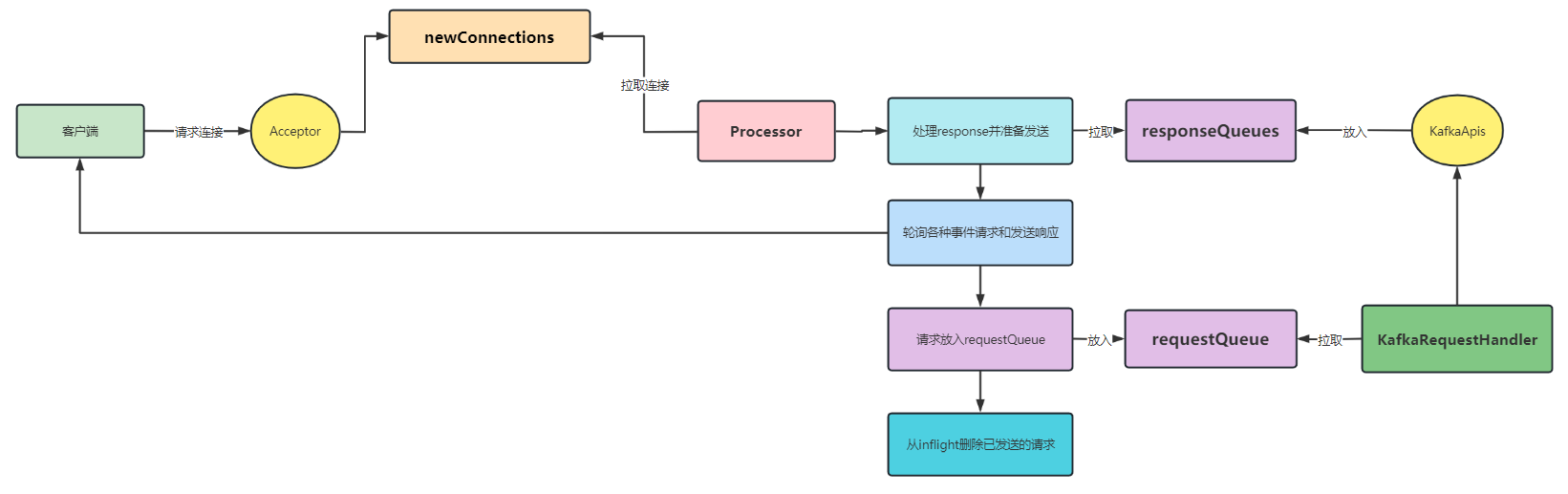
3.1 响应返回
当我们的
ApiKeys
处理完相对应的请求时,会执行以下方法:
// 将响应发送回套接字服务器,以便通过网络发送def sendResponse(response: RequestChannel.Response){// 将得到的响应放入到 responseQueues 中
responseQueues(response.processor).put(response)for(onResponse <- responseListeners)// 调用对应 processor 的 wakeup 方法
onResponse(response.processor)}
至于每个类型的请求是如何处理的,这一章我们暂时不讲
我们继续完善一下上面的图片:
三、问题解析
经过我们上面的讲述,相信大家对整个 服务端网络整体架构 有了更深的认识
还记得我在文中提到的两个问题嘛?
Kafka如何在高吞吐的状态下仍然能保证单Partition的有序性?- 为什么要频繁的删除掉
OP_READ事件监听、增加OP_READ事件监听?
接下来就是见证奇迹的时刻,也是面试的时候装逼的时刻,这一刻,你就是天选!
首先,我们从生产者的发送讲起,众所周知,生产者在发送服务端时会将相同
Partition
的放到一起,具体可见:Kafka 生产者全流程
所以我们的客户端与服务端的请求如下:
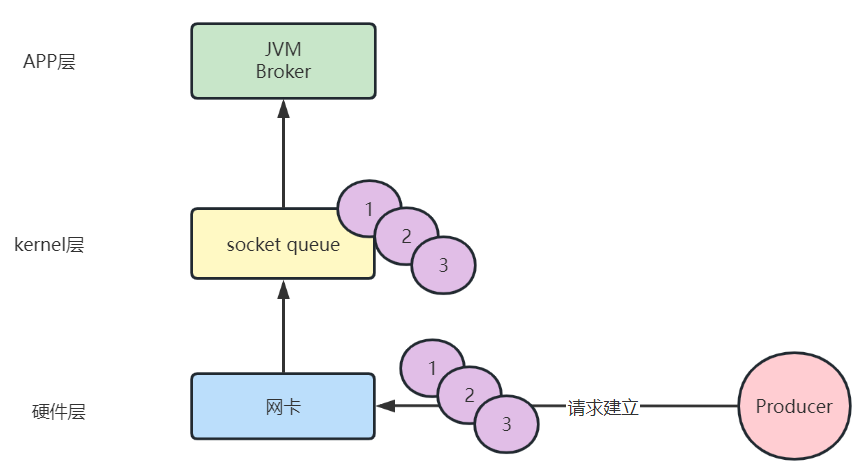
从上面我们可以看到,客户端(Producer)向服务端发送了
1、2、3
总共三条数据且三条数据处于一个
Partition
。
对于这三条数据来说,发送时是有序的,按照
1、2、3
的顺序,服务端落日志肯定也是有序的
1、2、3
问题来了,我们上面讲了客户端的请求都会被扔到
requestQueue
中,让
KafkaRequestHandler
去通过
KafkaApis
处理并将响应扔到
responseQueues
中
假如,我们全程没有不去删除
OP_READ
事件监听,会发生什么情况?大家可以想一下,给个提示:KafkaRequestHandler是多线程的
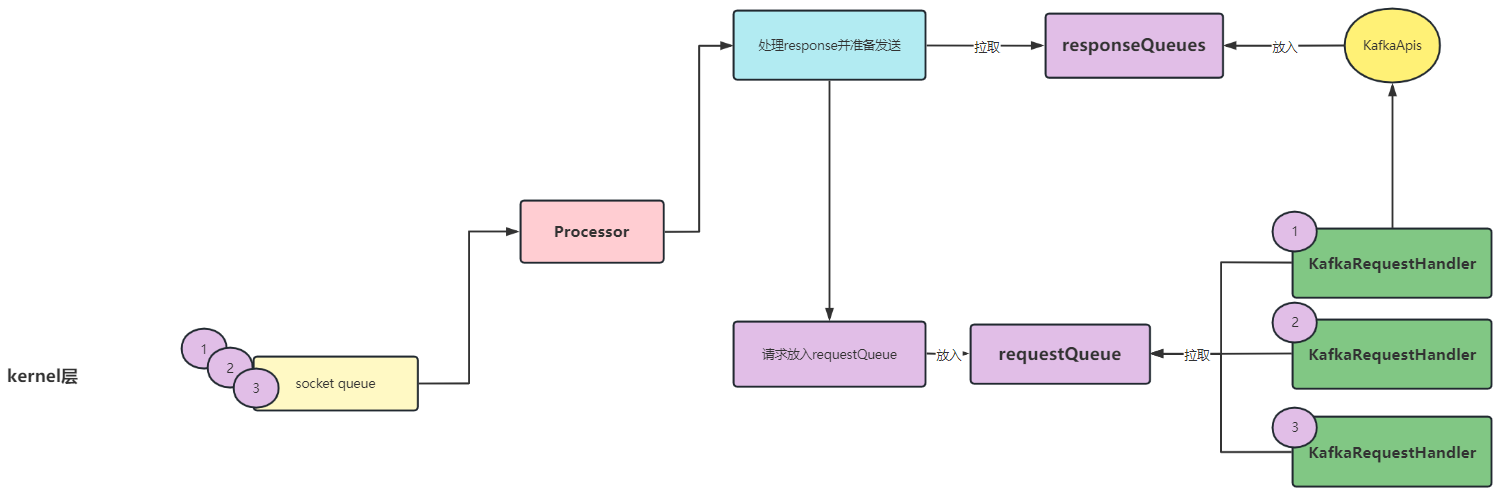
如上图所示,如果我们 **不去删除
OP_READ
事件监听**的话,我们的
1、2、3
三条信息会都放入到
requestQueue
中,那么我们的
KafkaRequestHandler
去拉取的时候,会出现乱序的现象。
比如,我们三个
KafkaRequestHandler
分别拉取到一条消息:
这个时候,三个
KafkaRequestHandler
线程同时去调用
KafkaApis
落日志,那么这种方式怎么可能保证有序性呢?
kafka
的开发者采取了
mute
的解决方式,将所有接受的事件先放到
kernel
中,每次只取一个请求,取完就关闭,等该请求的
response
过来后,再重新增加
OP_READ
事件的监听。
通过上述的方式,
kafka
做到了分区落日志的有序性。
四、总结
这一篇文章主要从
Kafka
服务端的网络架构入手,剖析了服务端网络如何连接、如何处理、如何返回的。
1 + N + M 的架构思想:
1个AcceptorN个ProcessorM个KafkaRequestHandler
其实,看过博主
Netty
系列的读者应该可以感觉到,
Kafka
服务端的这种网络架构正是著名的 Reactor模型。
对应关系如下:
boss====》Acceptor===》前台work====》Processor===》服务员
这里讲一个故事更形象化一些:
- 当你去酒店住宿的时候,首先需要去前台登记入住手续,登记完成后,前台会给你一个房间的钥匙。这个就相当于我们连接初始化连接的时候,
boss为刚连接进来的客户端分配SocketChannel。 - 之后,前台会让服务员领你去房间,如果你有什么需要,都可以跟这个服务员说。这个相当于我们的
boss将该客户端的连接交给了work线程,任何的业务处理都交由work线程去做。
这一篇文章到这里差不多快结束了。不出意外,这一篇又是鸽了很久的一篇
下次一定不会再鸽了,写这种中间件源码的文章确实难受,基本写了就是给自己看的
最后强调一下:kafka 的网络架构使用了 Reactor 模型,利用 1 + N + M 的架构模式,将 kafka 的通信支撑起来,最后通过 mute 的方法保障了分区有序性。
如果你能看到这,那博主必须要给你一个大大的鼓励,谢谢你的支持!
喜欢的可以点个关注,后续会继续更新
kafka
源码系列文章
我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,Java领域新星创作者,喜欢后端架构和中间件源码。
我们下期再见。
版权归原作者 爱敲代码的小黄 所有, 如有侵权,请联系我们删除。