
Selenium自动化测试
Selenium是一个免费的分布式的自动化测试工具,其测试能够直接运行在浏览器中,就像真正的用户在操作一样,支持的浏览器包括ie、ff、safari、opera、chrome。
【安装】
A、安装Selenium工具包
pip install selenium
B、安装webdriver,如果是谷歌浏览器,则需下载一个驱动chromedriver
下载路径:
https://chromedriver.chromium.org/downloads
查看当前谷歌浏览器的版本信息: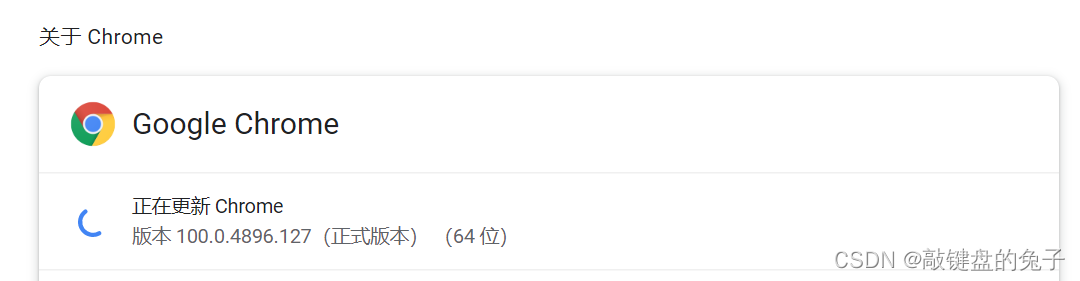
下载对应的版本驱动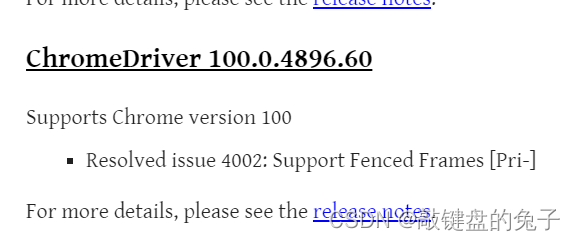
将其解压缩到谷歌浏览器的安装路径下,即可
【几个重要的库】
import time
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from lxml import etree
【几个重要的方法】
#等待目标可以操作
input = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR,选择指示))
)
#等待按钮可操作
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR, 选择指示))
)
#等待值为某个值
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR,“#J_bottomPage > span.p-num > a.curr”),str(page_number))
)
time.sleep(10)
【爬取网页,搜索内容】
#打开浏览器
browser = webdriver.Chrome()#搜索网页
browser.get("https://www.baidu.com")#网页等待0.05s
wait = WebDriverWait(browser,50)#打开网页
browser.get('https://www.jd.com/')#获取网页源码,返回页面资源(内容)
html = browser.page_source
#xpath解析网页内容,进行元素提取
items = html.xpath('//li[@class="gl-item"]')
Selenium的具体使用,还有很多知识点,内容比较多且杂,建议可以通过学习其官方文档,来展开深入学习。
这里是传送门
【xpath 访问网页元素】
XPath 是一门在 XML 文档中查找信息的语言。XPath 用于在 XML 文档中通过元素和属性进行导航,其使用路径表达式来选取 XML 文档中的节点或节点集。节点是通过沿着路径 (path) 或者步 (steps) 来选取的。
常用路径表达式含义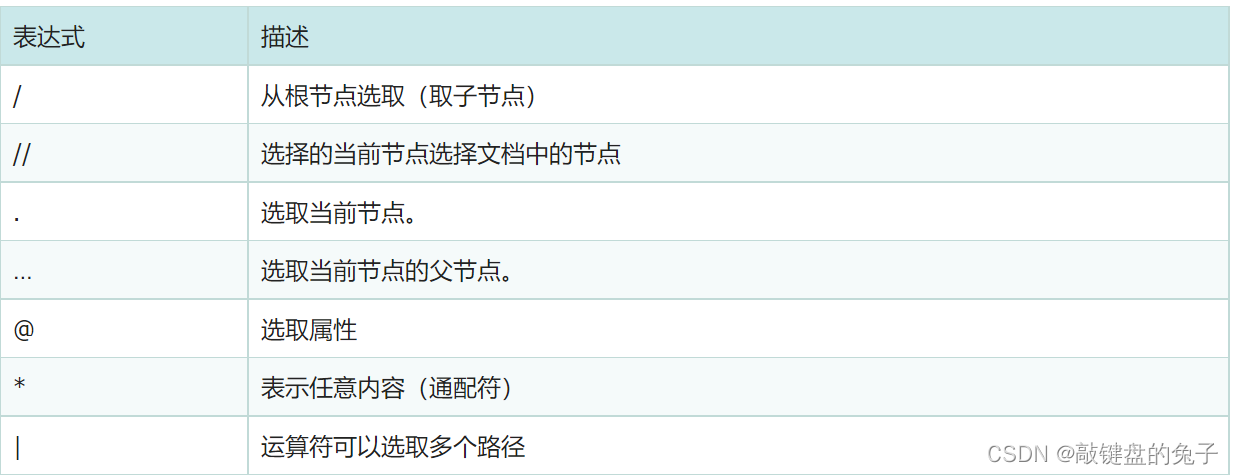

谓词的使用: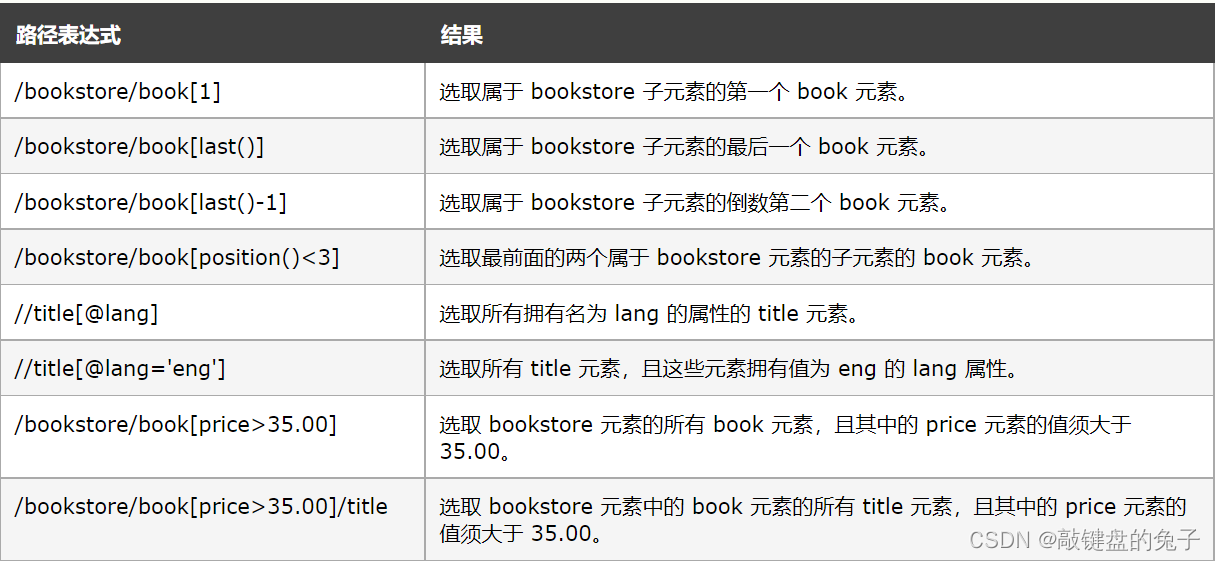
常用功能函数
选取若干路径
版权归原作者 敲键盘的兔子 所有, 如有侵权,请联系我们删除。