
1 深度学习简介
事实上,要想解读图像中的内容,需要寻找仅仅在结合成千上万的数值时才会出现的特征,如边缘、质地、形状、眼睛、鼻子等,最终才能判断图像中是否有猫。
我们可以收集一些已知包含猫与不包含猫的真实图像,然后我们的目标就转化成如何从这些图像入手得到一个可以推断出图像中是否有猫的函数。这个函数的形式通常通过我们的知识来针对特定问题选定。例如,我们使用一个二次函数来判断图像中是否有猫,但是像二次函数系数值这样的函数参数的具体值则是通过数据来确定。——思想“用数据编程”
通俗来说,机器学习是一门讨论各式各样的适用于不同问题的函数形式,以及如何使用数据来有效地获取函数参数具体值的学科。深度学习是指机器学习中的一类函数,它们的形式通常为多层神经网络。
我们希望从日常的观测中提取规则,并找寻不确定性。
时至今日,绝大多数神经网络都包含以下的核心原则。
- 交替使用线性处理单元与非线性处理单元,它们经常被称为“层”。
- 使用链式法则(即反向传播)来更新网络的参数。
机器学习研究如何使计算机系统利用经验改善性能。
在每一级(从原始数据开始),深度学习通过简单的函数将该级的表示变换为更高级的表示。因此,深度学习模型也可以看作是由许多简单函数复合而成的函数。当这些复合的函数足够多时,深度学习模型就可以表达非常复杂的变换。
以图像为例,它的输入是一堆原始像素值。深度学习模型中,图像可以逐级表示为特定位置和角度的边缘、由边缘组合得出的花纹、由多种花纹进一步汇合得到的特定部位的模式等。
2 预备知识
2.2 数据操作
索引出来的结果与原数据共享内存,也即修改一个,另一个会跟着修改。

-1所指的维度可以根据其他维度的值推出来

**
view()
返回的新
Tensor
与源
Tensor
虽然可能有不同的
size
,但是是共享
data
的,也即更改其中的一个,另外一个也会跟着改变。(顾名思义,view仅仅是改变了对这个张量的观察角度,内部数据并未改变)**
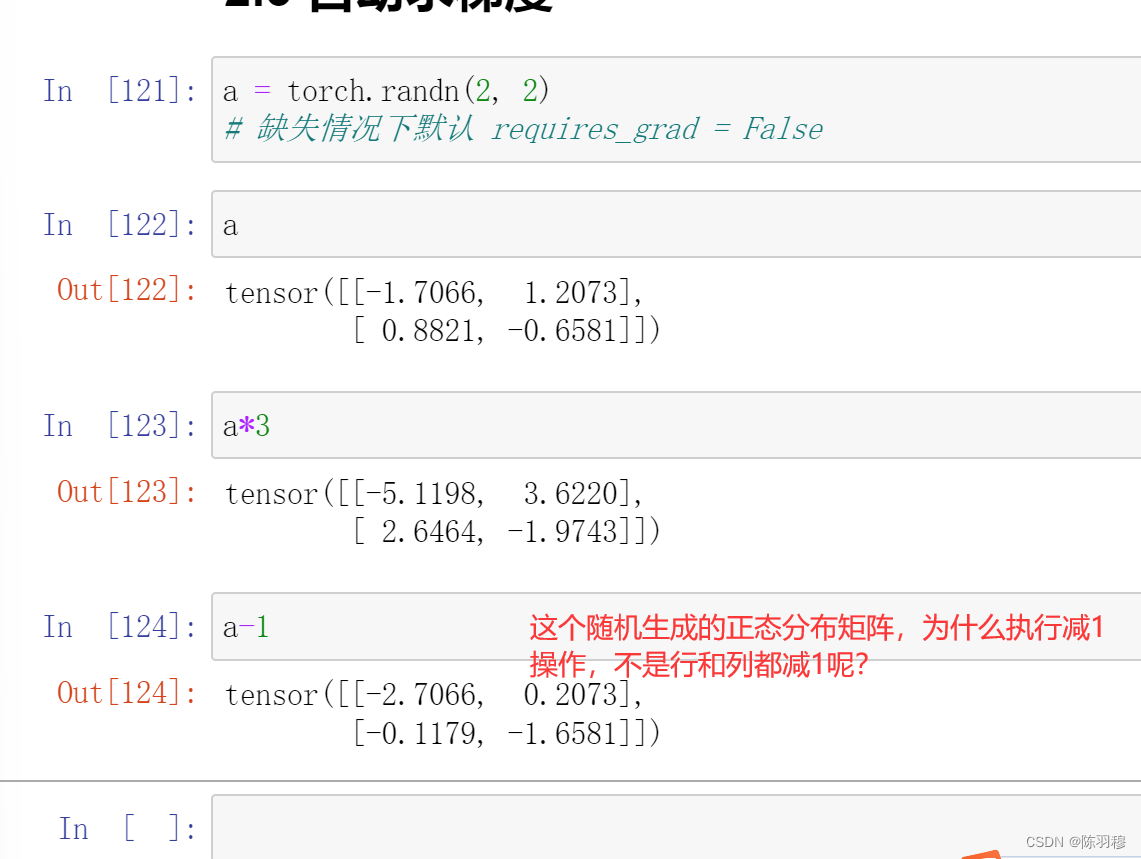
torch.rand(返回一个张量,包含了从区间(0,1)的均匀分布中抽取的一组随机数)和torch.randn(torch.randn:用来生成随机数字的tensor,这些随机数字满足标准正态分布(0~1)) 。
numpy()
和
from_numpy()
将
Tensor
和NumPy中的数组相互转换。 **这两个函数所产生的的
Tensor
和NumPy中的数组共享相同的内存(所以他们之间的转换很快),改变其中一个时另一个也会改变!!!**
Tensor转Numpy
使用
numpy()
将
Tensor
转换成NumPy数组:
a = torch.ones(5)
b = a.numpy()
print(a, b)
a += 1
print(a, b)
b += 1
print(a, b)
输出:
tensor([1., 1., 1., 1., 1.]) [1. 1. 1. 1. 1.]
tensor([2., 2., 2., 2., 2.]) [2. 2. 2. 2. 2.]
tensor([3., 3., 3., 3., 3.]) [3. 3. 3. 3. 3.]
Numpy数组转Tensor
使用
from_numpy()
将NumPy数组转换成
Tensor
:
import numpy as np
a = np.ones(5)
b = torch.from_numpy(a)
print(a, b)
a += 1
print(a, b)
b += 1
print(a, b)
输出:
[1. 1. 1. 1. 1.] tensor([1., 1., 1., 1., 1.], dtype=torch.float64)
[2. 2. 2. 2. 2.] tensor([2., 2., 2., 2., 2.], dtype=torch.float64)
[3. 3. 3. 3. 3.] tensor([3., 3., 3., 3., 3.], dtype=torch.float64)
直接用
torch.tensor()
将NumPy数组转换成
Tensor
,需要注意的是该方法总是会进行数据拷贝,返回的
Tensor
和原来的数据不再共享内存。
c = torch.tensor(a)
a += 1
print(a, c)
[4. 4. 4. 4. 4.] tensor([3., 3., 3., 3., 3.], dtype=torch.float64)
PyTorch提供的autograd包能够根据输入和前向传播过程自动构建计算图,并执行反向传播。
如果将其属性
.requires_grad
设置为
True
,它将开始追踪(track)在其上的所有操作(这样就可以利用链式法则进行梯度传播了)。完成计算后,可以调用
.backward()
来完成所有梯度计算。此
Tensor
的梯度将累积到
.grad
属性中。
y.backward()时,如果y是标量,则不需要为backward()传入任何参数;否则,需要传入一个与y同形的Tensor
每个
Tensor
都有一个
.grad_fn
属性,该属性即创建该
Tensor
的
Function
, 就是说该
Tensor
是不是通过某些运算得到的,若是,则
grad_fn
返回一个与这些运算相关的对象,否则是None。
x这种直接创建的称为叶子节点,叶子节点对应的
grad_fn
是
None

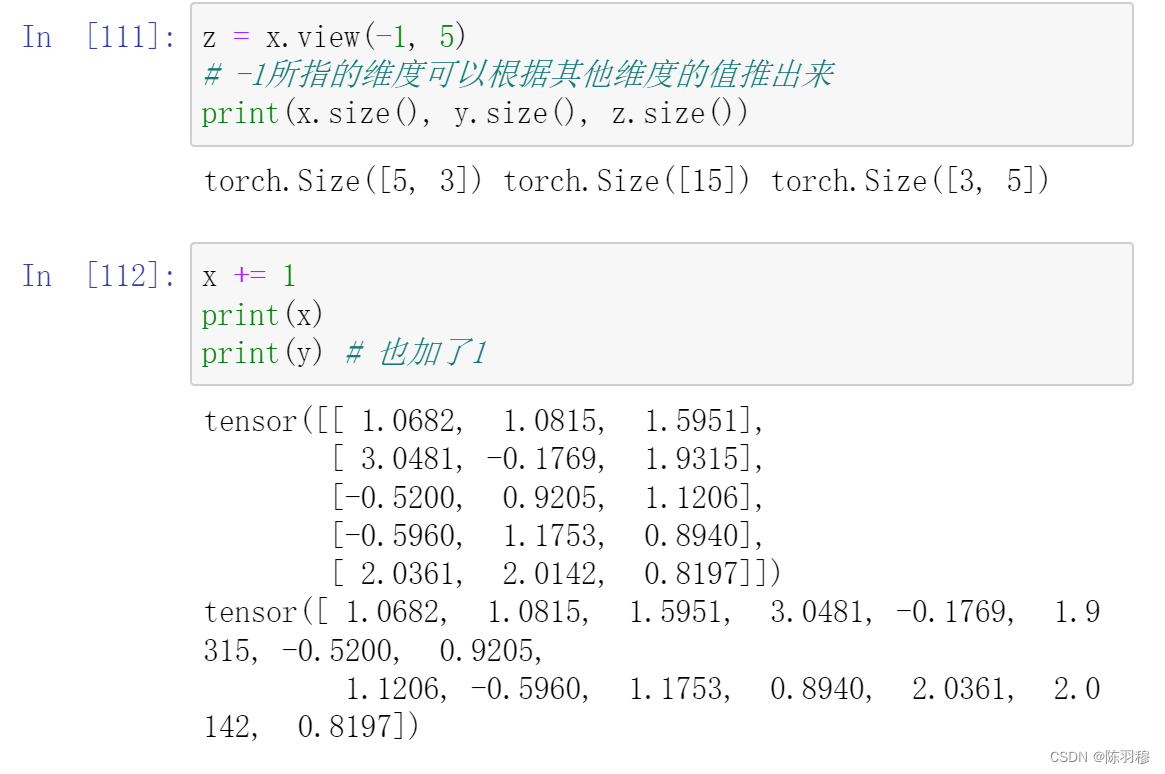
现在 z 不是一个标量,所以在调用backward时需要传入一个和z同形的权重向量进行加权求和得到一个标量。

x = torch.ones(2, 2, requires_grad=True)
print(x)
print(x.grad_fn)
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
None
y = x + 2
print(y)
print(y.grad_fn)
tensor([[3., 3.],
[3., 3.]], grad_fn=<AddBackward>)
<AddBackward object at 0x1100477b8>
x是直接创建的,所以它没有
grad_fn
, 而y是通过一个加法操作创建的,所以它有一个为
<AddBackward>
的
grad_fn
。
grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。
再来反向传播一次,注意grad是累加的
out2 = x.sum()
out2.backward()
print(x.grad)
out3 = x.sum()
x.grad.data.zero_()
out3.backward()
print(x.grad)
tensor([[5.5000, 5.5000],
[5.5000, 5.5000]])
tensor([[1., 1.],
[1., 1.]])
为什么在
y.backward()时,如果
y是标量,则不需要为
backward()传入任何参数;否则,需要传入一个与
y同形的
Tensor? 简单来说就是为了避免向量(甚至更高维张量)对张量求导,而转换成标量对张量求导。举个例子,假设形状为
m x n的矩阵 X 经过运算得到了
p x q的矩阵 Y,Y 又经过运算得到了
s x t的矩阵 Z。那么按照前面讲的规则,dZ/dY 应该是一个
s x t x p x q四维张量,dY/dX 是一个
p x q x m x n的四维张量。问题来了,怎样反向传播?怎样将两个四维张量相乘???这要怎么乘???就算能解决两个四维张量怎么乘的问题,四维和三维的张量又怎么乘?导数的导数又怎么求,这一连串的问题,感觉要疯掉…… 为了避免这个问题,我们不允许张量对张量求导,只允许标量对张量求导,求导结果是和自变量同形的张量。所以必要时我们要把张量通过将所有张量的元素加权求和的方式转换为标量,举个例子,假设
y由自变量
x计算而来,
w是和
y同形的张量,则
y.backward(w)的含义是:先计算
l = torch.sum(y * w),则
l是个标量,然后求
l对自变量
x的导数。
argmin f(x)
通俗意义上的解释是argmin表示使目标函数f(x)取最小值时的变量值
3.2 线性回归的从零开始实现
numpy.random.normal详解
numpy.random.normal详解_zhenyu wu的博客-CSDN博客_numpy.random.normal
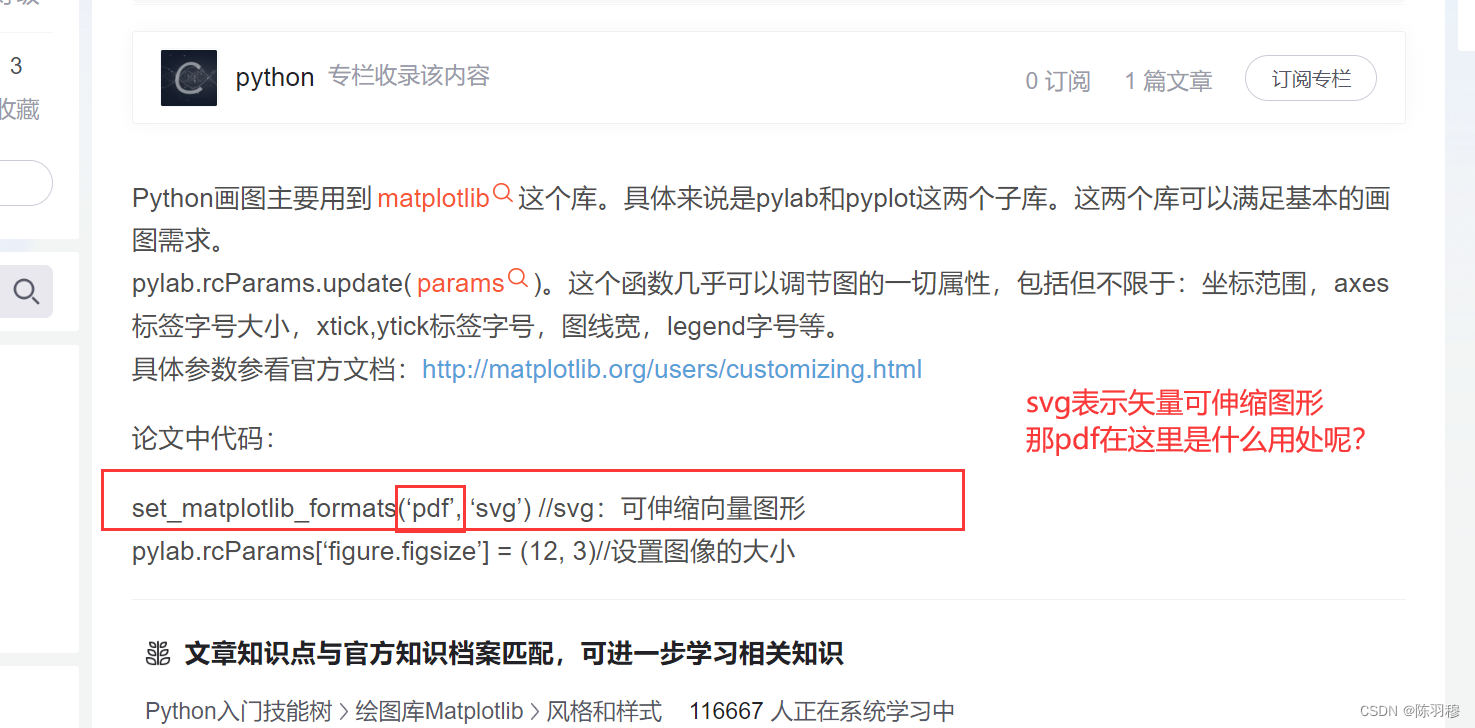
set_matplotlib_formats(‘pdf’, ‘svg’) //svg:可伸缩向量图形
3.1.2 优化算法
当模型和损失函数形式较为简单时,上面的误差最小化问题的解可以直接用公式表达出来。这类解叫作解析解(analytical solution)。
然而,大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解(numerical solution)。
在求数值解的优化算法中,小批量随机梯度下降(mini-batch stochastic gradient descent)在深度学习中被广泛使用。需要强调的是,这里的批量大小和学习率的值是人为设定的,并不是通过模型训练学出的,因此叫作超参数(hyperparameter)。我们通常所说的“调参”指的正是调节超参数,例如通过反复试错来找到超参数合适的值。在少数情况下,超参数也可以通过模型训练学出。
【02-07-批量梯度下降,随机梯度下降,小批量梯度下降】 https://www.bilibili.com/video/BV1bv4y1u7UV?share_source=copy_web&vd_source=9ee2521627a11b87c06e3907e194e1ab
import torch
import numpy as np
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
features = torch.randn(num_examples, num_inputs,
dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32)其中噪声项 ϵ\epsilonϵ 服从均值为0、标准差为0.01的正态分布。噪声代表了数据集中无意义的干扰
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"%matplotlib inline
import torch
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import randomdef use_svg_display():
# 用矢量图显示
display.set_matplotlib_formats('svg')def set_figsize(figsize=(3.5, 2.5)):
use_svg_display()
# 设置图的尺寸
plt.rcParams['figure.figsize'] = figsize# 在../d2lzh_pytorch里面添加上面两个函数后就可以这样导入
import sys
sys.path.append("..")
from d2lzh_pytorch import *
set_figsize()
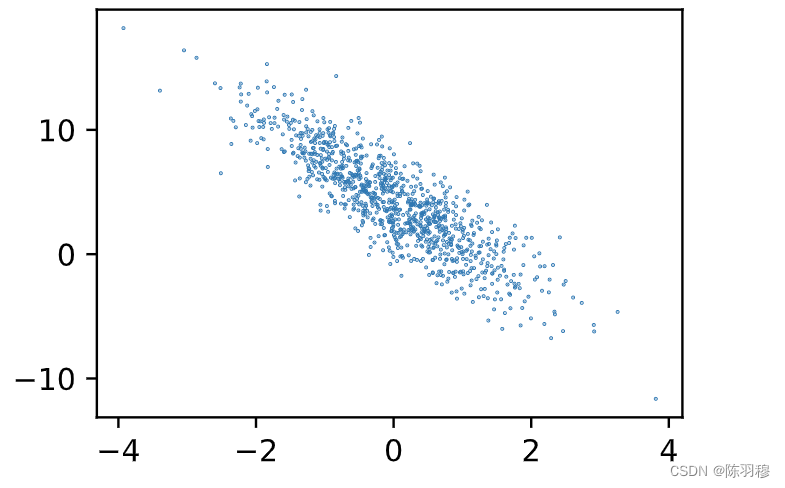
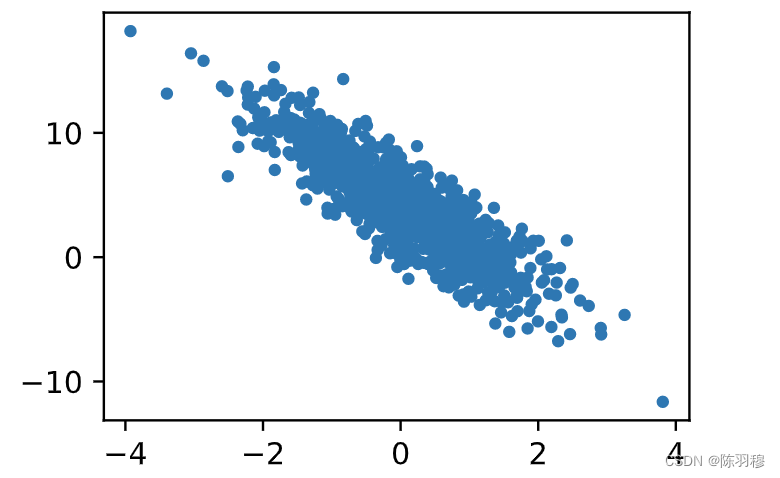
plt.scatter(features[:, 1].numpy(), labels.numpy(),0.1);
plt.scatter(features[:, 1].numpy(), labels.numpy(),10);
torch.longtensor和torch.tensor的差别在于:
torch.FloatTensor是32位浮点类型数据,torch.LongTensor是64位整型
torch.tensor是一个类,用于生成一个单精度浮点类型的张量。
# 本函数已保存在d2lzh包中方便以后使用
# torch.FloatTensor是32位浮点类型数据,torch.LongTensor是64位整型
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # 最后一次可能不足一个batch
yield features.index_select(0, j), labels.index_select(0, j)
yield就是 return 返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始。
初始化模型参数:
torch.nn
仅支持输入一个batch的样本不支持单个样本输入
from torch.nn import init
init.normal_(net.linear.weight, mean=0, std=0.01)
init.constant_(net.linear.bias, val=0) # 也可以直接修改bias的data: net[0].bias.data.fill_(0)
3.3 线性回归的简洁实现
1.optimizer.step()
optimizer.step()通常用在每个mini-batch之中,可以根据具体的需求来做。只有用了optimizer.step(),模型才会更新。
torch.utils.data模块提供了有关数据处理的工具,torch.nn模块定义了大量神经网络的层,torch.nn.init模块定义了各种初始化方法,torch.optim模块提供了很多常用的优化算法。
不显示坐标轴
f.axes.get_xaxis().set_visible(False)
f.axes.get_yaxis().set_visible(False)
zip() 函数返回一个zip对象,它是元组的迭代器,其中每个传递的迭代器中的第一项配对在一起,然后每个传递的迭代器中的第二项配对在一起,依此类推。如果传递的迭代器具有不同的长度,则项目数最少的迭代器将确定新迭代器的长度。
a = ("John", "Charles", "Mike")
b = ("Jenny", "Christy", "Monica")x = zip(a, b)
#use the tuple() function to display a readable version of the result:
print(tuple(x))
##(('John', 'Jenny'), ('Charles', 'Christy'), ('Mike', 'Monica'))
import sys:针对Python解释器相关的变量和方法
【Python基础之标准库sys】 https://www.bilibili.com/video/BV1Wf4y1R7W4?share_source=copy_web&vd_source=9ee2521627a11b87c06e3907e194e1ab
torch.gather()的作用在于提取张量中特定元素
当dim=0时,idx中的数为张量的行号,程序将遍历张量的每一列,依次获取张量每列中对应的元素,并返回于idx 相同的张量
当dim=1时,idx中的数为张量的列号,程序将遍历张量的每一行,依次获取张量每行中对应的元素,并返回idx shape相同的张量
b = torch.Tensor([[1,2,3],[4,5,6]]) print b index_1 = torch.LongTensor([[0,1],[2,0]]) index_2 = torch.LongTensor([[0,1,1],[0,0,0]]) print torch.gather(b, dim=1, index=index_1) print torch.gather(b, dim=0, index=index_2) 输出: 1 2 3 4 5 6 [torch.FloatTensor of size 2x3] 1 2 6 4 [torch.FloatTensor of size 2x2] 1 5 6 1 2 3 [torch.FloatTensor of size 2x3]

y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y = torch.LongTensor([0, 2])
print(y)
tensor([0, 2])
y.view(-1, 1)
tensor([[0],
[2]])
y_hat.gather(1, y.view(-1, 1))
tensor([[0.1000],
[0.5000]])
y_hat.argmax(dim=1)
tensor([2, 2])
y_hat.argmax(dim=1)==y
tensor([False, True])
(y_hat.argmax(dim=1)==y).float()
tensor([0., 1.])
(y_hat.argmax(dim=1)==y).float().mean()
tensor(0.5000)
(y_hat.argmax(dim=1)==y).float().mean().item()
0.5
def accuracy(y_hat, y):
return (y_hat.argmax(dim=1) == y).float().mean().item()
泛化误差不会随训练数据集里样本数量增加而增大
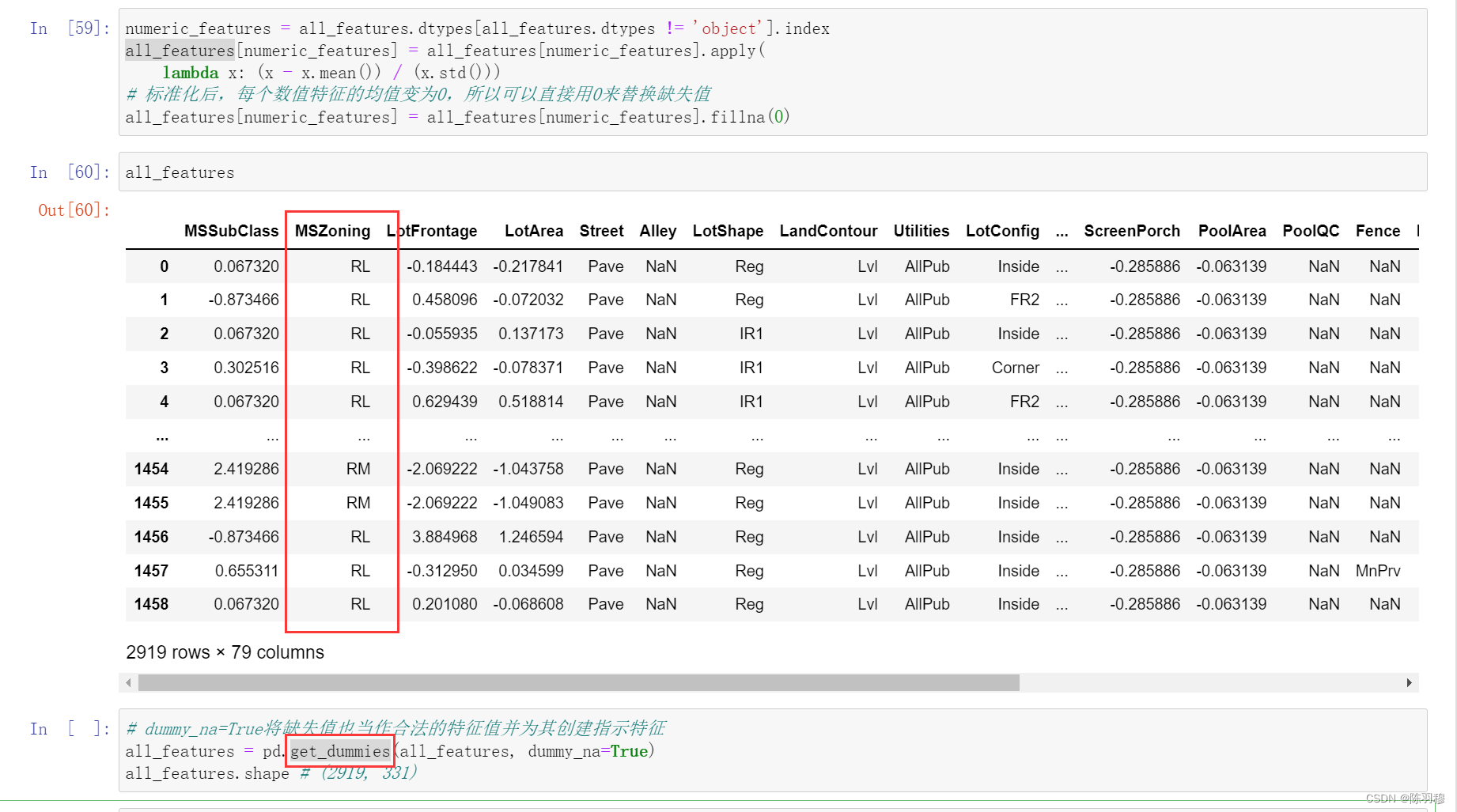
pandas中的get_dummies方法_大写的ZDQ的博客-CSDN博客_get_dummies pandas
detch的用法
detach()函数的用法_fK0pS的博客-CSDN博客_detach函数
看不懂哇:!!!
交叉熵损失函数!!

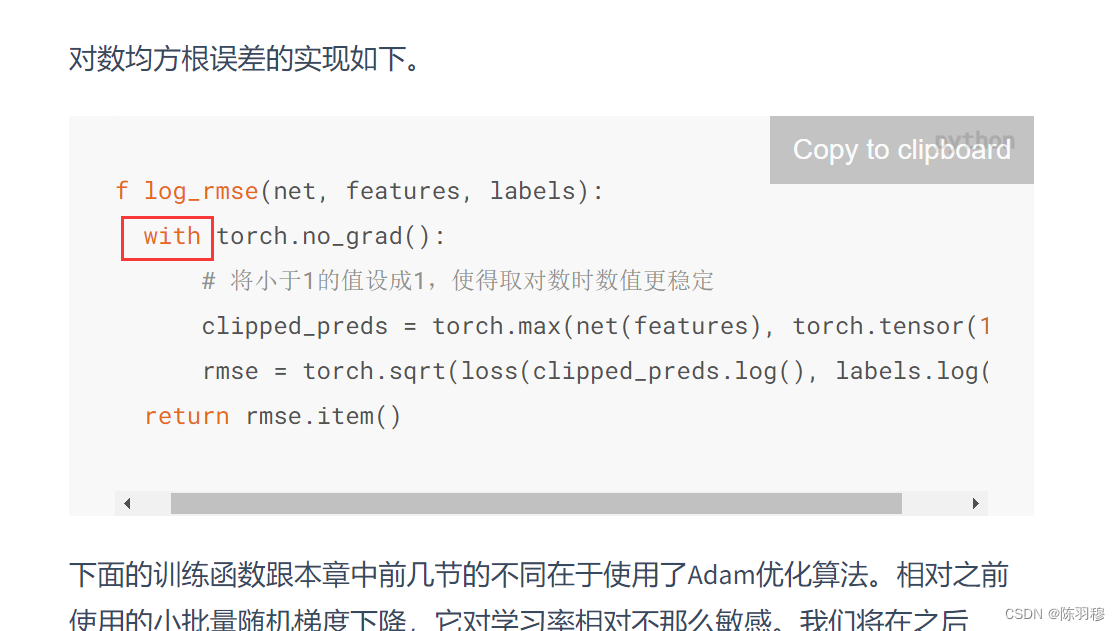
with torch.no_grad() 详解_失之毫厘,差之千里的博客-CSDN博客_torch.no_grad():

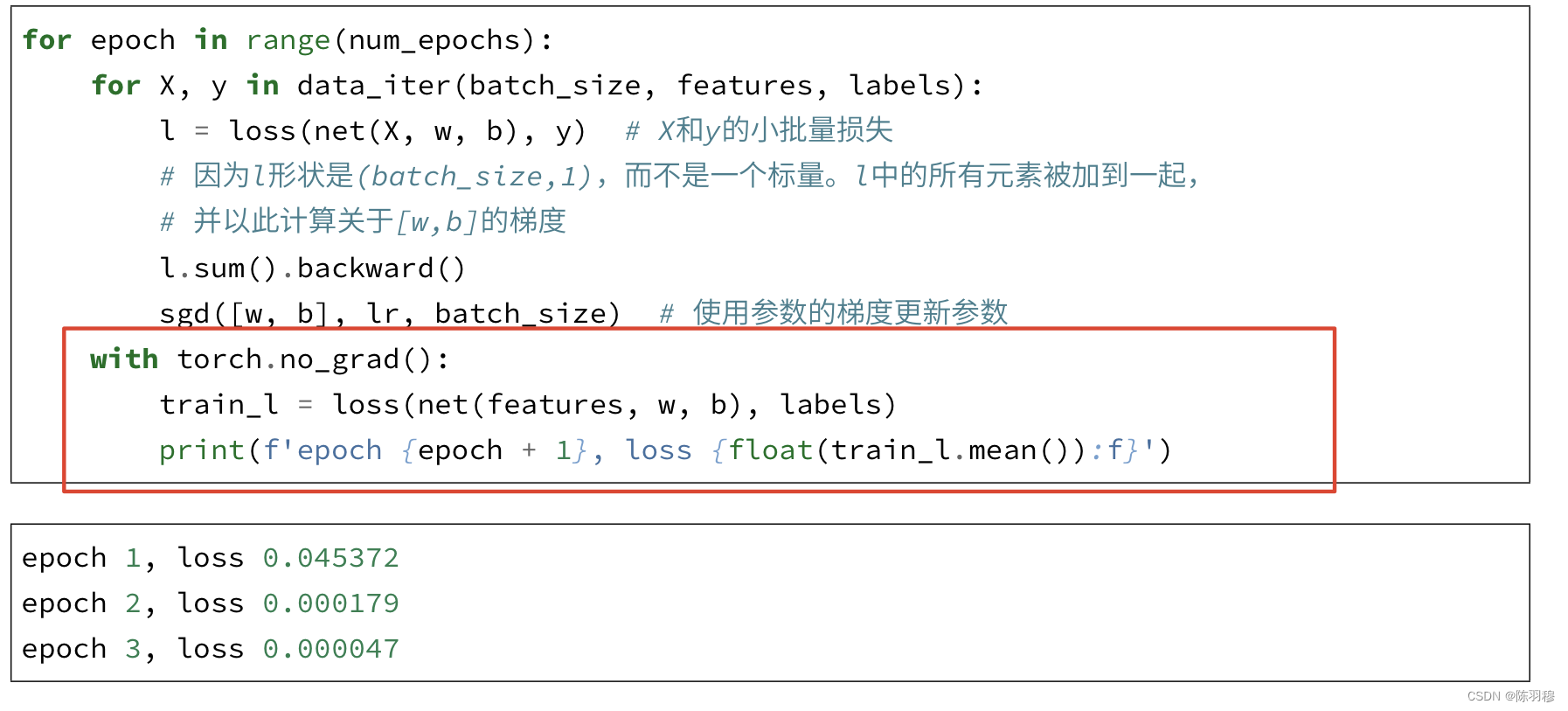
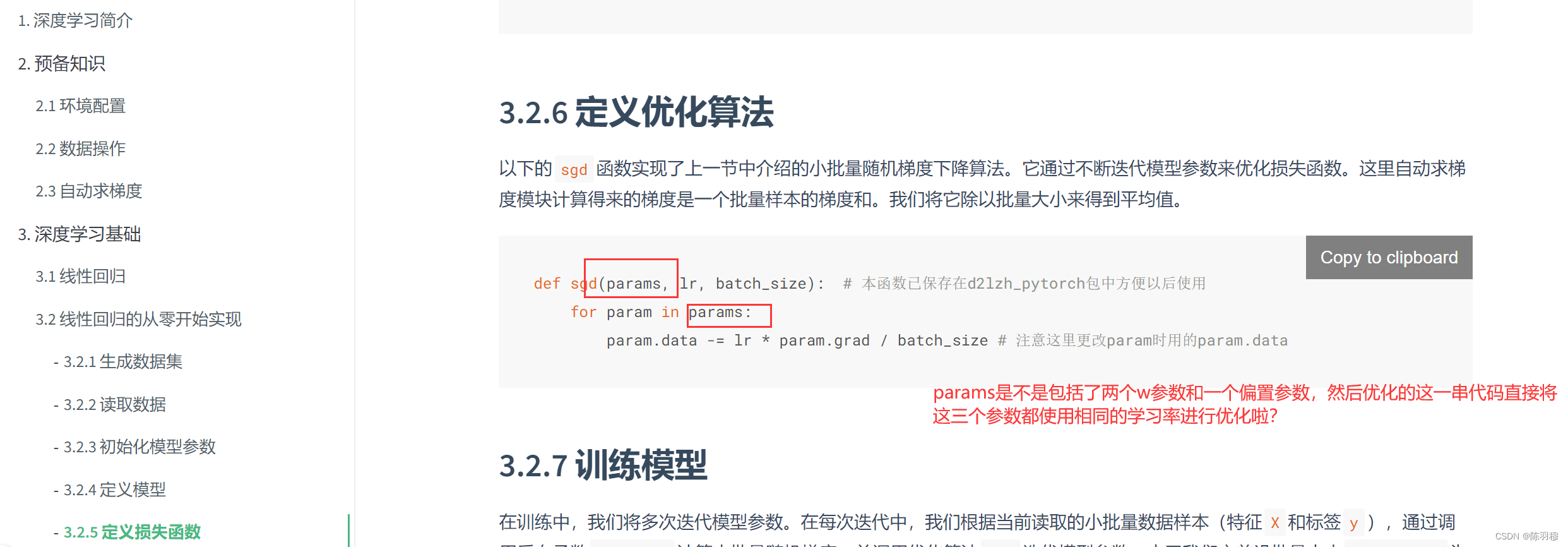
** !!!是只是将梯度清零了么?没有将w和b置零 **
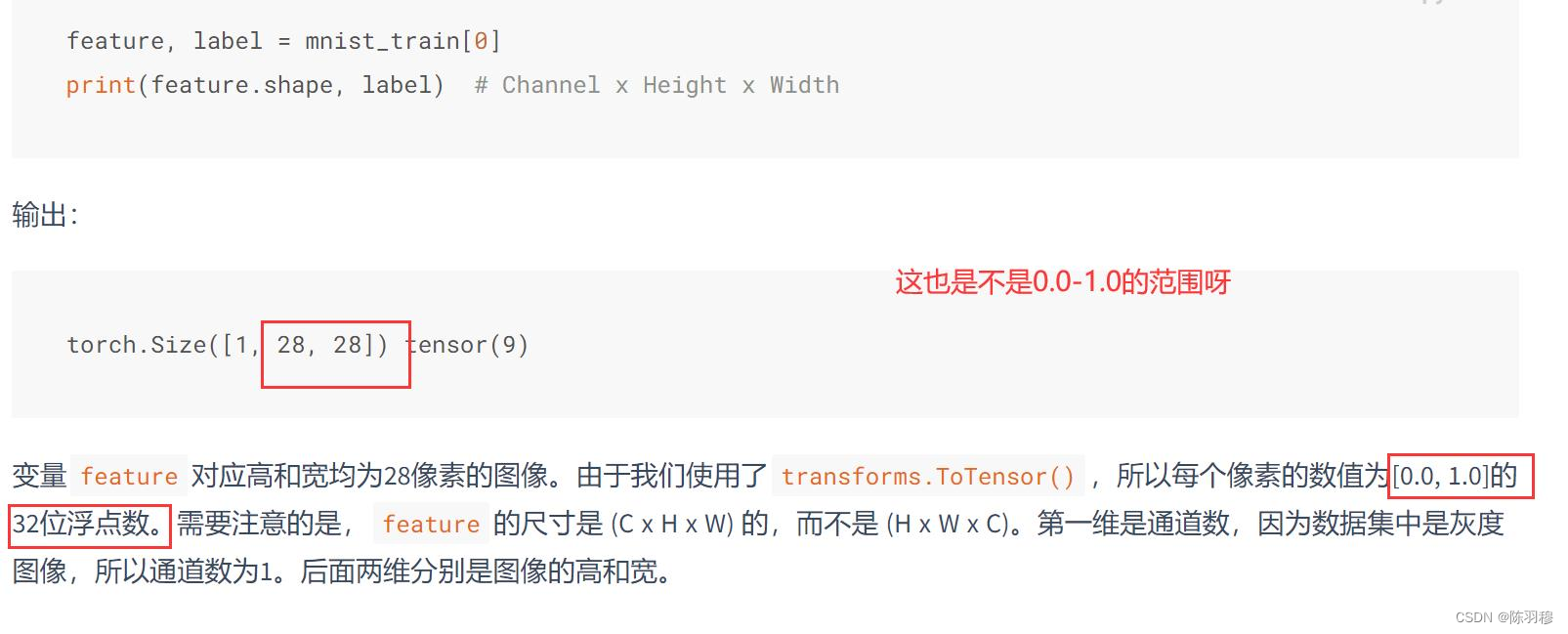

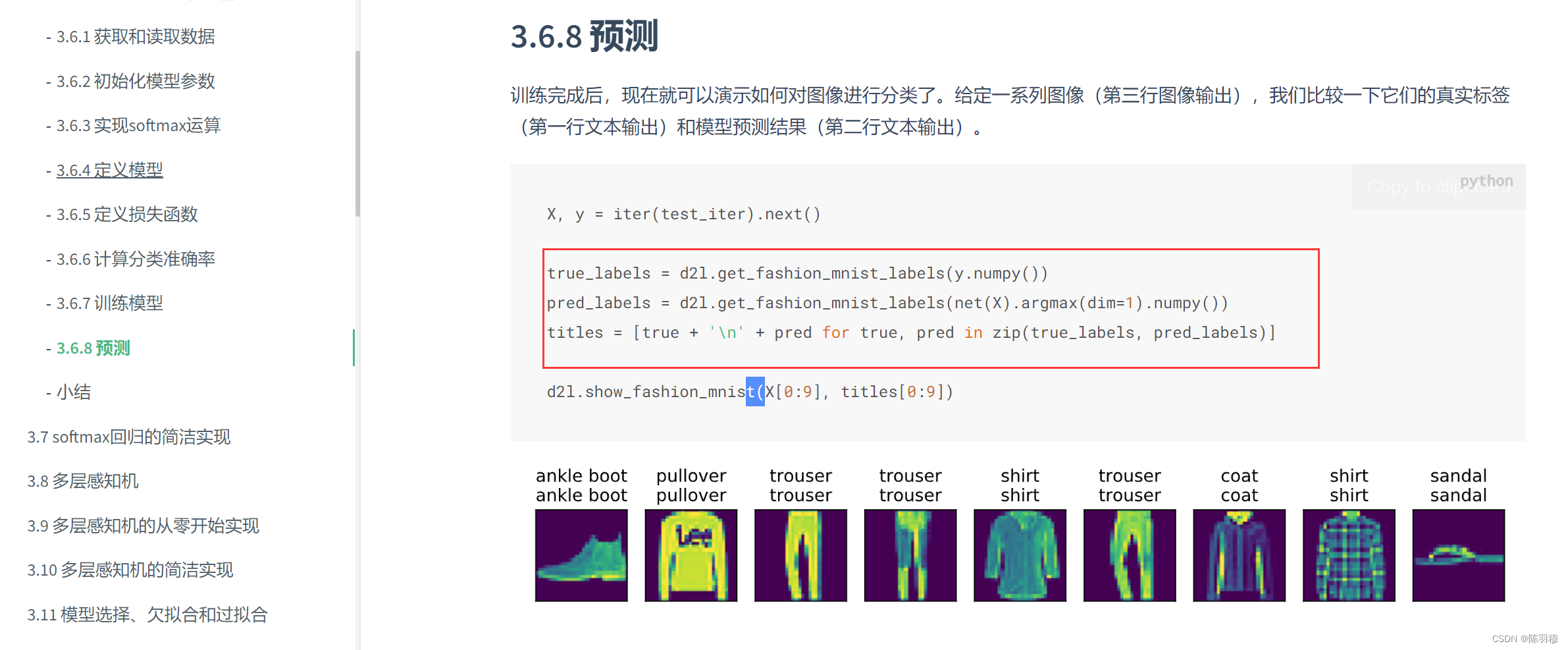
3.8 多层感知机 - Dive-into-DL-PyTorch (tangshusen.me)
梯度只能为标量(即一个数)输出隐式地创建。当输出不是标量时,调用.backwardI()就会出错 。
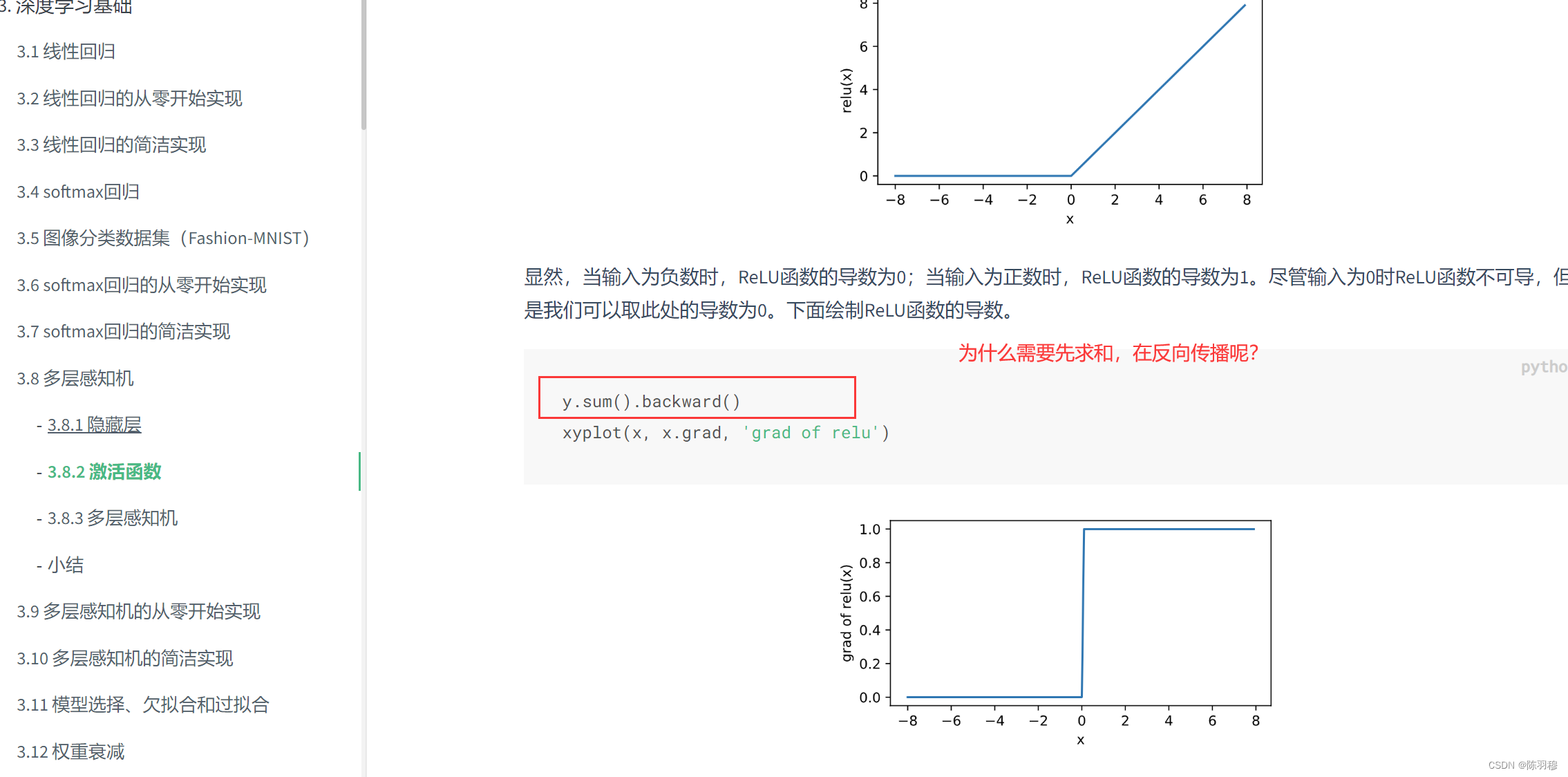
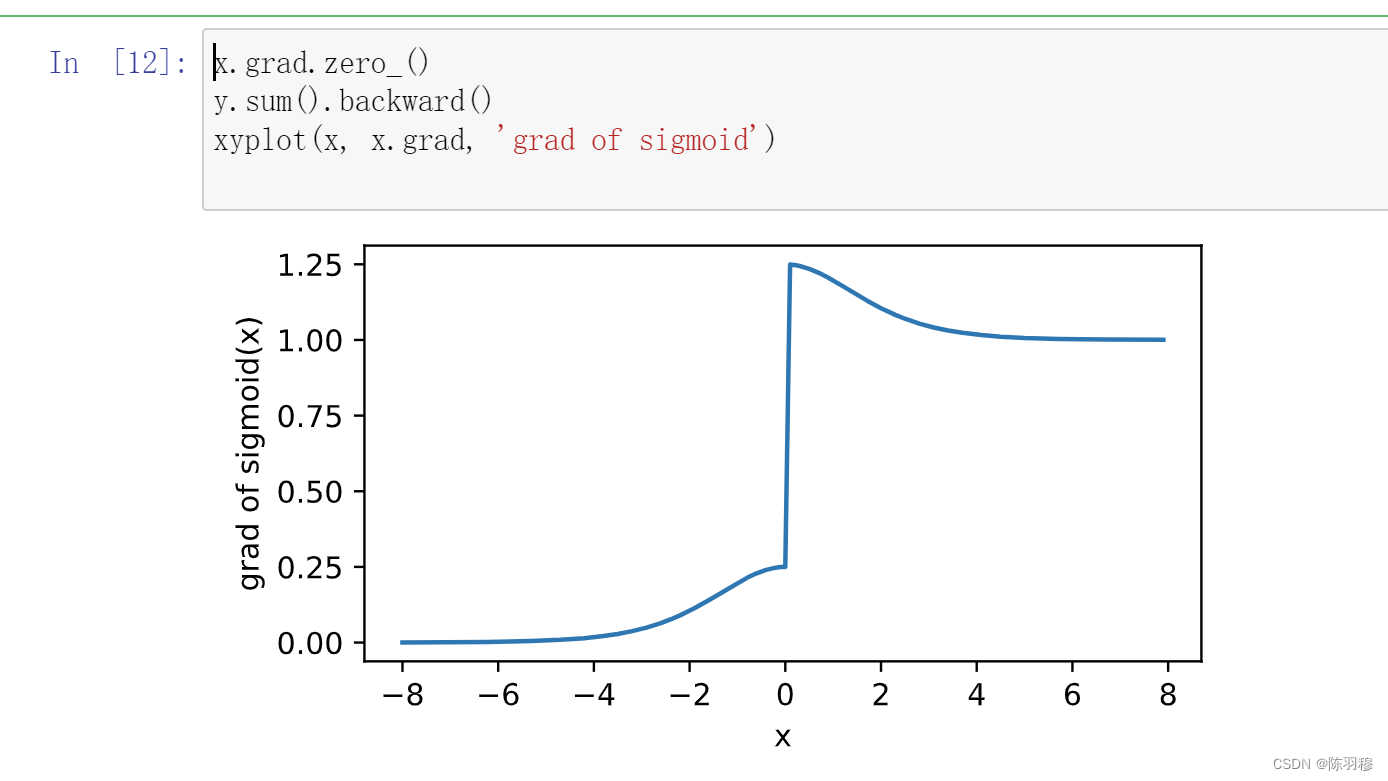
因为这一步,在执行上一步relu的时候,已经使用过x.grad,所以这一步需要将其置零,要不然会出现以下图案

pip install torchtext==0.13.0 ,torchtext成功安装成功,pytorch和torchtex版本号比对GitHub - pytorch/text: Data loaders and abstractions for text and NLP
torchtext安装教程_诸神缄默不语的博客-CSDN博客_torchtext安装
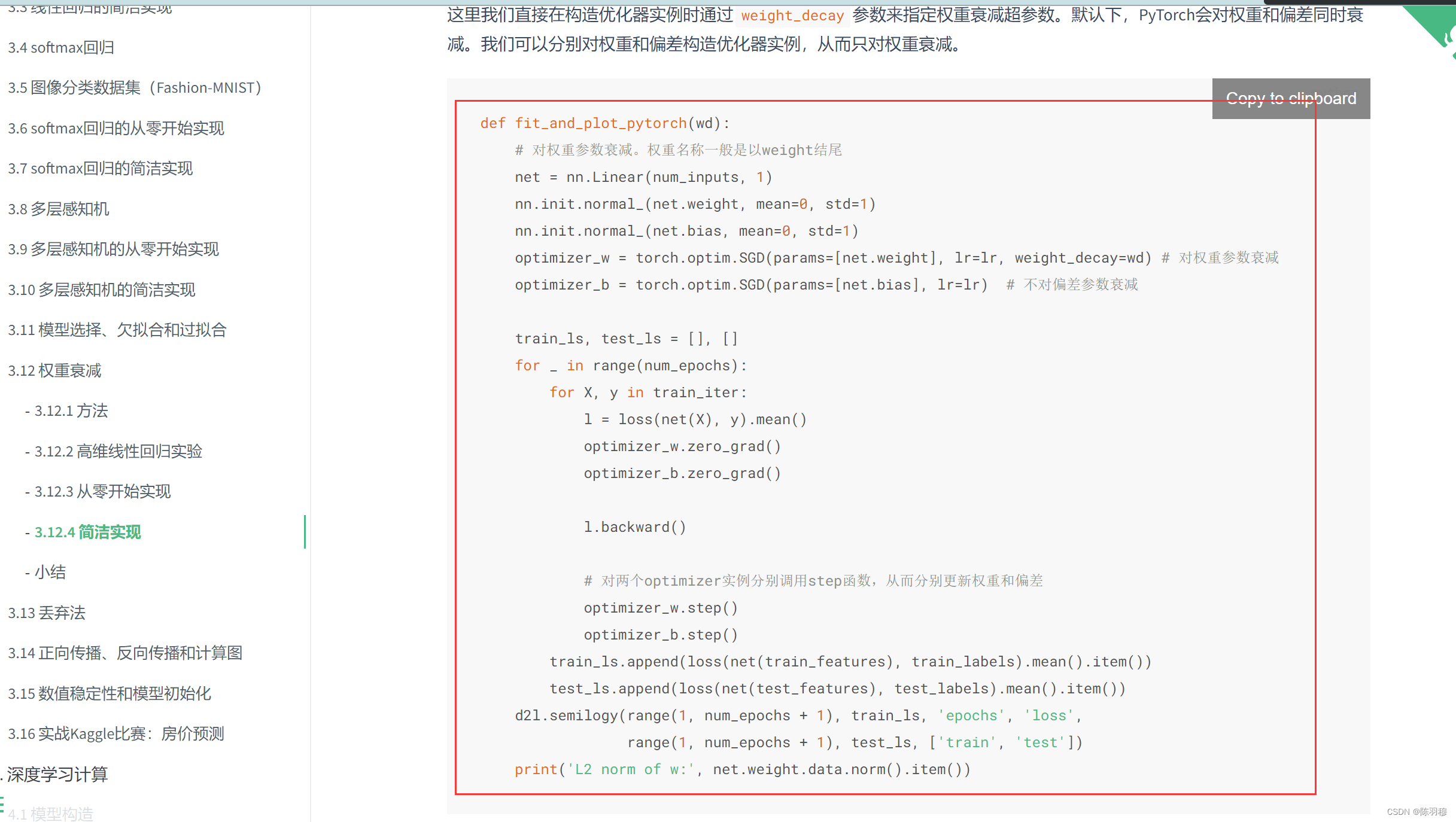
with torch.no_grad() 详解_失之毫厘,差之千里的博客-CSDN博客_torch.no_grad():
版权归原作者 陈羽穆 所有, 如有侵权,请联系我们删除。