
Hive 分桶表
一.概述
分区提供一个隔离数据和优化查询的便利方式。
不过,并非所有的数据集都可形成合理的分区。对于一张表或者分区,Hive 可以进一步组织成 ,也就是更为细粒度的数据范围划分;
分桶是将数据集分解成更容易管理的若干部分的另一个技术。
分区针对的是数据的存储路径;分桶针对的是数据文件。
分桶和分区的区别 ?
- 分桶针对的是数据文件,分区针对的是数据的存储路径;
- 分桶根据哈希函数进行分割,比较平均;分区按照字段的值进行分割,容易造成数据倾斜;
- 分桶分区互不干扰,可以把分区表进一步分桶;
如何创建分桶表 ?

分桶表的作用 ?
1)数据采样
案例1:如数据质量校验工作(一般会判断各个字段的结构信息是否完整);
案例2:在进行数据分析时,一天需要编写很多SQL,但是每编写一条SQL,都需要对SQL进行校验是否正确,
如果面对完整的数据集合做校验,会导致校验时间过长,影响进度,所以可以采样出一部分;
2)提升查询的效率(多表 join 优化)
二. 补充:通用的 join 优化
(1)空key过滤
使用场景:
①【外连接时】才用,内连接已经默认过滤null了)
②不需null字段的情况下
有时 join 超时是因为某些 key 对应的数据太多,而相同 key 对应的数据都会发送到相同 的 reducer 上,从而导致内存不够。因此先干掉异常的key!
例:在 join 之前就用
where is not null
过滤掉 ! 以免join之后再过滤;
select n.*from(select*from nullidtable where id isnotnull) n
leftjoin bigtable o on n.id = o.id;
(2)空key转换
有时虽然某个 key 为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在 join 的结果中
而同一个key的数据太大,同时进入一个reduce可能会导致数据倾斜;
此时可以表 a 中 key 为空的字段赋一个随机的值,使得数据随机均匀地 分不到不同的 reducer 上;
例:用
nvl(id,rand())
将为null 的字段赋为随机值;
select n.*from nullidtable n fulljoin bigtable o on nvl ( n.id,rand())= o.id;
三. 分桶表的作用
2.1 数据的采样
tablesample (bucket x outof y columnnanme)
x: 表示从第几个桶开始抽取,桶号是从1开始
y:抽取桶的比例,(总的桶数/2)=抽取桶的个数, 如10个桶,y=2即10/2=5个桶;
(y 必须是桶个数的因子或者倍数,如10个桶,y可以取2、5不能取3)
(x 一定要小于等于 y !)
columnname:表示按照哪个字段进行抽样(分桶字段)
tablesample
的位置:一定在from 表名的后面, 就算表有别名也要在别名的前面!
例: select * from table
tablesample
(bucket x out of y on column) as q;
例:
抽的桶个数: 20/5=4
2.2 提升查询效率(多表join优化)
(一)小表 join 大表
使用map join(
Block Cache
缓存技术,和环形缓冲区无关),在进行join时,将小表放在每个读取大表的MapTask的内存上,让mapTask每读取一次大表都和内存中小表的数据进行join,将join的结果输出到reduce端,从而实现在map端即reduce之前完成join的操作!
如何开启:
①开启map -join ②设置小表的阀值 ,默认25mb
(二)中表 join 大表
解决方案:
① 空key过滤,过滤成小表就能用map-join了
如:select n.* from (select * from nullidtable where id is not null) n left join bigtable o on n.id = o.id;
② 空key转换,可以尝试添加随机数(保证各个reduce接收的数据量差不多,减少数据倾斜)
如:select n.* from nullidtable n full join bigtable o on nvl ( n.id,rand() ) = o.id;
③基于分桶表的 bucket map join ,即两个表都以桶为单位拆分,让每个桶的数据分别去进行两个表的map-join,即中型表的桶就是map-join的小表,大表的桶和小表的桶对应进行join,比普通mapjoin效率更高;
bucket map join的条件:
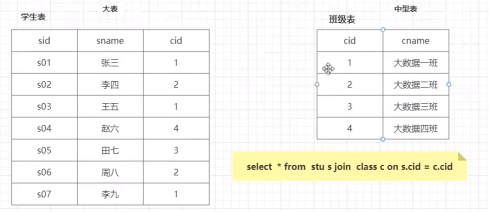
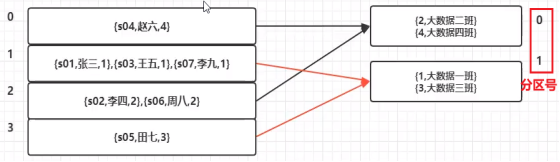
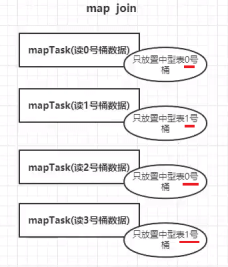
(三)大表 join 大表
整体思想和普通的bucket map join类似,将两个表按照桶进行拆分,不过此时两个表的数量相同,所以一个桶对应一个桶,每个桶达到map join的条件,一个桶放在一个maptask的内存中;
① 空key过滤,减少 join 的数量,提升效率;
② 空key转换,可以尝试添加随机数(保证各reduce接收的数据量接近,从而减少数据倾斜);
③ SMB(sort merge Buckect Map join);
SMB map join 条件:
①开启参数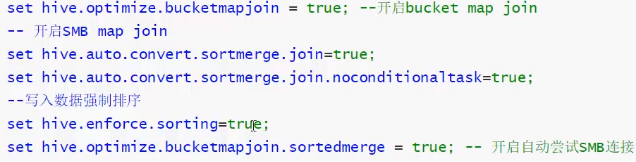
②两个表的bucket桶数量要相等! 而不是整数倍!
③bucket列=join列=sort列
版权归原作者 斯沃福德 所有, 如有侵权,请联系我们删除。