
一、介绍Hadoop生态圈相关组件
Hadoop是目前应用最为广泛的分布式大数据处理框架,其具备可靠、高效、可伸缩等特点。
Hadoop的核心组件是HDFS、MapReduce。随着处理任务不同,各种组件相继出现,丰富Hadoop生态圈,目前生态圈结构大致如图所示:
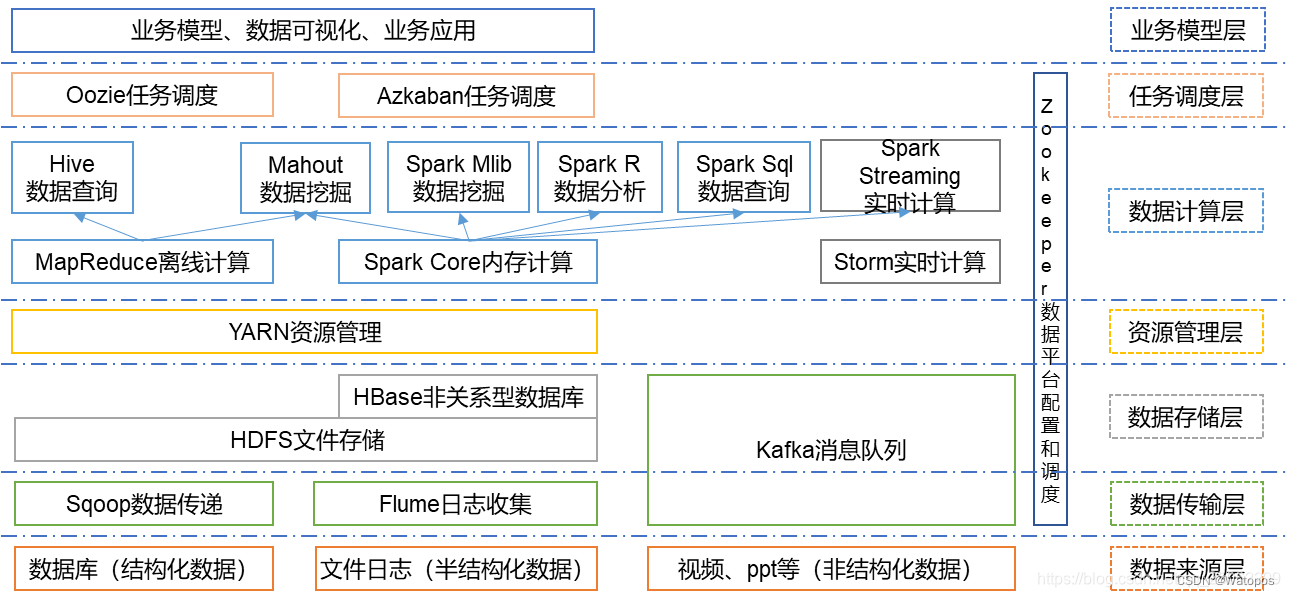
根据服务对象和层次分为:数据来源层、数据传输层、数据存储层、资源管理层、数据计算层、任务调度层、业务模型层。
生态圈相关组件:
- HDFS
HDFS:是一个分布式文件系统。
- MapReduce
MapReduce是一个分布式、并行处理的编程模型。
- YARN
是一个分布式资源管理系统,主要负责整个系统的资源管理和调度。
- HBase
HBase是一个建立在HDFS之上的面向列的数据库,用于快速读/写大量数据。HBase使用ZooKeeper进行管理,以确保所有组件都能正常运行。
- ZooKeeper
ZooKeeper是分布式协调服务的框架。
- Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,可以将SQL语句转换为MapReduce任务运行。
Hive的执行原理就是:将SQL语句翻译为MapReduce作业,并提交到Hadoop集群上运行。
- Pig
Pig是一个用于并行计算的高级数据流语言和执行框架,有一套和SQL类似的执行语句,处理的对象时HDFS上的文件。Pig的数据处理语言采取数据流方式,一步一步地进行处理。
- Sqoop
Sqoop是一个用于在关系数据库、数据仓库(Hive)和Hadoop之间转移数据的框架。可以借助Sqoop完成关系型数据库到HDFS、Hive、HBase等Hadoop生态圈中框架的数据导入导出操作,其底层也是通过MapReduce作业来实现的。
- Flume
Flume是由Cloudera提供的一个分布式、高可靠、高可用的服务,是用于分布式的海量日志的高效收集、聚合、移动/传输系统的框架;Flume是一个基于流式数据的非常简单的(只需要一个配置文件)、灵活的、健壮的、容错的架构。
- Oozie
Oozie是一个工作流调度引擎,在Oozie上可以执行MapReduce、Hive、Spark等不同类型的单一或者具有依赖性(后一个作业的执行依赖于前一个或者多个作业的成功执行)的作业。类似的在大数据中使用的工作流调度引擎还有Azkaban。
- Mahout
Mahout是一个机器学习和数据挖掘库,它提供的MapReduce包含很多实现,包括聚类算法、回归测试、统计建模。
二、详细介绍MapReduce的特点及运行架构
2.1MapReduce特点:
- 易于编程。它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器运行。
- 良好的扩展性。当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
- 高容错性。 MapReduce 设计的初衷就是使程序能够部署在廉价的PC机器上, 这就要求它具有很高的容错性。
- 能对PB级以上海量数据进行离线处理。适合离线处理而不适合实时处理, 比如要求毫秒级别的返回一个结果, MapReduce 很难做到。
2.2运行架构

三、详细介绍spark的特点,并与MapReduce作对比说明区别
3.1spark特点:
1.运行速度迅速:Spark基于内存进行计算(当然也有部分计算基于磁盘,比如shuffle),内存计算下,Spark 比 Hadoop 快100倍。。
2.容易上手开发:Spark的基于RDD的计算模型,比Hadoop的基于Map-Reduce的计算模型要更加易于理解,更加易于上手开发,实现各种复杂功能,比如二次排序、topn等复杂操作时,更加便捷。
3.超强的通用性:Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图计算等常见的任务。
4.集成Hadoop:Spark并不是要成为一个大数据领域的“独裁者”,一个人霸占大数据领域所有的“地盘”,而是与Hadoop进行了高度的集成,两者可以完美的配合使用。Hadoop的HDFS、Hive、HBase负责存储,YARN负责资源调度;Spark复杂大数据计算。实际上,Hadoop+Spark的组合,是一种“double win”的组合。
5.极高的活跃度:Spark目前是Apache基金会的顶级项目,全世界有大量的优秀工程师是Spark的committer。并且世界上很多顶级的IT公司都在大规模地使用Spark。
3.2对比
1、Spark处理数据是基于内存的,而MapReduce是基于磁盘处理数据的
MapReduce是将中间结果保存到磁盘中,减少了内存占用,牺牲了计算性能。
Spark是将计算的中间结果保存到内存中,可以反复利用,提高了处理数据的性能。
2、Spark在处理数据时构建了DAG有向无环图,减少了shuffle和数据落地磁盘的次数
Spark计算比MapReduce快的根本原因在于DAG计算模型。一般而言,DAG相比MapReduce在大多数情况下可以减少shuffle次数。Spark的DAGScheduler相当于一个改进版的MapReduce,如果计算不涉及与其他节点进行数据交换,Spark可以在内存中一次性完成这些操作,也就是中间结果无须落盘,减少了磁盘IO的操作。但是,如果计算过程中涉及数据交换,Spark也是会把shuffle的数据写磁盘的。
3、Spark比MapReduce快
有一个误区,Spark是基于内存的计算,所以快,这不是主要原因,要对数据做计算,必然得加载到内存,Hadoop也是如此,只不过Spark支持将需要反复用到的数据Cache到内存中,减少数据加载耗时,所以Spark跑机器学习算法比较在行(需要对数据进行反复迭代)。
4、Spark是粗粒度资源申请,而MapReduce是细粒度资源申请
粗粒度申请资源指的是在提交资源时,Spark会提前向资源管理器(YARN,Mess)将资源申请完毕,如果申请不到资源就等待,如果申请到就运行task任务,而不需要task再去申请资源。
MapReduce是细粒度申请资源,提交任务,task自己申请资源自己运行程序,自己释放资源,虽然资源能够充分利用,但是这样任务运行的很慢。
5、MapReduce的Task的执行单元是进程,Spark的Task执行单元是线程
进程的创建销毁的开销较大,线程开销较小。
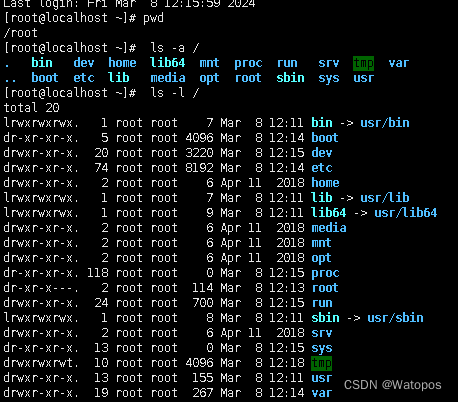
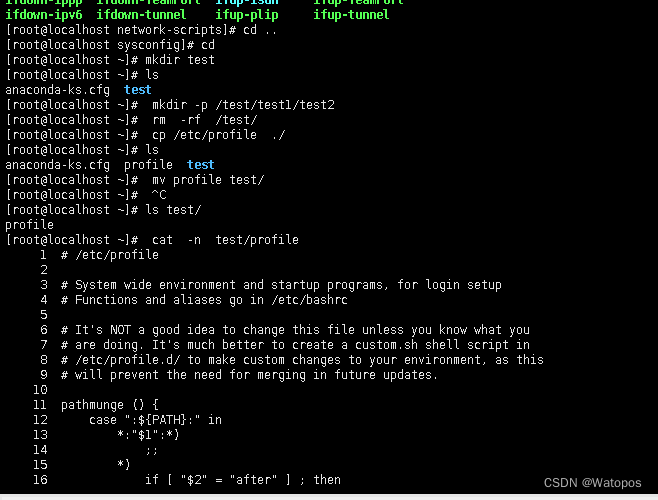
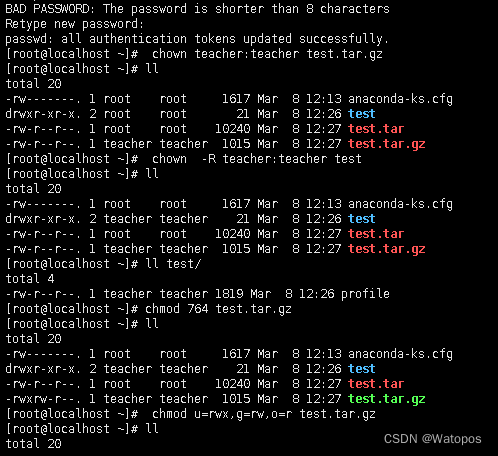
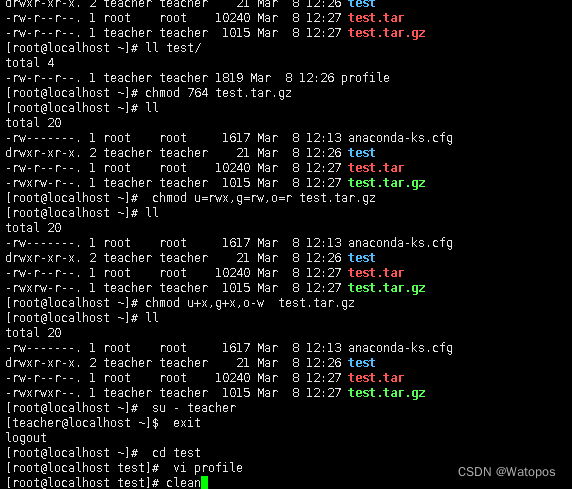
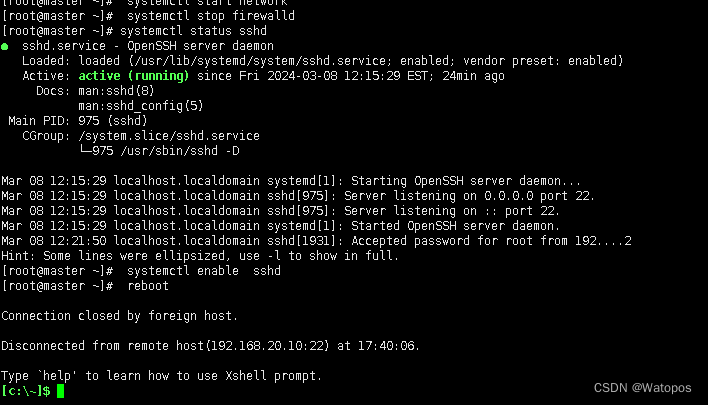
四、熟练掌握Linux操作命令并演示说明



五、冷备 温备 热备
1.热备:热备是在数据库运行期间进行备份的方式。 它可以实时备份数据库的数据和日志,保证数据的完整性和一致性。 常见的热备份方式有基于二进制日志(Binary Log)的备份和基于复制(Replication)的备份。
2.冷备:冷备是在数据库停止运行时进行备份的方式。 在进行冷备份之前,需要先停止数据库服务,然后将数据库文件进行拷贝或者打包压缩。 冷备份的优点是简单、可靠,但需要停止数据库服务,会造成一段时间的不可用。
3.温备:温备是介于热备和冷备之间的一种备份方式。 它是在数据库运行期间进行备份,但是不会备份所有的数据和日志,而是只备份部分数据或者增量数据。 温备可以减少备份所需的时间和资源消耗,但在恢复时可能需要额外的操作。
六、数据类型 (举例说明)
(1)整数类型:byte、short、int、long
(2)小数类型:float、double
(3)字符类型:char
(4)布尔类型:boolean
版权归原作者 Watopos 所有, 如有侵权,请联系我们删除。