
前言

事务~
什么是事务~
事务诞生的目的就是为了把若干个独立的操作给打包成一个整体~~
案例:
1.你要去银行取钱~
2.取完钱要去和女神约会~
如果你不取钱你就没办法和女神约会
你只有有钱了才能带女神约会但是如果你取完钱了女神突然不想和你约会了那你不是钱就白取了吗存在银行里吃几分的利息不香嘛所以这就相当于是两个独立的操作给打包成一个整体~~
要么就是把两个操作都执行完~
要么就一个操作也不执行~
不需要存在
只执行了第一步不执行第二步的中间状态~~这种情况下就可以使用事务~
事务的原子性~
在SQL中
有的复杂的任务需要多个SQL来执行的时候也同样需要打包在一起~前一个SQL是为了给后一个SQL提供支持
如果后一个SQL不执行出问题了前一个SQL也就失去了意义~~这样的特点我们就叫做原子性:要么全都执行完,要么一个都不执行,任务不可以被再细分~~
案例:
转账~
A给B转500
账户表(name, balance)
A 1000 B 1000给A这个账户余额减500
update 账户表 set balance = balance - 500 where name = "A";
给B这个账户余额加500
update 账户表 set balance = balance + 500 where name = "B";
那么在转账过程中,就可能会出现问题~
考虑一个极端情况:
执行完成第一个SQL之后,在执行第二个SQL之前,数据库崩了/程序崩了/机器崩了/机器断电了~
导致这里面的转账转出了一半这样一个中间状态~
显然这种中间状态是不科学的~~
而事务的原子性,就能避免出现这种中间状态~~
事务的原子性到底是咋避免的呢?
要么就全部执行~
要么就一个都不执行~~(其实该执行还是得执行,无法预知失败
当我们出现执行失败之后,由数据库自动执行一些"还原"性的工作,来消除前面的SQL带来的影响看起来就好像一个都没执行一样~)像这样还原性的工作我们把它称为"回滚"
你在执行到第二个SQL之前,你又没办法预知这次行动失败~~这个时候,就还是得先执行第一个SQL,执行完之后再执行第二个SQL,你只能试试看~
案例:
假设A给B转了500之后,接下来执行第二个SQL的时候出现了意外,导致无法执行~~
那么接下来数据库就会还原之前操作~~
也就是把之前改动过的数据给还原回去(上个操作是减,现在就是加,上个操作是乘,下个操作就是除)~
数据库是如何知道该还原成哪个值的呢?
数据库会拿个小本子,把执行过得每个操作都给记录下来~
既然都能还原,是不是就可以放心大胆的删除数据库了呢?
不可以~
数据库如果把这里面的所有操作都记得那么详细,也是要消耗大量的时间和空间的~
因此这个记录是必不会保存那么久~
如果你的数据库是经过了一年的时间沉淀出来的数据,但你的这些操作可能只记录了几天的.....
最近的这几天的操作可能也去能给你还原出来,但是要想把这一年中间零零散散的各种操作给它回溯回去,这种事其实就没那么容易了~
如果你想把整个库都还原,这事还是得依赖于备份~~
不要对删库这种行为跃跃欲试~~~no zuo no die why you try~~
备份其实更多的是为了应对一些突发情况,硬盘坏了.....(出现的概率比删库的概率其实更高,就不细讲了)~~
**事务相关的面试题~ **
谈谈事务的基本特征~
四个基本特征~
1.原子性:
把这些操作打包成一个整体,要么全都执行要么就一个都不执行~
2.一致性~
在事务执行之前和执行之后,数据库中的数据都是合理合法的~
例如:你转完账之后,不能出现这种账户为负数的情况~或者出现小数的情况
3.持久性~
事务一旦提交之后,数据就被持久性存储起来了
数据就写入硬盘了4.隔离性~
隔离性描述的是,事务并发执行的时候,产生的情况!!!
并发编程,是当下最主要的一个编程方式~~
写出来的代码,是并发式执行的~~(通俗点讲就是一心两用~)
但是人脑特别不擅长一心两用,而计算机特别擅长~~
计算机擅长并发,也是迫不得已~~
大家应该都听过"duoheCPU"
单个核心的提升能力已经快达到瓶颈了~~CPU是通过在硅晶圆上进行刻蚀电路(光刻机)制作出来的,很难很难做出来~
为什么难做呢?因为要提高算力,就得让单个的电路模块尽量小
能无限小嘛?显然不可能当物体小到一定程度的时候,经典力学就已经失效了,量子力学开始监管~
当我们并发执行多个事务,尤其是这多个事务都在尝试修改/读取同一份数据~
这个时候就同一出现一些问题~
事物的隔离性,就是在解决这样的问题~~
并发执行事务可能带来的问题~~
脏读~
有一天,我在写代码
写一个课后作业的代码比如:我在写代码中写了一个student类
在我写代码的过程中,有一个同学,在后面瞄了我屏幕,看到了我写的代码(看到了我写的代码里面有一个student类,有一些属性....)看完之后,他就走人了然后后面我把代码给改了~~
这个时候就意味着他在这里瞄的一眼,瞄到的并不是一个最终版本的数据.而是一个中间过程的数据
这里可能最终会被修改成别的值像这样的一个情况就成为"脏读"问题~
事务A在对某个数据进行修改,修改的同时,事务B去读取了这个数据.此时事务B读到的很可能是一个"脏数据"(这个数据是一个临时的结果,而不是最终的结果)
那么如果事务B拿着这个"脏数据"在进行一些后续操作很有可能就会出现问题.
出现脏读问题,原因就是事务和事务之间,没有进行任何的隔离~~如果加上一些约束限制,就可以有效的避免脏读问题~
如何处理脏读:给写操作加锁~
在修改的过程中,别人不能读了(加锁状态)
等修改完了之后,别人才能读(解锁状态)
和同学约好
不用着急窥屏我写完的作业会提交到码云上,你来看我码云上的代码~~
码云上就是我修改完毕的代码~~这样,同学读到的数据就不再是中间数据了~
一旦加上了写锁之后,就意味着事务之间的隔离性就高了,并发性就降低了
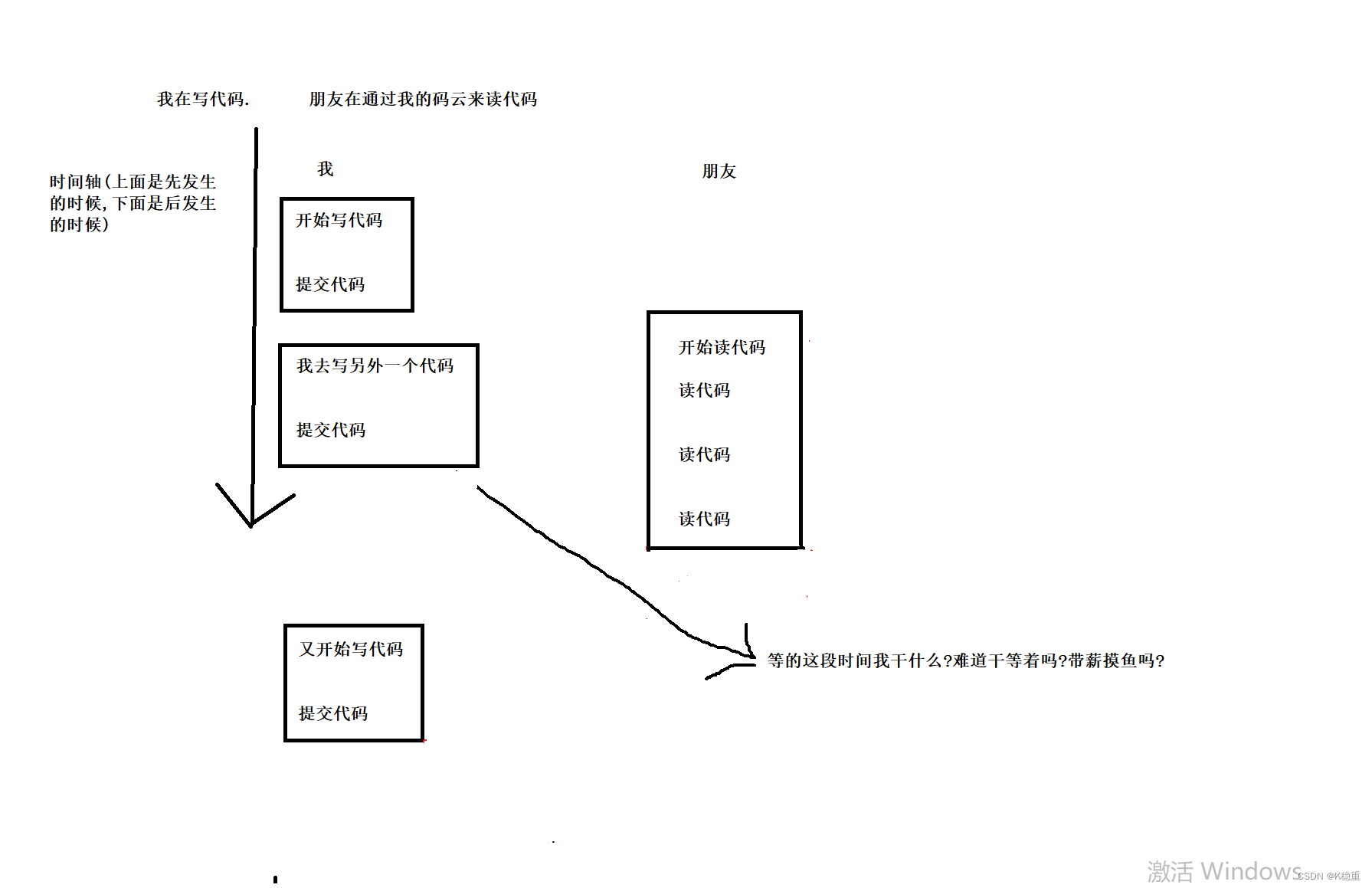
不可重复读~
我在写代码
朋友在通过我的码云来读取代码我开始写代码,写完之后提交码云,就可以把这个操作视为一个事务
同学在我提交之后开始读代码~
按照刚才针对脏读问题的约束.
给写操作进行了加锁,朋友要等我提交之后才能开始读~
但是在朋友读的过程中我可不可以继续写代码呢
当然可以
所以我可能要对代码进行修改
所以我又开始写代码,提交码云
这个时候在我第二次修改代码到提交之前,朋友读到的是我写的第一个版本的代码,在我修改完毕重新上传之后读到的又是我改的第二个版本的代码~
这样的话就出现了另外的问题:
在一个事务中,包含了多次的读操作,这多次的读操作读出来的结果不一致~
刚才约定的是,写的过程中不能读,没说读的过程中不能写~
这样的问题我们就叫做"不可重复读"
如何解决?
刚才这个问题就好比说:朋友在通过码云读代码~~随便刷新了一下,发现代码变了....(又得重新整理)
所以我们再做一个约定
之前咱么约定的是,你修改的时候我不能读,现在再约定一下,我读的时候,你也别修改给读操作也加锁了~~
意味着我必须得等朋友把代码读完了,才能进行修改~~
通过给读操作也加锁,就解决了不可重复读的问题~
此时事务的并发性又降低了,隔离性又提高了~~
并发性和隔离性二者不可得兼~~
到底要跑的快还是跑的对?
这件事需要看情况进行取舍了~~
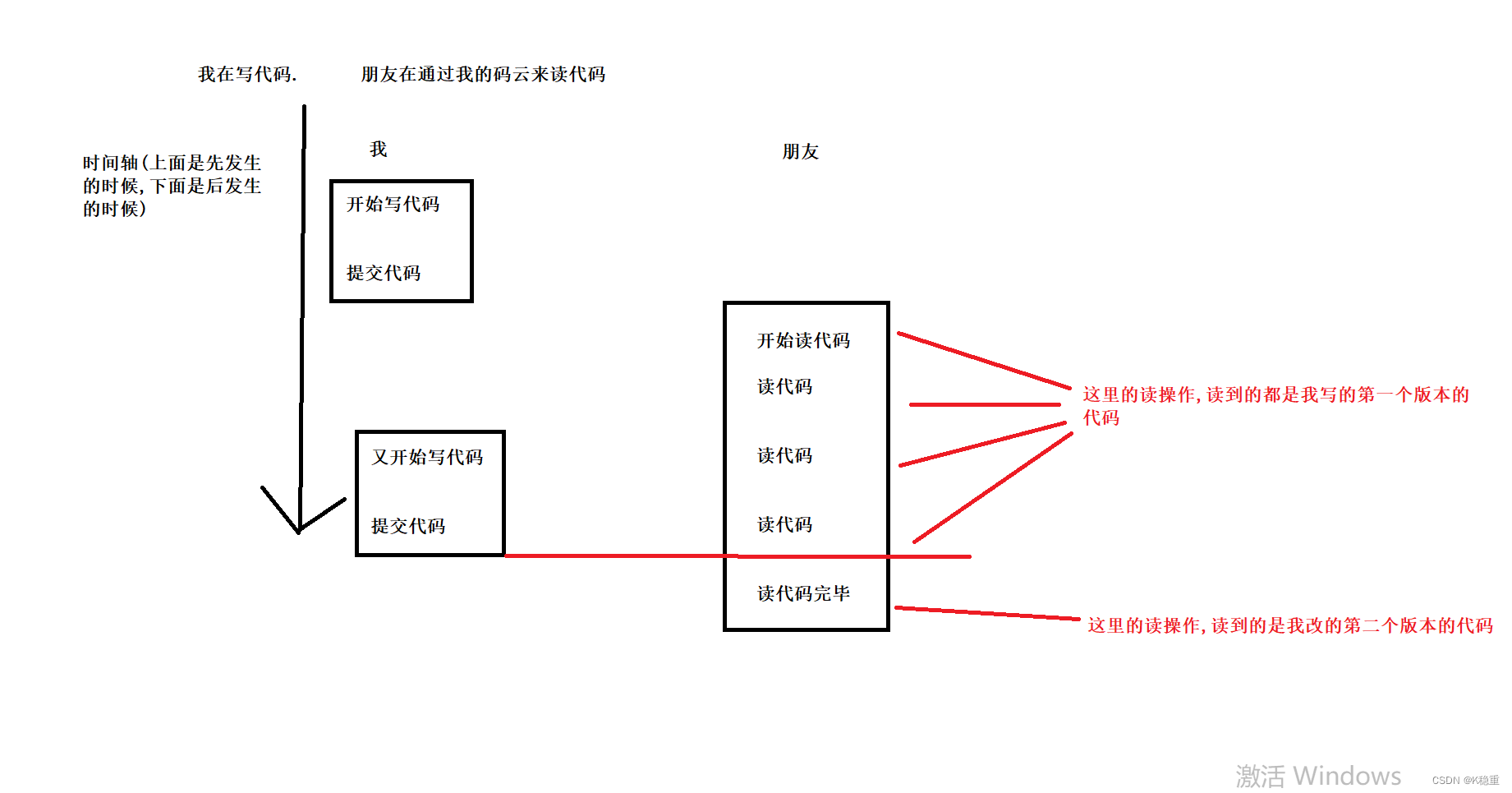
幻读~
我开始写代码,提交代码~
朋友读代码
此时我想写代码或者修改代码就得等朋友读完代码~
等的这段时间我该干嘛呢?不能干等着把,带薪摸鱼?不可取
所以我就决定去写另外一个代码,再提交码云~
注意:事务虽然在提交隔离性的时候要进行一系列加锁,但是这个锁也不是把整个数据库都给锁定了~
还可以改其他的表,甚至说改这个表的其他的行~~
假设朋友在读我写的代码JavaA,在读的过程中,发现代码数量变了~~
本来只有一个JavaA的,现在有多了一个JavaB~
这种就被称为"幻读"问题
一个事务执行的过程中进行了多次查询,多次查询的结果集不一样了~~(多了一条或者少了一条)
这个操作算是一种特殊的不可重复读~~
解决幻读问题:彻底串行化执行~~
朋友和我说好,他读代码的时候,我就赶紧摸鱼,不要写任何代码了......
这种就是隔离性最高,并发程度最低,数据最可靠,速度最慢~
并发(更快)和隔离(更准)是不可兼得~~
就可以根据实际需要来调整数据哭的隔离级别~~
通过不同的隔离级别,也就控制了事务之间的隔离性,也就控制了并发程度~~
MySQL中事务的隔离级别~
1.read uncommitted:允许读取未提交的数据,并发程度最高,隔离程度最低,会引入脏读+不可重复读+幻读问题~~
2.read committed:只允许读取提交之后的数据,相当于写加锁,并发程度降低了一些,隔离程度提高了一些,解决脏读,会引入不可重复读+幻读~
3.repeatable read:相当于给读和写都加锁,并发程度又降低了,隔离程度又提高了,解决了脏读和不可重复读,会引入幻读
4.serializable:串行化,并发程度最低(串行执行),隔离程度最高,解决了脏读,不可重复读,幻读问题,但执行速度最慢~
这几个隔离级别我们可以通过修改my.ini这个配置文件,来设置当前的隔离级别~
根据实际需求场景,来决定使用哪种隔离级别~~
**MySQL中的JDBC编程~ **
实际开发程序必要过程~
首先MySQL是一个客户端-服务器结构程序~
黑框框只是一个官方提供的客户端,官方也允许程序猿自己实现MySQL的客户端,并且MySQL提供了一组**API(计算机行业中经常见到的术语~Application Programming Interface:应用程序编程接口,MySQL提供了一些方法/类,供程序猿直接使用)**来支持程序猿实现这样的客户端
自己实现的客户端可以根据需要来完成一些更具体的增删改查功能咱们很容易的能够实现一个MySQL客户端
但是并不容易实现MySQL服务器.....MySQL服务器是本体,非常复杂....

**JDBC~ **
数据库又不是只有MySQL~~
还有Oracle,SQL sever,SQLite......
MySQL提供了API
Oracle也提供了API......
MySQL提供的API和Oracle提供的API是不是一样的?
显然这些不同的数据库是出自不同厂商之手~
而且关于数据库API的约定,并没有一个业界统一的标准~~
Java一看,不乐意了~~Java表示我诞生就是为了跨平台(这是Java诞生的初衷)
**Java就搞了一个大一统的方案:**JDBC~
Java约定了一组API:称为****JDBC
这组API里面就包含了一些类和一些方法,通过这些类和方法来实现数据库的基本操作~~
让JDBC和这些不同的数据库对接,再由各个厂商,提供各自的"数据库驱动包(通过驱动包把自己的API转换成JDBC风格的,两者对接在一起)",来和JDBC的API对接~~
程序猿只需要掌握这一套JDBC API就可以操作各种数据库了~~
总结一句话:啥是JDBC,就是一组类和方法
会了这个,就可以操作所有的数据库
学习使用JDBC编程~
创建项目~
1.打开idea: 点击new project
点击之后
设置名字,目录,点击Create
引入依赖~
JDBC编程需要用到MySQL的驱动包(驱动包就是把MySQL自身的API给转换成JDBC风格的)
驱动包是MySQL官方提供的~~
下载驱动包(从MySQL官方网站~~但是MySQL被Oracle收购了,Oracle的官方做的不太行.....)
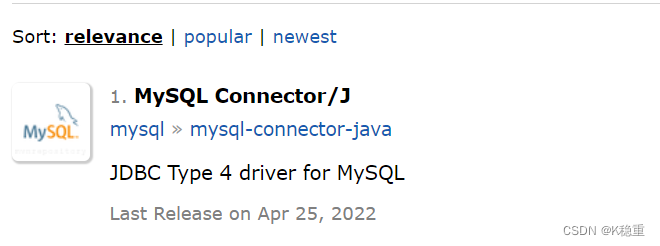
更好的选择可以去maven(Java中构建工具)中央仓库~
每次装个软件(第三方库)都需要去官网上找,就比较麻烦,就可以把这些第三方库给汇总起来,统一放到一个地方,中央仓库来下载~
中央仓库就相当于手机的应用商店~
搜索MySQL第一个就是
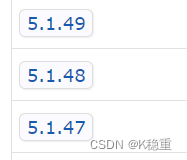
选择版本
因为我都MySQL版本是5系列的,所以jdbc版本要和mysql版本对应~~
如果你MySQL版本是8系列,就得用8系列的jdbc驱动~~
选一个版本点击一下:
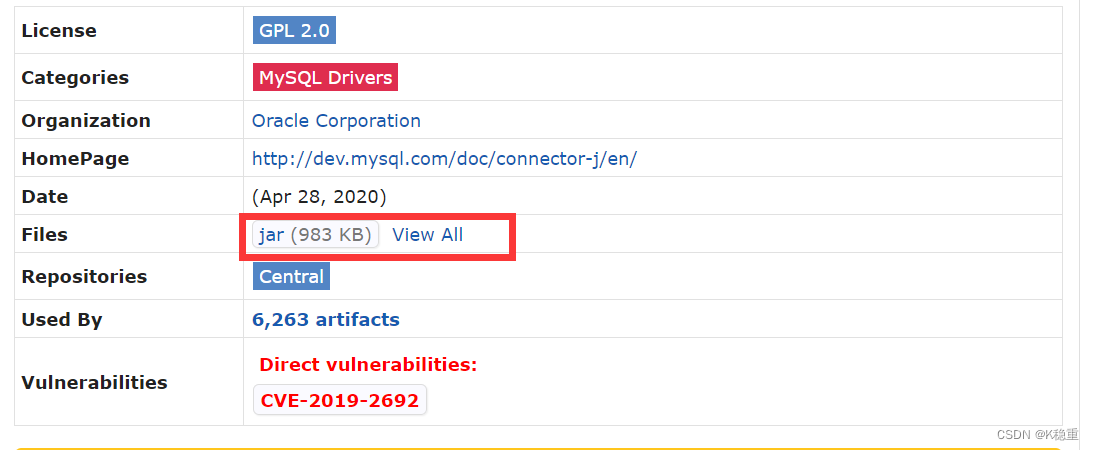
点击之后就会进入到这个界面
点击标红的地方就会下载驱动包
下载之后就会得到一个jar这样的文件(就相当于.zip这样的压缩包一样)
jar里面就是一些其他人写好的.class文件~

导入到项目中~
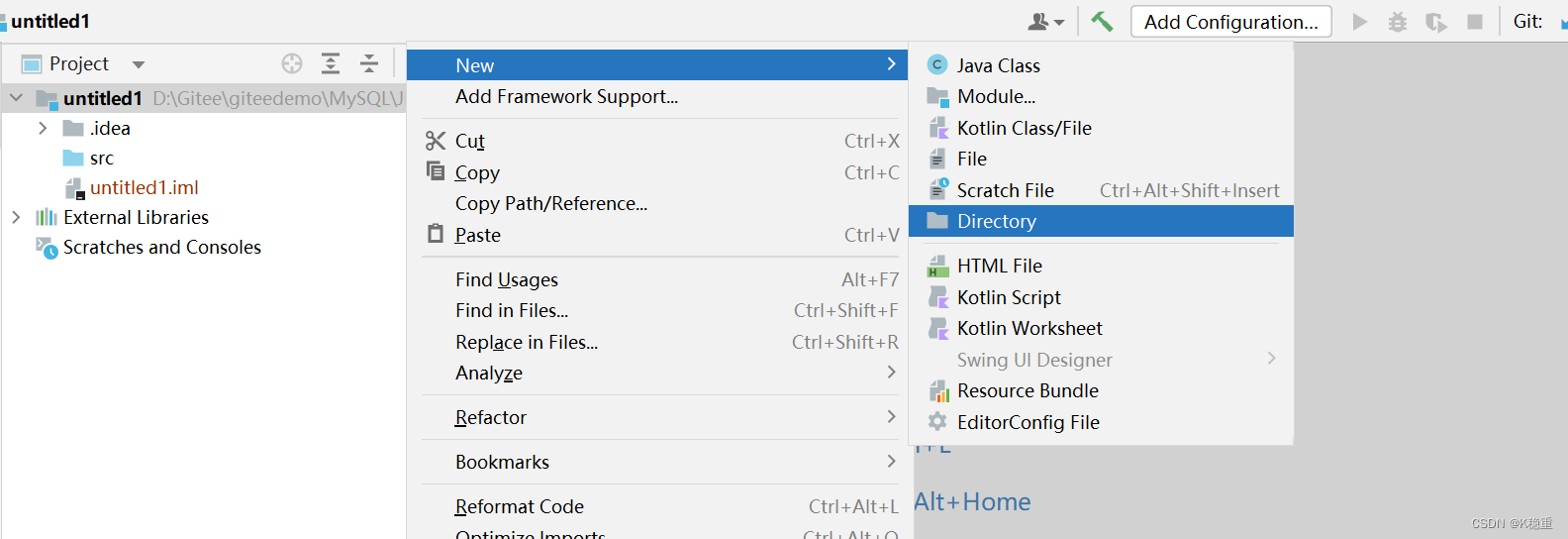
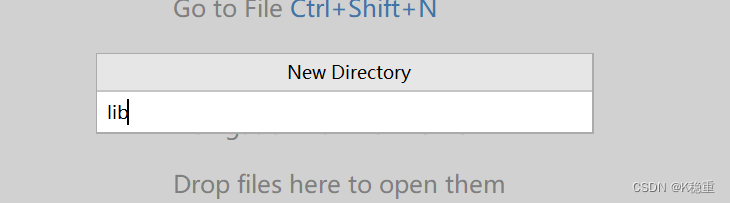
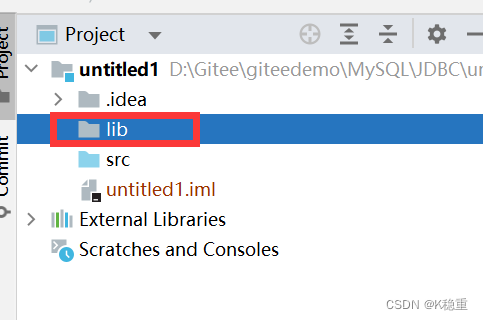
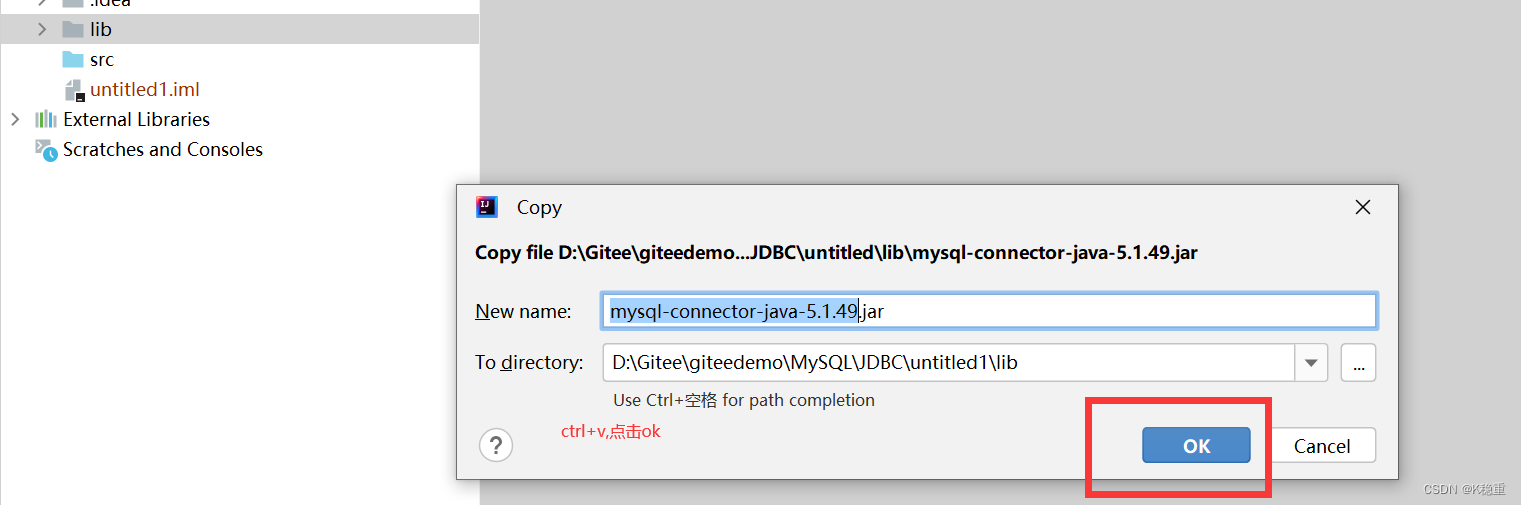
创建个目录,随便起个名字,例如叫做lib~
把刚才下载的jar文件拷贝到刚才的目录中去~
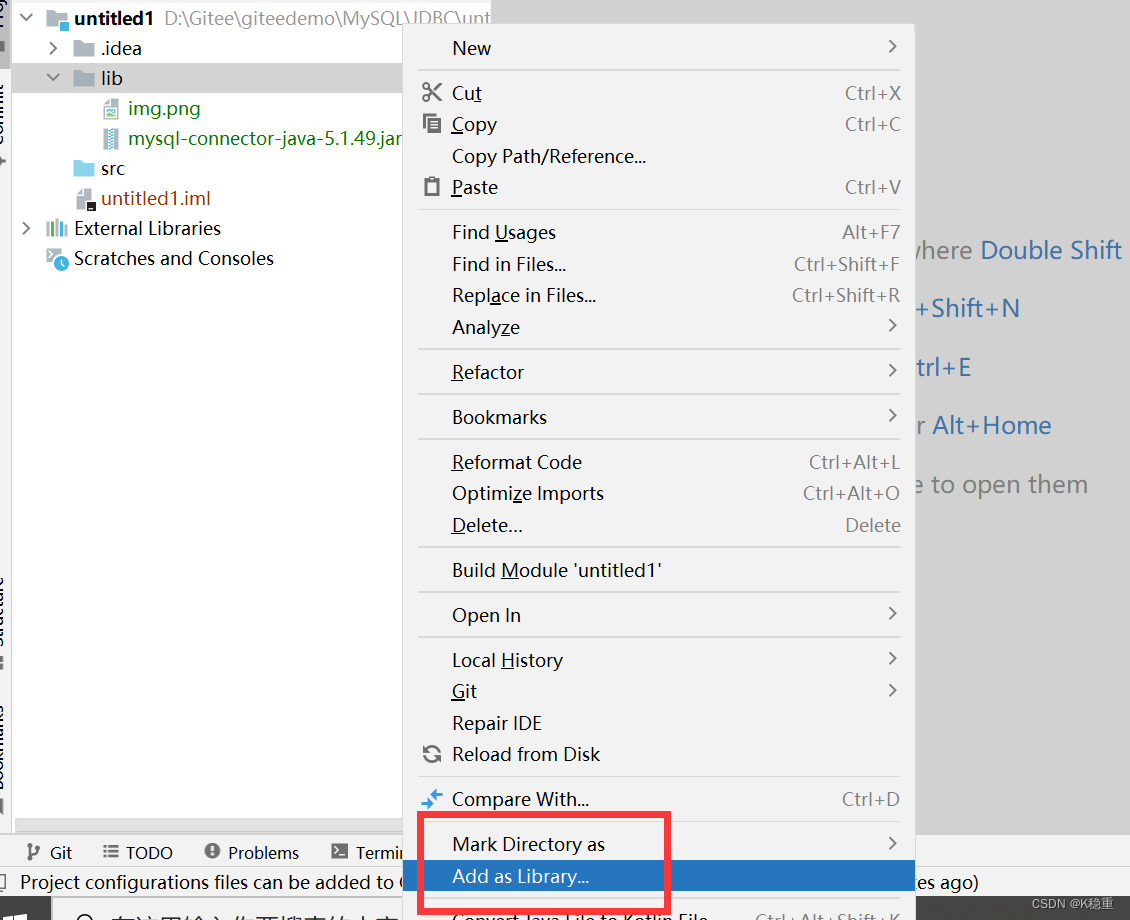
右键刚才的目录,有一个选项,叫做add as library,点击这个选项才能把这个jar引入到项目中.
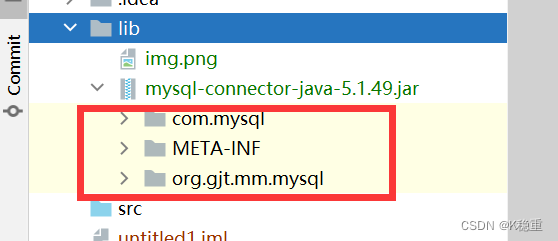
此时项目才会从jar里面读取内部的.class~否则,代码就找不到jar中的一些类了
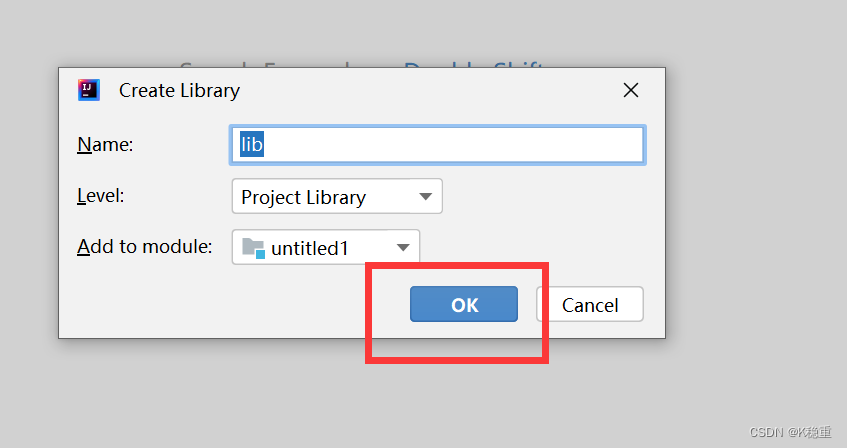
这样就成功了

编写代码~
下一章来如何编写代码~

版权归原作者 K稳重 所有, 如有侵权,请联系我们删除。