
文章目录
前言
#博学谷IT学习技术支持#
Hadoop包含HDFS分布式存储框架、MapReduce分布式计算框架和Yarn分布式资源调度框架,本篇文章主要介绍Hadoop三大框架中的MapReduce框架。
一、什么是分布式计算
分布式计算是一种计算方法,从字面理解就是将一个计算分布在多台计算机上面运行,与集中计算是相对的,通过分布式计算大大缩短计算时间,提高计算效率。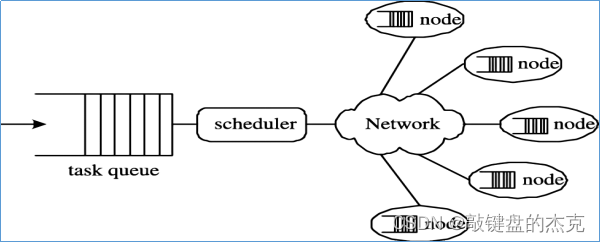
二、MapReduce简介
(一)介绍
MapReduce是一个软件框架,用于轻松编写应用程序,这些应用程序以可靠,容错的方式并行处理大型硬件集群上的大量数据,MapReduce主要处理海量数据,也是一种对大规模数据进行分布式计算的编程模型,其计算过程主要分为Map阶段、Shuffle阶段和Reduce阶段,即将先将数据按照一定规则进行拆分,接着讲数据打算重新排列,最终将计算出的结果进行合并。
(二)特点
MapReduce主要有以下四个特点:
(1)易于编程,Mapreduce框架提供了用于二次开发的接口,简单地实现一些接口,就可以完成一个分布式程序。
(2)良好的扩展性,当计算机资源不能得到满足的时候,可以通过增加机器来扩展它的计算能力。
(3)高容错性,Hadoop集群是分布式搭建和部署得,任何单一机器节点宕机了,它可以把上面的计算任务转移到另一个节点上运行,不影响整个作业任务得完成,过程完全是由Hadoop内部完成的。
(4)适合海量数据的离线处理,可以处理GB、TB和PB级别的数据量。
(三)局限性
虽然MapReduce有多个优势,但还是有一些两个不足点:
(1)实时计算性能差,MapReduce主要用于离线数据计算,无法实现实时的数据响应
(2)无法进行流式计算,流式计算指的是实时计算,而MapRedece只能进行离线计算,只要处理静态的数据,动态数据的无法实时计算。
三、MapReduce编程
(一)MapReduce架构体系
MapReduce程序在分布式运行包含三类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调
2、MapTask:负责map阶段的整个数据处理流程
3、ReduceTask:负责reduce阶段的整个数据处理流程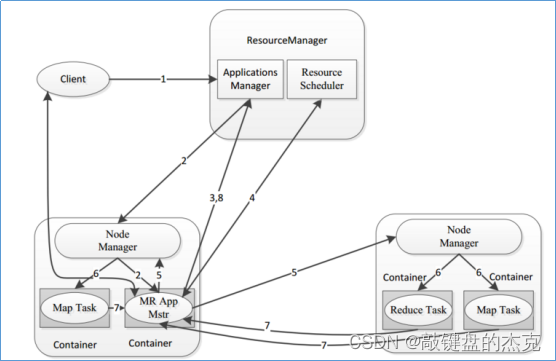
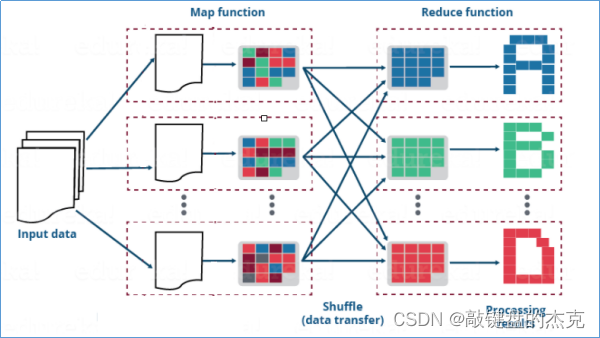
(二)MapReduce工作执行流程
整个MapReduce工作流程可以分为:Map阶段、Shuffle阶段和Reduce阶段
(1)Map阶段:负责把从数据源读取来到数据进行处理,读取数据返回的是kv键值对类型,经过自定义map方法处理之后,输出的也是kv键值对类型
(2)Shuffle阶段:map输出的数据会经过分区、排序、分组等自带动作进行重组,相当于洗牌的逆过程。这是MapReduce的核心所在,也是难点所在
(3)Reduce阶段:负责将经过Shuffle阶段的数据进行合并处理。
总结
MapReduce框架主要分为Map数据拆分阶段、Shuffle数据清晰阶段和Reduce数据合并阶段,该框架使用分布式计算的方式对数据进行拆分洗牌,最终合并数据,从而提高数据的处理效率。
版权归原作者 敲键盘的杰克 所有, 如有侵权,请联系我们删除。