
一、集群规划
本次测试采用3台虚拟机,操作系统版本为centos7.6。
Hadoop版本为3.3.4,其中Namenode采用HA高可用架构,开启kerberos和Ranger
操作系统用户:hadoop 操作系统用户组:hadoop
IP地址主机名ZKHIVE192.168.121.101node101.cc.localserver.1
HS2
HMS
192.168.121.102node102.cc.localserver.2
HS2
HMS
192.168.121.103node103.cc.localserver.3Mysql
Hive从0.14开始,使用Zookeeper实现了HiveServer2的HA功能(ZooKeeper Service Discovery),Client端可以通过指定一个nameSpace来连接HiveServer2,而不是指定某一个host和port。
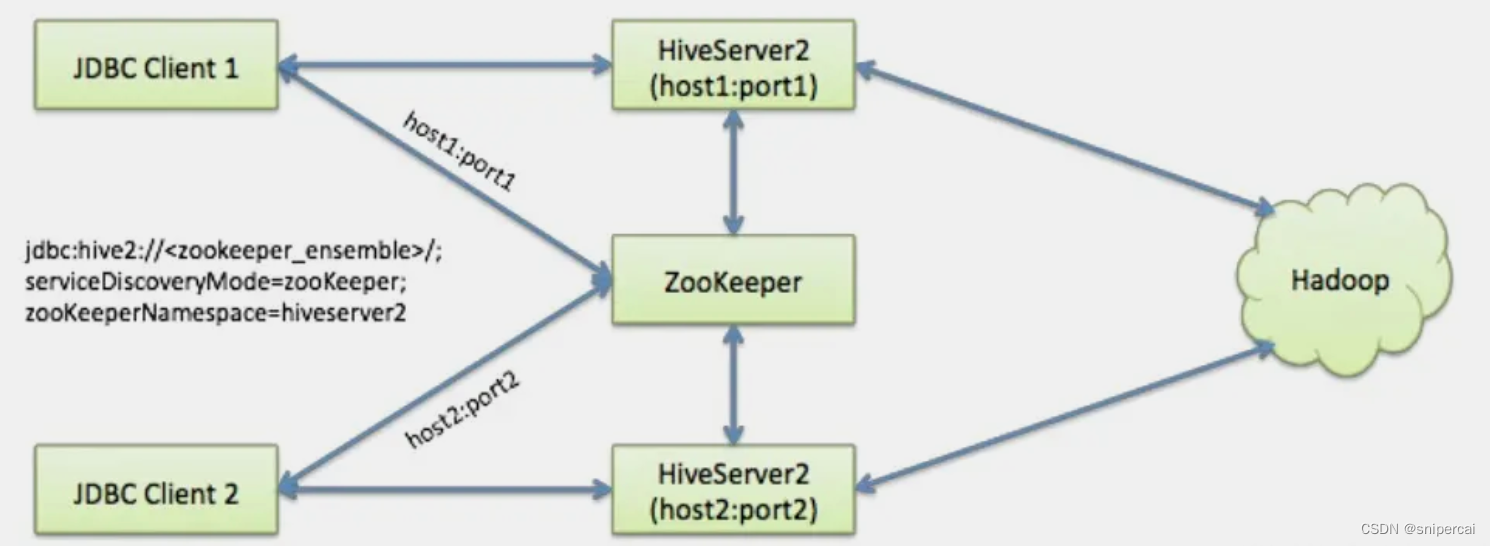
二、介质下载
官方下载地址:
Index of /hivehttps://dlcdn.apache.org/hive/
三、基础环境准备
1、解压文件
tar -xzvf apache-hive-3.1.3-bin.tar.gz
mv apache-hive-3.1.3-bin /opt/hadoop/hive-3.1.3
chown -R hadoop:hadoop /opt/hadoop/hive-3.1.3
2、配置环境变量
编辑文件 /etc/profile,新增hive的环境变量
export HIVE_HOME=/opt/hadoop/hive-3.1.3
export PATH=$HIVE_HOME/bin:$PATH
生效新配置
source /etc/profile
四、配置zookeeper
1、创建主体
注意:hiveserver2的高可用需要使用zookeeper,而HiveZooKeeperClient默认使用SASL进行认证,所以需要创建zookeeper主体。
#node101
kadmin -p kws/admin -w kws!101 -q"addprinc -randkey zookeeper/node101.cc.local"
kadmin -p kws/admin -wkws!101 -q"xst -k /etc/security/keytab/zk.keytab zookeeper/node101.cc.local"
#node102
kadmin -p kws/admin -w kws!101 -q"addprinc -randkey zookeeper/node102.cc.local"
kadmin -p kws/admin -wkws!101 -q"xst -k /etc/security/keytab/zk.keytab zookeeper/node102.cc.local"
#node103
kadmin -p kws/admin -w kws!101 -q"addprinc -randkey zookeeper/node103.cc.local"
kadmin -p kws/admin -wkws!101 -q"xst -k /etc/security/keytab/zk.keytab zookeeper/node103.cc.local"
2、修改zoo.cfg
配置conf/zoo.cfg,增加SASL配置
#zk SASL
authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
jaasLoginRenew=3600000
requireClientAuthScheme=sasl
zookeeper.sasl.client=true
kerberos.removeHostFromPrincipal=true
kerberos.removeRealmFromPrincipal=true
quorum.auth.enableSasl=true
quorum.auth.learner.saslLoginContext=Learner
quorum.auth.server.saslLoginContext=Server
quorum.auth.kerberos.servicePrincipal=zookeeper/_HOST@CC.LOCAL
4lw.commands.whitelist=mntr,conf,ruok,cons
3、新增jaas.conf
在conf目录下新增jaas.conf文件,注意主体zookeeper/XXX根据每个节点配置。
Server {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/etc/security/keytab/zk.keytab"
storeKey=true
useTicketCache=false
principal="zookeeper/node101.cc.local@CC.LOCAL";
};
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/etc/security/keytab/zk.keytab"
storeKey=true
useTicketCache=false
principal="zookeeper/node101.cc.local@CC.LOCAL";
};
Learner {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/etc/security/keytab/zk.keytab"
storeKey=true
useTicketCache=false
principal="zookeeper/node101.cc.local@CC.LOCAL";
};
注意:如果jaas.conf文件内容格式有误,ZK启动时会报在jaas文件中找不到Server段的错误
4、新增java.env
在conf目录下新增java.env文件
export JVMFLAGS="-Djava.security.auth.login.config=/opt/hadoop/apache-zookeeper-3.8.0-bin/conf/jaas.conf"
5、重启ZK
systemctl stop zookeeper
systemctl start zookeeper
6、验证ZK
登录zk
zkCli.sh -server node101.cc.local:2181,node102.cc.local:2181,node103.cc.local:2181
[zk: node101.cc.local:2181,node102.cc.local:2181,node103.cc.local:2181(CONNECTED) 0] ls /
[hadoop-ha, rmstore, yarn-leader-election, zookeeper]
五、配置元数据库
在Mysql中创建名为metastore数据库
mysql -uroot -p
Enter password:
mysql> create database metastore;
Query OK, 1 row affected (0.01 sec)
创建数据库用户hive并赋权
GRANT ALL PRIVILEGES ON . TO 'hive'@'%' identified by 'Hive!102';
GRANT ALL PRIVILEGES ON . TO 'hive'@'192.168.121.101' identified by 'Hive!102';
GRANT ALL PRIVILEGES ON . TO 'hive'@'192.168.121.102' identified by 'Hive!102';
GRANT ALL PRIVILEGES ON . TO 'hive'@'node101.cc.local' identified by 'Hive!102';
GRANT ALL PRIVILEGES ON . TO 'hive'@'node102.cc.local' identified by 'Hive!102';
拷贝MySQL的JDBC驱动拷贝到Hive的lib目录下
cp mysql-connector-java.jar $HIVE_HOME/lib
六、安装HIVE
1、创建Hiver的kerberso主体
hiveserver2和metastore服务都需要配置kerberos鉴权,因为hive可以配置服务所使用的kerberos主体,没有绑定固定主体名称,所以本次验证使用之前创建的hadoop主体,不再创建主体。
2、新增hive-site.xml
新增$HIVE_HOME/conf/hive-site.xml配置文件
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hive.server2.thrift.bind.host</name> <value>node102.cc.local</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://node102.cc.local:9083,thrift://node101.cc.local:9083</value> </property> <property> <name>hive.server2.support.dynamic.service.discovery</name> <value>true</value> </property> <property> <name>hive.server2.zookeeper.namespace</name> <value>hiveserver2_zk</value> </property> <property> <name>hive.zookeeper.quorum</name> <value>node101.cc.local:2181,node102.cc.local:2181,node103.cc.local:2181</value> </property> <property> <name>hive.zookeeper.client.port</name> <value>2181</value> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.121.103:3306/metastore?useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property><property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>Hive!102</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property><!-- jdbc连接的username--><property> <name>hive.server2.authentication</name> <value>kerberos</value> </property> <property> <name>hive.server2.authentication.kerberos.principal</name> <value>hadoop/[email protected]</value> </property> <property> <name>hive.server2.authentication.kerberos.keytab</name> <value>/etc/security/keytab/hadoop.keytab</value> </property> <property> <name>hive.metastore.sasl.enabled</name> <value>true</value> </property> <property> <name>hive.metastore.kerberos.principal</name> <value>hadoop/[email protected]</value> </property> <property> <name>hive.metastore.kerberos.keytab.file</name> <value>/etc/security/keytab/hadoop.keytab</value> </property> </configuration><!-- hiveserver2 支持kerberos认证 -->
3、初始化Hive元数据库
$ ./schematool -dbType mysql -initSchema -verbose
4、新增hive-default.xml
新增$HIVE_HOME/conf/hive-default.xml参数配置文件
cp hive-default.xml.template hive-default.xml
注意:默认配置文件:hive-default.xml,用户自定义配置文件:hive-site.xml,用户自定义配置会覆盖默认配置。
支持命令行参数方式
①启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。例如:
hive -hiveconf mapreduce.job.reduces=10;
注意:仅对本次Hive启动有效。
②查看参数设置
hive (default)> set mapreduce.job.reduces;
参数声明方式
①在HQL中使用SET关键字设定参数,例如:
hive(default)> set mapreduce.job.reduces=10;
注意:仅对本次Hive启动有效。
②查看参数设置:
hive(default)> set mapreduce.job.reduces;
注意:上述三种设定方式的优先级依次递增,即配置文件 < 命令行参数 < 参数声明。
5、新增hive-env.sh
新增$HIVE_HOME/conf/hive-env.sh环境配置文件
cp hive-env.sh.template hive-default.xml
6、新增hive-log4j2.properties
新增$HIVE_HOME/conf/hive-log4j2.properties日志配置文件
cp hive-log4j2.properties.template hive-log4j2.properties
修改hive日志路径,默认在/tmp
#property.hive.log.dir = ${sys:java.io.tmpdir}/${sys:user.name}
property.hive.log.dir = /opt/hadoop/hive-3.1.3/logs
注意:log4j属于系统级配置,必须用前参数或者参数设定方式。
7、启动Hive服务及验证
nohup hive --service metastore >> /opt/hadoop/hive-3.1.3/logs/metastore.log 2>&1 &
nohup hive --service hiveserver2 >> /opt/hadoop/hive-3.1.3/logs/hiveserver.log 2>&1 &
七、HIVE验证
1、检查zk注册情况
[zk: node101.cc.local:2181,node102.cc.local:2181,node103.cc.local:2181(CONNECTED) 2] ls /hiveserver2
[serverUri=node101.cc.local:10000;version=3.1.3;sequence=0000000003, serverUri=node102.cc.local:10000;version=3.1.3;sequence=0000000004]
2、使用beeline连接
$ kinit test -kt test.keytab
$ klist
Ticket cache: FILE:/tmp/krb5cc_1000
Default principal: test@CC.LOCALValid starting Expires Service principal
05/13/2024 16:18:33 05/14/2024 16:18:33 krbtgt/CC.LOCAL@CC.LOCAL
renew until 05/20/2024 16:18:33$ beeline -u "jdbc:hive2://node101.cc.local:2181,node102.cc.local:2181,node103.cc.local:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2"
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/hadoop/hive-3.1.3/lib/log4j-slf4j-impl-2.17.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/hadoop/hadoop-3.3.4/share/hadoop/common/lib/slf4j-reload4j-1.7.36.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Connecting to jdbc:hive2://node101.cc.local:2181,node102.cc.local:2181,node103.cc.local:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
24/05/13 16:18:55 [main]: INFO jdbc.HiveConnection: Connected to node102.cc.local:10000
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.3 by Apache Hive0: jdbc:hive2://node101.cc.local:2181,node102> show databases;
INFO : Compiling command(queryId=hadoop_20240513161906_820f0271-0309-4fd8-b636-3f01e9738de6): show databases
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hadoop_20240513161906_820f0271-0309-4fd8-b636-3f01e9738de6); Time taken: 1.819 seconds
INFO : Executing command(queryId=hadoop_20240513161906_820f0271-0309-4fd8-b636-3f01e9738de6): show databases
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hadoop_20240513161906_820f0271-0309-4fd8-b636-3f01e9738de6); Time taken: 0.145 seconds
INFO : OK
+----------------+
| database_name |
+----------------+
| default |
+----------------+
1 row selected (3.147 seconds)
八、安装hive-plugin
1、解压编译后的程序包
tar -zxvf ranger-2.4.0-hive-plugin.tar.gz
2、配置install.properties
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
Location of Policy Manager URL
Example:
POLICY_MGR_URL=http://policymanager.xasecure.net:6080
POLICY_MGR_URL=http://node103.cc.local:6080
This is the repository name created within policy manager
Example:
REPOSITORY_NAME=hivedev
REPOSITORY_NAME=hive_repo
Hive installation directory
Example:
COMPONENT_INSTALL_DIR_NAME=/var/local/apache-hive-2.1.0-bin
COMPONENT_INSTALL_DIR_NAME=/opt/hadoop/hive-3.1.3/
AUDIT configuration with V3 properties
Enable audit logs to Solr
#Example
#XAAUDIT.SOLR.ENABLE=true
#XAAUDIT.SOLR.URL=http://localhost:6083/solr/ranger_audits
#XAAUDIT.SOLR.ZOOKEEPER=
#XAAUDIT.SOLR.FILE_SPOOL_DIR=/var/log/hive/audit/solr/spoolXAAUDIT.SOLR.ENABLE=false
XAAUDIT.SOLR.URL=NONE
XAAUDIT.SOLR.USER=NONE
XAAUDIT.SOLR.PASSWORD=NONE
XAAUDIT.SOLR.ZOOKEEPER=NONE
XAAUDIT.SOLR.FILE_SPOOL_DIR=/var/log/hive/audit/solr/spoolEnable audit logs to ElasticSearch
#Example
#XAAUDIT.ELASTICSEARCH.ENABLE=true
#XAAUDIT.ELASTICSEARCH.URL=localhost
#XAAUDIT.ELASTICSEARCH.INDEX=auditXAAUDIT.ELASTICSEARCH.ENABLE=false
XAAUDIT.ELASTICSEARCH.URL=NONE
XAAUDIT.ELASTICSEARCH.USER=NONE
XAAUDIT.ELASTICSEARCH.PASSWORD=NONE
XAAUDIT.ELASTICSEARCH.INDEX=NONE
XAAUDIT.ELASTICSEARCH.PORT=NONE
XAAUDIT.ELASTICSEARCH.PROTOCOL=NONEEnable audit logs to HDFS
#Example
#XAAUDIT.HDFS.ENABLE=true
#XAAUDIT.HDFS.HDFS_DIR=hdfs://node-1.example.com:8020/ranger/auditIf using Azure Blob Storage
#XAAUDIT.HDFS.HDFS_DIR=wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>
#XAAUDIT.HDFS.HDFS_DIR=wasb://ranger_audit_container@my-azure-account.blob.core.windows.net/ranger/audit
#XAAUDIT.HDFS.FILE_SPOOL_DIR=/var/log/hive/audit/hdfs/spoolXAAUDIT.HDFS.ENABLE=false
XAAUDIT.HDFS.HDFS_DIR=hdfs://__REPLACE__NAME_NODE_HOST:8020/ranger/audit
XAAUDIT.HDFS.FILE_SPOOL_DIR=/var/log/hive/audit/hdfs/spoolFollowing additional propertis are needed When auditing to Azure Blob Storage via HDFS
Get these values from your /etc/hadoop/conf/core-site.xml
#XAAUDIT.HDFS.HDFS_DIR=wasb[s]://<containername>@<accountname>.blob.core.windows.net/<path>
XAAUDIT.HDFS.AZURE_ACCOUNTNAME=__REPLACE_AZURE_ACCOUNT_NAME
XAAUDIT.HDFS.AZURE_ACCOUNTKEY=__REPLACE_AZURE_ACCOUNT_KEY
XAAUDIT.HDFS.AZURE_SHELL_KEY_PROVIDER=__REPLACE_AZURE_SHELL_KEY_PROVIDER
XAAUDIT.HDFS.AZURE_ACCOUNTKEY_PROVIDER=__REPLACE_AZURE_ACCOUNT_KEY_PROVIDER#Log4j Audit Provider
XAAUDIT.LOG4J.ENABLE=false
XAAUDIT.LOG4J.IS_ASYNC=false
XAAUDIT.LOG4J.ASYNC.MAX.QUEUE.SIZE=10240
XAAUDIT.LOG4J.ASYNC.MAX.FLUSH.INTERVAL.MS=30000
XAAUDIT.LOG4J.DESTINATION.LOG4J=true
XAAUDIT.LOG4J.DESTINATION.LOG4J.LOGGER=xaauditEnable audit logs to Amazon CloudWatch Logs
#Example
#XAAUDIT.AMAZON_CLOUDWATCH.ENABLE=true
#XAAUDIT.AMAZON_CLOUDWATCH.LOG_GROUP=ranger_audits
#XAAUDIT.AMAZON_CLOUDWATCH.LOG_STREAM={instance_id}
#XAAUDIT.AMAZON_CLOUDWATCH.FILE_SPOOL_DIR=/var/log/hive/audit/amazon_cloudwatch/spoolXAAUDIT.AMAZON_CLOUDWATCH.ENABLE=false
XAAUDIT.AMAZON_CLOUDWATCH.LOG_GROUP=NONE
XAAUDIT.AMAZON_CLOUDWATCH.LOG_STREAM_PREFIX=NONE
XAAUDIT.AMAZON_CLOUDWATCH.FILE_SPOOL_DIR=NONE
XAAUDIT.AMAZON_CLOUDWATCH.REGION=NONEEnd of V3 properties
Audit to HDFS Configuration
If XAAUDIT.HDFS.IS_ENABLED is set to true, please replace tokens
that start with REPLACE with appropriate values
XAAUDIT.HDFS.IS_ENABLED=true
XAAUDIT.HDFS.DESTINATION_DIRECTORY=hdfs://__REPLACE__NAME_NODE_HOST:8020/ranger/audit/%app-type%/%time:yyyyMMdd%
XAAUDIT.HDFS.LOCAL_BUFFER_DIRECTORY=__REPLACE__LOG_DIR/hive/audit/%app-type%
XAAUDIT.HDFS.LOCAL_ARCHIVE_DIRECTORY=__REPLACE__LOG_DIR/hive/audit/archive/%app-type%
Example:
XAAUDIT.HDFS.IS_ENABLED=true
XAAUDIT.HDFS.DESTINATION_DIRECTORY=hdfs://namenode.example.com:8020/ranger/audit/%app-type%/%time:yyyyMMdd%
XAAUDIT.HDFS.LOCAL_BUFFER_DIRECTORY=/var/log/hive/audit/%app-type%
XAAUDIT.HDFS.LOCAL_ARCHIVE_DIRECTORY=/var/log/hive/audit/archive/%app-type%
XAAUDIT.HDFS.IS_ENABLED=false
XAAUDIT.HDFS.DESTINATION_DIRECTORY=hdfs://__REPLACE__NAME_NODE_HOST:8020/ranger/audit/%app-type%/%time:yyyyMMdd%
XAAUDIT.HDFS.LOCAL_BUFFER_DIRECTORY=__REPLACE__LOG_DIR/hive/audit/%app-type%
XAAUDIT.HDFS.LOCAL_ARCHIVE_DIRECTORY=__REPLACE__LOG_DIR/hive/audit/archive/%app-type%XAAUDIT.HDFS.DESTINTATION_FILE=%hostname%-audit.log
XAAUDIT.HDFS.DESTINTATION_FLUSH_INTERVAL_SECONDS=900
XAAUDIT.HDFS.DESTINTATION_ROLLOVER_INTERVAL_SECONDS=86400
XAAUDIT.HDFS.DESTINTATION_OPEN_RETRY_INTERVAL_SECONDS=60
XAAUDIT.HDFS.LOCAL_BUFFER_FILE=%time:yyyyMMdd-HHmm.ss%.log
XAAUDIT.HDFS.LOCAL_BUFFER_FLUSH_INTERVAL_SECONDS=60
XAAUDIT.HDFS.LOCAL_BUFFER_ROLLOVER_INTERVAL_SECONDS=600
XAAUDIT.HDFS.LOCAL_ARCHIVE_MAX_FILE_COUNT=10#Solr Audit Provider
XAAUDIT.SOLR.IS_ENABLED=false
XAAUDIT.SOLR.MAX_QUEUE_SIZE=1
XAAUDIT.SOLR.MAX_FLUSH_INTERVAL_MS=1000
XAAUDIT.SOLR.SOLR_URL=http://localhost:6083/solr/ranger_auditsEnd of V2 properties
SSL Client Certificate Information
Example:
SSL_KEYSTORE_FILE_PATH=/etc/hive/conf/ranger-plugin-keystore.jks
SSL_KEYSTORE_PASSWORD=none
SSL_TRUSTSTORE_FILE_PATH=/etc/hive/conf/ranger-plugin-truststore.jks
SSL_TRUSTSTORE_PASSWORD=none
You do not need use SSL between agent and security admin tool, please leave these sample value as it is.
SSL_KEYSTORE_FILE_PATH=/etc/hive/conf/ranger-plugin-keystore.jks
SSL_KEYSTORE_PASSWORD=myKeyFilePassword
SSL_TRUSTSTORE_FILE_PATH=/etc/hive/conf/ranger-plugin-truststore.jks
SSL_TRUSTSTORE_PASSWORD=changeitShould Hive GRANT/REVOKE update XA policies?
Example:
UPDATE_XAPOLICIES_ON_GRANT_REVOKE=true
UPDATE_XAPOLICIES_ON_GRANT_REVOKE=false
UPDATE_XAPOLICIES_ON_GRANT_REVOKE=true
Custom component user
CUSTOM_COMPONENT_USER=<custom-user>
keep blank if component user is default
CUSTOM_USER=hadoop
Custom component group
CUSTOM_COMPONENT_GROUP=<custom-group>
keep blank if component group is default
CUSTOM_GROUP=hadoop
3、页面配置
Service Name hive_repo
Display Name hive_repo
Description --
Active Status Enabled
Tag Service hive_tag
Config Properties :
Username hadoop //随便填
Password ***** //随便填
jdbc.driverClassName org.apache.hive.jdbc.HiveDriver
jdbc.url jdbc:hive2://node101.cc.local:2181,node102.cc.local:2181,node103.cc.local:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
Common Name for Certificate --
Add New Configurations :
tag.download.auth.users hadoop
policy.download.auth.users hadoop
注意:
1、填写好配置后,与HDFS和YARN不同,需要先保存。然后再点击编辑进入页面,再点击test来验证,不然会报错说rangerlookup没有操作权限。Caused by: org.apache.hive.service.cli.HiveSQLException: Error while compiling statement: FAILED: HiveAccessControlException Permission denied: user [rangerlookup] does not have [USE] privilege on [Unknown resource!!]
2、不管页面中用户怎么配置,ranger-admin都是使用rangerlookup用户去连接hive
九、策略配置
1、建库
已有测试用户test:test,并创建[email protected]的主体,并生成test.keytab文件。
注意:Hive建库会在HDFS的/user/hive/warehouse目录创建对于databasename.db目录。目前/user/hive/warehouse目录为<drwxr-xr-x - hadoop hadoop>,test用户没有该目录的写权限,如果允许test用户建库,则需要在ranger上为test用户配置/user/hive/warehouse目录的w权限
su - test
kinit -kt test.keytab test
beeline -u "jdbc:hive2://node101.cc.local:2181,node102.cc.local:2181,node103.cc.local:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2"
0: jdbc:hive2://node101.cc.local:2181,node102> select current_user();
INFO : Compiling command(queryId=hadoop_20240523171916_e2f9f27d-2650-42d4-b5fe-3d2bf4844869): select current_user()
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hadoop_20240523171916_e2f9f27d-2650-42d4-b5fe-3d2bf4844869); Time taken: 18.908 seconds
INFO : Executing command(queryId=hadoop_20240523171916_e2f9f27d-2650-42d4-b5fe-3d2bf4844869): select current_user()
INFO : Completed executing command(queryId=hadoop_20240523171916_e2f9f27d-2650-42d4-b5fe-3d2bf4844869); Time taken: 0.008 seconds
INFO : OK
+-------+
| _c0 |
+-------+
| test |
+-------+
1 row selected (20.42 seconds)
0: jdbc:hive2://node101.cc.local:2181,node102> show databases;
INFO : Compiling command(queryId=hadoop_20240523171424_db29902a-5df0-497b-b69c-e294648fdb82): show databases
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hadoop_20240523171424_db29902a-5df0-497b-b69c-e294648fdb82); Time taken: 0.032 seconds
INFO : Executing command(queryId=hadoop_20240523171424_db29902a-5df0-497b-b69c-e294648fdb82): show databases
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hadoop_20240523171424_db29902a-5df0-497b-b69c-e294648fdb82); Time taken: 0.334 seconds
INFO : OK
+----------------+
| database_name |
+----------------+
| default |
| hadoophive |
| testhive |
+----------------+
3 rows selected (0.533 seconds)
0: jdbc:hive2://node101.cc.local:2181,node102> create database if not exists testhivetmp;
INFO : Compiling command(queryId=hadoop_20240523171954_b88ede55-f197-4a14-bd79-fdeba2d74f6c): create database if not exists testhivetmp
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=hadoop_20240523171954_b88ede55-f197-4a14-bd79-fdeba2d74f6c); Time taken: 0.242 seconds
INFO : Executing command(queryId=hadoop_20240523171954_b88ede55-f197-4a14-bd79-fdeba2d74f6c): create database if not exists testhivetmp
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hadoop_20240523171954_b88ede55-f197-4a14-bd79-fdeba2d74f6c); Time taken: 4.935 seconds
INFO : OK
No rows affected (5.263 seconds)
0: jdbc:hive2://node101.cc.local:2181,node102> showdatabases;
Error: Error while compiling statement: FAILED: ParseException line 1:0 cannot recognize input near 'showdatabases' '<EOF>' '<EOF>' (state=42000,code=40000)
0: jdbc:hive2://node101.cc.local:2181,node102> show databases;
INFO : Compiling command(queryId=hadoop_20240523172013_392938e7-2e9e-4d10-8352-c33aed0aa8f7): show databases
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:database_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hadoop_20240523172013_392938e7-2e9e-4d10-8352-c33aed0aa8f7); Time taken: 0.081 seconds
INFO : Executing command(queryId=hadoop_20240523172013_392938e7-2e9e-4d10-8352-c33aed0aa8f7): show databases
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hadoop_20240523172013_392938e7-2e9e-4d10-8352-c33aed0aa8f7); Time taken: 0.547 seconds
INFO : OK
+----------------+
| database_name |
+----------------+
| default |
| hadoophive |
| testhive |
| testhivetmp |
+----------------+
4 rows selected (1.222 seconds)
2、建表
0: jdbc:hive2://node101.cc.local:2181,node102> use testhivetmp;
INFO : Compiling command(queryId=hadoop_20240523173510_10a22758-39aa-4b15-9b8d-c9291f85ae41): use testhivetmp
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=hadoop_20240523173510_10a22758-39aa-4b15-9b8d-c9291f85ae41); Time taken: 0.378 seconds
INFO : Executing command(queryId=hadoop_20240523173510_10a22758-39aa-4b15-9b8d-c9291f85ae41): use testhivetmp
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hadoop_20240523173510_10a22758-39aa-4b15-9b8d-c9291f85ae41); Time taken: 0.19 seconds
INFO : OK
No rows affected (0.621 seconds)
0: jdbc:hive2://node101.cc.local:2181,node102> show tables;
INFO : Compiling command(queryId=hadoop_20240523173521_e141106b-df8a-410c-90bd-5af756a86fa8): show tables
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hadoop_20240523173521_e141106b-df8a-410c-90bd-5af756a86fa8); Time taken: 0.192 seconds
INFO : Executing command(queryId=hadoop_20240523173521_e141106b-df8a-410c-90bd-5af756a86fa8): show tables
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hadoop_20240523173521_e141106b-df8a-410c-90bd-5af756a86fa8); Time taken: 0.152 seconds
INFO : OK
+-----------+
| tab_name |
+-----------+
+-----------+
No rows selected (0.516 seconds)
0: jdbc:hive2://node101.cc.local:2181,node102> create table stutmp(id int, name string);
INFO : Compiling command(queryId=hadoop_20240523173627_fbce607a-d41f-4c80-ab21-f8b25c2f630e): create table stutmp(id int, name string)
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:null, properties:null)
INFO : Completed compiling command(queryId=hadoop_20240523173627_fbce607a-d41f-4c80-ab21-f8b25c2f630e); Time taken: 0.282 seconds
INFO : Executing command(queryId=hadoop_20240523173627_fbce607a-d41f-4c80-ab21-f8b25c2f630e): create table stutmp(id int, name string)
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hadoop_20240523173627_fbce607a-d41f-4c80-ab21-f8b25c2f630e); Time taken: 3.185 seconds
INFO : OK
No rows affected (3.561 seconds)
0: jdbc:hive2://node101.cc.local:2181,node102> show tables;
INFO : Compiling command(queryId=hadoop_20240523173634_fc2276ca-2af2-482a-874f-e30b06b8a80f): show tables
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hadoop_20240523173634_fc2276ca-2af2-482a-874f-e30b06b8a80f); Time taken: 0.242 seconds
INFO : Executing command(queryId=hadoop_20240523173634_fc2276ca-2af2-482a-874f-e30b06b8a80f): show tables
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hadoop_20240523173634_fc2276ca-2af2-482a-874f-e30b06b8a80f); Time taken: 0.331 seconds
INFO : OK
+-----------+
| tab_name |
+-----------+
| stutmp |
+-----------+
1 row selected (0.829 seconds)
3、插入数据
注意:Hive在操作数据时会通过mapreduce的方式执行操作,操作时在HDFS上的/tmp/hadoop-yarn/staging/user目录下写入,但目前/tmp/hadoop-yarn目录为<drwxrwx--- - hadoop hadoop>,/tmp/hadoop-yarn/staging目录为<drwxrwx--- - hadoop hadoop>,test用户无法访问操作这两层目录,所以需要在ranger上为test用户配置/tmp/hadoop-yarn和/tmp/hadoop-yarn/staging目录的rwx权限
0: jdbc:hive2://node101.cc.local:2181,node102> insert into stutmp values(1,"sstmp");
INFO : Compiling command(queryId=hadoop_20240523174330_52af1f7d-8ca3-41dc-b935-fa5b90677210): insert into stutmp values(1,"sstmp")
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:col1, type:int, comment:null), FieldSchema(name:col2, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hadoop_20240523174330_52af1f7d-8ca3-41dc-b935-fa5b90677210); Time taken: 4.544 seconds
INFO : Executing command(queryId=hadoop_20240523174330_52af1f7d-8ca3-41dc-b935-fa5b90677210): insert into stutmp values(1,"sstmp")
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = hadoop_20240523174330_52af1f7d-8ca3-41dc-b935-fa5b90677210
INFO : Total jobs = 3
INFO : Launching Job 1 out of 3
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1716428726877_0004
INFO : Executing with tokens: [Kind: HDFS_DELEGATION_TOKEN, Service: ha-hdfs:ccns, Ident: (token for test: HDFS_DELEGATION_TOKEN owner=test, renewer=hadoop, realUser=hadoop/node102.cc.local@CC.LOCAL, issueDate=1716457418882, maxDate=1717062218882, sequenceNumber=9, masterKeyId=357), Kind: HIVE_DELEGATION_TOKEN, Service: HiveServer2ImpersonationToken, Ident: 00 04 74 65 73 74 04 74 65 73 74 20 68 61 64 6f 6f 70 2f 6e 6f 64 65 31 30 32 2e 63 63 2e 6c 6f 63 61 6c 40 43 43 2e 4c 4f 43 41 4c 8a 01 8f a4 bf 3a 4e 8a 01 8f c8 cb be 4e 01 01]
INFO : The url to track the job: http://node101.cc.local:8088/proxy/application_1716428726877_0004/
INFO : Starting Job = job_1716428726877_0004, Tracking URL = http://node101.cc.local:8088/proxy/application_1716428726877_0004/
INFO : Kill Command = /opt/hadoop/hadoop-3.3.4/bin/mapred job -kill job_1716428726877_0004
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
INFO : 2024-05-23 17:44:34,802 Stage-1 map = 0%, reduce = 0%
INFO : 2024-05-23 17:45:14,175 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.13 sec
INFO : 2024-05-23 17:45:40,414 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 7.86 sec
INFO : MapReduce Total cumulative CPU time: 7 seconds 860 msec
INFO : Ended Job = job_1716428726877_0004
INFO : Starting task [Stage-7:CONDITIONAL] in serial mode
INFO : Stage-4 is selected by condition resolver.
INFO : Stage-3 is filtered out by condition resolver.
INFO : Stage-5 is filtered out by condition resolver.
INFO : Starting task [Stage-4:MOVE] in serial mode
INFO : Moving data to directory hdfs://ccns/user/hive/warehouse/testhivetmp.db/stutmp/.hive-staging_hive_2024-05-23_17-43-30_901_2166959576750558632-1/-ext-10000 from hdfs://ccns/user/hive/warehouse/testhivetmp.db/stutmp/.hive-staging_hive_2024-05-23_17-43-30_901_2166959576750558632-1/-ext-10002
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table testhivetmp.stutmp from hdfs://ccns/user/hive/warehouse/testhivetmp.db/stutmp/.hive-staging_hive_2024-05-23_17-43-30_901_2166959576750558632-1/-ext-10000
INFO : Starting task [Stage-2:STATS] in serial mode
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 7.86 sec HDFS Read: 15232 HDFS Write: 245 SUCCESS
INFO : Total MapReduce CPU Time Spent: 7 seconds 860 msec
INFO : Completed executing command(queryId=hadoop_20240523174330_52af1f7d-8ca3-41dc-b935-fa5b90677210); Time taken: 134.102 seconds
INFO : OK
No rows affected (138.997 seconds)
0: jdbc:hive2://node101.cc.local:2181,node102> select * from stutmp;
INFO : Compiling command(queryId=hadoop_20240523175530_ace53296-91f5-4199-8d40-55a6197f3b7b): select * from stutmp
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:stutmp.id, type:int, comment:null), FieldSchema(name:stutmp.name, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hadoop_20240523175530_ace53296-91f5-4199-8d40-55a6197f3b7b); Time taken: 3.206 seconds
INFO : Executing command(queryId=hadoop_20240523175530_ace53296-91f5-4199-8d40-55a6197f3b7b): select * from stutmp
INFO : Completed executing command(queryId=hadoop_20240523175530_ace53296-91f5-4199-8d40-55a6197f3b7b); Time taken: 0.001 seconds
INFO : OK
+------------+--------------+
| stutmp.id | stutmp.name |
+------------+--------------+
| 1 | sstmp |
+------------+--------------+
1 row selected (3.624 seconds)
版权归原作者 snipercai 所有, 如有侵权,请联系我们删除。