
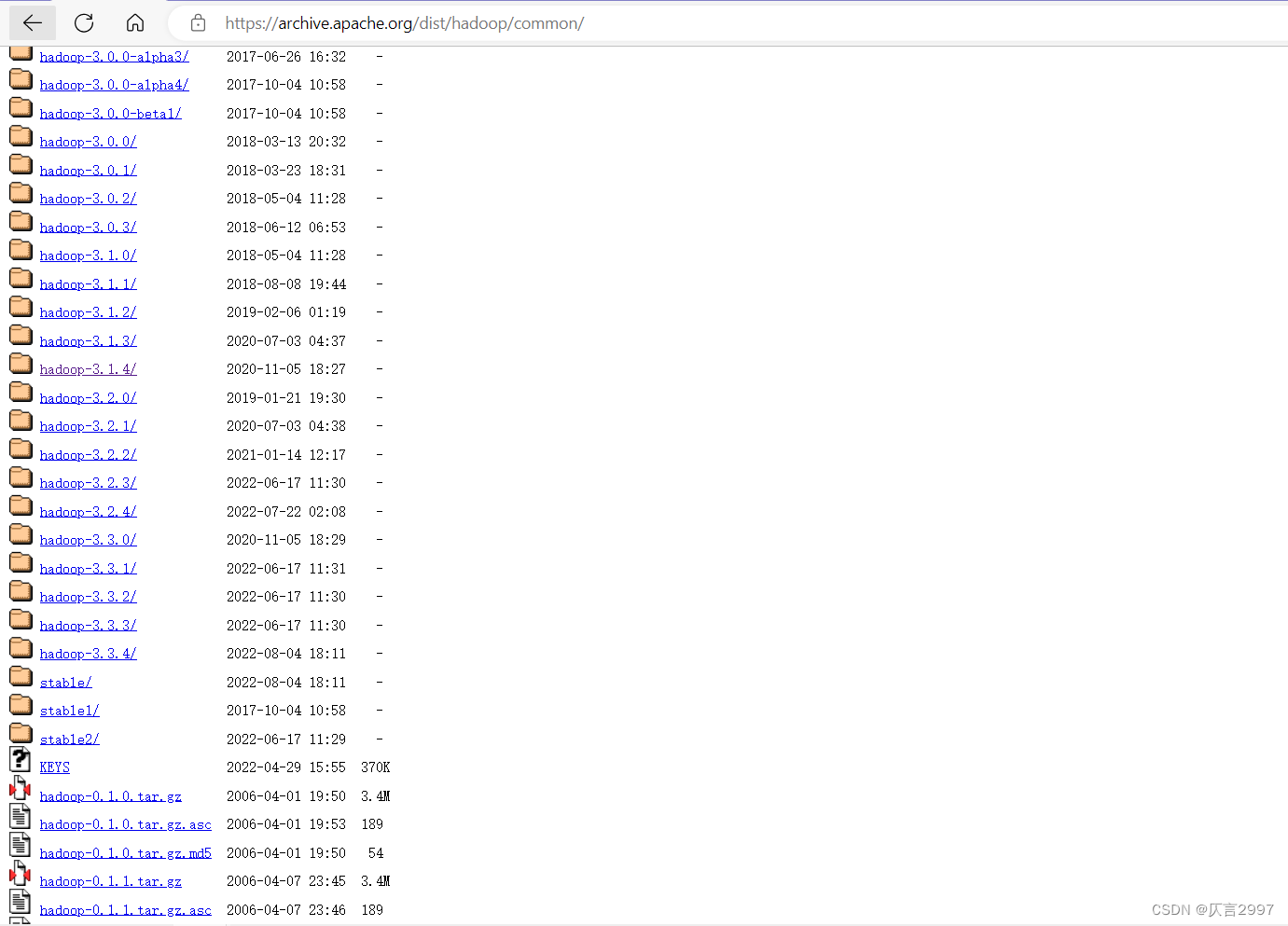
这里我们将完成虚拟机Hadoop的安装,我们需要选修改一个主机名方便以后查看,还需要下载好Hadoop文件,链接:Index of /dist/hadoop/common (apache.org)
选择你需要的Hadoop版本下载,我这里下载的是Hadoop-3.1.4/
修改一下主机名 命令:vi /etc/sysconfig/network

或者:vi /etc/hostname


重启虚拟机:reboot
重启虚拟机,主机名修改成功!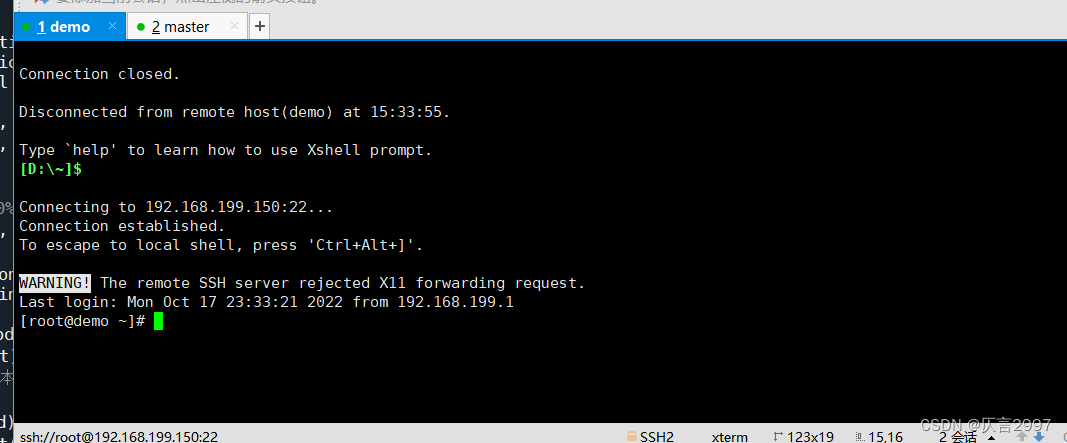
开始安装Hadoop!
(1)上传Hadoop 文件并解压,和上一个jdk的安装一样在xftp里面双击Hadoop文件。

上传成功!


解压 命令:tar -zxf hadoop-3.1.4.tar.gz -C /opt
 可删除安装包以节省磁盘空间。
可删除安装包以节省磁盘空间。
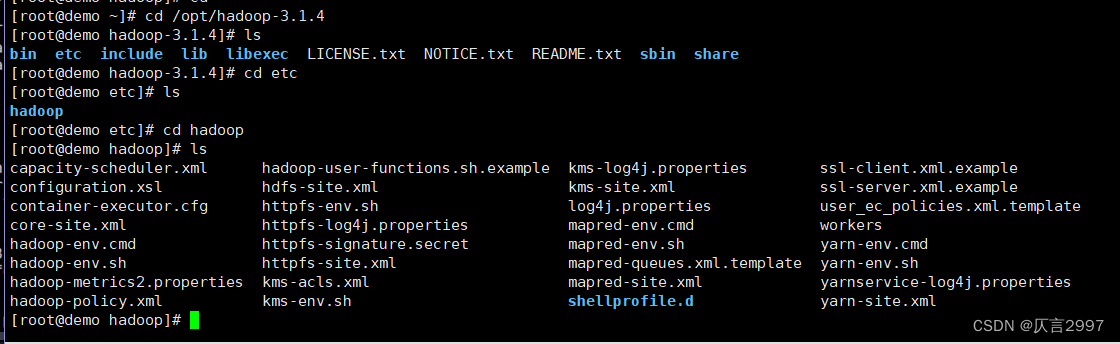
(2)修改配置文件 /opt/hadoop-3.1.4/etc/hadoop
先找到文件路径
######hadoop-env.sh
添加JAVA_HOME环境变量:
export JAVA_HOME=/usr/java/jdk1.8.0_341-amd64
(可以通过 echo $JAVA_HOME 获取路径)

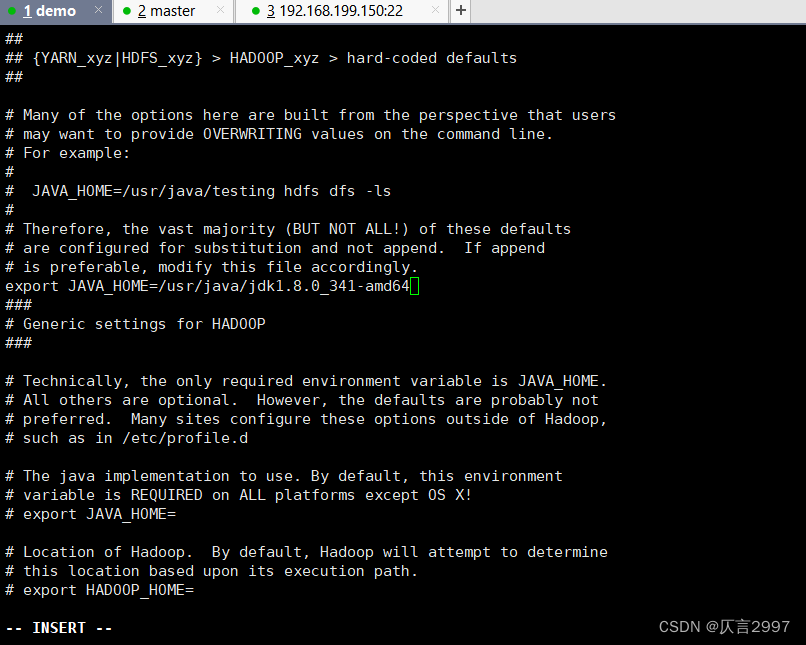
!!!在配置一下文件时注意修改自己的主机名字!!!!!
命令:vi hadoop-env.sh
vi core-site.xml
vi hdfs-site.xml
vi mapred-site.xml
vi yarn-site.xml
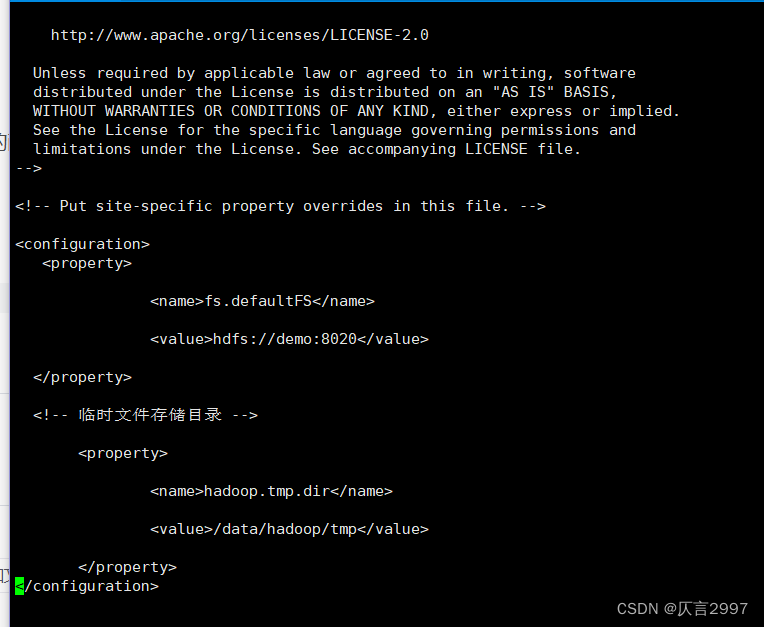
######core-site.xml
<configuration> <property> <name>fs.defaultFS</name>
<value>hdfs://demo:8020</value>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
 ######hdfs-site.xml
######hdfs-site.xml
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/datanode</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 是否启用hdfs权限检查 false 关闭-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>demo:50070</value>
</property>
 ######mapred-site.xml
######mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.1.4</value>
</property>
<name>mapreduce.application.classpath</name>
<value>/opt/Hadoop-3.1.4/share/Hadoop/mapreduce/:/opt/Hadoop-3.1.4/share/Hadoop/mapreduce/lib/</value>
</property>

######yarn-site.xml
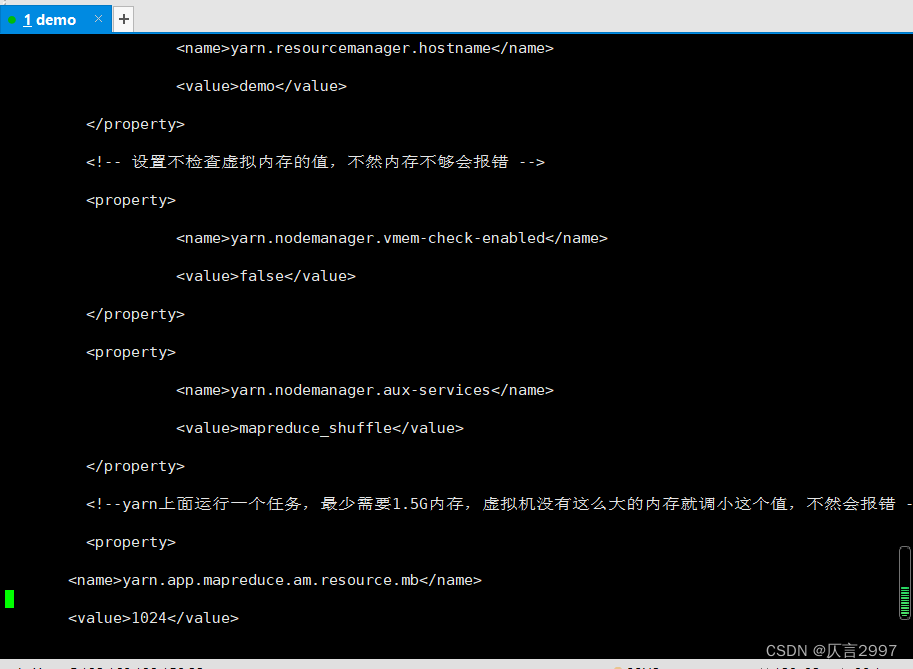
<configuration> <property>
<name>yarn.resourcemanager.hostname</name>
<value>demo</value>
</property>
<!-- 设置不检查虚拟内存的值,不然内存不够会报错 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--yarn上面运行一个任务,最少需要1.5G内存,虚拟机没有这么大的内存就调小这个值,不然会报错 -->
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>1024</value>
</property>
以上就是Hadoop的安装,下一篇文章:Hadoop集群的配置(4条消息) Hadoop集群的配置_仄言2997的博客-CSDN博客_集群配置hadoop
版权归原作者 仄言2997 所有, 如有侵权,请联系我们删除。