
一、什么是DataX?
DataX是阿里云商用产品DataWorks数据集成的开源版本,它是一个异构数据源的离线数据同步工具/平台(ETL工具)。DataX实现了包括Mysql,Oracle、OceanBase、Sqlserver,Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS等各种异构数据源之间高效的数据同步功能。
Tips:异构即不同类型的应用或者数据源,例如Mysql/Oracle/DB2/MongDB等不同类型的数据源;
Tips:离线数据同步常用Sqoop以及DataX工具。
Tips:ETL(Extract-Transform-Load)工具描述将从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据,其常用在数据仓库,但其对象并不限于数据仓库(DW)。
Github仓库:https://github.com/alibaba/Datax
Gitee国内仓库:https://gitee.com/mirrors/DataX
二.DataX的设计思想
描述:为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。简单的说DataX就像中间商一样为每一个服务对象进行需求供应。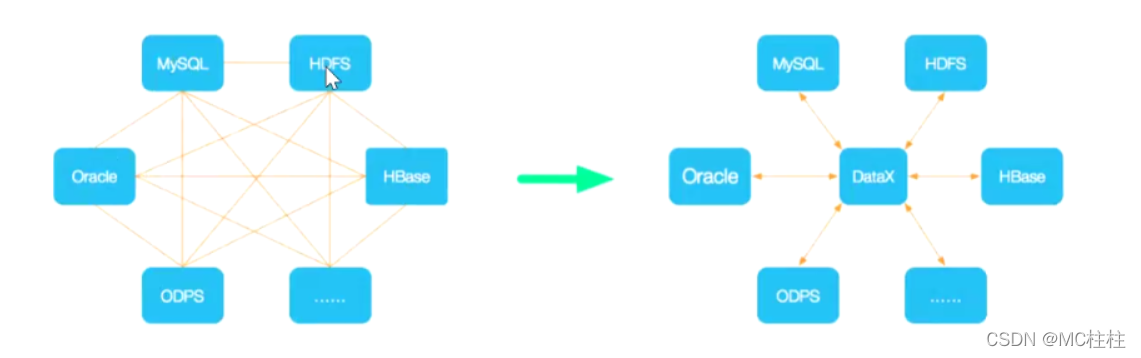
三.DataX的框架设计
描述:DataX本身作为离线数据同步框架,离线(批量)的数据通道通过定义数据源和去向的数据源和数据集,提供一套抽象化的数据抽取插件(Reader)、数据写入插件(Writer),并基于此框架设计一套简化版的中间数据传输格式,从而实现任意结构化、半结构化数据源之间数据传输。
DataX架构设计流程类似source(数据来源)->channel(数据存储池中转通道)->sink
Reader:数据采集模块,负责采集数据源的数据,将数据发送给FrameWork.
Writer:数据写入模块,负责不断向FrameWork取数据,并将数据写入到目的端。
FrameWork:用于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题。
Reader、Writer与Transformer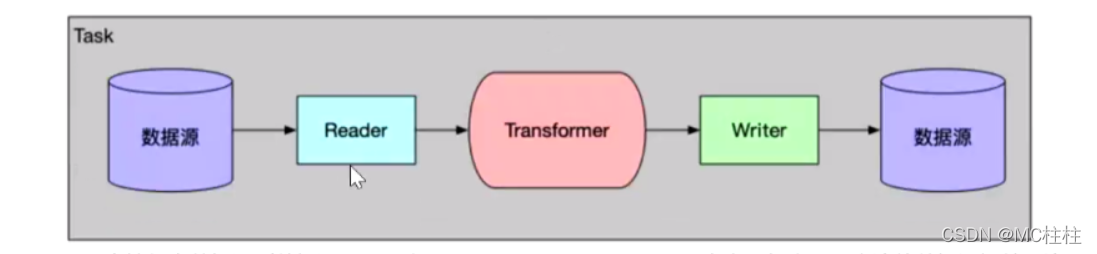
DataX可支持任意数据源到数据源,只要实现了Reader/Writer Plugin,官方已经实现了主流的数据源插件,比如Mysql,Oracle,Sqlserver等
例如:Mysql的数据离线同步到HDFS之中来展示DataX的框架设计结构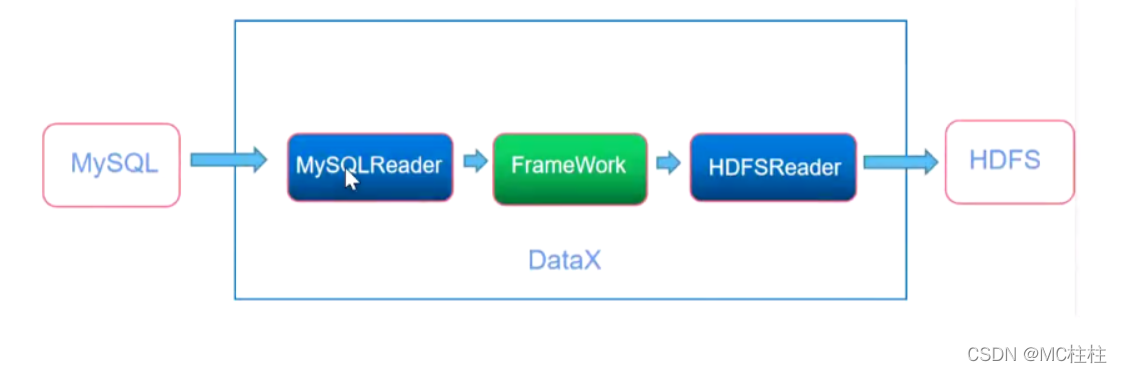
四.DataX调度流程
1.任务切分
计算并发量
并发量,及所需通道数量(needChannelNumber)。
按表数量
配置了每个通道处理1张表,那么同时处理100张表,就需要100个通道;
按记录数
配置了每个通道处理1000条记录,那么同时处理100000条记录数,就需要10个通道
任务切分
将多个job切分成多个Task:根据所需通道数量将job切分成多个Task
五.安装部署方式
直接下载DataX工具包:Datax下载地址
下载后解压至本地某个目录,进入bin目录,即可运行同步作业:
[root@vagary software]# wget http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
可以看一下datax的目录组成
$ # tree -d -L 2
├── bin # 可执行的Python脚本
├── conf # Datax 配置文件
├── job # 离线同步任务
├── lib # 依赖库
├── log # 任务执行过程日志
├── log_perf
├── plugin # 各类数据库读写插件
│ ├── reader
│ └── writer
├── script # 脚本存放
└── tmp # 临时目录
运行一个实例,检验是否成功安装
[vagary@vagary job]$ datax.py job.json
出现这个界面就成功了
2022-04-24 18:13:16.329 [job-0] INFO JobContainer - PerfTrace not enable!2022-04-24 18:13:16.329 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.027s | All Task WaitReaderTime 0.041s | Percentage 100.00%
2022-04-24 18:13:16.330 [job-0] INFO JobContainer -
任务启动时刻 :2022-04-24 18:13:06
任务结束时刻 :2022-04-24 18:13:16
任务总计耗时 : 10s
任务平均流量 :253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 :100000
读写失败总数 :0
六.DataX任务开发
1.生成导入脚本:
datax.py -r mysqlreader -w hdfswriter
2.生成MySQL -> HFDS 脚本:
{"job":{"content":[{"reader":{"name":"mysqlreader", --name:reader名
"parameter":{"column":[], -- 字段名
"connection":[{"jdbcUrl":[], --对数据库的JDBC连接信息
"table":[] --表名
【"querySql":[]】 -- 支持sql语句,配置它 --后,mysqlreader直接忽略 --table、column、where
}],
"password":"", --密码
"username":"", --用户名
"where":"" --筛选条件
【"splitPk":""】 --数据分片字段,一般是主键, --仅支持整型
}},
"writer":{"name":"hdfswriter", --name:writer名
"parameter":{"column":[], --column:写入数据的字段,其 --中name指定字段名,type指定类型
"compress":"", --hdfs文件压缩类型,默认未空
"defaultFS":"", --namenode节点地址
"fieldDelimiter":"", --分隔符
"fileName":"", --写入文件名
"fileType":"", --文件的类型,目前只支持用户配 --置为"text"或"orc""path":"", --hdfs文件系统的路径信息
"writeMode":""
-- hdfswriter写入前数据清理处理模式:
--(1)append:写入前不做任何处理,hdfswriter直接使用filename写入,会重复数据
--(2)nonConflict:如果目录下有fileName前缀的文件,直接报错。
}}}],
"setting":{"speed":{"channel":"" --并发数限速(根据自己CPU合理控制并发数)
-- channle=2,使用streamwriter打印的时候会打印两遍内容。
-- 但是如果是别的writer,比如hdfswriter,mysqlwriter,它只是 -- 启动两个并发任务,内容只有一次,不会重复两遍。
}}}}
3.编写配置文件(字段模式)
{"job":{"content":[{"reader":{"name":"mysqlreader","parameter":{"column":["bus_id","bus_name","telephone","pic_url","bus_user_name","province","city","dist","addr","zipcode","is_open","open_time","closed_time"],"connection":[{"jdbcUrl":["jdbc:mysql://hadoop04:3306/prod"],"table":["business_info"]}],"password":"shumeng_123","username":"shumeng","where":"1=1"}},"writer":{"name":"hdfswriter","parameter":{"column":[{"name":"bus_id","type":"string"},{"name":"bus_name","type":"string"},{"name":"telephone","type":"string"},{"name":"pic_url","type":"string"},{"name":"bus_user_name","type":"string"},{"name":"province","type":"string"},{"name":"city","type":"string"},{"name":"dist","type":"string"},{"name":"addr","type":"string"},{"name":"zipcode","type":"string"},{"name":"is_open","type":"string"},{"name":"open_time","type":"string"},{"name":"closed_time","type":"string"}],"compress":"snappy","defaultFS":"hdfs://hadoop04:8020","fieldDelimiter":",","fileName":"ods_business_info_full.txt","fileType":"orc","path":"/user/hive/warehouse/ods.db/ods_business_info_full/pt=2022-01-01","writeMode":"append"}}}],"setting":{"speed":{"channel":"1"}}}}
4.编写配置文件(SQL模式)
{"job":{"content":[{"reader":{"name":"mysqlreader","parameter":{"connection":[{"jdbcUrl":["jdbc:mysql://hadoop04:3306/prod"],"querySql":["select bus_id,bus_name,telephone,pic_url,bus_user_name,province,city,dist,addr,zipcode,is_open,open_time,close_time from prod.business_info "]}],"password":"shumeng_123","username":"shumeng","where":"1=1"}},"writer":{"name":"hdfswriter","parameter":{"column":[{"name":"bus_id","type":"string"},{"name":"bus_name","type":"string"},{"name":"telephone","type":"string"},{"name":"pic_url","type":"string"},{"name":"bus_user_name","type":"string"},{"name":"province","type":"string"},{"name":"city","type":"string"},{"name":"dist","type":"string"},{"name":"addr","type":"string"},{"name":"zipcode","type":"string"},{"name":"is_open","type":"string"},{"name":"open_time","type":"string"},{"name":"closed_time","type":"string"}],"compress":"snappy","defaultFS":"hdfs://hadoop04:8020","fieldDelimiter":",","fileName":"ods_business_info_full_sql.txt","fileType":"orc","path":"/user/hive/warehouse/ods.db/ods_business_info_full/pt=2022-01-01","writeMode":"append"}}}],"setting":{"speed":{"channel":"1"}}}}
PS:DataX的HDFS writer会将null值存储为空字符串’’ ,Hive默认null格式为\N。
alter table ods_business_info_full set serdeproperties('serialization.null.format'='');
版权归原作者 MC柱柱 所有, 如有侵权,请联系我们删除。