
需求
需求非常简单。把下面这个数据源:
{"productId": "a101", "status": 101}
{"productId": "a102", "status": 101}
{"productId": "a103", "status": 101}
{"productId": "a101", "status": 101}
Sink到mySQL的这样的一个表里product_tbl:
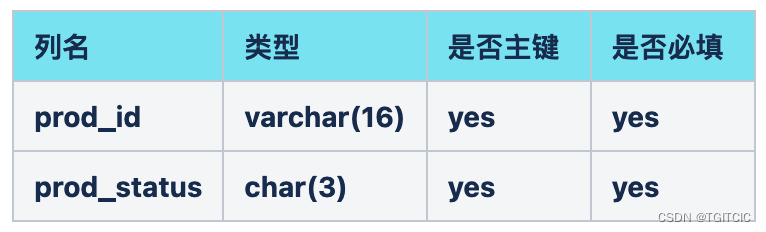
第一种姿势:暴力插入式
什么都不管,来一条sink一条,使用的是自定义Sink端extends RichSinkFunction<ProductBean>。然后在Sink端写PreparedStatement。下面上代码。
pom.xml
为了在flink里使用mysql,我们这边使用的是flink的最新版本1.15.2,因此在flink的1.15.2里访问mysql必须含有以下这两样内容
<properties>
<mysql-connector-java.version>5.1.46</mysql-connector-java.version>
<flink.version>1.15.2</flink.version>
</properties>
<!--mysql 加在dependencies里的类库-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql-connector-java.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>${flink.version}</version>
</dependency>
config.properties
#redis config
redis.host=192.168.0.106:27001,192.168.0.106:27002,192.168.0.106:27003
#redis.host=localhost:27001,localhost:27002,localhost:27003
redis.sentinel.master=master1
#redis.host=localhost:7003
redis.password=111111
jedis.pool.min-idle=5
jedis.pool.max-active=25
jedis.pool.max-idle=5
jedis.pool.max-wait=-1
jedis.pool.minEvictableIdleTimeMillis=10000
jedis.pool.timeBetweenEvictionRunsMillis=8000
jedis.pool.numTestsPerEvictionRun=-1;
connection.timeout=10000
jedis.pool.testOnBorrow=true;
jedis.pool.testWhileIdle=true
redis.selected.database=0
#kafka config
#kafka.host=192.168.0.102
kafka.host=127.0.0.1
kafka.port=9092
kafka.bootstrapservers=192.168.0.102:9092
#kafka.bootstrapservers=127.0.0.1:9092
kafka.topic=test
#mysql config
mysql.url=jdbc:mysql://192.168.0.106:3306/ecom?useUnicode=true&characterEncoding=utf-8&useSSL=false&useAffectedRows=true&autoReconnect=true
mysql.driver.name=com.mysql.jdbc.Driver
mysql.username=root
mysql.password=111111
自定义的mySQL的Sink-SimpleMySQLSink.java
package org.mk.demo.flink;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.configuration.Configuration;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
public class SimpleMySQLSink extends RichSinkFunction<ProductBean> {
private final static Logger logger = LoggerFactory.getLogger(SimpleMySQLSink.class);
private Connection connection = null;
private PreparedStatement prepareStatement = null;
@Override
public void open(Configuration config) throws Exception {
Configuration globConf = null;
ParameterTool paras = (ParameterTool) getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
connection = DriverManager.getConnection(paras.get("mysql.url"), paras.get("mysql.username"),
paras.get("mysql.password"));
String sql = "insert into product_tbl values(?, ?)";
prepareStatement = connection.prepareStatement(sql);
}
@Override
public void invoke(ProductBean value, Context context) throws Exception {
prepareStatement.setString(1, value.getProductId());
prepareStatement.setString(2, String.valueOf(value.getStatus()));
prepareStatement.execute();
}
@Override
public void close() throws Exception {
if (prepareStatement != null) {
prepareStatement.close();
}
if (connection != null) {
connection.close();
}
}
}
主程序-SimpleSinkToMySQL.java
package org.mk.demo.flink;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.mk.demo.flink.CountByOrderTypeAggregateWindow.ProductBeanJSONDeSerializer;
import org.mk.demo.flink.util.ParamConfig;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.alibaba.fastjson.JSON;
public class SimpleSinkToMySQL {
private final static Logger logger = LoggerFactory.getLogger(SimpleSinkToMySQL.class);
public static class ProductBeanJSONDeSerializer implements KafkaDeserializationSchema<ProductBean> {
private final String encoding = "UTF8";
@Override
public TypeInformation<ProductBean> getProducedType() {
return TypeInformation.of(ProductBean.class);
}
@Override
public boolean isEndOfStream(ProductBean nextElement) {
return false;
}
@Override
public ProductBean deserialize(ConsumerRecord<byte[], byte[]> consumerRecord) throws Exception {
if (consumerRecord != null) {
try {
String value = new String(consumerRecord.value(), encoding);
ProductBean product = JSON.parseObject(value, ProductBean.class);
return product;
} catch (Exception e) {
logger.error(">>>>>>deserialize failed : " + e.getMessage(), e);
}
}
return null;
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ParameterTool argParas = ParameterTool.fromArgs(args);
String propertiesFilePath = argParas.get("config_path");
if (logger.isDebugEnabled()) {
logger.debug(">>>>>>start to load properties from {}", propertiesFilePath);
}
ParameterTool paras = ParameterTool.fromPropertiesFile(propertiesFilePath);
env.getConfig().setGlobalJobParameters(paras);
KafkaSource<ProductBean> source = KafkaSource.<ProductBean>builder()
.setBootstrapServers(paras.get("kafka.bootstrapservers")).setTopics(paras.get("kafka.topic"))
.setGroupId("test01").setStartingOffsets(OffsetsInitializer.latest())
.setDeserializer(KafkaRecordDeserializationSchema.of(new ProductBeanJSONDeSerializer()))
.build();
DataStream<ProductBean> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
kafkaDS.addSink(new SimpleMySQLSink());
env.execute();
}
}
第二种姿势:生产应用常用的batch insert模式
在这个模式下我们要考虑以下几个因素
- 我们经常面临自以为只是往DB插入一条数据,不会引起什么不可测的因素。实际是上千、上万次一个循环,直接把生产的DB搞挂了。因此我们需要充分利用batchInsert模式;
- 每次插X百条,然后sleep(80-100毫秒)以便于CPU、内存、磁盘、以及mySQL在发生数据变更时需要做主从同步(生产都是X主X从模式)所需要的那个“喘吸时间”;
- 如果主键重复怎么办;
此时从代码上反面简单了。
config.properties和pom.xml文件不变动情况,我们也不用自定义Sink端,直接可以使用flink1.15.2的JdbcSink.sink来完成这件事。
主程序-BatchSinkToMySQL.java
package org.mk.demo.flink;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.connector.jdbc.JdbcConnectionOptions;
import org.apache.flink.connector.jdbc.JdbcExecutionOptions;
import org.apache.flink.connector.jdbc.JdbcSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.alibaba.fastjson.JSON;
public class BatchSinkToMySQL {
private final static Logger logger = LoggerFactory.getLogger(BatchSinkToMySQL.class);
public static class ProductBeanJSONDeSerializer implements KafkaDeserializationSchema<ProductBean> {
private final String encoding = "UTF8";
@Override
public TypeInformation<ProductBean> getProducedType() {
return TypeInformation.of(ProductBean.class);
}
@Override
public boolean isEndOfStream(ProductBean nextElement) {
return false;
}
@Override
public ProductBean deserialize(ConsumerRecord<byte[], byte[]> consumerRecord) throws Exception {
if (consumerRecord != null) {
try {
String value = new String(consumerRecord.value(), encoding);
ProductBean product = JSON.parseObject(value, ProductBean.class);
return product;
} catch (Exception e) {
logger.error(">>>>>>deserialize failed : " + e.getMessage(), e);
}
}
return null;
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
ParameterTool argParas = ParameterTool.fromArgs(args);
String propertiesFilePath = argParas.get("config_path");
if (logger.isDebugEnabled()) {
logger.debug(">>>>>>start to load properties from {}", propertiesFilePath);
}
ParameterTool paras = ParameterTool.fromPropertiesFile(propertiesFilePath);
env.getConfig().setGlobalJobParameters(paras);
KafkaSource<ProductBean> source = KafkaSource.<ProductBean>builder()
.setBootstrapServers(paras.get("kafka.bootstrapservers")).setTopics(paras.get("kafka.topic"))
.setGroupId("test01").setStartingOffsets(OffsetsInitializer.latest())
.setDeserializer(KafkaRecordDeserializationSchema.of(new ProductBeanJSONDeSerializer())).build();
DataStream<ProductBean> kafkaDS = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
kafkaDS.print();
kafkaDS.addSink(
JdbcSink.sink(
"insert into product_tbl (prod_id,prod_status) values (?, ?) on duplicate key update prod_id=?,prod_status=?",
(statement, product) -> {
statement.setString(1, product.getProductId());
statement.setString(2, String.valueOf(product.getStatus()));
statement.setString(3, product.getProductId());
statement.setString(4, String.valueOf(product.getStatus()));
},
JdbcExecutionOptions.builder().withBatchSize(100).withBatchIntervalMs(200).withMaxRetries(3)
.build(),
new JdbcConnectionOptions.JdbcConnectionOptionsBuilder().withUrl(paras.get("mysql.url"))
.withDriverName(paras.get("mysql.driver.name"))
.withUsername(paras.get("mysql.username")).withPassword(paras.get("mysql.password"))
.build()));
env.execute();
}
}
核心代码解释
- 使用JdbcExecutionOptions.builder().withBatchSize(100).withBatchIntervalMs(200).withMaxRetries(3)实现了“积满100条一次性batchInsert“,”每次批量insert后休息200毫秒“,”重试3次“。具体生产应用这几个值可以根据实际再调查;
- 书写insert时使用了on duplicate key update,但是这不是一个好的best practice。因为在实时计算里我们讲究的是“以大化小、各个击破、分而治之”,因此我们如果在业务上确认了有:过来的数据会可能存在duplicate key时我的建议时建一张表,这个表有一个无意义的自增长ID的主键(也可以使用分布式序列化生成器),然后把流水落盘后再做“小聚合”,或者在流批时直接做去重。要知道为什么要有实时计算,就是因为它是处理小数据的如:一个时间窗口就1万来条数据,1万来条数据在内存里这么去重一下比你1亿条历史数据记录里做去重,你自己比一下谁的效率高?因此才要以大化小、各个击破、分而治之;
本文转载自: https://blog.csdn.net/lifetragedy/article/details/127571462
版权归原作者 TGITCIC 所有, 如有侵权,请联系我们删除。
版权归原作者 TGITCIC 所有, 如有侵权,请联系我们删除。