
一、实验内容
1.借助词法分析工具Flex或Lex完成(参考网络资源)
2.输入:高级语言源代码(如helloworld.c)
3.输出:以二元组表示的单词符号序列。
二、实验目的
通过设计、编制、调试一个具体的词法分析程序,加深对词法分析原理的理解,并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
三、实验分析
由于各种不同的高级程序语言中单词总体结构大致相同,基本上都可用一组正则表达式描述,所以构造这样的自动生成系统:只要给出某高级语言各类单词词法结构的一组正则表达式以及识别各类单词时词法分析程序应采取的语义动作,该系统便可自动产生此高级程序语言的词法分析程序。Lex就是一个词法分析程序的自动生成工具。一个Lex源程序经过Lex编译系统可生成词法分析程序L。
一个Lex源程序具有如下形式:
声明部分
%%
转换规则
%%
辅助函数
在声明部分中,定义变量与常量。也可以声明正则表达式。
而Lex的每个转换规则具有如下形式:
模式 {动作}
其中,模式是正则表达式,可以使用声明部分中给出的正则定义。动作是代码片段,利用c语言编写。
Lex源程序存储在.l文件中,利用win_flex可以将其生成输出lex.yy.c文件。lex.yy.c文件可以被c语言编译器编译并运行。
为了识别一个真实的c语言源程序,需要用到如下辅助定义:
letter->a-zA-Z
digit->0-9
这两个辅助定义用于识别单个字母字符与单个数字字符。
在本实验中,需要识别的c语言程序保留字如下:while、if、else、switch、case、int、main、using、namespace、std、printf。可用一个正则表达式进行识别:
(while)|(if)|(else)|(switch)|(case)|(int)|(main)|(using)|(namespace)|(std)|(printf)
c语言的标识符id规则如下:由字母、数字、下划线组成,且第一个字符只能为字母或下划线。则标识符的正则表达式为:
({letter}|_)({letter}|{digit}|_)*
整数的正则表达式如下:
(‘+’|’-’)?{digit}*
其中,问号表示’+’号或’-’号要么不出现,要么出现了有且只有一次。这一正则表达式可以接受正数与负数。
浮点数的正则表达式如下:
{digit}+.{digit}+((E|e)(‘+’|’-’)?{digit}+)?
在小数点之前至少有一位数字,在小数点之后也至少有一位数字。在数字后可以附带这个数需要乘10的多少次幂,也可以不附带。
c语言中的运算符除了加减乘除、比较、赋值外,还有流输入输出。正则表达式如下:
\+|-|\*|<=|<|==|=|>=|>|>>|<<
。因为正则表达式本身有加号与乘号,所以在加号与乘号前追加反斜杠进行转义。
识别空格、tab、换行符、回车符(\r)的正则表达式为: \t\n\r,记为delim。为了识别多个空白,可用正则表达式
{delim}+
识别字符串的正则表达式为:
”[^”]*”
,即在两个双引号内可以有任意个除双引号字符以外的字符。为了转义,在c语言程序中需写作:
\"[^"]*\"
识别c语言程序开头包含的头文件时,需要先识别#号,再识别出除换行符以外的任何字符。正则表达式语句如下:
"#".*
在lex程序中,在读取完成需要进行词法分析的源代码文件后,调用yylex()即可自动开始进行词法分析,词法分析得到的词法单元属性值暂存在全局变量yylval中,而识别得到的单词字符串存放在变量yytext中。
在运行过程中,每将输入的文件匹配到一个正则表达式,就自动执行其动作。在本实验中,被执行的动作为以二元组形式表示当前单词。即为:(单词种别,单词自身的值)。这一过程反复进行,并会在识别到非法字符时报错。直到读取到文件结束时,这一过程结束。
四、实验流程
在下载完成win_flex的压缩包后,对该文件夹解压可以看到win_flex.exe的文件。这一exe文件不能直接运行。需要首先配置环境变量,将这一文件所在的路径添加到系统变量的Path内。在cmd窗口,对Lex源程序的.l文件执行
win_flex --nounistd lex.l
,就能生成出lex.yy.c。添加参数–nounistd的目的是生成出能在windows环境下编译运行的lex.yy.c而不是只能在linux/unix环境下执行的lex.yy.c。
在编写完.l文件后,执行win_flex,生成lex.yy.c。在visual studio等编译器中可以编译运行这个文件,将待分析的另一个c语言源程序进行词法分析并输出到控制塔上。
因此,实验的整体操作流程如下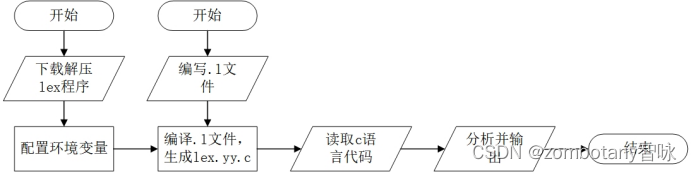
五、实验代码
5.1 代码说明
在%{ 与%}之间是插入c语言程序,include相关库并定义全局变量为计数器记录当前在分析第几个单词。
%{#include<stdio.h>#include<stdlib.h>int count =0;%}
正则表达式的声明部分,与第三章分析的各个单词类型对应的正则表达式是一致的。
digit [0-9]
letter [a-zA-Z]
reservedWord [w][h][i][l][e]|[i][f]|[e][l][s][e]|[s][w][i][t][c][h]|[c][a][s][e]|[i][n][t]|[m][a][i][n]|[u][s][i][n][g]|[n][a][m][e][s][p][a][c][e]|[s][t][d]|[p][r][i][n][t][f]id({letter}|_)({letter}|{digit}|_)*
num {digit}+
operator \+|-|\*|<=|<|==|=|>=|>|>>|<<
delim [ \t\n\r]
whitespace {delim}+
semicolon [\;]
str \"[^"]*\"
other .%%
辅助函数部分,针对每个正则表达式都执行对应动作:计数器加一,分析当前单词的单词种别与单词自身的值。
%%{reservedWord}{count++;printf("%d\t(reserved word,\'%s\')\n",count,yytext);}{id}{count++;printf("%d\t(id,\'%s\')\n",count,yytext);}{num}{count++;printf("%d\t(num,\'%s\')\n",count,yytext);}{operator}{count++;printf("%d\t(op,\'%s\')\n",count,yytext);}{whitespace}{/* do nothing*/}{str}{count++;printf("%d\t(string,\'%s\')\n",count,yytext);}"("{count++;printf("%d\t(left bracket,\'%s\')\n",count,yytext);}")"{count++;printf("%d\t(right bracket,\'%s\')\n",count,yytext);}"{"{count++;printf("%d\t(left bracket,\'%s\')\n",count,yytext);}"}"{count++;printf("%d\t(right bracket,\'%s\')\n",count,yytext);}":"{count++;printf("%d\t(colon,\'%s\')\n",count,yytext);}";"{count++;printf("%d\t(semicolon,\'%s\')\n",count,yytext);}"#".*{count++;printf("%d\t(head,\'%s\')\n",count,yytext);}{other}{printf("illegal character:\'%s\'\n",yytext);}%%
main函数的作用就是读取文件到yyin,并调用yylex()自动地对yyin的文件进行词法分析。
intmain(){
yyin=fopen("F:/HOMEWORK/Compiler/Lab2/test.c","r");yylex();return0;}intyywrap(){return1;}
5.2 完整代码
%{#include<stdio.h>#include<stdlib.h>int count =0;%}
digit [0-9]
letter [a-zA-Z]
reservedWord [w][h][i][l][e]|[i][f]|[e][l][s][e]|[s][w][i][t][c][h]|[c][a][s][e]|[i][n][t]|[m][a][i][n]|[u][s][i][n][g]|[n][a][m][e][s][p][a][c][e]|[s][t][d]|[p][r][i][n][t][f]id({letter}|_)({letter}|{digit}|_)*
num {digit}+
operator \+|-|\*|<=|<|==|=|>=|>|>>|<<
delim [ \t\n\r]
whitespace {delim}+
semicolon [\;]
str \"[^"]*\"
other .%%{reservedWord}{count++;printf("%d\t(reserved word,\'%s\')\n",count,yytext);}{id}{count++;printf("%d\t(id,\'%s\')\n",count,yytext);}{num}{count++;printf("%d\t(num,\'%s\')\n",count,yytext);}{operator}{count++;printf("%d\t(op,\'%s\')\n",count,yytext);}{whitespace}{/* do nothing*/}{str}{count++;printf("%d\t(string,\'%s\')\n",count,yytext);}"("{count++;printf("%d\t(left bracket,\'%s\')\n",count,yytext);}")"{count++;printf("%d\t(right bracket,\'%s\')\n",count,yytext);}"{"{count++;printf("%d\t(left bracket,\'%s\')\n",count,yytext);}"}"{count++;printf("%d\t(right bracket,\'%s\')\n",count,yytext);}":"{count++;printf("%d\t(colon,\'%s\')\n",count,yytext);}";"{count++;printf("%d\t(semicolon,\'%s\')\n",count,yytext);}"#".*{count++;printf("%d\t(head,\'%s\')\n",count,yytext);}{other}{printf("illegal character:\'%s\'\n",yytext);}%%intmain(){
yyin=fopen("F:/HOMEWORK/Compiler/Lab2/test.c","r");yylex();return0;}intyywrap(){return1;}
六、运行结果

编译运行.l文件,加入参数nounistd,生成了可在Windows 10 环境下可以运行的lex.yy.c,如图3所示。

如图4,编写用于测试词法分析器的真实c语言代码。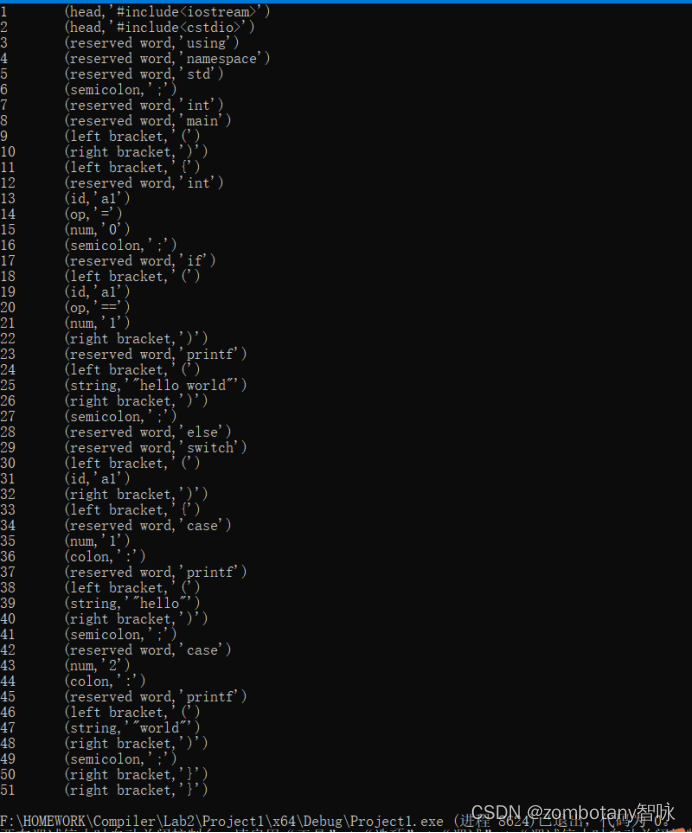
对lex.yy.c代码进行编译运行,并将结果输出在控制台上,如图5。该词法分析器能自动忽略空格、换行符、tab,按照顺序逐一将每个单词进行编号,并生成二元组(单词种别,单词自身的值)。
图5词法分析结果与图4的测试文件一一对应。
头文件首先被识别出来。识别语句
using namespace std
,并识别语句的分号。
识别
int main
,并识别紧随其后的左右小括号与大括号。
源代码“
int a1=0;
”被识别如下:保留字int,标识符a1,赋值号=,数字0。并识别分号。
源代码“
if(a1==1);
”被识别如下:保留字if、左括号、标识符a1、比较相等的符号==、数字1、右括号、分号。
源代码“
printf(“hello world”)
”被识别为:保留字printf、左括号、字符串”hello world”、右括号。需要说明的是,”hello world”字符串是一个单词,没有因为中间有空格而被识别为两个单词。
else、switch等单词均为保留字。识别标识符a1、括号的过程都是同理的。
源代码“
case 1:printf(“hello”);
”被识别为:保留字case、数字1、保留字printf、左括号、字符串”hello”、右括号、分号。源代码“
case 2:printf(“world”);
”同理。
最后识别两个右大括号。读取到文件结束符后,程序结束。
七、实验感悟
版权归原作者 zombo_tany 所有, 如有侵权,请联系我们删除。