
Join:
1、小表join大表
将key相对分散,并且数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率,再进一步可以使用group 让小的维表(1000条以下的记录条数)先进内存,在map端完成reduce。
selectcount(distinct s_id)from score;selectcount(s_id)from score groupby s_id;--在map端进行聚合,效率更高
2、多个表关联
多个表关联时,最好拆分成小段,避免大sql(无法控制中间Job)
3、大表Join大表
3.1、空key过滤
有时join超时是因为某些key对应的数据太多,而相同key对应的数据都会发送到相同的reducer上,从而导致内存不够。此时我们应该仔细分析这些异常的key,很多情况下,这些key对应的数据是异常数据,我们需要在SQL语句中进行过滤。例如key对应的字段为空,操作如下:
不过滤:
INSERT OVERWRITE TABLE jointable
SELECT a.*FROM nullidtable a JOIN ori b ON a.id = b.id;
结果:
Norows affected (152.135 seconds)-----------------------------------------------
过滤:
INSERT OVERWRITE TABLE jointable
SELECT a.*FROM(SELECT*FROM nullidtable WHERE id ISNOTNULL) a JOIN ori b ON a.id = b.id;
结果:
Norows affected (141.585 seconds)
3.2、空key转换
有时虽然某个key为空对应的数据很多,但是相应的数据不是异常数据,必须要包含在join的结果中,此时我们可以表a中key为空的字段赋一个随机的值,使得数据随机均匀地分不到不同的reducer上。例如:
3.2.1、不随机分布:
set hive.exec.reducers.bytes.per.reducer=32123456;set mapreduce.job.reduces=7;INSERT OVERWRITE TABLE jointable
SELECT a.*FROM nullidtable a
LEFTJOIN ori b ONCASEWHEN
a.id ISNULLTHEN'hive'ELSE a.id
END= b.id;--No rows affected (52.477 seconds)
结果:这样的后果就是所有为null值的id全部都变成了相同的字符串“hive”,及其容易造成数据的倾斜(所有的key相同,相同key的数据会到同一个reduce当中去) 为了解决这种情况,我们可以通过hive的rand函数,随记的给每一个为空的id赋上一个随机值,这样就不会造成数据倾斜
3.2.2、随机分布:
set hive.exec.reducers.bytes.per.reducer=32123456;set mapreduce.job.reduces=7;INSERT OVERWRITE TABLE jointable
SELECT a.*FROM nullidtable a
LEFTJOIN ori b ONCASEWHEN
id ISNULLTHEN concat('hive', rand())ELSE a.id
END= b.id;--No rows affected (42.594 seconds)
实际操作:
操作示例:测试大表JOIN小表和小表JOIN大表的效率 (新的版本当中已经没有区别了,旧的版本当中需要使用小表)
1、关闭mapjoin功能(默认是打开的)
set hive.auto.convert.join=false;
2、执行小表JOIN大表语句
INSERT OVERWRITE TABLE jointable2
SELECT b.id, b.time, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
FROM smalltable s
leftJOIN bigtable b
ON b.id = s.id;--Time taken: 67.411 seconds
3、执行大表JOIN小表语句
INSERT OVERWRITE TABLE jointable2
SELECT b.id, b.time, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
FROM bigtable b
leftJOIN smalltable s
ON s.id = b.id;--Time taken: 69.376seconds
可以看出大表join小表或者小表join大表,就算是关闭map端join的情况下,在新的版本当中基本上没有区别了(hive为了解决数据倾斜的问题,会自动进行过滤)
MapJoin
如果不指定MapJoin或者不符合MapJoin的条件,那么Hive解析器会将Join操作转换成Common Join(在Reduce阶段完成join)。容易发生数据倾斜。可以用MapJoin把小表全部加载到内存在map端进行join,避免reducer处理。
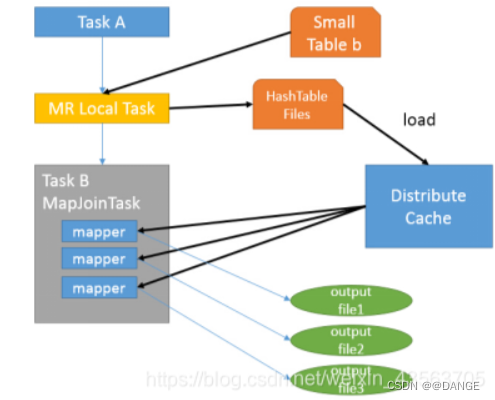
首先是Task A,它是一个Local Task(在客户端本地执行的Task),负责扫描小表b的数据,将其转换成一个HashTable的数据结构,并写入本地的文件中,之后将该文件加载到DistributeCache中。
接下来是Task B,该任务是一个没有Reduce的MR,启动MapTasks扫描大表a,在Map阶段,根据a的每一条记录去和DistributeCache中b表对应的HashTable关联,并直接输出结果。
由于MapJoin没有Reduce,所以由Map直接输出结果文件,有多少个Map Task,就有多少个结果文件。
案例实操:
1、开启Mapjoin功能
set hive.auto.convert.join=true; 默认为true
2、执行小表JOIN大表语句
INSERT OVERWRITE TABLE jointable2
SELECT b.id, b.time, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
FROM smalltable s
JOIN bigtable b
ON s.id = b.id;--Time taken: 31.814 seconds
3、执行大表JOIN小表语句
INSERT OVERWRITE TABLE jointable2
SELECT b.id, b.time, b.uid, b.keyword, b.url_rank, b.click_num, b.click_url
FROM bigtable b
JOIN smalltable s
ON s.id = b.id;--Time taken: 28.46 seconds
参考原文链接:
原文链接:https://blog.csdn.net/weixin_43563705/article/details/103297070
版权归原作者 @DANGE 所有, 如有侵权,请联系我们删除。