
本文整理自网易互娱资深开发工程师、Apache Kyuubi Committer 林小铂的《基于 Kyuubi 实现分布式 Flink SQL 网关》分享,内容主要分为以下四部分:
- Kyuubi 是什么
- Kyuubi 架构设计
- Flink x Kyuubi 优势
- 未来展望
一. Kyuubi 是什么
1.1. Kyuubi 简介
简单来说,Kyuubi 是一个分布式、多租户的 SQL 网关。相信大家先会想到的问题是,Flink 已经提供 SQL Gateway,为什么还需要 Kyuubi 呢?其实答案就是分布式和多租户两个关键词,两者相辅相成,Kyuubi 很多高级功能都是从分布式和多租户衍生而来的。

1.2. Kyuubi 的发展历程

- 2018-2020 0.x 版本
Kyuubi 在 2018 年立项,最初目的主要为解决 Hive 用户迁移到 Spark SQL (Spark Thrift Server) 的痛点,比如租户间隔离和服务稳定性的问题。2018-2020 年是 Kyuubi 的 0.x 版本阶段,这个时期主要定位为 Spark Thrift Server 的升级版,用户主要来自 Spark 社区。
- 2020-2021 1.x 版本
在 Kyuubi 发展过程中,我们逐渐意识到 Kyuubi 解决的问题并不是 Spark 独有,而是不同引擎都会遇到的共性问题。于是 2021 年 Kyuubi 进行了架构升级,将通用解决方案抽象成通用的 Kyuubi Server,然后对接不同引擎逻辑则成为 Kyuubi Engine。这是 Kyuubi 的 1.x 版本阶段,定位演变为通用的分布式多租户 SQL 网关。
- 2021 Apache 孵化
2021 年 9 月 Kyuubi 进入 Apache 孵化器,在 Flink 1.16 引入 SQL Gateway 后,Kyuubi Flink Engine 进行重构将底层改为基于 Flink SQL Gateway。
- 2023 Apache TLP
2023 年初 Kyuubi 从孵化器顺利毕业成为 Apache 顶级项目。
1.3. 主流计算引擎发展趋势
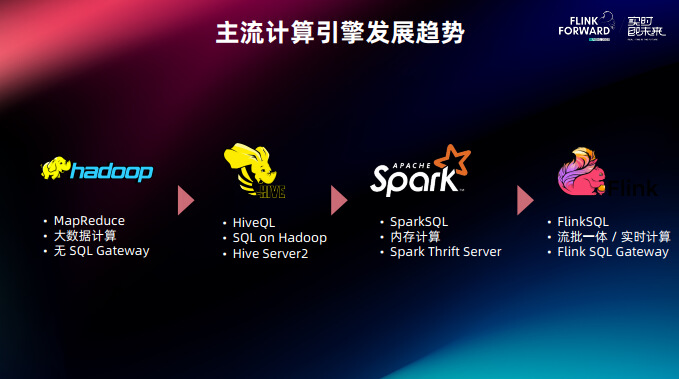
Kyuubi 的发展历程和开源大数据的计算引擎发展趋势是密不可分的。
业界最早的开源计算引擎是 MapReduce,这时编程 API 是 Java 不支持 SQL,所以也没有 SQL 网关一说。
在 2014 年左右,伴随着 SQL on Hadoop 潮流,Hive 代替 MapReduce 成为主流引擎。Hive 提供 Hive Server2 负责将 SQL 翻译成底层的 MapReduce,可以说是 SQL 网关的鼻祖。
后续 Spark 出现,其内存计算性能比起 Hive 大大提升,不少用户从 Hive 迁移至 Spark。Spark 提供了SparkSQL 编程 API,然后对应的 SQL 服务组件为 Spark Thrift Server。
在最近几年,Flink 在实时计算和流批一体上的优势又吸引不少用户从 Spark 或者 Hive 迁移过来。Flink 提供 FlinkSQL,对应的 SQL 服务组件为 Flink SQL Gateway。
在这几轮技术浪潮中,每个引擎有自己的 SQL 服务组件(我们可以统称他们为 SQL Gateway),但它们的功能其实并没有完全对齐,很多企业级的特性是缺失的,而 Kyuubi 的目标则是作为统一标准化的 SQL 网关来屏蔽掉这些差异。
1.4. SQL Gateway 对比

上图是不同 SQL 网关的关键特性对比。
1.4.1. 多租户
多租户包括认证和资源隔离两个关键标准。
- 在这方面,Hive Server 支持是最好的;
- 相对而言,Spark Thrift Server 因为本身会绑定一个 Spark 集群,而 Spark 集群是单用户的,所以仅能在 Driver 端做到 DDL 伪装,而在集群端执行的 DQL 和 DML 其实都是以 Spark Thrift Server 本身的用户来执行的;
- Flink SQL Gateway 则是受限于 Flink 本身不支持多租户;
- 最后是 Kyuubi,Kyuubi 是 Server 和 Engine 分离的架构,所以至少能在引擎粒度支持多租户
1.4.2. 水平拓展和高可用
水平拓展和高可用这两个特性通常和分布式的架构绑定,因此分布式架构的 Hive Server2 和 Kyuubi 都是支持的,而 Spark Thrift Server 和 Flink SQL Gateway 暂不支持。
1.4.3. 动态资源配置
- Hive Server 是可以在每条 SQL 的粒度上单独指定资源;
- Spark Thrift Server 会绑定一个 Application,所以资源是全局的,集群资源在 Spark Thrift Server 启动时就已经确定;
- Flink SQL Gateway 没有和 Flink Cluster 强绑定,所以资源还是集群粒度的;
- Kyuubi 可以在引擎粒度去执行资源。
1.4.4. 多版本能力
SQL 网关可以接受一些低版本的 Client 的请求,但通常要求和集群的计算引擎的版本是保持一致的。这会导致升级集群版本的时候可能要开多个 SQL 网关的实例,Kyuubi 对这方面做了兼容处理。Kyuubi 的一个实例,是可以兼容多个版本的计算引擎。比如 Kyuubi 的最新版本 Flink Engine ,它兼容 Flink 1.16 到 1.18 三个版本。
二. Kyuubi 的架构设计
2.1. Kyuubi 架构

Kyuubi 从部署架构上分为 Kyuubi Client、Kyuubi Server 和 Kyuubi Engine 三层:
- Kyuubi Client 主要是将用户 SQL 提交给 Kyuubi Server。Client 可以是和 Hive 兼容的 Beeline 或者支持 JDBC 或者 REST 的任意客户端。
- Kyuubi Server 负责 Session / Operation / Engine 的管理。Server 会接收 Client 连接,并将请求通过 RPC 传递给 Engine 执行。
- Kyuubi Engine 承载实际计算。Engine 会针对不同的引擎有对应的实现,比如 Flink Engine、Spark Engine、Trino Engine。Engine 一般会运行在引擎的 master 节点,对于 Spark 来说就是 Spark Driver,对 Flink 来说就是 JobManager。
2.2. Kyuubi 会话路由
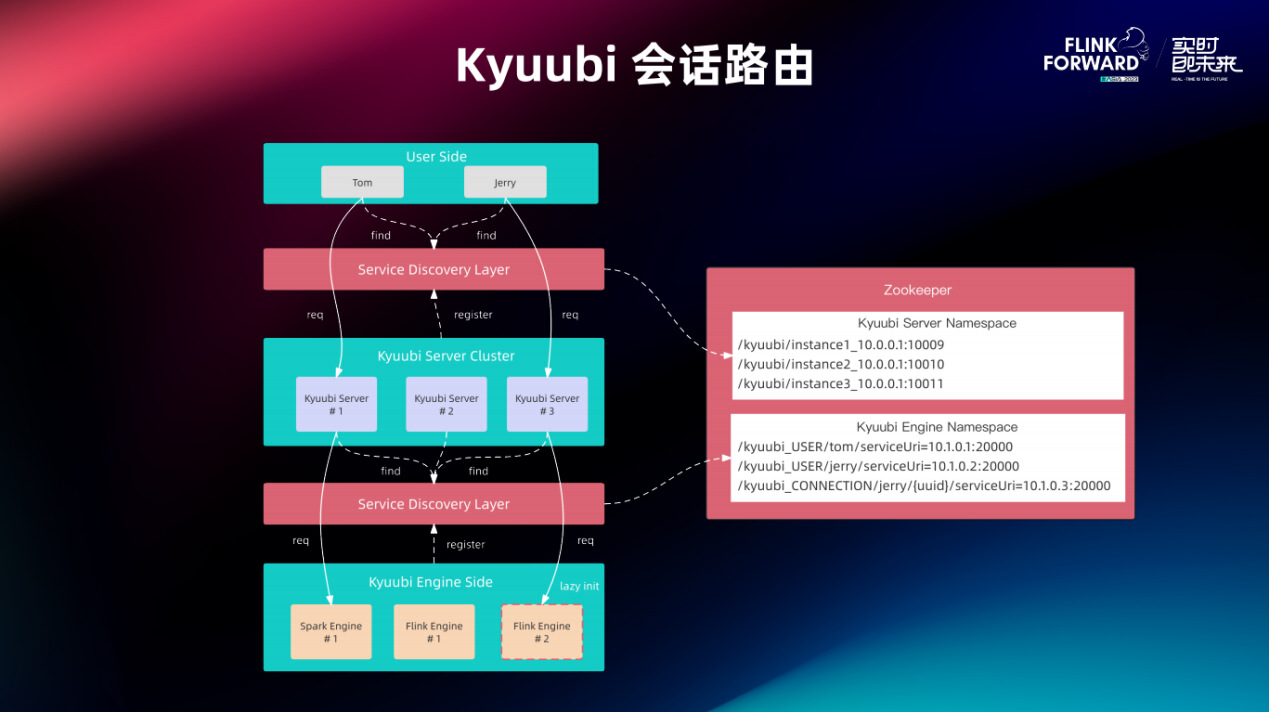
在 Kyuubi 架构中 Client 与 Server、Server 与 Engine 之间的通信均有基于 Zookeeper 的服务发现和负载均衡,这意味着不同模块之间是非常松耦合的。在同一个 Zookeeper namespace 下,Client 可以连到任意一个 Server 上, Server 也能访问任意一个 Engine。
一个请求最终落到哪个 Engine 上由 Kyuubi Server 自动控制。Kyuubi Server 会根据多租户隔离策略的自动选择一个合适的 Engine,如果满足要求的 Engine 不存在,那么 Kyuubi Server 会即时启动一个。相对地,当一个 Engine 闲置一段时间后,Engine 会自动退出来节省资源,当然也可以通过 Kyuubi Server 主动关闭 Engine。可以说 Kyuubi Engine 是按需启动的,然后生命周期也是由 Server 管理。
2.3. Kyuubi 引擎隔离级别

那么 Kyuubi Server 如何决定是否启动一个新的 Engine 呢?这很大程度上是由 Kyuubi 引擎隔离级别决定的。
Kyuubi 提供 4 种引擎隔离级别:
- CONNECTION 级别意味着每个连接独占一个 Engine,这是最高的隔离级别,比较适合离线的大作业、Ad-hoc 查询或者实时作业的情况
- USER 级别意味着每个用户独占一个 Engine,适合大部分场景
- GROUP 级别则是每个用户组共享一个 Engine,适合小数据量的场景
- SERVER 级别则是全部用户共享全局的一个 Engine,这是最低的隔离级别,一般是管理员执行管理操作时使用
在引擎隔离级别之上,Kyuubi 还提供细粒度的路由设定,也就是 Subdomain。比如一个用户可能希望用一个 Flink Engine 做实时计算,另外一个 Flink Engine 做 OLAP 查询。针对这种情况,Kyuubi 提供 subdomain 配置项。subdomain 允许在一个 namespace 再做划分。比如上述场景,用户可以分别在连接时指定 kyuubi.engine.share.level.subdomain=realtime 或 kyuubi.engine.share.level.subdomain=olap ,这样 Kyuubi Server 就会启动两个 Flink Engine。
2.4. Kyuubi Server 状态共享
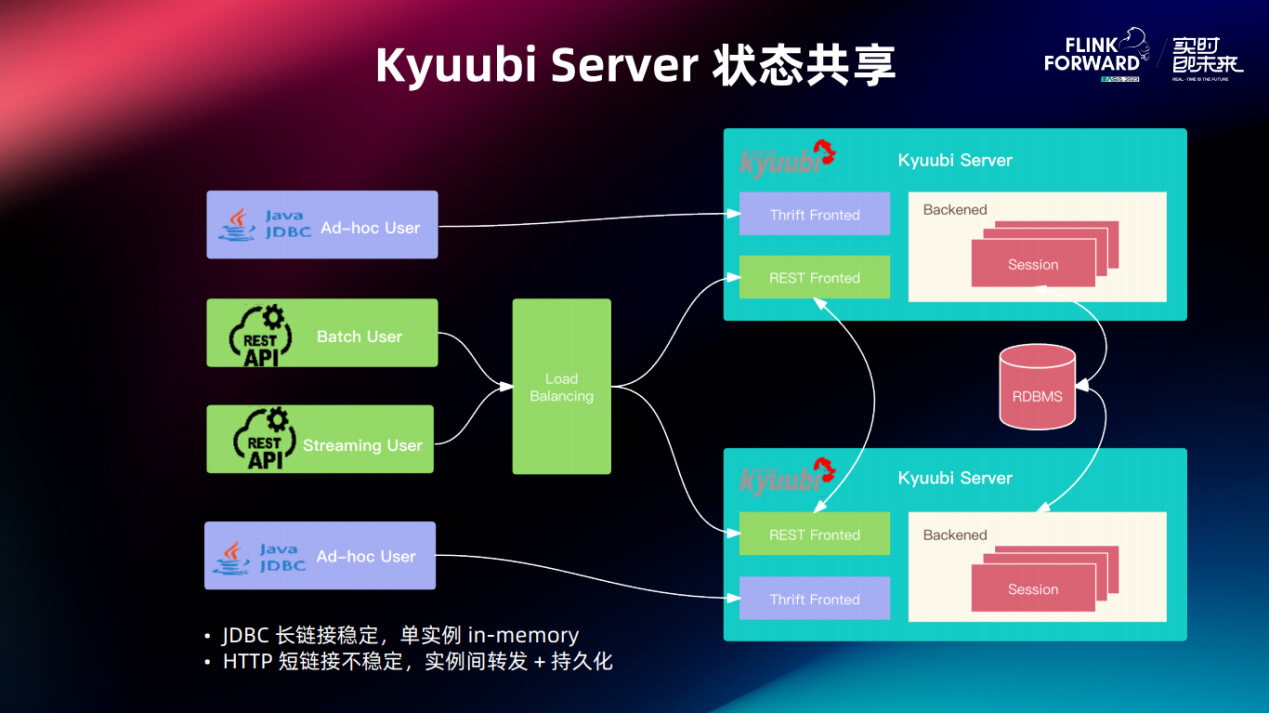
大部分情况下 Kyuubi Server 是没有状态的,但也会有例外。例如当用户批量提交大量的 SQL 到 Kyuubi,Kyuubi Server 会将请求放入队列,但这个队列是在内存的,其他 Kyuubi Server 实例并不知道这批请求。如果用户前后两个请求被路由到不同的 Kyuubi Server,那么可能会产生状态不一致的问题。用户可能会说我刚刚提交了一批作业,为什么现在查不到。
为此,Kyuubi 针对不同场景进行了优化。首先取决于 Client 类型,如果是基于 JDBC,JDBC 是长连接比较稳定,所以一般不会出问题。但如果是基于 REST,那么都是 HTTP 短链接,负载均衡器很可能把请求路由到不同实例上。
Kyuubi 的解决方案是引入了数据库来持久化 Server 的状态,包括请求的内容、Server ID 和 Client ID。如果其他 Kyuubi Server 接收到不属于自己的请求,可以通过 REST Fronted 将请求转发给正确的 Kyuubi 实例。
三. Flink x Kyuubi 优势
3.1. 优势一:分布式多租户
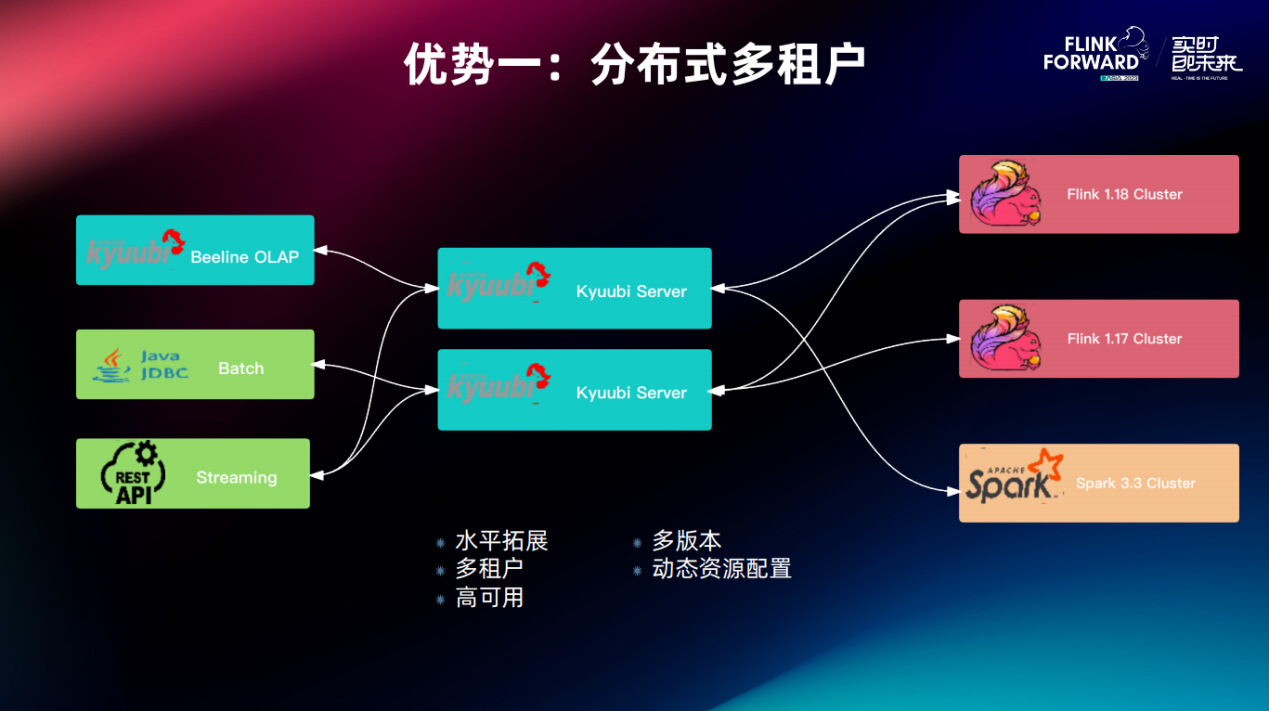
这是 Kyuubi 的一个标准优势:水平拓展、多租户、高可用、多版本和动态资源配置。
值得一提的是,在以前主打实时计算的背景下,其实 Flink 对 SQL 网关的需求不是很高,通常我们可能单实例的 SQL 网关就能解决问题。
但是随着 Flink 往流批一体和 OLAP 的方向发展,我们对 SQL 网关的需求越来越高,无论是连接数还是请求量都有可能翻一个数量级,甚至两个数量级。那么这时 Kyuubi 分布式的解决方案就会成为一个必需品。
3.2. 优势二:优化 Application 模式
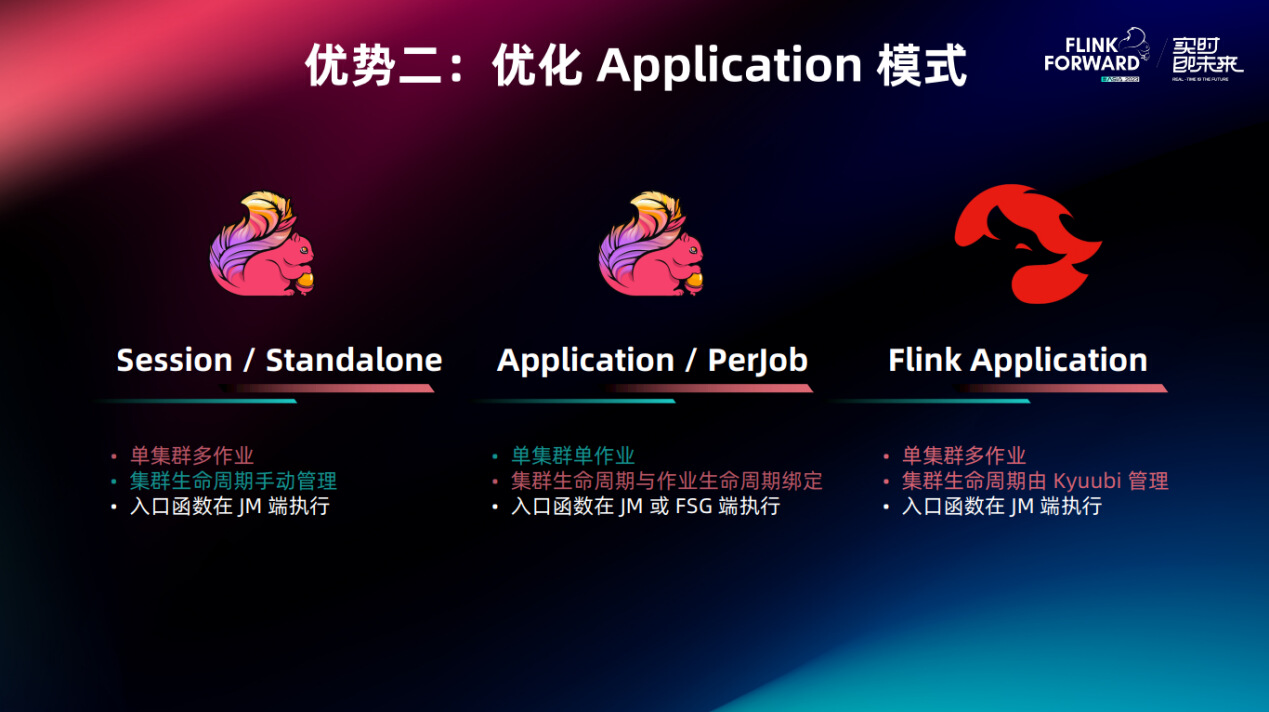
Kyuubi 的 Flink Application 模式其实和标准的 Application 模式是有一定差别的。Flink 是提供了四种部署的模式,可以分成两类:
- Session 和 Standalone 模式。这类是单集群可以运行多作业,但是集群的生命周期需要手动管控,需要在请求之前启动一个集群,不用了再手动关掉。
- Application 和 PerJob 模式。这类是单集群只允许单作业,但是优点是集群的生命周期可以直接绑定作业的生命周期,作业结束集群就会退出,释放资源。
以上这两类的部署模式是互有优缺点的。而 Kyuubi 的 Application 模式结合了两者的优点。它允许单集群多作业,而集群的生命周期由 Kyuubi 管控,用户是不用去操心的。为了解这点,我们下面先简单回顾一下 Flink SQL 的翻译流程。
3.2.1. Flink SQL 工作流程

从用户提交的 Flink SQL 到变成 Flink Runtime 可以去执行的作业,会有一个 SQL 翻译的过程。这个过程可以分成四步。
- 解析。用户提交的 SQL ,会被 Parser 解析成逻辑执行计划。
- 优化。逻辑执行计划会被 Optimizer 优化,生成物理执行计划。
- 编译。物理执行计划会被 Planner 编译成 Java 代码。
- 部署。 构建 JobGraph , 提交给 JobManager 。
通常来说,这四步都会在一个 TableEnvironment里面去完成。
3.2.2. Flink SQL Gateway PerJob 架构
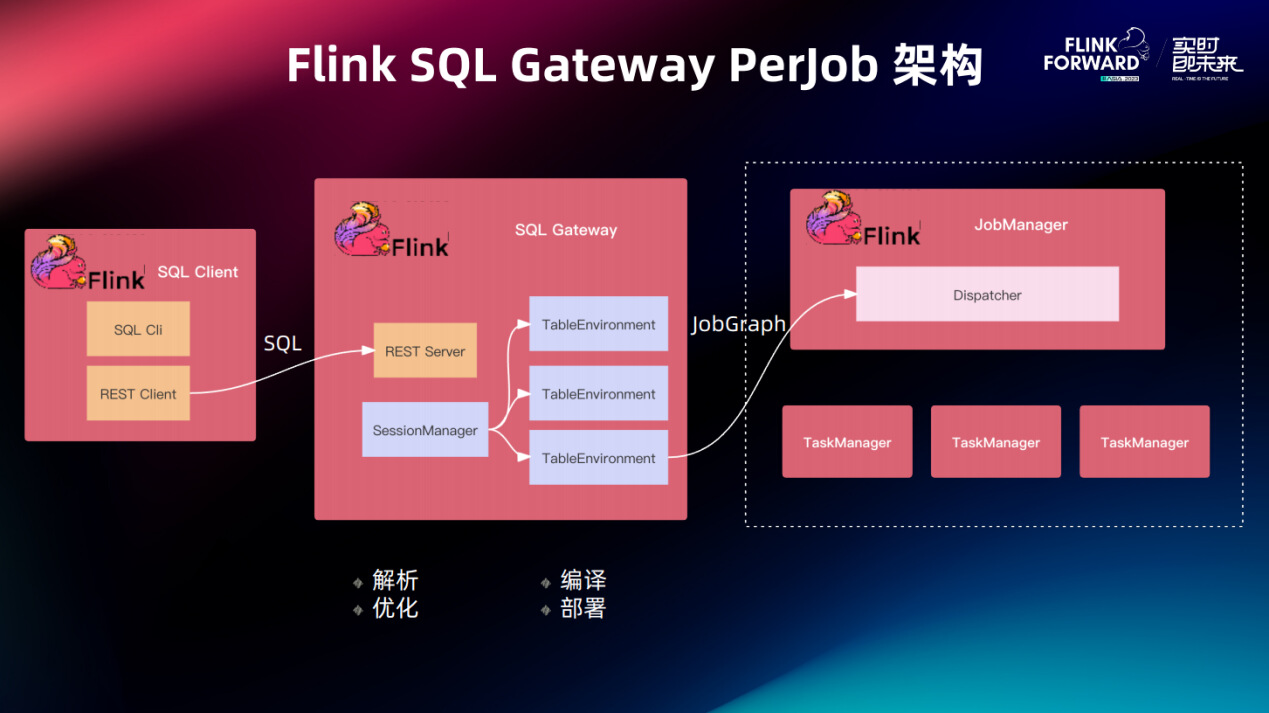
在 PerJob 架构下 Flink SQL Gateway 会在内部开启 TableEnvironment , SQL 翻译的四步全部做完后,生成 JobGraph 提交给 JobManager 。
这是很标准的一个使用制式,当然是没什么问题,当下 PerJob 的部署模式已经过时了,我们要迁移到 Application 的模式下。
3.2.3. Flink SQL Gateway Application 架构

在标准的一个 Application 模式下,会要求用户的 main 函数在 JobManager 上去执行,那么这意味着SQL 翻译至少最后一步的部署,会在 JobManager 上去完成。
针对这个问题,社区提出一个方案 FLIP-316,就是 Flink SQL Gateway去支持 Application 的一个模式。在这个议案里面 Flink SQL Gateway 会在本地内部的 TableEnvironment 完成 SQL 翻译的前两步,也就是解析优化。生成中间的物理执行计划可以被序列化为 JsonPlan ,然后与其他资源文件一起提交给 JobManager ,JobManager 会启一个main 函数去完成编译和部署这两步。通过这种方式 Flink SQL Gateway 就可以去支持 Application 模式。
但是这个方案有一个缺点,就是 JsonPlan 目前是只支持 DML ,这意味着在一些 OLAP 场景,常用的 Select 查询没有办法直接通过 Application 来支持。
3.2.4. Kyuubi Flink Application 架构
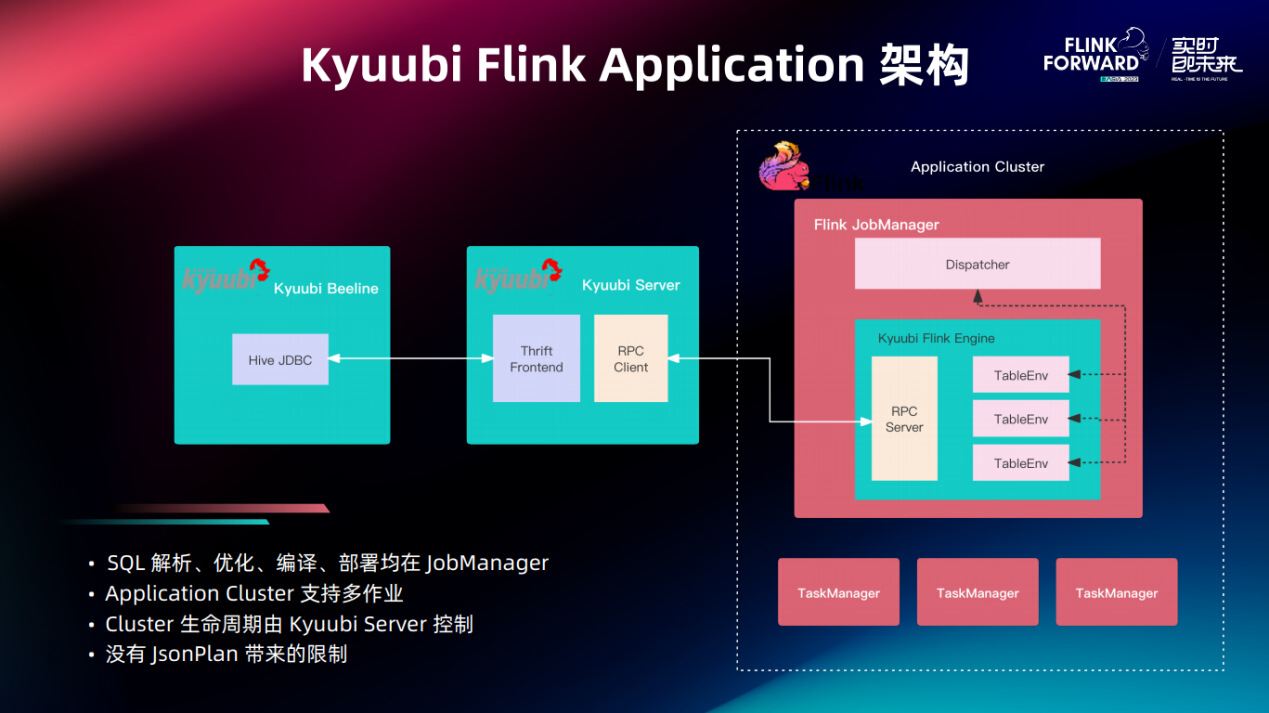
Kyuubi 的 Flink Application 架构模式是怎么解决这些问题的。
首先, Kyuubi 的 Flink Engine 是运行在 JobManager 里面的,它可以通过 RPC 的方式去接收到用户提交的 SQL ,他在内部的 Table Environment ,就可以像Flink SQL Gateway 里的 PerJob 模式,一次性完成上述四步工作。
最后得到的作业,通过 JobManager 内部的 Dispatcher API 去提交。通过这种方式就可以绕开 Application 模式下 JobManager 要求每个集群只有一个作业的限制,也没有 JsonPlan 带来的问题。
对于 JobManager 来说, Kyuubi Flink Engine相当于是一直在运行,没有退出的用户main函数。 Flink Engine 什么时候退出, JobManager 就会 Shutdown 把资源给释放掉。
3.3. 优势三:多引擎支持

这可以分成统一入口和引擎插件两个方面。
3.3.1. 统一入口
- 流批一体友好,它可以作为一个多引擎的统一入口,这样方便不同引擎的相互之间迁移。像从 Hive 、Spark 迁移到流批一体的 Flink ,可以直接用 Kyuubi 来实现。如果是 Spark SQL 的用户,那很可能也是 Kyuubi 的用户,就只要新增一个 Flink Engine 就可以。
- Kyuubi 可以做混合负载的复用网关,支持多种计算引擎,不需要为每一种计算引擎维护 SQL Gateway。
- Kyuubi Server 可以作为统一安全认证的入口,它可以在认证完毕以后把用户的凭证,比如 Kerberos TGT ,通过 RPC 方式传递给 Engine , 然后 Server 会负责定时 renew 凭证 。
3.3.2. 引擎插件
另一方面,Kyuubi 提供灵活的插件机制支持满足平台管理需求,例如 SQL 血缘提供、集成 Ranger 提供列级的访问控制或者监听事件。部分插件会依赖于引擎本身的支持,例如 Kyuubi Spark Engine 的血缘提取是通过 Spark 提供的 QueryExecutionListener 接口完成,而 Flink 的血缘支持也在 1.18 版本有了接口,后续 Kyuubi 这边也会跟进。
3.4. 优势四:可观测性
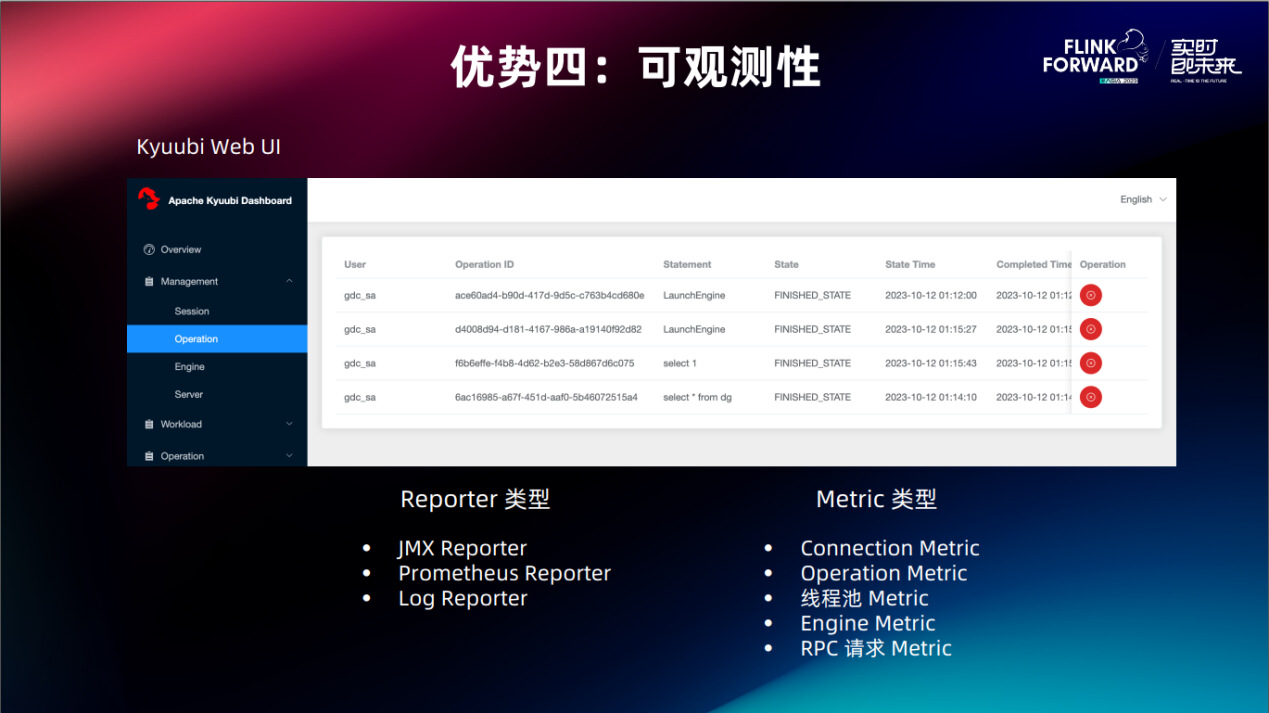
Kyuubi 的 Metric 系统是很完善的。
- Reporter 常用的有 JMX 、 Prometheus 和打印到日志的 Log Reporter 。
- Metric 纬度非常丰富,包括 Connection 、 Operation 、 Server 的线程池、 Engine 的状态、不同RPC请求的时长、频率等等。
同时,Kyuubi Server 提供内嵌的 Web UI,可以很直观的看到各项指标。
四. 未来展望

这是 Kyuubi 的 Flink Engine 的一些 Roadmap ,其中很多工作依赖 Flink 本身暴露的能力,需要两个社区共同推进。
- 完善 on K8s 的 Flink Application 模式,这点其实和 Flink SQL Gateway 遇到的阻塞点是一样的,这点会依赖于 FLIP-316。
- 目前 Kyuubi 的 Application Mode 缺乏多作业的 JM HA 支持,这点我们会推动社区去探索解决方案。
- Flink 引擎插件的支持,我们会不断完善 Flink Engine 的插件支持,包括审计、血缘等插件。
- 最后是 SQL 粒度的资源管理,目前 Flink 细粒度资源只支持 DataStream API,而 Flink SQL 只能通过调整并行度来设置资源,我们会探索把它暴露到 SQL API 的方式。
版权归原作者 Apache Flink 所有, 如有侵权,请联系我们删除。