
【大批量数据处理方式】monggoDB+xxxJob+rabbitMQ逐步提升查询性能
需求背景
当需要从monggoDB查询除符合条件的数据,把数据进行统计汇总,展示到前端
处理方式
从简单到难依次的处理方式:
1.直接从monggoDB中拿出来数据,对数据进行处理展示;(适合少批量且不容易修改的数据)
2.分批从monggoDB中拿出来数据,对数据进行处理展示;(适合中批量的数据)
3.分批从monggoDB中拿出来数据,对数据进行清理,组建成具体的sql,插入到新的表中,由于数据是每天实时更新的,所以需要对这个数据清理进行定时任务xxx-job的操作,让每天自动进行数据处理,这里处理时间的掌控,最好是前一天的最后时刻(比如定时任务00:00执行,就拿数据库里面统计的最后时间到前一天最后一秒来进行处理)
4.把这个数据处理的的操作放入到RabbitMQ中,让单线程的数据处理,改成多线程的方式执行
疑问
实际上,我们在第3种处理方式上,可以在具体的数据清理的方法内,加入java自带的多线程处理,但是由于对生产环境的一些配置:比如最大线程数之类的不太清楚,所以就想到了用MQ的方式处理,JAVA自带的多线程处理方式如下面这位SakamotoLz大佬的的文中所述:
SpringBoot + MongoDB 大容量数据多线程分批处理(示例:抽取字段构建新表)
大批量数据处理的不同实现方式
monggoDB 数据获取方式
太详细的东西咱们就不说了,咱们就直接看具体的代码实现
普通查和分批查
首先注入对应的对象
@AutowiredprivateMongoTemplate mongoTemplate;
普通查询
@TransactionalpublicvoidfindDate(){//查询mongodb工单数据(工单 && 已完成)List<Criteria> andCriteriaList =Lists.newArrayList();// 基本条件Criteria baseCriteria =Criteria.where("具体的字段").is("对应的值");
andCriteriaList.add(baseCriteria);//这里可以是多个条件,并加入到查询list里Query query =newQuery();
query.addCriteria(newCriteria().andOperator(andCriteriaList));List<"对应的monggoDB表对象"> mongodbList= mongoTemplate.find(query,"对应的monggoDB表对象".class,"对应的monggoDB表名");}
分批查询
@Getter@Setter@ToString@Accessors(chain =true)@ApiModel(value ="计数结果", description ="计数结果")publicclassCountResultD{privateLong count;publiclonggetCount(){return count;}publicvoidsetCount(long count){this.count = count;}}
@TransactionalpublicvoidfindDate(){//查询mongodb工单数据(工单 && 已完成)List<Criteria> andCriteriaList =Lists.newArrayList();// 基本条件Criteria baseCriteria =Criteria.where("具体的字段").is("对应的值");
andCriteriaList.add(baseCriteria);//这里可以是多个条件,并加入到查询list里AggregationOptions aggregationOptions =AggregationOptions.builder().allowDiskUse(true).build();CountOperation countOperation =Aggregation.count().as("count");Aggregation countAggregation =Aggregation.newAggregation(Aggregation.match(newCriteria().andOperator(andCriteriaList)),
countOperation
).withOptions(aggregationOptions);AggregationResults<CountResultD> countResult = mongoTemplate.aggregate(countAggregation,"对应的monggoDB表名",CountResultD.class);CountResultD countResultD = countResult.getUniqueMappedResult();long totalCount = countResultD!=null? countResultD.getCount():0;
log.info("总数:{}", totalCount);int pageSize=1000;//这个数值可以自己调整,意义是一次查询多少个数据进行处理;long totalPage=(totalCount % pageSize ==0)?(totalCount / pageSize):(totalCount / pageSize +1);List<"对应的monggoDB表对象"> mongodbList =newArrayList<>();for(long i=1;i<=totalPage;i++){Aggregation aggregation =Aggregation.newAggregation(Aggregation.match(newCriteria().andOperator(andCriteriaList))).withOptions(aggregationOptions);
aggregation.getPipeline().add(Aggregation.skip((i -1)* pageSize)).add(Aggregation.limit(pageSize));List<"对应的monggoDB表对象"> dataEList = mongoTemplate.aggregate(aggregation,"对应的monggoDB表名","对应的monggoDB表对象".class).getMappedResults();
mongodbList.addAll(dataEList);}//数据进行处理dateHand(mongodbList);}
这样就直接拿出来所以的符合条件的数据并对数据进行处理了.
xxxJob实现自动任务执行
基础的配置就稍后再讲,我们看具体的实现配置
@Component("bpmReportPolicedOrderCollectJob")@RequiredArgsConstructor@Slf4jpublicclassReportPolicedCollectJob{@XxlJob("reportPolicedOrderCollectJob")publicReturnT<String>reportPolicedOrderCollectAllJob(String param){long startTime =System.currentTimeMillis();
log.info("执行定时任务开始-:{} : {}");try{
processTaskService.findDate();}catch(Exception e){
log.error("执行定时任务失败"+ e);
e.printStackTrace();}long endTime =System.currentTimeMillis();
log.info("执行定时任务结束");
log.info("执行时间:"+(endTime - startTime));returnReturnT.SUCCESS;}}
下面是XXX-job具体的配置图,值得注意的是JobHandler的配置 要跟 @XxlJob(“reportPolicedOrderCollectJob”)保持一致,且如果任务执行失败,查看是否开启了任务,有时候不开启任务,执行任务是没作用的,也会失败的.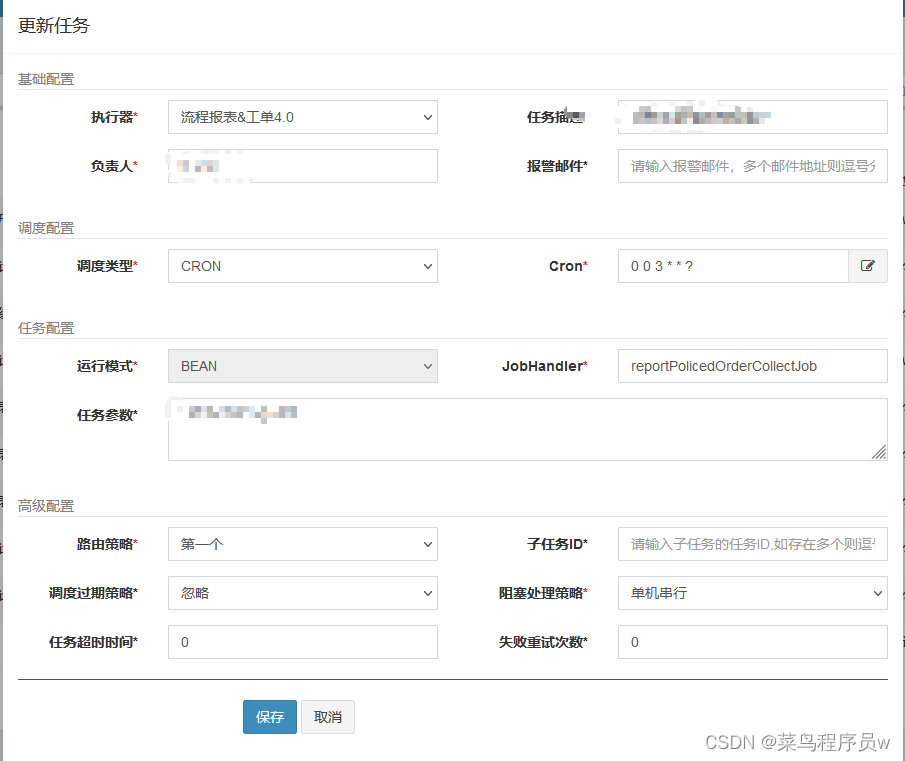
rabbitMQ将处理放到mq中进行处理消费
由于放到xxx-job是单线程执行任务,当配到执行的任务数量过于多,会占用大量的服务器资源,所以我们可以用rabbitMQ多线程并发处理,将我们的任务放入到mq中,持续的消费,就可以避免过多占用服务器资源的问题.
生产者:
@MessagingGateway@SuppressWarnings("UnresolvedMessageChannel")publicinterfaceReportPolicedMsgGetWay{@Gateway(requestChannel ="REPORT_POLICED_TASK_EVENT_OUTPUT")voidreportPolicedTaskMsg();}
消费者:
这里的 consumer 指的是java.util.function里面的方法,是用于接收到具体的任务,进行消费
@Component(value ="reportPolicedCollectConsumer")@Slf4jpublicclassReportPolicedCollectConsumerimplementsConsumer<PolicedPointReportMsg>{@Setter(onMethod_ ={@Autowired})privateProcessTaskService taskService;@Overridepublicvoidaccept(){
log.info("接收到任务状态发改变消息{}");
taskService.findDate();}}
具体的mq配置类:
application-mq-bpm.properties
一定要注意配置是否跟代码里面书写的是否保持一致;
bpm.output-bindings=reportPolicedTaskMsg
bpm.definition=reportPolicedCollectConsumer
spring.cloud.stream.function.bindings.reportPolicedTaskMsg-out-0=REPORT_POLICED_TASK_EVENT_OUTPUT
spring.cloud.stream.bindings.REPORT_POLICED_TASK_EVENT_OUTPUT.destination=REPORT_POLICED_TASK_EVENT
spring.cloud.stream.rabbit.bindings.REPORT_POLICED_TASK_EVENT_OUTPUT.producer.routing-key-expression=''
spring.cloud.stream.function.bindings.reportPolicedCollectConsumer-in-0=reportPolicedCollectConsumer_input
spring.cloud.stream.bindings.reportPolicedCollectConsumer_input.destination=REPORT_POLICED_TASK_EVENT
spring.cloud.stream.bindings.reportPolicedCollectConsumer_input.group=REPORT_POLICED_TASK_CHANGE_GROUP
修改我们之前的xxx-job方法:
@Component("bpmReportPolicedOrderCollectJob")@RequiredArgsConstructor@Slf4jpublicclassReportPolicedCollectJob{@ResourceprivateReportPolicedMsgGetWay reportPolicedMsgGetWay;@XxlJob("reportPolicedOrderCollectJob")publicReturnT<String>reportPolicedOrderCollectAllJob(String param){long startTime =System.currentTimeMillis();
log.info("执行定时任务开始-:{} : {}");try{
reportPolicedMsgGetWay.reportPolicedTaskMsg();}catch(Exception e){
log.error("执行定时任务失败"+ e);
e.printStackTrace();}long endTime =System.currentTimeMillis();
log.info("执行定时任务结束");
log.info("执行时间:"+(endTime - startTime));returnReturnT.SUCCESS;}}
结语
希望我的这次分享能给你带来一丝考虑,让我们一起慢慢成长,早日实现自己的理想!
版权归原作者 菜鸟程序员w 所有, 如有侵权,请联系我们删除。