
本文主要讲述Kettle中变量的分类,并针对每一类变量的使用进行说明。
变量的分类
在Kettle中变量一共可以分为3类,分别是系统变量(对应“kettle.properties”文件)、自定义变量(对应“设置变量”组件)和环境变量,其中系统变量是全局变量,自定义变量是局部变量,而环境变量指的是当前脚本文件中出现的所有变量,包括系统变量、自定义变量以及环境变量自身定义的变量。
系统变量和自定义变量的最大区别:系统变量是在文件中定义的,对所有脚本文件都始终有效;自定义变量是在脚本中定义的,只有定义后才能使用,其有效范围和范围参数有关。
最后也会对"从步骤获取数据"(以"表输入"为例)和"作为参数的字段"(以"执行SQL语句"为例)的使用进行说明。
变量的使用
1、在哪里使用变量
在Kettle中凡是带有“$”符号的输入框都可以使用变量和参数。
例如数据库连接时的主机名称、数据库名称、端口号、用户名、密码等。
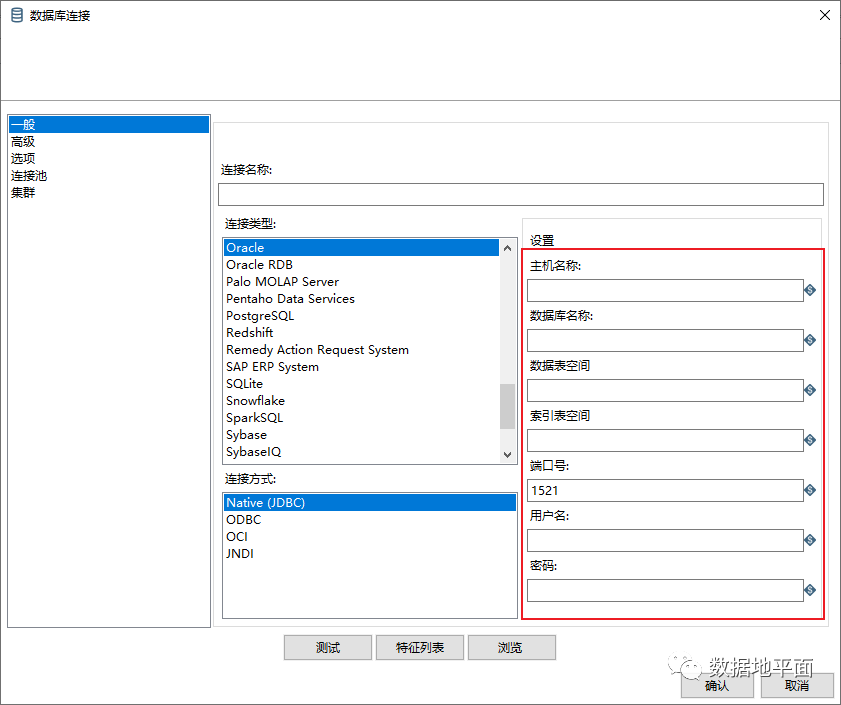
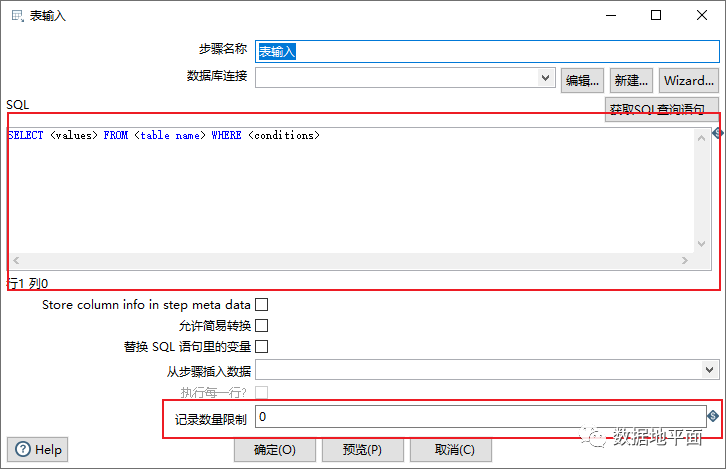
例如“表输入”组件,SQL输入框和记录数量限制输入框都可以使用变量,其中SQL输入框内容包含变量时,必须勾选“替换SQL语句里的变量”这句话。
2、怎么使用变量
变量的使用格式为%%name%%或者${name},效果一样,其中name为变量的名称,Kettle默认使用${name}格式。
对于系统变量,在使用时,可以按照格式直接填写;也可以同时按下CTRL-ALT-SPACE快捷键,使系统变量在下拉框中显示,然后选择需要的变量名称;把鼠标指针放在“$”符号,就会有快捷键使用提示。

补充说明:对于带有“$”符号的输入框,不要求必须使用变量,我们在填写时可以不使用变量,也可以只使用变量,当然也可以使用非变量内容和变量的组合。
下面将具体讲解下每种变量的具体使用方法。
系统变量
系统变量包含两类,一类是系统自带的,一类是用户通过配置文件添加的。
1、如何添加系统变量
用户可以通过编辑配置文件"kettle.properties"来添加变量,文件在"C:\Users\用户名.kettle"目录下面,例如把邮件相关配置信息设为为变量:
email.host=SMTP.139.comemail.port=25email.sendTo=date@[email protected][email protected]=123456
2、如何查看和编辑所有系统变量
Spoon客户端打开后,通过鼠标点击"编辑" ->"编辑kettle.properties文件",可以打开"kettle.properties"文件的编辑界面。
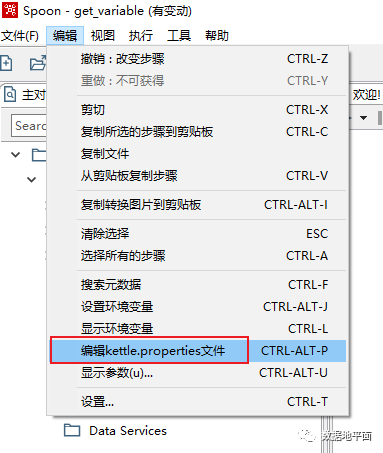
在这里,我们可以对所有的系统变量进行编辑、新增和删除,操作后的结果会保存在"kettle.properties"文件里。
3、什么时候使用系统变量
在下面这几种情况下推荐使用系统变量:
1、当脚本中的某个字段,在不同的环境中需要配置为不同的值时;
2、当某个字段在脚本中被多次使用,且根据业务逻辑,其将来被替换为其他值的可能性较大时,例如发送邮件的配置信息。
自定义变量
1、在转换中定义变量
首先新建一个转换文件,把"设置变量"组件拖进来:
然后需要选择一个输入组件,用来在设置变量时给变量赋值,例如常见的"表输入"组件;变量名称一般用大写字母表示;变量的有效范围有四种类型,作用范围上S > R > G > P,四种具体类型如下所示:
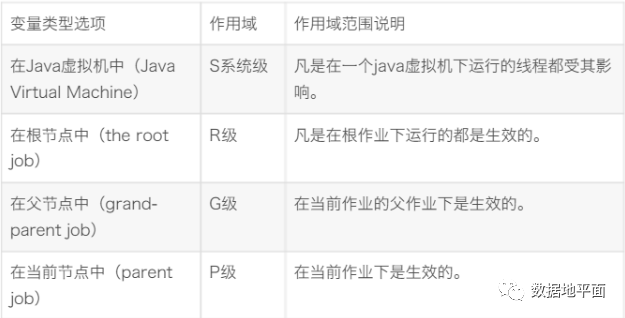
图片来源:kettle设置变量中变量范围的设置说明 - 百度文库
具体的数据输入、设置变量操作如下所示:

含有"设置变量"组件的转换无法单独运行调试,因为还没有指定"parent job",需要在后面的作业脚本中进行整体调试:
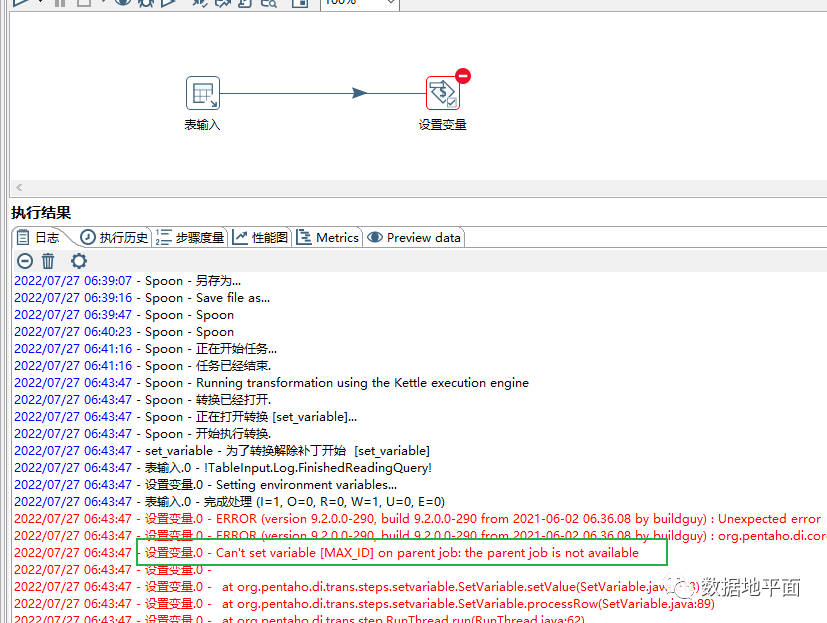
变量定义好后就可以使用了,有两点需要注意:1、变量的有效范围,超过使用范围后就无法使用了;2、在转换中定义的变量,在本次转换中不生效。
使用转换中的"设置变量"组件时,一般有两种用法:1、保存前一步骤的结果值,在其他步骤中使用;2、在循环执行中通过对变量赋值实现遍历操作。
2、在作业中定义变量
在作业中定义变量和在转换中定义的区别:1、变量值不需要从前一步骤获取,需要直接输入;2、变量定义后在当前文件就可以使用。
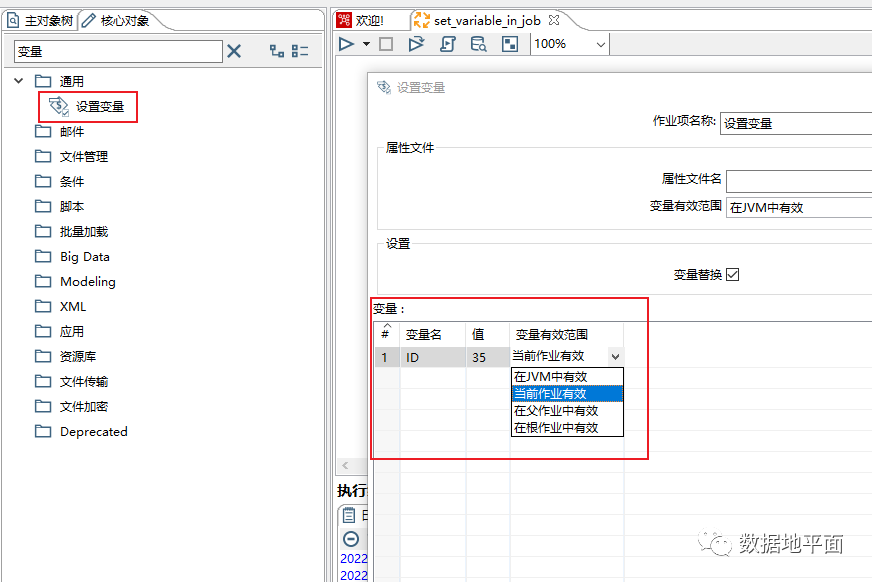
在作业中定义变量后在下一步直接使用举例:
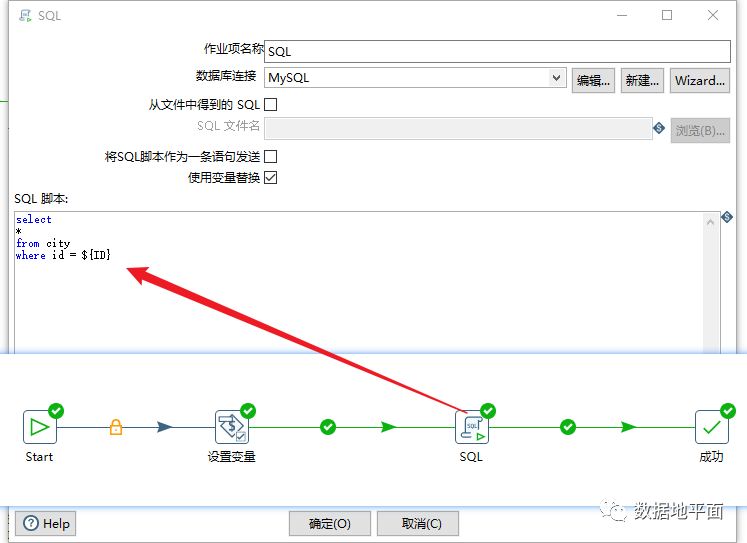
当作业以及作业包含的子作业、子转换中的组件,需要使用同一个变量值时,可以通过在作业中设置变量实现。
环境变量
在Kettle中环境变量指的是当前脚本文件中出现的所有变量,包括系统变量、自定义变量以及环境变量自身定义的变量。
通过下面的操作可以设置环境变量和查看环境变量:

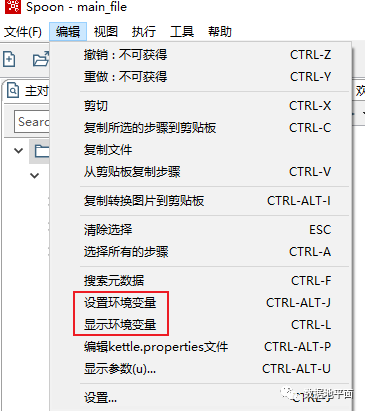
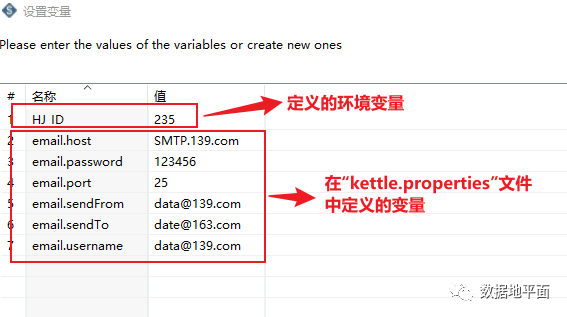
下图是通过点击"设置环境变量"打开的界面,其中第一个变量是新定义的环境变量,后面的变量是在该脚本文件中出现的变量,这里是在该脚本文件中出现的系统变量。
在当前作业定义好环境变量后,在当前作业、子转换和子作业中都可以正常使用,如下图所示:

其次,在转换中也可以定义环境变量。
从步骤获取数据
这里以"表输入"组件为例,如果我们只想从前面的步骤中获取脚本运行所需的条件,那么可以不通过设置变量来实现,如下操作就可实现:
1、确定要使用哪一个步骤的结果值作为条件后,在"从步骤插入数据"下拉框内选择对应的步骤名称;
2、在执行的SQL脚本中,使用"?"代替要使用的字段名称。需要注意的是,问号的顺序和字段的顺序要一一对应,即第一个问号对应从步骤插入数据的第一个字段。
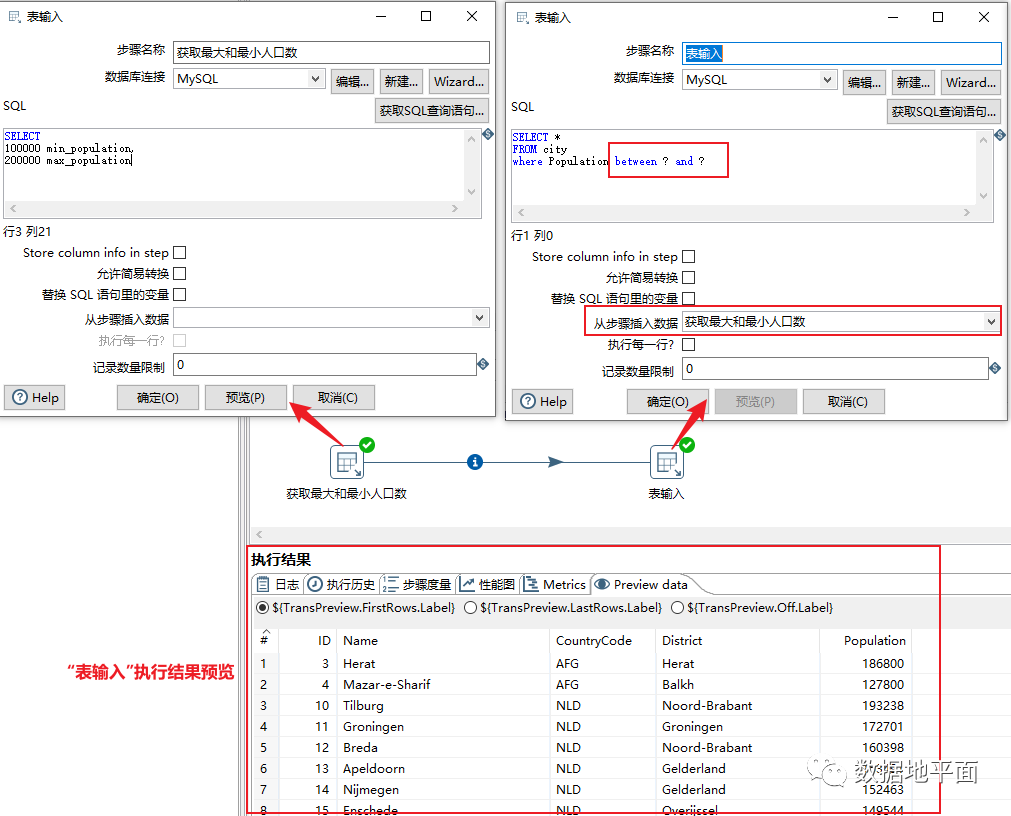
下图是脚本执行完后步骤"表输入"的预览数据:
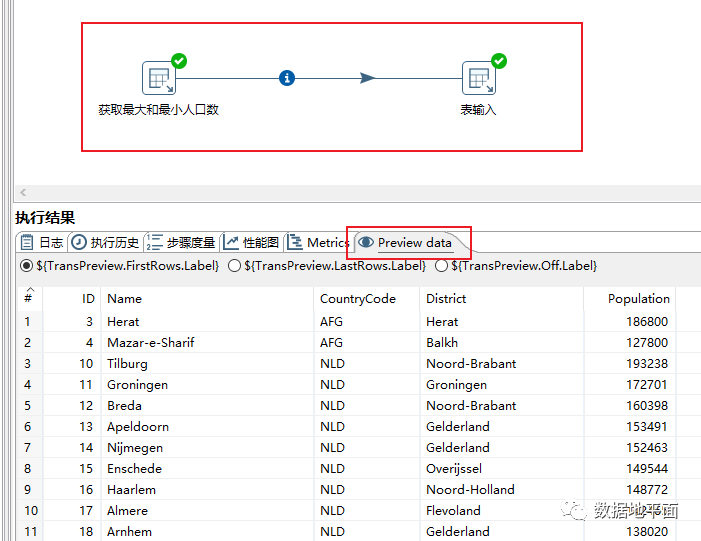
作为参数的字段
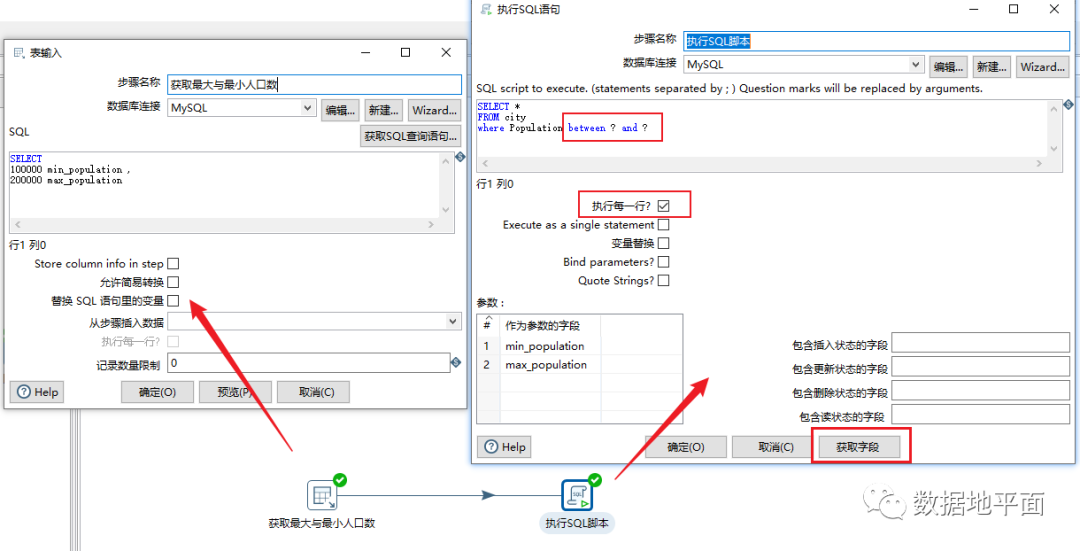
这里以"执行SQL语句"组件为例,如果需要从上一步的步骤中获取脚本运行所需的条件,那么可以不通过设置变量来实现,如下操作就可实现:
1、点击"执行SQL语句"组件的"获取字段",获取到作为参数的字段名称;
2、如果是转换文件,需要在"执行每一行"后面的方框内打钩,因为在默认条件下,"执行SQL语句"组件会在转换文件运行时优先执行;
3、在编写SQL脚本时,使用"?"代替要使用的字段名称,需要注意的是,问号的顺序和字段的顺序要一一对应,即第一个问号对应第一个字段。
总结
本文介绍了在Kettle中变量的基本使用方法,除了系统变量(对应“kettle.properties”文件)是对所有文件都有效外,其他变量只在对应的脚本文件中有效,大家可以根据业务需要选择合适的实现方式。
案例中使用的数据为MySQL自带的的示例数据,对应数据库名称"world",MySQL安装好后登录本地库就可看到。我已经把对应的Kettle脚本文件上传到百度网盘,需要的话,请关注公众号后,回复“变量和参数”获取。
针对以上内容,如果大家有订正、补充或者建议的地方,欢迎发私信联系,谢谢!
在关于Kettle的后续文章中,将会继续分享变量和参数的使用方法,为了方便感兴趣的您第一时间获取,请扫码关注下。
版权归原作者 数据地平面 所有, 如有侵权,请联系我们删除。