
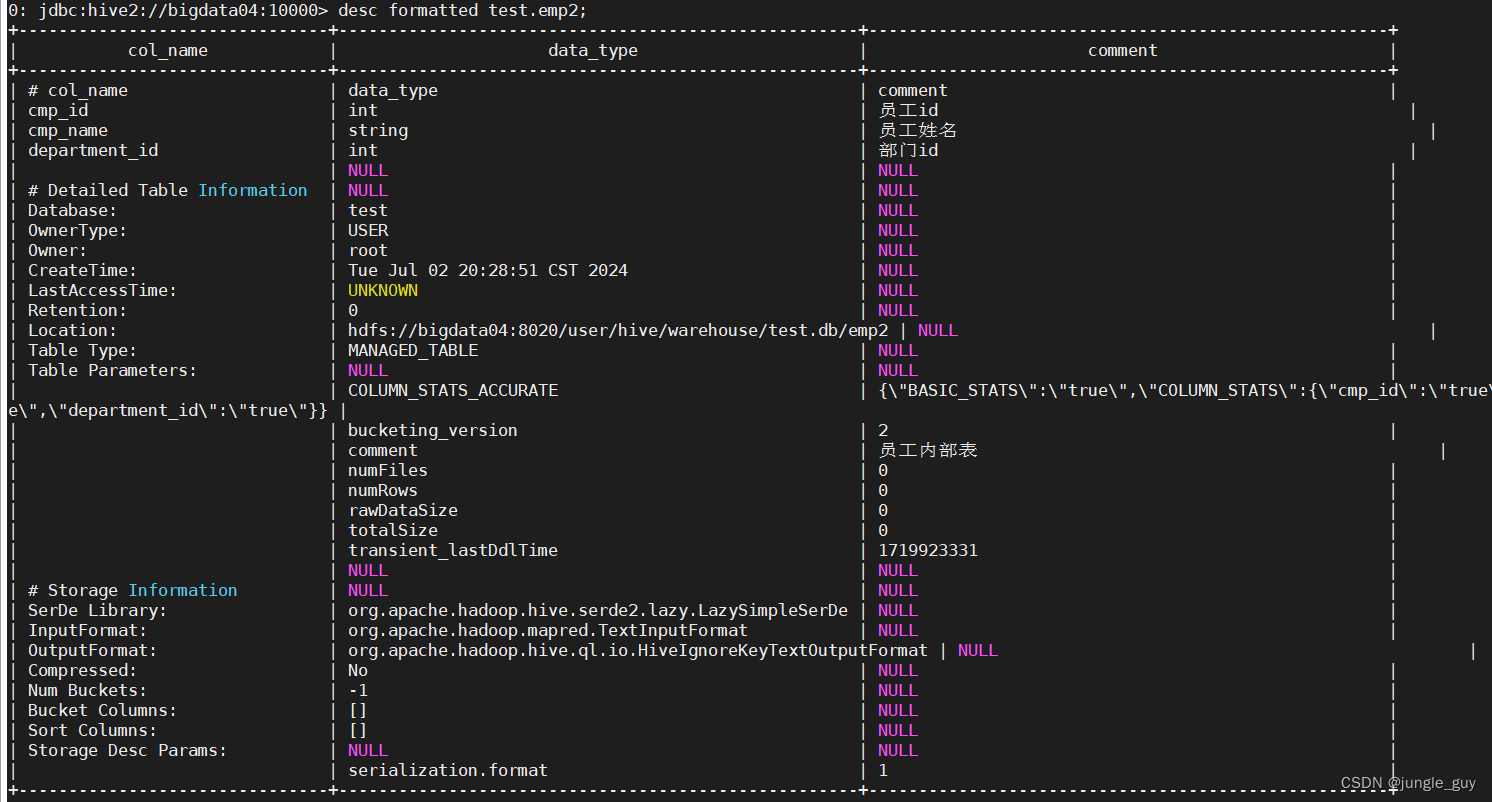
Hive中表的操作
Hive建表
默认的创建表方式
hive创建的表都会保存至HDFS上,可以在建表时指定以什么形式储存,以及数据如何分割
如下,创建员工表,以txt格式保存至HDFS,用","分割数据字段
--创建指定裂分隔符内部表emp3createtableifnotexists test.emp3(
cmp_id intcomment"员工id",
cmp_name string comment"员工姓名",
department_id intcomment"部门id")comment"员工内部表"row format delimited fieldsterminatedby','
stored AS textfile;
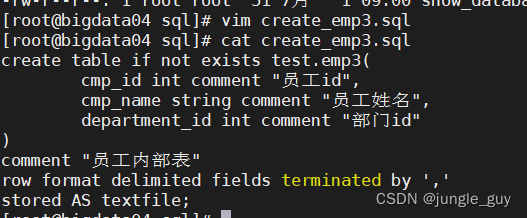
检查创建结果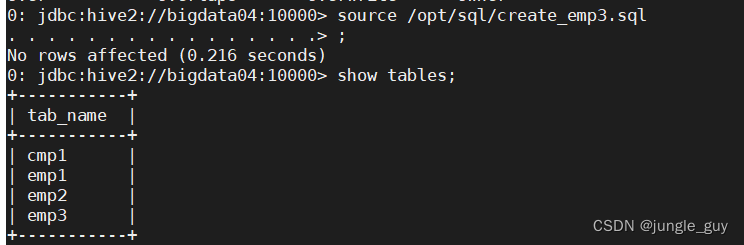
查看建表结构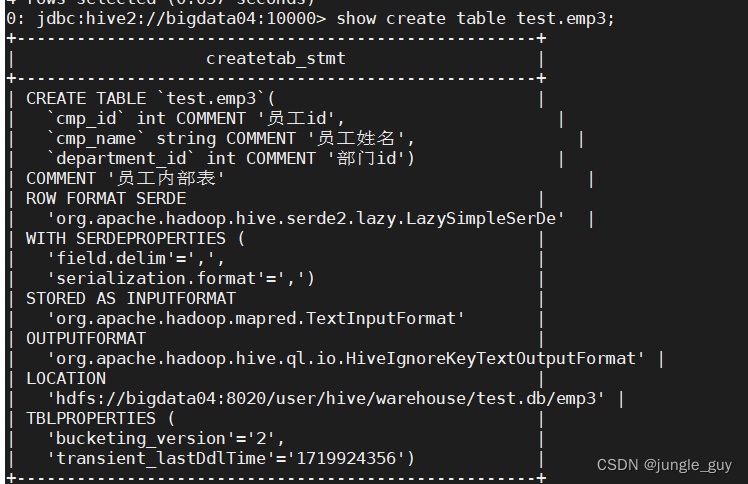
将emp2与刚刚创建的emp3对比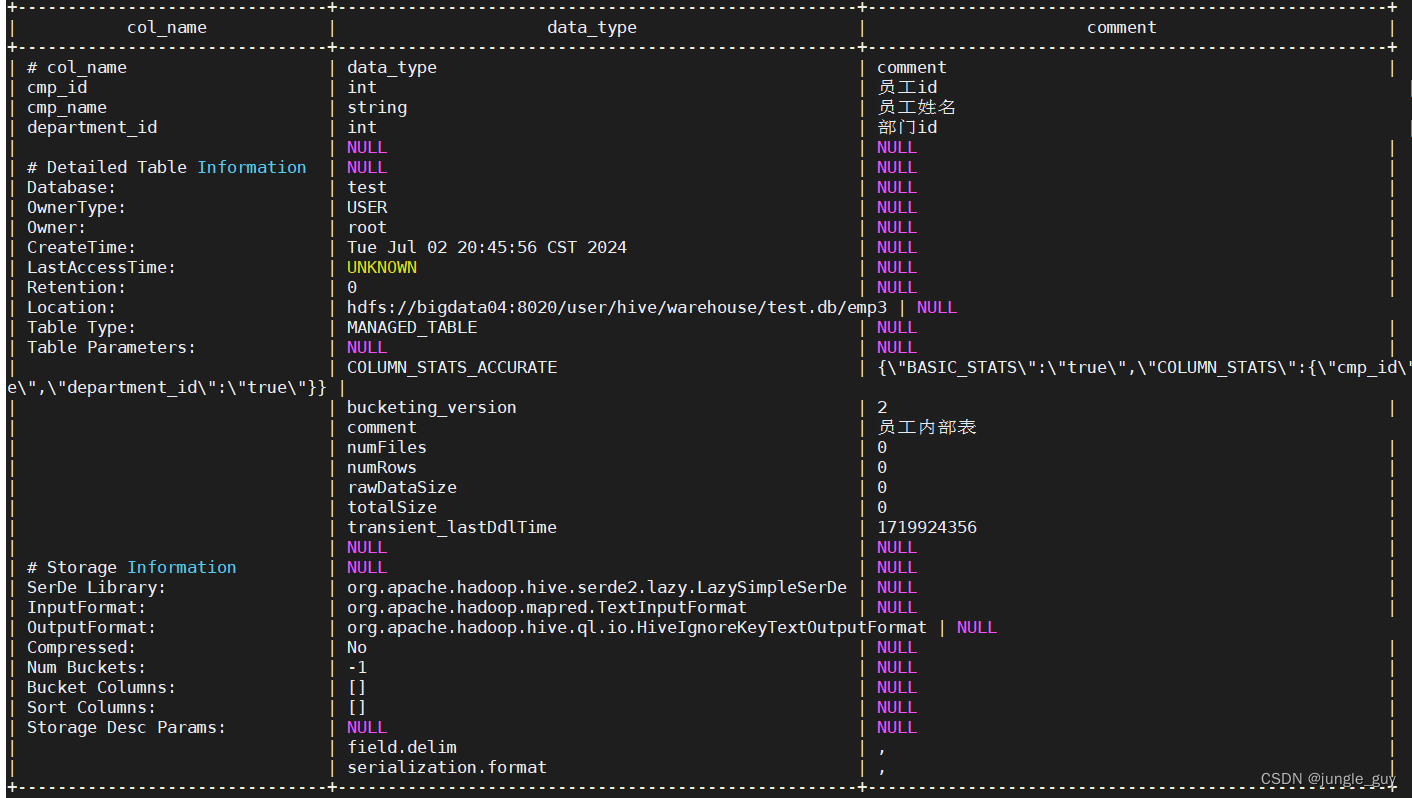
创建外部表
EXTERNAL关键字可以创建一个外部表,在建表的同时指定一个实际数据的路径(LOCATION)
,hive在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据
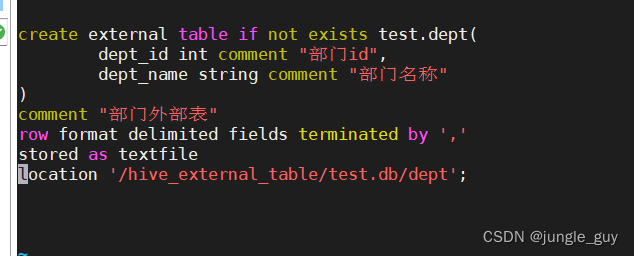
--创建部门外部表deptcreate external tableifnotexists test.dept(
dept_id intcomment"部门id",
dept_name string comment"部门名称")comment"部门外部表"row format delimited fieldsterminatedby','
stored as textfile
location '/hive_external_table/test.db/dept';
检查创建结果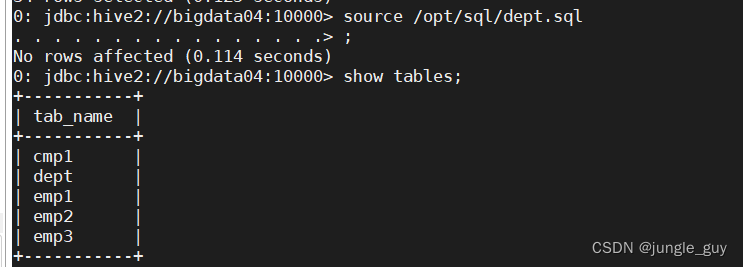
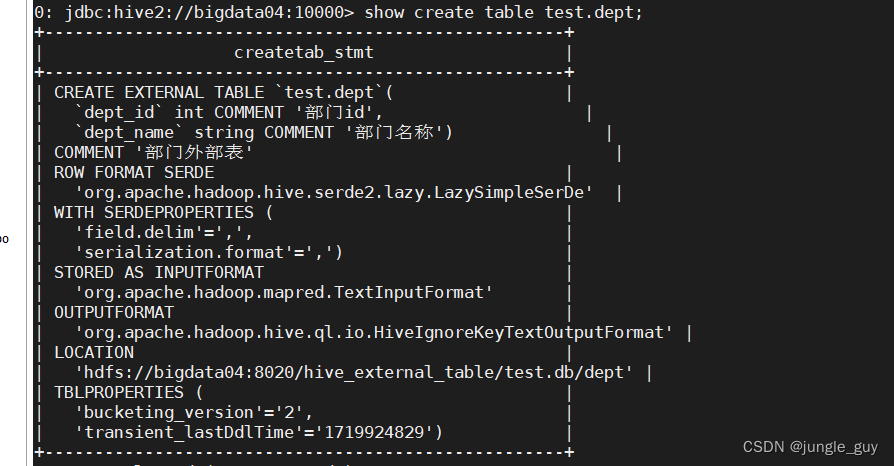
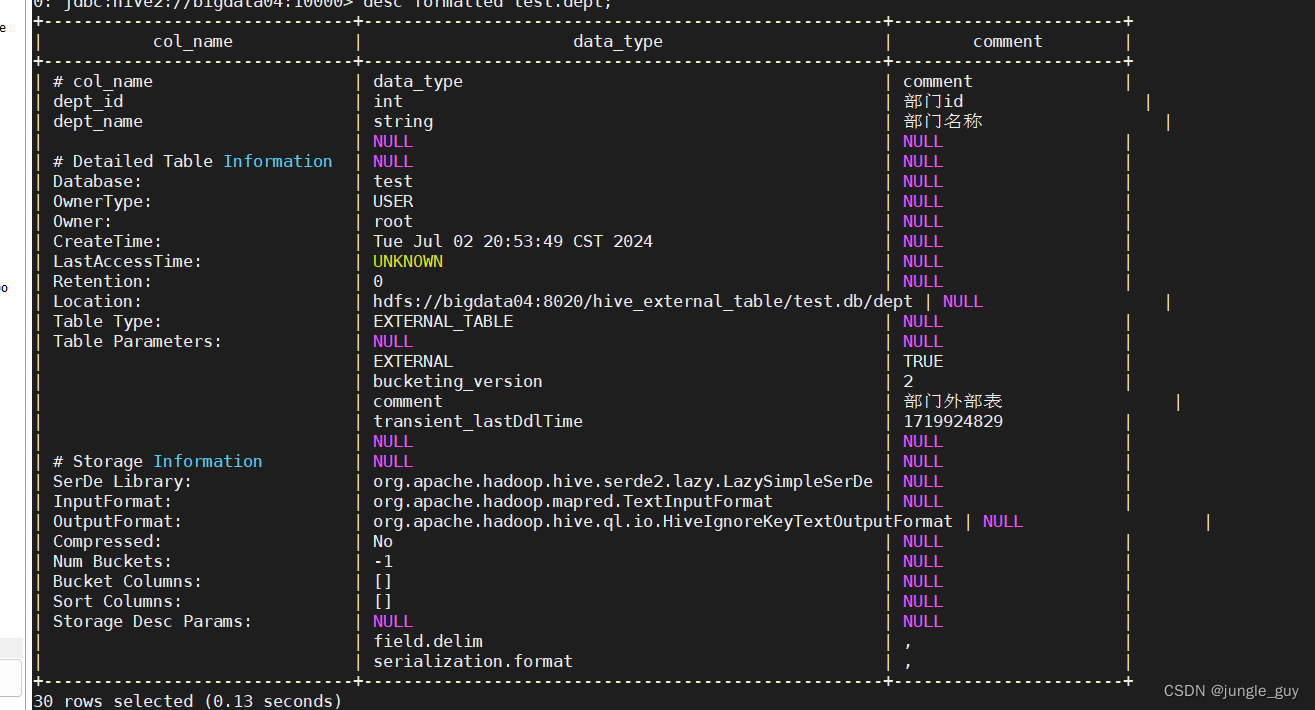
可以看到,外部表在HDFS上专门创建了一个目录来存放数据
创建带有分区参数的静态表
如下,使用了partitioned by指定了年月日作为分区参数
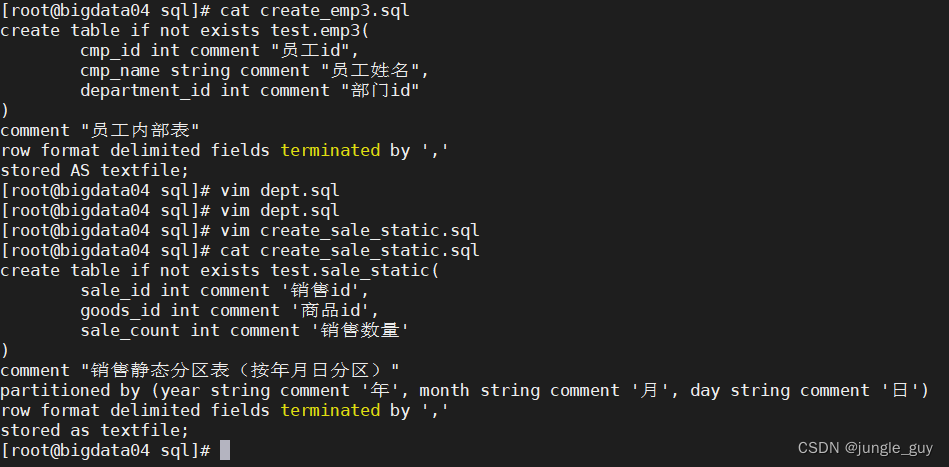
--分区表createtableifnotexists test.sale_static(
sale_id intcomment'销售id',
goods_id intcomment'商品id',
sale_count intcomment'销售数量')comment"销售静态分区表(按年月日分区)"
partitioned by(year string comment'年',month string comment'月',day string comment'日')row format delimited fieldsterminatedby','
stored as textfile;
检查结果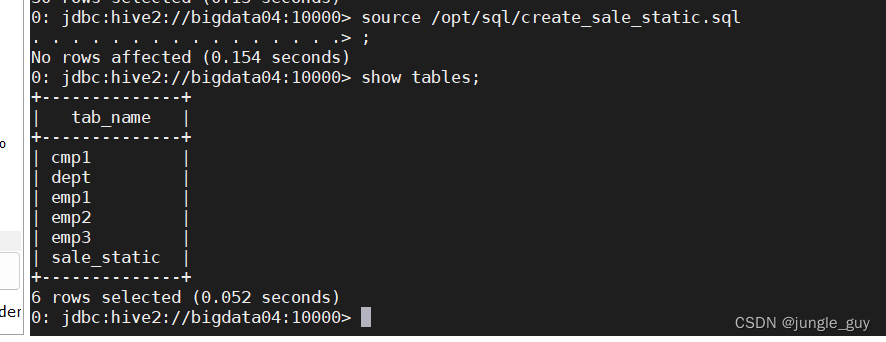
向Hive表中导入数据
向带有分区参数的静态表导入数据
向虚拟机中导入txt格式的数据
load data local inpath '/opt/file/init_sale_static_data.txt' into table test.sale_static partition(year='2024',month='07',day='02');

查看结果
可以看到,由于sale_static是静态分区表,所以在对于的目录下,已经生成了对应的数据
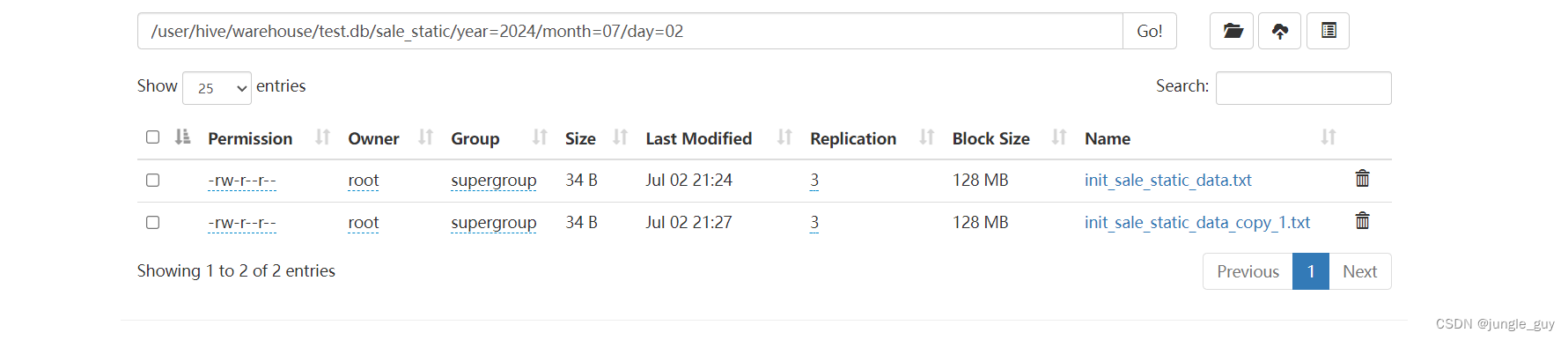
多次导入,出现重复字段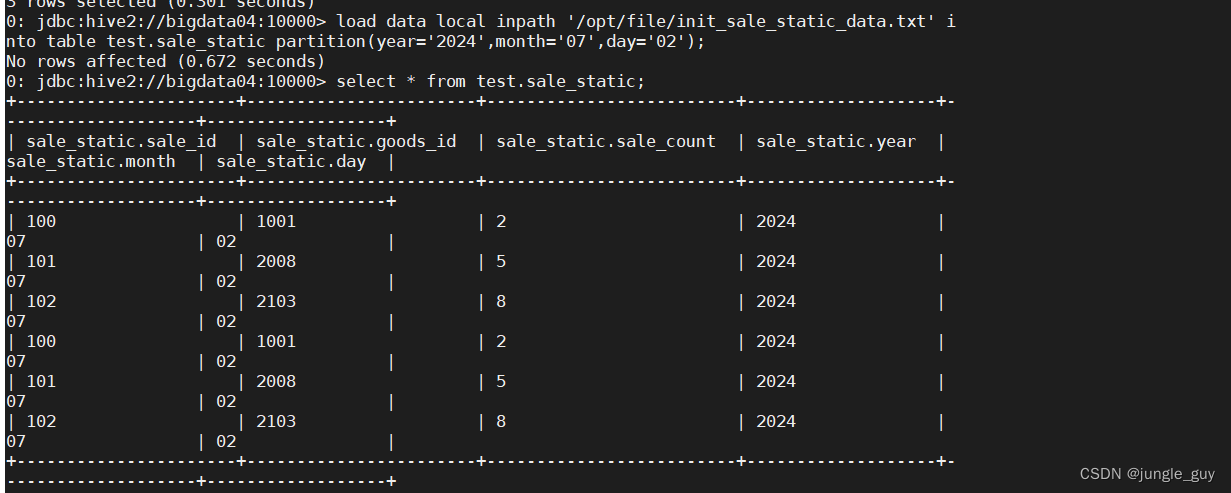
当加入overwrite参数时,会进行覆写
load data local inpath '/opt/file/init_sale_static_data.txt' overwrite into table test.sale_static partition(year='2024',month='07',day='01');
将year=‘2024’,month=‘07’,day='01’这一分区的数据进行覆写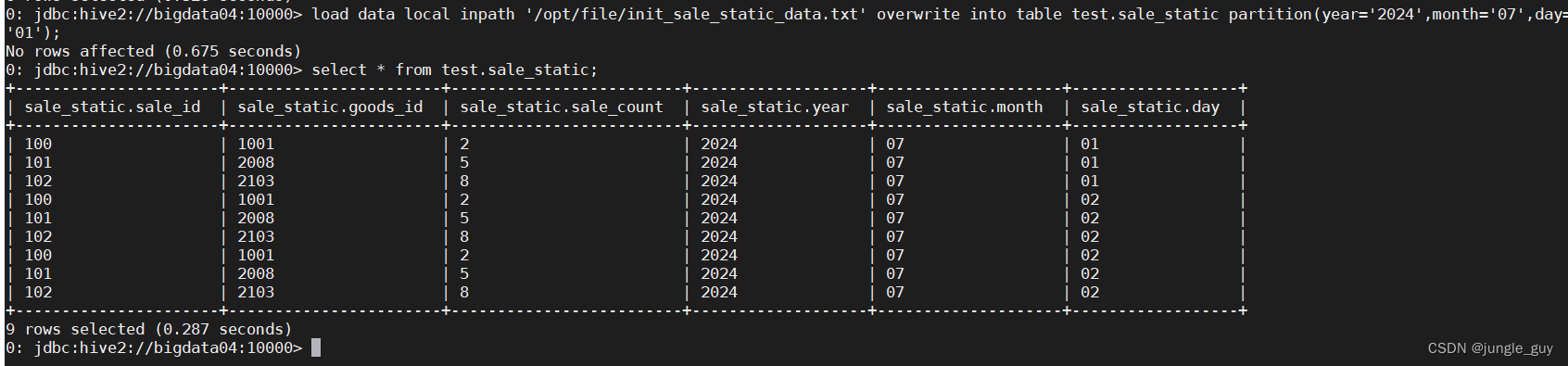

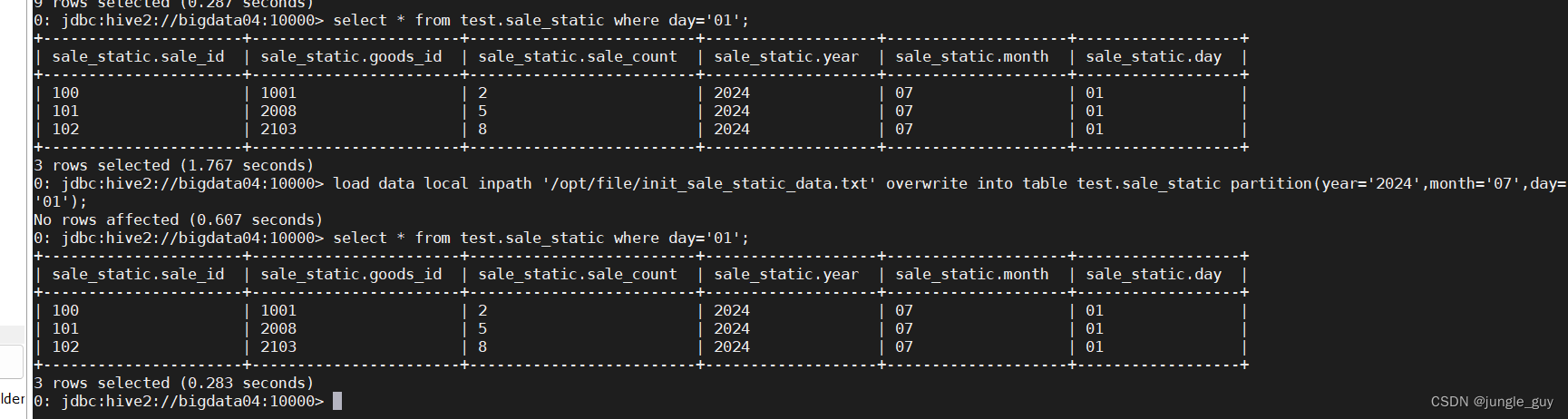
向含有参数的动态分区表插入数据
要向动态分区表插入数据,只能先将数据导入到一个前置表中,通过这个前置表向动态表插入数据
先创建动态表
createtableifnotexists test.sale_dynamic(
sale_id intcomment'销售id',
goods_id intcomment'商品id',
sale_count intcomment'销售数量')comment"销售动态分区表(按年月日分区)"
partitioned by(year string comment'年',month string comment'月',day string comment'日')row format delimited fieldsterminatedby','
stored as textfile;
创建用于数据中转的前置表
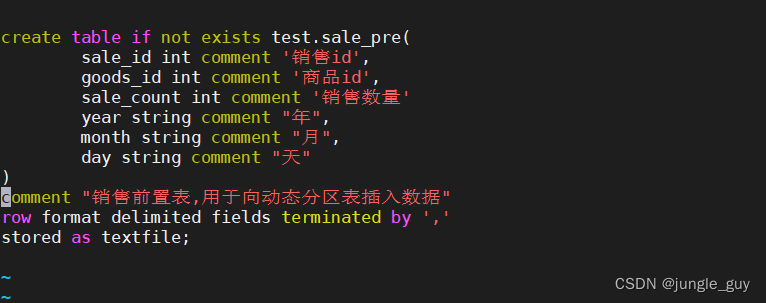
createtableifnotexists test.sale_pre(
sale_id intcomment'销售id',
goods_id intcomment'商品id',
sale_count intcomment'销售数量'year string comment"年",month string comment"月",day string comment"天")comment"销售前置表,用于向动态分区表插入数据"
partitioned by(year string comment'年',month string comment'月',day string comment'日')row format delimited fieldsterminatedby','
stored as textfile;
检查创建结果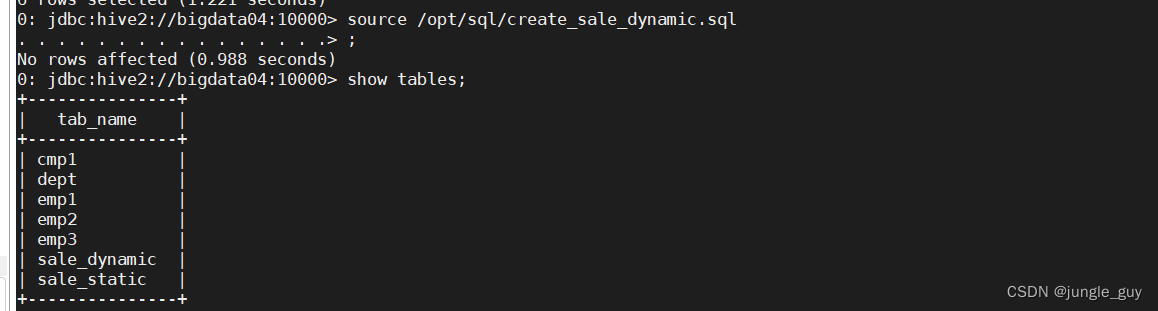
向前置表导入数据
load data local inpath '/opt/file/init_sale_pre_data.txt' overwrite into table test.sale_pre;
检查操作结果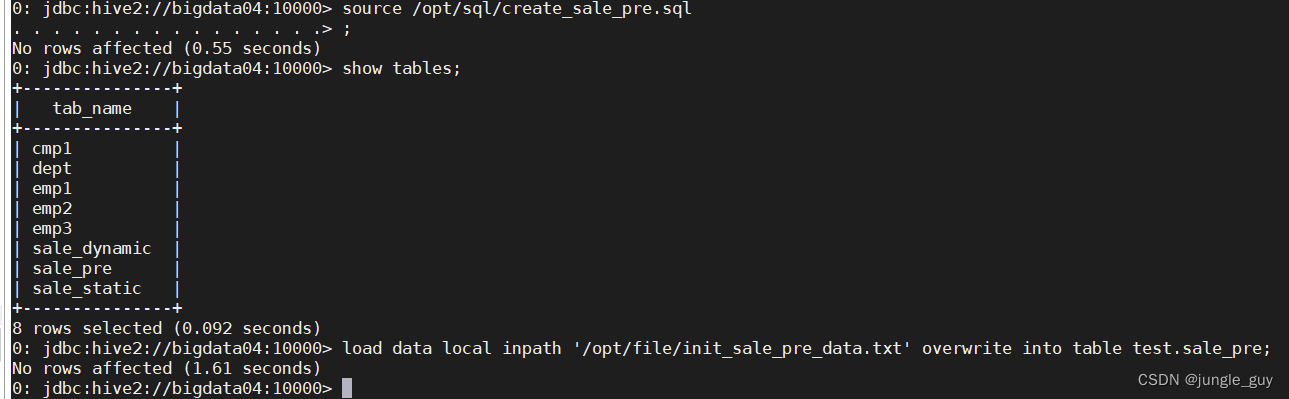

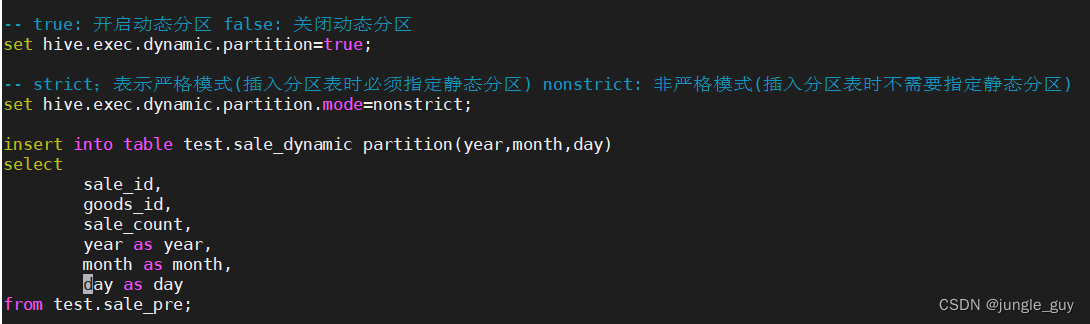
插入数据,sql语句很长,创建sql文件执行
-- true: 开启动态分区 false: 关闭动态分区set hive.exec.dynamic.partition=true;-- strict;表示严格模式(插入分区表时必须指定静态分区) nonstrict: 非严格模式(插入分区表时不需要指定静态分区)set hive.exec.dynamic.partition.mode=nonstrict;insertintotable test.sale_dynamic partition(year,month,day)select
sale_id,
goods_id,
sale_count,yearasyear,monthasmonth,dayasday,from test.sale_pre;
执行,在yarn中产生事物记录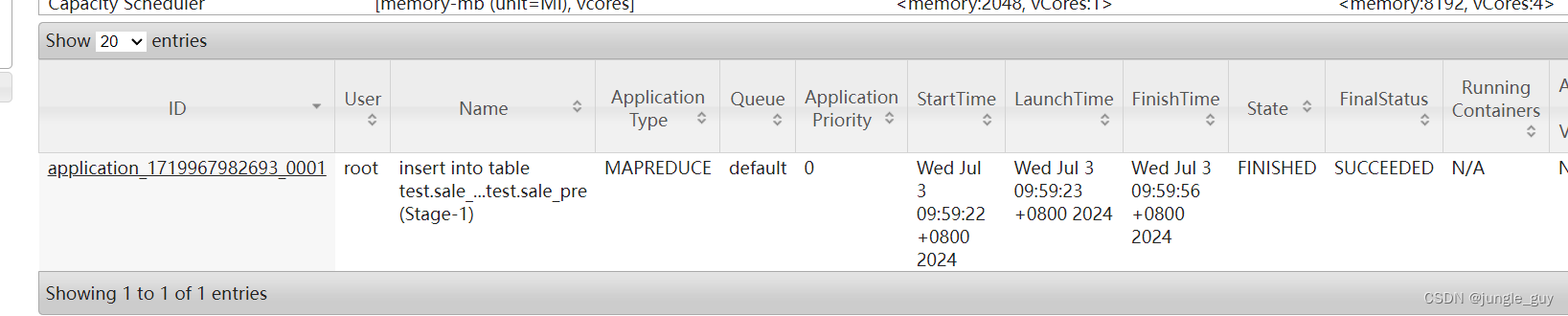
HDFS的对应分区也产生了数据文件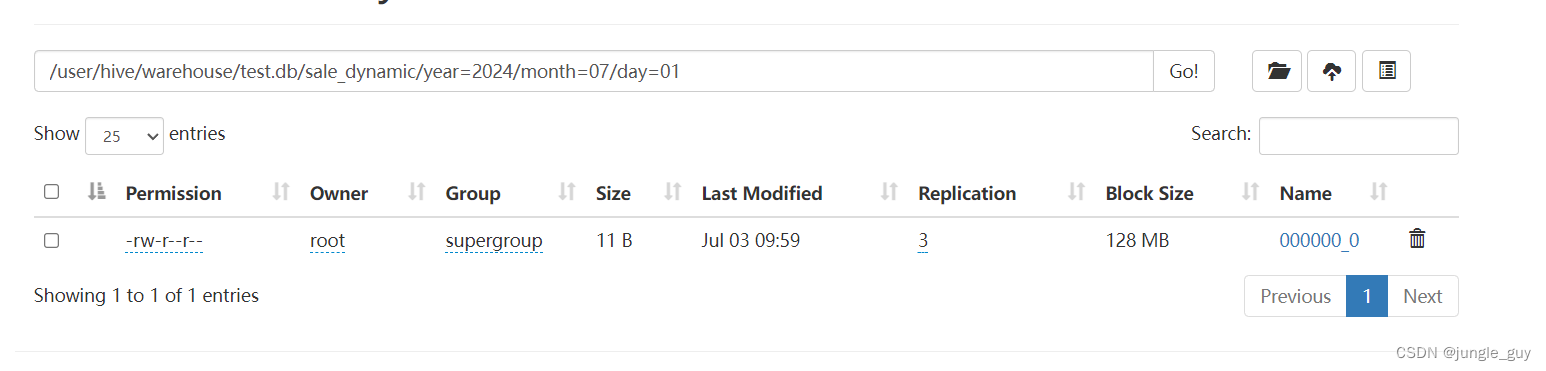
查询sale_dynamic表,数据已经成功导入
向不含参数的静态表导入数据
比起以上两种数据导入,其sql语句要简单一点
可以直接通过上传文件的形式,将符合表结果的数据文件上传至对应的HDFS目录下即可


查询数据,导入成功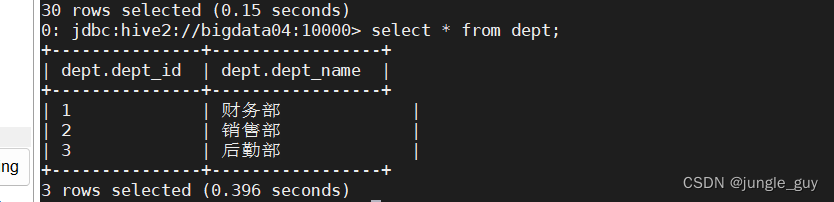
创建学生创建数据库
数据库与表的构建脚本
-- 将对应的命令写在每个步骤中-- 1.在hive中创建数据库schoolcreatedatabaseifnotexists school;-- 2.在数据库school中创建如下的表 每张表的列分隔符都是, 存储格式是textfile-- 创建表名为student_info,-- 字段为stu_id 类型为string,注释为学生id-- 字段为stu_name 类型为string,注释为学生姓名-- 字段为birthday 类型为string,注释为出生日期-- 字段为sex 类型为string,注释为性别createtableifnotexists school.student_info(
stu_id string comment"学生id",
stu_name string comment"学生姓名",
birthday string comment"出生日期",
sex string comment"性别")comment"学生信息表"row format delimited fieldsterminatedby','
stored AS textfile;--创建表名为course_info,--字段为course_id 类型为string,注释为课程id--字段为course_name 类型为string,注释为课程名--字段为tea_id 类型为string,注释为教师idcreatetableifnotexists school.course_info(
course_id string comment"课程id",
course_name string comment"课程名",
tea_id string comment"教师id")comment"课程信息表"row format delimited fieldsterminatedby','
stored AS textfile;--创建表名为teacher_info,--字段为tea_id 类型为string,注释为教师id--字段为tea_name 类型为string,注释为教师姓名createtableifnotexists school.teacher_info(
tea_id string comment"教师id",
tea_name string comment"教师姓名")comment"教师信息表"row format delimited fieldsterminatedby','
stored AS textfile;--创建表名为score_info,--字段为stu_id 类型为string,注释为学生id--字段为course_id 类型为string,注释为课程id--字段为score 类型为int,注释为成绩createtableifnotexists school.score_info(
stu_id string comment"课程id",
sourse_id string comment"课程名",
score string comment"成绩")comment"成绩信息表"row format delimited fieldsterminatedby','
stored AS textfile;-- 3. 将对应的数据文件加载到对应的表中loaddatalocal inpath '/opt/file/student_info.txt' overwrite intotable school.student_info;loaddatalocal inpath '/opt/file/course_info.txt' overwrite intotable school.course_info;loaddatalocal inpath '/opt/file/teacher_info.txt' overwrite intotable school.teacher_info;loaddatalocal inpath '/opt/file/score_info.txt' overwrite intotable school.score_info;
创建成功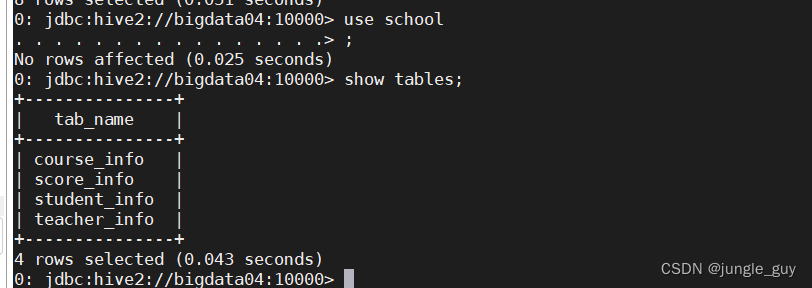
查询数据,也导入成功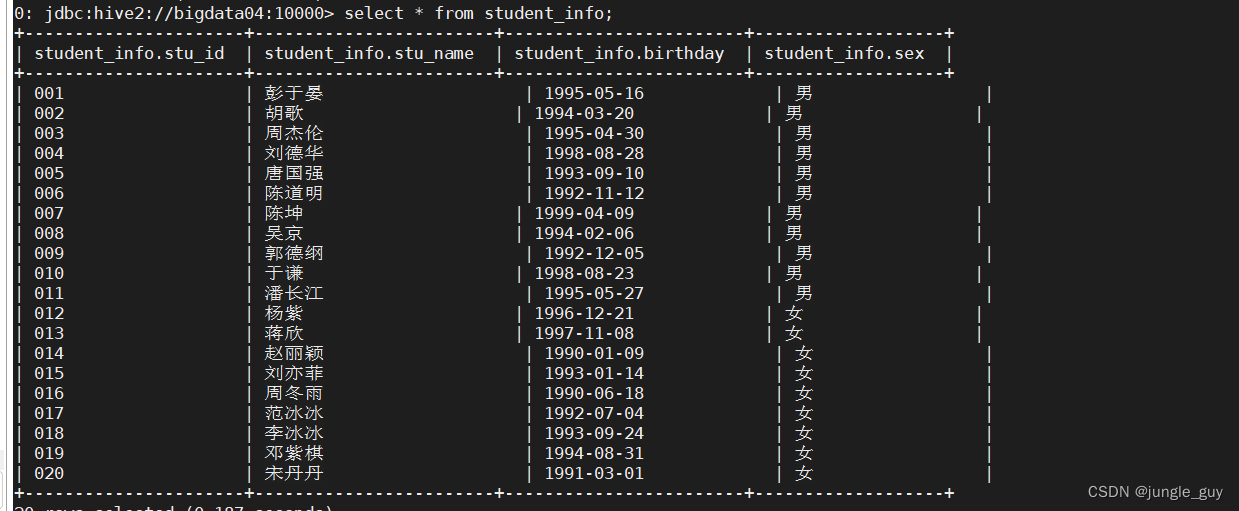
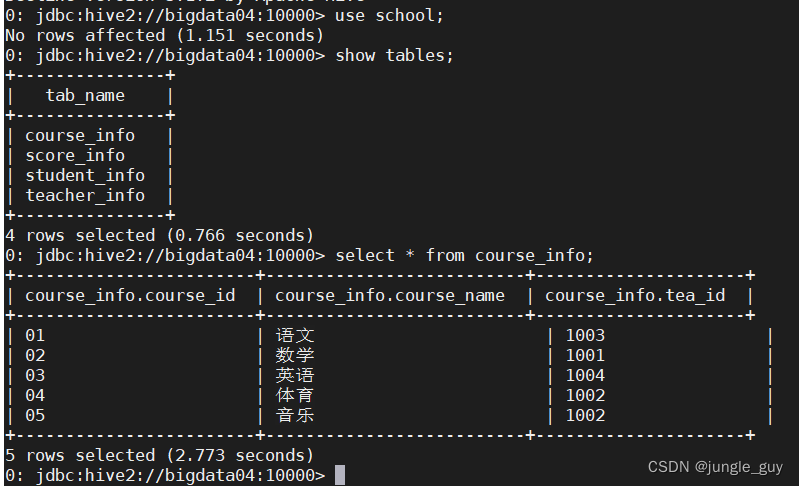
SQL的复杂查询
select*from course_info;
查询名字包含“冰”字的学生
select*from school.student_info where stu_name like'%冰%';

查询姓“周”的学生
select*from school.student_info where stu_name like'周%';

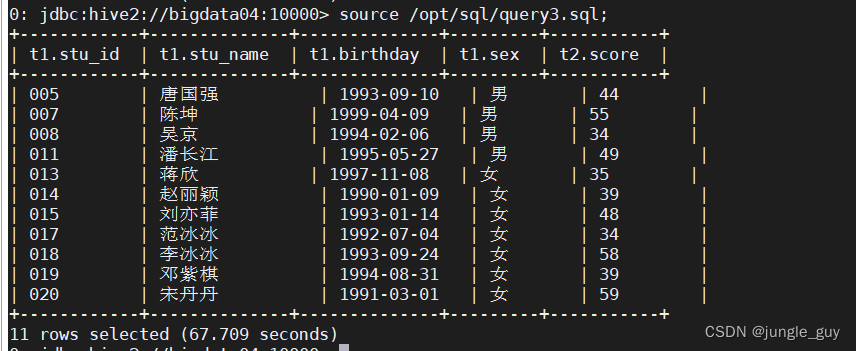
查询数学成绩小于60的学生信息
select
t1.*,t2.score
from
school.student_info t1
innerjoin(select
stu_id,score
from
school.score_info
where
course_id=(select
course_id
from
school.course_info
where
course_name='数学')) t2 on t1.stu_id = t2.stu_id
where
t2.score<60orderby
t1.stu_id;
查询课程号为“03”的总成绩
select course_id,sum(score)from school.score_info where course_id='03'groupby course_id;

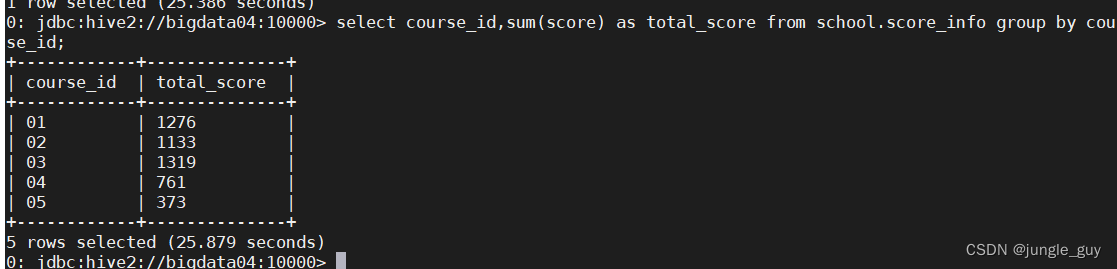
查询所有的课程的总成绩
select course_id,sum(score)as total_score from school.score_info groupby course_id;
查询有多少学生参与了考试
selectcount(distinct stu_id)as count from school.score_info;

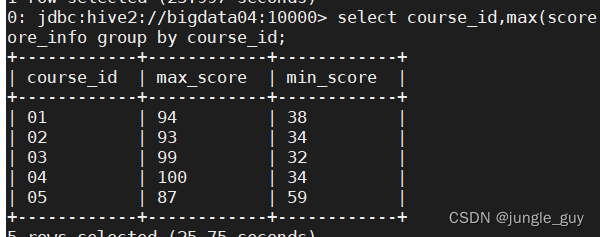
查询各科最高分最低分
select course_id,max(score)as max_score,min(score)as min_score from school.score_info groupby course_id;
查询各科平均分大于60的学生姓名
select t1.stu_name,t2.avg_score from school.student_info t1
innerjoin(select stu_id,avg(score)as avg_score from school.score_info groupby stu_id) t2
on t1.stu_id = t2.stu_id
where t2.avg_score >60;
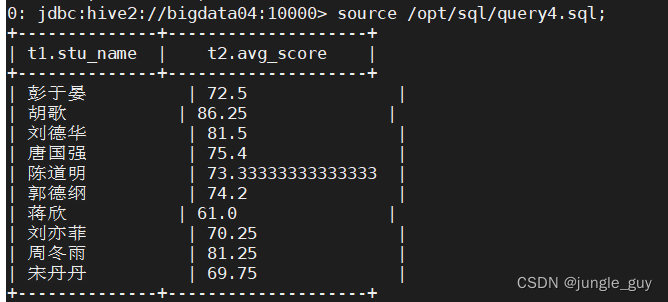
查询各科平均分大于60的学生id
select stu_id,avg(score)as avg_score from school.score_info groupby stu_id havingavg(score)>60;
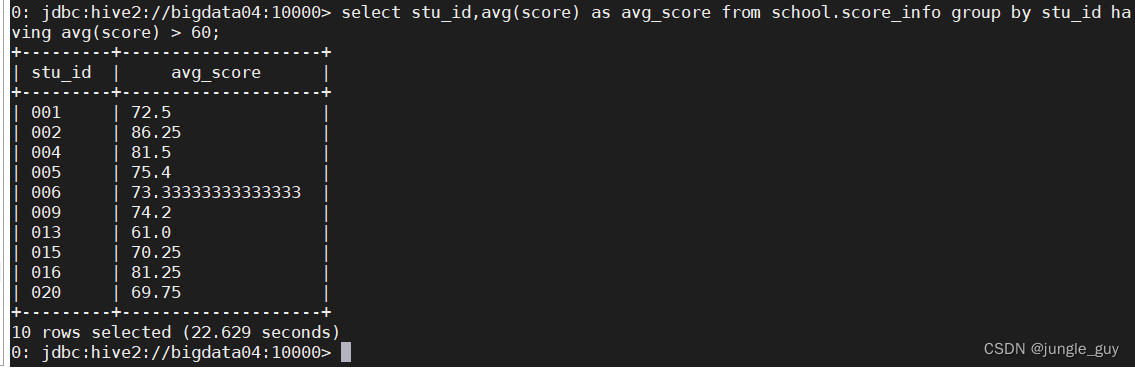
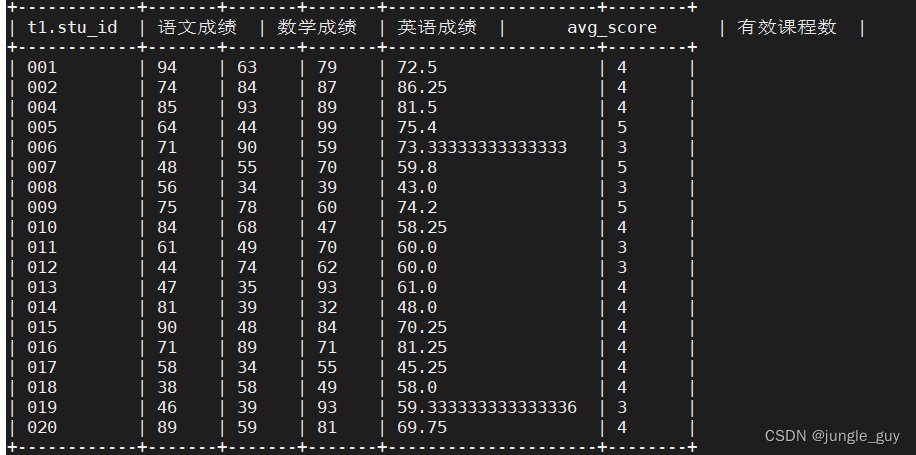
查询学生有效课程数
SELECT
t1.stu_id,sum(if(t2.course_name='语文',score,0))as`语文成绩`,sum(if(t2.course_name='数学',score,0))as`数学成绩`,sum(if(t2.course_name='英语',score,0))as`英语成绩`,avg(t1.score)as avg_score,count(*)as`有效课程数`FROM
score_info t1
INNERJOIN school.course_info t2 ON t1.course_id = t2.course_id
GROUPBY
stu_id;
版权归原作者 jungle_guy 所有, 如有侵权,请联系我们删除。