
未来数据库革新:AI与云原生的融合之旅

1. 智能数据库管理:AI的魔法
在数字化时代,数据库技术作为信息管理的核心,正经历着前所未有的变革。AI(人工智能)和云原生技术的融合,正在重新定义数据库的性能、可扩展性和智能化水平。本文将深入探讨这一融合之旅,分析AI如何赋能数据库管理,云原生如何成为新时代的引擎,以及全球化数据管理面临的新挑战与机遇。
1.1 AI在数据库优化中的角色:自动化索引、智能查询、异常侦测
在现代数据库管理中,AI技术的应用已经成为提升效率和性能的关键。本节将深入探讨AI在数据库优化中的三大核心角色:自动化索引、智能查询处理和异常侦测。
1.1.1 自动化索引
索引是数据库性能优化的基石,它通过减少数据检索的时间来提高查询效率。传统上,索引的创建和管理依赖于数据库管理员(DBA)的经验和手动操作,这不仅耗时,而且容易出错。AI技术的引入使得索引的自动化管理成为可能,极大地提升了效率和准确性。
自动化索引的核心在于使用机器学习算法来分析查询模式和数据访问频率,从而动态调整索引策略。例如,通过强化学习算法,数据库系统可以根据查询的响应时间和资源消耗来自动优化索引策略。数学模型可以表示为:
max
I
∑
t
=
0
T
γ
t
R
(
Q
t
,
I
t
)
\max_{I} \sum_{t=0}^{T} \gamma^t R(Q_t, I_t)
Imaxt=0∑TγtR(Qt,It)
其中,
I
t
I_t
It 是在时间
t
t
t 的索引策略,
Q
t
Q_t
Qt 是查询集合,
R
(
Q
t
,
I
t
)
R(Q_t, I_t)
R(Qt,It) 是使用索引策略
I
t
I_t
It 处理查询
Q
t
Q_t
Qt 的奖励(通常是查询响应时间),
γ
\gamma
γ 是折扣因子。
1.1.2 智能查询处理
智能查询处理是AI在数据库管理中的另一个重要应用。通过分析历史查询数据,AI系统可以预测特定查询的执行时间,并据此优化查询执行计划。这种优化不仅包括选择最佳的查询执行路径,还包括动态调整查询参数,如JOIN操作的顺序和类型。
数学上,这可以通过回归分析来实现,其中查询的执行时间被建模为查询特征的函数:
ExecutionTime
=
f
(
QueryFeatures
)
+
ϵ
\text{ExecutionTime} = f(\text{QueryFeatures}) + \epsilon
ExecutionTime=f(QueryFeatures)+ϵ
其中,
QueryFeatures
\text{QueryFeatures}
QueryFeatures 包括查询的复杂性、数据量等特征,
ϵ
\epsilon
ϵ 是误差项。通过最小化误差项,可以找到最优的查询执行策略。
1.1.3 异常侦测
异常侦测是AI在数据库安全管理中的关键应用。通过监控数据库操作模式,AI系统可以识别异常行为,如未授权的访问尝试或数据篡改。这些异常通常通过统计方法或机器学习模型来检测。
例如,使用高斯分布模型,可以检测到偏离正常操作模式的异常行为:
P
(
x
)
=
1
2
π
σ
2
e
−
(
x
−
μ
)
2
2
σ
2
P(x) = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}
P(x)=2πσ21e−2σ2(x−μ)2
如果某个操作的特征
x
x
x 的概率
P
(
x
)
P(x)
P(x) 低于某个阈值,则该操作被视为异常。
在实际应用中,异常侦测系统通常会结合多种算法和模型,以提高检测的准确性和效率。例如,除了高斯分布模型,还可以使用基于决策树或神经网络的异常检测算法。
通过上述分析,我们可以看到AI在数据库优化中的重要作用。自动化索引、智能查询处理和异常侦测不仅提高了数据库的性能和安全性,还极大地减轻了DBA的工作负担。随着AI技术的不断进步,其在数据库管理中的应用将更加广泛和深入。
1.2 机器学习在数据洞察中的应用:预测模型、模式发现、数据净化
在数据驱动的世界中,机器学习(ML)已成为解锁数据洞察的关键技术。通过预测模型、模式发现和数据净化,ML不仅提升了数据分析的深度和广度,还极大地增强了决策的准确性和效率。本节将深入探讨机器学习在这些领域的应用及其背后的数学原理。
1.2.1 预测模型
预测模型是机器学习在数据分析中最直接的应用之一。通过分析历史数据,预测模型可以预测未来的趋势和行为。例如,在金融领域,可以使用时间序列分析来预测股票价格的变动。
数学上,时间序列预测通常使用自回归积分滑动平均(ARIMA)模型,其公式可以表示为:
X
t
=
c
+
∑
i
=
1
p
ϕ
i
X
t
−
i
+
∑
j
=
1
q
θ
j
ϵ
t
−
j
+
ϵ
t
X_t = c + \sum_{i=1}^{p} \phi_i X_{t-i} + \sum_{j=1}^{q} \theta_j \epsilon_{t-j} + \epsilon_t
Xt=c+i=1∑pϕiXt−i+j=1∑qθjϵt−j+ϵt
其中,
X
t
X_t
Xt 是时间
t
t
t 的观测值,
c
c
c 是常数,
ϕ
i
\phi_i
ϕi 和
θ
j
\theta_j
θj 是模型参数,
ϵ
t
\epsilon_t
ϵt 是误差项。通过调整参数
p
p
p 和
q
q
q,可以优化模型的预测能力。
1.2.2 模式发现
模式发现是机器学习在数据分析中的另一个重要应用。通过聚类分析、关联规则学习等技术,可以从大量数据中发现有价值的模式和关联。例如,在市场分析中,可以使用聚类算法将客户分为不同的群体,每个群体代表具有相似购买行为的客户。
K-means聚类算法是最常用的聚类方法之一,其数学表达为:
min
μ
1
,
…
,
μ
k
∑
i
=
1
n
min
1
≤
j
≤
k
∥
x
i
−
μ
j
∥
2
\min_{\mu_1, \ldots, \mu_k} \sum_{i=1}^n \min_{1 \leq j \leq k} \|x_i - \mu_j\|^2
μ1,…,μkmini=1∑n1≤j≤kmin∥xi−μj∥2
其中,
x
i
x_i
xi 是数据点,
μ
j
\mu_j
μj 是聚类中心,
k
k
k 是聚类的数量。通过迭代优化,算法将数据点分配到最近的聚类中心。
1.2.3 数据净化
数据净化是确保数据质量的关键步骤。机器学习可以帮助识别和纠正数据中的错误和不一致。例如,通过构建分类模型,可以自动检测和修复数据中的异常值。
分类模型通常使用逻辑回归或支持向量机(SVM),其数学表达为:
IsAnomaly
=
{
1
if
P
(
x
)
<
threshold
0
otherwise
\text{IsAnomaly} = \begin{cases} 1 & \text{if } P(x) < \text{threshold} \\ 0 & \text{otherwise} \end{cases}
IsAnomaly={10if P(x)<thresholdotherwise
其中,
P
(
x
)
P(x)
P(x) 是数据点
x
x
x 的概率,
threshold
\text{threshold}
threshold 是异常检测的阈值。通过调整阈值,可以控制异常检测的敏感度。
通过上述分析,我们可以看到机器学习在数据洞察中的强大作用。预测模型、模式发现和数据净化不仅提高了数据分析的效率和准确性,还为决策提供了坚实的数据支持。随着技术的不断进步,机器学习在数据管理中的应用将更加广泛和深入。
1.3 实时数据流的智能处理:技术与策略
在数字化时代,数据以流的形式不断产生,实时处理这些数据流成为提升业务响应速度和决策质量的关键。机器学习和人工智能技术在实时数据流处理中扮演着至关重要的角色,它们不仅能够快速分析数据,还能实时识别模式和异常,从而支持即时决策。本节将探讨实时数据流智能处理的技术和策略。
1.3.1 实时数据流处理技术
实时数据流处理技术主要包括流处理引擎和实时分析算法。流处理引擎如Apache Kafka和Apache Flink能够高效地收集和处理大量实时数据。实时分析算法则利用机器学习模型,如决策树、随机森林和神经网络,对数据流进行实时分析。
数学上,实时数据流处理可以看作是一个连续的数据处理过程,其中每个数据点都被即时处理。例如,使用滑动窗口技术,可以对最近的数据点进行分析:
WindowedSum
=
∑
i
=
t
−
w
+
1
t
x
i
\text{WindowedSum} = \sum_{i=t-w+1}^t x_i
WindowedSum=i=t−w+1∑txi
其中,
w
w
w 是窗口大小,
x
i
x_i
xi 是时间
i
i
i 的数据点。通过调整窗口大小,可以控制分析的粒度和实时性。
1.3.2 实时异常检测策略
实时异常检测是实时数据流处理中的一个重要应用。通过监控数据流,系统可以即时识别异常模式,如欺诈行为或系统故障。异常检测通常基于统计方法或机器学习模型,如高斯分布模型或基于密度的空间聚类(DBSCAN)。
高斯分布模型用于检测偏离正常模式的数据点:
P
(
x
)
=
1
2
π
σ
2
e
−
(
x
−
μ
)
2
2
σ
2
P(x) = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}
P(x)=2πσ21e−2σ2(x−μ)2
如果数据点
x
x
x 的概率
P
(
x
)
P(x)
P(x) 低于某个阈值,则该点被视为异常。
1.3.3 实时模式识别策略
实时模式识别是另一种重要的实时数据流处理策略。通过分析数据流,系统可以识别出有价值的模式,如用户行为模式或市场趋势。模式识别通常使用聚类算法或序列分析技术。
序列分析技术,如隐马尔可夫模型(HMM),可以用于识别时间序列数据中的模式:
P
(
X
)
=
∑
Y
P
(
X
∣
Y
)
P
(
Y
)
P(X) = \sum_Y P(X|Y) P(Y)
P(X)=Y∑P(X∣Y)P(Y)
其中,
X
X
X 是观测序列,
Y
Y
Y 是隐藏状态序列。通过训练模型参数,可以优化模式识别的准确性。
1.3.4 实时决策支持系统
实时决策支持系统结合了实时数据流处理和机器学习技术,为决策者提供即时数据分析结果。这些系统通常包括数据收集、实时分析和决策反馈三个主要组件。
例如,在金融交易中,实时决策支持系统可以分析市场数据流,即时识别交易机会,并自动执行交易。数学模型可以表示为:
Trade
=
{
1
if
P
(
Profit
)
>
threshold
0
otherwise
\text{Trade} = \begin{cases} 1 & \text{if } P(\text{Profit}) > \text{threshold} \\ 0 & \text{otherwise} \end{cases}
Trade={10if P(Profit)>thresholdotherwise
其中,
P
(
Profit
)
P(\text{Profit})
P(Profit) 是预测的盈利概率,
threshold
\text{threshold}
threshold 是决策阈值。
通过上述技术和策略,实时数据流的智能处理不仅提高了数据分析的效率,还增强了决策的实时性和准确性。随着技术的不断发展,实时数据流处理将继续在各个行业中发挥重要作用。
1.4 成功案例:AI如何助力企业通过数据库优化实现成本削减与效率提升
在数字化转型的浪潮中,人工智能(AI)已成为企业提升数据库管理效率和降低成本的强大工具。通过自动化索引、智能查询处理和实时数据分析,AI不仅优化了数据库性能,还显著提高了业务决策的速度和质量。本节将通过几个具体案例,展示AI如何助力企业在数据库优化方面取得显著成效。
1.4.1 自动化索引优化的案例
一家大型电商公司面临数据库查询响应时间过长的问题,严重影响了用户体验和销售业绩。通过引入AI驱动的自动化索引优化工具,该公司能够实时分析查询模式和数据访问频率,动态调整索引策略。
数学模型上,自动化索引优化可以表示为:
min
I
∑
Q
ResponseTime
(
Q
,
I
)
\min_{I} \sum_{Q} \text{ResponseTime}(Q, I)
IminQ∑ResponseTime(Q,I)
其中,
I
I
I 是索引策略,
Q
Q
Q 是查询集合,
ResponseTime
(
Q
,
I
)
\text{ResponseTime}(Q, I)
ResponseTime(Q,I) 是使用索引策略
I
I
I 处理查询
Q
Q
Q 的响应时间。通过机器学习算法,系统能够自动找到最优的索引配置,显著减少了查询响应时间,提升了用户体验。
1.4.2 智能查询处理的案例
一家金融服务公司需要处理大量复杂的金融数据查询。通过部署AI驱动的智能查询处理系统,该公司能够预测查询执行时间,并据此优化查询执行计划。
智能查询处理的数学模型可以表示为:
ExecutionTime
=
f
(
QueryComplexity
,
DataSize
)
+
ϵ
\text{ExecutionTime} = f(\text{QueryComplexity}, \text{DataSize}) + \epsilon
ExecutionTime=f(QueryComplexity,DataSize)+ϵ
其中,
QueryComplexity
\text{QueryComplexity}
QueryComplexity 和
DataSize
\text{DataSize}
DataSize 是查询的复杂性和数据量,
ϵ
\epsilon
ϵ 是误差项。通过回归分析,系统能够预测查询的执行时间,并选择最佳的查询执行路径,从而大幅提高了查询处理效率。
1.4.3 实时数据流分析的案例
一家社交媒体公司需要实时分析用户行为数据,以优化内容推荐和广告投放。通过实施AI驱动的实时数据流分析系统,该公司能够即时识别用户行为模式,并据此调整推荐算法。
实时数据流分析的数学模型可以表示为:
UserEngagement
=
g
(
UserBehaviorData
)
+
ϵ
\text{UserEngagement} = g(\text{UserBehaviorData}) + \epsilon
UserEngagement=g(UserBehaviorData)+ϵ
其中,
UserBehaviorData
\text{UserBehaviorData}
UserBehaviorData 是用户行为数据,
ϵ
\epsilon
ϵ 是误差项。通过实时分析用户行为数据,系统能够即时调整内容推荐策略,显著提高了用户参与度和广告收入。
通过上述案例,我们可以看到AI在数据库优化中的巨大潜力。自动化索引、智能查询处理和实时数据流分析不仅提高了数据库的性能和效率,还为企业带来了显著的成本节约和业务增长。随着AI技术的不断进步,其在数据库管理中的应用将更加广泛和深入。
1.5 实战代码与案例剖析:AI工具优化数据库的实际操作
在数据库管理领域,AI工具的应用已成为提升效率和性能的关键。本节将深入探讨如何通过实际代码和案例分析,利用AI工具优化数据库操作。我们将从自动化索引、智能查询优化、异常检测和数据净化四个方面进行详细阐述。
1.5.1 自动化索引优化
自动化索引优化是提高数据库查询性能的重要手段。通过AI算法,可以动态分析查询模式并自动调整索引策略。以下是一个简化的Python代码示例,使用机器学习模型来预测索引需求:
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# 假设df是包含查询历史的数据框
df = pd.read_csv('query_history.csv')# 特征工程:提取查询特征
df['feature1']= df['query'].apply(lambda x:len(x))
df['feature2']= df['result_size']/ df['execution_time']# 使用随机森林分类器预测是否需要索引
model = RandomForestClassifier()
model.fit(df[['feature1','feature2']], df['needs_index'])# 预测新查询的索引需求
new_query ={'feature1':100,'feature2':5}
prediction = model.predict([list(new_query.values())])if prediction ==1:print("需要创建索引")else:print("不需要创建索引")
在这个例子中,我们使用查询的长度和结果大小与执行时间的比率作为特征,通过随机森林分类器预测是否需要为新查询创建索引。
1.5.2 智能查询优化
智能查询优化涉及使用AI算法来分析查询执行计划,并提出优化建议。以下是一个使用成本模型来优化查询的示例:
-- 假设我们有一个查询优化器,它可以根据查询成本模型提出优化建议EXPLAINANALYZESELECT*FROM orders WHERE customer_id =1000;-- 优化器可能会建议创建一个索引来加速查询CREATEINDEX idx_customer_id ON orders(customer_id);-- 再次执行查询以验证性能提升EXPLAINANALYZESELECT*FROM orders WHERE customer_id =1000;
在这个SQL示例中,我们首先分析查询的执行计划,然后根据优化器的建议创建索引,最后再次分析以验证性能提升。
1.5.3 异常检测
异常检测在数据库管理中用于识别和处理异常行为,如数据输入错误或恶意攻击。以下是一个使用统计方法进行异常检测的Python代码示例:
import numpy as np
# 假设data是包含数据点的数组
data = np.array([1,2,3,4,5,100])# 计算平均值和标准差
mean = np.mean(data)
std_dev = np.std(data)# 定义异常检测阈值
threshold =2* std_dev
# 检测异常点
outliers = data[np.abs(data - mean)> threshold]print("异常点:", outliers)
在这个例子中,我们计算数据的平均值和标准差,然后使用这些统计量来检测偏离正常范围的异常点。
1.5.4 数据净化
数据净化是确保数据质量的关键步骤。AI工具可以帮助自动识别和修复数据中的错误。以下是一个使用规则引擎进行数据净化的示例:
# 假设我们有一个包含错误数据的数据框df
df = pd.DataFrame({'age':[25,30,150,20],'salary':[50000,60000,70000,80000]})# 定义规则:如果年龄大于100,则将其设置为NaN
df['age']= df['age'].apply(lambda x: np.nan if x >100else x)print(df)
在这个例子中,我们定义了一个简单的规则来识别年龄字段中的异常值,并将其设置为NaN,以便进一步处理。
通过上述实战代码和案例剖析,我们可以看到AI工具在数据库优化中的实际应用和效果。这些工具不仅提高了数据库的性能和效率,还帮助企业节省了大量成本和时间。随着AI技术的不断发展,其在数据库管理中的应用将更加广泛和深入。
1.6 效果可视化:AI优化成果的直观展示
在数据库管理中,AI的应用不仅提升了效率和性能,还带来了显著的成本节约。然而,这些成果往往需要通过直观的方式展示,以便决策者和团队成员能够快速理解和评估。本节将探讨如何通过可视化技术,展示AI在数据库优化中的成果。
1.6.1 性能提升的可视化
性能提升是AI优化数据库最直接的效果之一。通过图表和仪表盘,可以直观地展示查询响应时间、吞吐量和资源利用率的变化。例如,使用折线图来展示优化前后查询响应时间的变化:
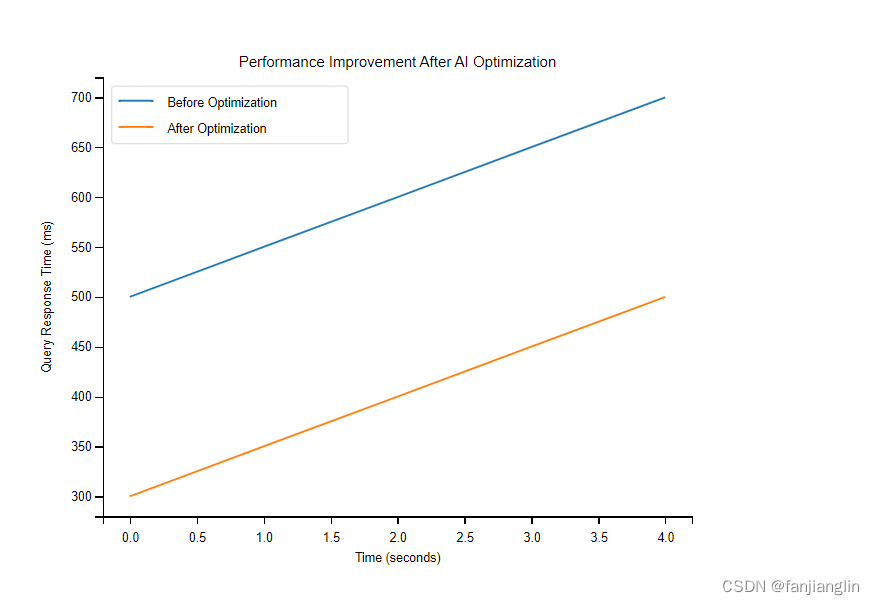
在这个图中,横轴代表时间,纵轴代表查询响应时间。通过对比优化前后的数据点,可以清晰地看到AI优化带来的性能提升。
1.6.2 成本节约的可视化
成本节约是企业采用AI优化数据库的另一个重要考量。通过柱状图或饼图,可以展示优化前后硬件资源、能源消耗和维护成本的变化。例如,使用柱状图来展示优化前后的成本对比:
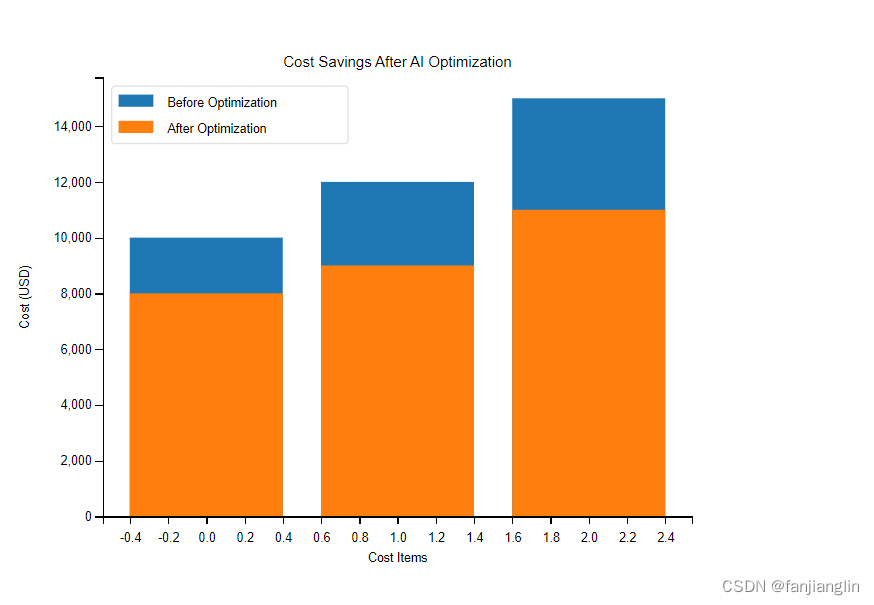
在这个图中,横轴代表不同的成本项目,纵轴代表成本金额。通过对比优化前后的柱状高度,可以直观地看到成本节约的效果。
1.6.3 异常检测和数据净化的可视化
异常检测和数据净化是AI在数据库管理中的重要应用。通过热力图或散点图,可以展示异常数据点和净化效果。例如,使用热力图来展示异常检测的结果:
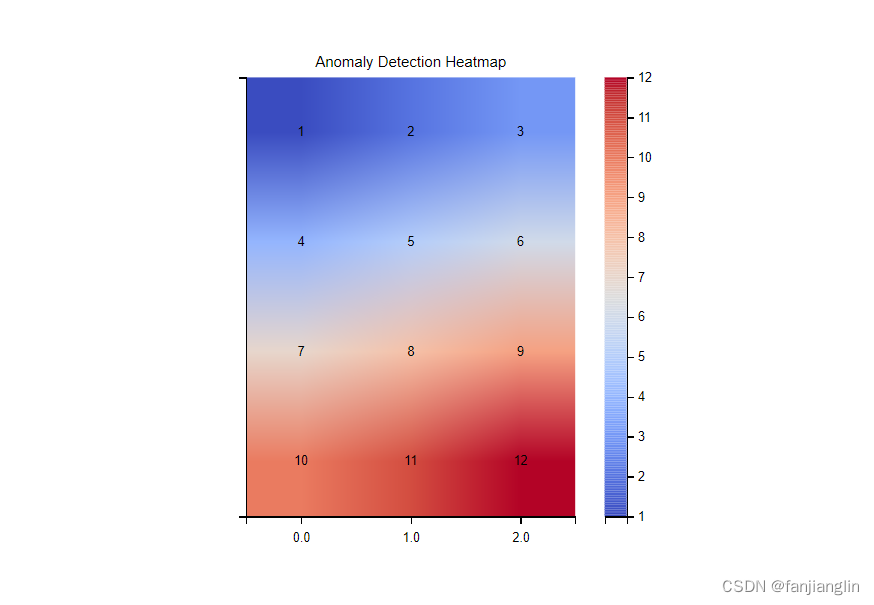
在这个图中,颜色深浅代表异常程度,通过颜色的变化可以直观地看到异常数据点的分布。
1.6.4 实时数据流处理的可视化
实时数据流处理是AI优化数据库的另一个关键领域。通过实时更新的仪表盘,可以展示数据流的处理速度、实时分析结果和决策支持信息。例如,使用实时仪表盘来展示数据流处理的状态:
在这个仪表盘上,可以实时看到数据流的处理进度、分析结果和系统状态,帮助团队快速响应和决策。
通过上述可视化技术,AI优化数据库的成果得以直观展示,不仅增强了决策的信心,还促进了团队之间的沟通和协作。随着技术的进步,可视化工具将更加强大和灵活,为数据库管理带来更多的便利和效率。

2. 云原生数据库:新时代的引擎
2.1 云原生数据库的核心优势:弹性、可用性、自动化
云原生数据库作为现代数据管理的新引擎,其核心优势在于提供了前所未有的弹性、可用性和自动化能力。这些特性不仅极大地提升了数据库的性能和可靠性,还为企业带来了灵活性和成本效益。本节将深入探讨这些核心优势,并通过具体的例子和数学模型来解释其背后的原理。
2.1.1 弹性(Elasticity)
弹性是云原生数据库最显著的特性之一,它允许数据库根据实际需求动态调整资源。这种能力在处理突发流量或季节性数据高峰时尤为重要。例如,一个电商平台在“黑色星期五”期间可能会遇到比平时多出数倍的访问量,云原生数据库可以自动扩展以应对这种流量激增。
数学上,弹性可以通过资源分配的优化模型来描述。假设我们有一个资源分配问题,目标是最大化性能(P),同时满足成本(C)和延迟(L)的约束:
max
x
P
(
x
)
\max_{x} P(x)
xmaxP(x)
s.t.
C
(
x
)
≤
C
m
a
x
\text{s.t.} \quad C(x) \leq C_{max}
s.t.C(x)≤Cmax
L
(
x
)
≤
L
m
a
x
L(x) \leq L_{max}
L(x)≤Lmax
其中,
x
x
x 是资源分配的决策变量,
P
(
x
)
P(x)
P(x) 是性能函数,
C
(
x
)
C(x)
C(x) 和
L
(
x
)
L(x)
L(x) 分别是成本和延迟函数。通过优化这个模型,可以实现资源的最优分配,从而达到弹性的目的。
2.1.2 可用性(Availability)
高可用性是云原生数据库的另一个关键优势。通过分布式架构和数据复制技术,云原生数据库能够在硬件故障或网络问题发生时保持服务的连续性。例如,Google Cloud的Cloud Spanner提供了99.999%的可用性保证,这意味着每年的停机时间不超过5分钟。
可用性通常可以通过系统可靠性模型来量化。例如,假设一个系统由n个组件组成,每个组件的可靠性为
R
i
R_i
Ri,则系统的整体可靠性
R
s
y
s
R_{sys}
Rsys可以通过乘积规则计算:
R
s
y
s
=
∏
i
=
1
n
R
i
R_{sys} = \prod_{i=1}^{n} R_i
Rsys=i=1∏nRi
通过提高单个组件的可靠性或增加冗余组件,可以提高系统的整体可用性。
2.1.3 自动化(Automation)
自动化是云原生数据库的第三个核心优势。通过自动化工具和机器学习算法,云原生数据库可以自动执行诸如备份、恢复、扩展和优化等任务。这种自动化不仅减少了人工干预的需要,还提高了操作的准确性和效率。
自动化可以通过决策树或强化学习等算法来实现。例如,一个自动化扩展系统可能会使用强化学习来学习在不同负载条件下的最佳扩展策略。数学上,强化学习可以表示为一个马尔可夫决策过程(MDP):
max
π
E
π
[
∑
t
=
0
∞
γ
t
r
t
]
\max_{\pi} \mathbb{E}_{\pi} \left[ \sum_{t=0}^{\infty} \gamma^t r_t \right]
πmaxEπ[t=0∑∞γtrt]
其中,
π
\pi
π 是策略,
r
t
r_t
rt 是时间
t
t
t的奖励,
γ
\gamma
γ 是折扣因子。通过优化这个目标函数,可以学习到最优的自动化策略。
2.1.4 小结
云原生数据库的弹性、可用性和自动化特性为企业提供了强大的数据管理能力。通过深入理解这些特性的数学基础和实现机制,企业可以更有效地利用云原生数据库来支持其业务需求。随着技术的不断进步,云原生数据库将继续演化,为企业带来更多的创新和价值。
2.2 云服务巨头的解决方案:AWS、Azure、Google Cloud
在云原生数据库的领域中,三大云服务提供商——亚马逊网络服务(AWS)、微软Azure和谷歌云平台(Google Cloud)——提供了各自独特的解决方案,这些方案不仅体现了云原生数据库的核心优势,还展示了各自的技术特色和市场定位。本节将深入探讨这些解决方案的特点,并通过具体的案例和数学模型来解释其背后的原理。
2.2.1 亚马逊网络服务(AWS)
AWS提供了一系列云原生数据库服务,其中最著名的是Amazon DynamoDB和Amazon Aurora。DynamoDB是一个完全托管的NoSQL数据库服务,适用于需要高可扩展性和低延迟的应用。Aurora则是一个兼容MySQL和PostgreSQL的关系型数据库,它结合了高端商业数据库的速度和可靠性以及开源数据库的简单性和成本效益。
数学上,DynamoDB的性能可以通过其内置的自动扩展功能来优化。例如,假设有一个读写请求的速率函数:
R
(
t
)
=
R
0
+
k
t
R(t) = R_0 + kt
R(t)=R0+kt
其中,
R
0
R_0
R0 是初始请求速率,
k
k
k 是增长率,
t
t
t 是时间。DynamoDB可以根据这个函数自动调整其读写容量单位,以保持最佳性能。
2.2.2 微软Azure
Azure的数据库服务包括Azure SQL Database和Azure Cosmos DB。Azure SQL Database是一个完全托管的关系型数据库服务,它基于Microsoft SQL Server引擎。Cosmos DB则是一个全球分布式的多模型数据库服务,支持多种数据模型和API,包括SQL、MongoDB、Cassandra等。
Azure Cosmos DB的全球分布能力可以通过其一致性模型来优化。例如,Cosmos DB提供了五种一致性级别:强一致性、有限过期、会话、一致前缀和最终一致性。选择合适的一致性级别可以通过以下数学模型来决定:
min
c
Cost
(
c
)
\min_{c} \text{Cost}(c)
cminCost(c)
s.t.
Latency
(
c
)
≤
L
m
a
x
\text{s.t.} \quad \text{Latency}(c) \leq L_{max}
s.t.Latency(c)≤Lmax
Availability
(
c
)
≥
A
m
i
n
\text{Availability}(c) \geq A_{min}
Availability(c)≥Amin
其中,
c
c
c 是一致性级别,
Cost
(
c
)
\text{Cost}(c)
Cost(c) 是成本,
Latency
(
c
)
\text{Latency}(c)
Latency(c) 是延迟,
Availability
(
c
)
\text{Availability}(c)
Availability(c) 是可用性。通过优化这个模型,可以选择最适合应用需求的一致性级别。
2.2.3 谷歌云平台(Google Cloud)
Google Cloud的数据库服务包括Google Cloud SQL和Google Cloud Spanner。Cloud SQL是一个完全托管的关系型数据库服务,支持MySQL、PostgreSQL和SQL Server。Cloud Spanner是一个全球分布式的关系型数据库服务,它提供了水平扩展和高可用性,适用于需要强一致性和复杂事务的应用。
Cloud Spanner的扩展能力可以通过其分布式事务处理机制来优化。例如,假设有一个事务处理模型:
T
(
x
)
=
T
0
+
α
x
T(x) = T_0 + \alpha x
T(x)=T0+αx
其中,
T
0
T_0
T0 是基础事务处理时间,
x
x
x 是数据量,
α
\alpha
α 是单位数据量的事务处理时间。Cloud Spanner可以根据这个模型自动调整其资源分配,以保持最佳的事务处理性能。
2.2.4 小结
AWS、Azure和Google Cloud提供的云原生数据库解决方案各有千秋,它们不仅体现了云原生数据库的核心优势,还展示了各自的技术特色和市场定位。通过深入理解这些解决方案的数学模型和实现机制,企业可以更有效地选择和使用云原生数据库服务,以支持其业务需求。随着技术的不断进步,这些云服务提供商将继续推出更多创新的数据库解决方案,为企业带来更多的价值。
2.3 迁移策略:从传统到云原生的无缝过渡
随着云原生数据库技术的不断成熟,越来越多的企业开始考虑将其传统数据库迁移到云原生平台上。这一过程不仅涉及到技术层面的转换,还需要考虑业务连续性、数据安全性和成本效益等多方面因素。本节将详细探讨从传统数据库到云原生数据库的迁移策略,包括迁移前的评估、迁移过程中的技术选择和迁移后的优化。
2.3.1 迁移前的评估
在开始迁移之前,企业需要对现有的数据库环境进行全面的评估。这包括但不限于数据库的规模、性能、数据模型、依赖的应用程序以及业务需求。评估的目的是为了确定迁移的可行性,并为迁移过程制定详细的计划。
数学上,评估可以通过成本效益分析(CBA)来量化。例如,假设迁移的总成本为
C
t
o
t
a
l
C_{total}
Ctotal,迁移后的预期收益为
B
e
x
p
e
c
t
e
d
B_{expected}
Bexpected,则迁移的净现值(NPV)可以表示为:
N
P
V
=
B
e
x
p
e
c
t
e
d
−
C
t
o
t
a
l
NPV = B_{expected} - C_{total}
NPV=Bexpected−Ctotal
如果
N
P
V
>
0
NPV > 0
NPV>0,则迁移在经济上是可行的。
2.3.2 迁移过程中的技术选择
迁移过程中的技术选择是关键步骤,它涉及到选择合适的云服务提供商、数据库服务类型以及迁移工具。例如,如果企业选择AWS作为云服务提供商,它可以选择使用AWS DMS(Database Migration Service)来实现数据的迁移。
数学上,技术选择可以通过决策树分析来优化。例如,假设有多个技术选项
T
i
T_i
Ti,每个选项的成本为
C
i
C_i
Ci,收益为
B
i
B_i
Bi,则可以通过以下公式来选择最佳技术:
max
i
B
i
C
i
\max_{i} \frac{B_i}{C_i}
imaxCiBi
2.3.3 迁移后的优化
迁移完成后,企业需要对新的云原生数据库进行优化,以确保其性能和可靠性。这可能包括调整数据库配置、优化查询性能、实施监控和自动化等。
数学上,优化可以通过性能建模来实现。例如,假设数据库的性能指标为
P
P
P,影响性能的因素为
x
1
,
x
2
,
…
,
x
n
x_1, x_2, \ldots, x_n
x1,x2,…,xn,则可以通过建立性能模型来优化:
P
=
f
(
x
1
,
x
2
,
…
,
x
n
)
P = f(x_1, x_2, \ldots, x_n)
P=f(x1,x2,…,xn)
通过调整
x
i
x_i
xi的值,可以找到最佳的性能配置。
2.3.4 案例分析
为了更具体地说明迁移策略,我们可以考虑一个实际案例。假设一家金融机构决定将其传统的Oracle数据库迁移到Google Cloud的Cloud Spanner。在迁移前,该机构进行了详细的评估,确定了迁移的成本和收益。在迁移过程中,它使用了Google Cloud的迁移工具,并确保了数据的完整性和一致性。迁移后,该机构对Cloud Spanner进行了优化,提高了查询性能和系统的可扩展性。
2.3.5 小结
从传统数据库到云原生数据库的迁移是一个复杂的过程,需要企业在技术、业务和成本等多方面进行综合考虑。通过制定详细的迁移策略,选择合适的技术和工具,并进行迁移后的优化,企业可以实现从传统到云原生的无缝过渡,从而充分利用云原生数据库的优势,提升业务的灵活性和竞争力。随着云原生技术的不断发展,迁移策略也将不断演进,为企业带来更多的机遇和挑战。
2.4 实战代码与案例剖析:传统数据库云原生化的步骤
将传统数据库迁移到云原生环境是一个复杂但可行的过程,涉及多个步骤和技术决策。本节将通过实战代码和案例分析,详细介绍如何实现这一迁移过程,确保数据的无缝过渡和系统的稳定性。
2.4.1 评估与规划
在开始迁移之前,首先需要对现有数据库进行全面的评估。这包括数据库的类型、大小、性能指标、依赖的应用程序以及业务需求。评估的目的是为了确定迁移的可行性,并为迁移过程制定详细的计划。
数学上,评估可以通过成本效益分析(CBA)来量化。例如,假设迁移的总成本为
C
t
o
t
a
l
C_{total}
Ctotal,迁移后的预期收益为
B
e
x
p
e
c
t
e
d
B_{expected}
Bexpected,则迁移的净现值(NPV)可以表示为:
N
P
V
=
B
e
x
p
e
c
t
e
d
−
C
t
o
t
a
l
NPV = B_{expected} - C_{total}
NPV=Bexpected−Ctotal
如果
N
P
V
>
0
NPV > 0
NPV>0,则迁移在经济上是可行的。
2.4.2 选择云服务提供商和数据库服务
根据评估结果,选择合适的云服务提供商和数据库服务。例如,如果企业选择AWS作为云服务提供商,它可以选择使用Amazon RDS或Amazon Aurora作为目标数据库服务。
2.4.3 数据迁移
数据迁移是迁移过程中的核心步骤。这通常涉及到使用特定的迁移工具,如AWS DMS(Database Migration Service),来复制数据和结构。以下是一个使用AWS DMS迁移数据的示例代码片段:
import boto3
# 创建DMS客户端
dms = boto3.client('dms', region_name='us-west-2')# 创建迁移任务
response = dms.create_replication_task(
ReplicationTaskIdentifier='my-migration-task',
SourceEndpointArn='arn:aws:dms:us-west-2:123456789012:endpoint:source-endpoint',
TargetEndpointArn='arn:aws:dms:us-west-2:123456789012:endpoint:target-endpoint',
ReplicationTaskSettings='{"迁移设置"}')
2.4.4 验证与测试
迁移完成后,需要对新的云原生数据库进行验证和测试,确保数据的完整性和系统的稳定性。这可能包括执行一系列的查询测试、性能测试和故障恢复测试。
数学上,验证可以通过统计测试来实现。例如,假设有
n
n
n个测试用例,通过的用例数为
m
m
m,则通过率可以表示为:
通过率
=
m
n
\text{通过率} = \frac{m}{n}
通过率=nm
2.4.5 优化与监控
最后,对新的云原生数据库进行优化,并实施监控以确保长期稳定运行。这可能包括调整数据库配置、优化查询性能、实施自动化监控和报警系统。
数学上,优化可以通过性能建模来实现。例如,假设数据库的性能指标为
P
P
P,影响性能的因素为
x
1
,
x
2
,
…
,
x
n
x_1, x_2, \ldots, x_n
x1,x2,…,xn,则可以通过建立性能模型来优化:
P
=
f
(
x
1
,
x
2
,
…
,
x
n
)
P = f(x_1, x_2, \ldots, x_n)
P=f(x1,x2,…,xn)
通过调整
x
i
x_i
xi的值,可以找到最佳的性能配置。
2.4.6 案例分析
为了更具体地说明迁移步骤,我们可以考虑一个实际案例。假设一家电子商务公司决定将其传统的MySQL数据库迁移到Google Cloud的Cloud SQL。在迁移前,该公司进行了详细的评估,确定了迁移的成本和收益。在迁移过程中,它使用了Google Cloud的迁移工具,并确保了数据的完整性和一致性。迁移后,该公司对Cloud SQL进行了优化,提高了查询性能和系统的可扩展性。
2.4.7 小结
从传统数据库到云原生数据库的迁移是一个复杂的过程,需要企业在技术、业务和成本等多方面进行综合考虑。通过制定详细的迁移策略,选择合适的技术和工具,并进行迁移后的优化,企业可以实现从传统到云原生的无缝过渡,从而充分利用云原生数据库的优势,提升业务的灵活性和竞争力。随着云原生技术的不断发展,迁移策略也将不断演进,为企业带来更多的机遇和挑战。
2.5 性能对比:云原生与传统数据库的性能较量
在数据库技术的演进中,云原生数据库的出现为传统的本地数据库带来了新的挑战和机遇。云原生数据库以其高度的可扩展性、弹性和自动化管理等特点,逐渐成为企业数据管理的新选择。本节将深入探讨云原生数据库与传统数据库在性能上的对比,通过具体的数学模型和案例分析,揭示两者之间的差异和优劣。
2.5.1 性能指标的定义
在进行性能对比之前,首先需要明确性能指标。常见的性能指标包括响应时间、吞吐量、并发用户数、数据一致性和可用性等。这些指标可以通过数学模型来量化,例如响应时间可以用以下公式表示:
T
r
e
s
p
o
n
s
e
=
T
q
u
e
r
y
+
T
p
r
o
c
e
s
s
i
n
g
+
T
n
e
t
w
o
r
k
T_{response} = T_{query} + T_{processing} + T_{network}
Tresponse=Tquery+Tprocessing+Tnetwork
其中,
T
r
e
s
p
o
n
s
e
T_{response}
Tresponse 是总响应时间,
T
q
u
e
r
y
T_{query}
Tquery 是查询时间,
T
p
r
o
c
e
s
s
i
n
g
T_{processing}
Tprocessing 是处理时间,
T
n
e
t
w
o
r
k
T_{network}
Tnetwork 是网络传输时间。
2.5.2 云原生数据库的性能优势
云原生数据库通常具有以下性能优势:
弹性扩展:云原生数据库可以根据负载自动扩展资源,这可以通过以下数学模型来描述:
R s c a l e = α × L R_{scale} = \alpha \times LRscale=α×L
其中,
R
s
c
a
l
e
R_{scale}
Rscale 是资源扩展量,
α
\alpha
α 是扩展系数,
L
L
L 是负载量。
高可用性:云原生数据库通过分布式架构提供高可用性,可用性可以通过以下公式计算:
A v a i l a b i l i t y = M T B F M T B F + M T T R × 100 % A_{vailability} = \frac{MTBF}{MTBF + MTTR} \times 100\%Availability=MTBF+MTTRMTBF×100%
其中,
M
T
B
F
MTBF
MTBF 是平均故障间隔时间,
M
T
T
R
MTTR
MTTR 是平均修复时间。
- 自动化管理:云原生数据库的自动化管理可以减少人为错误,提高系统稳定性。
2.5.3 传统数据库的性能特点
传统数据库虽然在某些方面可能不如云原生数据库灵活,但它们在以下方面可能具有优势:
成熟稳定:传统数据库经过长时间的发展,通常具有较高的稳定性和成熟度。
定制化:传统数据库可以根据特定需求进行深度定制,这可以通过以下公式来描述:
P c u s t o m i z a t i o n = β × D P_{customization} = \beta \times DPcustomization=β×D
其中,
P
c
u
s
t
o
m
i
z
a
t
i
o
n
P_{customization}
Pcustomization 是定制化程度,
β
\beta
β 是定制化系数,
D
D
D 是需求复杂度。
- 性能优化:传统数据库可以通过硬件升级和优化配置来提升性能。
2.5.4 性能对比案例分析
为了更具体地展示云原生与传统数据库的性能对比,我们可以考虑一个实际案例。假设一家金融机构需要处理大量的交易数据,它可以选择使用传统的Oracle数据库或者云原生的Google Cloud Spanner。通过对比两者的响应时间、吞吐量和可用性,可以得出以下结论:
- 在响应时间方面,Spanner由于其分布式架构和自动扩展能力,可能在高负载下表现更好。
- 在吞吐量方面,Oracle数据库可能在单点性能上略有优势,但在大规模并发处理上可能不如Spanner。
- 在可用性方面,Spanner的高可用性设计使其在故障恢复和灾难恢复方面具有明显优势。
2.5.5 小结
云原生数据库与传统数据库在性能上各有千秋,企业在选择时需要根据自身的业务需求和成本考虑进行权衡。随着云原生技术的不断成熟,其在性能上的优势将越来越明显,但传统数据库在某些特定场景下仍然具有不可替代的价值。通过深入分析和对比,企业可以更好地理解两者的性能差异,从而做出更合适的选择。随着技术的不断进步,数据库技术将继续演化,为企业带来更多的可能性和挑战。
2.6 深度阅读:云原生数据库的最佳实践与案例研究推荐
随着云原生数据库技术的快速发展,越来越多的企业和开发者开始关注如何在实际应用中有效地利用这些技术。本节将推荐一些关于云原生数据库的最佳实践和案例研究,帮助读者深入理解云原生数据库的实际应用和优化策略。
2.6.1 云原生数据库的最佳实践
云原生数据库的最佳实践通常包括以下几个方面:
资源优化:合理配置数据库资源,以满足业务需求同时避免资源浪费。例如,通过监控数据库的CPU和内存使用情况,动态调整资源分配。
性能调优:通过优化查询、索引和数据模型,提高数据库的响应速度和吞吐量。性能调优可以通过以下数学模型来量化:
P o p t i m i z a t i o n = T b e f o r e − T a f t e r T b e f o r e × 100 % P_{optimization} = \frac{T_{before} - T_{after}}{T_{before}} \times 100\%Poptimization=TbeforeTbefore−Tafter×100%
其中,
P
o
p
t
i
m
i
z
a
t
i
o
n
P_{optimization}
Poptimization 是性能提升的百分比,
T
b
e
f
o
r
e
T_{before}
Tbefore 和
T
a
f
t
e
r
T_{after}
Tafter 分别是优化前后的响应时间。
高可用性和灾难恢复:设计高可用的数据库架构,确保在硬件故障或自然灾害时数据的安全和服务的连续性。高可用性可以通过以下公式来评估:
A v a i l a b i l i t y = M T B F M T B F + M T T R × 100 % A_{vailability} = \frac{MTBF}{MTBF + MTTR} \times 100\%Availability=MTBF+MTTRMTBF×100%
其中,
M
T
B
F
MTBF
MTBF 是平均故障间隔时间,
M
T
T
R
MTTR
MTTR 是平均修复时间。
- 安全性:实施严格的安全策略,包括数据加密、访问控制和审计日志,以保护数据不受未授权访问和恶意攻击。
2.6.2 案例研究推荐
以下是一些值得深入研究的云原生数据库案例:
- Netflix的Cassandra云原生部署:Netflix使用Cassandra作为其云原生数据库,实现了高度的可扩展性和灵活性。该案例详细介绍了Netflix如何通过自动化工具和监控系统来管理和优化其Cassandra集群。
- Spotify的云原生数据仓库:Spotify采用Google BigQuery作为其云原生数据仓库,有效地处理和分析了大量的用户数据。该案例研究了Spotify如何通过BigQuery实现数据驱动的决策支持。
- Airbnb的实时数据处理:Airbnb使用Apache Kafka和Google Cloud Pub/Sub构建了其实时数据处理系统,实现了对用户行为的实时监控和分析。该案例展示了如何通过云原生技术实现复杂的数据流处理。
2.6.3 小结
云原生数据库的最佳实践和案例研究为我们提供了宝贵的经验和知识,帮助我们更好地理解和应用这些先进的技术。通过深入阅读和分析这些案例,我们可以学习到如何在实际业务中有效地部署和优化云原生数据库,从而提升企业的数据处理能力和业务竞争力。随着云原生技术的不断发展,未来的数据库管理将更加智能、高效和安全,为企业带来更多的创新和价值。
3. 全球化数据管理:新挑战与机遇
3.1 跨地域数据策略:同步、复制、分片
在全球化的商业环境中,企业面临着跨地域数据管理的挑战。为了确保数据的一致性、可用性和性能,企业需要采取有效的数据策略,如数据同步、复制和分片。本节将深入探讨这些策略的原理、实施方法和数学模型,并通过具体案例分析,展示它们在实际应用中的效果。
3.1.1 数据同步
数据同步是指在不同地理位置的数据库之间保持数据的一致性。这通常涉及到实时或定期的数据传输,以确保所有数据库副本都包含最新的数据变更。数据同步可以通过以下数学模型来描述:
S
s
y
n
c
=
T
u
p
d
a
t
e
T
p
r
o
p
a
g
a
t
i
o
n
S_{sync} = \frac{T_{update}}{T_{propagation}}
Ssync=TpropagationTupdate
其中,
S
s
y
n
c
S_{sync}
Ssync 是同步效率,
T
u
p
d
a
t
e
T_{update}
Tupdate 是数据更新时间,
T
p
r
o
p
a
g
a
t
i
o
n
T_{propagation}
Tpropagation 是数据传播到所有副本的时间。
3.1.2 数据复制
数据复制是指在多个地理位置创建数据库的副本,以提高数据的可用性和读取性能。复制策略可以分为同步复制和异步复制。同步复制确保所有副本的数据完全一致,而异步复制则允许副本之间存在一定的延迟。数据复制的数学模型可以表示为:
R
r
e
p
l
i
c
a
t
i
o
n
=
N
r
e
p
l
i
c
a
s
N
t
o
t
a
l
R_{replication} = \frac{N_{replicas}}{N_{total}}
Rreplication=NtotalNreplicas
其中,
R
r
e
p
l
i
c
a
t
i
o
n
R_{replication}
Rreplication 是复制率,
N
r
e
p
l
i
c
a
s
N_{replicas}
Nreplicas 是副本数量,
N
t
o
t
a
l
N_{total}
Ntotal 是总的数据库数量。
3.1.3 数据分片
数据分片是将大型数据库分割成多个较小的部分,每个部分称为一个分片。分片可以基于数据的某个属性(如用户ID、地理位置等)进行。分片策略有助于提高数据库的性能和可管理性。数据分片的数学模型可以表示为:
S
s
h
a
r
d
i
n
g
=
S
d
a
t
a
S
s
h
a
r
d
S_{sharding} = \frac{S_{data}}{S_{shard}}
Ssharding=SshardSdata
其中,
S
s
h
a
r
d
i
n
g
S_{sharding}
Ssharding 是分片效率,
S
d
a
t
a
S_{data}
Sdata 是总数据量,
S
s
h
a
r
d
S_{shard}
Sshard 是单个分片的数据量。
3.1.4 案例分析:跨地域数据策略的实施
为了更具体地说明这些策略的应用,我们可以考虑一个跨国电子商务公司的案例。该公司在全球多个地区设有数据中心,需要确保所有用户都能快速访问其服务。通过实施以下策略,该公司实现了高效的跨地域数据管理:
- 数据同步:使用实时同步技术,确保所有数据中心的库存数据保持一致,从而避免了超卖的情况。
- 数据复制:在每个数据中心创建主数据库的副本,以提高读取性能和容错能力。通过监控复制延迟,确保数据的一致性。
- 数据分片:根据用户的地理位置将用户数据分片,使得用户请求可以被最近的数据中心处理,从而减少延迟。
3.1.5 小结
跨地域数据策略是全球化数据管理的关键组成部分。通过合理选择和实施数据同步、复制和分片策略,企业可以有效地应对数据一致性、可用性和性能的挑战。随着技术的不断进步,这些策略将继续演化,为企业带来更多的灵活性和效率。通过深入理解和应用这些策略,企业可以更好地适应全球化的商业环境,实现数据驱动的决策和创新。
3.2 数据一致性与合规性:全球数据管理的法律与隐私考量
在全球化的数据管理实践中,确保数据的一致性和合规性是企业面临的关键挑战。随着数据保护法规的日益严格,企业不仅需要关注技术层面的数据同步和复制,还必须深入理解并遵守各国的法律和隐私规定。本节将探讨如何在跨地域数据管理中实现数据一致性和合规性,并提供相关的法律和隐私考量。
3.2.1 数据一致性的技术挑战
数据一致性是指在分布式系统中,所有数据副本保持同步和一致的状态。在跨地域数据管理中,由于网络延迟、数据复制延迟和并发操作等因素,保持数据一致性是一个复杂的问题。数据一致性可以通过以下数学模型来量化:
C
c
o
n
s
i
s
t
e
n
c
y
=
N
c
o
n
s
i
s
t
e
n
t
N
t
o
t
a
l
×
100
%
C_{consistency} = \frac{N_{consistent}}{N_{total}} \times 100\%
Cconsistency=NtotalNconsistent×100%
其中,
C
c
o
n
s
i
s
t
e
n
c
y
C_{consistency}
Cconsistency 是数据一致性的百分比,
N
c
o
n
s
i
s
t
e
n
t
N_{consistent}
Nconsistent 是保持一致的数据副本数量,
N
t
o
t
a
l
N_{total}
Ntotal 是总的数据副本数量。
3.2.2 合规性的法律框架
合规性要求企业在处理个人数据时遵守相关的法律和规定。例如,GDPR要求企业在处理欧盟居民的个人数据时必须遵循数据最小化、目的限制、存储限制和数据主体权利等原则。合规性可以通过以下数学模型来评估:
C
c
o
m
p
l
i
a
n
c
e
=
N
c
o
m
p
l
i
a
n
t
N
t
o
t
a
l
×
100
%
C_{compliance} = \frac{N_{compliant}}{N_{total}} \times 100\%
Ccompliance=NtotalNcompliant×100%
其中,
C
c
o
m
p
l
i
a
n
c
e
C_{compliance}
Ccompliance 是合规性的百分比,
N
c
o
m
p
l
i
a
n
t
N_{compliant}
Ncompliant 是符合法律要求的数据处理操作数量,
N
t
o
t
a
l
N_{total}
Ntotal 是总的数据处理操作数量。
3.2.3 隐私保护的技术措施
为了保护用户隐私,企业需要实施各种技术措施,如数据加密、匿名化和访问控制。数据加密可以通过数学算法来实现,例如使用RSA算法进行非对称加密:
E
c
i
p
h
e
r
t
e
x
t
=
R
S
A
(
E
p
r
i
v
a
t
e
,
D
p
l
a
i
n
t
e
x
t
)
E_{ciphertext} = RSA(E_{private}, D_{plaintext})
Eciphertext=RSA(Eprivate,Dplaintext)
其中,
E
c
i
p
h
e
r
t
e
x
t
E_{ciphertext}
Eciphertext 是加密后的密文,
E
p
r
i
v
a
t
e
E_{private}
Eprivate 是私钥,
D
p
l
a
i
n
t
e
x
t
D_{plaintext}
Dplaintext 是明文数据。
3.2.4 案例分析:跨国公司的数据合规策略
考虑一家跨国公司,其业务遍布全球,需要处理来自不同国家和地区的用户数据。该公司采取了以下策略来确保数据一致性和合规性:
- 数据同步:使用分布式事务处理技术,确保在不同地理位置的数据库之间实现强一致性。
- 合规性审查:定期进行合规性审查,确保所有数据处理活动符合当地法律和国际标准。
- 隐私保护:实施端到端的数据加密,确保数据在传输和存储过程中的安全性。同时,对敏感数据进行匿名化处理,以保护用户隐私。
3.2.5 小结
在全球数据管理中,数据一致性和合规性是企业必须面对的重要挑战。通过采用先进的技术和策略,企业可以有效地实现数据一致性,并确保遵守相关的法律和隐私规定。随着数据保护法规的不断发展,企业需要持续关注法律变化,并调整其数据管理策略,以适应不断变化的全球数据环境。通过深入理解和应用这些策略,企业可以更好地保护用户隐私,同时确保数据的准确性和可用性,从而在全球市场中保持竞争力。
3.3 实战代码与案例剖析:全球数据管理的有效策略
在全球化的商业环境中,数据管理策略的有效性直接关系到企业的运营效率和合规性。本节将通过具体的实战代码和案例剖析,展示如何实施全球数据管理的有效策略。我们将探讨数据同步、复制、分片以及合规性管理的实际操作,并提供相关的数学模型和算法。
3.3.1 数据同步的实战代码
数据同步是确保跨地域数据库一致性的关键技术。以下是一个简化的数据同步实战代码示例,使用Python语言和MySQL数据库:
import mysql.connector
from mysql.connector import errorcode
# 配置数据库连接
config ={"user":"username","password":"password","host":"192.168.1.1","database":"database_name","raise_on_warnings":True}try:
cnx = mysql.connector.connect(**config)
cursor = cnx.cursor()# 同步数据
query =("SELECT * FROM table_name")
cursor.execute(query)for(column1, column2,...)in cursor:print("{} / {} / ...".format(column1, column2))
cursor.close()
cnx.close()except mysql.connector.Error as err:if err.errno == errorcode.ER_ACCESS_DENIED_ERROR:print("Something is wrong with your user name or password")elif err.errno == errorcode.ER_BAD_DB_ERROR:print("Database does not exist")else:print(err)
3.3.2 数据复制的实战代码
数据复制是提高数据可用性和读取性能的常用策略。以下是一个使用MySQL的复制功能进行数据复制的实战代码示例:
-- 在主数据库上配置复制
CHANGE MASTER TO MASTER_HOST='master_host_name', MASTER_USER='replication_user_name', MASTER_PASSWORD='replication_password', MASTER_LOG_FILE='recorded_log_file_name', MASTER_LOG_POS=recorded_log_position;-- 启动复制START SLAVE;
3.3.3 数据分片的实战代码
数据分片是将大型数据库分割成多个较小的部分,以提高性能和管理效率。以下是一个使用哈希函数进行数据分片的实战代码示例:
defhash_shard(key, num_shards):returnhash(key)% num_shards
# 示例使用
key ="user_id_123"
num_shards =10
shard_id = hash_shard(key, num_shards)print("Shard ID for key {} is {}".format(key, shard_id))
3.3.4 合规性管理的实战代码
合规性管理涉及到数据处理活动的监控和审计。以下是一个使用Python和SQLite进行数据审计的实战代码示例:
import sqlite3
# 连接到SQLite数据库
conn = sqlite3.connect('audit.db')
cursor = conn.cursor()# 创建审计表
cursor.execute('''CREATE TABLE IF NOT EXISTS audit_log
(timestamp TEXT, user TEXT, action TEXT)''')# 记录审计日志
cursor.execute("INSERT INTO audit_log VALUES (CURRENT_TIMESTAMP, 'user_name', 'data_action')")# 提交更改并关闭连接
conn.commit()
conn.close()
3.3.5 案例剖析:跨国公司的数据管理策略
考虑一家跨国公司,其业务遍布全球,需要处理来自不同国家和地区的用户数据。该公司采取了以下策略来确保数据一致性和合规性:
- 数据同步:使用分布式事务处理技术,确保在不同地理位置的数据库之间实现强一致性。
- 合规性审查:定期进行合规性审查,确保所有数据处理活动符合当地法律和国际标准。
- 隐私保护:实施端到端的数据加密,确保数据在传输和存储过程中的安全性。同时,对敏感数据进行匿名化处理,以保护用户隐私。
3.3.6 小结
通过实战代码和案例剖析,我们可以看到全球数据管理的有效策略是如何在实际中应用的。这些策略不仅涉及技术层面的实现,还包括法律和隐私的考量。随着技术的不断进步,企业需要持续关注并适应新的数据管理技术和法规要求,以确保在全球化竞争中保持领先地位。通过深入理解和应用这些策略,企业可以更好地保护用户隐私,同时确保数据的准确性和可用性,从而在全球市场中保持竞争力。
3.4 架构可视化:全球化数据管理架构的直观展示
在全球化数据管理中,架构可视化是一种强大的工具,它帮助企业和技术团队直观地理解和优化复杂的数据管理架构。通过图形化的展示,我们可以更清晰地看到数据流、系统交互和架构设计,从而更有效地进行决策和优化。本节将探讨如何通过可视化技术来展示全球化数据管理架构,并提供一些实用的工具和方法。
3.4.1 数据流的可视化
数据流可视化是展示数据如何在不同系统和服务之间流动的过程。这通常涉及到使用流程图、时序图或数据流图来表示数据的传输路径。例如,一个简单的数据流图可以表示如下:
#mermaid-svg-noCU7CLT28jCYDpB {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-noCU7CLT28jCYDpB .error-icon{fill:#552222;}#mermaid-svg-noCU7CLT28jCYDpB .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-noCU7CLT28jCYDpB .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-noCU7CLT28jCYDpB .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-noCU7CLT28jCYDpB .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-noCU7CLT28jCYDpB .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-noCU7CLT28jCYDpB .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-noCU7CLT28jCYDpB .marker{fill:#333333;stroke:#333333;}#mermaid-svg-noCU7CLT28jCYDpB .marker.cross{stroke:#333333;}#mermaid-svg-noCU7CLT28jCYDpB svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-noCU7CLT28jCYDpB .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-noCU7CLT28jCYDpB .cluster-label text{fill:#333;}#mermaid-svg-noCU7CLT28jCYDpB .cluster-label span{color:#333;}#mermaid-svg-noCU7CLT28jCYDpB .label text,#mermaid-svg-noCU7CLT28jCYDpB span{fill:#333;color:#333;}#mermaid-svg-noCU7CLT28jCYDpB .node rect,#mermaid-svg-noCU7CLT28jCYDpB .node circle,#mermaid-svg-noCU7CLT28jCYDpB .node ellipse,#mermaid-svg-noCU7CLT28jCYDpB .node polygon,#mermaid-svg-noCU7CLT28jCYDpB .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-noCU7CLT28jCYDpB .node .label{text-align:center;}#mermaid-svg-noCU7CLT28jCYDpB .node.clickable{cursor:pointer;}#mermaid-svg-noCU7CLT28jCYDpB .arrowheadPath{fill:#333333;}#mermaid-svg-noCU7CLT28jCYDpB .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-noCU7CLT28jCYDpB .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-noCU7CLT28jCYDpB .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid-svg-noCU7CLT28jCYDpB .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid-svg-noCU7CLT28jCYDpB .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-noCU7CLT28jCYDpB .cluster text{fill:#333;}#mermaid-svg-noCU7CLT28jCYDpB .cluster span{color:#333;}#mermaid-svg-noCU7CLT28jCYDpB div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-noCU7CLT28jCYDpB :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;}
请求
处理请求
返回数据
响应
用户
应用服务器
数据库
在这个图中,用户(A)向应用服务器(B)发送请求,应用服务器处理请求并从数据库(C)获取数据,最后将响应返回给用户。
3.4.2 系统架构的可视化
系统架构可视化涉及到使用架构图来展示系统的组件和它们之间的关系。这可以帮助理解系统的整体结构和组件之间的依赖关系。例如,一个云原生数据库的架构图可能包括以下组件:
- 数据库实例
- 负载均衡器
- 存储服务
- 安全层
这些组件可以通过UML图或更直观的图形工具如Draw.io来展示。
3.4.3 数据分片和复制的可视化
数据分片和复制是全球化数据管理中的关键技术。通过可视化,我们可以展示数据如何被分割成多个部分,并在不同的地理位置进行复制。例如,一个数据分片的可视化可能展示如下:
#mermaid-svg-5Mu1F7cfSFE95s5B {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-5Mu1F7cfSFE95s5B .error-icon{fill:#552222;}#mermaid-svg-5Mu1F7cfSFE95s5B .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-5Mu1F7cfSFE95s5B .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-5Mu1F7cfSFE95s5B .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-5Mu1F7cfSFE95s5B .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-5Mu1F7cfSFE95s5B .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-5Mu1F7cfSFE95s5B .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-5Mu1F7cfSFE95s5B .marker{fill:#333333;stroke:#333333;}#mermaid-svg-5Mu1F7cfSFE95s5B .marker.cross{stroke:#333333;}#mermaid-svg-5Mu1F7cfSFE95s5B svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-5Mu1F7cfSFE95s5B .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-5Mu1F7cfSFE95s5B .cluster-label text{fill:#333;}#mermaid-svg-5Mu1F7cfSFE95s5B .cluster-label span{color:#333;}#mermaid-svg-5Mu1F7cfSFE95s5B .label text,#mermaid-svg-5Mu1F7cfSFE95s5B span{fill:#333;color:#333;}#mermaid-svg-5Mu1F7cfSFE95s5B .node rect,#mermaid-svg-5Mu1F7cfSFE95s5B .node circle,#mermaid-svg-5Mu1F7cfSFE95s5B .node ellipse,#mermaid-svg-5Mu1F7cfSFE95s5B .node polygon,#mermaid-svg-5Mu1F7cfSFE95s5B .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-5Mu1F7cfSFE95s5B .node .label{text-align:center;}#mermaid-svg-5Mu1F7cfSFE95s5B .node.clickable{cursor:pointer;}#mermaid-svg-5Mu1F7cfSFE95s5B .arrowheadPath{fill:#333333;}#mermaid-svg-5Mu1F7cfSFE95s5B .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-5Mu1F7cfSFE95s5B .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-5Mu1F7cfSFE95s5B .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid-svg-5Mu1F7cfSFE95s5B .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid-svg-5Mu1F7cfSFE95s5B .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-5Mu1F7cfSFE95s5B .cluster text{fill:#333;}#mermaid-svg-5Mu1F7cfSFE95s5B .cluster span{color:#333;}#mermaid-svg-5Mu1F7cfSFE95s5B div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-5Mu1F7cfSFE95s5B :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;}
分片1
分片2
分片3
主数据库
分片数据库1
分片数据库2
分片数据库3
在这个图中,主数据库(A)将数据分片到三个不同的分片数据库(B, C, D)。
3.4.4 合规性和安全性的可视化
合规性和安全性是全球化数据管理中不可忽视的方面。通过可视化,我们可以展示数据如何被加密、匿名化以及如何遵守各种数据保护法规。例如,一个数据加密的可视化可能展示如下:
#mermaid-svg-WekbqXB2mO9qUNud {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-WekbqXB2mO9qUNud .error-icon{fill:#552222;}#mermaid-svg-WekbqXB2mO9qUNud .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-WekbqXB2mO9qUNud .edge-thickness-normal{stroke-width:2px;}#mermaid-svg-WekbqXB2mO9qUNud .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-WekbqXB2mO9qUNud .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-WekbqXB2mO9qUNud .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-WekbqXB2mO9qUNud .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-WekbqXB2mO9qUNud .marker{fill:#333333;stroke:#333333;}#mermaid-svg-WekbqXB2mO9qUNud .marker.cross{stroke:#333333;}#mermaid-svg-WekbqXB2mO9qUNud svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-WekbqXB2mO9qUNud .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-WekbqXB2mO9qUNud .cluster-label text{fill:#333;}#mermaid-svg-WekbqXB2mO9qUNud .cluster-label span{color:#333;}#mermaid-svg-WekbqXB2mO9qUNud .label text,#mermaid-svg-WekbqXB2mO9qUNud span{fill:#333;color:#333;}#mermaid-svg-WekbqXB2mO9qUNud .node rect,#mermaid-svg-WekbqXB2mO9qUNud .node circle,#mermaid-svg-WekbqXB2mO9qUNud .node ellipse,#mermaid-svg-WekbqXB2mO9qUNud .node polygon,#mermaid-svg-WekbqXB2mO9qUNud .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-WekbqXB2mO9qUNud .node .label{text-align:center;}#mermaid-svg-WekbqXB2mO9qUNud .node.clickable{cursor:pointer;}#mermaid-svg-WekbqXB2mO9qUNud .arrowheadPath{fill:#333333;}#mermaid-svg-WekbqXB2mO9qUNud .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-WekbqXB2mO9qUNud .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-WekbqXB2mO9qUNud .edgeLabel{background-color:#e8e8e8;text-align:center;}#mermaid-svg-WekbqXB2mO9qUNud .edgeLabel rect{opacity:0.5;background-color:#e8e8e8;fill:#e8e8e8;}#mermaid-svg-WekbqXB2mO9qUNud .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-WekbqXB2mO9qUNud .cluster text{fill:#333;}#mermaid-svg-WekbqXB2mO9qUNud .cluster span{color:#333;}#mermaid-svg-WekbqXB2mO9qUNud div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-WekbqXB2mO9qUNud :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;}
加密
存储
明文数据
密文数据
安全存储
在这个图中,明文数据(A)被加密成密文数据(B),然后存储在安全的存储系统(C)中。
3.4.5 案例分析:跨国公司的数据管理架构可视化
考虑一家跨国公司,其业务遍布全球,需要处理来自不同国家和地区的用户数据。该公司通过以下步骤实现了数据管理架构的可视化:
- 数据流可视化:使用流程图展示了数据从用户到应用服务器再到数据库的完整路径。
- 系统架构可视化:通过架构图展示了云原生数据库的各个组件及其交互。
- 数据分片和复制可视化:展示了数据如何在不同地理位置进行分片和复制。
- 合规性和安全性可视化:展示了数据如何在整个流程中保持安全和合规。
3.4.6 小结
架构可视化是理解和优化全球化数据管理架构的关键工具。通过清晰地展示数据流、系统架构、数据分片和复制以及合规性和安全性,企业和技术团队可以更有效地进行决策和优化。随着技术的不断进步,可视化工具和方法也将不断发展,帮助我们更好地应对全球化数据管理的挑战。通过深入理解和应用这些可视化策略,企业可以更好地保护用户隐私,同时确保数据的准确性和可用性,从而在全球市场中保持竞争力。

4. 结语:展望未来
在本文中,我们深入探讨了未来数据库革新的关键领域,包括智能数据库管理、云原生数据库以及全球化数据管理。这些技术的发展不仅推动了数据处理能力的飞跃,也为企业带来了前所未有的机遇和挑战。在结语部分,我们将展望这些技术的未来趋势,探讨它们如何影响不同行业,并提供个人和企业的行动建议。
4.1 技术融合的趋势:AI、云原生与区块链的协同作用
随着技术的不断进步,AI、云原生和区块链等技术的融合将成为推动数据库革新的重要力量。AI的智能分析能力与云原生的弹性、自动化特性相结合,将使数据管理更加高效和智能。例如,通过机器学习算法优化数据库查询,可以显著减少查询时间,提高数据检索效率。此外,区块链技术的引入可以增强数据的安全性和不可篡改性,这对于金融、医疗等行业的数据管理尤为重要。
数学上,我们可以通过优化理论来分析和设计这些系统的效率。例如,使用线性规划或整数规划来优化资源分配,确保在有限的资源下实现最大的性能提升。公式如下:
maximize
c
T
x
subject to
A
x
≤
b
,
x
≥
0
\text{maximize} \quad c^T x \\ \text{subject to} \quad A x \leq b, \quad x \geq 0
maximizecTxsubject toAx≤b,x≥0
其中,
x
x
x 是决策变量,
c
c
c 是目标函数的系数,
A
A
A 和
b
b
b 是约束条件。
4.2 数据管理的未来挑战:隐私保护与合规性
随着数据量的激增,数据隐私和合规性成为全球数据管理面临的主要挑战。GDPR等法规的实施要求企业必须严格遵守数据保护规定,这不仅涉及技术层面的数据加密和匿名化处理,还需要在组织结构和业务流程上进行相应的调整。
在数学上,隐私保护可以通过差分隐私(Differential Privacy)来实现,其核心思想是在数据发布时添加一定的随机性,以保护个体信息不被识别。差分隐私的数学定义如下:
ϵ
−
differentially private
⟺
∀
S
⊆
R
a
n
g
e
(
M
)
,
Pr
[
M
(
x
)
∈
S
]
≤
e
ϵ
Pr
[
M
(
x
′
)
∈
S
]
\epsilon-\text{differentially private} \iff \forall S \subseteq Range(M), \quad \Pr[M(x) \in S] \leq e^\epsilon \Pr[M(x') \in S]
ϵ−differentially private⟺∀S⊆Range(M),Pr[M(x)∈S]≤eϵPr[M(x′)∈S]
其中,
M
M
M 是一个随机算法,
x
x
x 和
x
′
x'
x′ 是相邻数据集,
ϵ
\epsilon
ϵ 是一个小的正数,控制隐私保护的程度。
4.3 教育与培训:培养未来的数据库专家
面对这些技术变革,教育与培训成为关键。未来的数据库专家不仅需要掌握传统的数据库知识,还需要深入理解AI、云原生和区块链等新兴技术。教育机构和企业应合作开发新的课程和培训项目,以确保人才的持续供应和技术的顺利过渡。
4.4 结语:行动建议
对于个人,建议积极学习新技术,特别是AI和云原生相关的知识,以提升自身的竞争力。对于企业,建议制定长期的技术发展规划,投资于新技术和人才培训,同时密切关注行业法规的变化,确保合规性。
总之,未来的数据库技术将继续以惊人的速度发展,为我们带来更多的可能性和挑战。让我们拥抱变化,共同迎接这个充满机遇的新时代。
版权归原作者 fanjianglin 所有, 如有侵权,请联系我们删除。